我是一个技术人,既不是那种天天需要写代码的,也不是那种天天都不写代码的,Coding纯属兴趣,不求完全靠这个吃饭,只求在探索的过程中找到自己的快乐。正如网名所示,我的文风将会是"流水账",因为我相信,技术的探索永远在过程中,如果有人在乎过程,那么经过一定提炼的探索流水账,将比一个精炼的总结更有价值。
这么苦我该怎么办
尝过之前面试的版本的苦,和上面的这些苦之后,我想要有所改变,由于之前做过AI方面的小应用,我知道这个时候我们需要做的就是,尽可能多的提供给AI它没有的信息,在这里就是最新版本的特性和代码样例,那么应该用什么方式去呈现呢?我最先想到的是MCP,如果AI在Vibe Coding的过程中知道它可能不知道,那么应该就有可能会去想办法去找相关的新特性和代码样例,然后在代码样例的指导下进行编码,MCP应该就是这么一个让AI在运行过程中可以去调用外部工具的接口。
那么下面就出现了2个问题:
- 这些特性和代码样例去哪里找?
- 找来了这些信息怎么通过MCP来提供服务呢?
于是我尝试请教Gemini,先说结论,首先现在似乎没有一站式的方案,但是分成两步的话还是有一些办法的。对于第一个问题,新版本的特性和代码样例基本在库文档或生成式文档里都有,但是怎么爬下来是个问题,下面我们就说说怎么爬文档的问题。
文档的爬取
Gemini给出的方案基本上就是两种,SaaS平台的文档爬取和装在本地的爬取库,爬下来之后都能转成markdown。这里我实际尝试了两个,分别是:
- SaaS方案: www.firecrawl.dev/
- 一定用量以下免费,但是基本每月只够爬500篇
- 还支持一些AI现场爬的方案,单独收费
- 支持通过MCP+AI现场爬,但是似乎不支持MCP+已经爬好的内容
- 这个firecrawl也开源本地部署,但是那个Docker Compose的构建过程很漫长,也有各种报错(我用的是一个已经不能再更新的老Mac,就不要再折腾自己了),我也是试了一下就放弃了。
- 本地方案: Crawl4ai
- 这个是Python的库,各种爬取方式和过滤也都支持,效果也不差,关键是也不要钱,效果嘛,过会儿我们一起看。
- 用起来倒是很方便,让AI帮忙写一段调用代码,写一个文档的根目录,写一个过滤前缀就可以了。
AI告诉我Cursor内置的应该也是firecrawl的方案,所以这个SaaS还收钱应该差不了,我实际尝试让它去爬了一些LangChain的文档,效果还不错。但是额度用的太快,不交钱估计是用不了了。
而在去试Crawl4ai的时候,需要考虑的一个问题就是这个跑在哪的问题,本来常用的文档都在外面,而爬取本来来回通信就要走很多次,又有可能很容易被墙,考虑了一会儿,我想到的一个好地方是: Google Colab。
有人可能要说我怎么这么喜欢G家的产品,而事实是,G家确实提供了太多成本低(很多都免费)又开放的方案给开发者,让我们自由去发挥。Google Colab的核心就是一个在线的Jupyter Notebook,运行在临时分配的虚拟机上,初衷应该还是做ML/AI和科学计算相关的内容,而你纯粹把它当成一个在线的,在外面的Jupyter Notebook也完全没有问题。这里安利的一点是,这个Jupyter Notebook可以提供免费的GPU使用额度,所以如果你想用它浅浅尝试一下LLM的微调甚至BERT的小规模预训练也未尝不可。在这里我通过Jupyter Notebook挂载Google Drive的方式,就可以让Colab帮我去爬对应页面,只要设好sleep间隔,爬了几千页也没有被墙。
下面分享我的Jupyter的爬取Kubernetes JavaScript SDK文档(没错,我把文档host到一个github.io上了)爬取代码:
python
!pip install crawl4ai # 安装crawl4ai,建议把这一行单独写一个代码框,因为首次运行后可能需要点击重启CoLab的Runtime
!crawl4ai-setup # crawl4ai初始化
from google.colab import drive
drive.mount('/content/drive') # 挂载Google Drive网盘
import asyncio
import os
import re
from urllib.parse import urlparse
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
# ==================== 配置区 ====================
# 1. 目标与范围
BASE_URL = "https://zhibinyang.github.io/kubernetes-client-node-docs-v1.4-unofficial/modules/index.html"
PREFIX = "https://zhibinyang.github.io/kubernetes-client-node-docs-v1.4-unofficial/"
# 2. 后缀过滤 (设置为 None 或 [] 则不过滤后缀,抓取前缀下的所有页面)
ALLOWED_EXTENSIONS = ['.html', '.htm']
# 3. 存储设置
OUTPUT_DIR = "/content/drive/MyDrive/Docs/Kubernetes-Node"
TRACKER_FILE = os.path.join(OUTPUT_DIR, "crawled_urls.txt")
# 4. 爬取偏好
SLEEP_TIME = 1.0 # 间隔秒数
# ===============================================
os.makedirs(OUTPUT_DIR, exist_ok=True)
def clean_url(url):
"""去除锚点和查询参数,确保唯一性"""
return url.split('#')[0].split('?')[0].rstrip('/')
def should_crawl(url, prefix, processed_set, allowed_exts):
"""判断一个 URL 是否符合爬取条件"""
cleaned = clean_url(url)
# 基本条件:没爬过且符合前缀
if cleaned in processed_set or not cleaned.startswith(prefix):
return False
# 后缀条件:如果设置了过滤列表,则必须匹配其中之一
if allowed_exts:
path = urlparse(cleaned).path
# 处理 index 情况:如果路径以 / 结尾,通常对应 index.html
if path.endswith('/') or not os.path.basename(path):
return True
return any(path.lower().endswith(ext.lower()) for ext in allowed_exts)
return True
def get_file_name(url):
"""通用命名逻辑:取最后两级路径名"""
path = urlparse(clean_url(url)).path.strip('/')
# 移除所有已知的扩展名后缀,便于统一存为 .md
if ALLOWED_EXTENSIONS:
for ext in ALLOWED_EXTENSIONS:
path = re.sub(re.escape(ext) + r'$', '', path, flags=re.IGNORECASE)
parts = [p for p in path.split('/') if p]
if len(parts) >= 2:
name = f"{parts[-2]}-{parts[-1]}"
elif len(parts) == 1:
name = parts[0]
else:
name = "index"
return re.sub(r'[^\w\-]', '_', name) + ".md"
async def universal_crawler():
# 1. 加载进度
processed_urls = set()
if os.path.exists(TRACKER_FILE):
with open(TRACKER_FILE, 'r') as f:
processed_urls = set(line.strip() for line in f if line.strip())
# 2. 爬虫配置
browser_config = BrowserConfig(headless=True)
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
word_count_threshold=100,
remove_overlay_elements=True
)
async with AsyncWebCrawler(config=browser_config) as crawler:
queue = [BASE_URL]
while queue:
current_raw_url = queue.pop(0)
current_url = clean_url(current_raw_url)
# 再次检查(防止队列中存在重复)
if current_url in processed_urls:
continue
print(f"🚀 Processing: {current_url}")
result = await crawler.arun(url=current_url, config=run_config)
if result.success:
# A. 保存文件
file_name = get_file_name(current_url)
file_path = os.path.join(OUTPUT_DIR, file_name)
with open(file_path, "w", encoding="utf-8") as f:
f.write(result.markdown)
# B. 更新追踪器
processed_urls.add(current_url)
with open(TRACKER_FILE, "a") as f:
f.write(current_url + "\n")
# C. 发现新链接
for link in result.links.get("internal", []):
link_url = clean_url(link['href'])
if should_crawl(link_url, PREFIX, processed_urls, ALLOWED_EXTENSIONS):
queue.append(link_url)
else:
print(f"❌ Failed: {current_url} - {result.error_message}")
await asyncio.sleep(SLEEP_TIME)
# 运行
await universal_crawler()CoLab相对来说有一个限制就是,它需要你保持浏览器开启且网络持续连接,才能保留你的资源,对于这种程度的资源,基本上全天一直开着也不是问题,但是如果网络断了超过30分钟,那么资源就会被释放,而你的脚本就停止了,所以上面的脚本一定程度上也考虑了重传,但是因为没有存下来原始的页面HTML,所以即使要继续也只能复用之前爬过的页面列表,而需要换一个页面入口。
上面的代码里的Kubernetes的文档我是第二波爬的,第一波爬的是LangChain.js和LangGraph.js的全站文档,大概400多页,而当我在跑Kubernetes的时候,我已经测试完了LangChain.js爬取后查询的效果,看了结果之后我就没有一直开机让Kubernetes跑完,我就拿一篇爬下来的文档给大家先看看,下一节我们再说说用MCP提供服务。
md
On this page
* [Create tools](https://docs.langchain.com/oss/javascript/langchain/tools#create-tools)
* [Basic tool definition](https://docs.langchain.com/oss/javascript/langchain/tools#basic-tool-definition)
* [Accessing Context](https://docs.langchain.com/oss/javascript/langchain/tools#accessing-context)
* [Context](https://docs.langchain.com/oss/javascript/langchain/tools#context)
* [Memory (Store)](https://docs.langchain.com/oss/javascript/langchain/tools#memory-store)
* [Stream Writer](https://docs.langchain.com/oss/javascript/langchain/tools#stream-writer)
[Core components](https://docs.langchain.com/oss/javascript/langchain/agents)
# Tools
Copy page
Copy page
Tools extend what [agents](https://docs.langchain.com/oss/javascript/langchain/agents) can do---letting them fetch real-time data, execute code, query external databases, and take actions in the world. Under the hood, tools are callable functions with well-defined inputs and outputs that get passed to a [chat model](https://docs.langchain.com/oss/javascript/langchain/models). The model decides when to invoke a tool based on the conversation context, and what input arguments to provide.
For details on how models handle tool calls, see [Tool calling](https://docs.langchain.com/oss/javascript/langchain/models#tool-calling).
## Create tools
### Basic tool definition
The simplest way to create a tool is by importing the `tool` function from the `langchain` package. You can use [zod](https://zod.dev/) to define the tool's input schema:
```
import * as z from "zod"
import { tool } from "langchain"
const searchDatabase = tool(
({ query, limit }) => `Found ${limit} results for '${query}'`,
{
name: "search_database",
description: "Search the customer database for records matching the query.",
schema: z.object({
query: z.string().describe("Search terms to look for"),
limit: z.number().describe("Maximum number of results to return"),
}),
}
);
```
**Server-side tool use** Some chat models (e.g., [OpenAI](https://docs.langchain.com/oss/javascript/integrations/chat/openai), [Anthropic](https://docs.langchain.com/oss/javascript/integrations/chat/anthropic), and [Gemini](https://docs.langchain.com/oss/javascript/integrations/chat/google_generative_ai)) feature [built-in tools](https://docs.langchain.com/oss/javascript/langchain/models#server-side-tool-use) that are executed server-side, such as web search and code interpreters. Refer to the [provider overview](https://docs.langchain.com/oss/javascript/integrations/providers/overview) to learn how to access these tools with your specific chat model.
## Accessing Context
**Why this matters:** Tools are most powerful when they can access agent state, runtime context, and long-term memory. This enables tools to make context-aware decisions, personalize responses, and maintain information across conversations.The runtime context provides a structured way to supply runtime data, such as DB connections, user IDs, or config, into your tools. This avoids global state and keeps tools testable and reusable.
#### Context
Tools can access an agent's runtime context through the `config` parameter:
```
import * as z from "zod"
import { ChatOpenAI } from "@langchain/openai"
import { createAgent } from "langchain"
const getUserName = tool(
(_, config) => {
return config.context.user_name
},
{
name: "get_user_name",
description: "Get the user's name.",
schema: z.object({}),
}
);
const contextSchema = z.object({
user_name: z.string(),
});
const agent = createAgent({
model: new ChatOpenAI({ model: "gpt-4o" }),
tools: [getUserName],
contextSchema,
});
const result = await agent.invoke(
{
messages: [{ role: "user", content: "What is my name?" }]
},
{
context: { user_name: "John Smith" }
}
);
```
#### Memory (Store)
Access persistent data across conversations using the store. The store is accessed via `config.store` and allows you to save and retrieve user-specific or application-specific data.
```
import * as z from "zod";
import { createAgent, tool } from "langchain";
import { InMemoryStore } from "@langchain/langgraph";
import { ChatOpenAI } from "@langchain/openai";
const store = new InMemoryStore();
// Access memory
const getUserInfo = tool(
async ({ user_id }) => {
const value = await store.get(["users"], user_id);
console.log("get_user_info", user_id, value);
return value;
},
{
name: "get_user_info",
description: "Look up user info.",
schema: z.object({
user_id: z.string(),
}),
}
);
// Update memory
const saveUserInfo = tool(
async ({ user_id, name, age, email }) => {
console.log("save_user_info", user_id, name, age, email);
await store.put(["users"], user_id, { name, age, email });
return "Successfully saved user info.";
},
{
name: "save_user_info",
description: "Save user info.",
schema: z.object({
user_id: z.string(),
name: z.string(),
age: z.number(),
email: z.string(),
}),
}
);
const agent = createAgent({
model: new ChatOpenAI({ model: "gpt-4o" }),
tools: [getUserInfo, saveUserInfo],
store,
});
// First session: save user info
await agent.invoke({
messages: [
{
role: "user",
content: "Save the following user: userid: abc123, name: Foo, age: 25, email: foo@langchain.dev",
},
],
});
// Second session: get user info
const result = await agent.invoke({
messages: [
{ role: "user", content: "Get user info for user with id 'abc123'" },
],
});
console.log(result);
// Here is the user info for user with ID "abc123":
// - Name: Foo
// - Age: 25
// - Email: foo@langchain.dev
```
#### Stream Writer
Stream custom updates from tools as they execute using `config.streamWriter`. This is useful for providing real-time feedback to users about what a tool is doing.
```
import * as z from "zod";
import { tool, ToolRuntime } from "langchain";
const getWeather = tool(
({ city }, config: ToolRuntime) => {
const writer = config.writer;
// Stream custom updates as the tool executes
if (writer) {
writer(`Looking up data for city: ${city}`);
writer(`Acquired data for city: ${city}`);
}
return `It's always sunny in ${city}!`;
},
{
name: "get_weather",
description: "Get weather for a given city.",
schema: z.object({
city: z.string(),
}),
}
);
```
* * *
[Edit this page on GitHub](https://github.com/langchain-ai/docs/edit/main/src/oss/langchain/tools.mdx) or [file an issue](https://github.com/langchain-ai/docs/issues/new/choose).
[Connect these docs](https://docs.langchain.com/use-these-docs) to Claude, VSCode, and more via MCP for real-time answers.
Was this page helpful?
YesNo
[ Messages Previous ](https://docs.langchain.com/oss/javascript/langchain/messages)[ Short-term memory Next ](https://docs.langchain.com/oss/javascript/langchain/short-term-memory)
[](https://docs.langchain.com/)
[](https://github.com/langchain-ai)[](https://x.com/LangChainAI)[](https://www.linkedin.com/company/langchain/)[](https://www.youtube.com/@LangChain)
Resources
[Forum](https://forum.langchain.com/)[Changelog](https://changelog.langchain.com/)[LangChain Academy](https://academy.langchain.com/)[Trust Center](https://trust.langchain.com/)
Company
[About](https://langchain.com/about)[Careers](https://langchain.com/careers)[Blog](https://blog.langchain.com/)
[](https://github.com/langchain-ai)[](https://x.com/LangChainAI)[](https://www.linkedin.com/company/langchain/)[](https://www.youtube.com/@LangChain)
[Powered by](https://www.mintlify.com?utm_campaign=poweredBy&utm_medium=referral&utm_source=langchain-5e9cc07a)
Assistant
Responses are generated using AI and may contain mistakes.爬完了我怎么用
数据花了很大的功夫趴下来了,总得赶快用MCP去服务一下,本着不造轮子的原则,我需要考虑怎么用尽可能简单的方法提供这个服务。这个时候我把目光放到了我之前用了一段时间的一个软件上------Obisidian
Obsidian是免费的Markdown笔记软件,有很丰富的插件生态,之前我用过里面一个也叫Copilot的插件就很不错,它通过内置的向量数据库,结合Embedding Model的API(来自OpenAI或者火山这样的外部提供商),在配合BYOK的LLM API的总结,可以实现比较完整的个人知识库向量搜索+总结的效果。而因为是笔记软件,所以对于Markdown的渲染本来就是内置功能。
那么如果有一个插件,可以实现向量数据库+Embedding Model的连接,对外又能提供MCP,那么我不是既能在Obsidian里管理我的文档(通过Review查看文档内容,然后及时编辑),又能对接AI实现知识库的查询。查了一圈,虽然内置的有一个类似的MCP工具叫做MCP Tools,但是它似乎不支持向量搜索,我又找到一个叫做MCP Server的,它不在Obsidian的插件商店里,而需要从Github上Clone并构建,并将关键文件手动复制到Obsidian的插件目录下。
bash
https://github.com/Minhao-Zhang/obsidian-mcp-server这个插件有比较完整的RAG知识库的影子,比如可设置OpenAI API兼容的Embedding模型,分Chunk,Chunk间设置Overlap, 设置similarity阈值,设置召回的文档个数等,这不就是现成的方案?但是开始没有发现,之后才注意到有个严重的问题是,这个插件不支持增量更新,也就是说如果要加一篇文档,需要重新构建整个向量数据库,如果文档多的话,这个API的成本也不低。
启动后尝试用MCP官方的inspector做了测试:
bash
npx @modelcontextprotocol/inspector使用SSE模式,填入MCP Server里的SSE的地址,然后连接使用Direct。之后列出工具,选择simple_vector_search就可以搜索了

效果如何呢
前面说到了我们使用Crawl4ai爬取了文档,然后又实用Obsidian里的MCP Server插件实现了向量数据库,我们迫不及待的想看看在Vibe Coding里使用的效果怎么样,但是在Inspector中的测试我就看出了问题。
正如正面给出的LangChain文档的Markdown的例子,我们发现文档页面的开始部分有大量的引言,而这些引言包含了大量与LangChain特性相关的关键字,那么如果我们正常使用MCP Server插件的按照1000或2000个字符进行分割的话,这些引言就会成为单独的Chunk。而从向量数据库的角度来说,这些Chunk的的语义密度其实是大于代码块,且引言又包含了跨页面的内容,所以最终用MCP Server接口搜出来的,按照近似度排序,靠前的全是不同页面的引言部分。下面给出上面原始页面的地址,大家可以上去看一看。
ruby
https://docs.langchain.com/oss/javascript/langchain/models引言的截图如下:
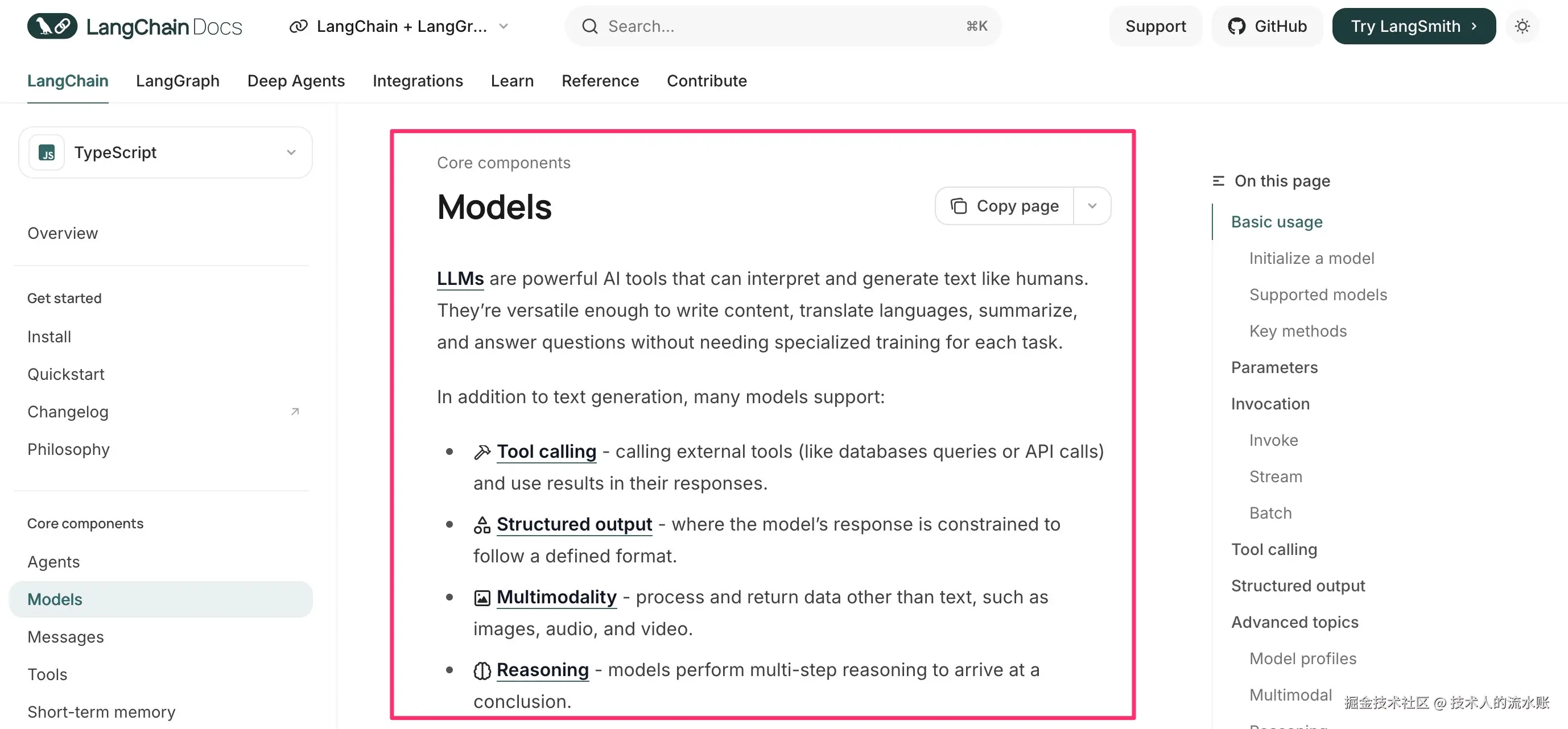
从这个角度看,目前为止我们大费周折终于差一步要跑通的东西似乎效果并不好,那么为了Vibe Coding的效果,我们还能挣扎点什么呢?
有当然是有,效果好不好另说,我们下回接着分解吧。