L11综合流程&编译&硬件生成
编译与综合流程之间的关系:在开始综合之前,我们要检查语法是否正确,这一步就是编译。综合器能够设别RTL结构,然后把这些结构映射到具体的硬件资源上,这些资源就是我们的标准单元库。

L13 标准单元库&库定义&单元类型
库定义阶段会告诉综合工具去哪里寻找用于绑定的叶子单元,以及进行工艺映射时所用的目标库是哪一个。比如从库里实例化一个特定的标准单元,或使用SRAM这样的IP,那么这些就是叶子单元,我们需要把代码(网表)绑定到它们上面。
目标库也就是标准单元库,我们希望将RTL或布尔逻辑结构映射到这个库里,它其实就是我们拥有的所有硬宏的集合。这些.lib文件包含了它们的时序信息,供综合工具使用。因此我们需要提供一个特定工艺角下的所有库文件列表,这样工具才能找到叶子单元,并把RTL映射上去。

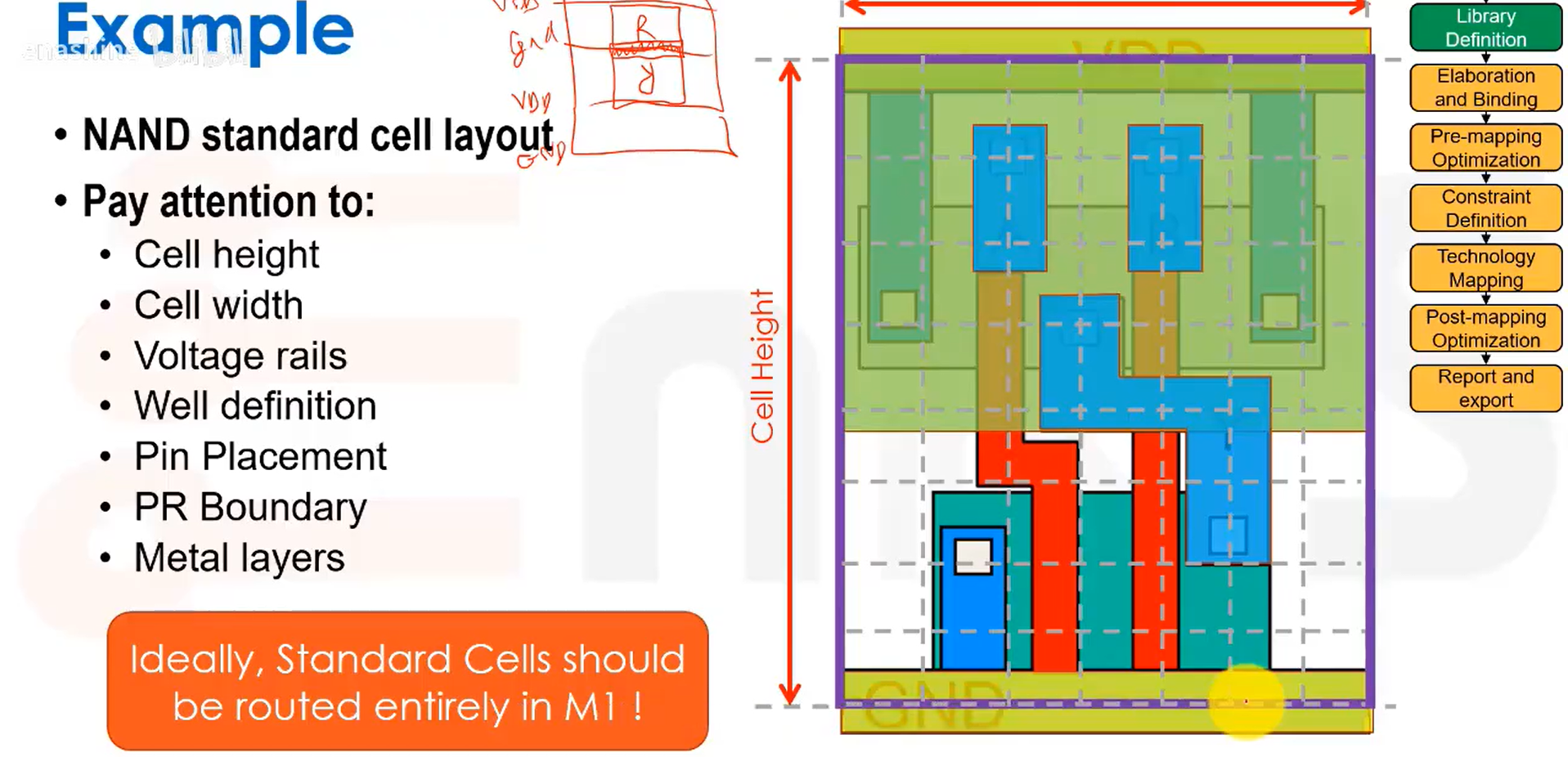
理想情况下,标准单元的布线应该完全限制在M1层,从而把其他区域留出进行更复杂的全局布线。
标准单元库中的元件:组合逻辑单元、缓冲器/反相器、时序逻辑单元、物理单元等。

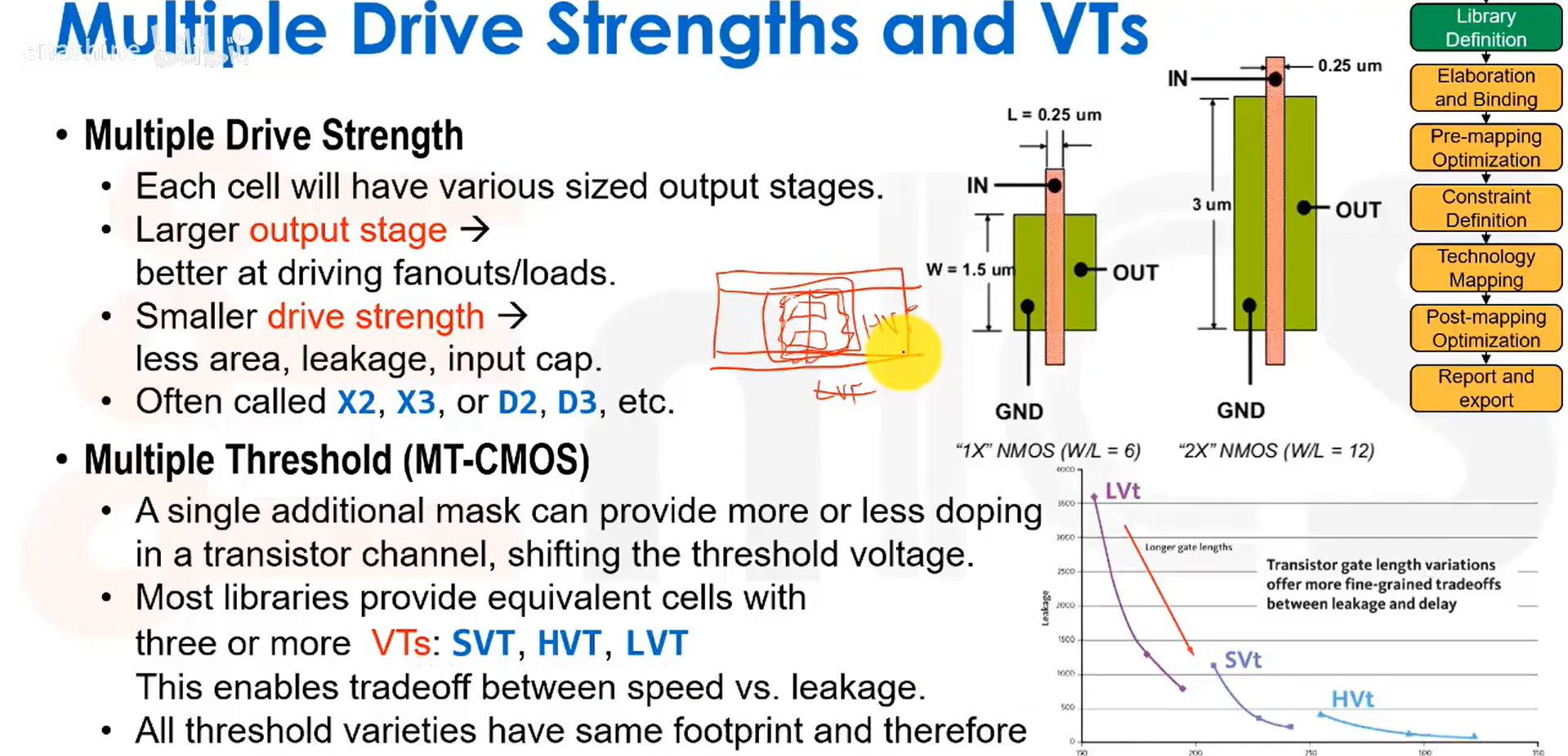
多驱动强度与多阈值电压单元设计。我们可以改变晶体管的阈值电压,方法是在某个工艺步骤上增加或去除一层特定的掩膜。阈值电压更低的晶体管将具有更强的驱动能力,但它的漏电流也会增大。如果我们发现某个单元不在关键路径上,就可以把它换成高阈值电压的版本,也就是把那层掩膜换成高VT掩膜,这样晶体管漏电流会减小,从而降低功耗,代价是增加单元的传播延迟。因此我们通常会提供具有不同阈值电压的等效单元库。
接下来是时钟单元。一般来说,标准单元是针对速度优化的,但并不代表它们是对称平衡的。这将引入不期望的时钟偏移。一般来说,时钟路径上只允许使用缓冲区与反相器:

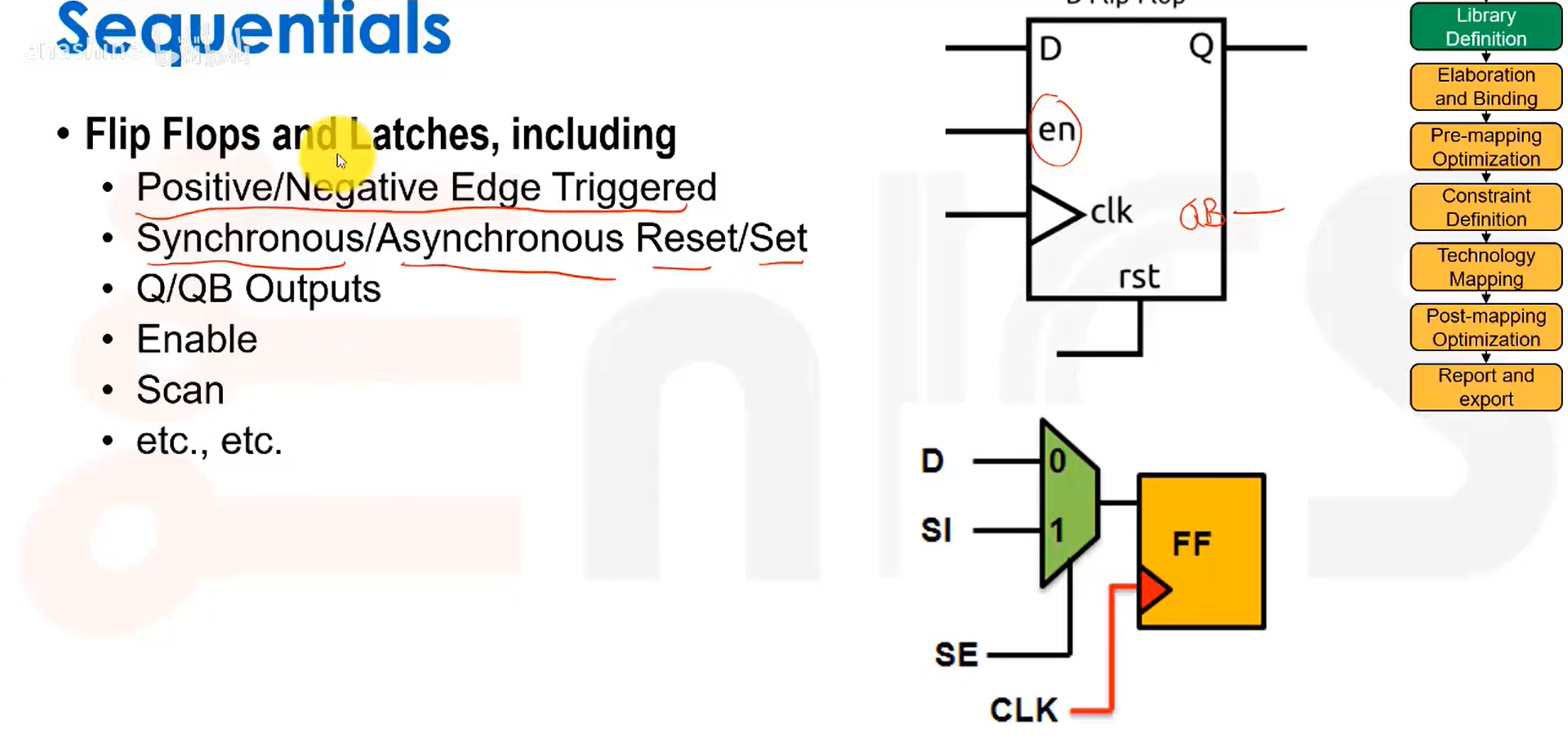
时序单元:
电平转换单元:
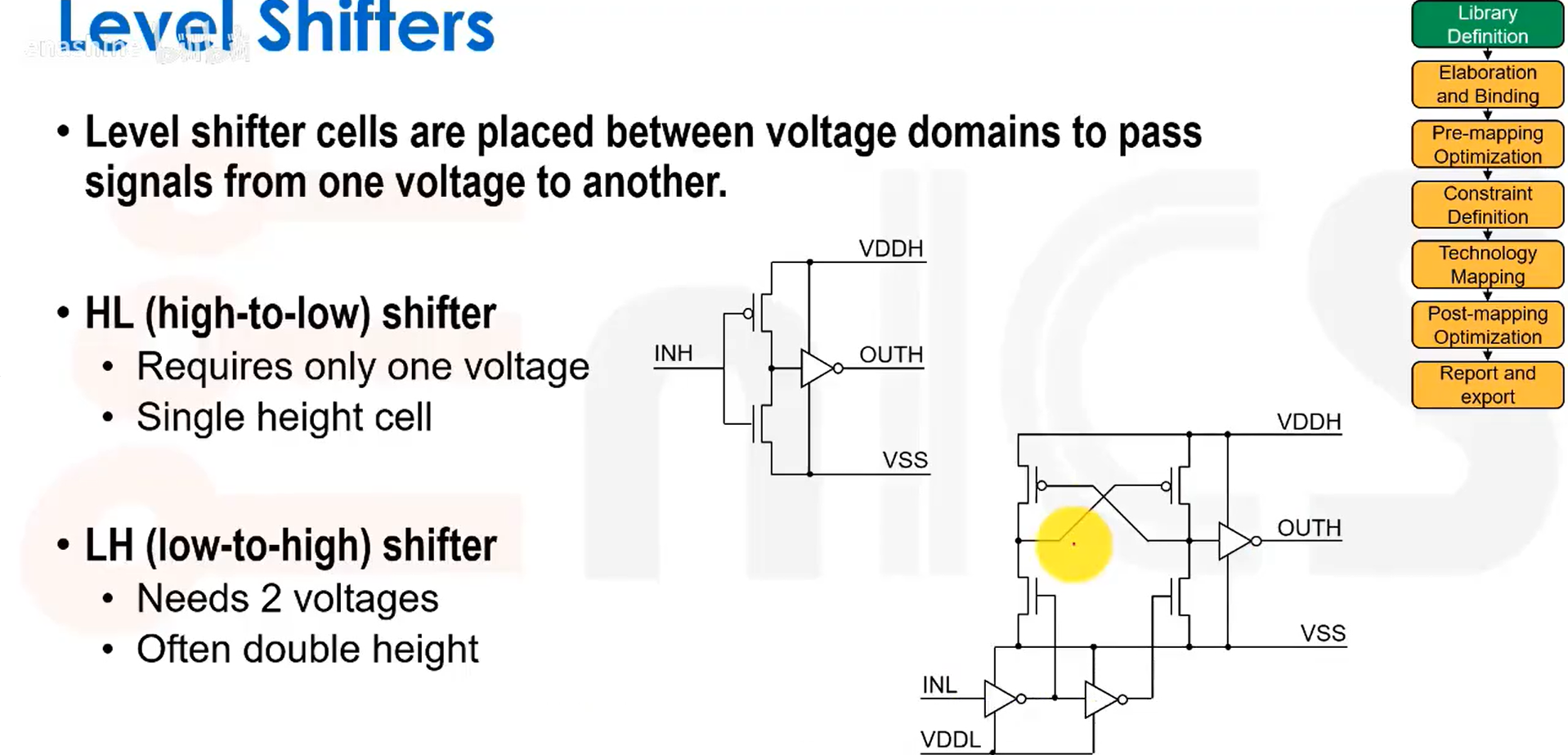
填充与接触单元。出于布线等考虑,在标准单元之间存在空隙,但这可能导致不同层(比如阱区)出现不连续的问题,因此需要加入填充单元。在某些工艺中,还有一种叫做端帽(End Cap)的单元,我们将其放置在每行的两端。其他填充物可能还有MOS电容,用于连接VDD和地,滤除电源噪声。因此我们希望VDD和地之间的电容越大越好,实现这一点的方法是直接在这些填充单元里嵌入电容,可以使用不同类型的MOS电容实现,这类填充单元称为去耦电容单元。
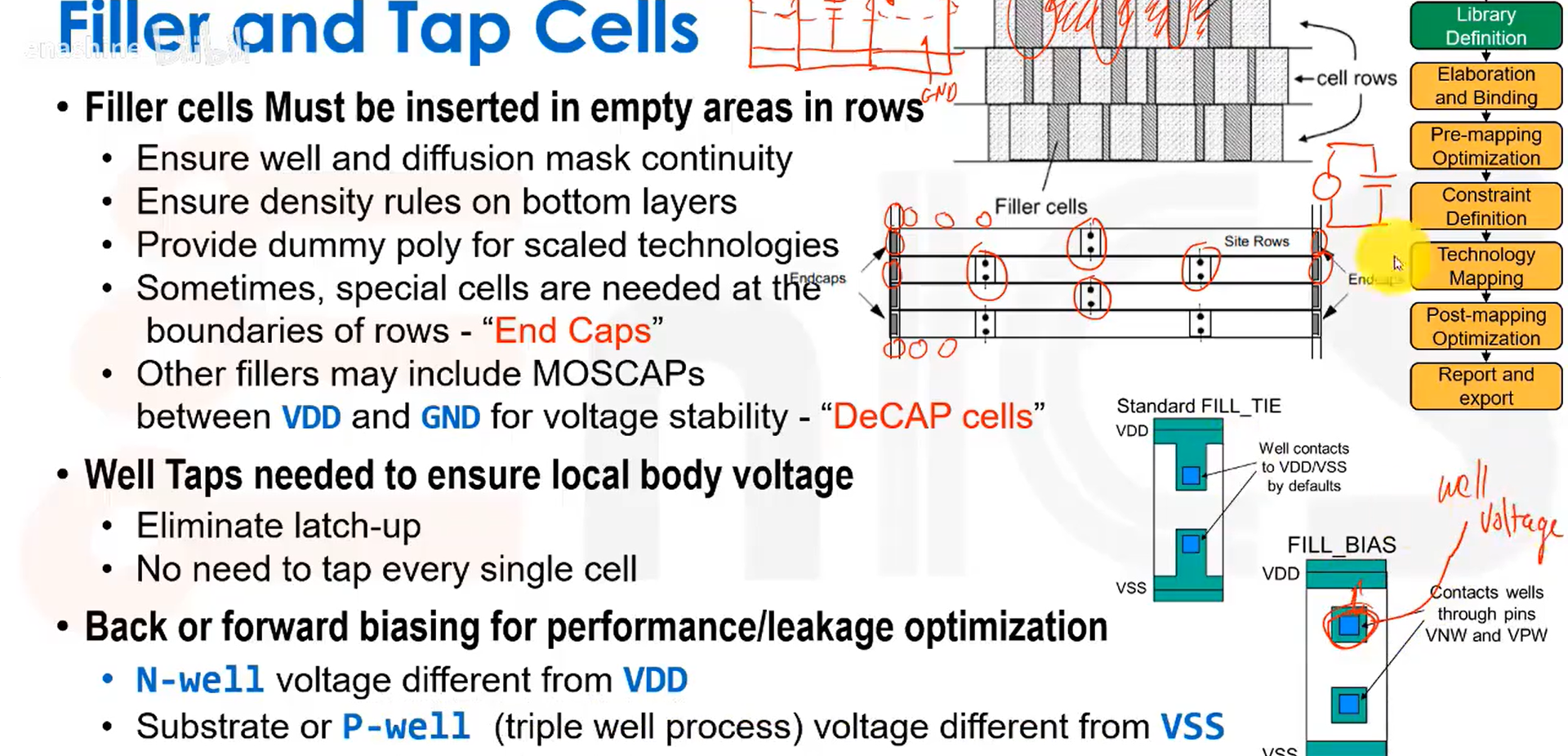
另一种填充单元是阱接触。在旧工艺中,这类接触通常做在标准单元内部,但实际上我们并不需要如此频繁地放置阱接触。所以我们改用内部集成了阱接触的特殊单元,如图所示,它的作用就是将衬底连接到地,将N阱连接到VDD。并且我们会遵循某种设计规则,比如每隔20um在版图中放置这些单元。
阱接触还有一个额外的作用。通常情况下,PMOS的N阱电压连接到VDD,NMOS的P型衬底/阱连接到VSS,可以设置阱电压的正偏或反偏改变晶体管阈值电压(以NMOS为例,VB<0,Vth增加;VB>0,Vth减小),实现性能或功耗的优化。
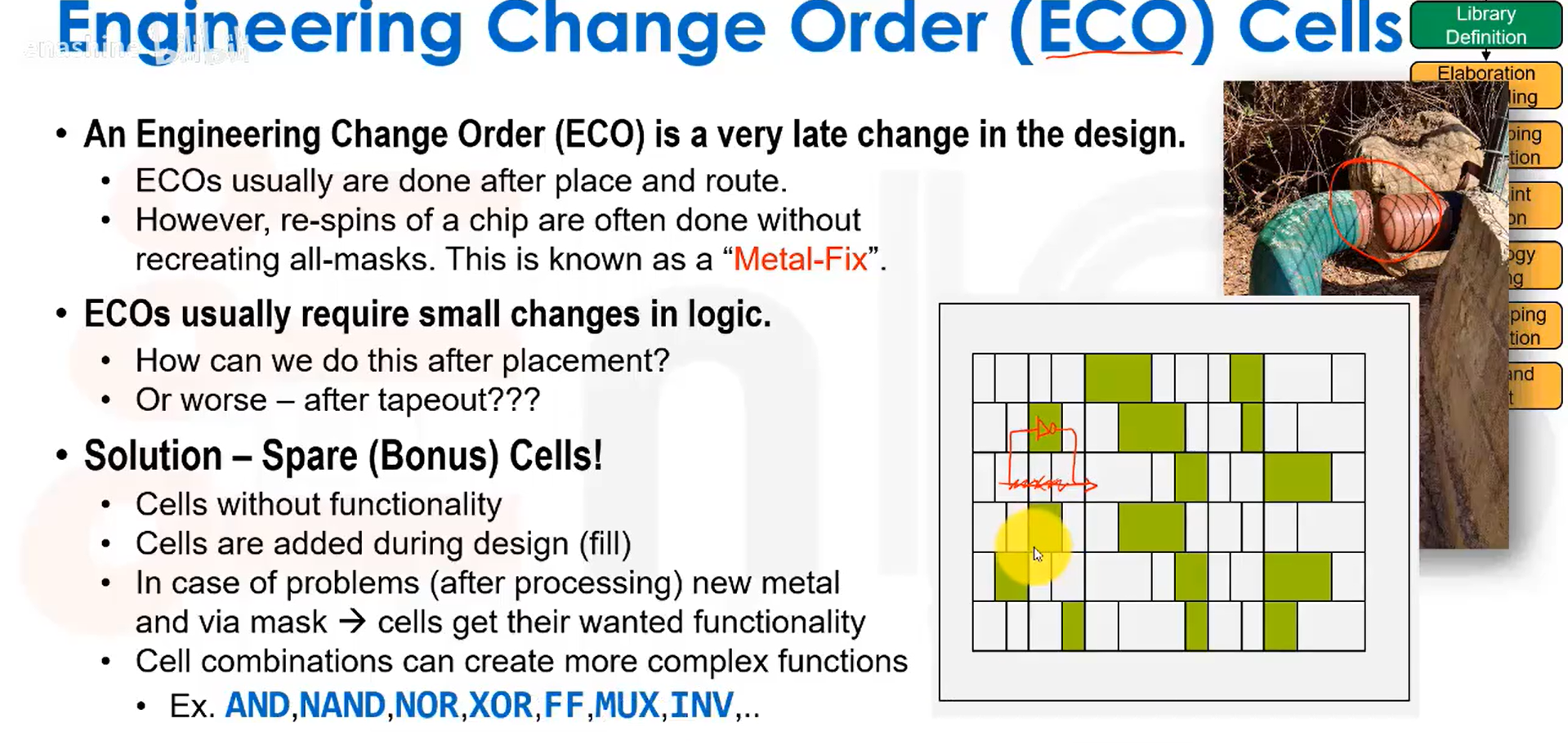
ECO与冗余单元:
标准单元库文件类型:

L14 LEF文件&版图抽象&技术库定义
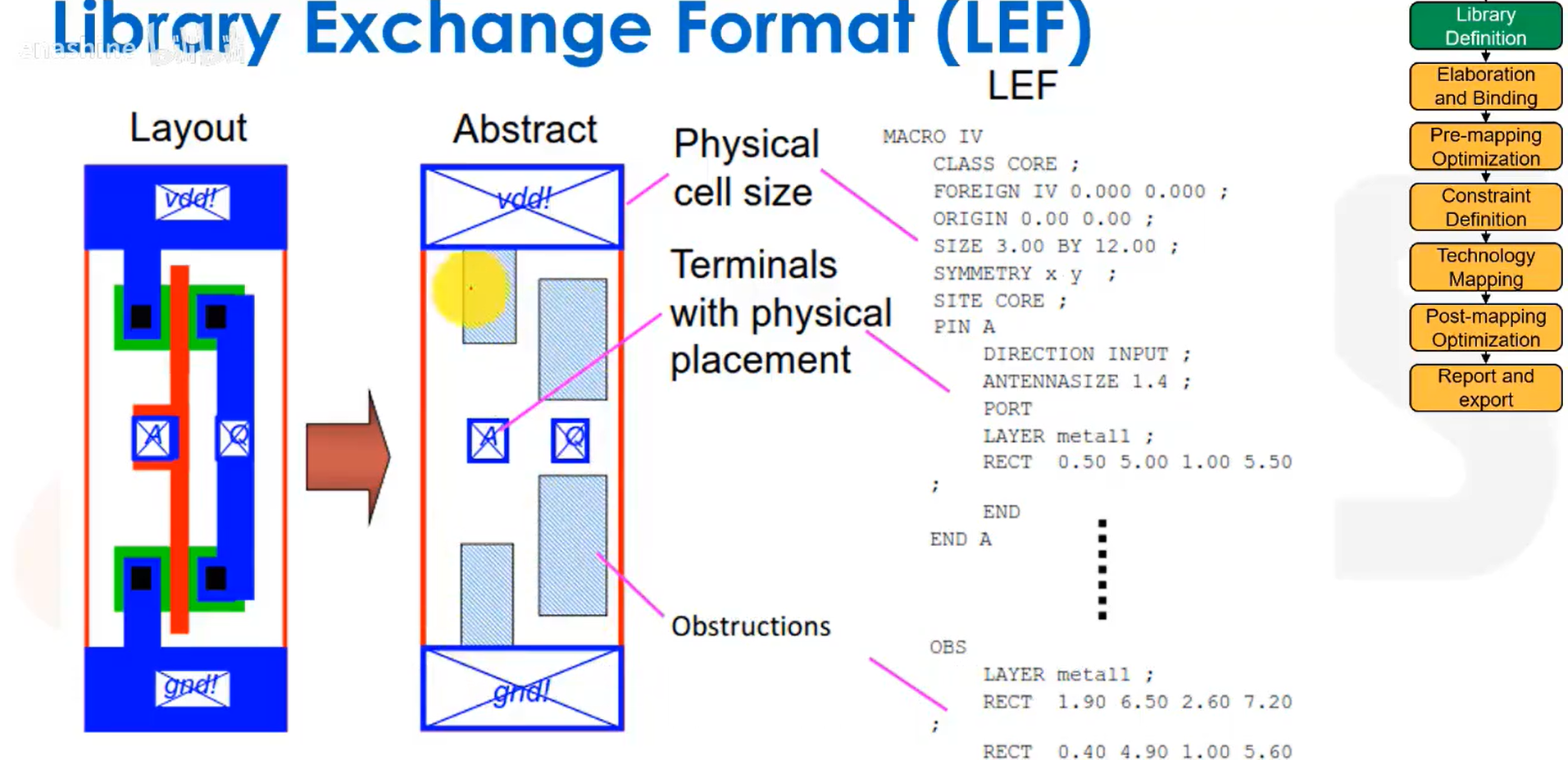
库交换格式LEF是一种用于布局布线的版图抽象定义,它采用可读的ASCII格式,包含了详细的引脚连接信息,但不会包含前端工序线、多晶硅扩散等具体制造数据。抽象视图包括单元轮廓、引脚位置和金属阻挡层等,我们希望所有内容都使用M1层实现。
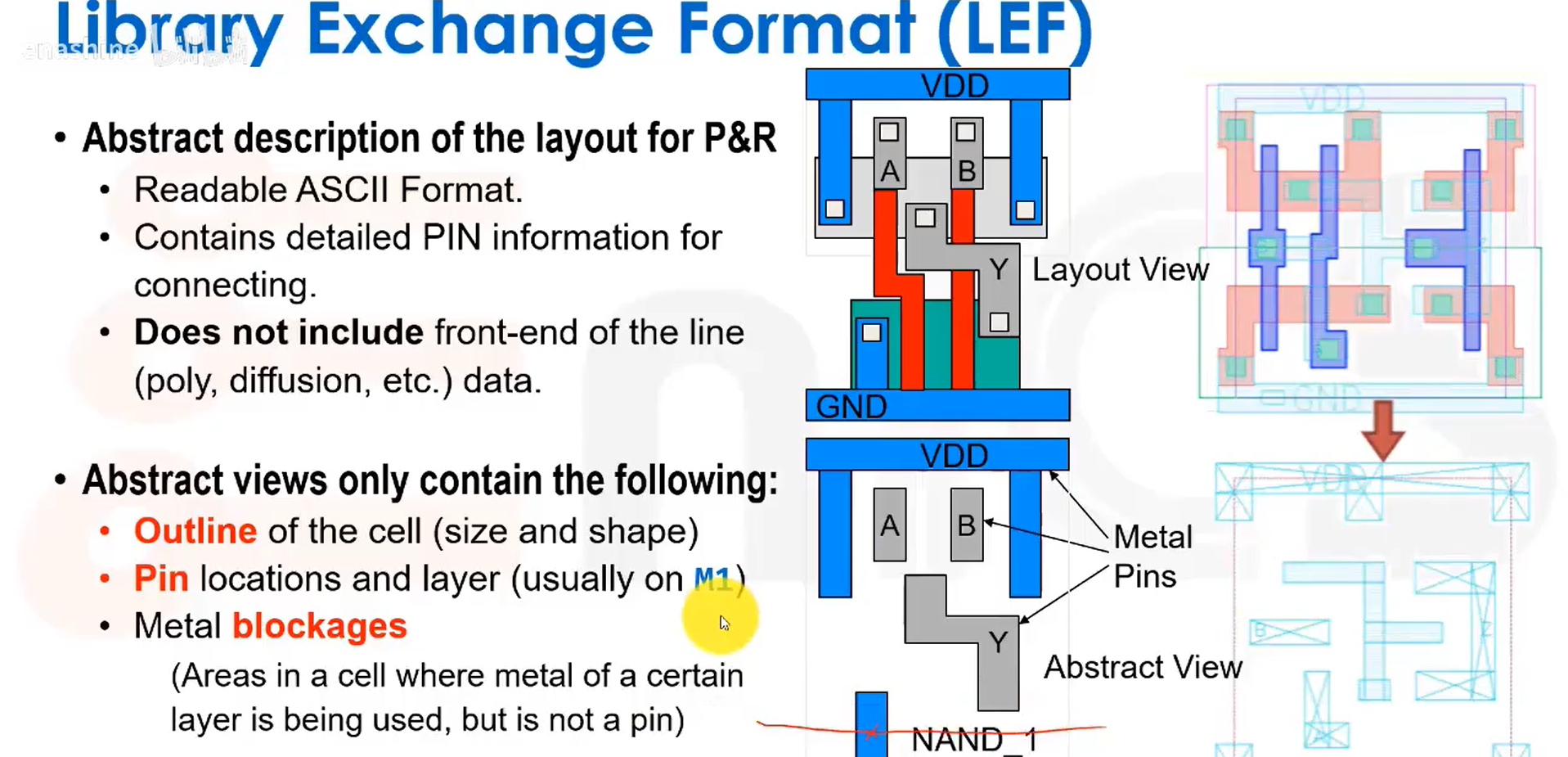
图示为一个命名为IV的反相器单元。单元的物理尺寸为3um*12um,并具有SYMMETRY属性,即单元可以进行镜像翻转。还描述了引脚A的金属层参数;最后是OBS(阻挡层)区域,它用来标识出哪些区域(比如这些M1的图形)是禁止在上面布线的。
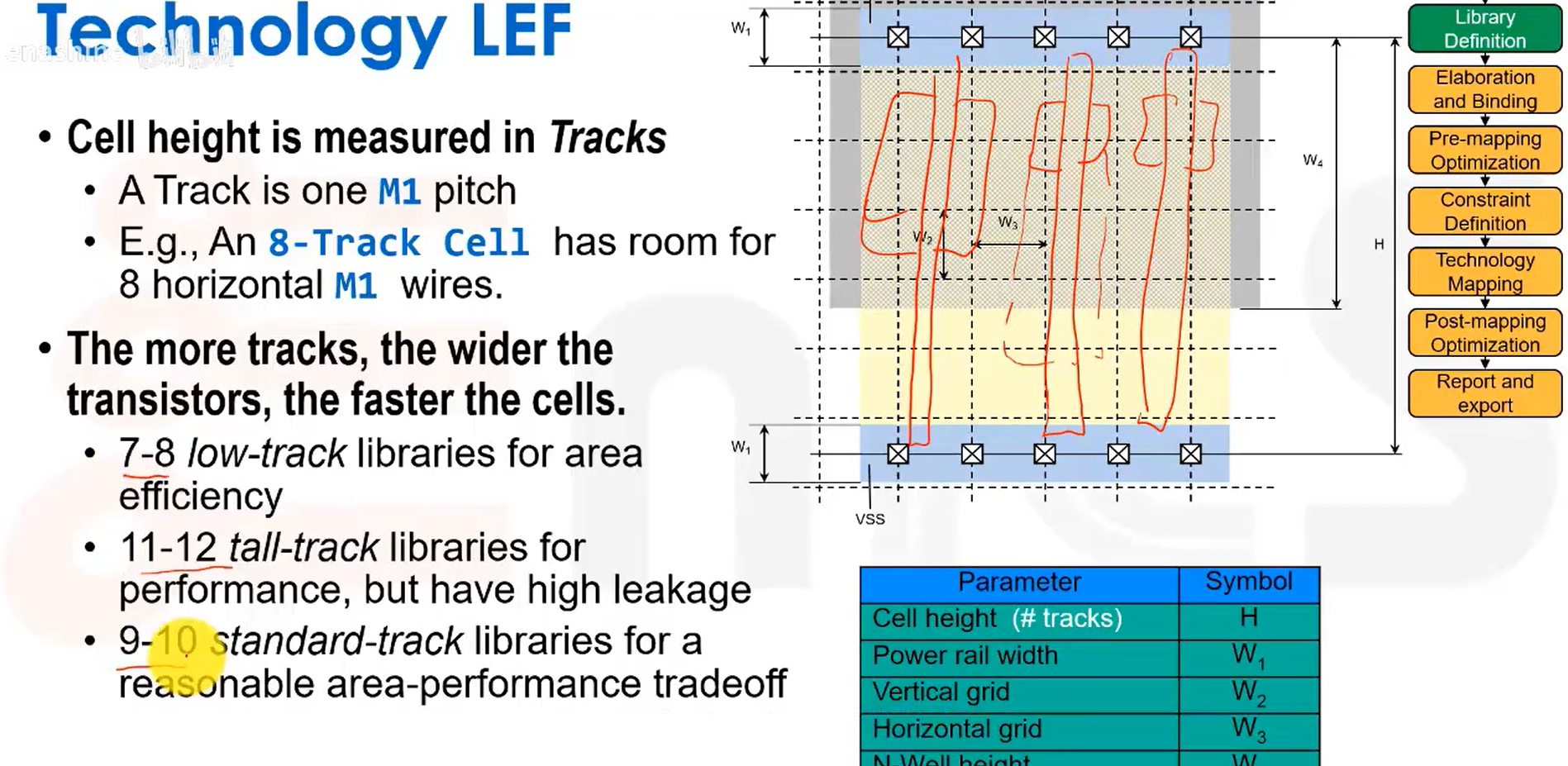
技术库包含了简化的工艺信息,供布局布线工具使用。如定义了图示的MET1层为布线层,定义了它的中距(pitch)、线宽(width)、线距(space)、布线方向、方块电阻以及方块电容等参数。

标准单元是等高的,高度通过轨道数衡量。一条轨道的宽度基本上就是M1的中距(也就是M1的宽度加上金属间距)。更多的轨道数意味着可以放置更宽的晶体管,从而实现高速或高驱动能力的单元。9-10轨道库可能是一种面积与性能的折中方案。
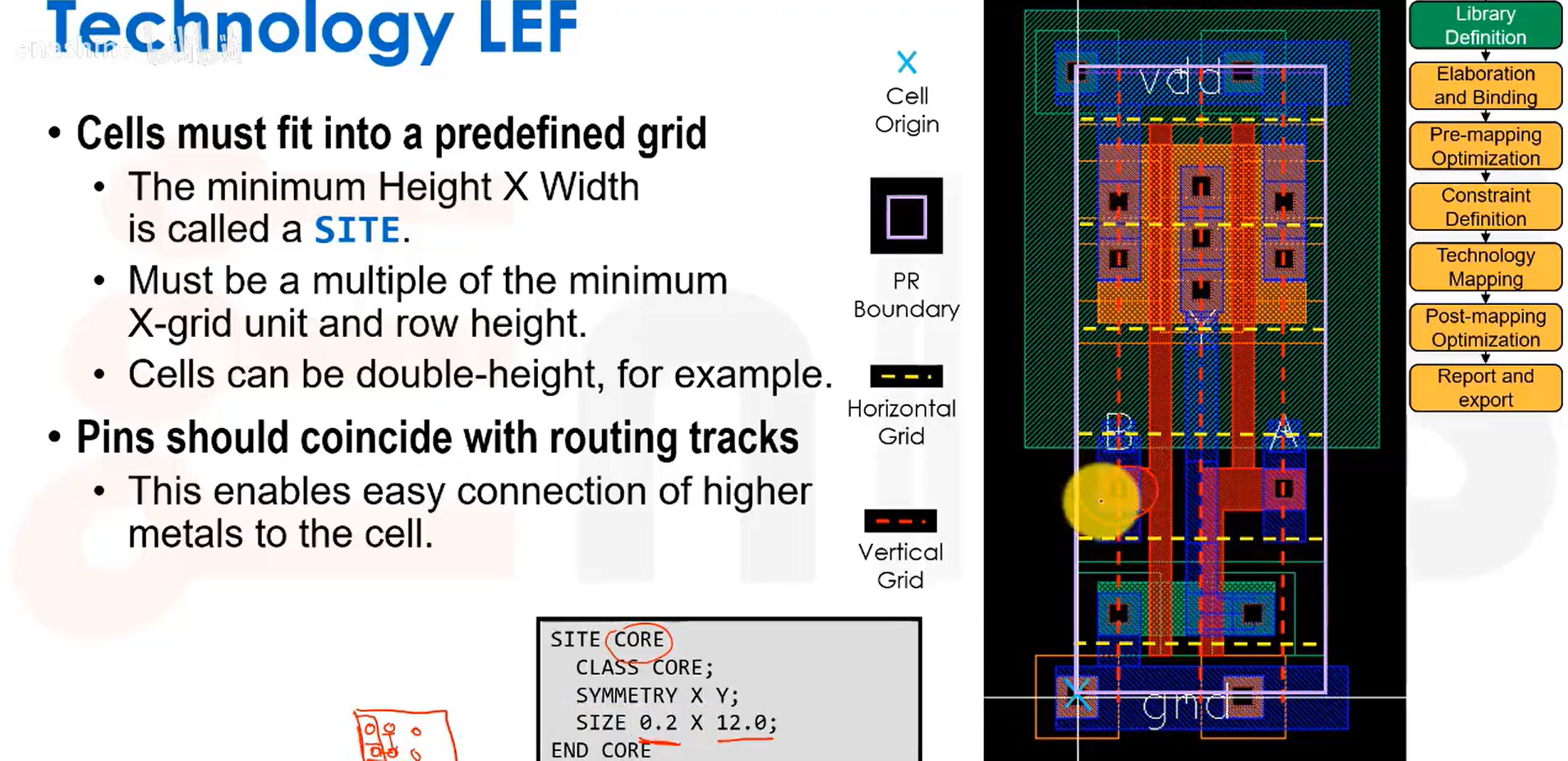
site指布局位置格点,是定义标准单元的最小组成单位。如图所示,它的类别属性为core,表示用于标准单元;而类比属性为pad的site则用于输入输出单元。这里每个标准单元的宽度都必须是0.2的整数倍。
另外一点是关于引脚,我们希望引脚的位置与布线轨道对齐,即图中垂直走线的中间位置,这样只需放置一个通孔就能连接到更高层的导线。
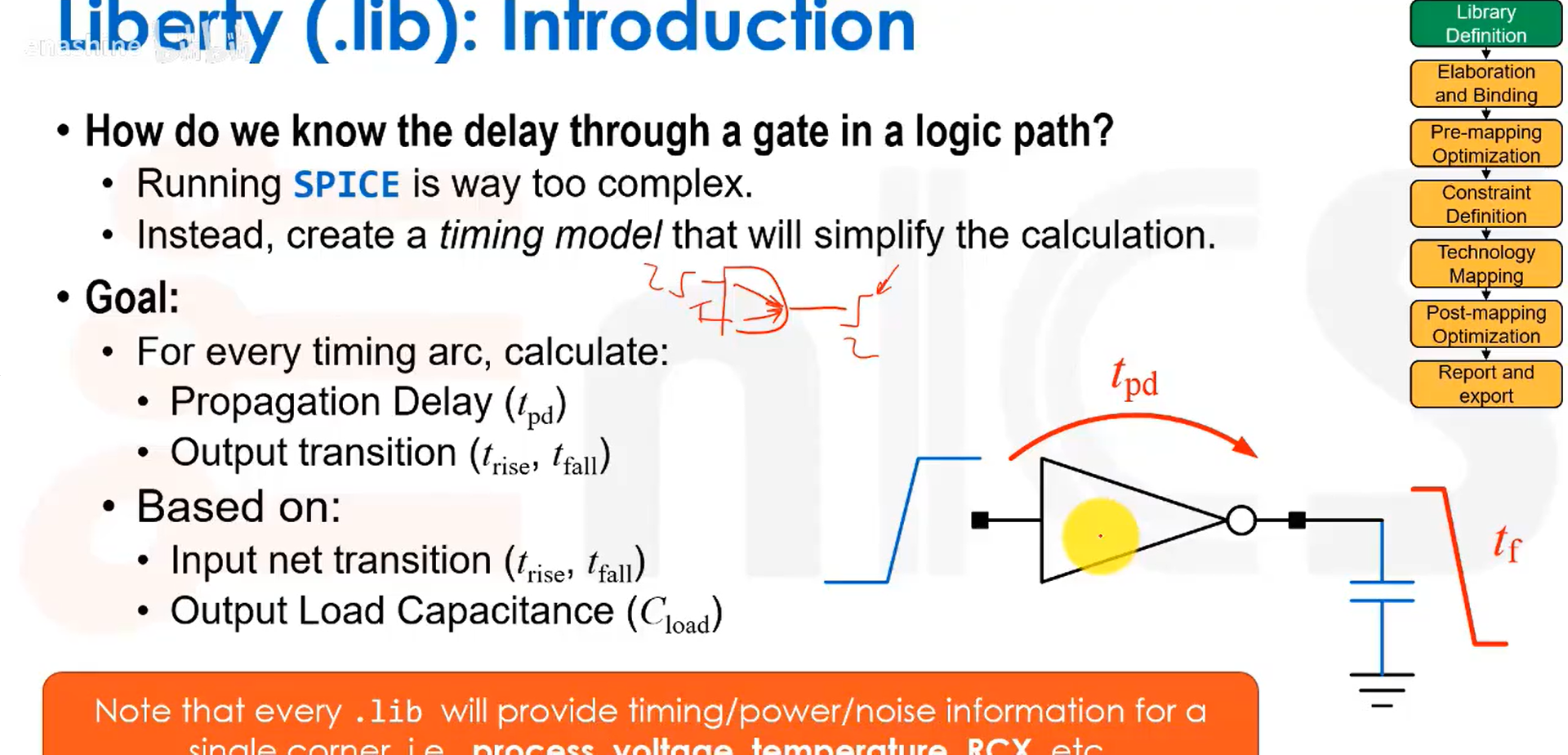
L15 Liberty时序模型&延迟计算&电流源模型
我们怎么知道逻辑路径中一个门电路的延迟呢?我们会建立一个简化的时序模型。我们的目标是处理每一个时序弧,arc指的是从输入到输出的任意路径。对于每个时序弧我们需要计算两个参数:传播延迟和输出信号的上升/下降时间。计算基于门电路输入端的信号转换时间(上升/下降时间)和门电路输出端的负载。只要给定了输入转换时间和输出负载,我们就能计算出传播延迟以及输出的上升/下降时间。
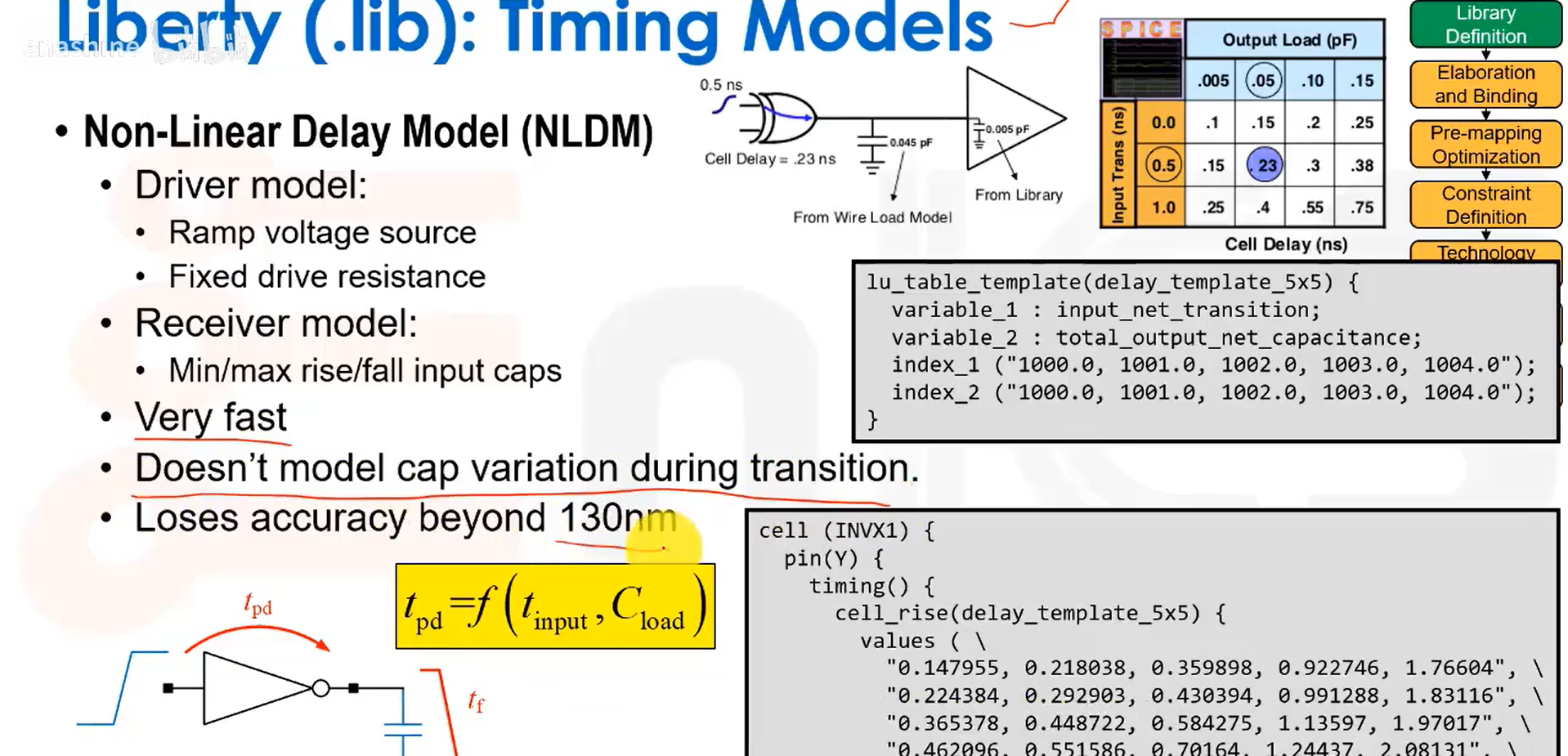
.lib文件中标准单元的时序信息:

非线性延迟模型、查找表确认单元延迟:
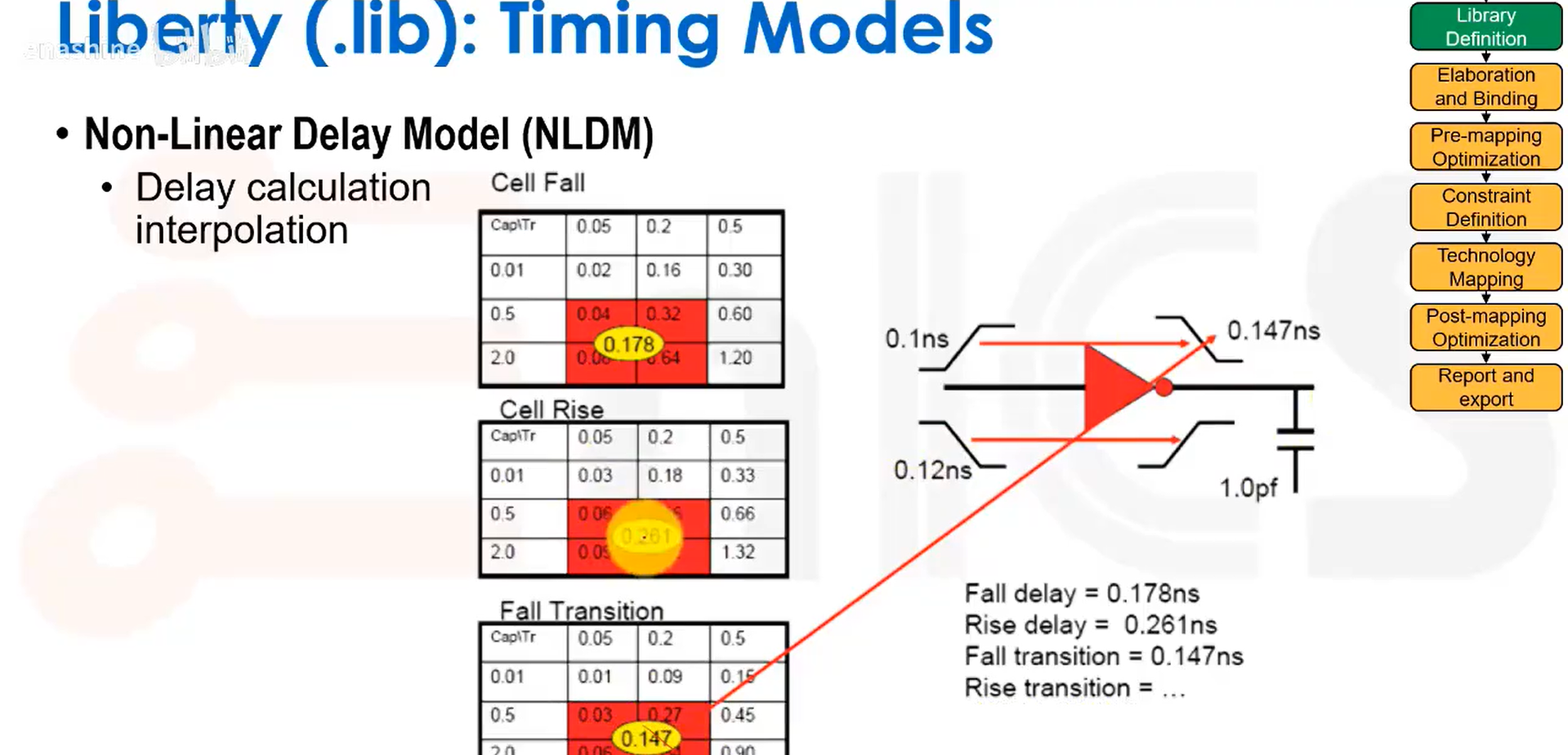
插值计算实例:
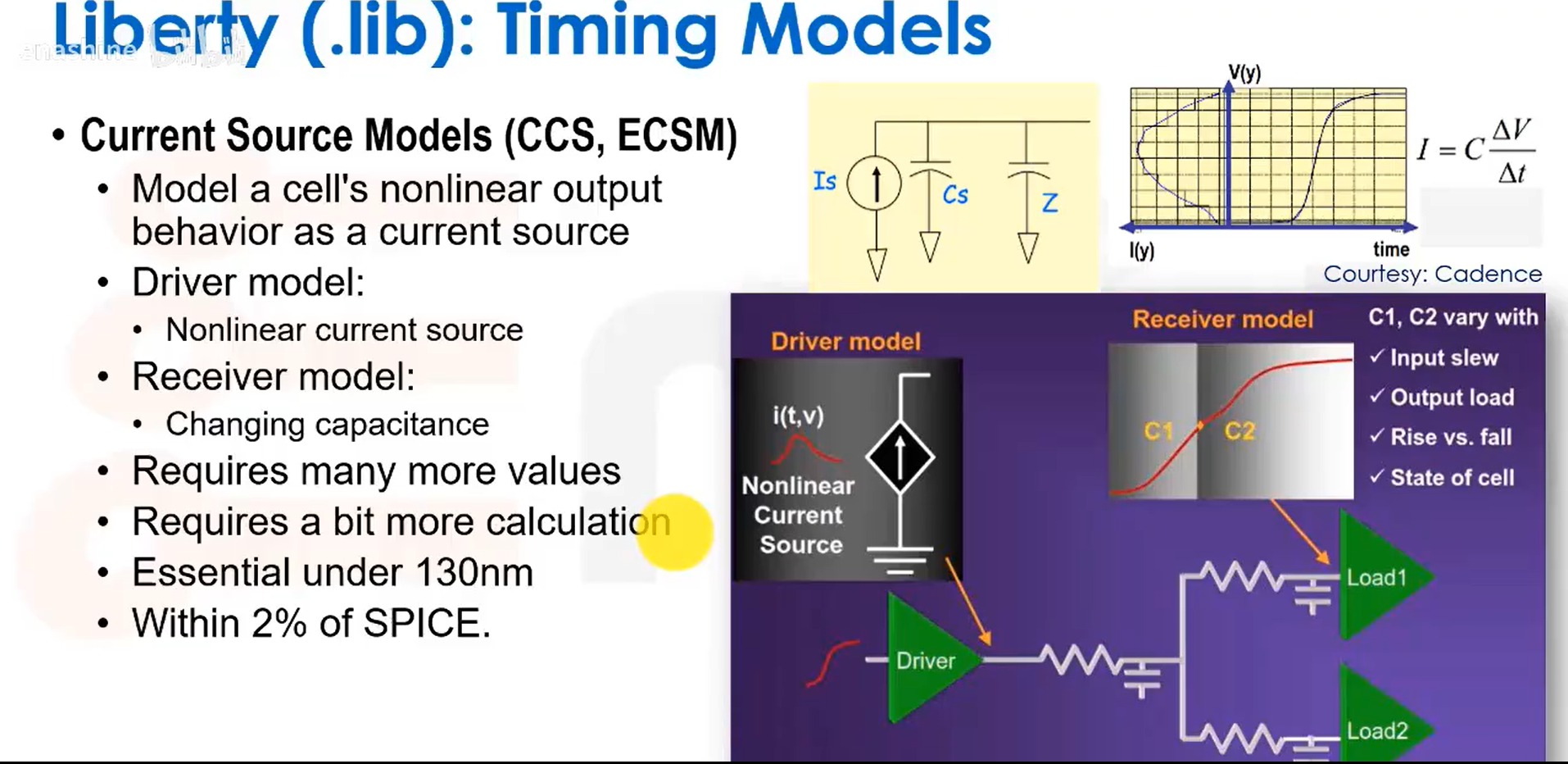
另一种时序建模方式:电流源模型。
在布局布线之前,我们通常会使用连线负载模型估算一个网络的寄生参数,虽然并不准确:

使用物理感知综合方式建立更精确的线负载模型:

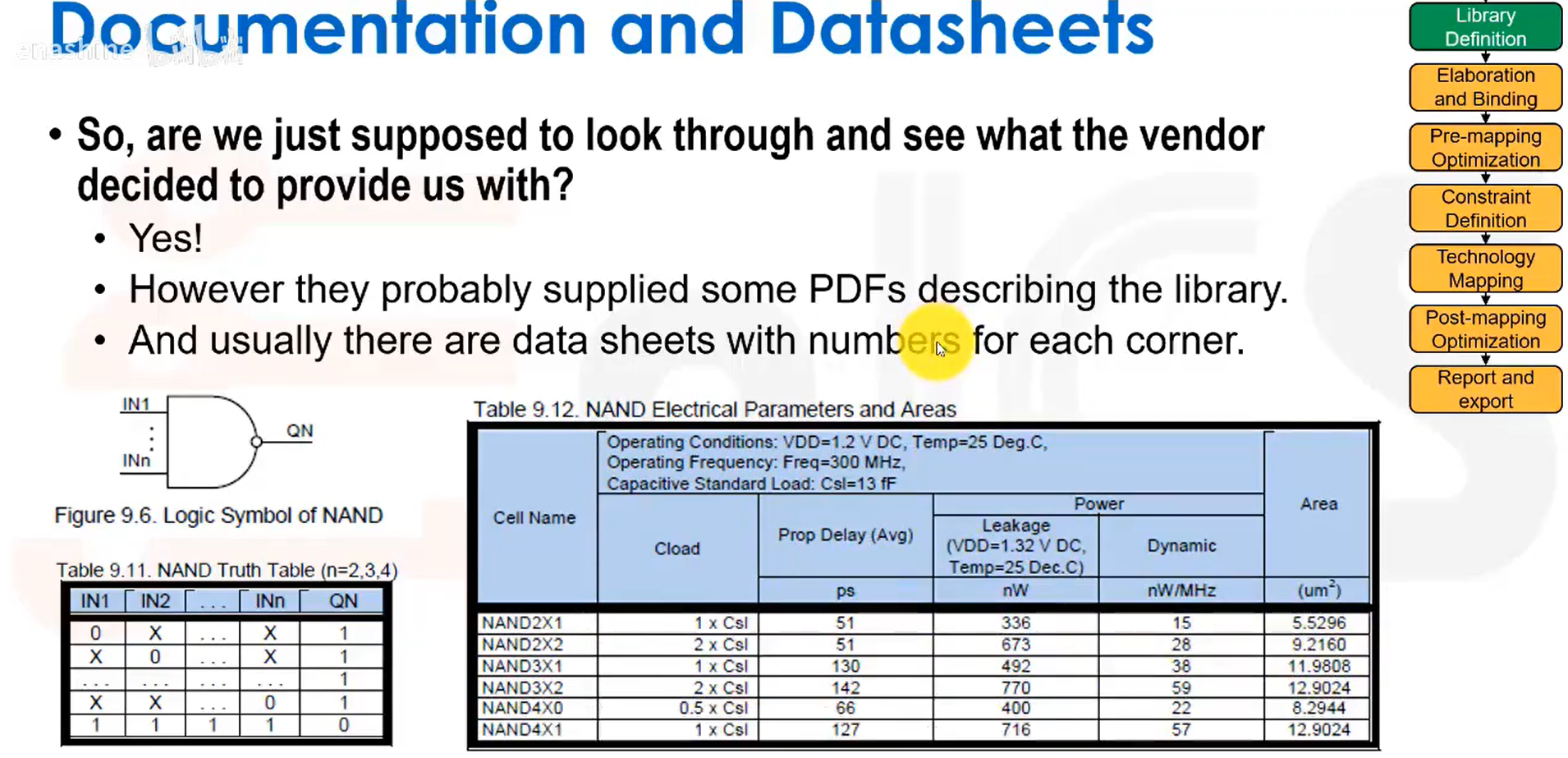
我们通常能在库文件中找到的信息:

L22 时序优化&尺寸调整&单元复制
我们应该如何优化时序?实际上,综合工具可以对逻辑电路应用许多变换,以优化其代价函数。比如调整单元尺寸、插入缓冲器(将延迟从O(N)降低到O(log N))和复制单元以减小关键路径负载、分解大单元、交换公共端引脚连接、将关键信号前移、增加提前路径、面积优化等等。综合工具会应用大量不同的启发式方法。
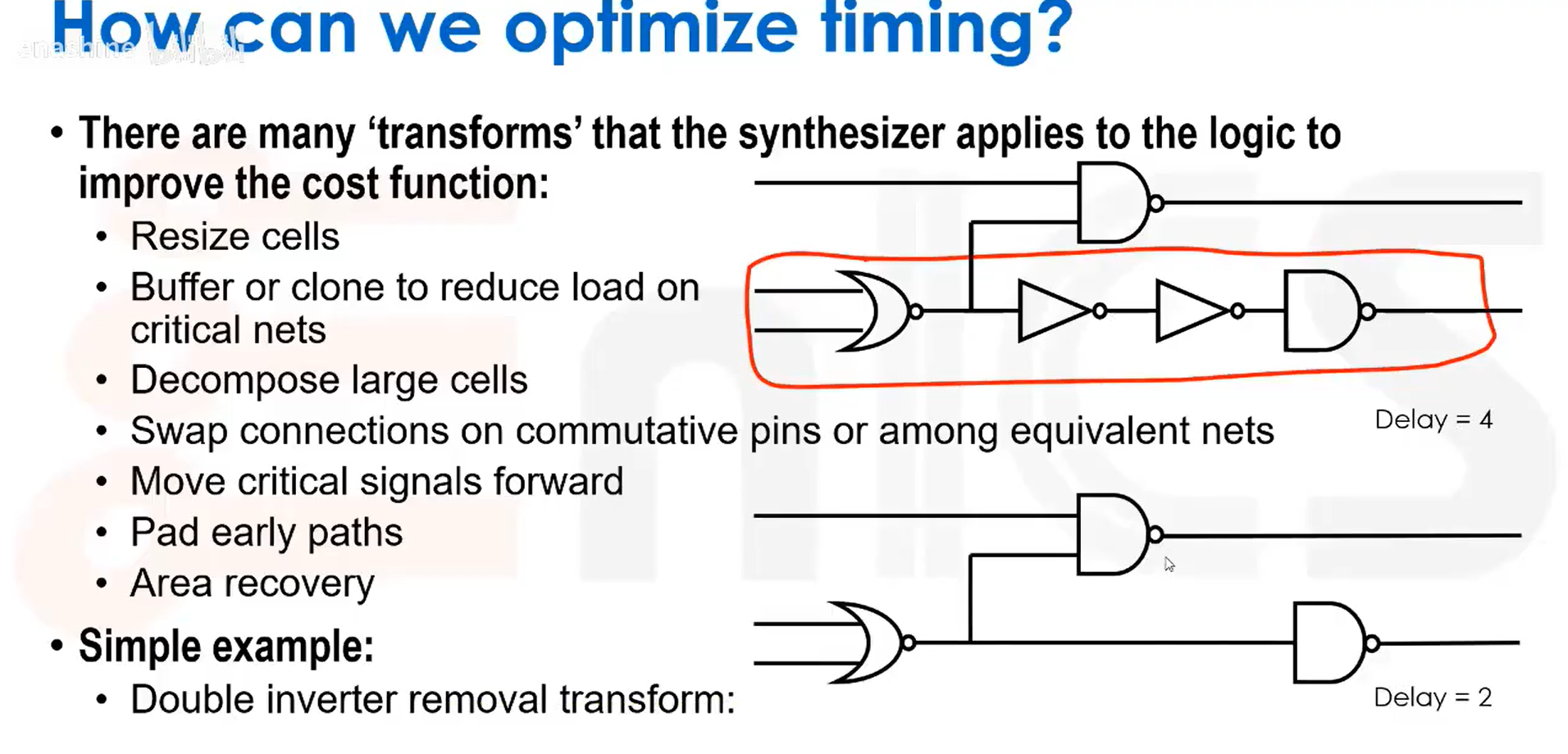
逻辑/时序优化的三种基本方法:
1、调整驱动单元尺寸。观察曲线发现在负载为0.7时门电路C的延迟最小,约为0.026,因此对于此负载应该选用C尺寸单元驱动,从而获得更小的延迟/
2、单元复制。如一个与非门驱动一个很大的负载,我们可以复制一个相同的门,让每个门分别驱动一部分负载。
3、在扇出网络插入缓冲器。让一部分负载通过缓冲器驱动,从而获得更均衡的负载分配。

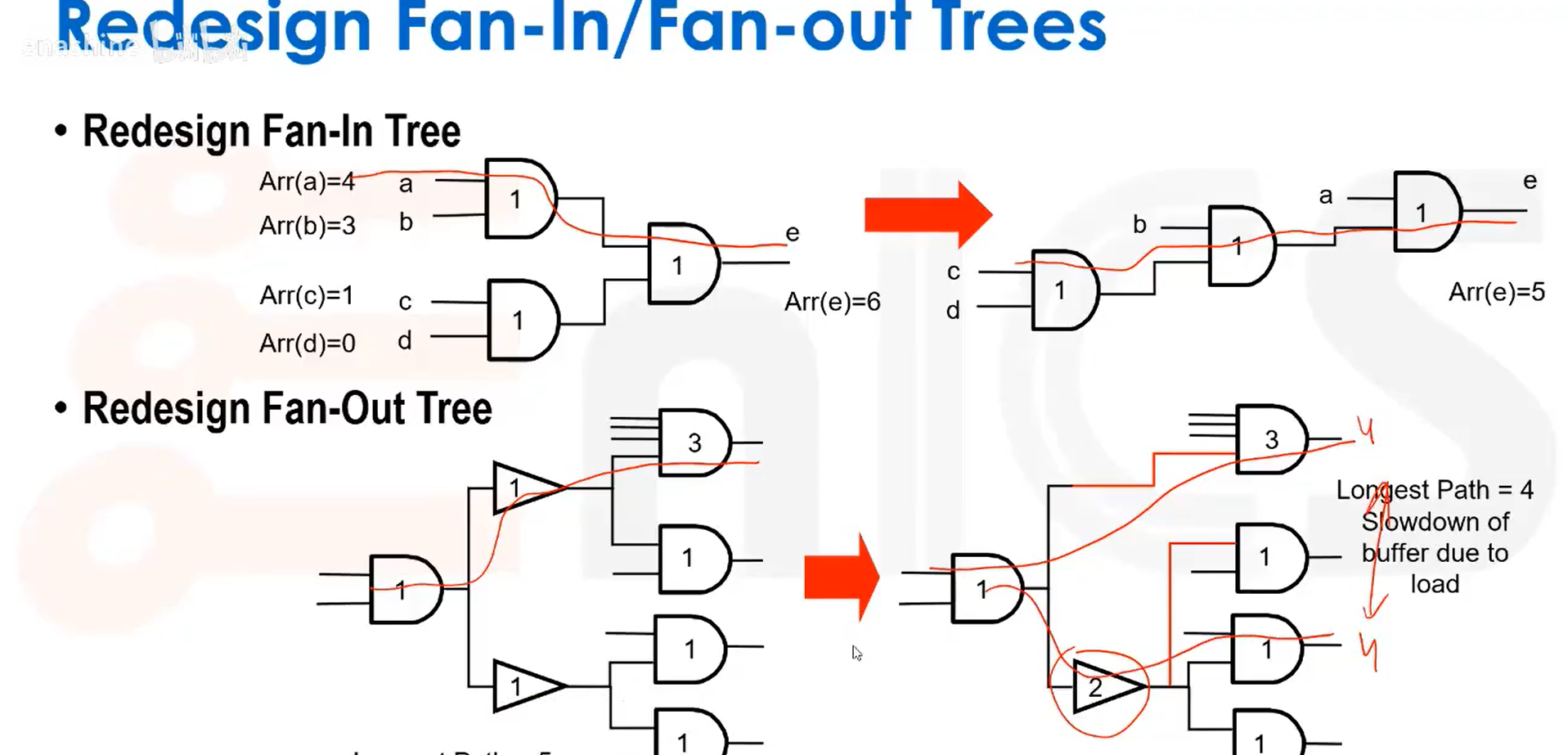
我们还可以重新设计扇入/扇出树结构,均衡信号路径:
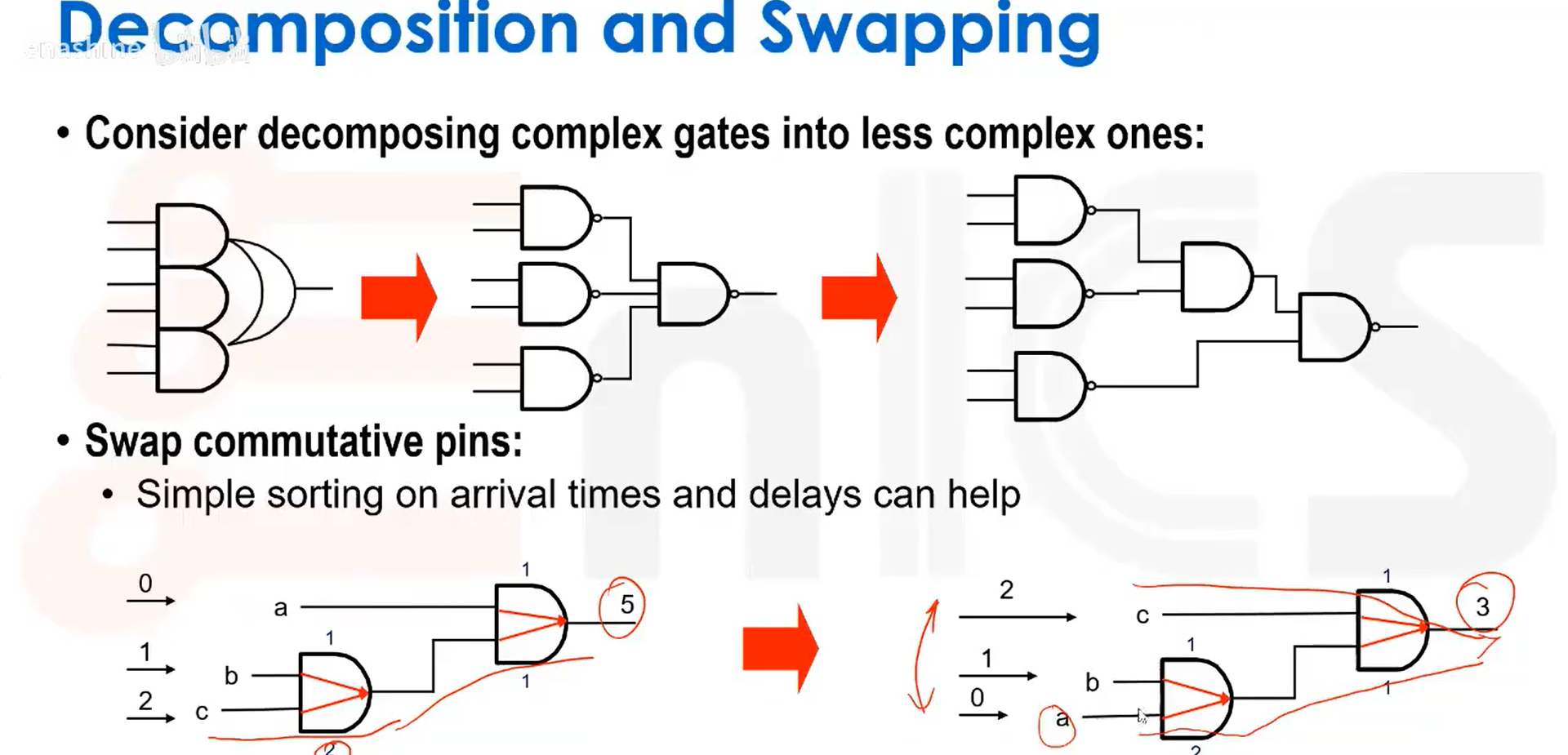
另一种方法是进行逻辑分解与交换:
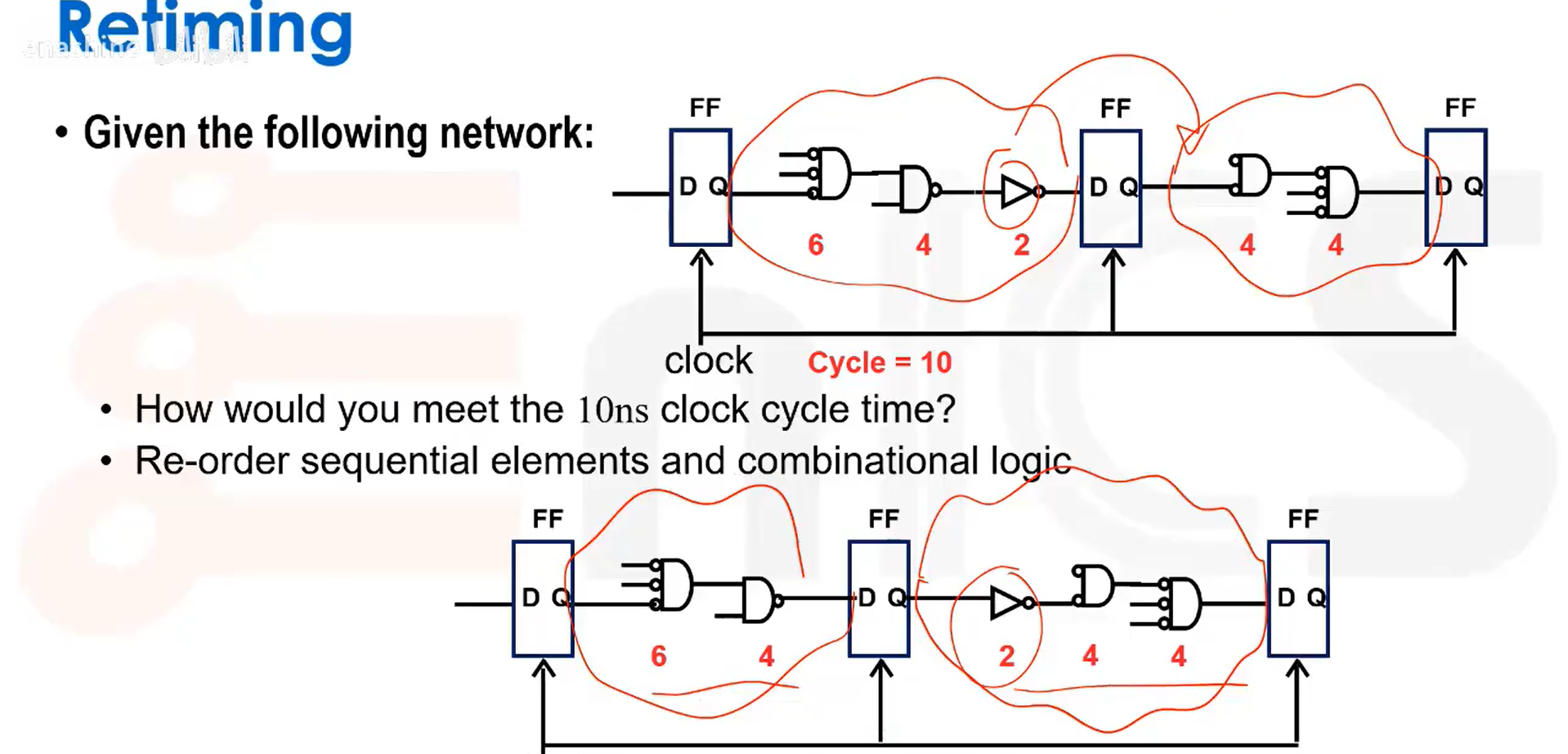
一种更复杂的优化方法是重定时,用来平衡不同的时序路径,最终实现更高的吞吐量:
L27 静态时序分析&设计约束&SDC语法

L28 SDC约束&时钟定义&IO约束
时钟定义及生成时钟:

在综合阶段,将时钟设置为理想网络,告知综合工具不必在线负载模型中包含时钟的高扇出负载,从而产生巨大延迟。但为了获得真实的时序,还需要设置一定的转换时间,以及可能的抖动:

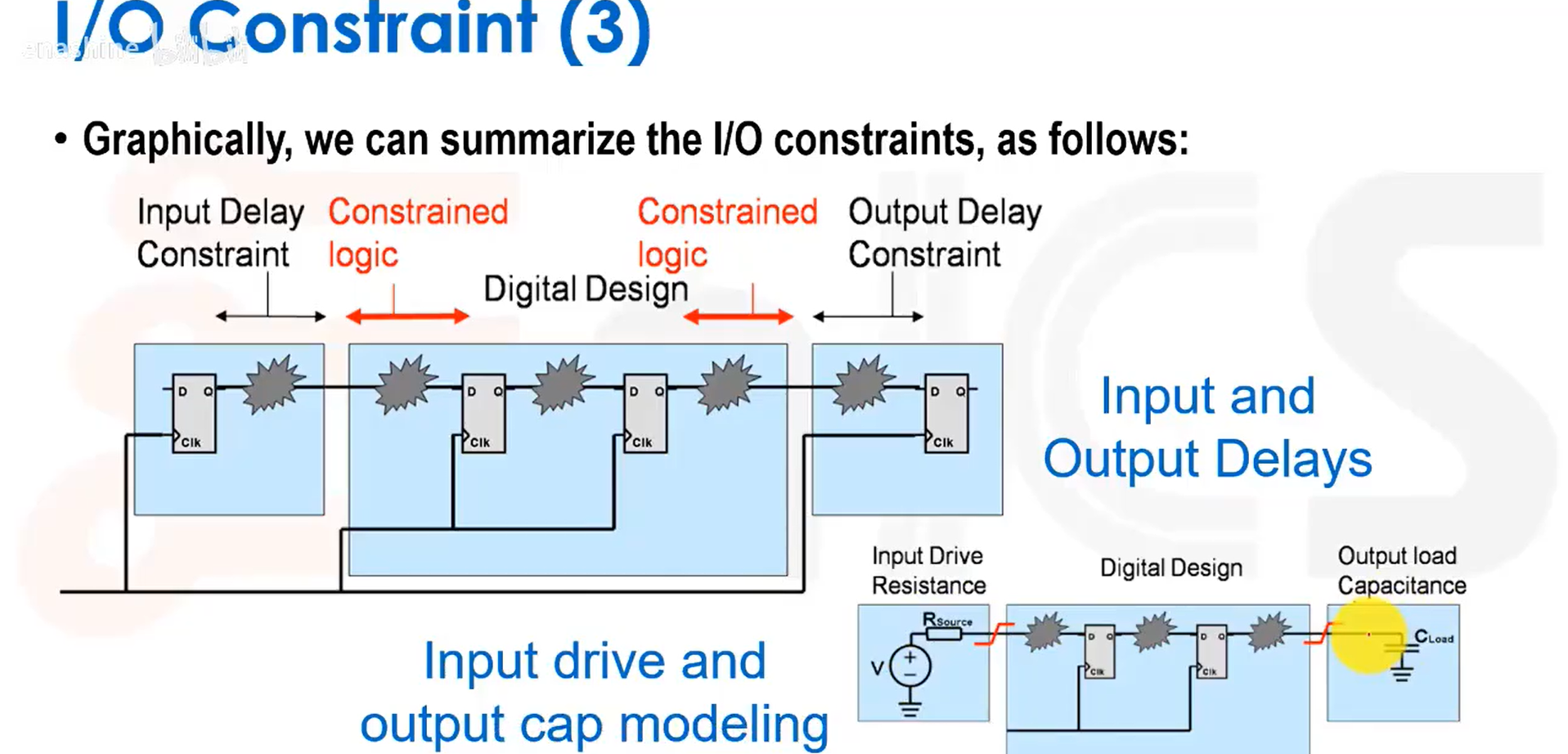
考虑设计与外部的交互,需要对IO进行输入输出延时约束:
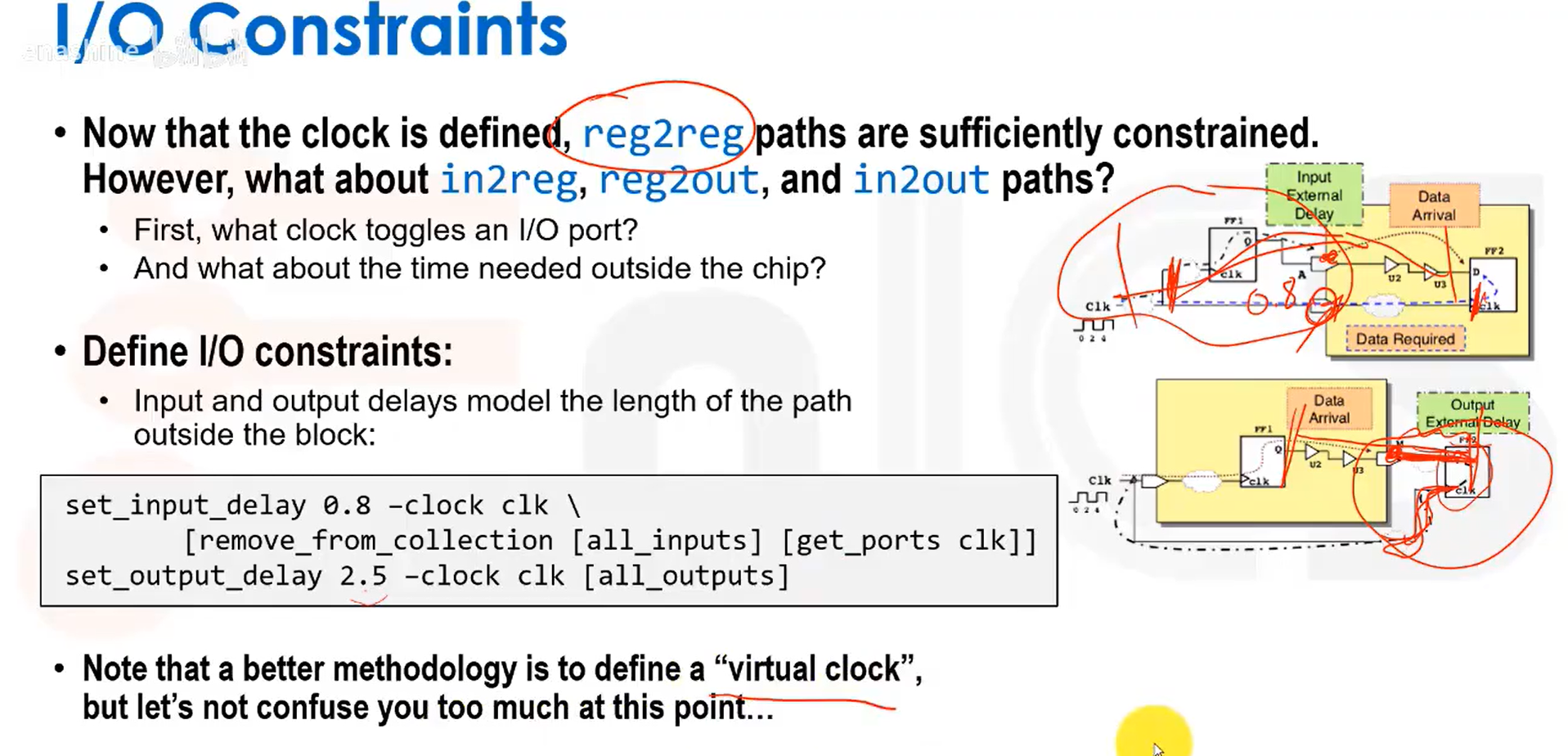
另一种可能的IO约束方式是设置最大延迟。我们还需要对输入管脚的驱动和输出管脚的负载电容进行建模,使能更接近真实情况:

我们可以将实际不可能存在的路径设置为伪路径,告知工具不需要检查此类路径:
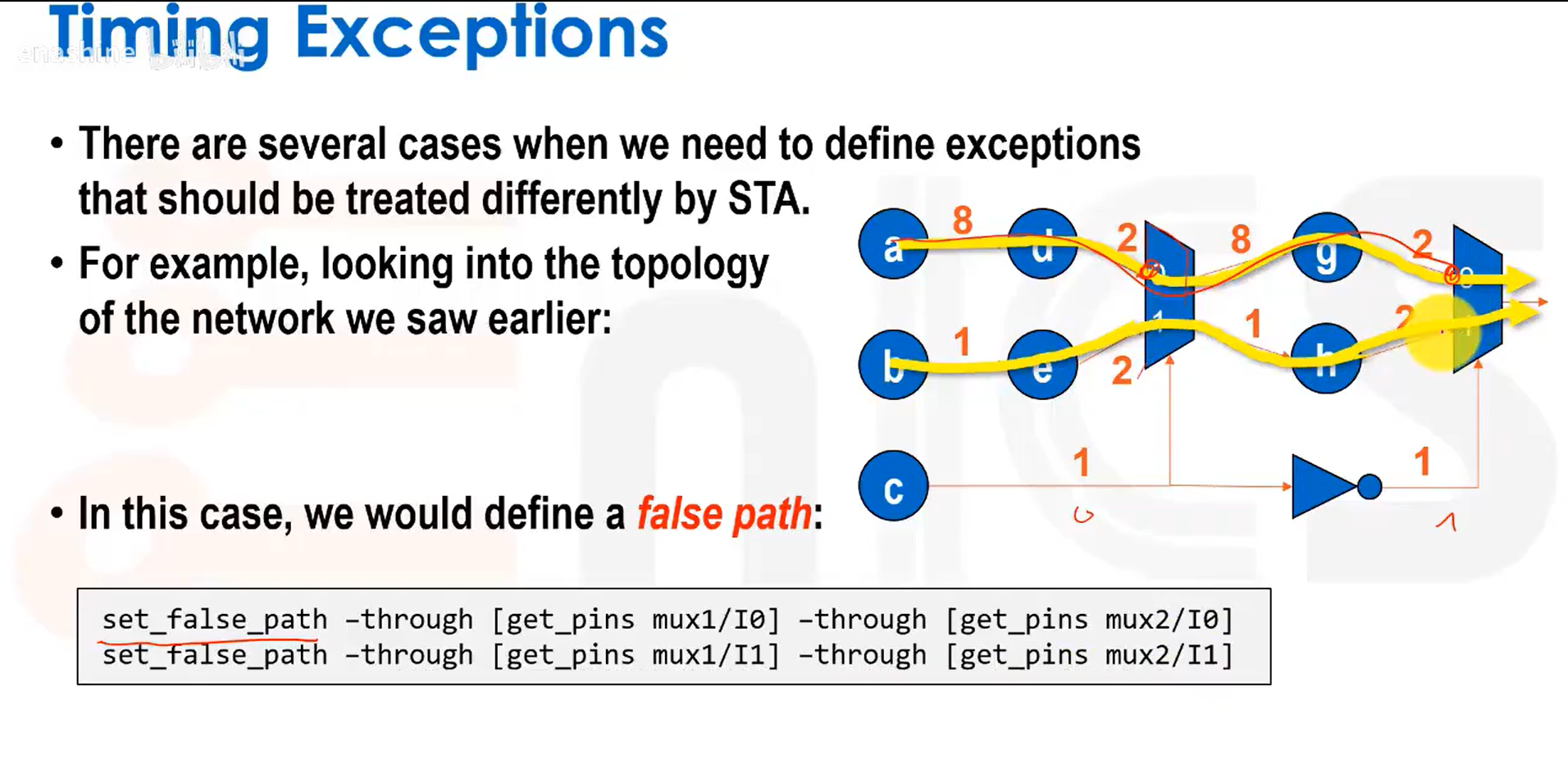
一种常见的伪路径是跨时钟域同步器。可使用上述命令,也可以将两个时钟组设为逻辑互斥,这样工具会自动屏蔽所有经过CK1和CK2的路径:

设计规则约束:

L30 芯片时序分析&多模式&多角点
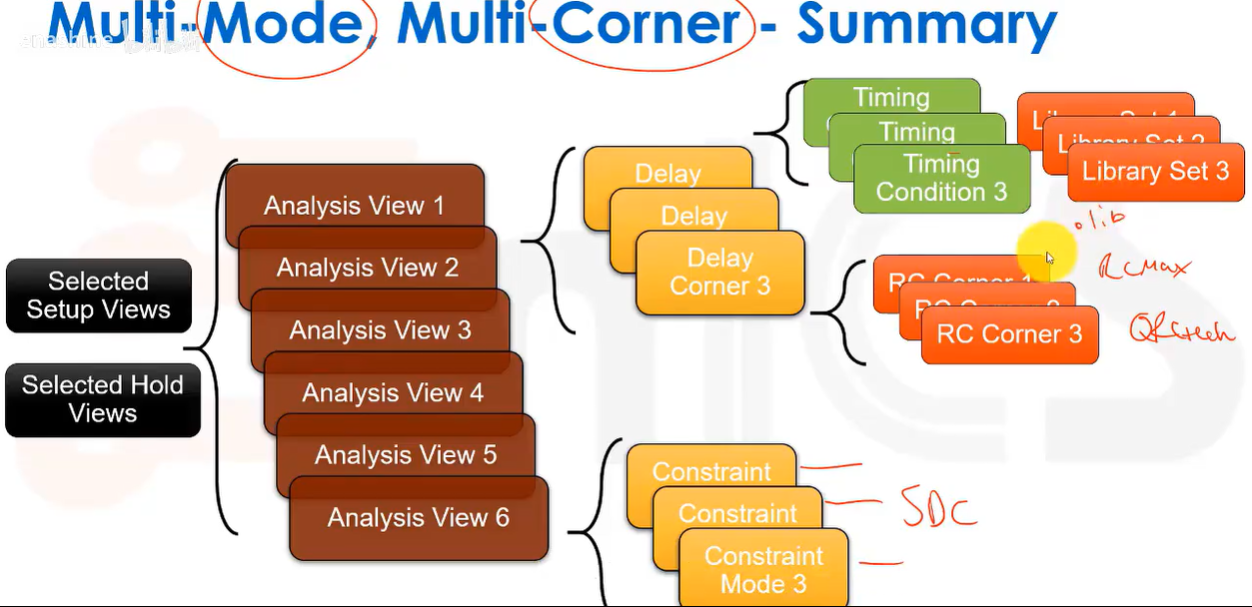
MMMC:多模式多角点分析方法。建立一套自动化流程,在这套流程中,可以定义多种不同的模式和工艺角点,然后让工具识别它们,依次加载,运行时序分析,进行优化,再次进行时序分析,并自动完成所有检查。作为用户只需要进行初始定义,达到简化工作的目的。

其核心理念是建立分析视图(analysis view),一个分析视图包含一个工作模式和一个工艺。角点。下图展示了三种不同的分析视图。

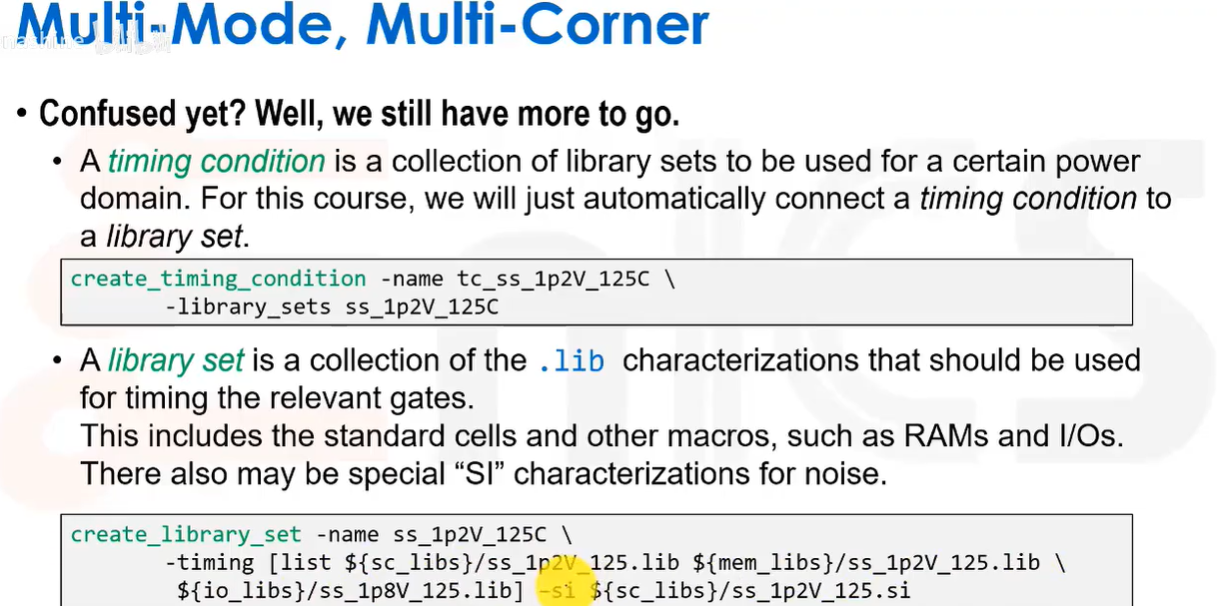
分析视图的模式通过约束模式定义,角点通过延迟/时序角点定义。时序角的作用是告诉工具应该如何计算延迟,因此它包含了时序库和寄生参数提取规则;而约束模式本质上就是针对特定工作模式的相关SDC命令的集合,如时钟周期,工作条件等约束。

下图为约束模式和时序角的具体设置。可以看到,时序角是由RC角 (决定我们如何进行寄生参数提取,如何获取电阻电容值)和时序条件(决定我们如何基于时序库进行时序分析)组成的。

下图创建了一个时序条件,并把它关联到一个库集合(library set)。一个库集合实际上就是相关门电路所需.lib文件(如标准单元库,存储器库,IO库)的集合。
最后是RC工艺角,它实质上是RC提取所需规则的集合:

总结:
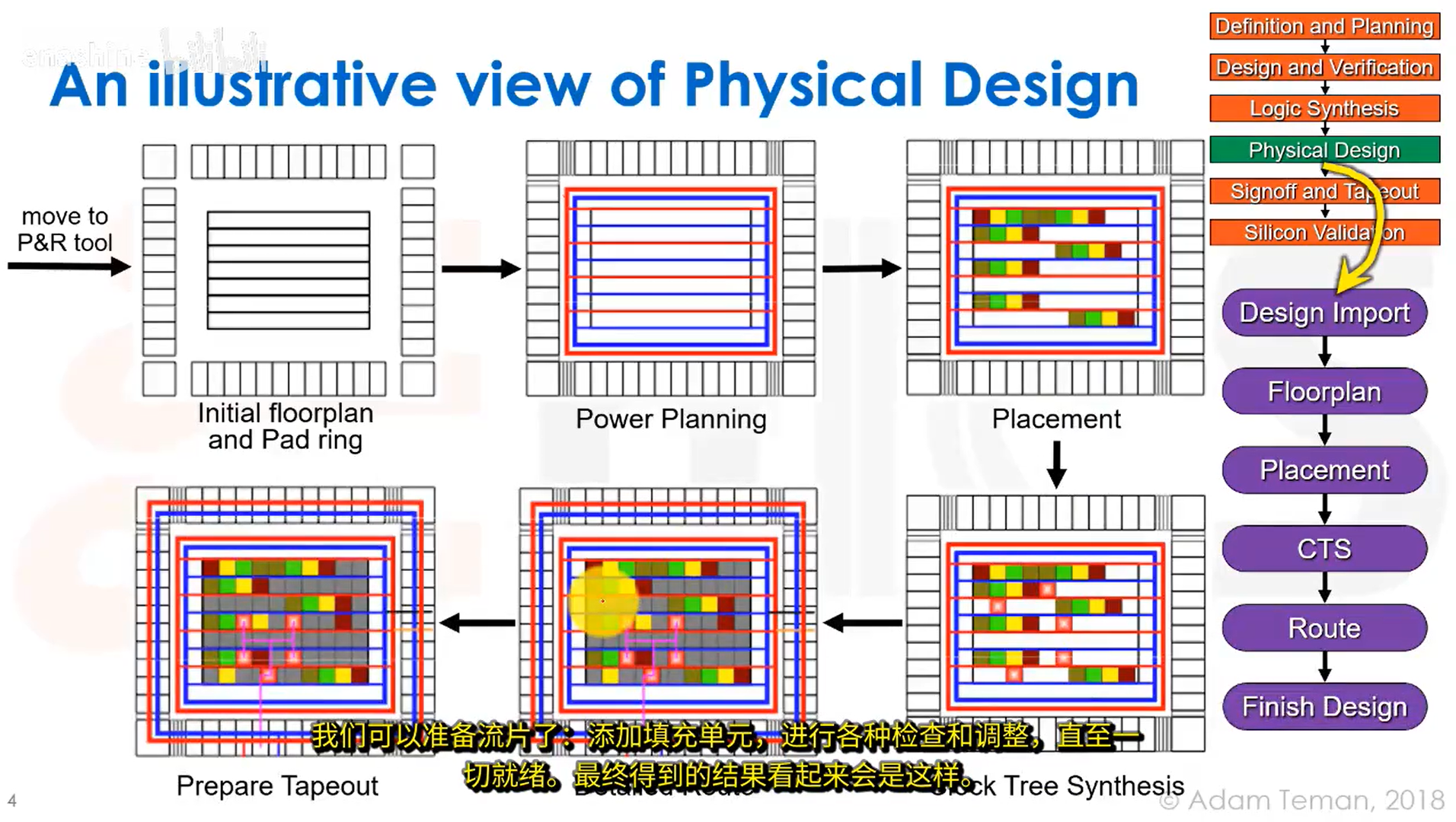
L31 VLSI物理设计&版图规划&时钟树综合
首先我们要从基于逻辑设计的工具转换到基于物理设计的工具,为设计打下物理基础。我们要做的第一件事是制定版图规划,包括确定模块位置,电源网格,特殊走线等。之后可以进行门级电路的布局,即放置标准定单元,这个过程需要考虑时序和拥塞。
布局完成后,触发器的位置就确定下来,这样我们就知道了时钟元件的位置,之后就可以构建时钟树,将时钟信号分配到设计的每个部分。最后可以进行布线,将所有的网格实际连接到各个门电路和IP核的引脚上,这个过程需要考虑DRC,时序,噪声等因素。

流程示意如下图所示,红色方块为时钟树综合加入的缓冲器。
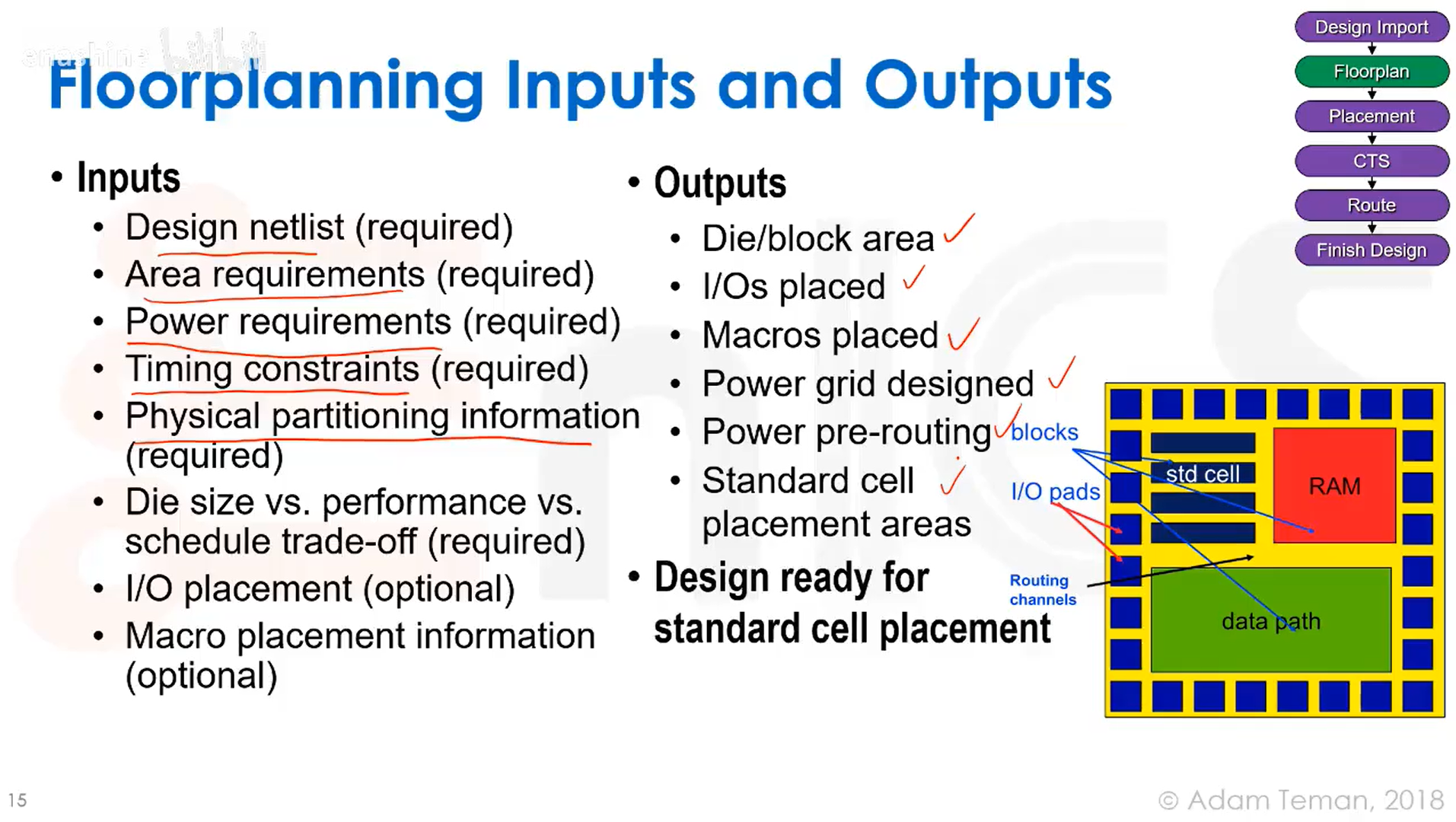
版图布图前需要准备的文件:

要开始物理实现,我们首先需要定义全局网络,比如明确VDD是什么,它如何实际连接到各个单元等;我们必须提供技术规则和单元抽象信息,说明DRC规则是什么,以及包含单元尺寸、引脚实际位置等信息的.lef文件;还需要提供物理单元,如用于填充版图空白区域的填充单元,将门电路钳位到高电平或低电平的钳位单元等;我们需要在所有工作模式和条件下定义保持时间约束,这在综合时的理想条件下比较容易满足,但进入物理设计阶段后需要考虑。

L33 芯片布局规划&模块放置&布线优化
布局规划的目标:

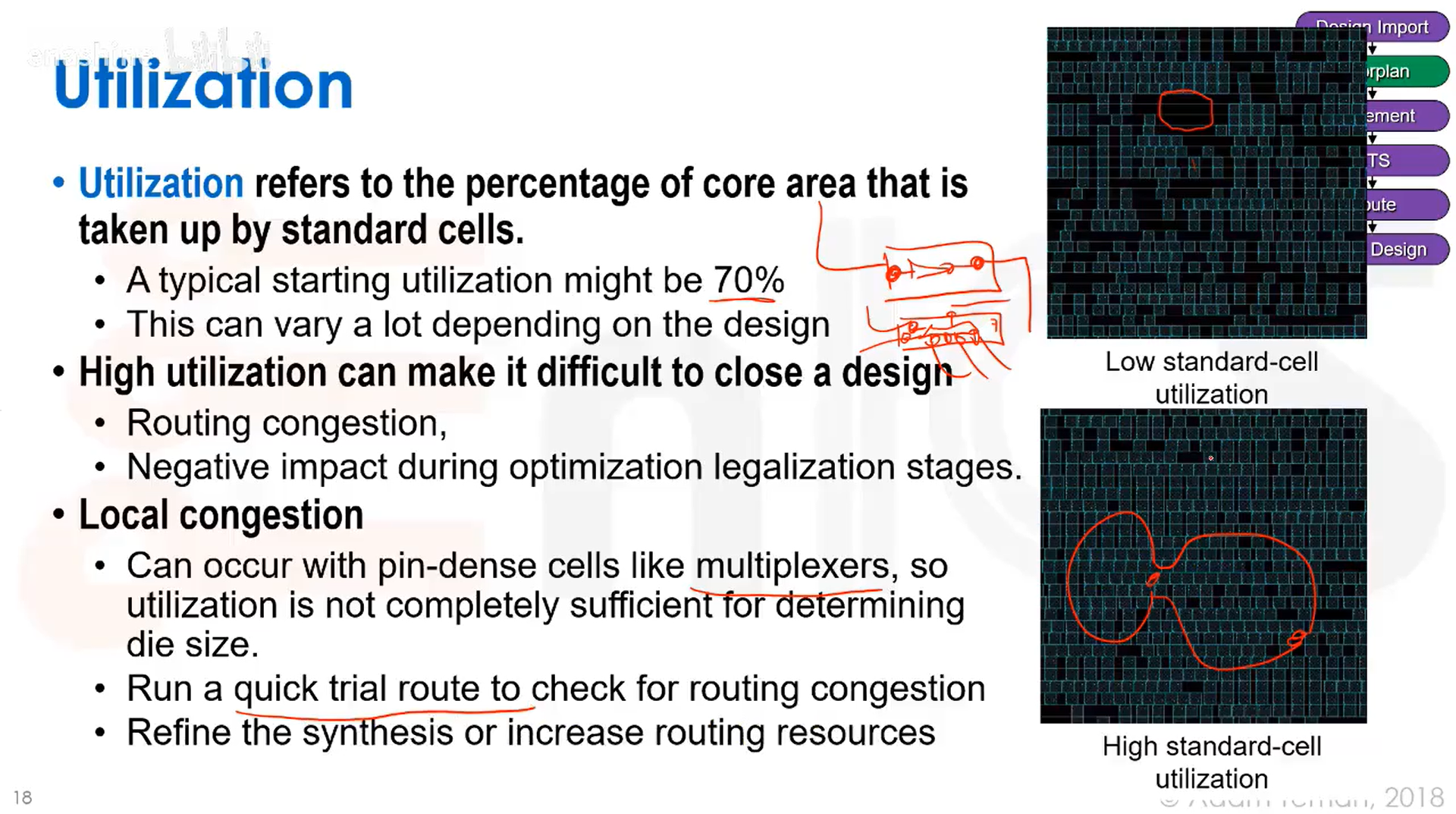
利用率指的是核心区域被标准单元所占面积的百分比。初始利用率可能设置在70%左右。高利用率会使设计收敛变得困难。
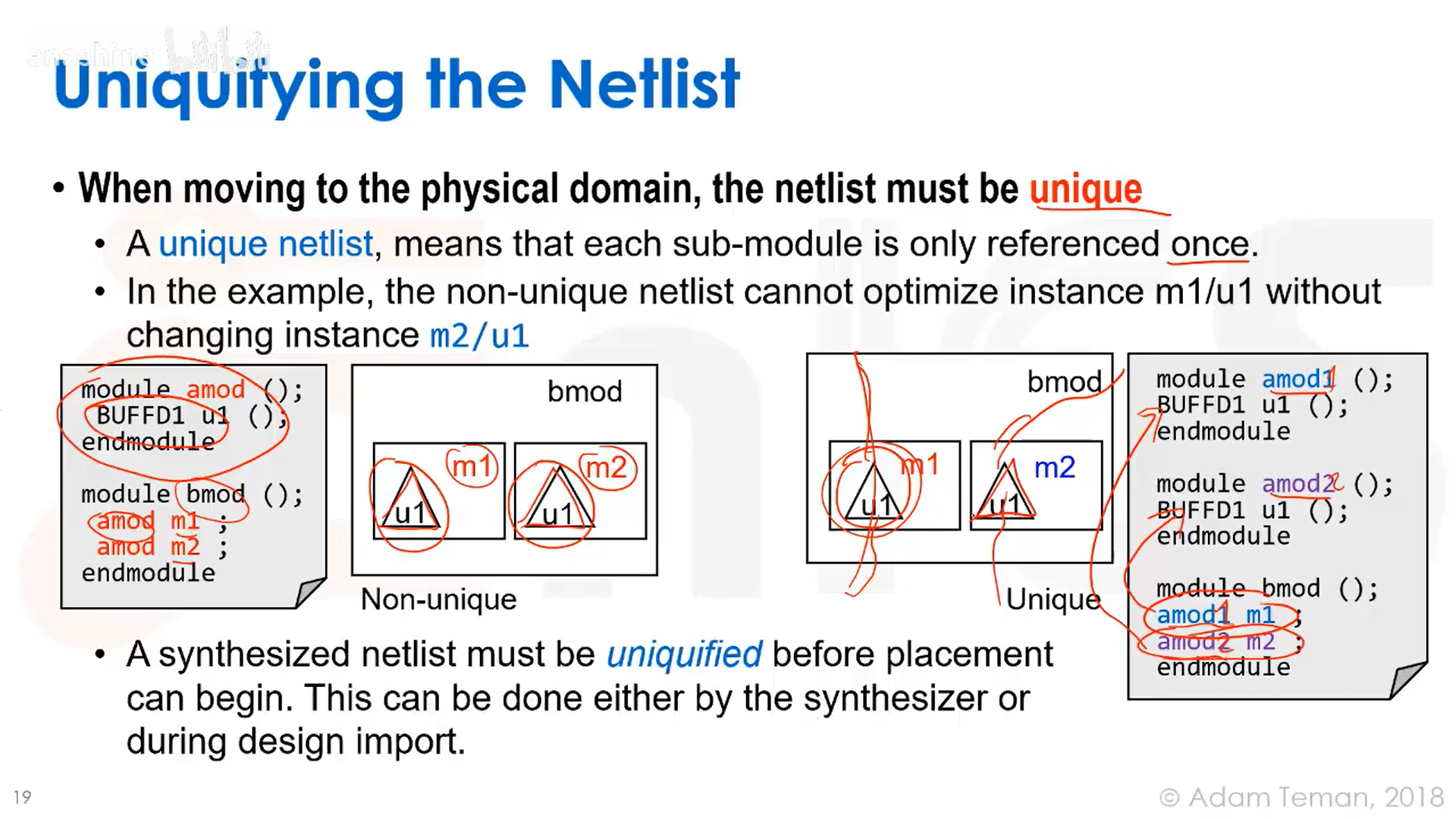
布局布线前需要进行网表唯一化,通常这个工作在综合阶段已经完成。
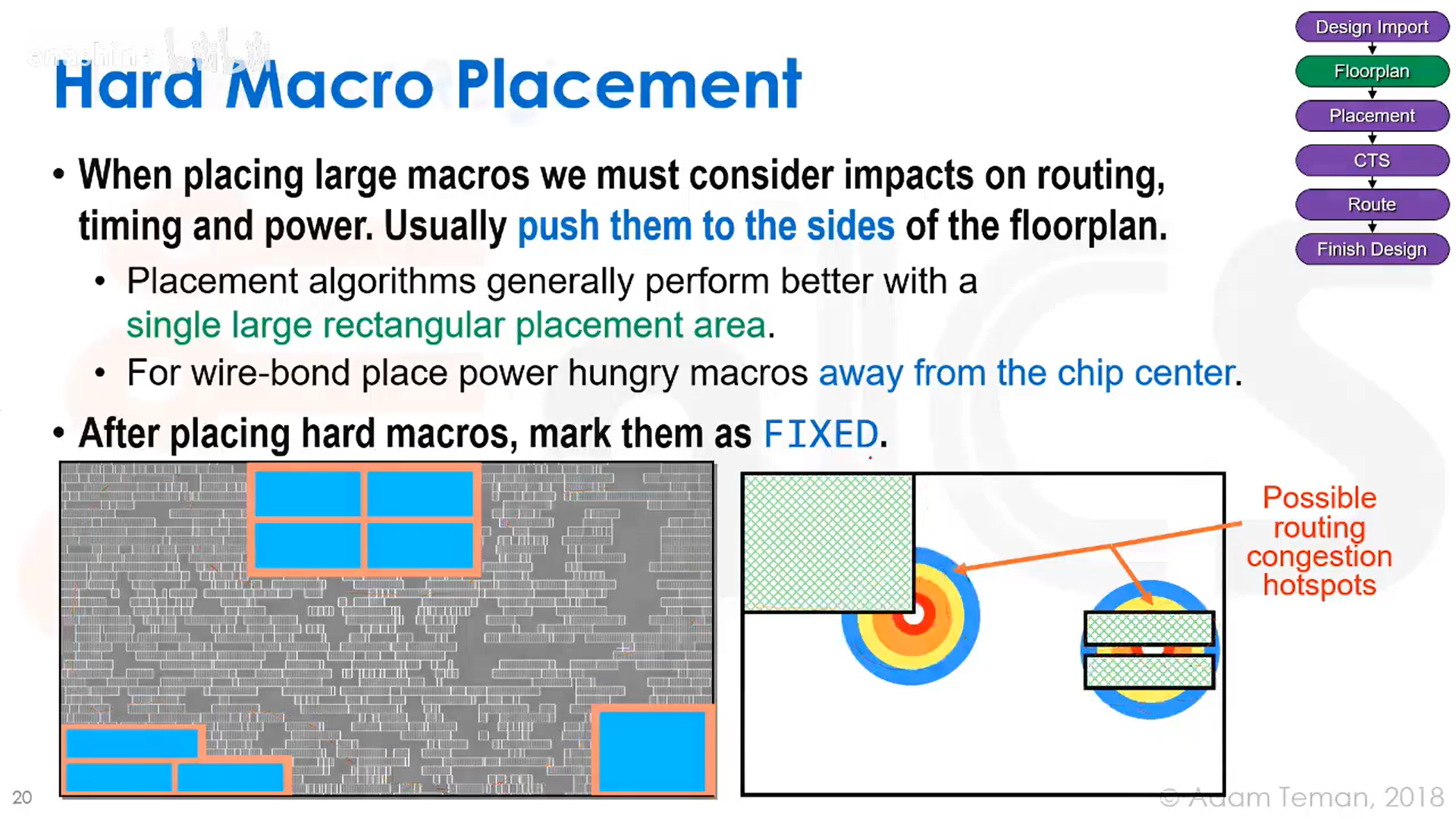
硬核宏模块通常放置在版图边缘,放置后将它们标记为固定,确保位置不会改变;
可以选择施加布局区域约束:

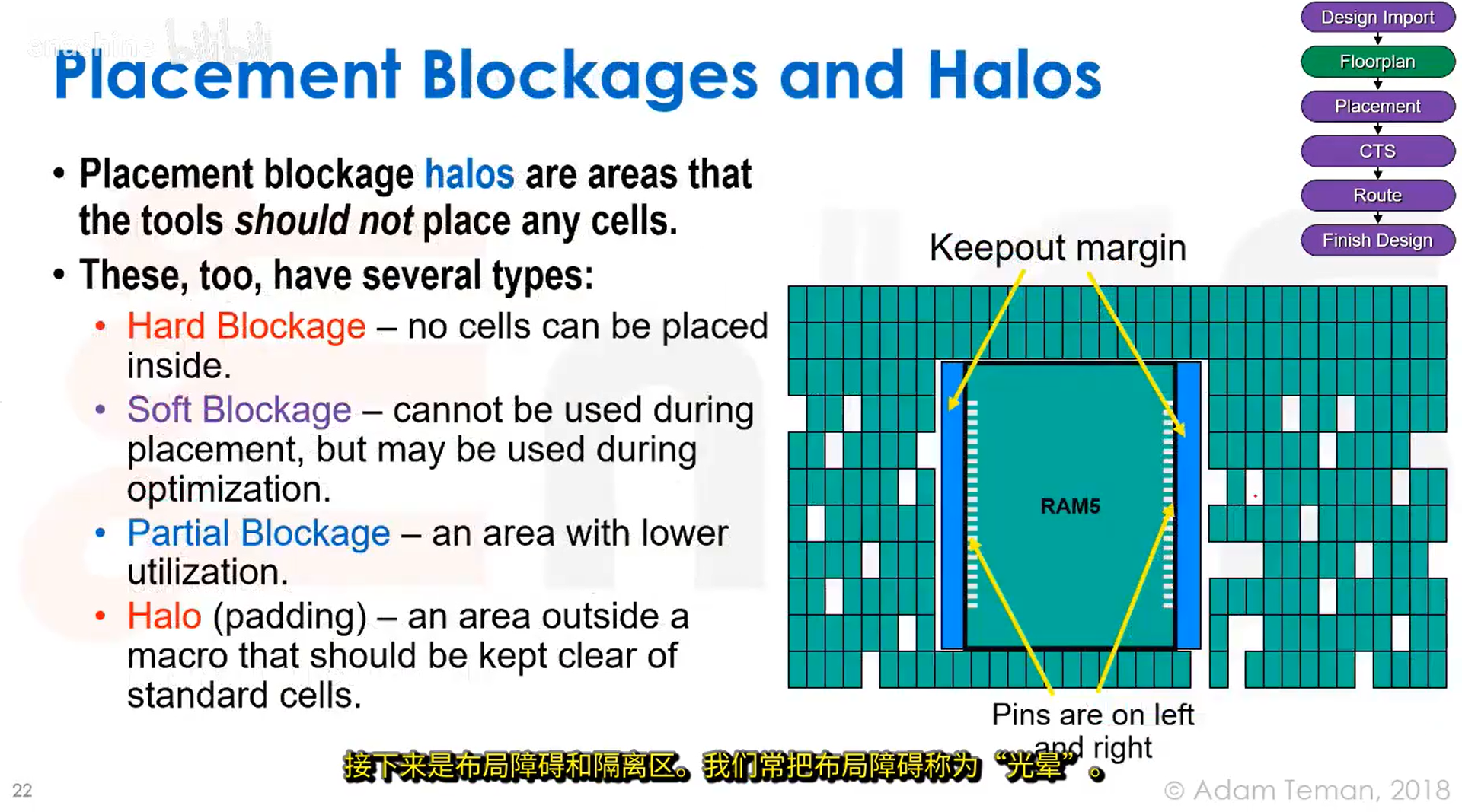
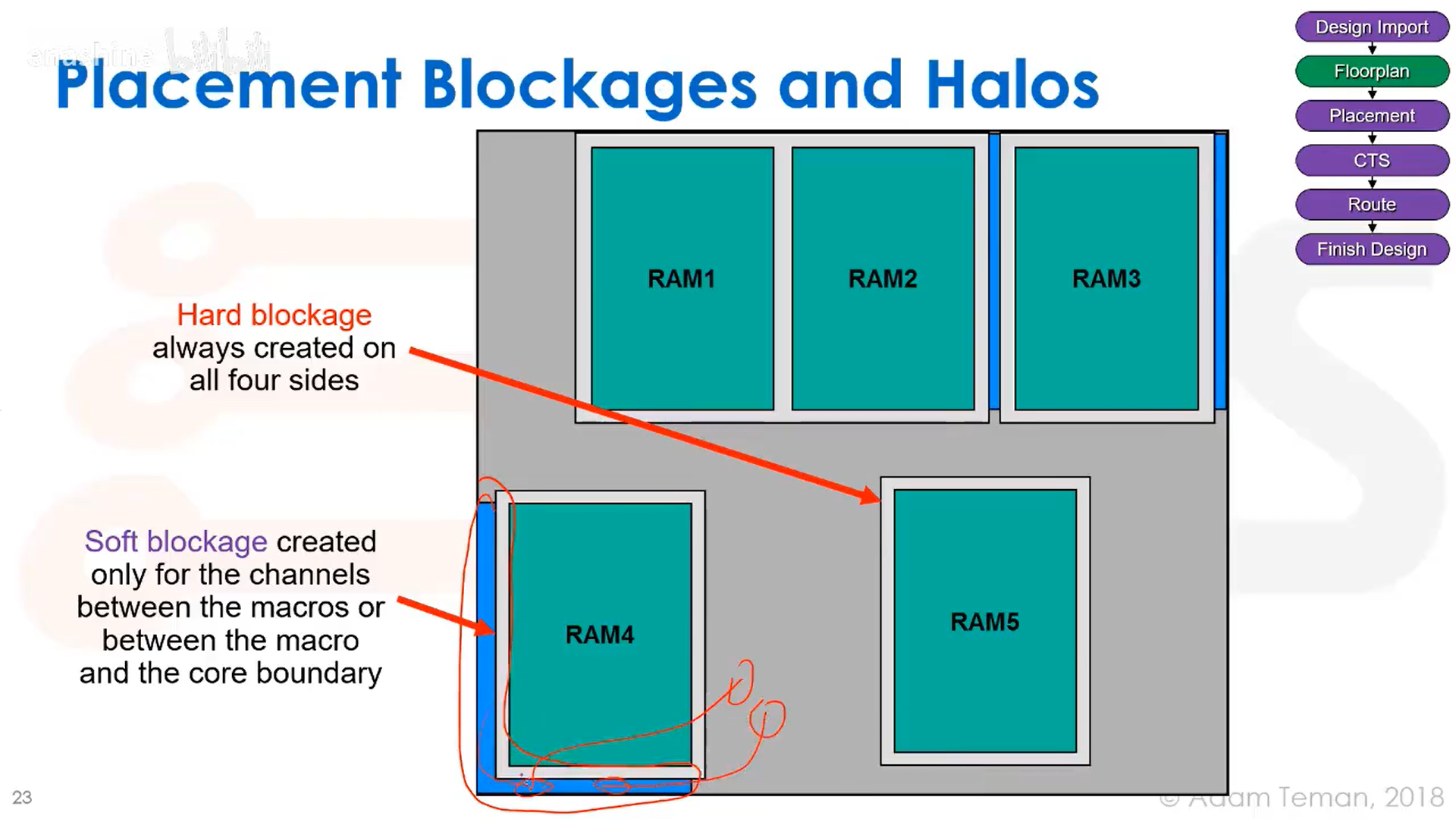
放置布局障碍和隔离区(halo),我们经常在宏模块引脚正前方区域放置布局障碍,用来防止标准单元放置到引脚附近而产生的布线问题:
当我们不希望有任何走线经过某个区域,可以设置布线障碍:
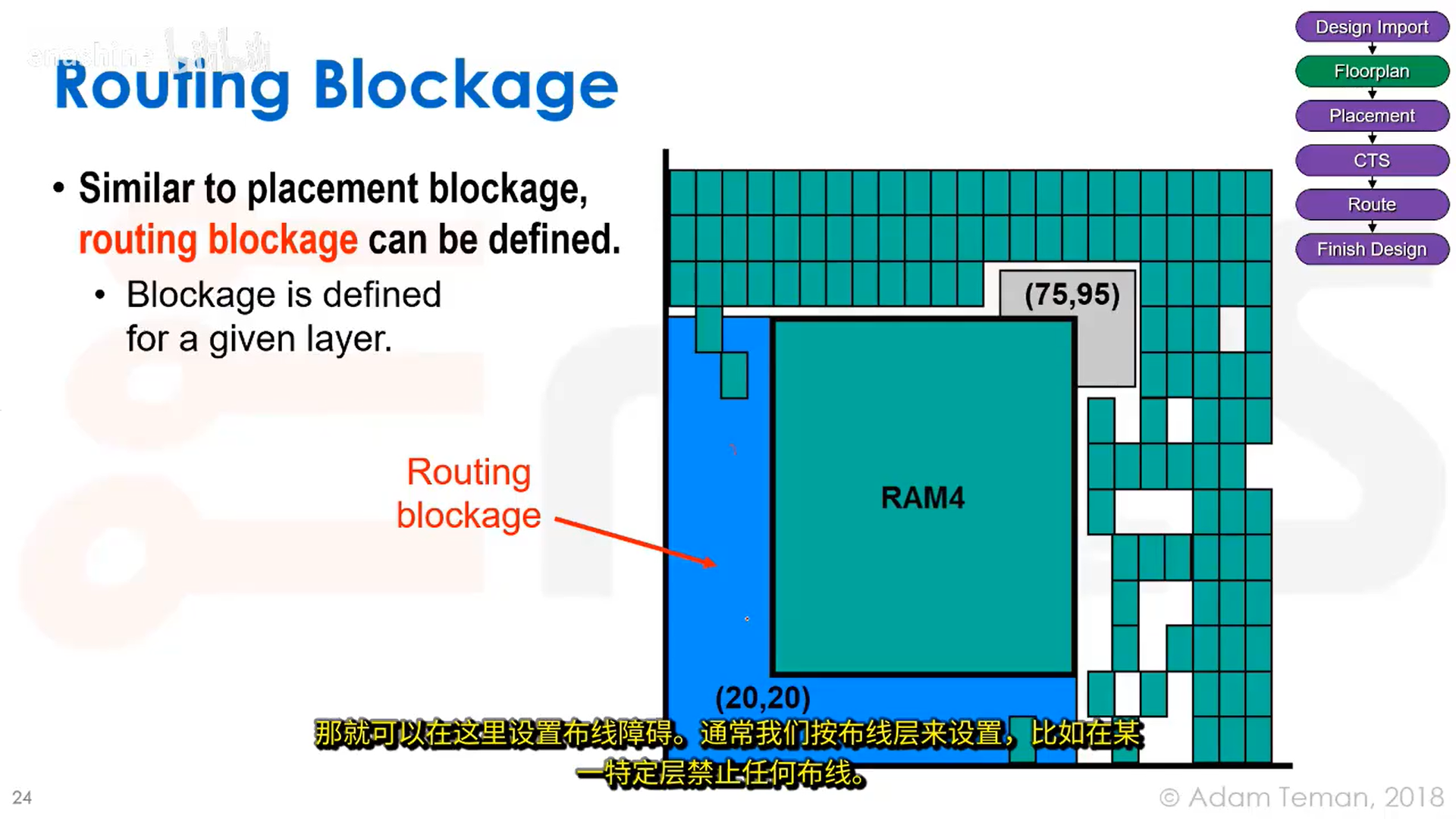
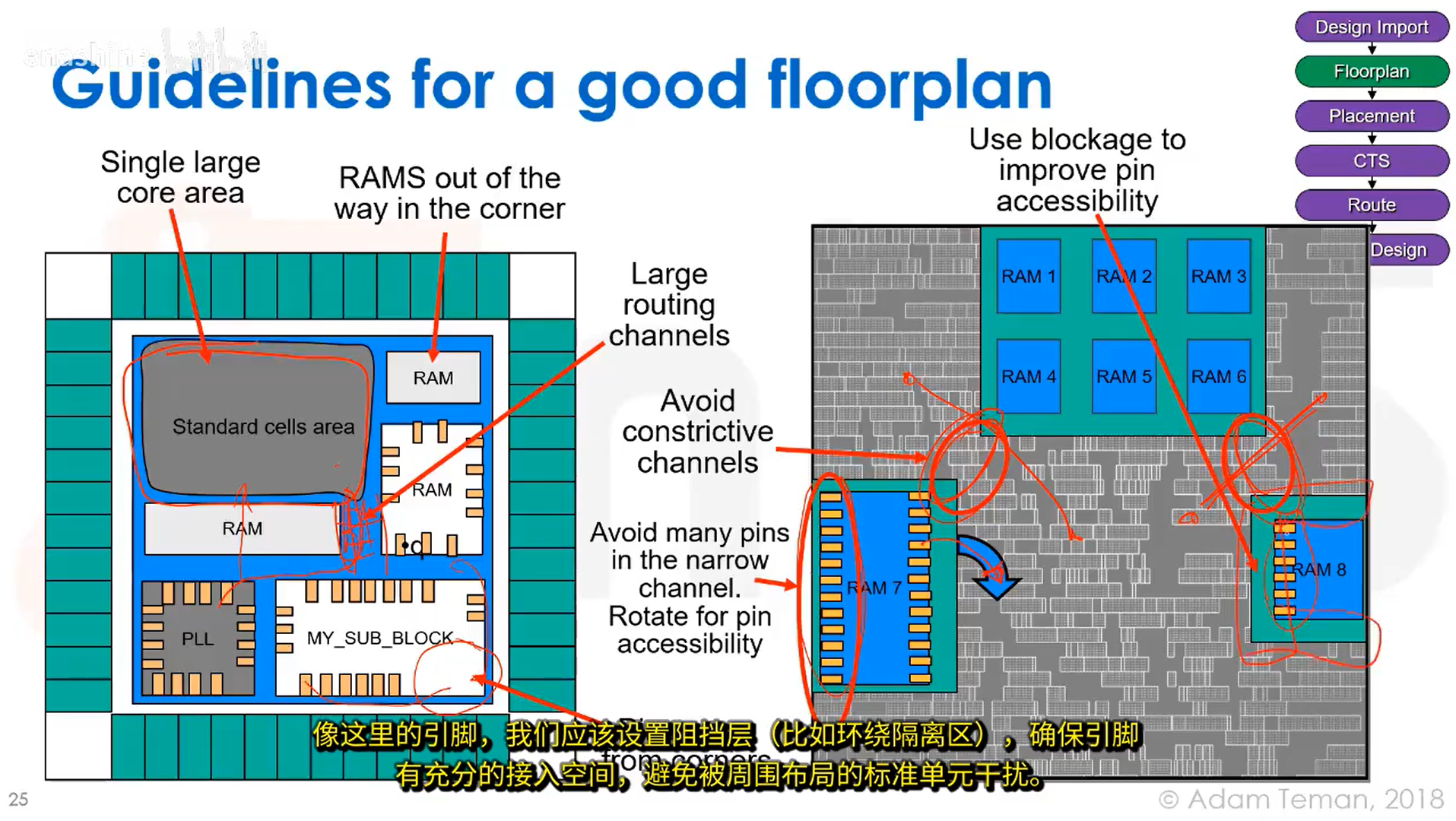
关于良好布图规划的指导原则:
L35 电源规划&IR压降&电迁移
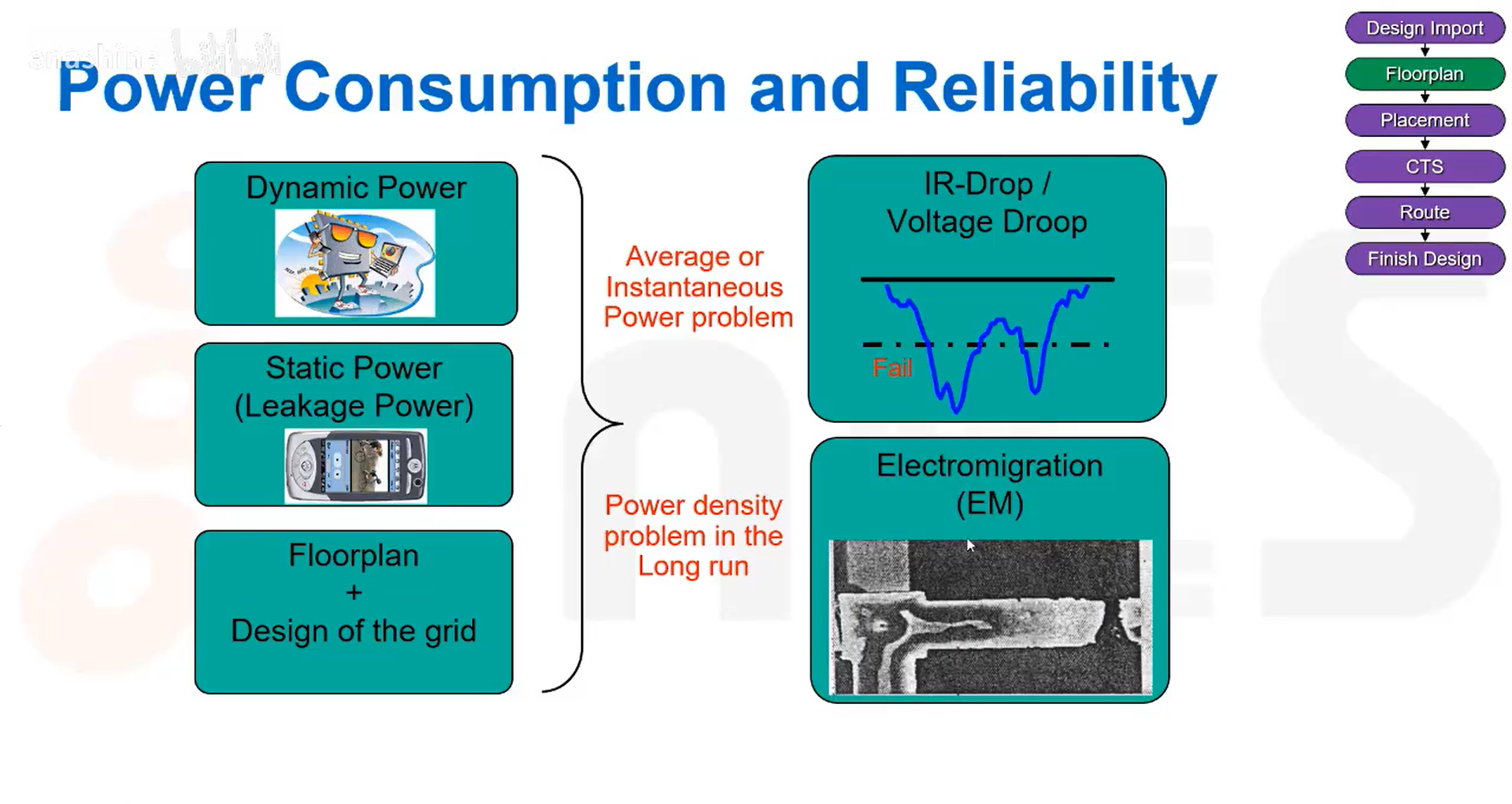
瞬时IR压降问题:

另一个长期可靠性问题是电迁移,它指的是由于电流流过导体导致导体内的金属原子逐渐发生迁移,本质上是电子动量的转移。电流流经导体时,其中的电子会撞击金属原子,长此以往可能会导致导线断裂或尺寸变化,如使导线变细,从而使电阻变大,性能下降。

电源分配有几个主要功能。首先,它必须将电流从芯片的焊盘(外部I/O接口和晶体管焊盘)输送到晶体管;它需要维持一个低噪声的稳定电压,并同时满足平均功耗和峰值功耗的要求;需要为电流提供完整的回流路径,并且必须避免电迁移和自热引起的损耗。
一种实现方法是加宽电源线。更宽的电源线意味着更小的电阻,从而减小静态IR压降;还能够减小封装电感,从而降低动态压降;导线加宽后,电迁移现象也会减弱,因为原子被电子撞击移位的概率降低了。但是,加宽电源线也将导致留给信号布线的通道和资源减少,从而加剧布线拥塞程度。
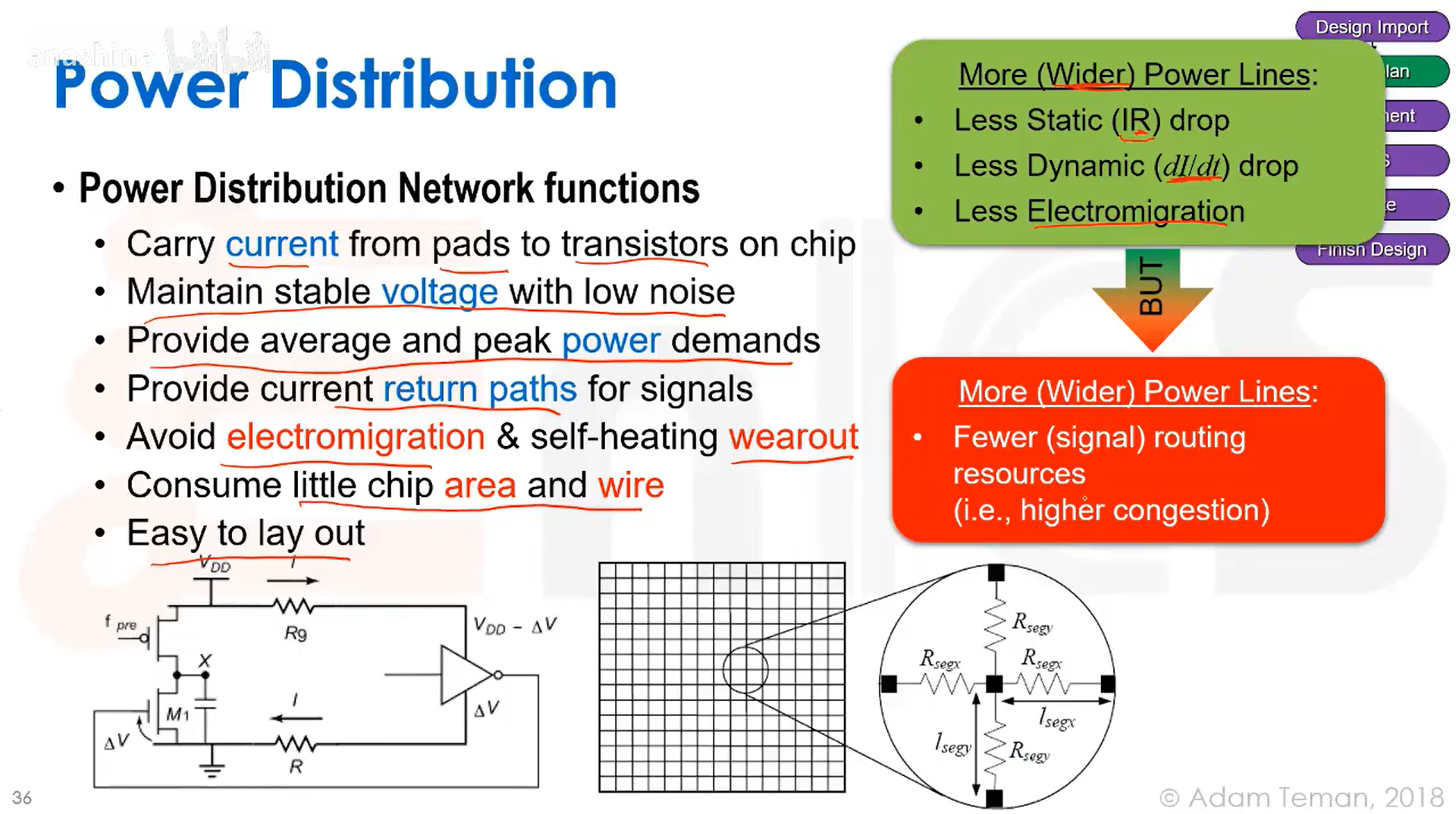
IR压降的计算示例,我们需要把电源轨道做得尽可能宽(减少方块数)、尽可能厚(减小方块电阻),从而降低IR压降:

IR压降的热力图:
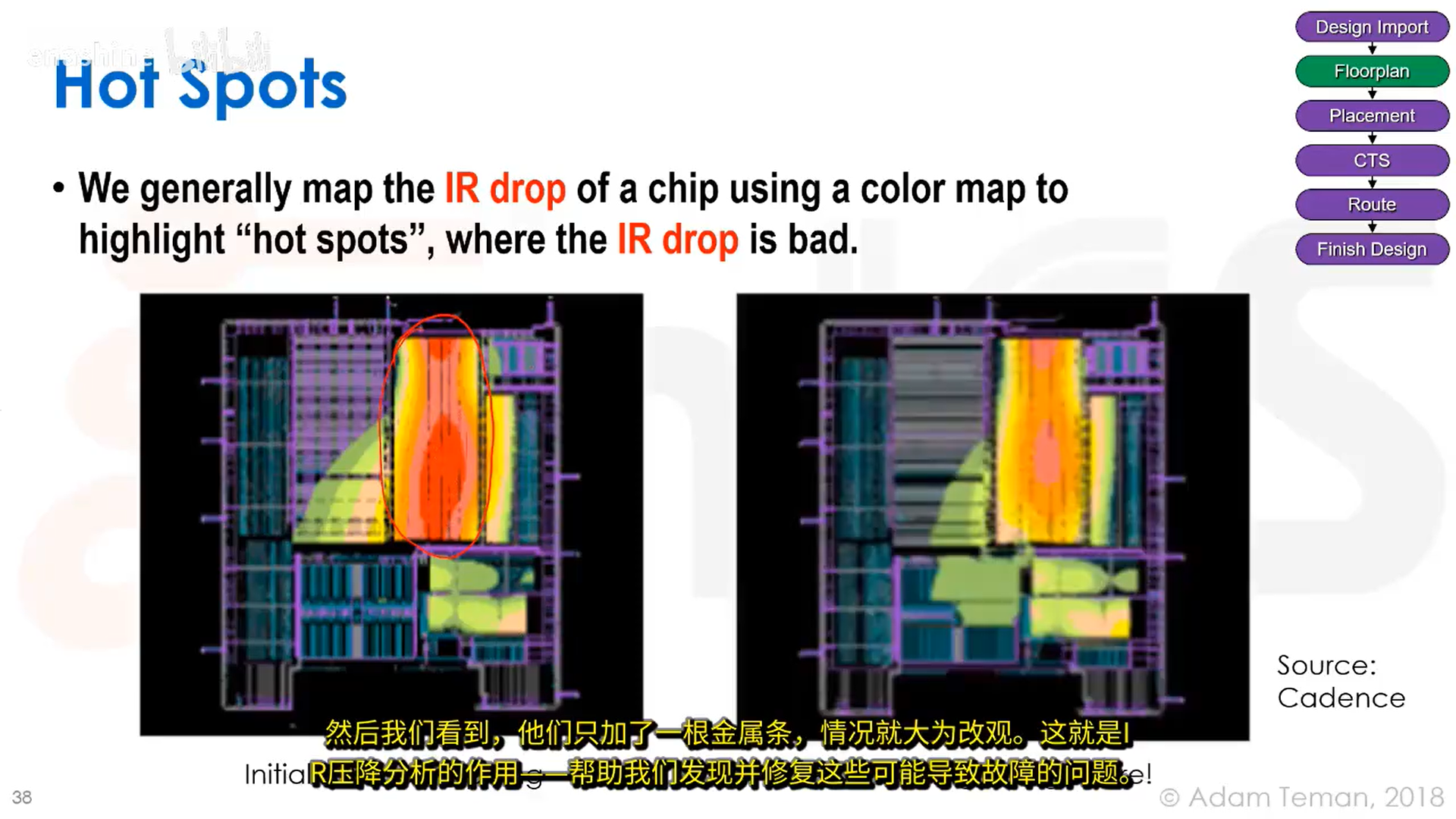
我们的做法是设置VDD和GND交替的轨道,为标准单元(每个CMOS门)供电,每个门都需要这两类电源轨。然而如上文所述,长导线会带来很大的电阻,因此我们的目标是降低从电源焊盘到每一个门的路径电阻,通常通过电源网格来实现。
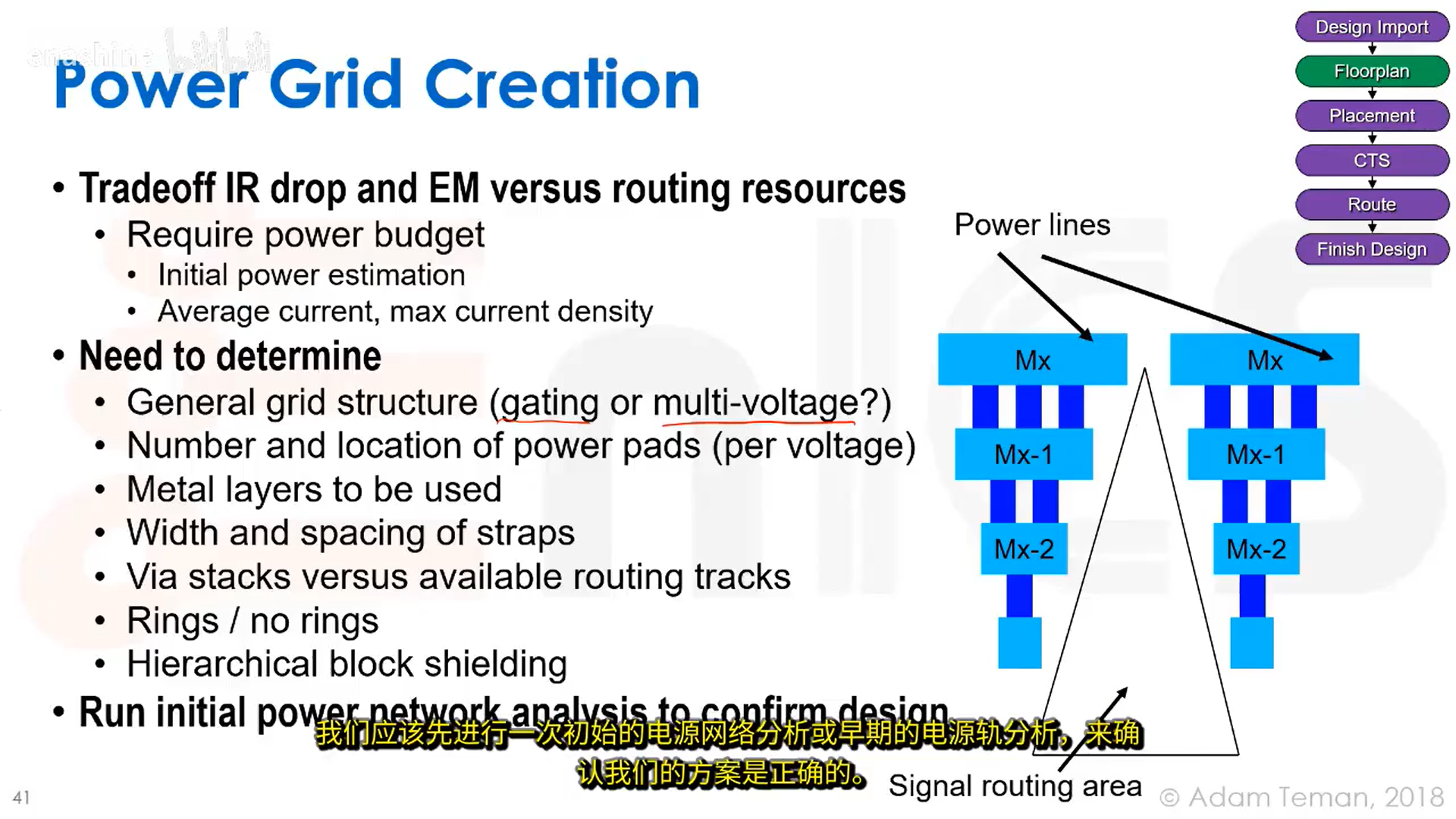
具体做法是,从封装引出的电源/地焊盘,会连接到电源环/地环这样的结构上,这样芯片周围就形成了一个近似等电位的环境。接着我们会布设一些走线,将它们与环连接起来,从而更高效地供电。这通常使用分层结构,如先从顶层开始,我们会使用顶层那些宽、厚所以方块电阻较低的导线,它们主要用来连接VDD和地;接着往下层走,当需要连接到直接与晶体管本身连接的METAL1层时,我们就借助通孔堆叠和更细的走线来实现。我们会在层间使用大量通孔,以降低通孔电阻。
我们通常会在布局规划的早期预留好电源和地的布线资源,之后就不能将它们用于时钟线或信号线的布置了。

标准方法是构建一个供电网络,通过纵横交错的走线,将VDD和地连接起来,通常上层较厚金属层中超过一半的布线资源都会被用于VDD和地,另一种方法是采用专用的VDD和地层,这曾应用于Alpha 21264处理器,这种方法会在VDD和地之间产生大量我们所需要的寄生电容,但这种方式非常耗费布线资源,但能够简化矩阵分析。
我们还需要对电源和地的输入输出结构进行协同优化,如在VDD和GND之间使用去耦电容储存大量电荷,从而降低噪声、滤除高频波动,达到稳压目的。例如突然有一个反相器需要开关,它就可以直接从这些本地电容获取电荷,而不必从主电源抽取。
这就是为什么我们需要在VDD和地之间尽可能多地放置电容,以及在一切可能的地方添加去耦电容。我们可以直接加入这些额外的电容,电容可以集成在标准单元里,比如包含一个MOS电容或其他类型的电容;或者仅仅是将VDD走线和地线紧挨着放置,它们之间的耦合电容对我们也是有益的。

那么,如何构建供电网络?我们需要在IR压降,电迁移和布线资源之间进行权衡。电源布线越多,IR压降和电迁移问题就越有可能得到改善,但留给信号布线的资源就越少。因此我们需要提前进行估算,如确认平均电流以及各处最大电流密度是多少,然后采用这种自上而下的分层设计方法,确认总体网格结构,电源焊盘数量,电源条带宽度和间距等。信号布线将主要集中在底层。
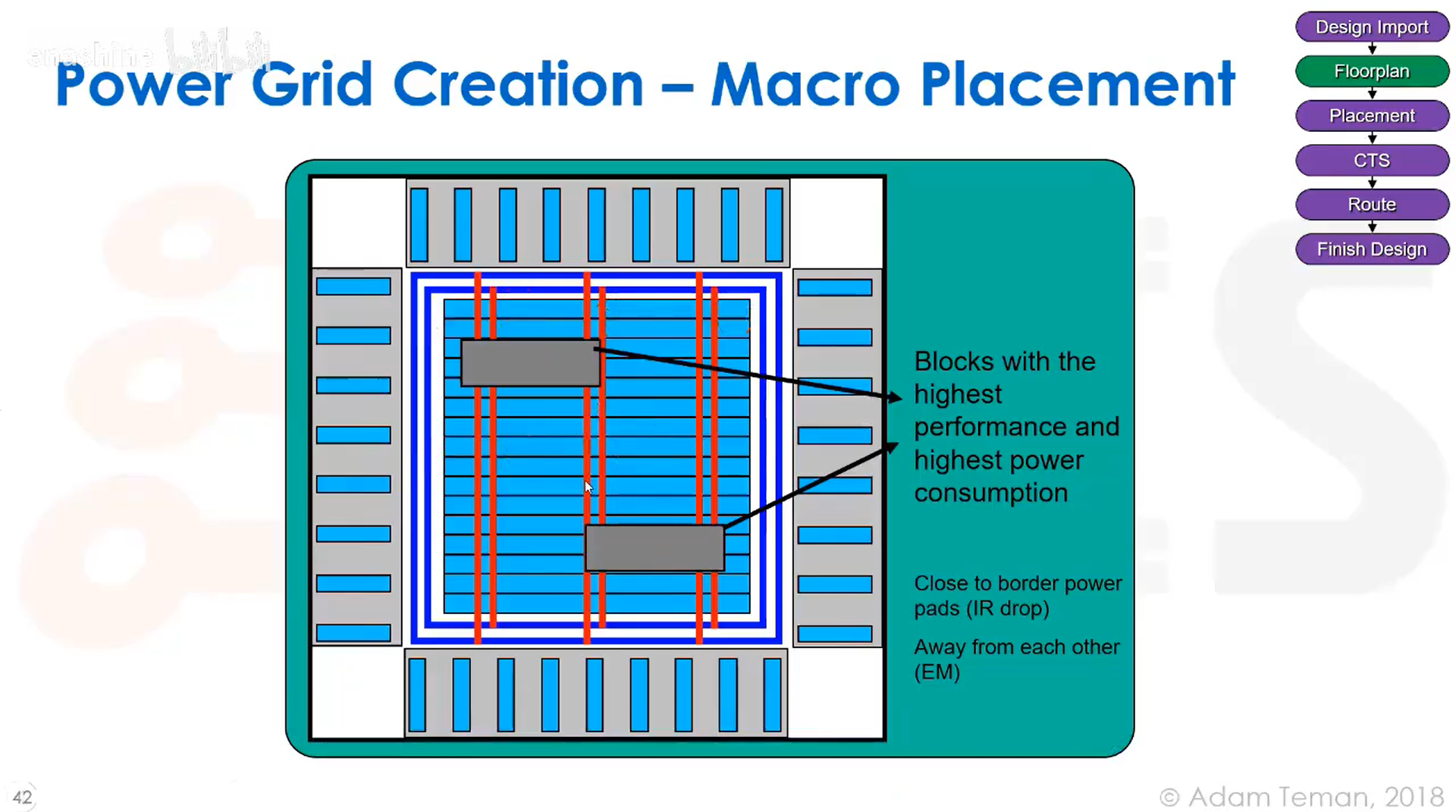
对于那些性能要求最高,功耗最大的模块,我们的做法是尽量将它们放在靠近边缘的位置,以使IR压降最低,同时让它们彼此远离:
Innovus Floorplan设计流程总结:

如我们决定将电源网络命名为VDD,而一个反相器单元的电源引脚为VCC,我们需要让VDD连接到VCC,这将通过定义全局网络实现。接下来是创建电源环与电源网格,最后为设计分配引脚。

L36、37 芯片布局&全局布局&布局优化算法
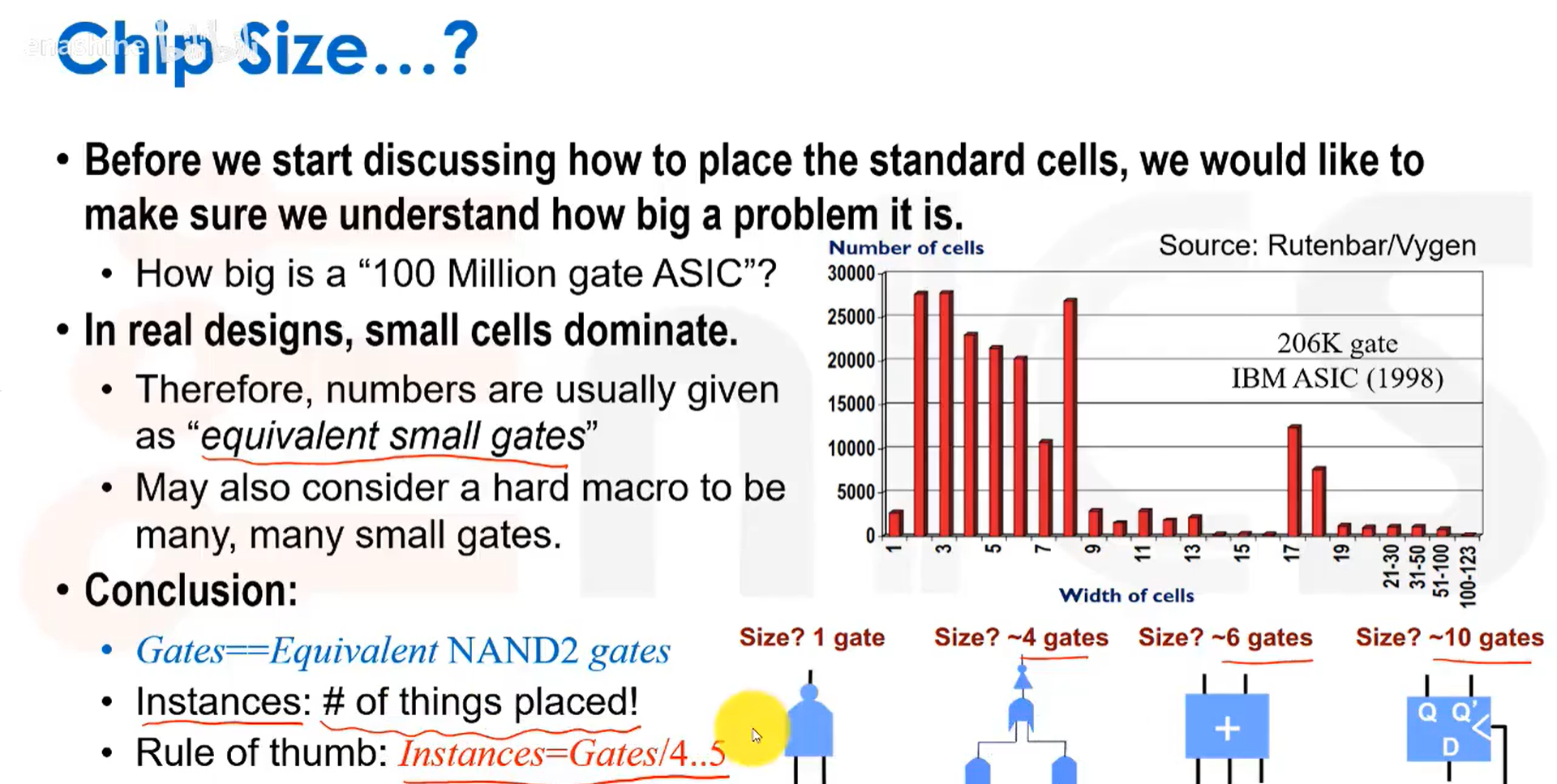
芯片规模通常指的是等效的NAND2门的数量:
· 全局布局与详细布局:
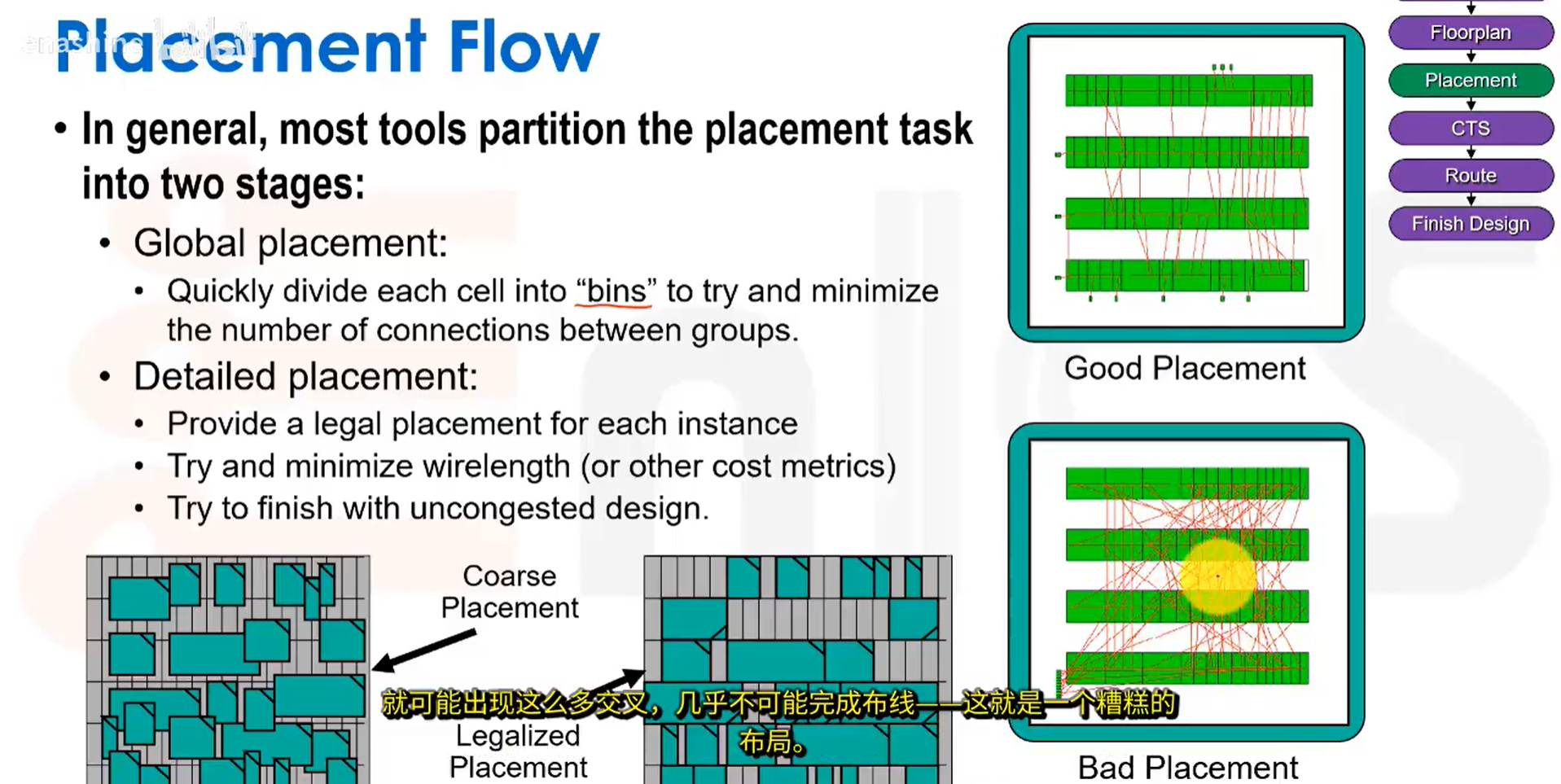
布局目标是最小化面积与线长,并考虑时序与拥塞:

一种度量方式:半周长线长。
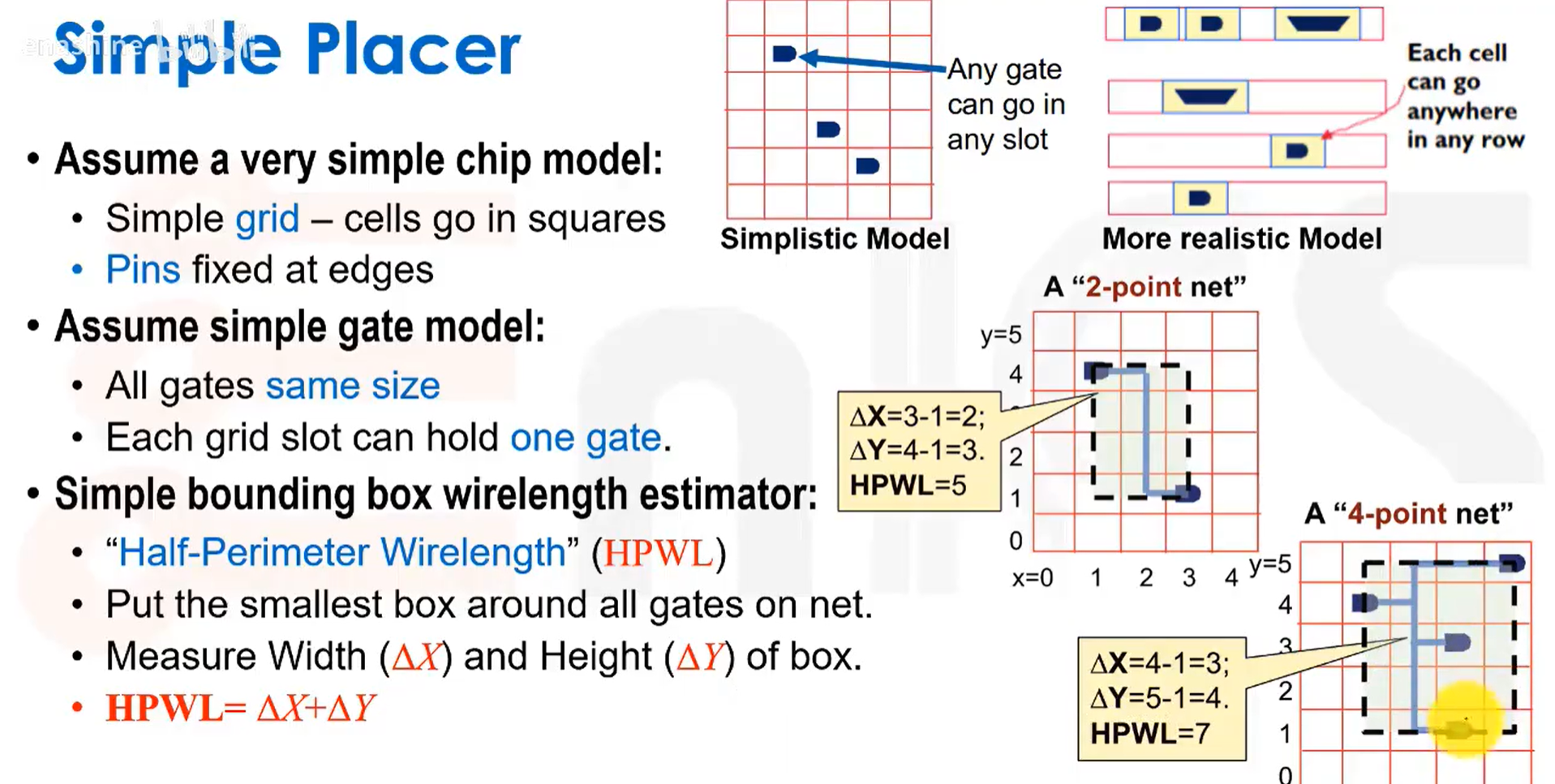
一个简单的布局算法如下。随机放置所有门电路,并计算总的半周长线长。之后随机选取一对门电路,交换它们的位置,重新计算总半周长线长,如果wirelength减小,则保留交换,否则撤销交换。重复该过程直到半周长线长不再变化。 
该方法有一定效果,但会导致陷入局部最优解:
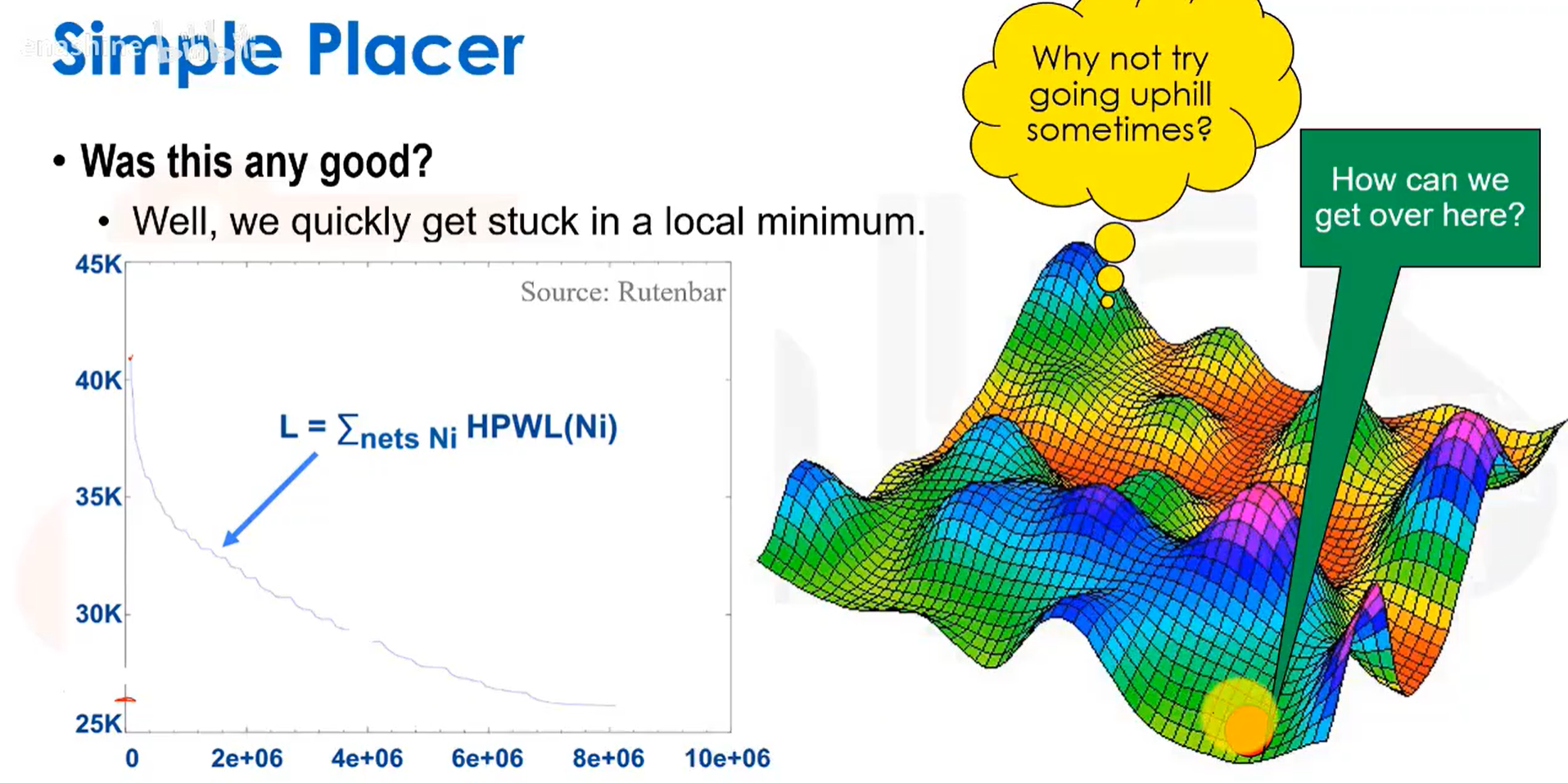
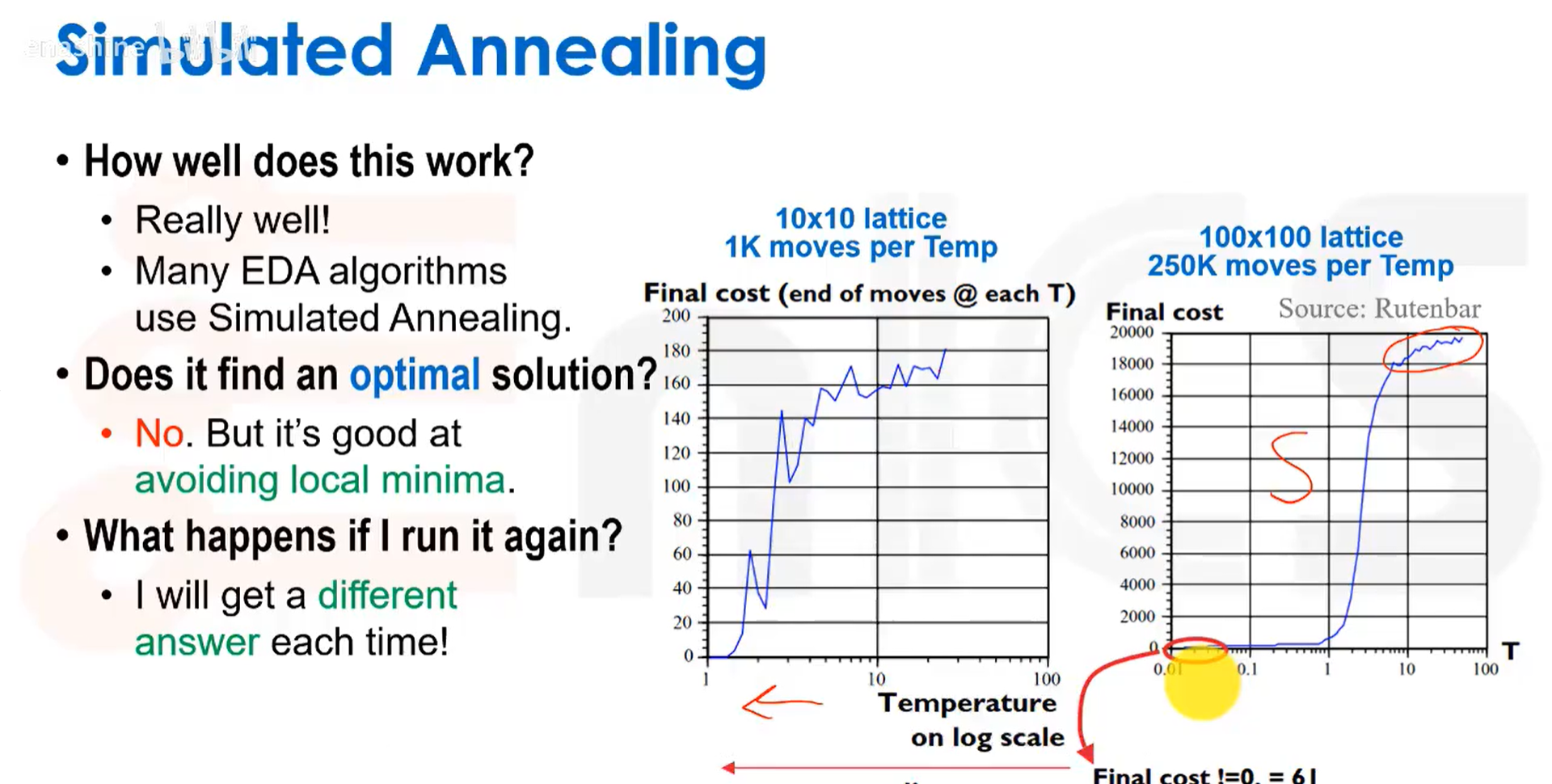
这引出了模拟退火算法。我们可以采用一个移动概率公式,能量变化越大,我们接收移动的概率就越高;能量/温度越低,我们进行移动的概率就越低,这样我们大幅移动的次数就变少了。

首先生成一个随机的初始布局,然后随机交换两个门电路,评估半周长线长的变化,如果线长变短,就接受这次交换;如果线长增加,我们会评估一个退火概率函数P,然后随机生成一个0到1之间的随机数R,如果R<P,则保留交换。其中T是模拟温度,从高温开始,然后逐渐冷却。
这意味在算法运行初期,由于P值较大,随机数R<P的概率要大得多,随着温度降低,P值会变小,因此R>P的概率就会降低。我们的做法是,在进行一定次数的交换尝试后就去改变T,即降低温度,一旦改变停止,就进入冻结状态,并跳出主循环。所以,流程就是在每一个温度下,都进行大量的模拟尝试,在这些尝试中,有时我们接受交换,有时不接受,然后降低温度,再进行新一轮的大量尝试,如此反复。

可以看到这个方法卓有成效。由于它是一种基于随机过程的启发式方法,所以它无法找到理论上的最优解,但它擅长避开或跳出局部最优解。