1.读写分离带来的问题及解决方法
1.1 延时问题
主从复制,主库与从库之间由于网络,设备差异,负载情况等,必然存在延时,延时有大有小,只要延时保持再一个合理的范围内是可以接受的。
1.1.1造成主从延时的参见原因
-
主从设备差异:例如主库性能较好,从库性能较差,对于同样的写入或更新操作,主库能较快完成,从库花费时间较多,如果系统持续维持高频的写入更新,主库与从库之间的差异会被逐渐拉大。导致主从的延迟越来越大。对于这种情况,需要尽量保证主从服务器性能一致,使得两种处理相同量的数据花费的时间尽可能接近。这样一般情况而言主从延时可以保证在一个合理范围,不会出现很大的差异。
-
从库上执行了过多任务:由于从库是只读的,加上相比于主库而言重要性没那么高,所以其他系统可能会从库进行大量的数据同步或分析业务,导致从库被占用过多资源,处理从主库同步过来的日志较慢,造成了延迟。此时需要注意从库的压力,考虑负载均衡或采用其他方式使得从库负载不要太高,造成较长延迟。
-
大事务:如果主库执行一个要更新或删除大量数据的SQL,例如主库都需要执行20s.那么对于语句或数据(取决于binlog格式)复制到从库,从库也需要执行20s.这样主从之间就天然的存在一个延迟,这个延时由事务的执行时间决定。所以需要避免大事务,开发过程中就需要注意,同时需要添加监控,对于执行情况进行监控预警。
提高从库复制性能的方法:从库的io线程通过读取主库的日志,然后sql线程将读取日志内容执行,如果执行sql的线程是单线程执行效率会偏低。主库写入时是可以并发写入的,如果从库执行采用多线程执行,可以提高从库的复制效率降低延迟。MySQL会判断可以并发执行的部分语句使用多个线程并发执行。
1.2 读写分离的挑战:读一致性
主从的延迟总会存在,那么一个操作写入主库,此时从从库读取数据,可能读到可能读不到,这取决于从库的延迟以及读取的时机。如果主从延迟大于,写入主库与读取从库的间隔,那么读取的从库就不会存在这次写入操作。反之就可以读取到这次写入操作。这两种情况存在一定的随机成分,例如用户写入主库后,很快进行了读取,可能这次读取的从库没有当前的写入数据。如果用户隔了一段时间才读取,这次可能可以在从库中读取对于的操作。由此引发了读一致的问题,有些操作可以接受一定程度的延迟,有些操作不能接收延迟,需要保证写后立即可见。
1.2.1 读之所写
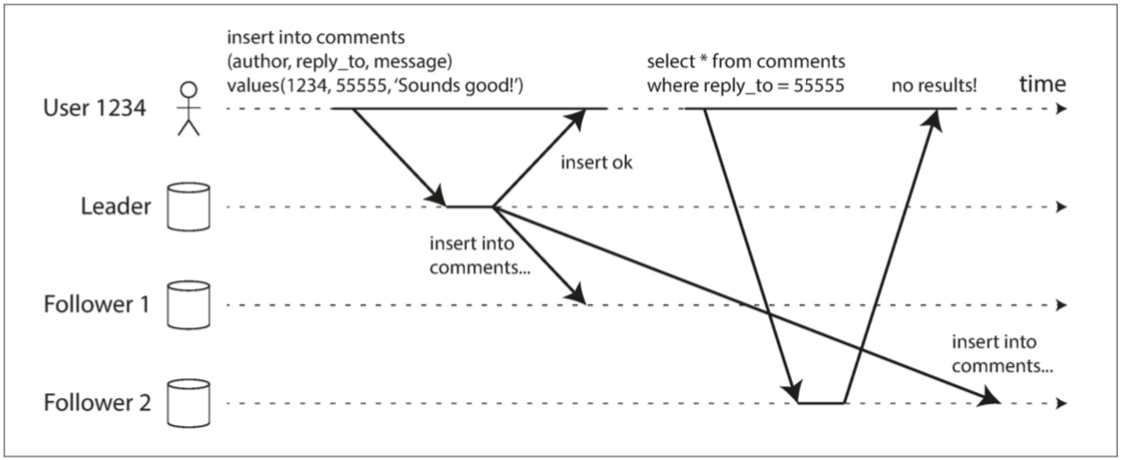
例如用户编辑自己的主页信息,保存后刷新页面获取自己的主页信息。第一个操作是写操作,请求会被路由到主库,第二个操作是读操作会被路由到从库。如果主库与从库之间存在延时,且第二次读取操作的从库还没有及时同步主库的数据,此时就会出现怪异的现象,用户编辑后执行保存,提示保存成功。但他刷新页面,发现页面还是修改前的信息。这显然会对用户造成困扰,或者所一致性被破坏,记录提示了用户保存成功,那么刷新页面读取时应该读取到保存的数据,但实际情况确没有读取到。这种不一致性可能还会导致用户重复操作,造成损失,例如用户执行一个操作提示成功,然后用户查询,发现没有记录刚才的操作,他可能会再次执行这个操作,后续主从同步完毕后,他会查询到两次操作,可他的预期是只进行一次操作。针对用户写入后,需要读取到自己写入的最新数据,这种读一致性称为读己所写。
如何保证读己所写的隔离级别?
-
读主库:简单粗暴直接读主库,如果当前的读操作对一致性要去较高,直接读主库,这次请求肯定保证读的一致性,对于同一个实例就不存在一致性问题了。但其缺点也很明显,读写分离是为了将读操作路由到从库,降低主库负载,使得系统提供更多的吞吐量。如果多数读请求最后还是被路由到了主库,扩展性降低了,大量操作都依赖主库,没有被剥离出来。
-
判断主从点位,选择合适的从库
例如用户写入主库后,当前bindlog的点位是100.执行show slave status;获取从库同步主库的点位信息,如果当前从库的点位信息大于等于主库,那么主库之前的写操作在该从库是可见的。

例如上图,如果主库写入的时的点位小于等于当前从库的点位,那么此次读取操作对之前的写入操作可见。
当然,如果主从延时比较大,例如30s.不可能等到从库同步好之后再查询从库,延时较大情况,指定时间内没有满足条件的从库需要触发降级逻辑,可直接查询主库。同时添加好监控,延时达到上限需要告警,同时统计好路由从库失败被转发到主库的操作,想办法优化对应问题。
当然也不是所有的操作需要读己所写,还需要根据具体业务情况分析。以上例为例,对于用户编辑自己主页信息,对于用户本人来说肯定是需要读己所写的。当对于其他人来说则不需要读己所写,访问其他人的主页,由于自己不可能编辑他人的主页,所以主页的写操作对他人来说是不可见的,此时直接读取从库即可,等待从库同步好对应数据后,才读取最新数据也是可以接受的。这样看读取其他用户的主页似乎没有问题,何时同步好就何时读取最新数据,但是存在多个从库又会带来新的问题,这就是下一节的单调读问题。
1.2.2基于sharding jdbc实现读之所写。
-
基本环境:一主两从基于jdbc。主库3310端口,从库3311,3312端口.
-
实现思路:自定义从库选择算法,如果需要读己所写,将请求路由到合适的从库,如果没有从库符合条件,路由到主库。
-
整体流程:定时Job读取主库从库点位信息记录在Redis中。对于需要记录点位信息的写操作添加注解,写入后记录事务提交时的点位信息读请求添加注解,标识当前请求是否需要读之所写,记录在上下文中。根据当前用户写入操作时记录的点位,选择合适的从库,如果没有符合条件的,降级到主库。
/** * 1.定时Job读取主库从库点位信息记录在Redis中。 * 每500ms刷新主库与库点位信息 * * @throws SQLException */ @Scheduled(fixedRate = 5000) // 每500ms更新一次 public void refreshSlavePositon() throws SQLException { log.info("zookeeper info ={}", JSON.toJSONString(this.zookeeperCurrentVersionInfoHolder)); //写入从库点位 Map<String, Connection> slaveConnection = getSlaveConnection(); slaveConnection.forEach((slaveName, connection) -> { try { log.info("slave={} url={}", slaveName, connection.getMetaData().getURL()); } catch (SQLException e) { throw new RuntimeException(e); } BinlogPosition binlogPosition = this.getSlaveBinLogPoint(connection); redisTemplate.<String, String>opsForHash().put(slavesPositionInfoCachePreKey, slaveName, JSON.toJSONString(binlogPosition)); }); //写入主库点位 Connection masterConnection = getMasterConnection(); log.info("masterConnection url={}", masterConnection.getMetaData().getURL()); BinlogPosition binlogPosition = this.getMasterBinLogPoint(masterConnection); redisTemplate.<String, String>opsForHash().put(slavesPositionInfoCachePreKey, MASTER_DB_NAME, JSON.toJSONString(binlogPosition)); }/**
-
2.对于需要记录点位信息的写操作添加注解,写入后记录事务提交时的点位信息
*/
@Slf4j
@Aspect
@Component
public class CacheUserBinlogPositionAspect {@Autowired
private BinlogPositionService binLogService;@Pointcut("@annotation(com.example.annotation.CacheUserBinlogPosition)")
public void cacheUserMasterPositionCut() {
}@AfterReturning(pointcut = "cacheUserMasterPositionCut()", returning = "result")
public Object cacheMasterPosition(JoinPoint joinPoint, Object result) throws Throwable {
String uid = UserManager.getUid();// 注册事务回调,由于执行到改切面时,事务的切面还没有提交,所以需要注册事务提交后执行获取点位方法,以确保获取提交后的点位信息 TransactionSynchronizationManager.registerSynchronization( new TransactionSynchronization() { @Override public void afterCommit() { // 在事务提交后执行 try { //获取主库点位 BinlogPosition masterDBPosition = binLogService.getMasterBinLogPoint(); //缓存当前用户主库点位 binLogService.cacheUserBinlogPosition(uid, masterDBPosition); } catch (Exception e) { log.error("记录binlog点位失败", e); } } } ); return result;}
}
/**
-
- 读请求添加注解,标识当前请求是否需要读之所写,记录在上下文中。
*/
@Slf4j
@Aspect
@Component
public class ReadConsistencyAspect {
@Pointcut("@annotation(com.example.annotation.ReadSelfWrite)")
public void readSelfWritePointCut() {
}@Before(value = "readSelfWritePointCut()")
public void readSelfWritePoint(JoinPoint joinPoint) throws Throwable {
//对于标注了读己所写的接口,上下文中设置对应属性
ReadConsistencyManager.setReadSelfWrite();
}
} - 读请求添加注解,标识当前请求是否需要读之所写,记录在上下文中。
/** *4. 根据当前用户写入操作时记录的点位,选择合适的从库,如果没有符合条件的,降级到主库。 */ @Slf4jpublic class BinlogAwareLoadBalanceAlgorithm implements ReadQueryLoadBalanceAlgorithm {
private Properties properties; @Override public Properties getProps() { return this.properties; } @Override public void init(Properties properties) { this.properties = properties; } @Override public String getType() { return "BINLOG_AWARE"; } /** * read query load-balance algorithm. * @param name read query logic data source name * @param writeDataSourceName name of write data source * @param readDataSourceNames names of read data sources * @param context context * @return */ @Override public String getDataSource(String name, String writeDataSourceName, List<String> readDataSourceNames, TransactionConnectionContext context) { return this.getDataSource(name, writeDataSourceName, readDataSourceNames); } /** * 选择数据源的核心方法 * * @param name read query logic data source name * @param writeDataSourceName 主库名称 * @param readDataSourceNames 从库名称列表 * @return 选择的数据源名称 */ public String getDataSource(String name, String writeDataSourceName, List<String> readDataSourceNames) { try { if (ReadConsistencyManager.readSelfWrite()) { //要求读之所写 return getDb(writeDataSourceName, readDataSourceNames); } else { //不要求读之所写 return loadBalance(readDataSourceNames); } } finally { //清理Thread Local ReadConsistencyManager.clear(); } } /** * 获取大于等于用户当前存储点位信息的从库,如果没有从库满足条件,返回主库。存储的点位不不会过期情况下。 * @param writeDataSourceName * @param readDataSourceNames * @return */ private String getDb(String writeDataSourceName, List<String> readDataSourceNames) { //该类被SPI创建,无法通过spring容器注入,所以通过单例模式从容器中获取service BinlogPositionService binlogPositionService = Singleton.getBinlogPositionServiceInstance(); //获取用户点位 BinlogPosition positionInfo = binlogPositionService.getUserPosition(UserManager.getUid()); //存在点位信息 if (positionInfo.isEffective()) { //可以找到包含指定点位的从库,返回对于从库 List<String> containsSpecPositionSourceName = binlogPositionService.getContainSpecPositionSlave(positionInfo); if (CollectionUtils.isNotEmpty(containsSpecPositionSourceName)) { return loadBalance(containsSpecPositionSourceName); } //没有查询到满足条件的从库,查询主库 return writeDataSourceName; } else { //没有点位信息,用户没有执行过写操作 //此时,任选一个从库即可 return loadBalance(slaveNames); } } /** * 负载均衡策略随机选择 * * @param readDataSourceNames * @return */ private String loadBalance(List<String> readDataSourceNames) { return readDataSourceNames.get(ThreadLocalRandom.current().nextInt(readDataSourceNames.size())); } -
以上策略实在用户点位信息没有过期时间的基础上可保证读己所写。如果点位设置了过期时间,则需要调整逻辑。(如果保证点位信息不会过期,或者存储到用户侧始终会有点位信息,就不需要考入下列逻辑了)如果点位设置了过期时间,没有获取到点位信息可能存在两种情况。1.用户没有执行写操作。2.用户执行了写操作,但当前时间已经超过点位的过期时间。由于1.2在点位不存在的情况下,无法区分具体是哪一种情况。所以此时就需要判断主从同步延时,选取延迟时间小于等于过期时间的从库,满足条件的从库即可以读取到之前写入的数据。证明过程如下:



延迟时间小于等于过期时间的从库,可以读取到之前的写入数据,但如果延时时间大于过期时间,实际存在两种情况,一种是可以读取到,一种是无法读取到。此时由于点位已经过期,无法区分出来。所以统一走降级逻辑查主库。从库包含写入的条件:Δt ≥ L。延时时间(L)大于过期时间(6s)Δt = 10秒, L = 8秒条件:10 ≥ 8 ✅结果:从库已包含写入,可以安全读取
Δt = 7秒, L = 9秒条件:7 ≥ 9 ❌结果:从库还未同步写入,读取会得到旧数据例如用户写入后,数据被同步到了所有从库,用户第二天发起查询请求,此时点位信息以及过期,且用户写入主库数据已经同步到所有从库。用户此时需要判断主从延时,假设此时主从延时达到30s.但是用户昨天的数据早已写入,此时还是会被路由到主库。
/**
* 获取大于等于用户当前存储点位信息的从库,如果没有从库满足条件,返回主库。
* @param writeDataSourceName
* @param readDataSourceNames
* @return
*/
private String getDb(String writeDataSourceName, List<String> readDataSourceNames) {
//该类被SPI创建,无法通过spring容器注入,所以直接从容器中获取service
BinlogPositionService binlogPositionService = Singleton.getBinlogPositionServiceInstance();
//获取用户点位
BinlogPosition positionInfo = binlogPositionService.getUserPosition(UserManager.getUid());
//存在有效的点位信息
if (positionInfo.isEffective()) {
//可以找到包含指定点位的从库,返回对于从库
List<String> containsSpecPositionSourceName = binlogPositionService.getContainSpecPositionSlave(positionInfo);
if (CollectionUtils.isNotEmpty(containsSpecPositionSourceName)) {
return loadBalance(containsSpecPositionSourceName);
}
//没有查询到满足条件的从库,查询主库
return writeDataSourceName;
} else {
//没有点位信息存在两种情况
//case1 用户没有执行过写操作
//此时,任选一个从库即可
//case2 用户执行写操作,但存储的用户点位信息已过期。
//可将用户点位信息过期时间,设置为主从延迟的三倍。用户点位过期是主从延迟的三倍,过期后一般情况下,从库都同步了对应点位数据。
//但也可能存在没有同步的情况,此时就需要判断主从同步延时,选取延迟时间小于等于过期时间的从库。
//或者,将点位信息不设置过期时间,这样始终可以通过点位比较,然后通过定时任务,判断存储的点位信息小于所有从库当前点位就将其清空。
Set<String> slaveNames = binlogPositionService.getReasonablyDelayedSlave();
if (CollectionUtils.isNotEmpty(slaveNames)) {
return loadBalance(slaveNames);
}
//没有符合条件的,降级主库。
return writeDataSourceName;
}
}由于Shrding Jdbc的自定义查询负载均衡算法使用SPI加载的,所以还需要指定自定义算法SPI文件。在resource目录下创建一个META-INF/services文件夹,添加一个名为org.apache.shardingsphere.readwritesplitting.spi.ReadQueryLoadBalanceAlgorithm的文件。文件中添加自定义实现了ReadQueryLoadBalanceAlgorithm的具体类的路基。
#SPI load
com.example.config.BinlogAwareLoadBalanceAlgorithm1.2.3 单调读
单调读如下图所示,如果用户A更新或插入了数据,这个行为对用户B不可见,用户B只需要查询从库即可,从库何时同步了对应数据,就何时读取即可。由于写入操作是用户A进行的,所以用户B无需读己所写的保证。但如果用户B第一次读取的从库,已经同步了用户A的写入或更新内容,此时用户B可以查看到A的写入或更新。但是用户B再次刷新页面,此时读请求被路由到另外一个从库,此从库因为网络问题改从库没有同步用户A的写入或更新。此时对用户B来说,第一次看到了内容,第二次又没有看到内容。用户首先从新鲜副本读取,然后从陈旧副本读取,时间似乎倒退了。为了防止这种异常,我们需要单调读。单调读提供的保证是,不会读取到比之前读取数据更旧的数据。也就说单调读读取的数据,保持单调递增,每一次读取的数据版本只会大于或等于前一次读取的数据。
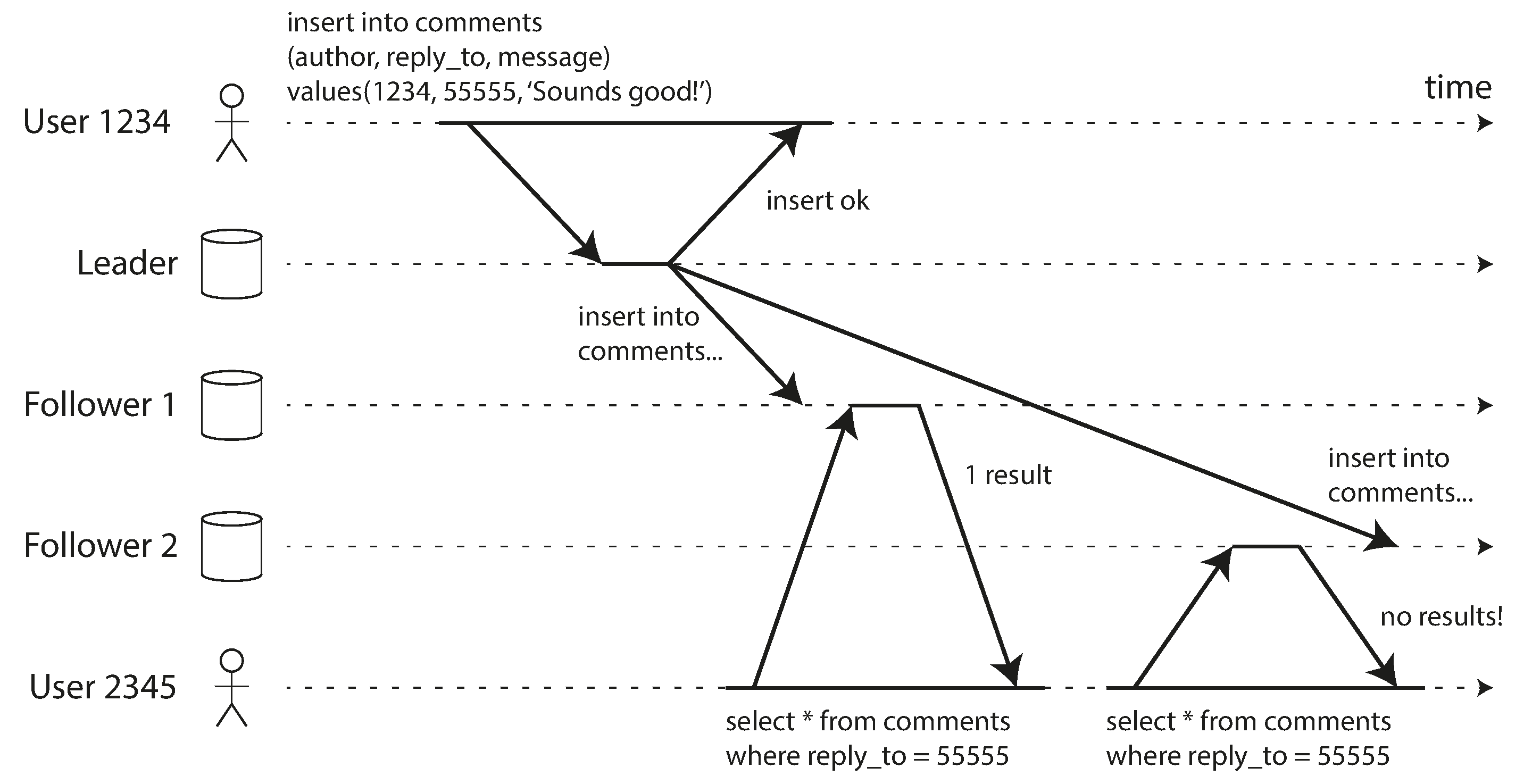
如何保证单调读隔离级别?
-
同一个用户每个请求路由到固定的从库,就当个数据库而言,数据版本是递增的,读取单个实例,读取的数据版本只会大于或等于上一次读取的数据。
-
记录第一次读取数据库的点位信息,保证后续请求只会被路由到比记录点位相等或更新的数据库。
如果仅仅只是需要单调读的保证,将读操作根据用户uid hash后路由到固定从库是实现最简单的方式。但某些在单调读的基础上,需要保证读之所写的混合情况时,路由到固定从库这个方案就不行了,路由到固定从库只能满足单调读的一致性,但无法满足读己所写。下一节会说明单调读+读己所写的混合情况。
1.2.4 基于Shrding Jdbc实现单调读
/**
*1. 读一致性切面添加单调读标识
* 读一致性注解,用于标识当读请求的一致性级别
*/
@Slf4j
@Aspect
@Component
public class ReadConsistencyAspect {
//读己所写
@Pointcut("@annotation(com.example.annotation.ReadSelfWrite)")
public void readSelfWritePointCut() {
}
@Before(value = "readSelfWritePointCut()")
public void readSelfWritePoint(JoinPoint joinPoint) throws Throwable {
//对于标注了读之所写的接口,上下文中设置对应属性
ReadConsistencyManager.setReadSelfWrite();
}
//单调读
@Pointcut("@annotation(com.example.annotation.MonotonicRead)")
public void monotonicReadPointCut() {
}
@Before(value = "monotonicReadPointCut()")
public void monotonicReadPoint(JoinPoint joinPoint) throws Throwable {
//对于标注了读之所写的接口,上下文中设置对于属性
ReadConsistencyManager.setMonotonicRead();
}
}
/**
* 2.自定义算法中,单调读选择分区。
*
* @param name read query logic data source name
* @param writeDataSourceName 主库名称
* @param readDataSourceNames 从库名称列表
* @return 选择的数据源名称
*/
public String getDataSource(String name, String writeDataSourceName, List<String> readDataSourceNames) {
try {
if (ReadConsistencyManager.readSelfWrite()) {
//2.只要求读之所写
return getDb(writeDataSourceName, readDataSourceNames);
} else if (ReadConsistencyManager.monotonicRead()) {
//3.只要求单调读(根据唯一标识分区即可),此处使用uid hash后取余,将请求路由到指定分区。
//由于hashCode可能算出负数,所以将其与0x7ffffff按位相与,使其首位置0变为正数。
return readDataSourceNames.get((UserManager.getUid().hashCode() & Integer.MAX_VALUE) % readDataSourceNames.size());
} else {
//4.不要求读之所写+单调读
return loadBalance(readDataSourceNames);
}
} finally {
//清理Thread Local
ReadConsistencyManager.clear();
}
}1.2.5 读己所写+单调读
前面提到,读己所写和单调读,但这两个混合的情况呢。这两个读一致性是独立的,满足其中一个并不能意味着满足另外一个。但有时会需要当前的请求需要同时满足两个读一致性的要求。例如当前用户编辑自己主页,后续读取自己主页要满足读己所写,此时在用户看来,编辑和读取自己的主页都没有问题,可以看到修改后的数据。但是读取别人主页呢,此时就没有任何保证了。例如用户当前最新的更新已经同步到所有从库(S1,S2),当前读取满足读己所写,请求被路由到任一个从库即可,该从库有自己最新写入的数据,满足读己所写,同时当前从库S1有用户B的更新操作,但由于网络原因,用户B的最新数据没有被同步到从库S2,此时用户如果只保证读己所写,第一次被路由到S1满足读己所写,用户同时查看用户B的主页,第一次被路由到S1可以看到修改过后的内容,第二次被路由到S2又无法看到用户修改后的内容,S1,S2均满足读己所写,但写入操作是其他用户B写入的,对当前用户来说感知不到,但此时读取其他用户又存在单调读的问题。或者是购物车场景,用户需要满足读己所写,即添加到购物车的内容需要添加后马上可见,同时多次读取自己购物车需要满足单调读,不能出现数据回退的现象。两种读一致性需要根据具体场景具体满足对于一致性要求。
既然要实现读己所写+单调读,如何保证这两种读一致性,本质上不一致问题都是读取的数据版本造成的,读取到比当前应该看见的数据版本更旧的版本导致的。无论时读己所写(读取数据版本 ≥ 自己最后写入版本),还是单调读(读取版本要 ≥ 最后一次读取的数据版本),所以只要保证了读取的数据版本 ≥ max(最后读取版本, 最后写入版本),即可保证两种一致性。
所以具体实现策略为,**根据用户记录的点位,先保证读己所写,获取一个满足条件的数据版本,然后读取该数据版本,并且记录当前读取的版本,将其最为最新点位。**后续读取操作必须大于等于当前点位,即不会出现回退现象。写入操作时写入主库,同时更新点位(写入操作是写入主库,点位保持单调递增),即不会出现违背读己所写情况。所以最后读取的数据版本 ≥ max(最后读取版本, 最后写入版本),即可保证两种一致性。
L = 当前已知最大版本点位Vᵣ = 读操作实际版本V = 写操作产生版本设写操作 w(x,v) 在 r(x) 之前:w(x,v) 后:L ≥ v (写操作更新规则,记录写入点位)r(x) 要求:Vᵣ ≥ L (读操作要求,即当前读取数据副本要大于等于记录的用户副本)由传递性:Vᵣ ≥ L ≥ v,即当前读操作可以读取到自己最新写入的数据即 Vᵣ ≥ v 满足读己所写。
设 r₁(x) 在 r₂(x) 之前:r₁(x) 后:L ≥ Vᵣ₁ (读操作更新规则,读取数据后记录当前读取点位,即L ≥ Vᵣ₁)r₂(x) 要求:Vᵣ₂ ≥ L (读操作要求,读取要求读取数据必须大于等于记录点位)由传递性:Vᵣ₂ ≥ L ≥ Vᵣ₁,即第二次读取的数据,必得大于等于第一次读取数据不会出现回退。即 Vᵣ₂ ≥ Vᵣ₁ 满足单调读。
1.2.6 基于Sahrding Jdbc实现读己所写+单调读
/**
* 选择数据源的核心方法
*
* @param name read query logic data source name
* @param writeDataSourceName 主库名称
* @param readDataSourceNames 从库名称列表
* @return 选择的数据源名称
*/
public String getDataSource(String name, String writeDataSourceName, List<String> readDataSourceNames) {
try {
if (ReadConsistencyManager.readSelfWrite() && ReadConsistencyManager.monotonicRead()) {
//如果是读之所写+单调读
//先根据读之所写,获取能读取的库。
//此时有三种清空
//1. 存在点位信息,可以找到满足点位的从库,选择从库。
//2. 存在点位信息,无法找到满足点位的从库,选择主库。
String dbName = getDb(writeDataSourceName, readDataSourceNames);
//获取当前读取库的点位信息,并缓存
//后续请求必须大于等于存储的最新点位。
BinlogPositionService binlogPositionService = Singleton.getBinlogPositionServiceInstance();
BinlogPosition specDbPosition = binlogPositionService.getPositionFromCache(dbName);
binlogPositionService.cacheUserBinlogPosition(UserManager.getUid(), specDbPosition);
return dbName;
} else if (ReadConsistencyManager.readSelfWrite()) {
//2.只要求读之所写
return getDb(writeDataSourceName, readDataSourceNames);
} else if (ReadConsistencyManager.monotonicRead()) {
//3.只要求单调读(根据唯一标识分区即可)
return readDataSourceNames.get((UserManager.getUid().hashCode() & Integer.MAX_VALUE) % readDataSourceNames.size());
} else {
//4.不要求读之所写+单调读
return loadBalance(readDataSourceNames);
}
} finally {
//清理Thread Local
ReadConsistencyManager.clear();
}
}1.3 高可用篇 - 故障切换
1.3.1 切换的一致性问题
切换前,首先要讨论,主从数据一致性问题。如果是预期的切换,即主库没有宕机的情况下。这种情况一致性是很容易保证的。具体切换流程如下。1.判断备库 B 现在的 seconds_behind_master,如果小于某个值(比如 5 秒)继续下一步,否则持续重试这一步;2.把主库 A 改成只读状态,即把 readonly 设置为 true;3.判断备库 B 的 seconds_behind_master 的值,直到这个值变成 0 为止;4.把备库 B 改成可读写状态,也就是把 readonly 设置为 false;5.把业务请求切到备库 B。切换后数据主从数据是一致的,且没有丢失。
那如果是主库宕机呢?这时情况就比较复杂呢。首先,我们主从复制的情况下,数据有两个大的约束。约束1,客户端收到成功响应保证主库事务已提交并持久化。约束2,从库读取主库binlog写入relay log成功,主库必定写入对应binlog。约束1,由MySQL保证,约束2,也很容易看出,从库中继日志的内容就是主库的binlog内容,写入了从库中继日志,主库必定会存在对应日志内容。那么主要场景如下:
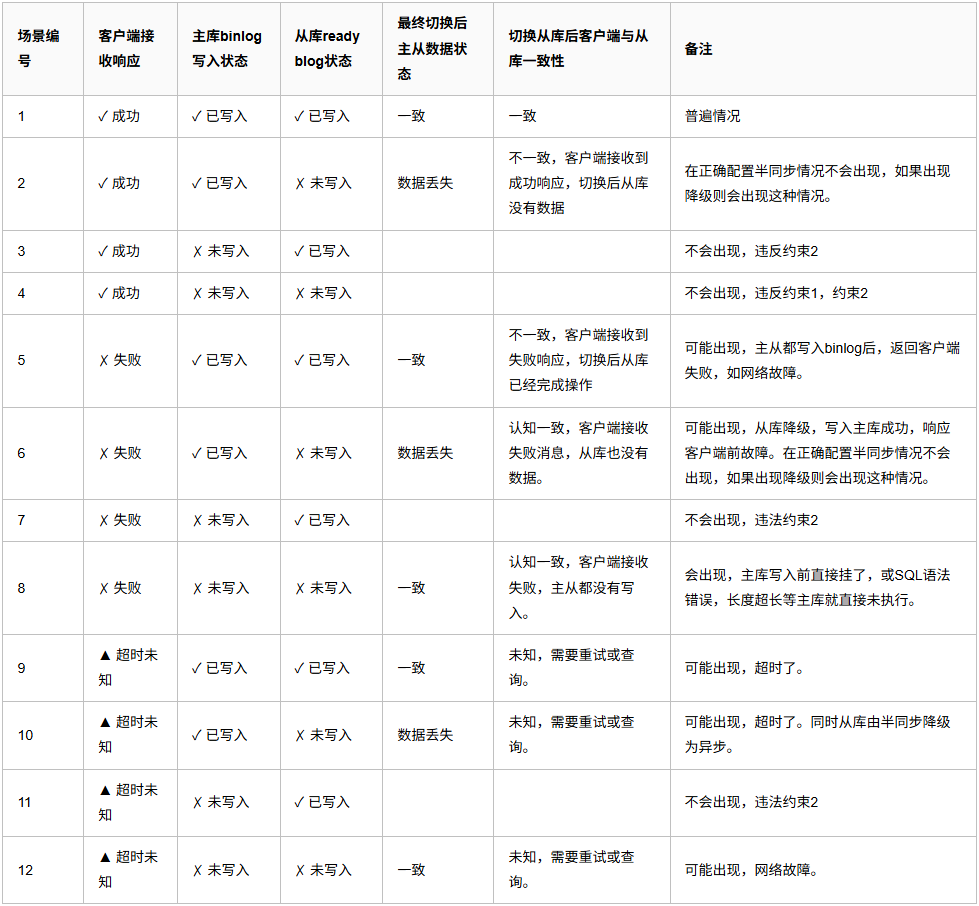
读写分离场景下,用户不关注主从数据是否一致,用户只关注客户端接收响应,与切换后从库数据状态。所以我们提取这两列。去除不可能出现和前后一致的情况,保留不一致的情况如下:
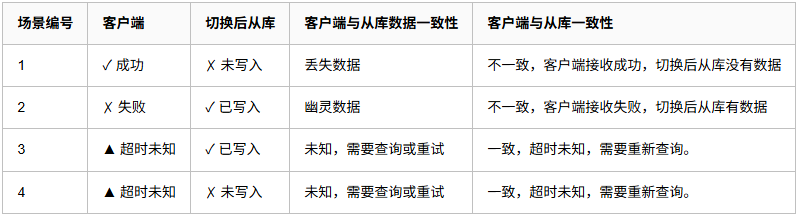
场景1,明显数据丢失了,内部统还好,操作以事务为单位,即使数据丢失,整体数据状态也是一致的。预期是由一致性状态A转移到一致性状态B。即使没有转移到一致性状态B,但数据也保持了之前的一致性状态A,也是安全的。例如状态,A用户扣减100,B用户增加100.即使这个事务操作丢失,A用户钱也没有扣减,B用户钱也没增加还是一致的。但涉及第三方系统一致性既没有办法得到保证了,事务只能保证内部系统的一致性,例如是创建一个订单,后续根据这个订单调用第三方接口转账,然后更新订单状态。如果这个订单数据丢失,同时也调用了第三方接口完成了状态。那这个就需要对账去处理了。系统内当前有100笔订单,第三方系统有101笔,通过监控找出不一致性的数据,要么在第三方系统中退掉订单,或在内部系统恢复数据。场景2,幽灵数据,客户接收响应失败,但数据写入了,这时用户可能重复操作,有些操作是覆盖的,重复操作以最后一次为准即可,例如修改个人主页。重复写入后面覆盖前面即可,多次操作是安全的。但有些不允许出现重复数据的操作,就需要结合业务场景考虑幂等操作。场景3,4,对于客户来说,接收的是超时。那么切换后,从库数据无论是存在还是丢失都是可以接受的,比较没有明确的返回成功或失败。针对这些返回,需要先查询一次,同时考虑重试或幂等去重即可。
上述就是切换后的一致性问题,需要根据业务重要性去做相对于的兜底操作。对于不重要的业务数据,丢失或重复都是可接收的。对于重要的数据就需要考虑好各种情况,能通过监控等手段,识别最终数据的一致性情况,加上做好预案,出现问题能快速修复即可。毕竟,真正的不一致情况相对来说还是较少的,大多数情况都是正常情况,但也要考虑到最坏情况。
1.3.2 基于Zookeeper的动态配置切换
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-cluster-mode-core</artifactId>
<version>5.2.1</version>
<exclusions>
<exclusion>
<groupId>org.yaml</groupId>
<artifactId>snakeyaml</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.yaml</groupId>
<artifactId>snakeyaml</artifactId>
<version>1.33</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-cluster-mode-repository-zookeeper</artifactId>
<version>5.3.0</version>
</dependency>
# ShardingSphere读写分离配置:
shardingsphere:
mode:
type: Cluster
repository:
type: ZooKeeper
props:
namespace: governance_ds
server-lists: hcf.com:2181
retryIntervalMilliseconds: 500
timeToLiveSeconds: 60
maxRetries: 3
operationTimeoutMilliseconds: 5000
overwrite: false应用启动,配置信息上传到zookeeper。后续直接修改zookeeper中的配置信息。shrding-jdbc会收到通知,修改对应配置,如分片规则,主从数据源等。
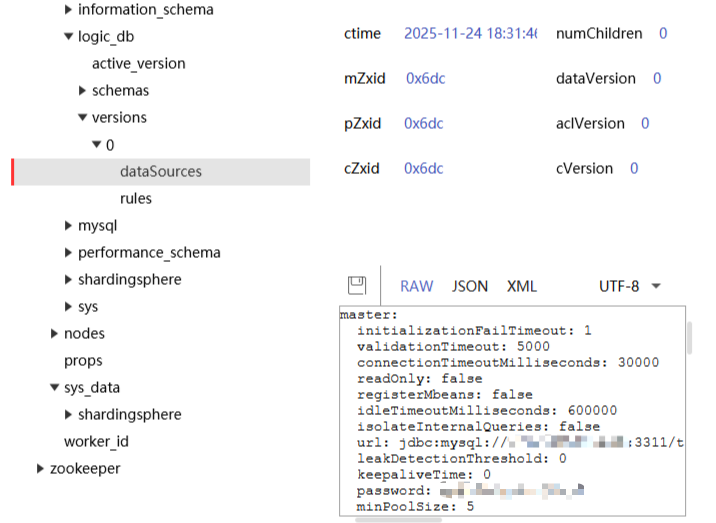
主:3311,从1:3312,从2:3313

修改zookeeper上的配置。假装主库宕机,3312变为新的主库,3313保持从库。
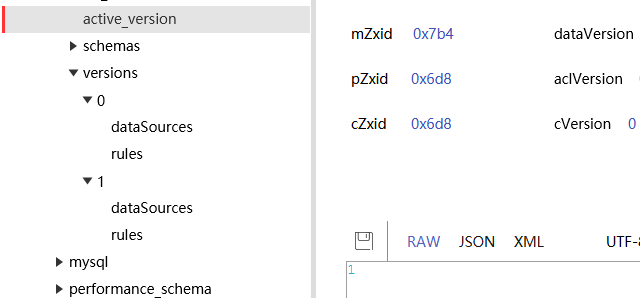
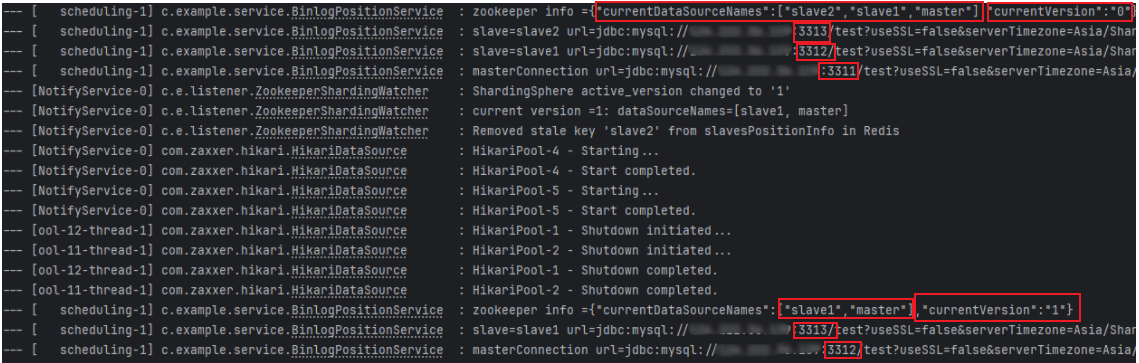
可以看到,zookeeper中versions下新增一个版本号为1的配置,在里面填写修改后配置,然后将active_version修改为1,后续项目中数据源也刷新了。主库变为3312,从库变为了3313.
文章转载自: ++gcmh++