ConcurrentHashMap是Java并发包中一个线程安全且高效的HashMap实现,通过在JDK 1.8中引入的低粒度锁和CAS操作,实现了卓越的并发性能。
🔄 设计思路演变
ConcurrentHashMap的设计思路经历了重要演变:
- JDK 1.7及之前 :采用分段锁机制,整个哈希表由多个Segment组成,每个Segment独立加锁。这种设计减少了锁竞争,但并发度受Segment数量限制。
- JDK 1.8及之后 :摒弃分段锁,改用
synchronized+CAS+volatile的实现。锁的粒度从Segment级别细化到单个桶(链表头节点/红黑树根节点),显著提升了并发度。其底层数据结构与HashMap类似,都是"数组+链表+红黑树"的组合。
🏗️ 核心数据结构与关键属性
理解ConcurrentHashMap源码,首先要掌握几个核心内部类和关键属性。
核心内部类
-
Node<K,V>:最基础的节点类,代表单个键值对,用于存储普通链表节点。javastatic class Node<K,V> implements Map.Entry<K,V> { final int hash; // 不可变,保证稳定性 final K key; // 不可变 volatile V val; // volatile保证可见性 volatile Node<K,V> next; // volatile保证可见性 } -
TreeNode<K,V>:红黑树的节点类,继承自Node。当链表长度过长时,会转换为红黑树以提升查询效率。 -
TreeBin<K,V>:不直接存储用户数据 ,而是包装红黑树的根节点TreeNode,并持有读写锁,管理对红黑树的并发访问。实际存放在哈希数组中的是TreeBin对象,而非TreeNode。 -
ForwardingNode<K,V>:一个特殊的占位节点(其hash字段固定为MOVED,值为-1)。在扩容数据迁移阶段,旧表中某个桶的元素全部迁移到新表后,会在旧表的这个桶位置放置一个ForwardingNode,其nextTable指针指向新表,用于引导查询和并发迁移。
关键控制属性
sizeCtl:这是一个至关重要的控制标识符,它是一个volatile变量,不同取值有不同含义:-1:表示哈希表table正在初始化。< -1:即-N,表示有N-1个线程正在进行扩容操作。0:表示table还未被初始化。> 0:如果table未初始化,此值代表初始容量;如果table已初始化,此值代表下一次需要扩容的阈值(通常是容量 * 负载因子,默认负载因子0.75)。
⚙️ 核心方法源码解析
🔍 put操作全景图
ConcurrentHashMap的put操作核心在于通过CAS(无锁化尝试) 和 synchronized(细粒度锁) 的结合来实现高性能的线程安全。其主流程如下:
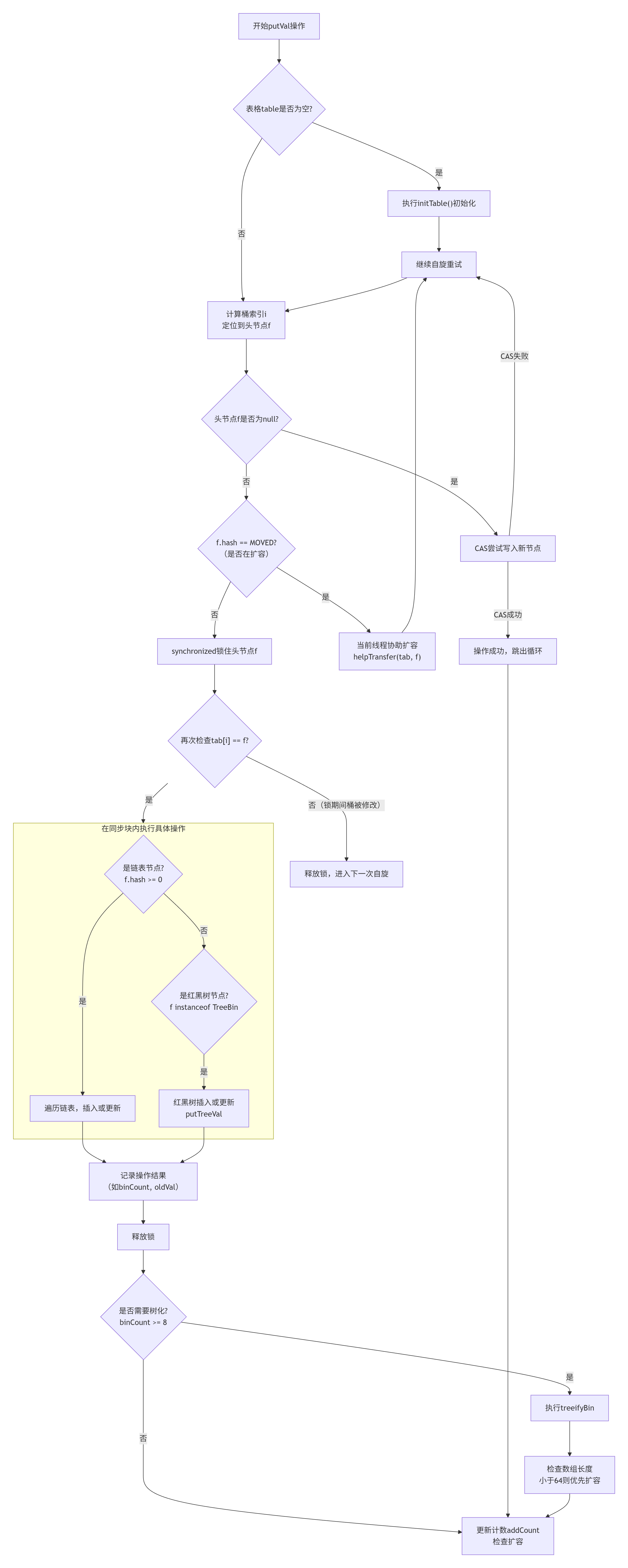
⚙️ 关键步骤与技术解析
对应流程图的每个关键阶段,其背后的实现机制如下:
-
计算哈希与定位桶
首先对key的哈希值进行二次处理(
spread方法),目的是让高位也参与运算,减少哈希冲突。然后通过(n - 1) & hash计算桶的索引i 。 -
初始化表格(initTable)
ConcurrentHashMap采用懒加载 机制,在第一次put时才会初始化数组
table。初始化过程通过一个关键变量sizeCtl来协调 。- 如果
sizeCtl < 0,说明已有其他线程正在初始化,当前线程让出CPU。 - 如果当前线程通过CAS 将
sizeCtl成功设置为-1,则由它执行初始化,创建默认大小为16的数组,并计算新的扩容阈值sizeCtl = 12 (n * 0.75)。
- 如果
-
处理空桶(CAS无锁插入)
如果计算出的桶
f为null,直接使用CAS操作 (casTabAt)将新节点放入该桶。成功则跳出循环,失败则意味着发生竞争,进入下一轮自旋重试 。这是并发高性能的第一个关键点:在无竞争时避免使用锁。 -
识别与协助扩容
如果桶
f的hash标记为MOVED,表示该桶的数据正在迁移到新数组(扩容中)。当前线程不会阻塞,而是调用helpTransfer方法协助数据迁移,加快整体扩容速度 。 -
处理哈希冲突(同步块内操作)
当桶不为空且未在扩容时,进入有锁操作阶段:
- 加锁 :使用
synchronized锁住桶的头节点f,确保同一时间只有一个线程能修改这个链表或树 。 - 安全性复查 :加锁后再次检查
tabAt(tab, i) == f,防止在加锁前该桶已被其他线程修改 。 - 链表操作 :遍历链表。若找到key相同的节点,则根据参数
onlyIfAbsent决定是否更新value;若未找到,则将新节点尾插至链表末端 。 - 红黑树操作 :如果头节点是
TreeBin类型(红黑树的包装器),则调用putTreeVal方法进行树的插入或更新 。
- 加锁 :使用
-
树化判断(treeifyBin)
链表插入后,如果长度达到阈值(
TREEIFY_THRESHOLD=8),会尝试树化。但会先判断当前数组长度是否达到最小树化容量(MIN_TREEIFY_CAPACITY=64)。如果未达到,会优先进行扩容,因为扩容可能直接减少链表长度 。 -
更新计数与扩容检查(addCount)
最后调用
addCount方法。此方法使用CAS和分片计数 (CounterCell)等高并发技巧来更新元素总数。同时检查容量,若超过阈值(sizeCtl),则触发扩容 。
💡 核心设计思想总结
| 阶段 | 核心技术 | 设计目标 |
|---|---|---|
| 初始化/空桶插入 | CAS | 无锁化提升性能,避免线程阻塞。 |
| 哈希冲突处理 | synchronized(锁桶头节点) | 细粒度锁,仅锁住冲突点,不同桶的操作可并行。 |
| 扩容 | 多线程协助迁移 (helpTransfer) |
并发扩容,将扩容压力分摊到多个线程,避免单点瓶颈。 |
ConcurrentHashMap通过这种精细的并发控制,完美诠释了"乐观锁用于无冲突路径,悲观锁用于冲突路径"的设计哲学,从而在保证线程安全的同时获得了极高的并发性能。
2. GET操作流程
get操作是无锁的,这也是其高性能的重要原因。
- 计算key的哈希值,定位到桶。
- 检查桶的头节点:
- 如果头节点就是要找的节点(key的hash和值都匹配),直接返回其value。
- 如果头节点的
hash < 0,说明该桶是特殊状态(可能是TreeBin或ForwardingNode)。这时会调用节点对应的find方法(如TreeBin.find()或ForwardingNode.find())在新结构或新表中进行查找。 - 否则,遍历链表查找。
整个过程依赖于volatile修饰的val和next字段来保证读线程能看到其他线程发布的最新值,从而保证可见性,无需加锁。
3. 扩容机制
扩容是ConcurrentHashMap中最复杂的过程,主要在transfer方法中实现,其设计目标是支持多线程并发扩容。
- 触发时机 :元素数量达到阈值(
sizeCtl),或单个链表长度过长但数组总容量尚未达到树化阈值时。 - 流程概述 :
- 构建一个容量为旧表两倍的新数组
nextTable。 - 线程从数组的高索引位向低索引位依次迁移数据。通过维护一个
transferIndex变量来分配每个线程需要迁移的桶区间,避免重复劳动。 - 迁移某个桶时,会锁住该桶的头节点。然后根据节点是链表还是树,进行数据迁移。链表节点迁移后会形成两个链表(高位链和低位链),分别放入新数组的
i和i + n位置(n为旧数组长度)。 - 某个桶迁移完成后,会在旧表的这个位置设置一个
ForwardingNode节点。这个节点有两个作用:一是作为该桶已迁移的标记,其他线程看到后就知道去新表中查找;二是如果其他线程也来操作这个桶,可能会协助迁移。
- 构建一个容量为旧表两倍的新数组
- 并发扩容 :第一个触发扩容的线程会将
sizeCtl设置为一个负值(如- (1 + n),n为扩容线程数),并通过CAS方式增加扩容线程数。其他线程在执行put操作时如果遇到ForwardingNode,则会调用helpTransfer方法来协助扩容,共同完成数据迁移任务。
⚠️ 重要特性与使用建议
- 线程安全与性能 :ConcurrentHashMap通过细粒度锁和CAS实现了高并发下的线程安全。读操作通常是无锁的,写操作只在特定桶上同步,性能远优于早期使用全局锁的
Hashtable。 - 弱一致性迭代器 :ConcurrentHashMap的迭代器(
keySet(),values(),entrySet())返回的是弱一致性 的视图。它们在遍历时反映的是创建迭代器时或之后某个时间点的Map状态,但不保证 能反映遍历过程中所有并发修改,也不会 抛出ConcurrentModificationException。 - 不允许null值 :与HashMap不同,ConcurrentHashMap不允许key或value为null 。这是为了避免在并发环境下,通过
get(key)返回null时产生歧义(无法区分是key不存在,还是key对应的value本身就是null)。 - Size方法的近似性 :
size()方法返回的是一个估计值,因为在统计时可能有其他线程正在并发修改。如果需要精确值,可能需要全局锁,这会牺牲性能。因此,在并发要求高的场景,应理解其近似性。 - 使用建议 :
- 对于读多写少的场景,ConcurrentHashMap性能优异。
- 如果需要执行复合操作 (例如"若不存在则添加"),应使用ConcurrentHashMap提供的原子方法,如
putIfAbsent()、compute()、merge()等,而不是自己先检查再操作。 - 理解其弱一致性特性,不要在迭代过程中假设能获取Map的完全实时状态。
ConcurrentHashMap是Java并发编程的杰作,其精巧的设计平衡了线程安全、性能和复杂性。理解其源码对于掌握高并发编程和数据结构设计大有裨益。