本文介绍了 Twilio Segment 团队将服务端事件转发基础设施从微服务架构迁移为单体架构的实践,介绍了迁移的背景、权衡和需要考虑的方面。原文:Goodbye Microservices: From 100s of problem children to 1 superstar
微服务是一种面向服务的软件架构,通过结合多种单一用途、低占用的网络服务构建服务端应用,其宣称的好处包括改进模块化、降低测试负担、更好的功能组合、环境隔离以及开发团队自主性。相反,单体架构将大量功能集中在单一服务中,作为整体进行测试、部署和扩展。
Twilio Segment 早期就采纳了这一做法,这在某些情况下很有帮助,但我们很快发现,在另一些情况下则不那么理想。
在 Twilio Segment 早期,产品的核心部分(segment.com/product "Twilio Segment Product "产品的核心部分")达到了临界点,感觉就像是从微服务的大树上掉了下来,撞上了每一根树枝。小团队不仅没有让我们加快速度,反而陷入了爆炸式增长的复杂性中,微服务架构的优势变成了负担。随着速度骤降,缺陷率爆炸式增长。
团队最终发现无法取得进展,三名全职工程师大部分时间都在维持系统的运转。必须做出改变,本文讲述了团队如何后退一步,采纳了一种产品需求和团队需求高度契合的方法。
微服务为何有效
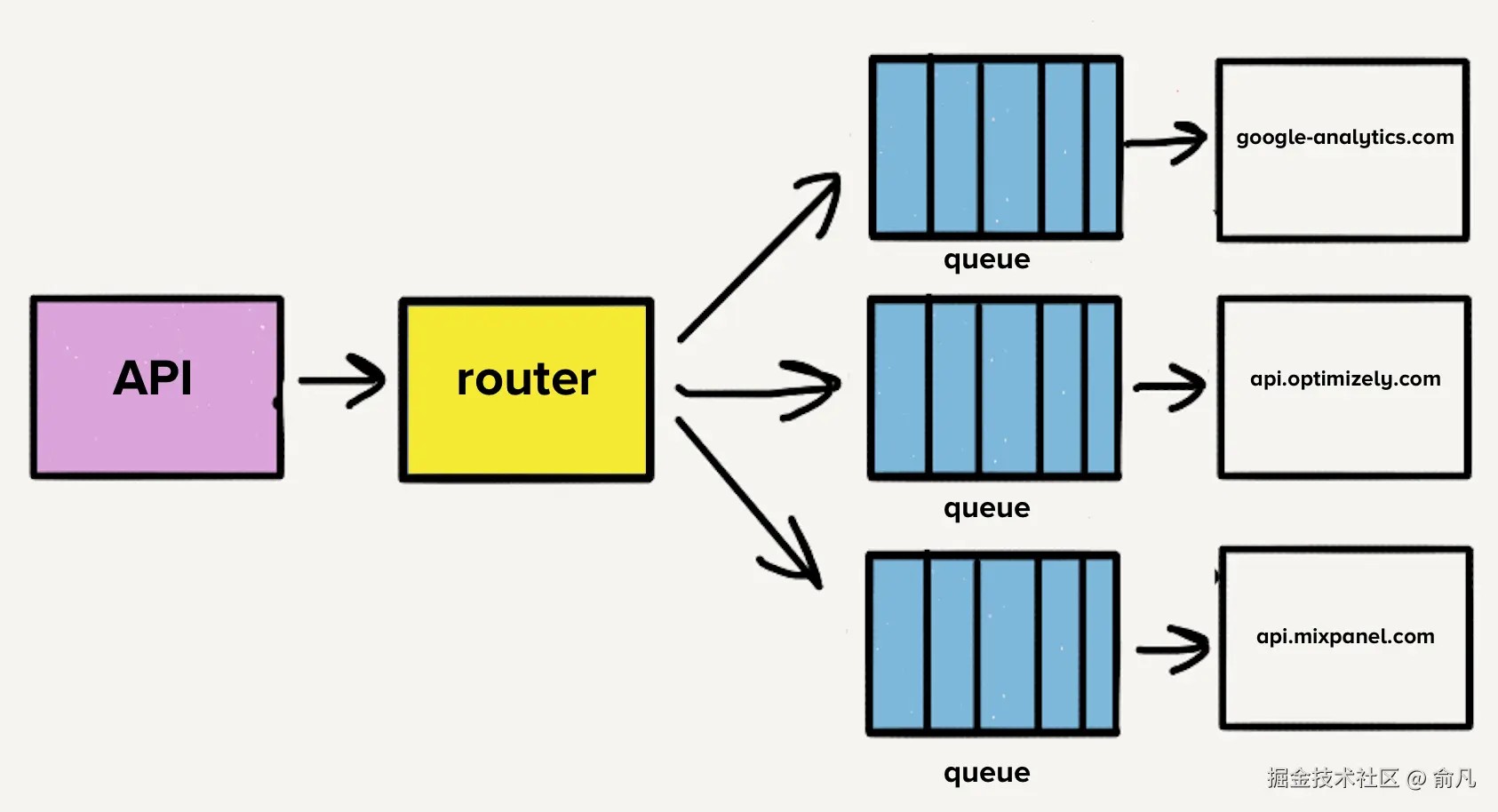
Twilio Segment 的客户数据基础设施每秒接收数十万事件,并将其转发到合作伙伴 API,也就是 服务器端目的地 。这些目的地有一百多种类型,比如 Google Analytics、Optimizely,或自定义 Webhook。
多年前这款产品刚推出时,架构非常简单,有一个可以导入事件并将其转发到分布式消息队列的 API,事件是由网页或移动应用生成的 JSON 对象,包含用户及其操作信息。
消费队列中的事件时,会检查客户设置以决定哪些目的地应接收该事件,随后将其依次发送到每个目的地 API。这很方便,因为开发者只需将事件发送到单个端点 ------ Twilio Segment 的 API,而无需对每一个都构建集成,Twilio Segment 会负责向每个目标端点发送请求。
如果某个请求失败,有时会在稍后尝试再次发送该事件。有些失败可以安全重试,而有些则不行。可重试错误是指目标方可能接受的错误,并且不需要更改请求。例如,HTTP 500、速率限制和超时。不可重试错误是指我们可以确定目的地永远不会接受的请求。例如,无效凭证或缺少必填字段的请求。

上图展示了队列包含最新事件以及可能的多次重试事件,涵盖所有目的地,导致 队列头阻塞(head-of-line blocking)。也就是说,在这种情况下,如果某个目的地变慢或宕机,重试会淹没队列,导致所有目的地都出现延迟。
想象一下,目的地 X 出现了临时问题,每个请求都会出错并超时。这不仅会造成大量尚未到达目的地 X 的请求积压,而且每个失败事件都会被重新放回队列中重试。虽然系统会根据负载自动扩容,但队列深度的突然增加会超过扩容能力,导致最新事件延迟。由于目的地 X 发生了短暂停机,造成所有目的地的发送时间都会增加。客户依赖交付的及时性,因此我们不能承受流水线中任何等待时间的增加。

为了解决队列头阻塞问题,团队为每个目的地创建了独立的服务和队列。该新架构包含一个额外的路由进程,接收入站事件并将事件副本分发到每个选定的目的地。如果一个目的地出现问题,只有对应队列会积压,其他目的地不会受到影响。这种微服务式架构将目的地彼此隔离开来,这在某个目的地出现问题时至关重要。
独立仓库的理由
每个目标 API 使用不同请求格式,需要自定义事件转换代码以匹配该格式,例如目的地 X 需要在负载中发送 birthday 作为 traits.dob,而我们的 API 则接受 traits.birthday。
许多现代目标端点采用了 Twilio Segment 的请求格式,使得某些转换相对简单。然而,转换也可能非常复杂,完全取决于目标 API 结构。例如,对于一些较老且规模很大的目的地,需要将数值塞入手工拼接的 XML 负载中。
最初,当目的地被划分为独立服务时,所有代码都存放在同一个仓库中。一个很大的问题是,如果某个测试失误导致所有目的地的测试都失败,当我们想部署变更时,即使这些失败与变更无关,我们也得花时间修复那个坏掉的测试。针对这一问题,团队决定将每个目的地的代码拆分到各自仓库中。由于所有目的地都已划分为独立的服务,因此这一过渡相当自然。
拆分到不同仓库让团队能够轻松隔离目标测试套件,这种隔离性使开发团队能够快速维护目的地。
扩展微服务和仓库
随着时间推移,我们新增了 50 多个目的地,也就是新增了 50 多个仓库。为了减轻开发和维护代码库的负担,我们创建了共享库,让通用转换和功能(如 HTTP 请求处理)可以在各目的地之间更简单、更统一的共享。
例如,如果我们想获取某个事件中的用户名,可以在任意目的地的代码中调用 event.name()。共享库会检查事件中的属性键名和名称,如果没有,就会检查 firstName、first_name 和 FirstName 这些属性。对姓氏的检查也一样,然后将两者合并成全名。
共享库让新目标的构建变得更快,统一的共享功能带来的熟悉感让维护工作不再那么麻烦。
然而新问题开始出现。对共享库的测试和部署变更影响了所有的目的地,维护起来需要大量时间和精力。为了改进库而做出的变更,必须测试和部署数十项服务,是一项风险极高的举动。在时间紧迫时,工程师只会将这些库的更新版本纳入单一目标代码库。
随着时间推移,共享库的版本开始在不同目标代码库中出现分裂,曾经的巨大好处开始逆转,最终不同服务都使用了共享库的不同版本。我们本可以开发自动化推送变更的工具,但此时不仅开发者生产力下降,我们还开始遇到微服务架构的其他问题。
另一个问题是,每个服务都有独特的负载模式。有些服务每天处理少量事件,而另一些则每秒处理数千事件。对于处理少量事件的目的地,在遇到意外负载激增时,运维人员必须手动扩大服务规模以满足需求。
虽然实现了自动扩展,但每个服务对 CPU 和内存资源的需求差异很大,使得调整自动扩展配置更像是艺术而非科学。
目的地数量持续快速增长,团队平均每月新增三个目的地,这意味着更多的仓库、更多的队列以及更多的服务。由于微服务架构,运维开销随着每个目的地的增加而线性增长。因此,我们决定后退一步,重新思考整个流程。
放弃微服务和队列
首先考虑的是将现已超过 140 个的微服务整合为单一服务。管理所有这些服务的开销对团队来说是巨大的负担。我们甚至无法睡觉,值班工程师经常被叫起来处理负载激增。
然而,当时的架构使得迁移到单一服务变得具有挑战性。如果每个目的地有独立队列,每个员工都必须检查每个队列的工作,这会给目的地服务增加复杂性,我们对此感到不放心。这正是 Centrifuge 的主要灵感来源,Centrifuge 将替换所有单独队列,负责将事件发送到单一服务。(注意,Centrifuge 成为了 Connections 的后端基础设施。)

单体仓库迁移
鉴于只有一个服务,将所有目标代码迁移到一个仓库中是合理的,这意味着将所有不同的依赖和测试合并到一个仓库中。
对于 120 个独特依赖,我们承诺为所有目的地提供一个版本。当我们迁移目的地时,会检查它使用的依赖,并更新到最新版本,并修复出现问题的目的地。
通过这次迁移,我们不再需要追踪依赖版本之间的差异,所有的目的地都使用同一个版本,大大降低了整个代码库的复杂性。维护目的地变得更省时、风险更低。
我们还希望有一个测试套件,能够快速轻松的运行所有目的地测试,而运行所有测试是之前更新共享库时的主要障碍之一。
幸运的是,目的地测试的结构都比较相似,有基本的单元测试来验证自定义转换逻辑是否正确,并会向合作伙伴端点执行 HTTP 请求,以验证事件是否如预期出现在目的地。
回想一下,最初将每个目标代码库分开到独立仓库的动机是为了隔离测试失败。然而,事实证明这是一种虚假的优势,发送 HTTP 请求的测试仍然经常失败。目的地被分开到各自的仓库,几乎没有动力去清理失败的测试。这种糟糕的习惯导致技术债务持续堆积,通常本应只需一两个小时的小变更,最终却需要几天到一周时间才能完成。
构建强韧的测试套件
测试运行期间向目标端点发出的 HTTP 请求是测试失败的主要原因。像过期证书这样无关的问题不应该让测试失败。我们也从经验中知道,有些目的地端点比其他端点要慢得多。有些目的地的测试时间长达 5 分钟。我们的测试套件覆盖 140 多个目的地,运行时间可能长达一小时。
为了解决这两个问题,我们基于 yakbak 创建了 Traffic Recorder,负责记录和保存目的地的测试流量。每个测试首次运行时,所有请求及其对应的响应都会被记录到文件中。在后续测试中,文件中的请求和响应会被回放,而不用请求目标端点。这些文件会被记录在仓库中,确保每次变更的测试保持一致。现在测试套件不再依赖互联网上的 HTTP 请求,使得测试更有弹性,成为迁移到单一仓库的必备条件。
在集成 Traffic Recorder 后,完成所有 140 多个目的地的测试只需要几毫秒。而以前单单完成一个目的地的测试可能都需要几分钟时间。
为什么单体有效
一旦所有目的地代码都集中在一个仓库中,就可以合并成一个服务。随着每个目的地都集中在同一服务中,开发者生产力大幅提升。我们不再需要为某个共享库的变更部署 140 多个服务,一名工程师可以在几分钟内就完成部署。
变更速度也证明了这一点。在微服务架构时期,我们对共享库进行了 32 项改进。而在迁移为单体架构一年后,我们已经做了 46 项改进。
这一变化也优化了我们的运维。由于每个目的地都集中在一个服务中,使得 CPU 和内存密集型的目的地被良好组合在一起,从而让服务扩展更加容易。庞大的算力池能吸收负载峰值,因此团队不需要半夜被叫起来处理问题。
权衡
从微服务架构转向单体架构带来了巨大进步,但也需权衡利弊:
-
错误隔离很难。由于所有功能都运行在单体中,如果某个目的地出现了导致服务崩溃的 bug,所有目的地的服务都会崩溃。我们有全面的自动化测试,但测试只能做到一定程度。我们目前正在研发一种更为强大的方法,防止一个目的地造成整个服务瘫痪,同时保持所有目的地的整体状态。
-
内存缓存效果较差。此前,每个目的地只提供一项服务,低流量目的地只有少数进程,意味着它们的内存缓存会保持控制平面数据的活跃状态。现在缓存分散在 3000 多个进程中,被命中的可能性大大降低。我们可以用 Redis 之类的工具来解决这个问题,但那又是另一个需要考虑的扩展点。最终,鉴于运维带来的显著收益,我们接受了效率的损失。
-
更新依赖版本可能会导致多个目的地被破坏。虽然把所有东西迁移到一个仓库解决了之前的依赖问题,但意味着如果我们想使用最新版本的库,可能需要更新其他目的地以配合新版本。不过我们认为,值得为这一简单性付出代价。借助全面的自动化测试套件,我们可以快速查看新版本依赖中存在的问题。
结论
最初的微服务架构曾经有效,通过隔离目的地解决了当时流水线的性能问题。但是随着规模扩大,当需要批量更新时,缺乏合适的工具来测试和部署微服务。结果,我们的开发者生产力迅速下降。
转向单体架构让我们摆脱了流程中的运维问题,同时显著提升了开发者生产力。不过这个转变绝非轻率,如果想要成功,必须考虑一些因素。
- 需要坚实可靠的测试套件,把所有东西放进一个仓库。没有这些,我们会陷入当初决定分开他们时同样的境地。过去不断的测试失败影响了工作效率,我们不希望这种情况再次发生。
- 接受单体架构固有的利弊,并确保权衡了两者的优劣,我们必须接受变化带来的一些牺牲。
在选择微服务还是单体架构时,需要考虑不同的因素。在我们基础设施的某些部分,微服务运行良好,但我们的服务器端目的地恰好说明了这一流行趋势实际上会损害生产力和性能。事实证明,适合我们的解决方案是单体架构。
Hi,我是俞凡,一名兼具技术深度与管理视野的技术管理者。曾就职于 Motorola,现任职于 Mavenir,多年带领技术团队,聚焦后端架构与云原生,持续关注 AI 等前沿方向,也关注人的成长,笃信持续学习的力量。在这里,我会分享技术实践与思考。欢迎关注公众号「DeepNoMind」,星标不迷路。也欢迎访问独立站 www.DeepNoMind.com,一起交流成长。