Rime小狼毫和雾凇拼音方案是两个非常不错的项目,我的体验很好。
https://github.com/rime/weasel
https://github.com/iDvel/rime-ice
但是,我原本QQ拼音积累的熟悉的输入方案怎么办?
首先在QQ拼音里导出
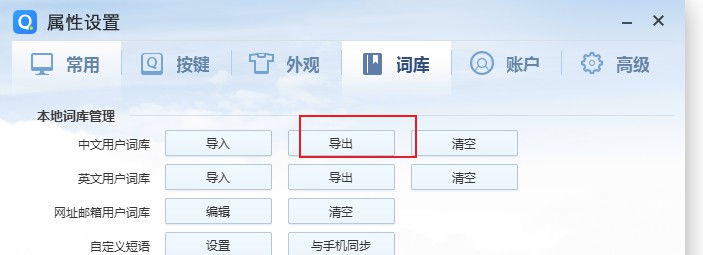
首先设置,.翻页
default.custom.yaml
bash
customization:
distribution_code_name: Weasel
distribution_version: 0.16.3
generator: "Rime::SwitcherSettings"
modified_time: "Wed Dec 31 08:34:49 2025"
rime_version: 1.11.2
patch:
"menu/page_size": 9
schema_list:
- {schema: rime_ice}
"switcher/hotkeys":
- "Control+grave"
- "Control+F3"
key_binder:
bindings:
- { when: composing, accept: comma, send: Page_Up } #翻页
- { when: composing, accept: period, send: Page_Down } #翻页rime_ice.dict.yaml
bash
import_tables:
- cn_dicts/8105 # 字表
# - cn_dicts/41448 # 大字表(按需启用)(启用时和 8105 同时启用并放在 8105 下面)
- cn_dicts/base # 基础词库
- cn_dicts/ext # 扩展词库
- cn_dicts/tencent # 腾讯词向量(大词库,部署时间较长)
- cn_dicts/others # 一些杂项
- cn_dicts/myqq #你的词库把qq词库放在
Rime\cn_dicts下myqq.dict.yam
转换python程序
python
import re
input_file = "QQPinyin_2025_12_31.txt"
output_file = "myqq.dict.yaml"
def read_lines(path):
for enc in ("utf-16", "utf-8", "gbk"):
try:
with open(path, encoding=enc) as f:
return f.readlines()
except UnicodeDecodeError:
pass
raise RuntimeError("无法识别文件编码")
lines = read_lines(input_file)
entries = []
for line in lines:
line = line.strip()
if not line:
continue
m = re.match(r"([a-z']+)\s+([\u4e00-\u9fa5]+)\s+(\d+)", line)
if not m:
continue
code, word, weight = m.groups()
pinyin = code.replace("'", " ")
entries.append(f"{word}\t{pinyin}\t{weight}")
with open(output_file, "w", encoding="utf-8") as f:
f.write(
"---\n"
"name: my_qq\n"
"version: \"1.0\"\n"
"sort: by_weight\n"
"...\n\n"
)
f.write("\n".join(entries))
print(f"转换完成:{len(entries)} 条")