01、PDF 神级翻译工具
翻译 PDF 最痛苦的不是翻译本身,而是格式乱套。
用某些工具全文翻译,会有公式乱码、图表错位,翻译完的文档丑得没法看问题。
这个叫 BabelDOC 的 GitHub 开源项目,就是一个 PDF 翻译神器:在保留原汁原味排版的前提下,给你整出高质量的翻译文档。

arduino
开源地址:https://github.com/funstory-ai/BabelDOCBabelDOC 是一个基于 Python 的开源工具,用来翻译 PDF 文档。
它不仅仅是把字变成中文,更重要的是它会深度解析 PDF 的结构。
它知道哪里是标题,哪里是正文,哪里是图片下面的注释。然后,它利用大模型的翻译能力,把文字翻译好,再填回原来的位置。
最牛的是,它支持中英对照(双语)模式。左边是原汁原味的英文,右边是对应的中文,排版对齐得非常舒服。

它不是用那种生硬的机器翻译引擎,而是支持 OpenAI 接口。你可以用 GPT-4o,也可以用 DeepSeek、Qwen 这些国产高质量模型来翻译。
翻译出来的味儿,明显比机翻通顺多了。
如何使用?
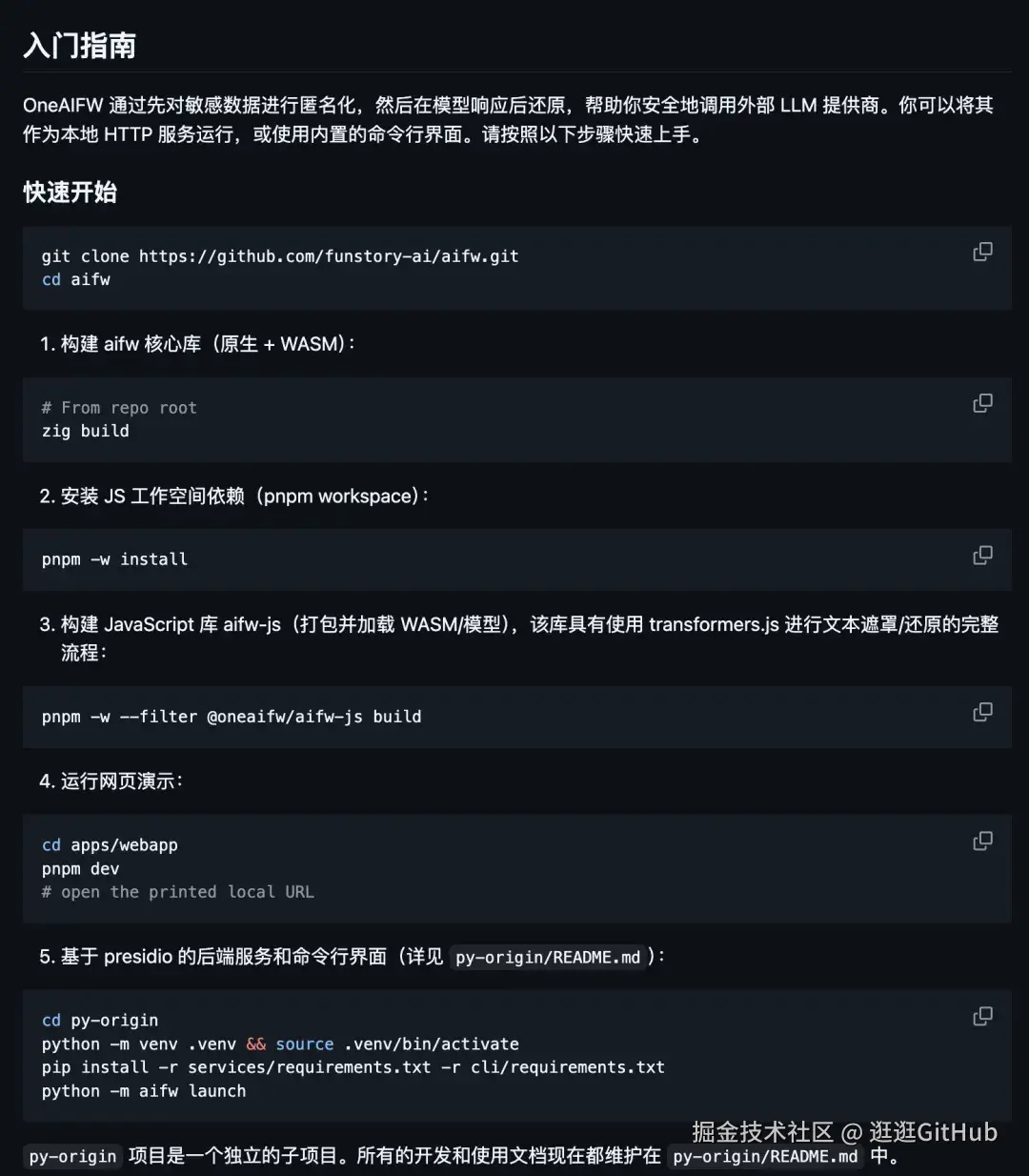
这东西主要是给开发者或者稍微懂点技术的用户准备的,目前主要是命令行操作(CLI)。
它推荐用 uv 这个工具来安装,当然你直接用 pip 或者源码安装也行。
bash
# 如果你有 uvuv tool install babeldoc# 或者把源码拉下来,进目录git clone https://github.com/funstory-ai/BabelDOCcd BabelDOCuv run babeldoc --help假设你有一个大模型 DeepSeek 的 Api Key ,你想翻译一个叫 paper.pdf 的文件。
命令行输入下面这样的命令就行了:
csharp
babeldoc \ --files paper.pdf \ --openai \ --openai-model "deepseek-chat" \ --openai-base-url "https://api.deepseek.com" \ --openai-api-key "sk-你的key" \ --lang-out zh-CN回车之后,它就开始干活了:解析 PDF -> 提取文本 -> 丢给大模型翻译 -> 重组排版 -> 生成新 PDF。
如果你想直接使用,可以访问如下链接,直接上传你的 PDF 文档,一键翻译。
arduino
地址:https://app.immersivetranslate.com/babel-doc/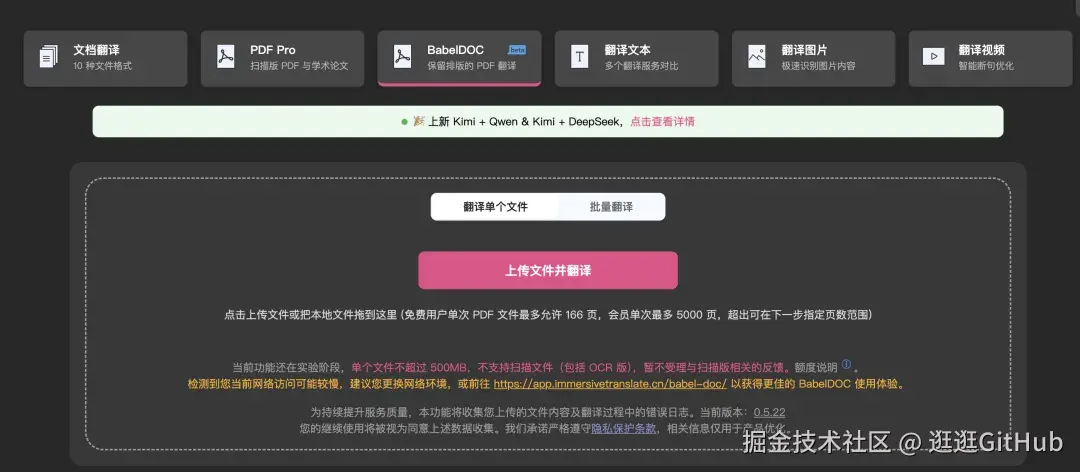
02、AI 防火墙
今天逛 GitHub 的时候,还发现了一个很有意思的开源项目。
它叫 OneAIFW (AI Firewall) ,听名字就很霸气:AI 防火墙 。但这玩意儿不是防黑客的,是防你自己手滑泄密的。

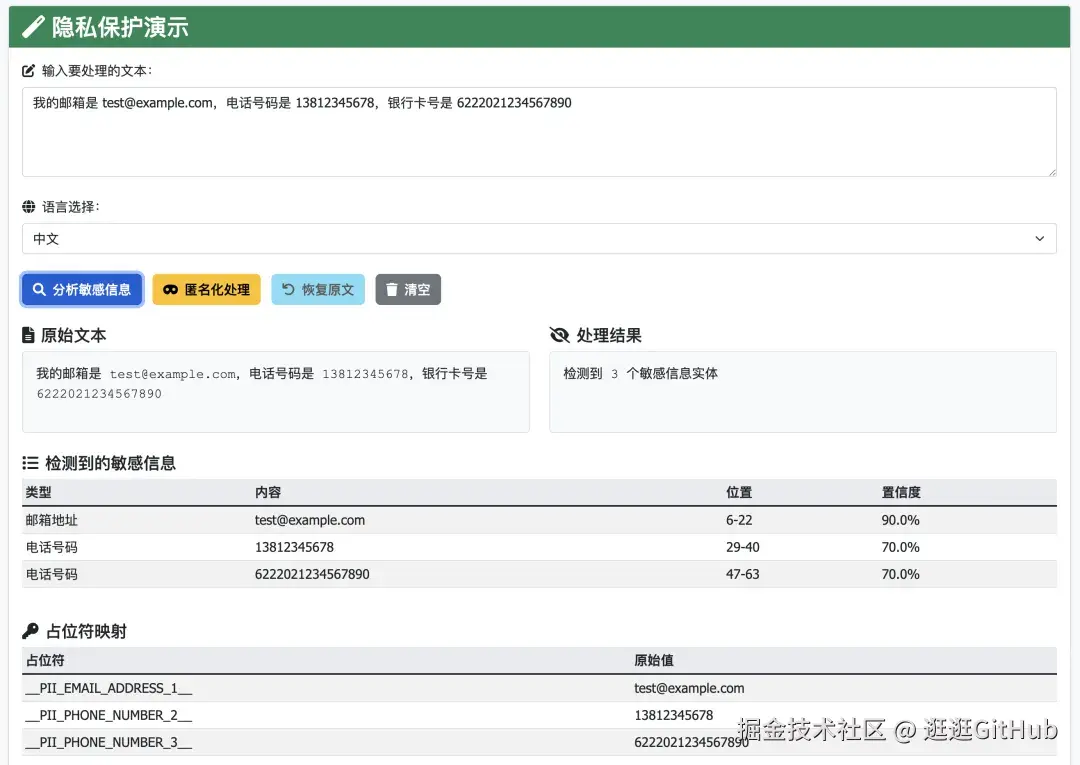
当你向大模型提问时,OneAIFW 会抢先一步,把你问题里的敏感信息,比如邮箱、手机号、银行卡号、密钥全部调包。
arduino
开源地址:https://github.com/funstory-ai/aifw举个栗子:
你的原始 Prompt:
"帮我写封邮件给 li_lei@example.com,告诉他下周三的会议改到 Room 303。"
OneAIFW 处理后,发给大模型的是:
"帮我写封邮件给 PII_EMAIL_ADDRESS_00000001 ,告诉他下周三的会议改到 PII_LOCATION_00000002。"

等大模型回复了:
"好的,邮件草稿如下:Dear PII_EMAIL_ADDRESS_00000001 ..."
OneAIFW 再次拦截,把占位符还原:
"好的,邮件草稿如下:Dear li_lei@example.com ..."

全程无感。
你看到的是完美的结果,而大模型那边拿到的是一堆乱码占位符。你的隐私数据,不会进入大模型的服务器。
如何使用