TMI 2024 纯卷积的反击!RDP:无需预对齐的递归金字塔医学图像配准新 SOTA
论文题目 :Recursive Deformable Pyramid Network for Unsupervised Medical Image Registration
发表出处 :IEEE Transactions on Medical Imaging (TMI), Vol. 43, No. 6, June 2024
作者机构 :Haiqiao Wang, Dong Ni, Yi Wang 等 (深圳大学医学超声关键技术国家地方联合工程实验室)
关键词 :Deformable Image Registration, Convolutional Neural Networks, Pyramid Network, Brain MRI
Github:https://github.com/ZAX130/RDP.git
1. 🚀 省流版摘要 (TL;DR)
本文提出了一种名为 RDP (Recursive Deformable Pyramid) 的无监督医学图像配准网络。与当前盲目堆砌 Transformer 或复杂注意力机制的趋势不同,RDP 回归了纯卷积 架构,通过巧妙的递归金字塔策略,实现了由粗到精的形变场预测。
该方法不仅在 LPBA 、Mindboggle 和 IXI 三大公开数据集上击败了包括 TransMorph 在内的 SOTA 方法,更重要的是,它无需耗时的仿射预对齐(Affine Pre-alignment) 也能处理大变形,极大地提升了临床部署的便捷性和效率。
2. 🧐 背景与痛点 (Motivation)
现有问题
医学图像配准(Image Registration)旨在寻找一个非线性变换,将浮动图像(Moving Image)对齐到固定图像(Fixed Image)。然而,面对大体积形变(Large Volumetric Deformations),传统的迭代优化方法速度太慢,而早期的深度学习方法(如 VoxelMorph)往往因为单阶段预测能力有限,难以捕捉复杂的解剖结构变化。
传统方法的局限
为了解决大变形问题,业界提出了"金字塔(Pyramid)"结构,即由粗到精逐步配准。然而,现有的金字塔网络存在以下痛点:
- 架构臃肿:为了提升性能,许多网络引入了沉重的 Transformer 或复杂的 Attention 模块(如 PCnet),导致显存占用高,训练困难。
- 语义模糊:部分方法在金字塔层级间传递特征时,忽略了高层语义信息的融合,导致底层特征缺乏全局指导。
- 依赖预处理:绝大多数现有的深度配准网络(包括 TransMorph)都假设输入图像已经经过了刚性或仿射对齐。如果直接输入原始图像,性能会断崖式下跌。这意味着临床使用时必须先跑一个传统的仿射配准,增加了额外的时间成本和插值误差。
本文的切入点
作者团队反其道而行之,思考:是否可以不使用 Transformer,仅通过优化纯卷积网络的结构设计来解决大变形问题?
他们的答案是 RDP------利用**递归(Recursive)**机制,在金字塔的每一层内部进行多次迭代修正,并强化层级间的语义传递,从而在保持模型轻量化的同时,实现对大变形的精准捕捉。
3. 💡 核心方法 (Methodology)
本文的核心在于设计了一个递归可变形金字塔(Recursive Deformable Pyramid)。
3.1 整体架构 (Overall Architecture)
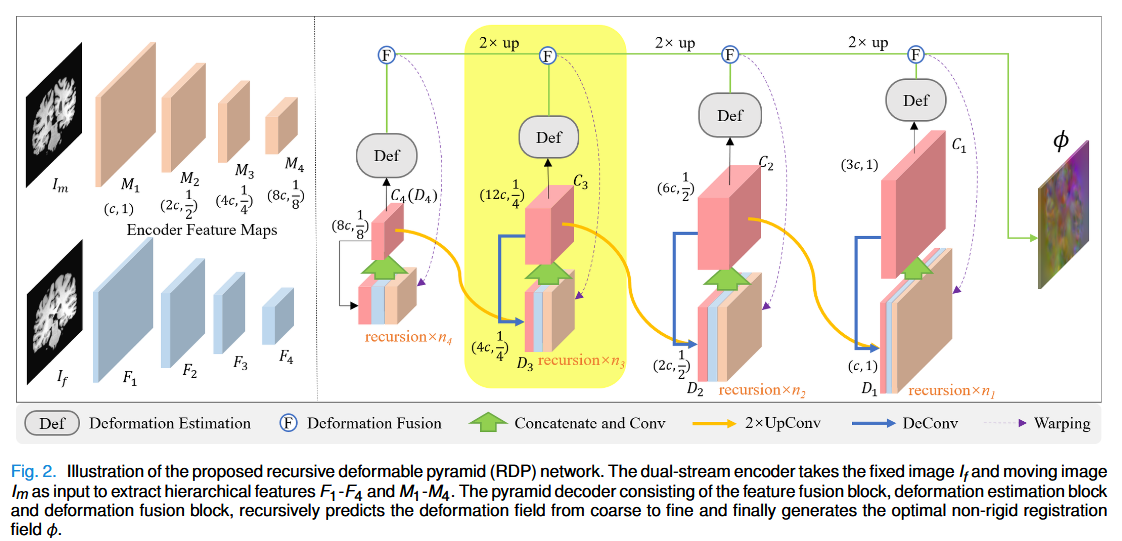
模型采用了经典的 U-Net 变体结构:
- 双流编码器 (Dual-stream Encoder):不共享权重的 ResNet 模块分别提取 Fixed Image 和 Moving Image 的特征。这考虑到两幅图像在未对齐前空间分布差异巨大,独立编码更合理。
- 金字塔解码器:这是核心所在。解码器分为 4 个层级(Level),从最深层(低分辨率)到浅层(高分辨率)依次进行。
3.2 关键模块详解 (Key Modules)
1. 递归策略 (Recursion Strategy)
这是 RDP 的灵魂。在解码器的每一层 lll 中,网络并不是只预测一次形变场,而是进行 nln_lnl 次循环递归。
- 流程 :
- 特征融合 (CConv) :将当前层的 Fixed 特征、经过当前形变场 Warp 后的 Moving 特征、以及上一层上采样来的特征进行拼接融合,生成融合特征 ClC_lCl。
- 形变估计 (Def) :基于 ClC_lCl 预测一个残差形变场 (Residual Deformation Field) ϕs\phi_sϕs。这里使用了微分同胚(Diffeomorphism)层,通过积分速度场来保证形变的拓扑保真性(防止折叠)。
- 形变融合 (Fusion) :将新预测的残差场 ϕs\phi_sϕs 与之前的累积形变场 ϕs−1\phi_{s-1}ϕs−1 进行组合。公式如下:
φs=φs−1∘ϕs+ϕs \varphi_s = \varphi_{s-1} \circ \phi_s + \phi_s φs=φs−1∘ϕs+ϕs
注意这里使用的是复合运算(Composition)而非简单的加法,这更符合物理上的连续形变过程。
2. 语义传递 (Semantic Transfer)
为了解决传统金字塔网络中"语义模糊"的问题,RDP 在递归过程中,不仅传递形变场,还将融合后的高层语义特征 ClC_lCl 上采样后传递给下一层分辨率。这样,浅层(高分辨率)的计算也能感知到深层的全局语义信息,从而在处理细节时不会"迷失方向"。
3. 纯卷积设计 (Pure Convolutional Design)
整个网络完全由标准的卷积层、实例归一化(Instance Norm)和 LeakyReLU 组成,没有使用任何 Self-Attention 或 Transformer 模块。这使得网络易于实现,且计算效率极高。
4. 📊 实验与结果 (Experiments)
数据集
作者在三个公开的脑部 MRI 数据集上进行了广泛测试:
- LPBA (40 volumes)
- Mindboggle (62 labeled ROIs, 包含大变形)
- IXI (58 test volumes)
对比实验
与 SyN (传统方法), VoxelMorph, TransMorph (Transformer SOTA), PCnet, RDN 等 12 种方法进行了对比。
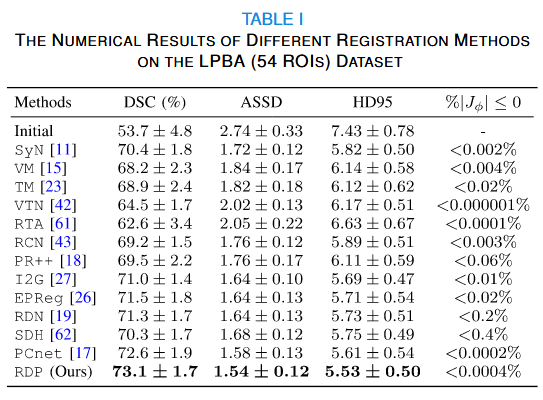
核心结论 1:全方位性能领先
在所有三个数据集上,RDP 在 Dice Score (DSC) 、ASSD 和 Hausdorff Distance 指标上均取得最优结果。特别是在 Mindboggle 这种大变形数据集上,RDP 表现尤为出色。
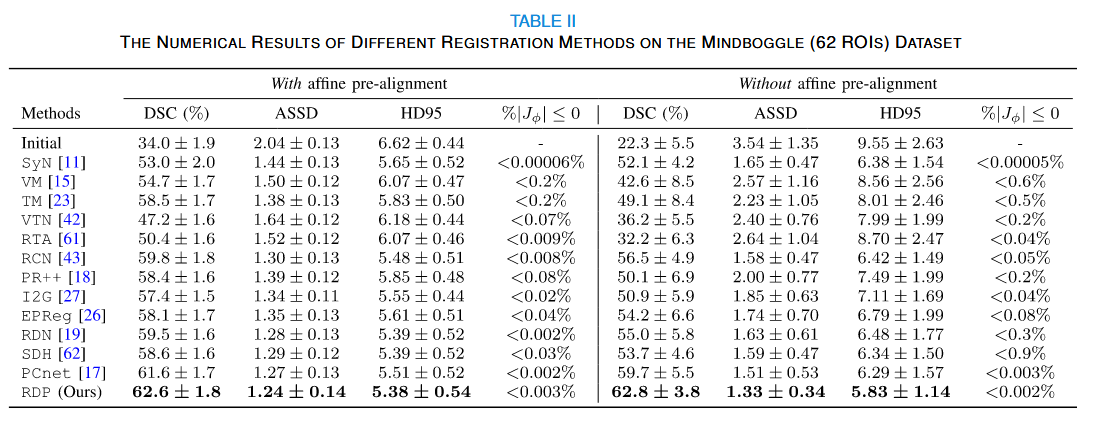
核心结论 2:无需预对齐 (No Affine Pre-alignment)
这是本文最大的亮点。
- 实验设置:对比了使用"经过仿射预对齐的数据"和"原始未对齐数据"训练/测试的效果。
- 结果 :大多数方法(如 VoxelMorph, TransMorph)在处理未预对齐数据时,性能大幅下降(Dice 暴跌)。而 RDP 即使在没有预对齐的情况下,依然保持了极高的精度 ,甚至超过了其他方法在预对齐数据上的表现。
核心结论 3:效率优势
相比于结构复杂的 PCnet,RDP 在相同通道数设置下,训练显存减少了 25%,推理速度快了 33%(仅需 0.68秒)。
消融实验
- 递归次数:实验证明,增加递归次数能逐步提升精度,最终选定各层的递归次数为 (2, 2, 3, 1)。
- 语义传递:去除语义传递机制后,模型性能有明显下降,证明了高层语义对精细配准的指导作用。
5. 🧠 笔者思考与总结 (Conclusion & Thoughts)
优点总结
- 大道至简 :在 Transformer 统治医学图像分析的今天,RDP 证明了精心设计的纯卷积网络依然具有强大的竞争力。
- 解决痛点:无需仿射预对齐是一个巨大的工程优势。这意味着医生在使用 AI 辅助配准时,可以直接输入原始图像,省去了繁琐的预处理步骤,真正实现了 End-to-End。
- 递归细化:通过在同一分辨率下反复"打磨"形变场,模拟了人类"先看大概,再修细节"的认知过程。
潜在局限
- 虽然推理速度很快,但由于引入了递归(循环),训练时的计算图可能会比单阶段网络(如 VoxelMorph)更深,对显存有一定要求(尽管比 PCnet 低)。
- 论文主要验证了脑部 MRI,对于形变更为剧烈且不规则的腹部器官(如肝脏、肺部呼吸运动),其递归策略的鲁棒性还有待进一步验证。
未来展望
RDP 的递归思想可以很容易地扩展到其他任务中,例如医学图像分割(递归细化边缘)或多模态配准。此外,将这种递归结构与轻量级的 Attention 机制结合,可能会在精度和效率之间找到更好的平衡点。