CDP任务流配置
ADF(Azure Data Factory)是 Azure 云平台上的数据集成与工作流编排工具,核心功能是帮你把分散在不同地方的数据、任务串成自动化流程,不用写大量代码就能实现 "数据搬运 + 任务调度 + 依赖管理"。
用大白话讲,ADF 就像一个 "数据任务总指挥",主要干这几件事:
- 数据搬运:跨源数据同步 / 转换
跨系统搬数据:能把数据从数据库(MySQL/SQL Server)、存储(Blob/S3)、API、大数据平台(HDFS/Databricks)等几十种源,搬到目标存储 / 数据库里(比如从 MySQL 同步到 Data Lake)。
数据清洗 / 转换:支持用 "数据工厂管道" 做简单清洗(比如字段映射、格式转换),也能调用 Databricks/Spark 做复杂计算。 - 任务编排:串起所有任务的执行顺序
依赖管理:像你现在做的 ------ 让 "数据清洗最后一个 Job"→"后端任务"→"大数据任务" 按顺序执行,用 "活动依赖"(蓝色箭头)就能可视化配置。
循环 / 分支逻辑:支持 Until(循环查状态)、If Condition(满足条件才执行某任务)等逻辑,不用写代码实现复杂流程。 - 调度与监控
定时触发:可以设置 "每天凌晨 2 点自动跑整个流程",不用手动启动。
运行监控:能看每个任务的执行状态(成功 / 失败)、耗时、日志,失败了还能自动重试 / 发告警。 - 无缝对接 Azure 生态
直接调用 Databricks Job、Azure Function、Synapse Analytics 等服务,不用额外写集成代码。
简单说:ADF 是 "无代码 / 低代码" 的工具,帮你把数据相关的 "搬运、清洗、任务执行" 打包成自动化流水线,不用自己搭调度系统(比如 Airflow),直接用云服务搞定。
CDP 打标签圈人群任务依赖于后端抽取每天的新数据到datalake,后端抽取数据的任务依赖于ETL Job。这个时候我们就可以利用ADF能做任务变拍的特点来处理这个调度。
ETL 有很多job,已经配置完自身的任务流,但是这个任务流太长,为了将CDP任务与ETL任务隔离,我就将CDP任务配置做成了一个新的任务流。后端服务器上有脚本检测ETL任务完成后在执行后端的任务,后端任务之行完毕后往数据库的表中加入一条数据
步骤一: 建立ADF
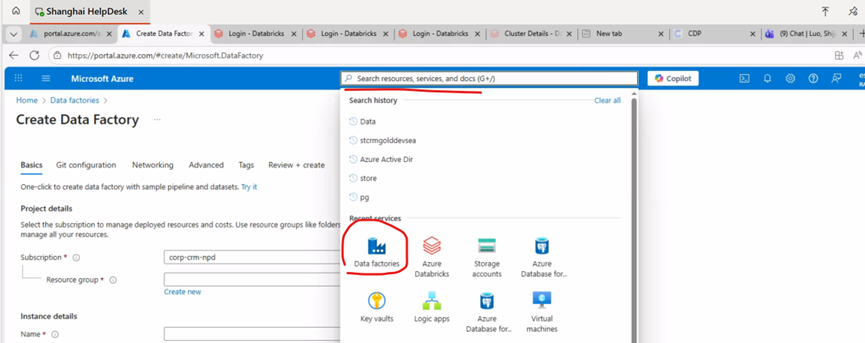
登录 Azure 门户,搜索栏搜索Data factory,选择create后设置Resource group(资源组)、Name(ADF 名称)、Region(区域)。注意Name需要唯一,Region需要跟调度的job在同一个区域
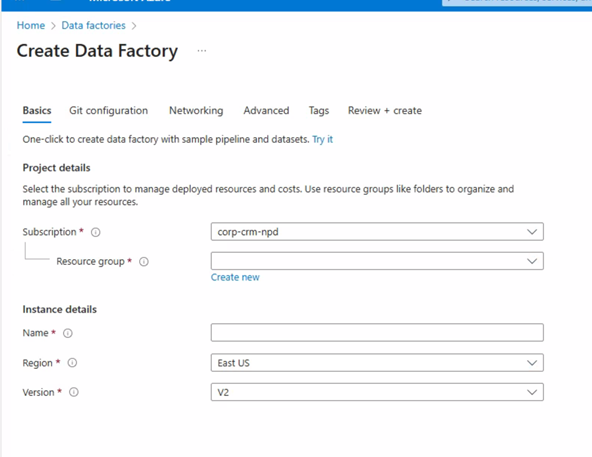
步骤二:配置pipelines
登录https:adf.azure.com , 选择刚才创建的ADF,选择Pipelines 创建管道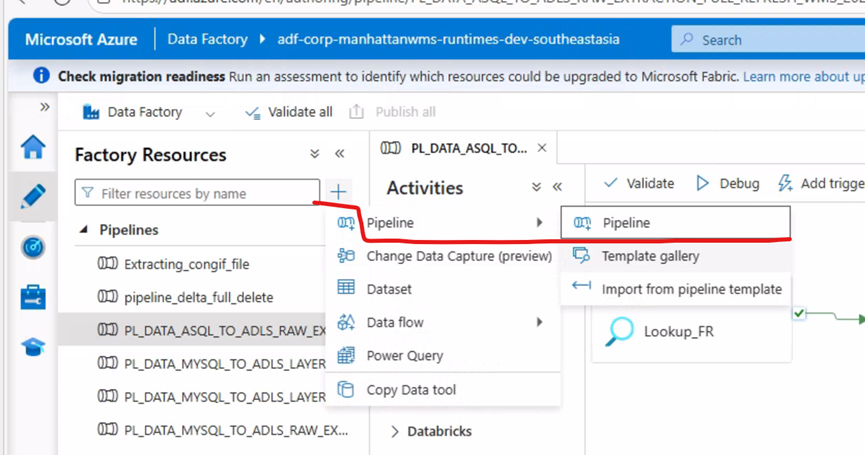
**步骤三:利用Unit和lookup **
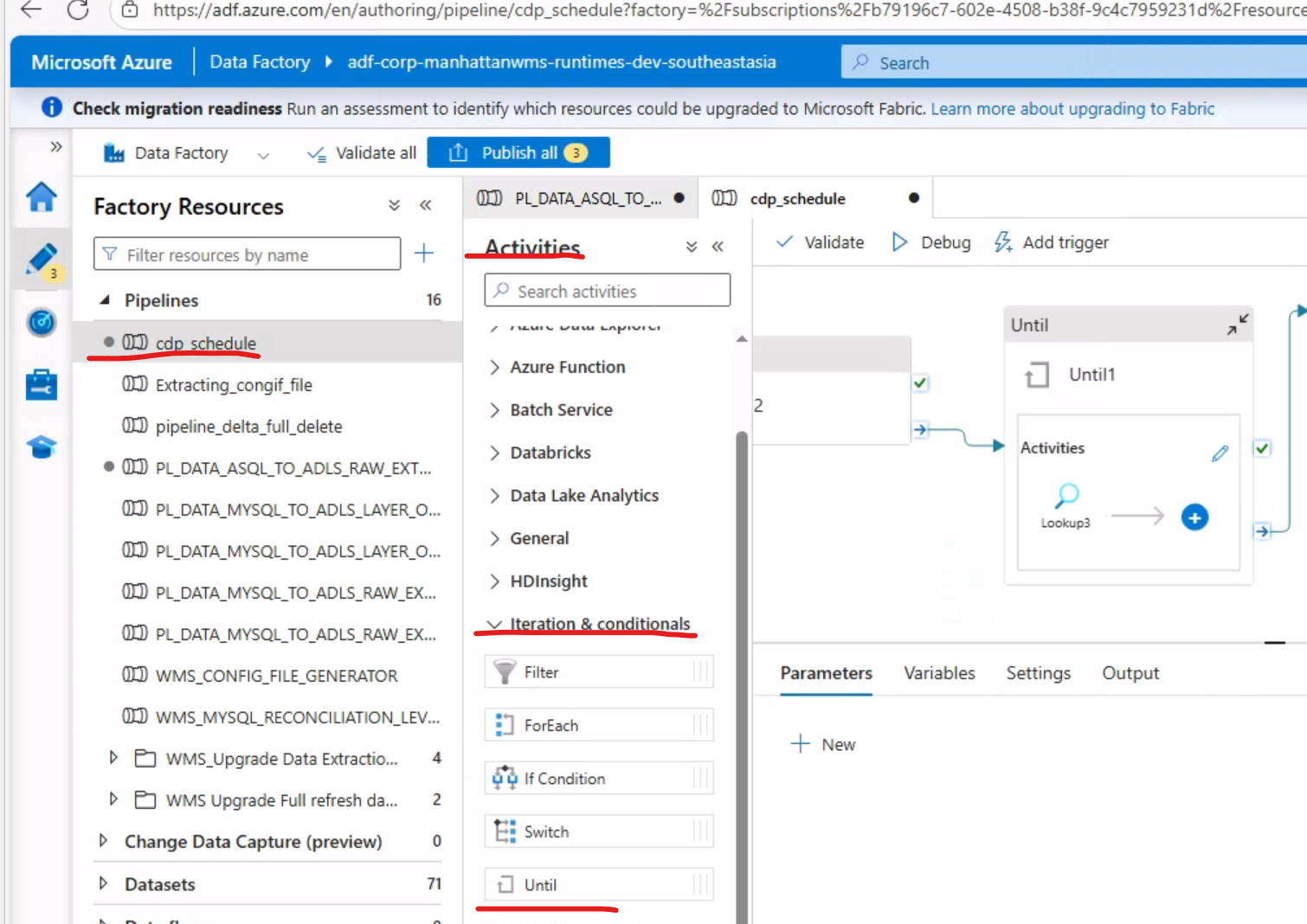
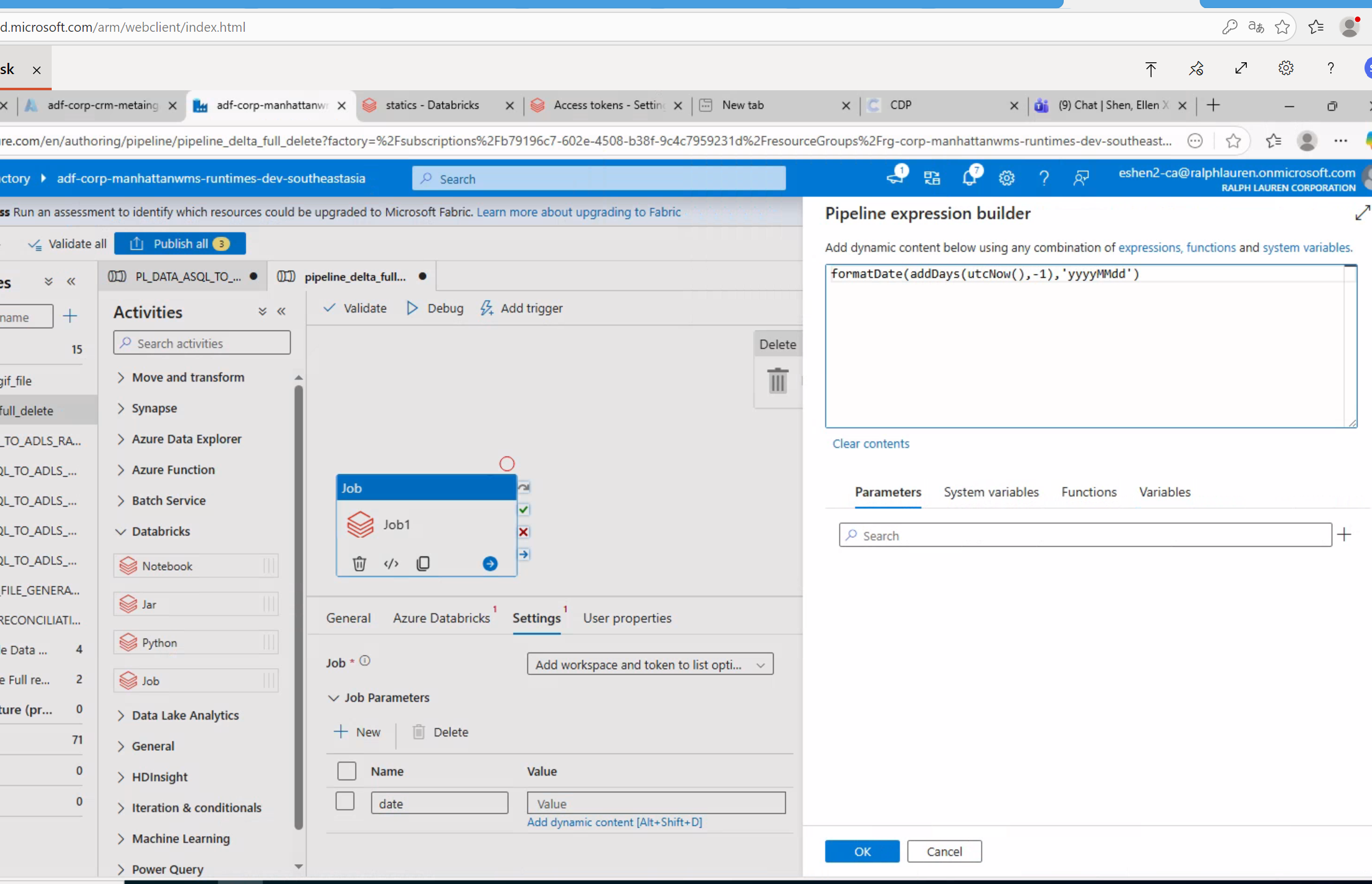
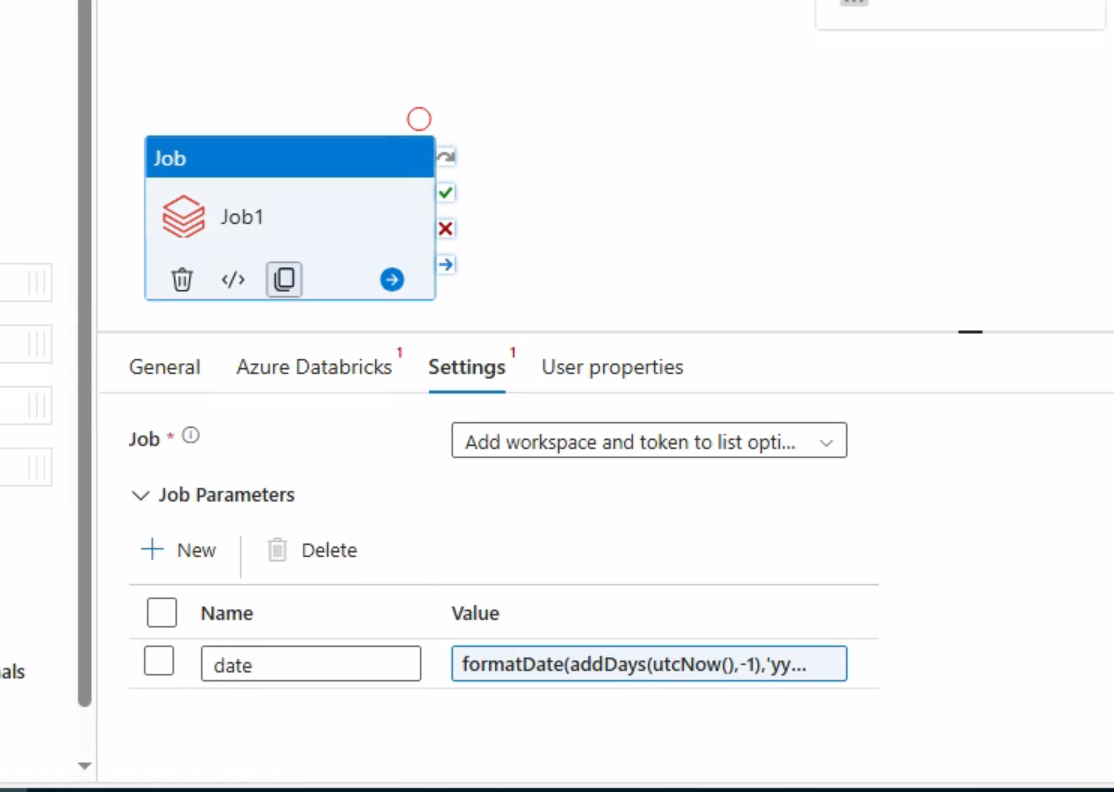
Unit中添加LookUp (后端任务执行完毕后,往postgre sql 数据库中表A写入一行数据,数据时间为当天pt,故此处采用LookUp查询数据是否存在)
配置LookUp。LookUp中要查询表中数据,股需要配置相应的Linkservice 。
Lookup中用到的Linkservice 配置: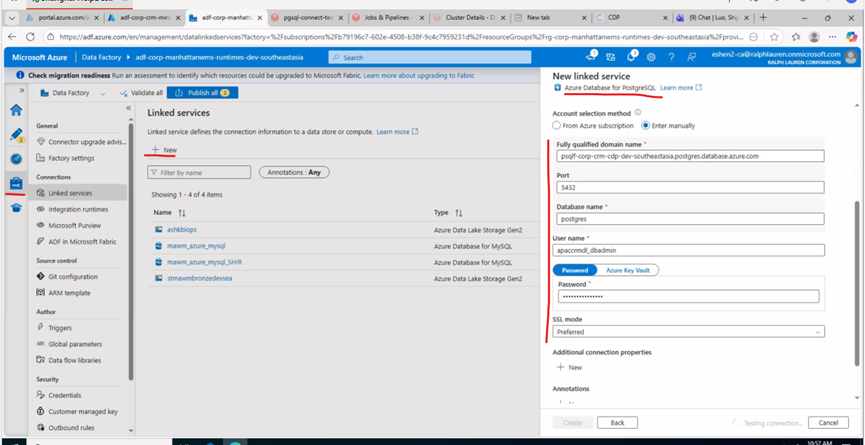
Linkservice 配置结束后再配置Unit中LookUp
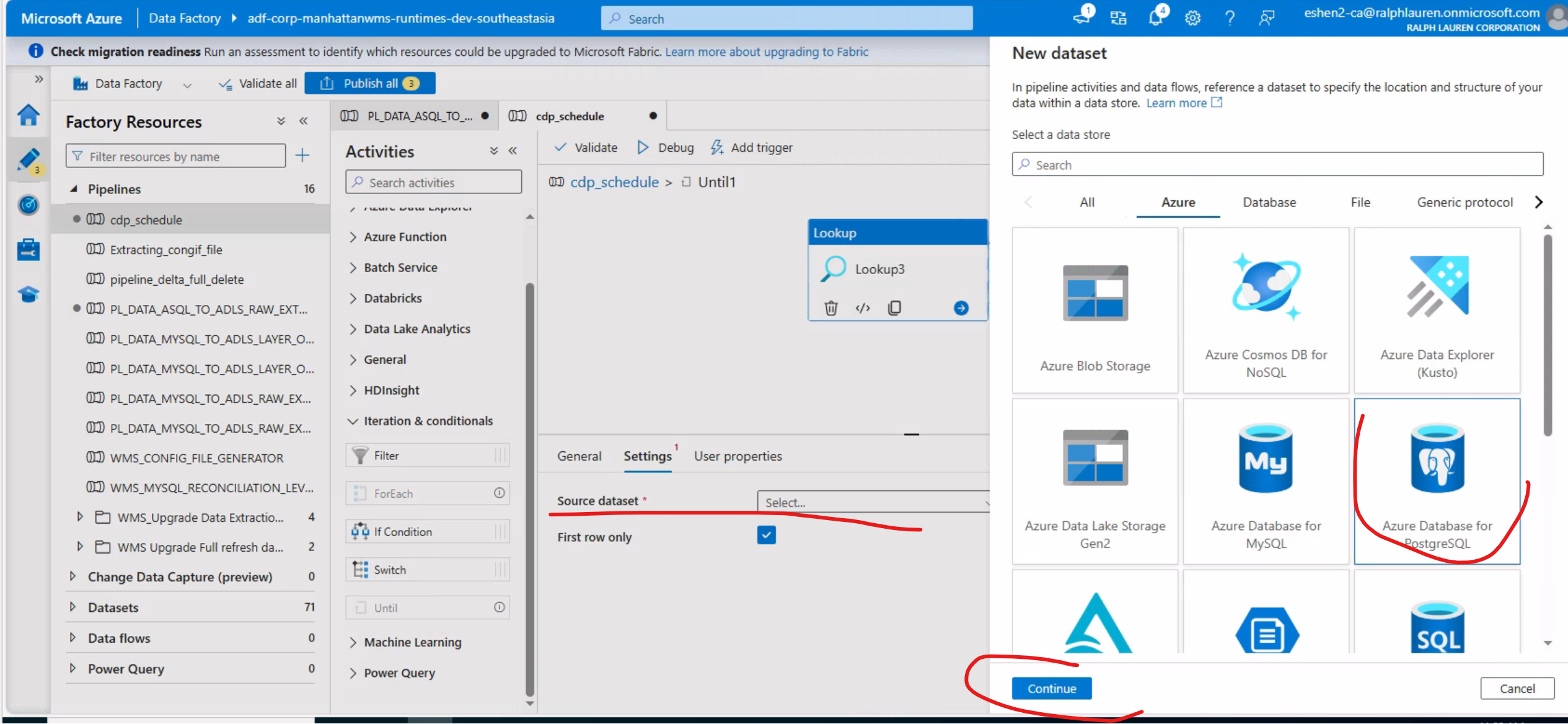
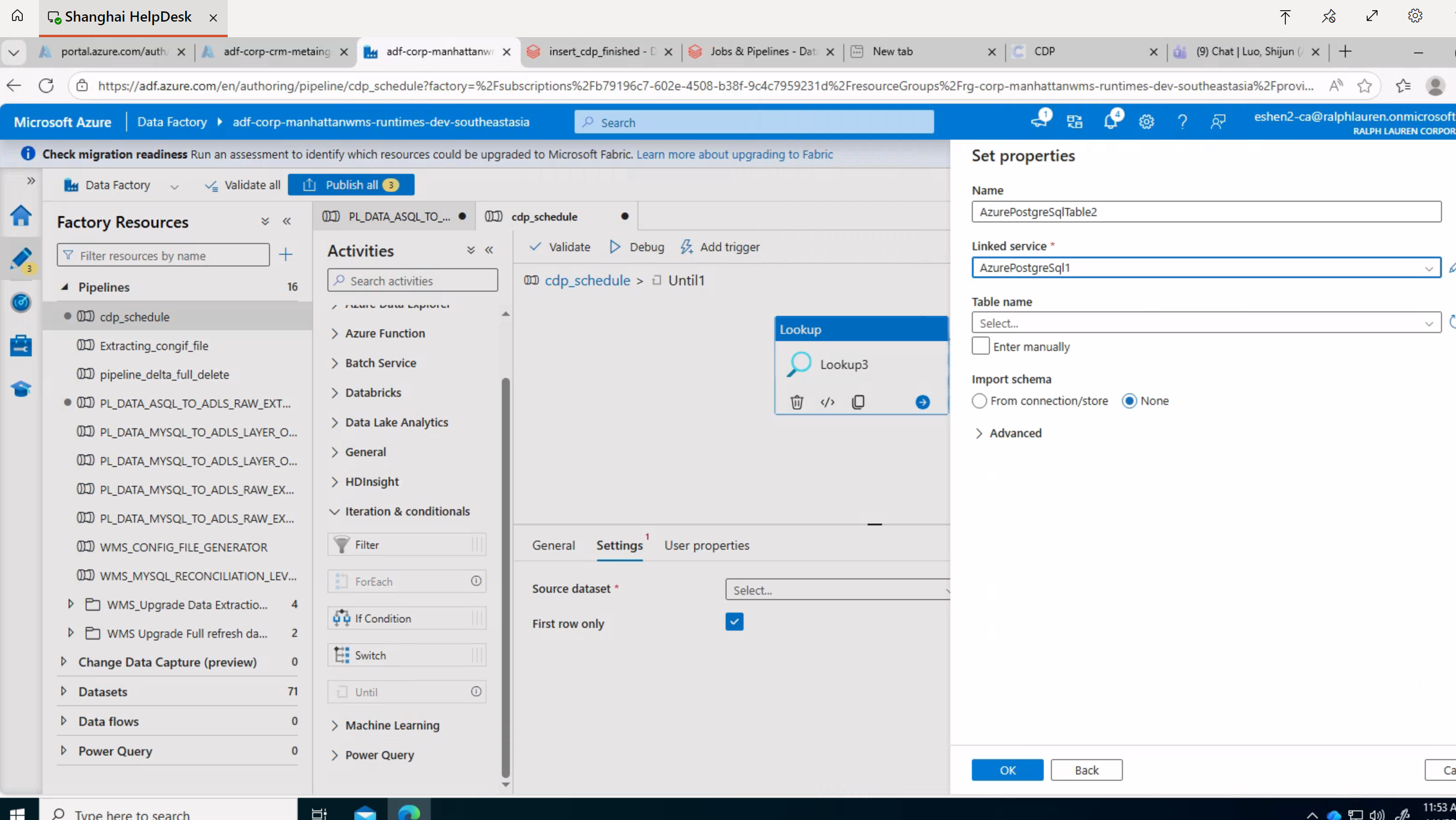
选择table 或者手动输入后再点击OK。接着配置查询语句
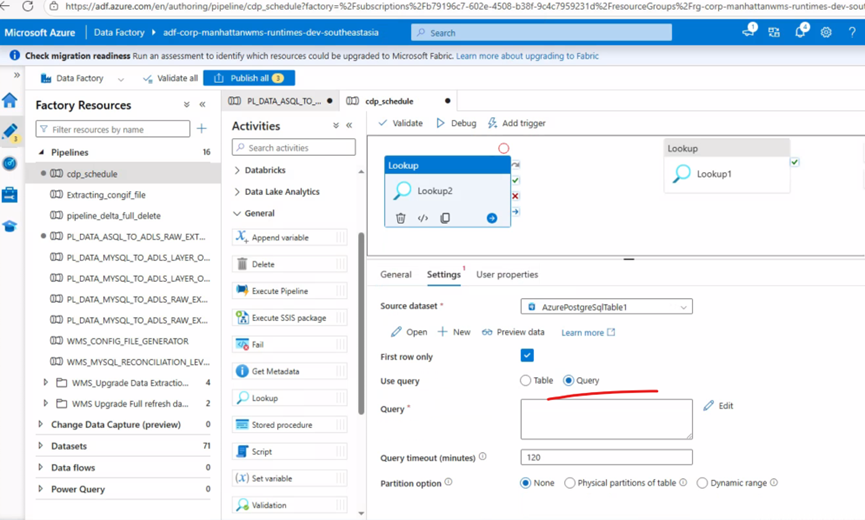
步骤四:加上databricks job 完成任务流配置
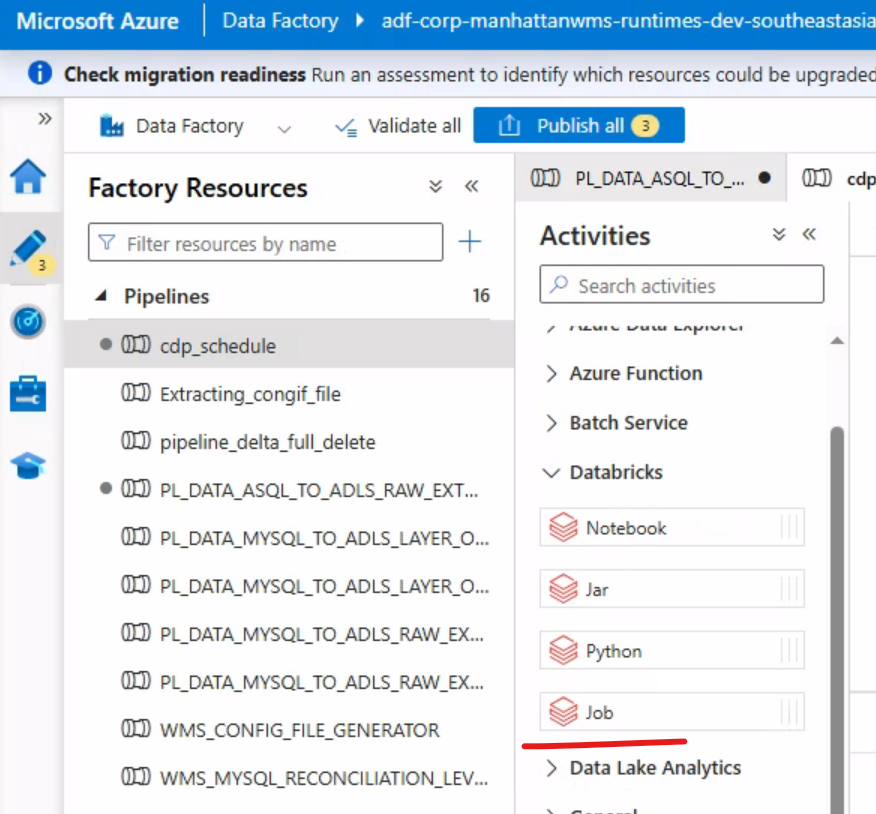
将job拖到画布中,然后针对job配置Azure Databricks 和 Job
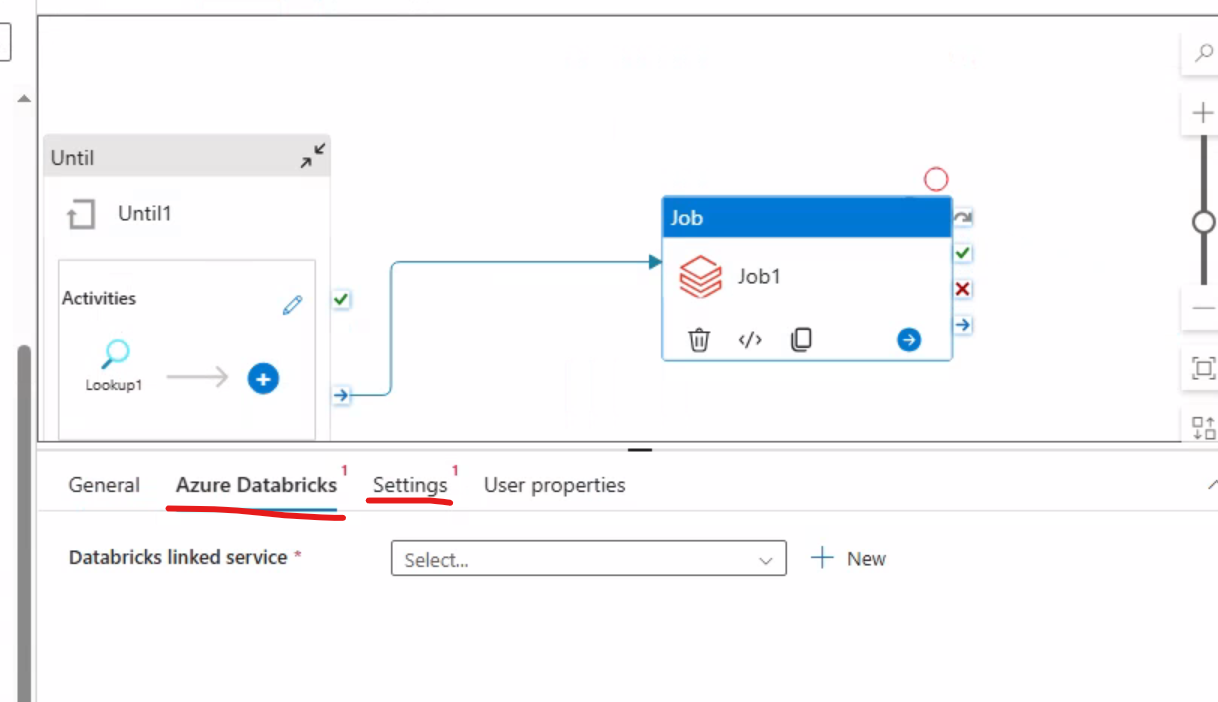
选中Job和Unit,将Unit蓝色小箭头跟Job连接起即可。
步骤五:验证和发布 点击画布上方的 "Validate" 按钮,验证 Pipeline 配置是否有错误;验证通过后,点击 "Publish all" 保存所有配置。任务发布后需要配置触发条件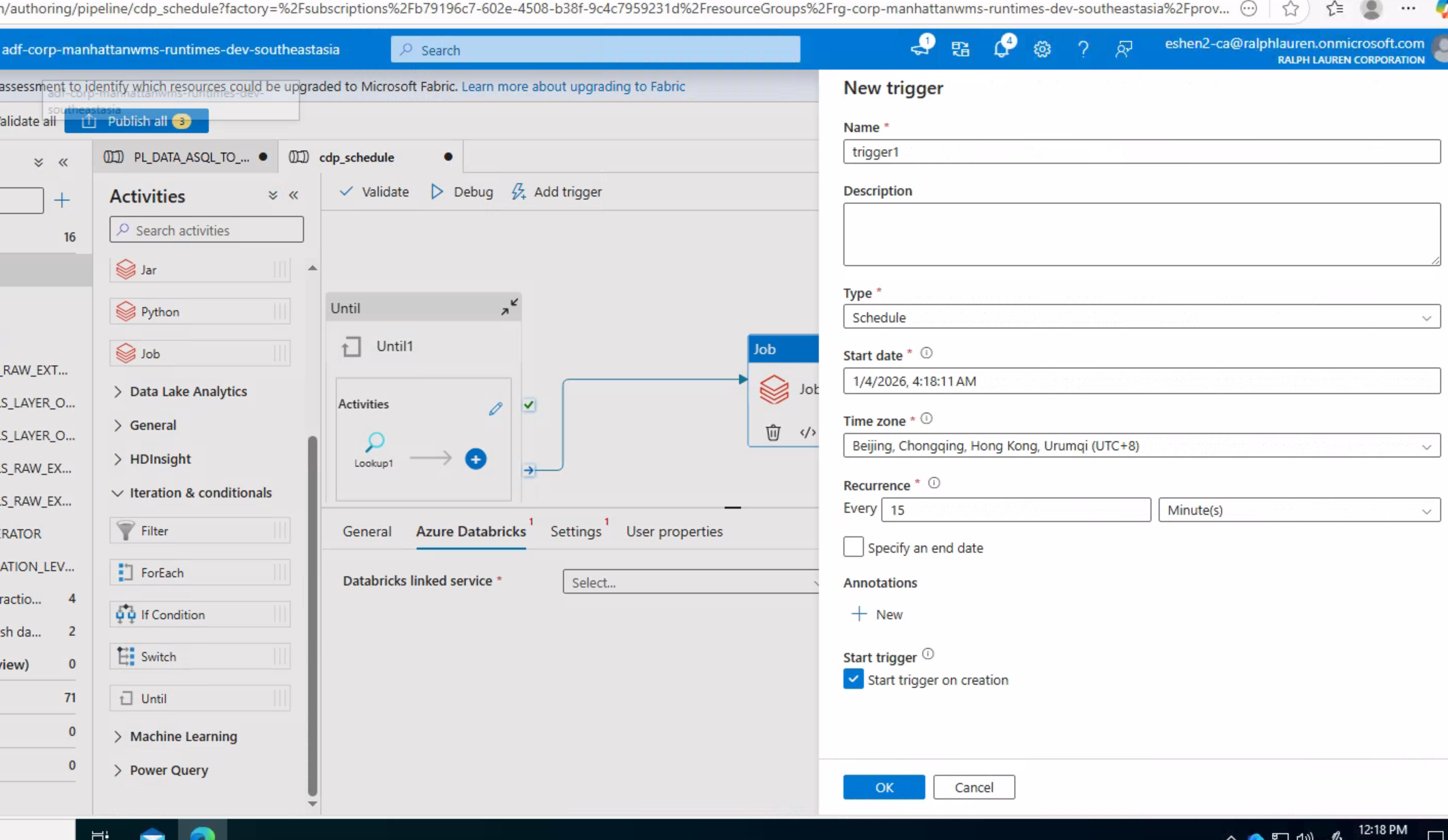
更优方案:
将后端任务也加入ADF。鉴于我现在用的ADF是旧版,没有SSH,故只能通过web轻量服务来调用后端的脚本。
步骤 1:在后端服务器部署轻量 API(以 Python Flask 为例)
安装Flask
powershell
pip install flask后端服务器上新建script_api.py:
python
from flask import Flask
import subprocess
app = Flask(__name__)
# 定义接口:调用你的脚本
@app.route('/job_combine.sh', methods=['GET'])
def run_script():
# 替换为你的脚本路径
script_path = "/home/cdp/job_combine.sh"
# 执行脚本(异步执行,避免ADF超时)
subprocess.Popen(["sh", script_path])
return "Script started successfully", 200
if __name__ == '__main__':
# 开放端口(确保服务器防火墙允许8080端口)
app.run(host='0.0.0.0', port=8080)后端启动脚本
powershell
nohup python3 script_api.py &步骤 2:在 ADF 中配置 Web 活动
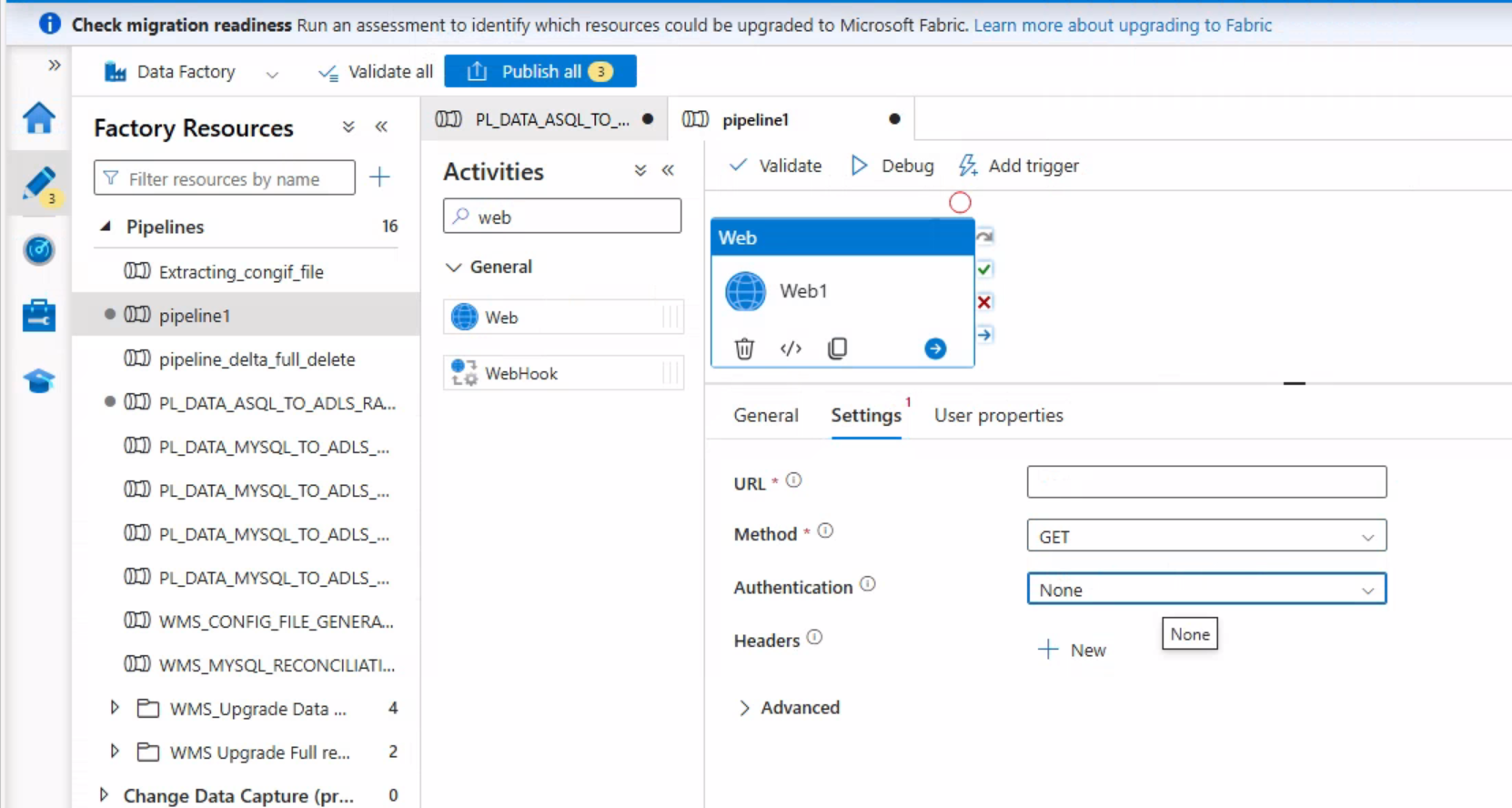
URL:填写后端服务器的 API 地址(比如http://后端服务器IP:8080/job_combine);
Method:选择 "GET"
将之前的Unit任务删除,将web跟cdp 其他job 连接起来即可。如果cdp job 也要接受可变传参,那么也可用web方式来处理。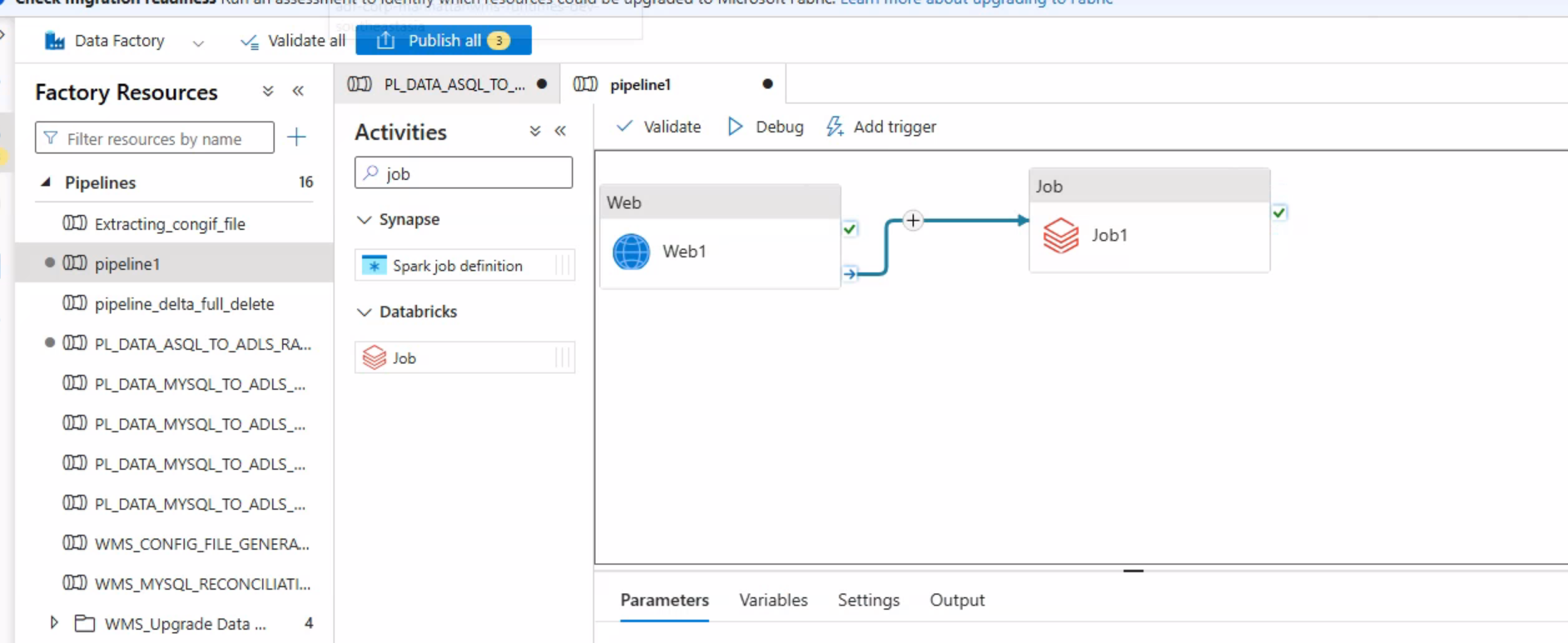
如果Job中也需要可变参数,则需要在 Databricks Job 的Parameters中,把可变传参改成占位符(比如先写成"--date", "PLACEHOLDER_DATE")
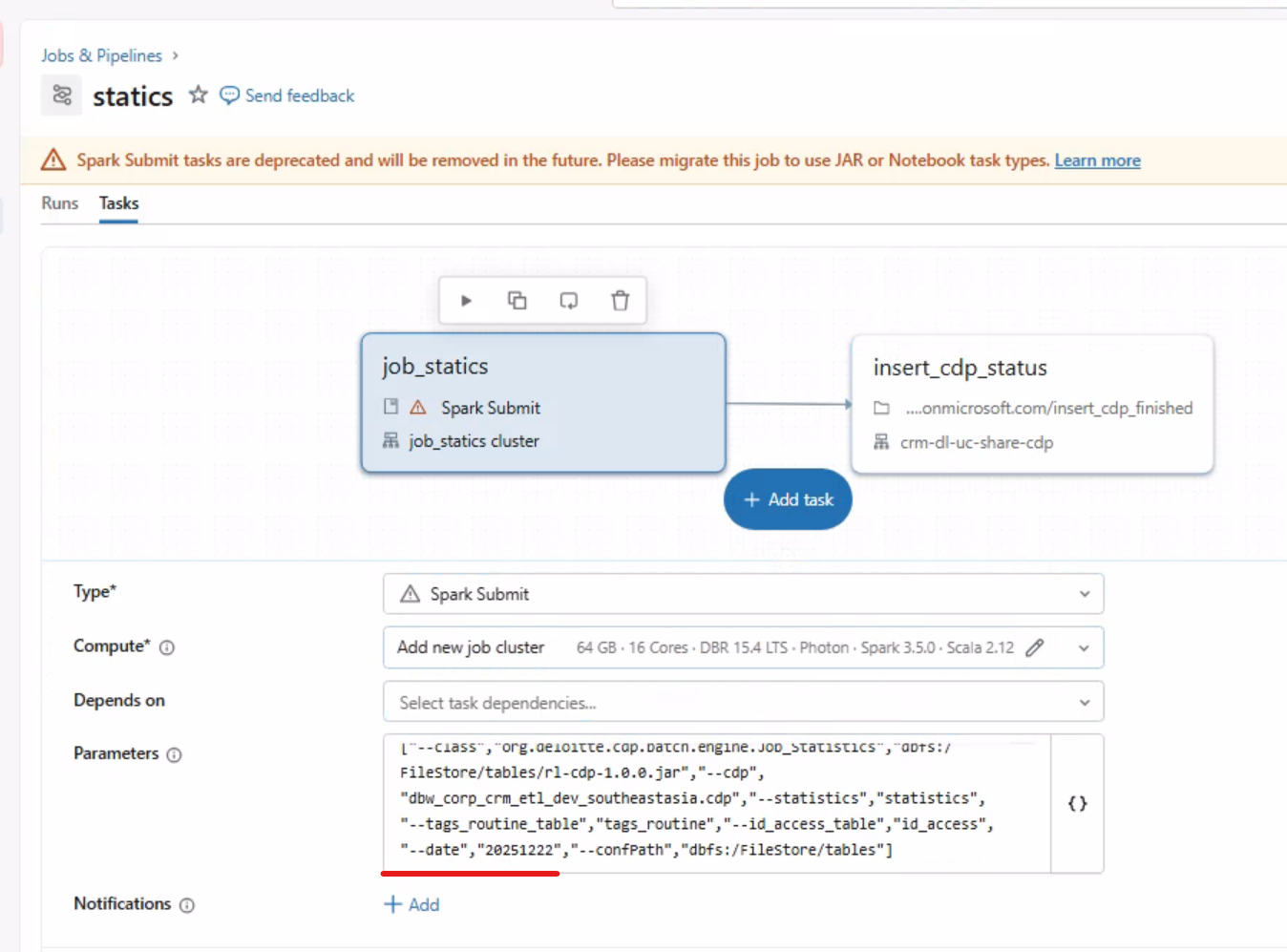
然后在ADF的pipeline的job 的setting中设置动态传参