百度指数数据采集与可视化平台 BaiduIndexHunter
本文详细介绍开源项目 BaiduIndexHunter:面向百度指数数据的采集、存储与可视化平台,采用前后端分离架构,支持六大维度数据采集、Cookie 轮换、断点续爬、实时进度与多格式导出,适合学术研究、市场分析与舆情监测。包含项目说明、系统架构、完整部署步骤与常见问题。

项目地址 :https://github.com/Auroral0810/BaiduIndexHunter
一、项目概述与重要声明
1.1 项目简介
BaiduIndexHunter (百度指数猎人)是一套面向百度指数数据 的采集、存储与可视化平台,采用前后端分离 架构,基于 Flask + Vue 3 + Element Plus 构建。系统支持搜索指数 、资讯指数 、需求图谱 、人群属性 、兴趣分布 、地域分布六大维度数据采集,集成任务调度、Cookie 轮换、断点续爬、实时进度推送与数据大屏等核心能力。
项目面向学术研究、市场分析与舆情监测等场景,支持批量关键词与多地域采集、多格式导出(CSV / Excel / Parquet / dta / json / SQLite 等),并内置 API 鉴权、环境校验等安全机制,适用于单机或小规模团队部署使用。用户只需在前端选择关键词、地区、日期范围、输出格式等参数,即可批量采集海量百度指数数据,无需编写爬虫代码。
1.2 重要声明
- 本项目仅供学习与技术交流 ,严禁用于任何商业用途或非法行为。
- 使用者需遵守所属国家和地区的法律法规;因违反政策、法规或他人权益而导致的任何后果,由使用者自行承担全部责任。
- 作者对由此项目引发的任何直接或间接损失、法律责任与风险不承担任何法律责任。
- 若对免责声明条款有疑问或无法接受,请立即停止下载和使用本项目。
二、功能特性
| 核心能力 | 详细描述 |
|---|---|
| 六大模块全覆盖 | 深度集成搜索指数、资讯指数、需求图谱、人群属性、兴趣分布、地域分布六大数据接口。 |
| 实时状态监控 | 基于 WebSocket 技术,秒级同步采集进度与系统日志,实时监控项目运行状态。 |
| 高效并发采集 | 采用分布式消息队列设计,支持多任务同时运行,高效应对海量关键词采集场景。 |
| 智能账号池 | 内置账号状态自动巡检机制,支持 Cookie 自动轮换,封禁预警和用量可视化统计。 |
| 任务断点续存 | 支持任务检查点(Checkpoint)机制,意外中断后可一键恢复,杜绝重复流量消耗。 |
| 结构化数据导出 | 采集结果自动清洗为 CSV / Excel / Parquet / dta / json 等六种主流数据结构,并支持结构化数据库存储。 |
| 多语言与国际化 | 完整支持九种语言界面切换,满足多语种全球用户的需求。 |
| 深色模式支持 | 适配现代 IDE 审美,支持 Dark Mode 一键切换,保护长时间工作下的视觉体验。 |
| 全面数据可视化支持 | 内置丰富的数据分析与可视化展示,助力数据洞察与业务决策。 |
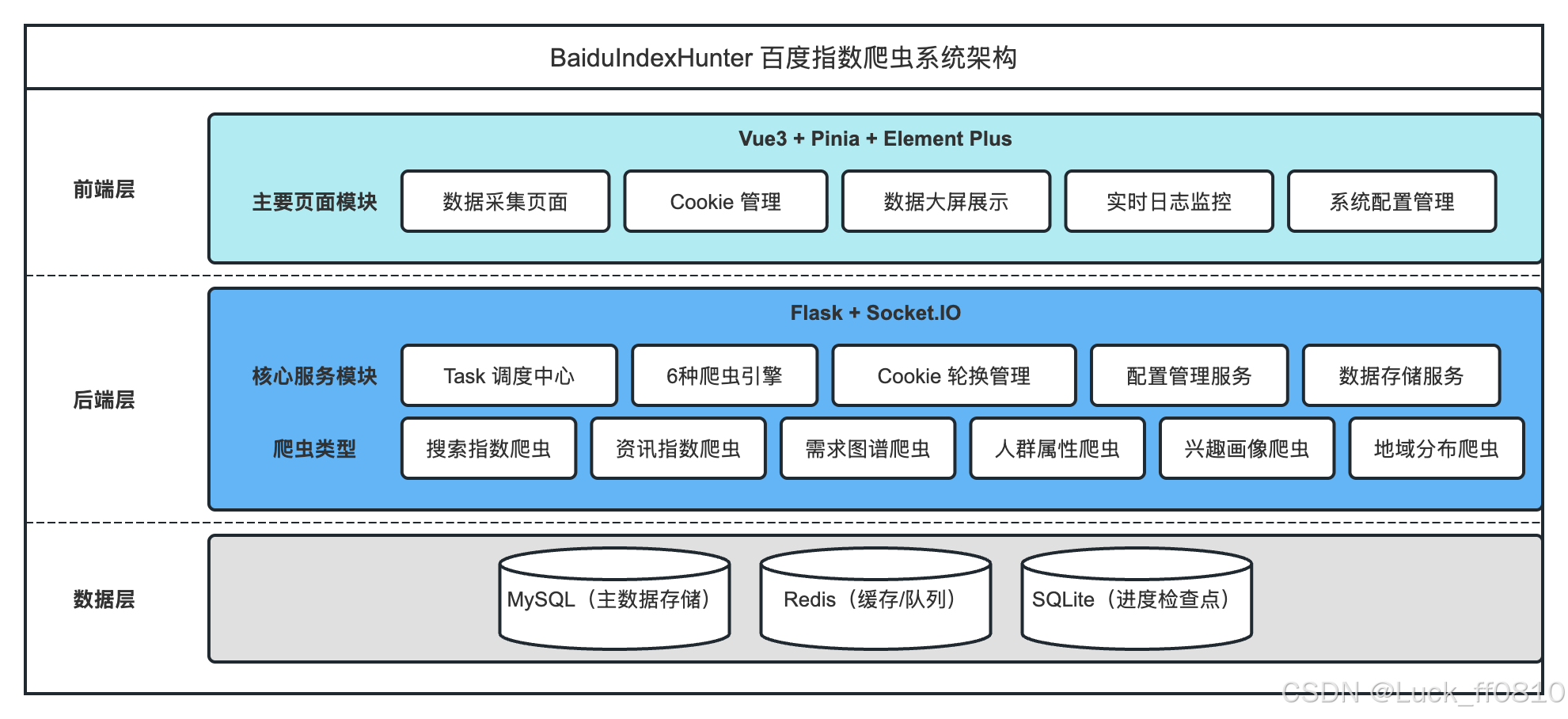
三、系统架构
3.1 整体架构图
系统采用前端(Vue 3 SPA)+ 后端(Flask API + 任务调度 + 爬虫引擎)+ 数据层(MySQL + Redis + SQLite 检查点) 的分层架构。前端通过 REST API 与 WebSocket 与后端通信;后端由任务调度器、多种爬虫、Cookie 轮换、存储与进度管理、WebSocket 推送等模块组成。
3.2 一次完整采集流程
从用户在前端配置参数到任务完成、可下载结果,整体流程如下表所示。
| 步骤 | 阶段名称 | 主要操作 | 参与组件 | 循环特性 |
|---|---|---|---|---|
| 1 | 用户配置 | 前端选择关键词、地区、日期范围、输出格式等参数 | DataCollection + SearchIndexTask/FeedIndexTask 等 | - |
| 2 | 任务提交 | 用户点击创建任务,前端 POST /api/task/create | 任务组件 + request.js(鉴权) | - |
| 3 | 接口接收 | 后端验证请求、解析参数 | TaskController + TaskService | - |
| 4 | 参数处理 | 解析关键词列表、城市代码、日期范围,生成蜘蛛参数 | TaskService | - |
| 5 | 任务入队 | 生成 task_id,写入 MySQL,加入优先级队列 | TaskScheduler + TaskRepository | - |
| 6 | 响应返回 | 前端收到 task_id,展示「任务已创建」 | 前端 + WebSocket 订阅 | - |
| 7 | 调度出队 | 后台调度循环检查队列,取出待执行任务 | TaskScheduler | - |
| 8 | 爬虫实例化 | 根据 task_type 实例化对应爬虫(如 SearchIndexCrawler) | TaskExecutor | - |
| 9 | 初始化与续爬 | 加载 SQLite 检查点(若有),生成子任务列表,跳过已完成项 | BaseCrawler + ProgressManager | - |
| 10-N | 循环阶段 | 并发采集 + 进度上报 | 爬虫 + CookieRotator + WebSocket | 多轮循环 |
| 10.1 | 获取 Cookie | 从 Cookie 池按策略选取可用账号 | CookieRotator + CookieService | 每批/每子任务 |
| 10.2 | 加密 Token | 生成 Cipher-Text 等请求头 | CipherGenerator + execjs | 每子任务 |
| 10.3 | 请求解析 | 请求百度指数 API,解析 JSON 响应 | Processor(search_processor 等) | 每子任务 |
| 10.4 | 数据缓冲 | 追加到内存缓冲,达到阈值时批量写入 CSV | BaseCrawler + StorageService | 每批 |
| 10.5 | 检查点更新 | 标记已完成/失败,写入 SQLite 检查点 | ProgressManager | 每批 |
| 10.6 | 进度推送 | 向前端推送进度条、速度、ETA | WebSocketService + Logs.vue | 每批 |
| N+1 | 数据落盘 | 刷新缓冲,将剩余数据写入 CSV | StorageService | - |
| N+2 | 格式转换 | 按配置将 CSV 转为 Excel/DTA/JSON/Parquet/SQLite | StorageService | - |
| N+3 | 任务完成 | 更新任务状态、输出路径,推送完成事件 | TaskRepository + WebSocketService | - |
| N+4 | 前端展示 | 任务列表显示完成,用户可下载输出文件 | TaskList + DirPicker | - |
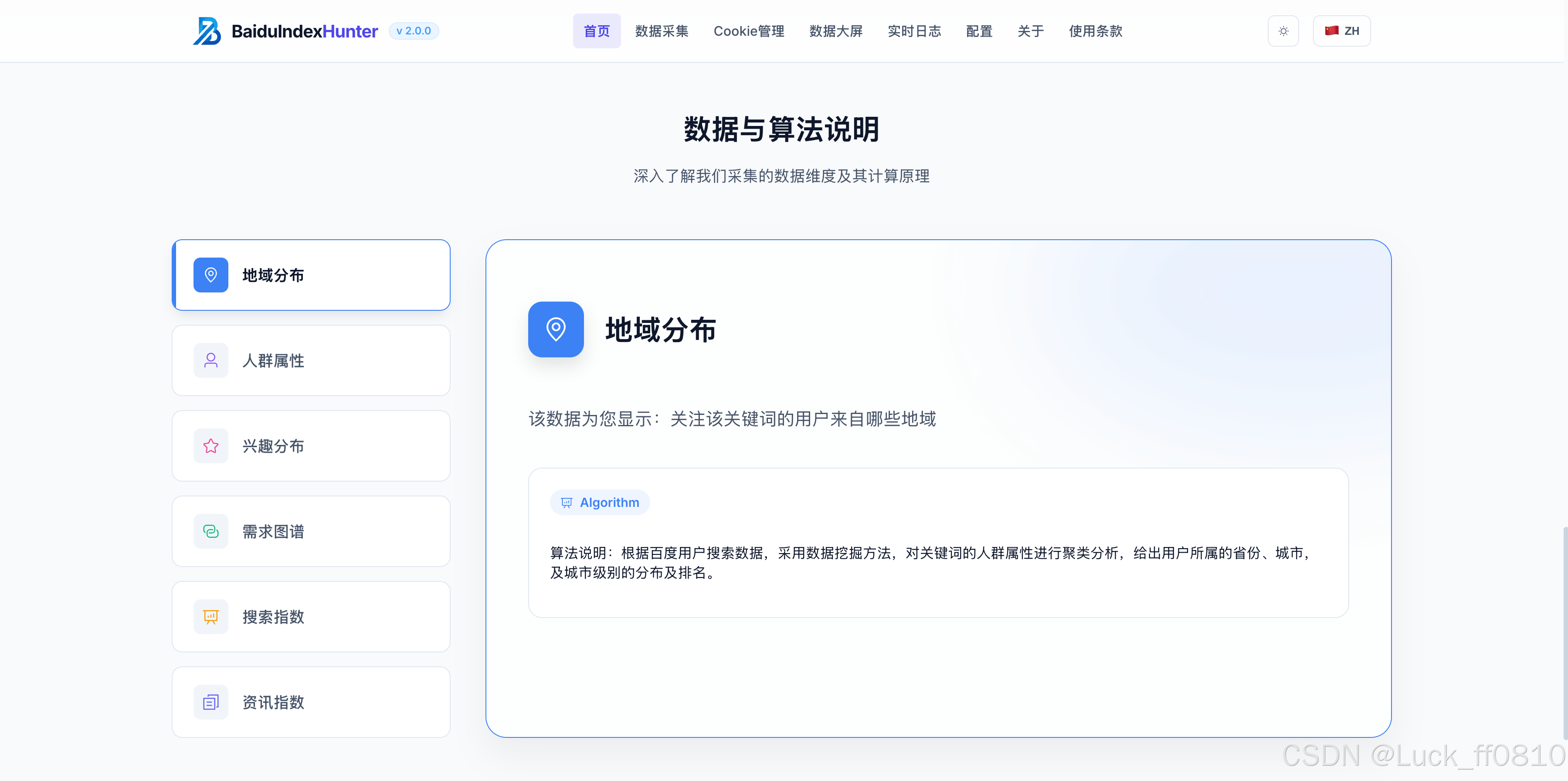
四、系统界面模块化展示
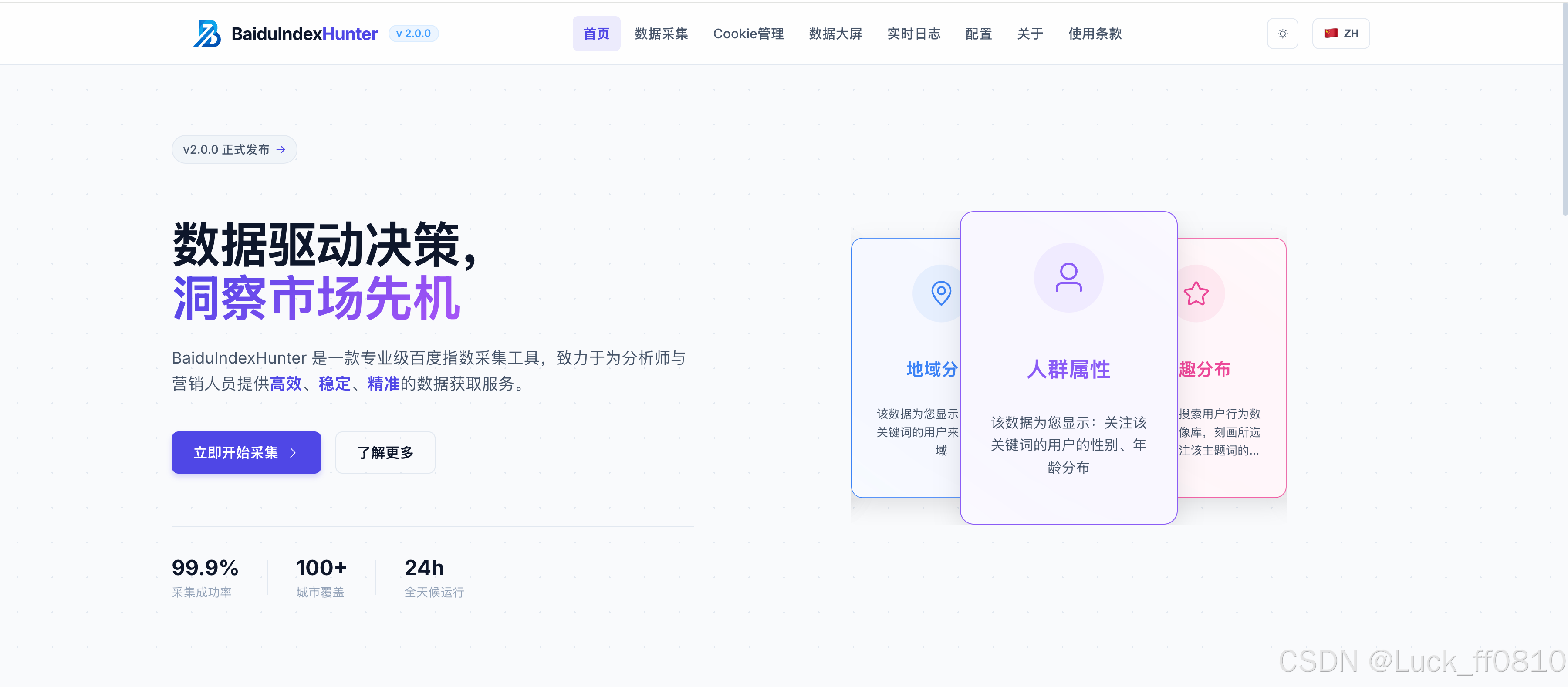
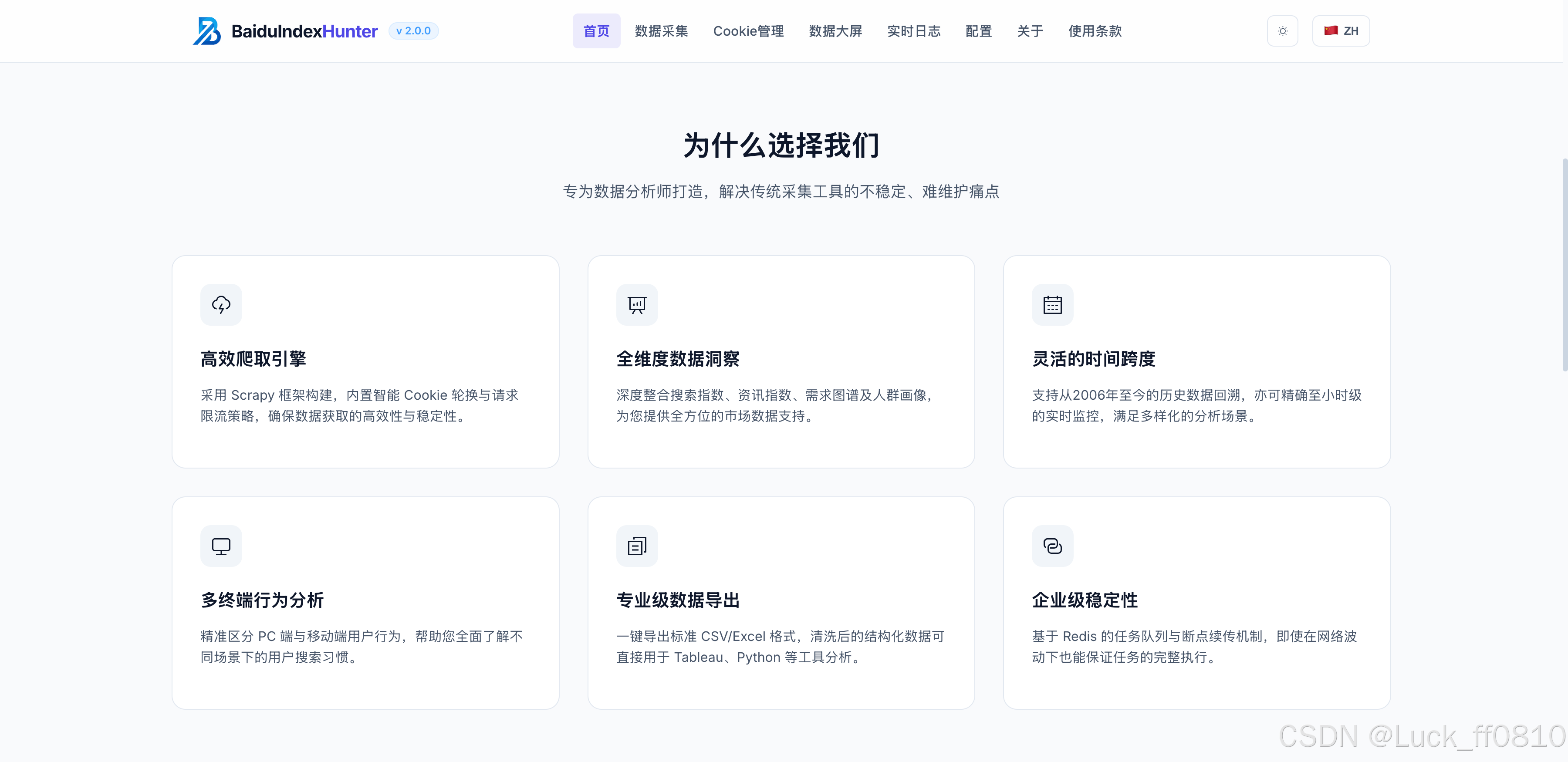
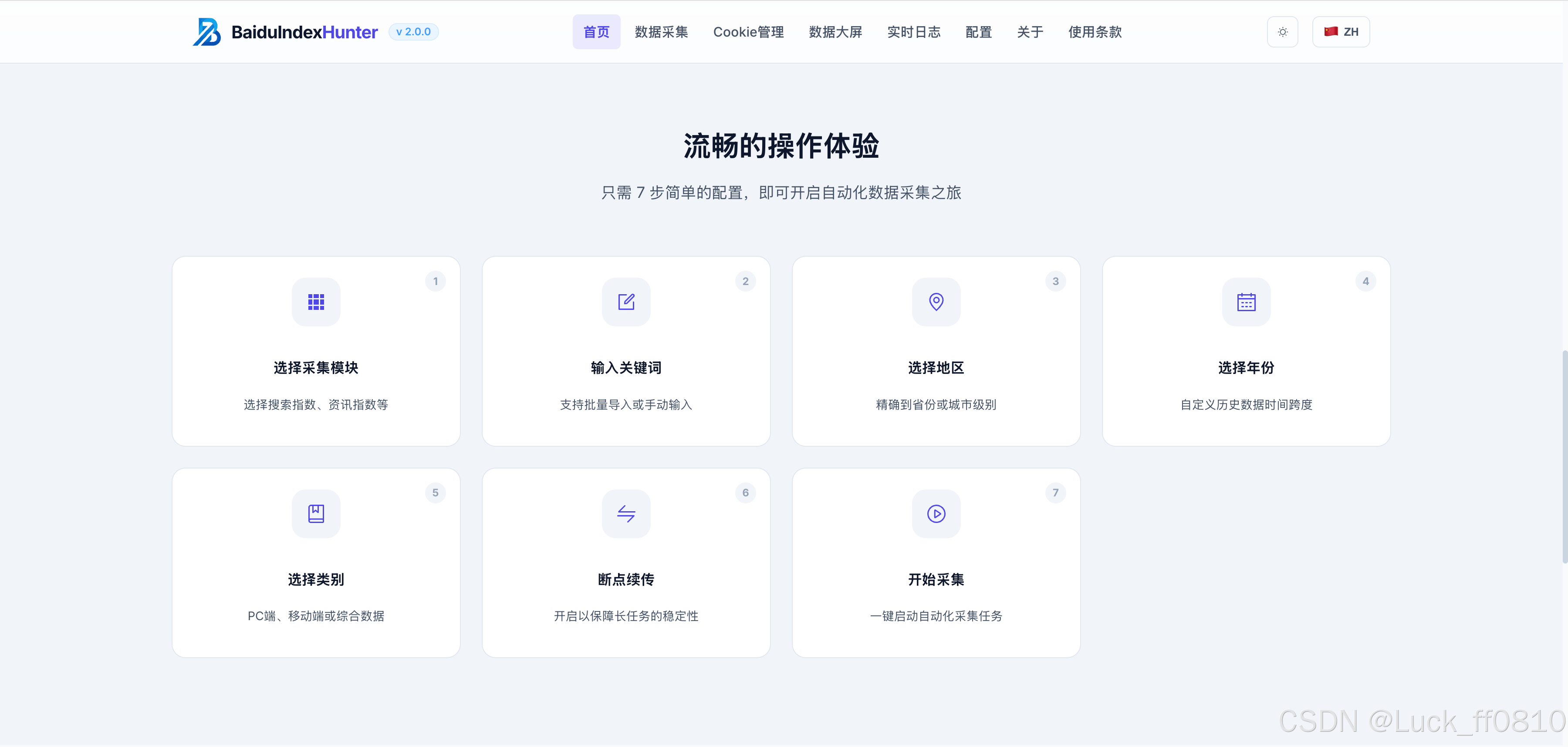
4.1 首页
提供产品入口、数据来源说明、产品优势展示,以及引导性操作体验和导航。
 |
 |
|---|---|
 |
 |
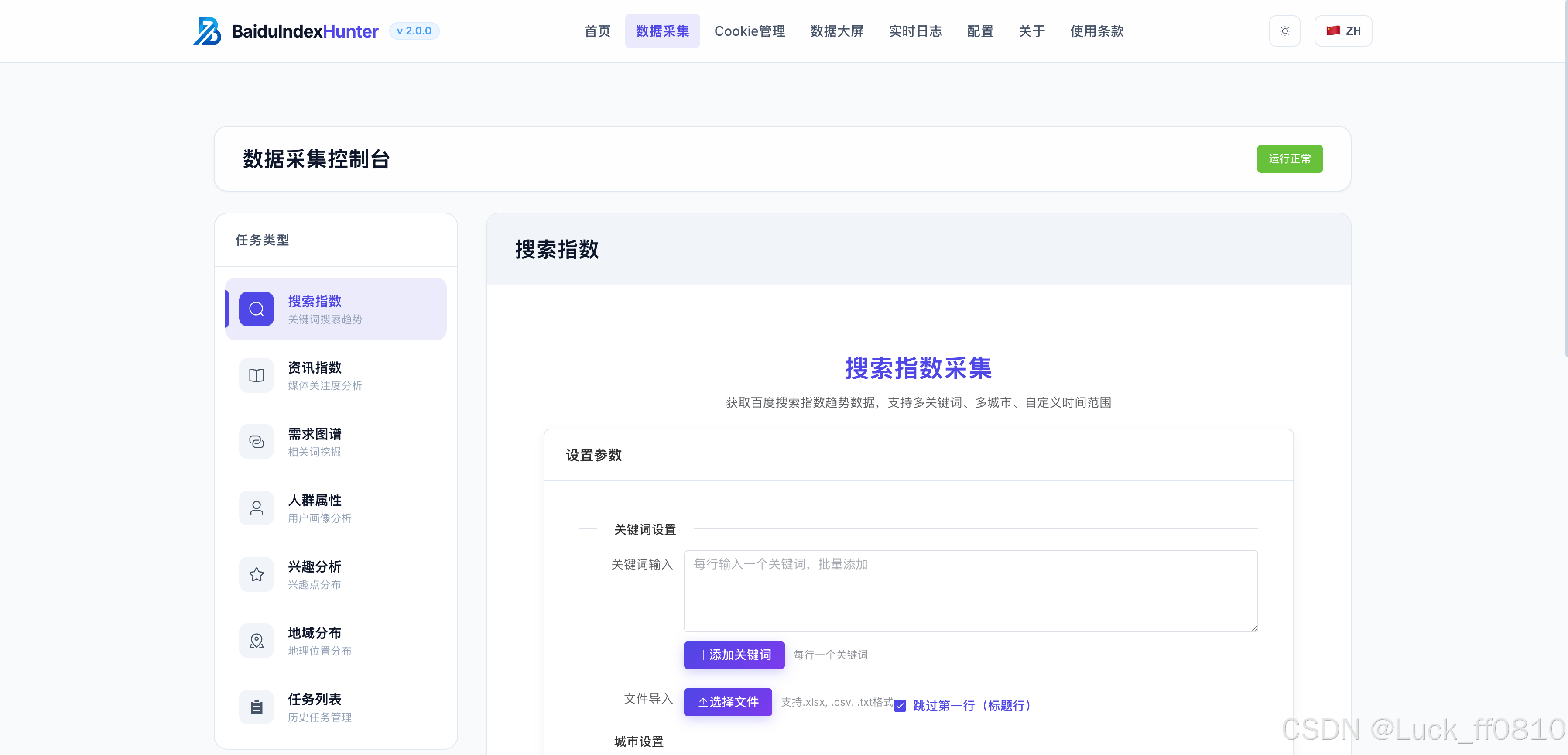
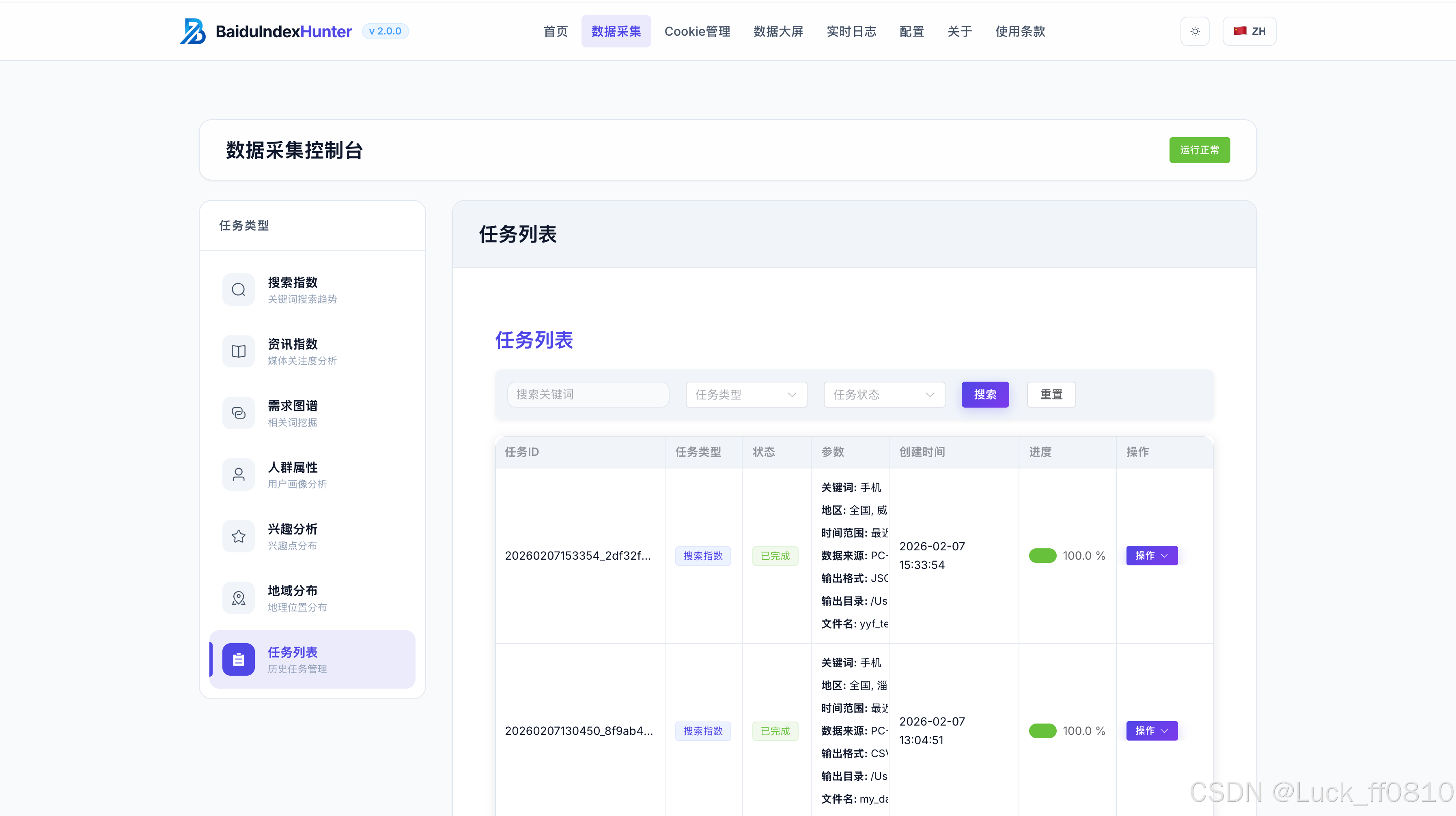
4.2 数据采集页
支持批量关键词采集任务,展示任务列表、采集维度,实时采集进度与即时反馈。包含搜索指数、资讯指数、需求图谱、人群属性、兴趣画像、地域分布等子页面。
 |
 |
|---|
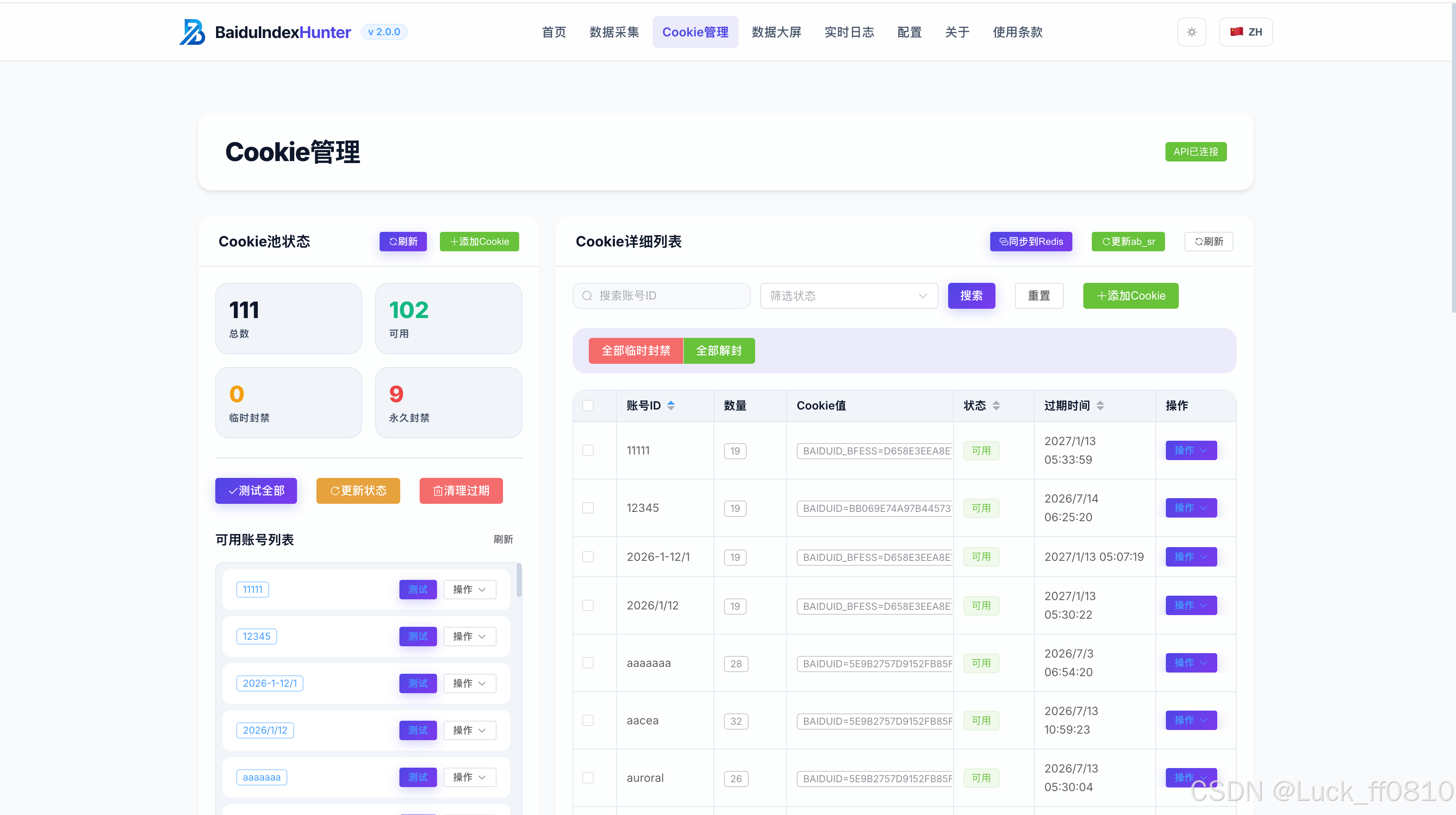
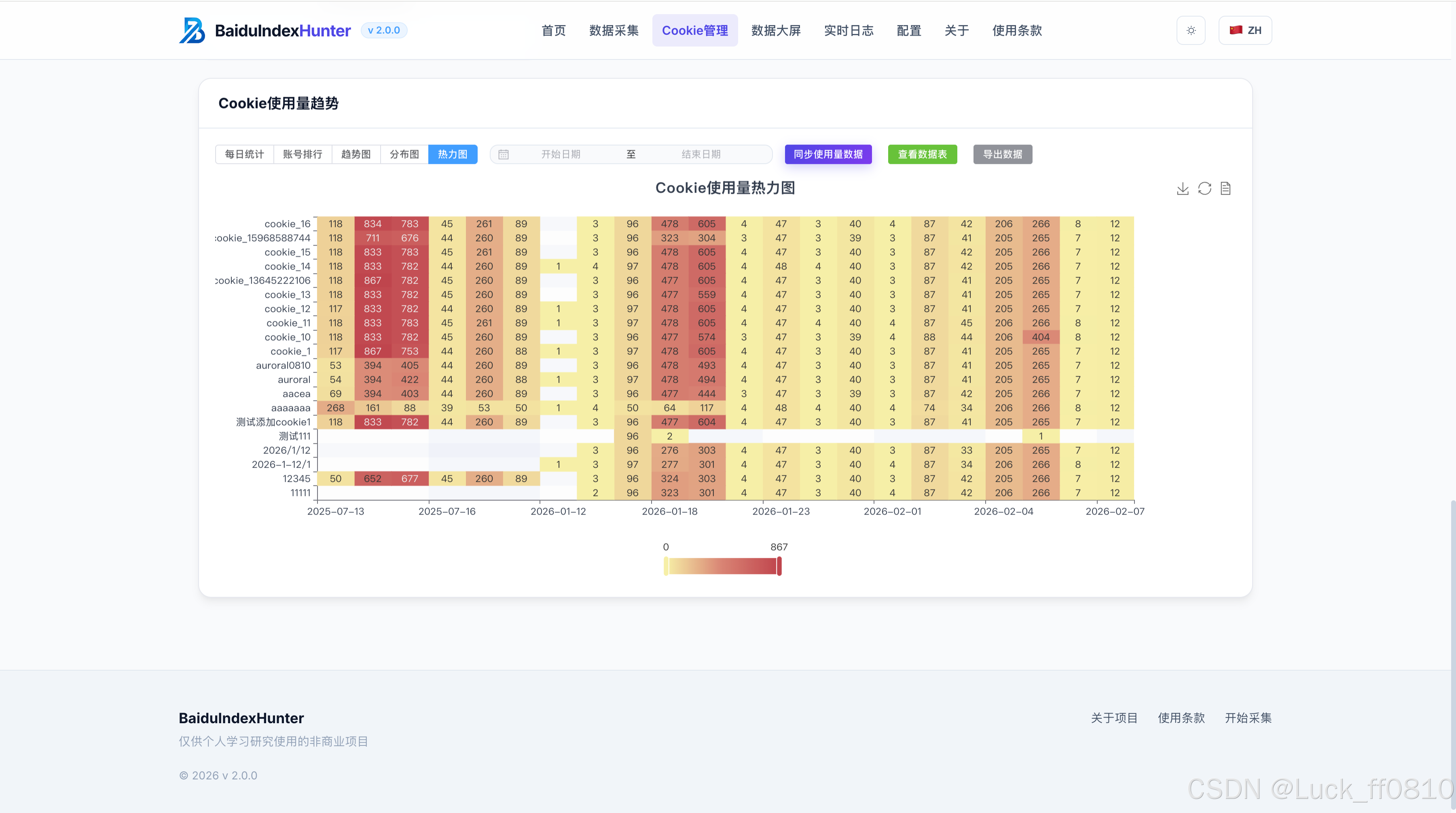
4.3 Cookie 管理页
支持账号与 Cookie 的导入、轮换、状态监控,提供用量统计及状态可视化。
 |
 |
|---|
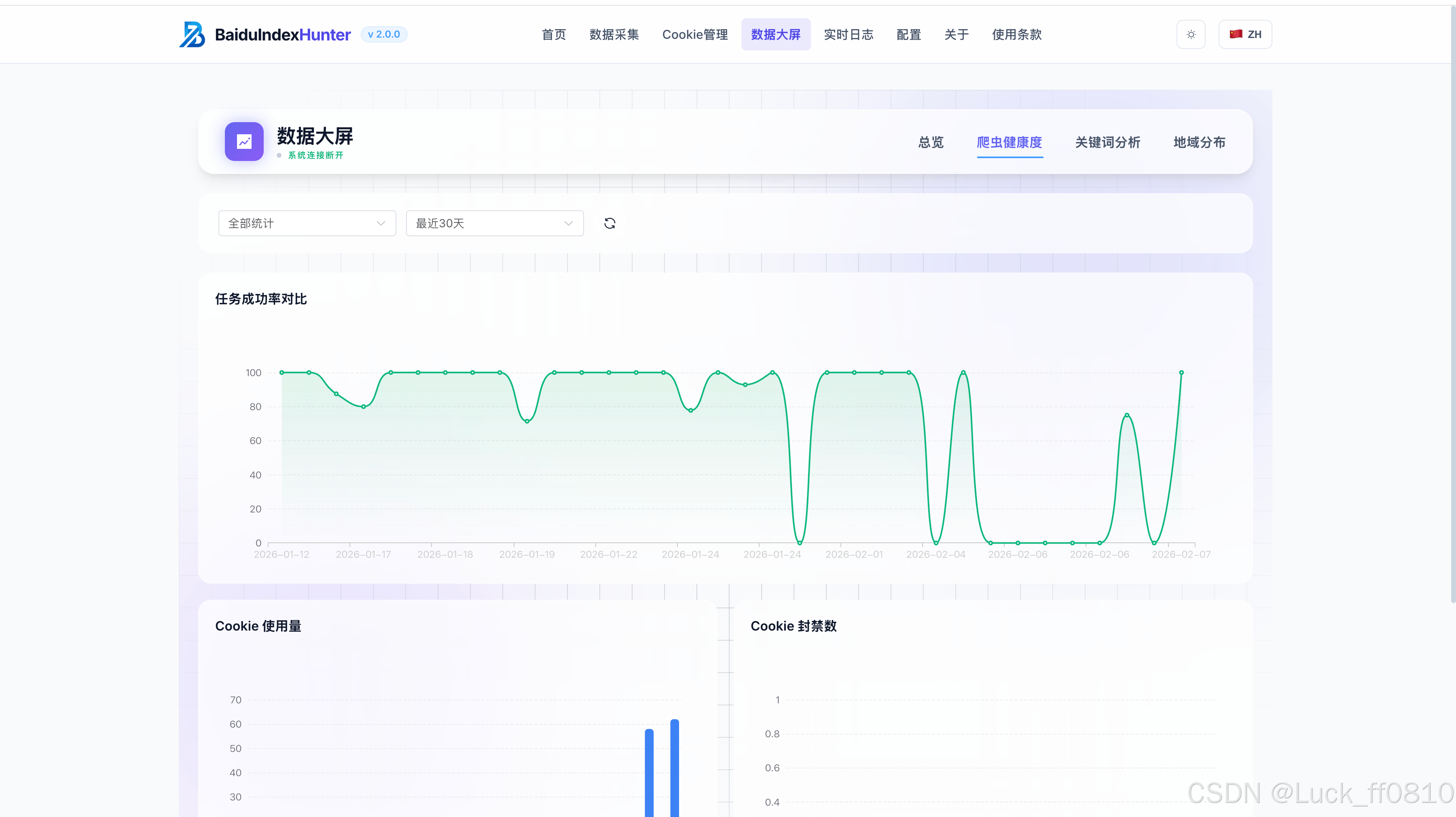
4.4 数据可视化页(数据大屏)
多维展示采集与分析结果,包含关键词分析、任务进展、趋势图等可视化面板。
 |
 |
|---|
(请插入:static/数据大屏-总览.png、static/数据大屏-关键词分析.png、static/数据大屏-任务完成率.png)
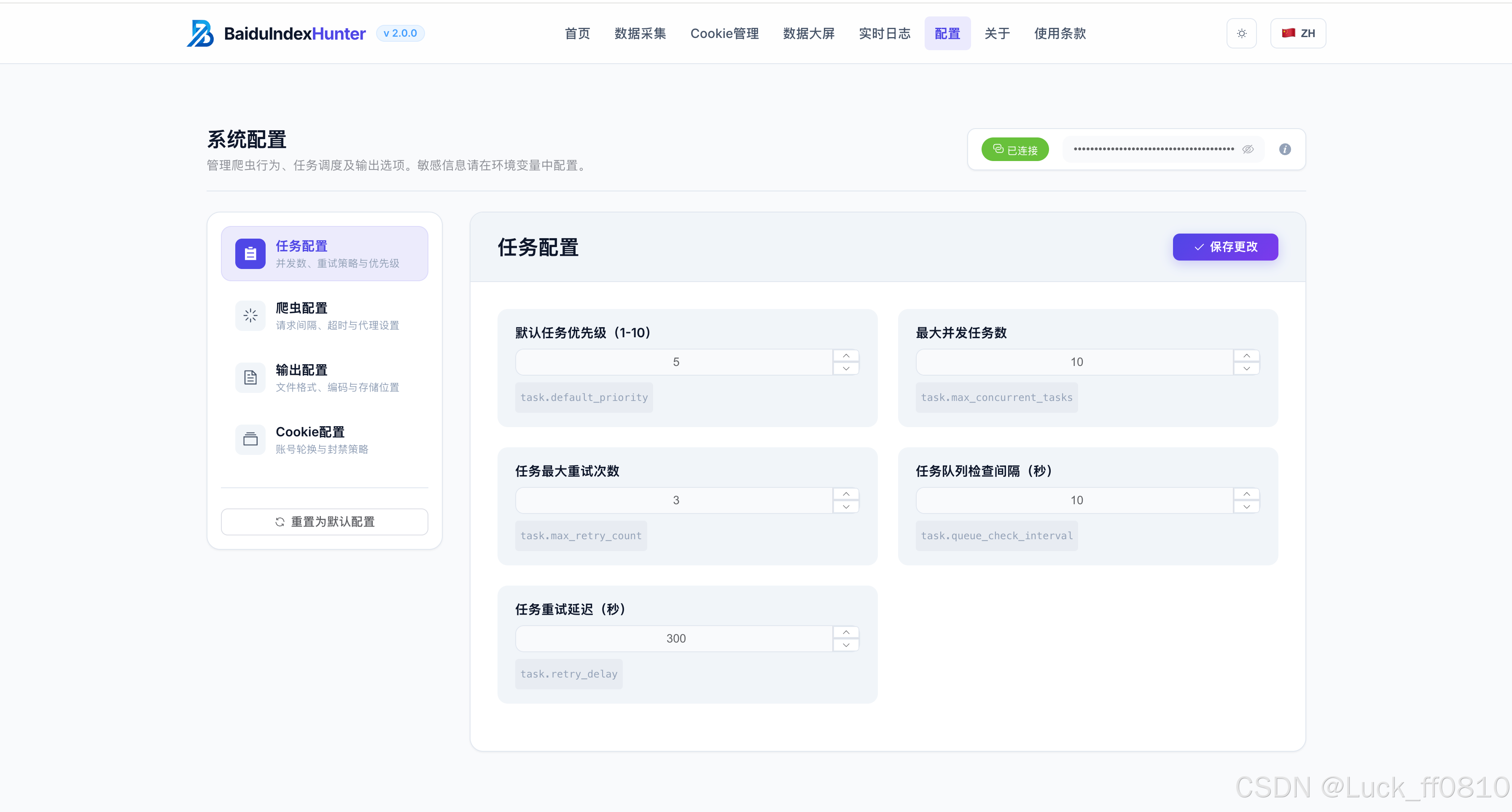
4.5 日志和配置页
系统配置修改、环境信息校验,采集与系统运行日志实时监控。
 |
 |
|---|
4.6 主题与国际化
一键切换暗色/亮色主题,内置多语言界面(9 种语言),支持国际化无障碍体验。
 |
 |
|---|
4.7 采集数据示例
展示年度、日度等不同粒度的数据样例,辅助理解采集与分析能力。
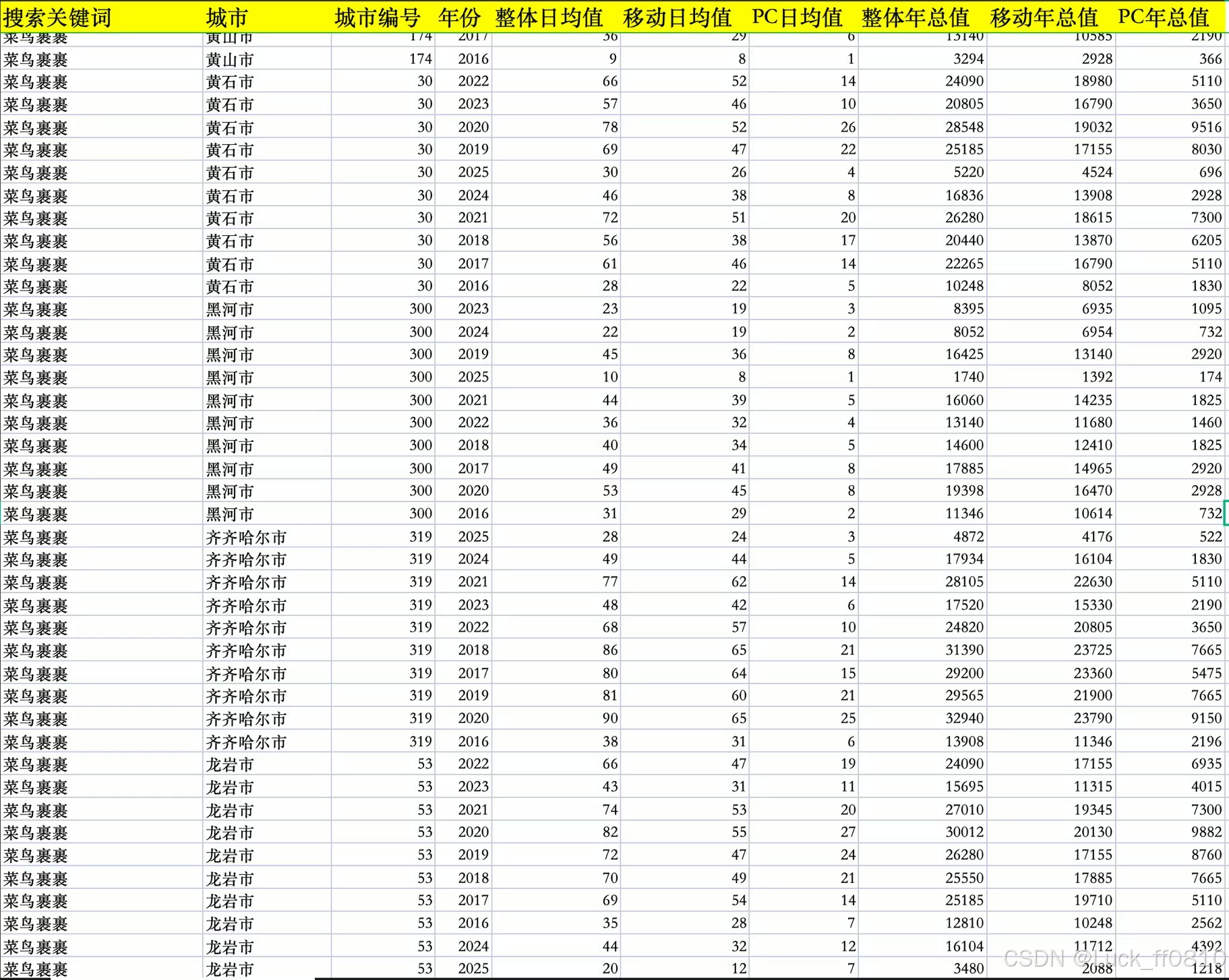 |
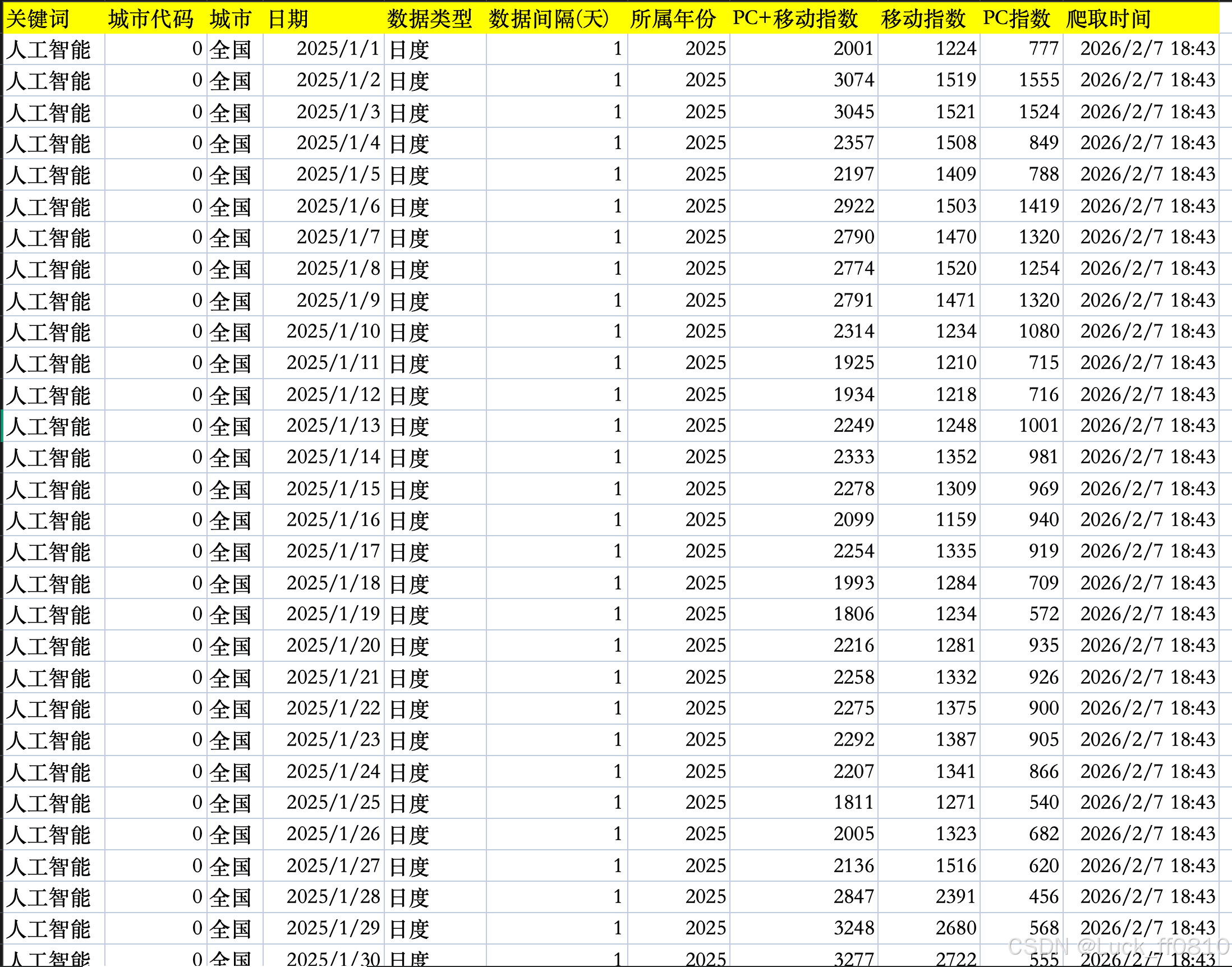 |
|---|
五、环境要求与准备
5.1 操作系统
| 平台 | 要求 |
|---|---|
| Windows | 10 / 11 |
| macOS | 10.14 或更高版本 |
| Linux | Ubuntu 18.04+ / CentOS 7+ / Debian 9+ |
5.2 必需软件
| 软件 | 最低版本 | 推荐版本 |
|---|---|---|
| Python | 3.11 | 3.11.x |
| Node.js | 18.0 | 18.x 或 21.x |
| MySQL | 8.0 | 8.x |
| Redis | 7.4 | 7.4 |
Windows 用户说明:
- Node.js 推荐使用 nvm-windows 管理多版本,安装后执行
nvm install 21、nvm use 21使用 Node 21。 - Redis 在 Windows 下可使用 Memurai 替代,安装后需确保
memurai-cli ping返回PONG。
5.3 环境验证
在终端执行以下命令,确认版本与服务正常:
bash
# 验证 Python(应为 3.11.x)
python --version
# 或 python3 --version
# 验证 Node.js(应为 v18.x 或 v21.x)
node --version
# 验证 MySQL(应为 8.x)
mysql --version
# 验证 Redis(Linux/macOS 为 redis-cli,Windows 为 memurai-cli,应返回 PONG)
redis-cli ping
# 或 memurai-cli ping六、配置
6.1 初始化数据库
在项目根目录下执行:
bash
# 登录 MySQL(输入密码)
mysql -u root -p在 MySQL 命令行中执行(注意路径,从项目根目录执行时使用以下路径):
sql
source baidu-index-hunter-backend/scripts/BaiduIndexHunter.sql
exit若当前已在 baidu-index-hunter-backend 目录下,则使用:
sql
source scripts/BaiduIndexHunter.sql
exit6.2 配置环境变量
- 进入后端目录:
baidu-index-hunter-backend/config/ - 将
.env.example复制为.env - 编辑
.env,至少修改以下必填项:
| 配置项 | 说明 |
|---|---|
MYSQL_PASSWORD |
替换为你的 MySQL 登录密码,禁止使用占位符 |
API_SECRET_KEY |
替换为随机生成的复杂密钥(用于 API 鉴权),禁止使用「请修改此密钥」等占位文字 |
- 其他配置(Redis 地址、Flask 端口、爬虫参数、输出目录等)可按需调整,完整说明见
config/.env.example。
重要 :启动前会校验
MYSQL_PASSWORD和API_SECRET_KEY,若使用占位值会导致启动失败。
七、安装依赖
7.1 后端依赖
bash
# 进入后端目录
cd baidu-index-hunter-backend
# 创建 Python 虚拟环境(推荐,目录名可为 venv 或 baiduindexhunter)
python -m venv venv
# 激活虚拟环境
# Windows (CMD)
venv\Scripts\activate
# Windows (PowerShell)
venv\Scripts\Activate.ps1
# macOS / Linux
source venv/bin/activate
# 安装依赖
pip install -r requirements.txt
# 若安装较慢,可使用国内镜像
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple7.2 前端依赖
bash
# 进入前端目录
cd baidu-index-hunter-frontend
# 安装依赖
npm install
# 若安装较慢,可先切换国内镜像
npm config set registry https://registry.npmmirror.com
npm install八、启动服务
需同时启动后端和前端,建议使用两个终端窗口。
8.1 启动后端
终端一:
bash
cd baidu-index-hunter-backend
# 激活虚拟环境(若未激活)
# Windows: venv\Scripts\activate
# macOS/Linux: source venv/bin/activate
# 启动后端服务
python app.py启动成功标志:终端输出类似以下内容:
成功连接到MySQL和Redis
任务调度器启动成功
启动应用,地址: http://0.0.0.0:5001
API文档地址: http://0.0.0.0:5001/api/docs/8.2 启动前端
终端二:
bash
cd baidu-index-hunter-frontend
# 启动前端开发服务器
npm run dev启动成功标志:终端输出类似:
VITE v5.x.x ready in xxx ms
➜ Local: http://localhost:5173/8.3 一键启动(macOS / Linux)
项目根目录下提供 start.sh 脚本,可自动检查环境、安装依赖(若缺失)并先后启动后端与前端:
bash
chmod +x start.sh
./start.sh按 Ctrl+C 可同时停止后端与前端。
九、验证安装与首次使用
9.1 验证步骤
| 步骤 | 操作 | 预期结果 |
|---|---|---|
| 1 | 浏览器访问 http://localhost:5001/api/health |
返回 JSON,包含 status: "UP" |
| 2 | 浏览器访问 http://localhost:5173/ |
显示项目首页 |
| 3 | 前端 → 左侧菜单「系统配置」 | 能正常加载配置项(说明数据库连接正常) |
| 4 | 前端 → 「Cookie 管理」→ 添加 Cookie | 能成功添加(需先登录百度指数,从浏览器开发者工具复制 Cookie) |
| 5 | 前端 → 「搜索指数采集」→ 测试一个简单关键词 | 任务能创建并执行,有进度反馈 |
9.2 Cookie 获取方式
- 登录 百度指数
- 按 F12 打开浏览器开发者工具
- 切换到「Application 」或「存储 」→ Cookies → 选择
index.baidu.com - 复制所有 Cookie 键值对,粘贴到项目前端的「Cookie 管理」页面中保存
完成上述步骤后,即可在「搜索指数采集」「资讯指数采集」等页面创建任务并开始采集。
十、常见问题
| 问题 | 可能原因 | 处理建议 |
|---|---|---|
| 后端启动失败,提示环境变量校验错误 | MYSQL_PASSWORD 或 API_SECRET_KEY 使用占位值 |
修改 baidu-index-hunter-backend/config/.env,填写真实 MySQL 密码和随机生成的 API 密钥 |
| 无法连接 MySQL | 密码错误、MySQL 未启动、端口非 3306 | 检查 MySQL 服务是否启动、密码是否正确、端口是否与 .env 中一致 |
| 无法连接 Redis | Redis 未启动、Windows 未安装 Memurai | 启动 Redis 服务;Windows 用户安装并启动 Memurai,确保 memurai-cli ping 返回 PONG |
| 前端请求 401 | 前端未配置 API_SECRET_KEY |
在「系统配置」→「API 连接」中填写与后端 .env 中一致的 API_SECRET_KEY;或在前端 .env 中配置 VITE_API_SECRET_KEY |
十一、项目代码结构概览
以下为提交到 Git 的主要目录与文件(已排除 node_modules、venv、logs、output、.env 等)。
-
baidu-index-hunter-backend/:后端 Flask 应用
app.py:Flask 主入口config/.env.example:环境变量示例scripts/BaiduIndexHunter.sql:数据库建表与初始化脚本src/api/:REST API 层(schemas、v1 控制器)src/core/:鉴权、配置、日志、Redis、环境校验src/data/:数据库、ORM 模型、Repository、静态区域数据src/engine/:爬虫引擎(crypto 加密、processors 解析、spider 各类型爬虫)src/scheduler/:任务调度与执行器src/services/:任务、Cookie、配置、存储、进度、WebSocket 等业务服务tests/:单元测试与集成测试
-
baidu-index-hunter-frontend/:前端 Vue 3 SPA
src/views/:首页、数据采集、Cookie 管理、数据大屏、日志、配置、关于等页面src/components/:目录选择器、区域选择器、Cookie 用量图表、各任务创建组件与任务列表src/store/:Pinia 状态(主题、语言、配置、区域、需求图谱)src/api/、src/utils/:API 封装、鉴权拦截器、WebSocketsrc/i18n/:9 种语言国际化
-
static/:README 与博客用图片、演示资源
-
start.sh:一键启动脚本(后端+前端)
-
README.md / README_EN.md:中英文说明
-
CONTRIBUTING.md / CONTRIBUTING_en.md:贡献指南
-
LICENSE:非商业许可协议
十二、免责声明
- 合规性:本项目中的所有代码、工具和功能均仅供学习、学术研究和教育目的使用;严禁用于任何商业用途、盈利性活动以及任何违法、违规或侵犯他人权益的行为。
- 爬虫功能:爬虫功能仅用于技术学习和研究;使用者必须遵守目标网站的 robots.txt 与使用条款及相关法律法规;因使用爬虫功能产生的任何法律后果由使用者自行承担。
- 数据使用:项目涉及的数据分析功能仅供学术研究使用;严禁将分析结果用于商业决策或盈利目的;使用者应确保所分析数据的合法性和合规性。
- 技术:本项目按"现状"提供,不提供任何明示或暗示的保证;作者不对使用本项目造成的任何直接或间接损失承担责任;使用者应自行评估适用性与风险。
- 责任限制:使用者在使用前应充分了解相关法律法规,并确保使用行为符合当地法律法规;因违反法律法规使用本项目而产生的任何后果由使用者自行承担。
使用本项目即表示您已阅读并同意上述条款。
十三、许可证与联系
- 许可证 :本项目采用 EULA 非商业许可协议,详见仓库 LICENSE 文件。
- 项目地址 :https://github.com/Auroral0810/BaiduIndexHunter
- 中文文档 :仓库
README.md - 英文文档 :仓库
README_EN.md - 贡献指南 :
CONTRIBUTING.md(中文)、CONTRIBUTING_en.md(英文)
联系作者:微信 Lucky_ff0810 / QQ 1957689514 / Email 15968588744@163.com
如果这个项目对你有帮助,欢迎在 GitHub 给一个 ⭐ Star 支持,感谢。