总结概述
Dify 的工作流引擎展现了 事件驱动架构 + 领域驱动设计 的工业级实践:
- DAG 拓扑 通过邻接表 + 动态入度检查实现高效调度
- 变量池 采用双层哈希 + 命名空间隔离保证并发安全
- 持久化层 使用 PostgreSQL 存储完整 DSL + 执行日志,支持精确回溯
- 并发控制 通过 Worker 并行 + Dispatcher 串行写入避免分布式锁开销
- 资源管控 依赖 Layer 系统实现步数/时间/内存三重限制
工作流架构对比表
| 维度 | Airflow (传统) | Temporal (现代) | Dify Workflow (本设计) |
|---|---|---|---|
| 调度算法 | Kahn 拓扑排序 | Event-Driven DAG | Event-Driven + Ready Queue |
| 变量传递 | XCom (DB 序列化) | Workflow Context | Variable Pool (内存 + PostgreSQL) |
| 并行模型 | 多进程 + Celery | 多 Worker 协程 | 动态线程池 (min=1, max=CPU) |
| 状态持久化 | 每个 Task 独立记录 | Event Sourcing | GraphRuntimeState 序列化 |
| 原子性保障 | DB 事务 | SAGA 模式 | 单线程 Dispatcher 写入 |
| 断点续传 | Task 级别 | Workflow 级别 | 全局状态快照(变量池+就绪队列) |
| 资源限制 | 外部调度器控制 | Worker 级别限制 | Layer 系统三重限制 |
总结流程图
工作流执行:从 DSL 到 DAG 执行
整体流程概览
简单理解:
- 输入:用户配置的工作流 DSL(JSON 格式)
- 解析:将 DSL 解析为 DAG(有向无环图)
- 执行:多线程并行执行节点
- 输出:返回执行结果和事件流
完整链路:
- DSL 输入 → JSON 配置
- Graph.init() → 解析为 DAG(节点、边、拓扑)
- WorkflowEntry → 创建 GraphEngine
- GraphEngine.init() → 初始化 10+ 子系统
- GraphEngine.run() → 启动执行
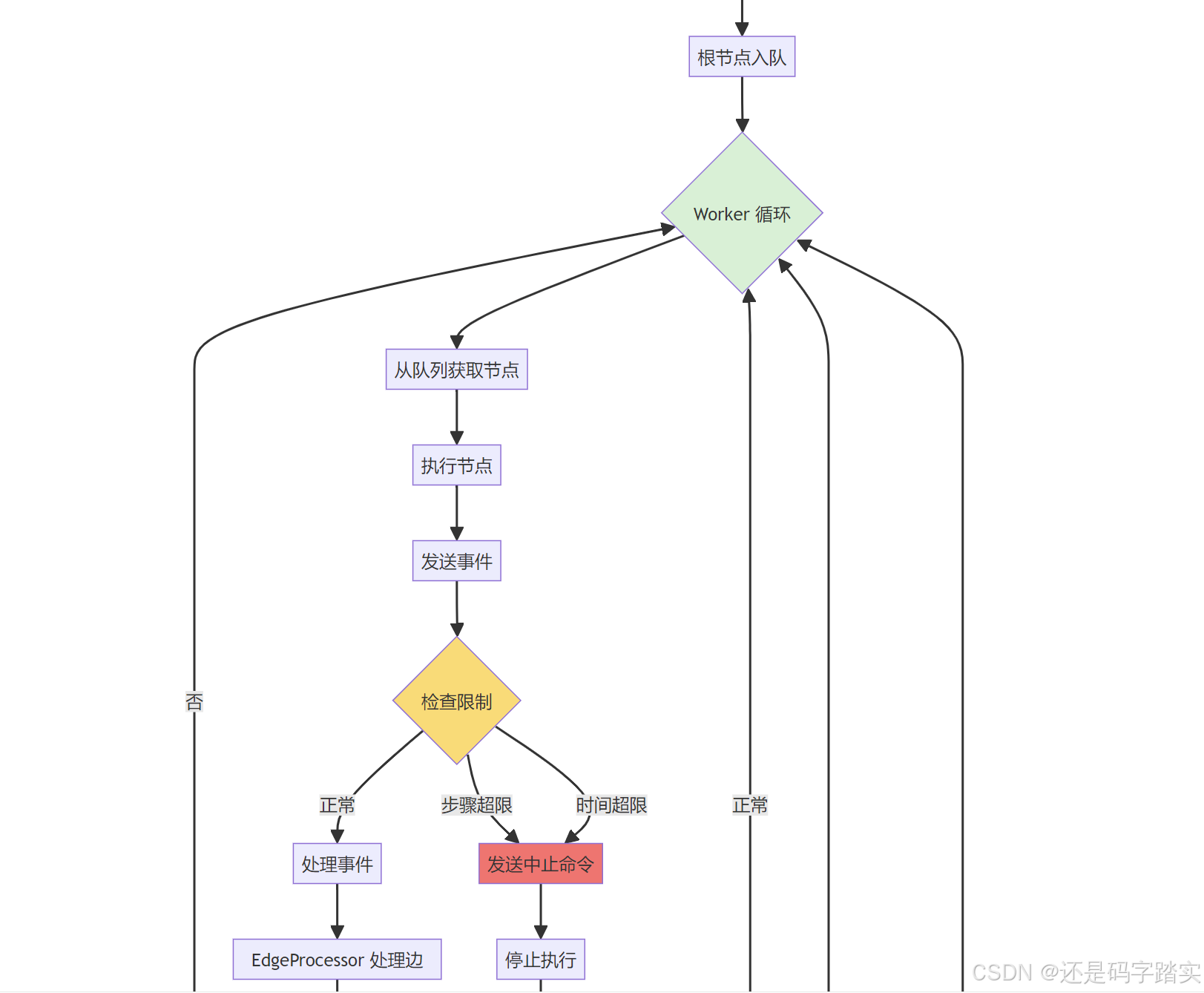
- root 节点入队 → 放入 ReadyQueue
- Worker 取节点 → 执行 node.run()
- 事件入队 → 放入 EventQueue
- Dispatcher 取事件 → 分发给 EventHandler
- EventHandler 处理 → 根据事件类型执行逻辑
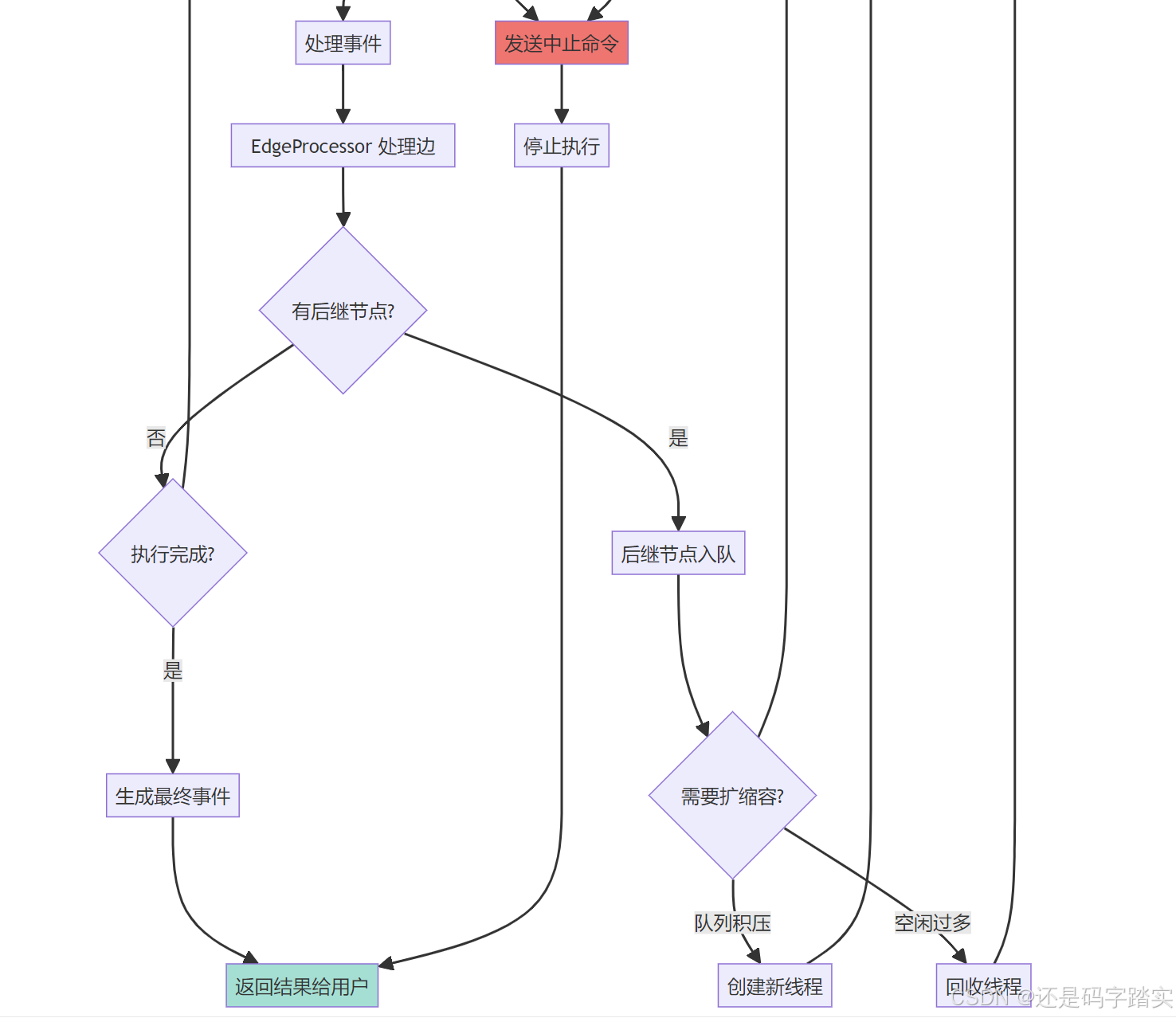
- EdgeProcessor → 找到下游就绪节点
- 下游节点入队 → 放入 ReadyQueue
- 不断循环直到ReadyQueue、EventQueue队列空 → 执行完成
- 返回结果 → GraphRunSucceededEvent
核心优势:
- ✅ 并行执行:多个 Worker 同时处理节点
- ✅ 事件驱动:解耦节点执行和流程控制
- ✅ 模块化:每个子系统职责单一
- ✅ 可扩展:Layer 机制支持插件
- ✅ 可暂停/恢复:通过命令通道控制
完整执行流程图
JSON配置
Graph对象
创建
初始化子系统
启动
从ReadyQueue取节点
生成事件
分发
成功
失败
其他
找到下游节点
重试
终止
队列空且无运行节点
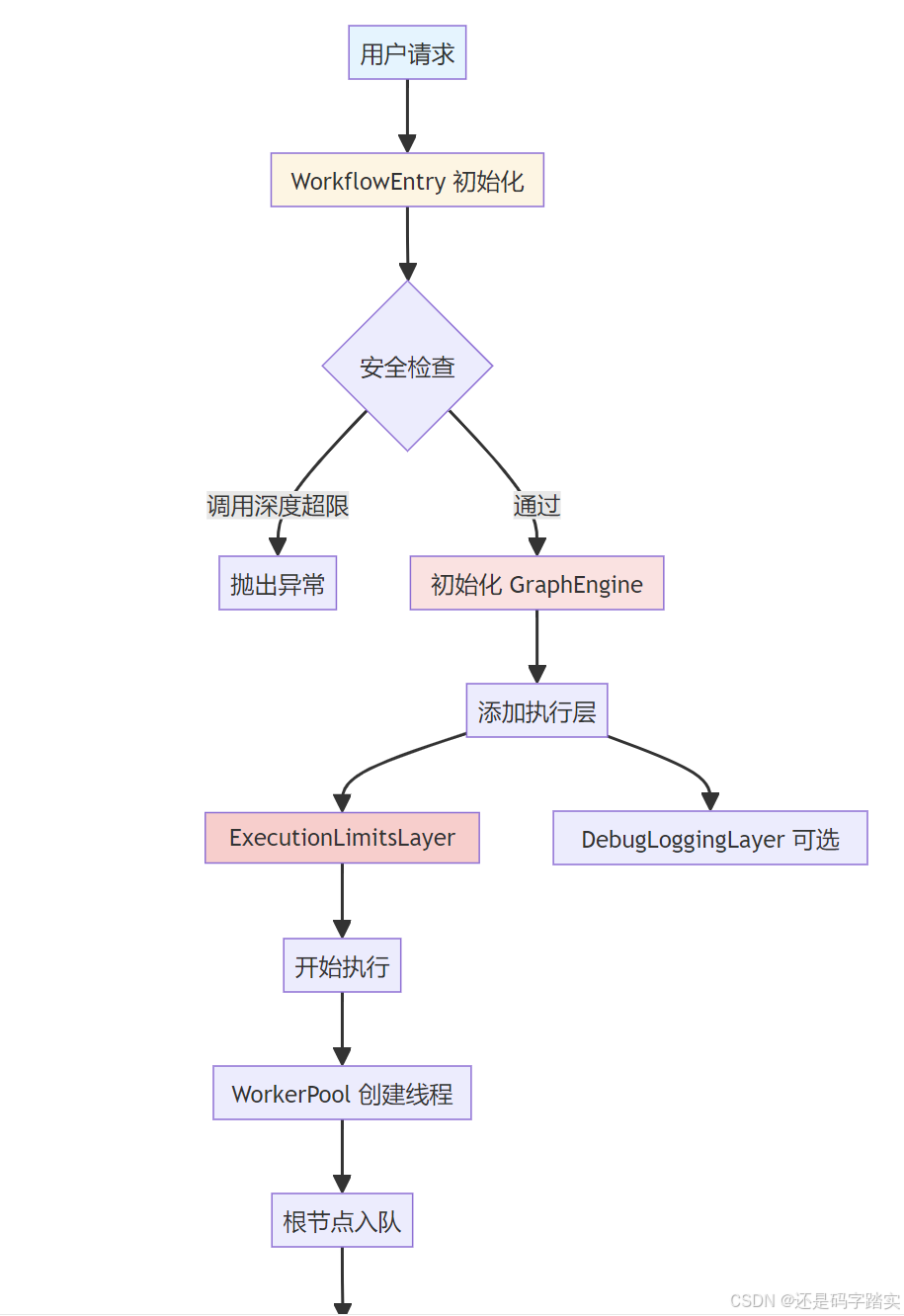
- DSL输入
用户工作流配置 2. Graph.init
解析DSL为DAG 3. WorkflowEntry初始化
创建执行入口 4. GraphEngine
执行引擎 5. 初始化执行组件 WorkerPool
工作线程池
ReadyQueue
就绪队列
EventQueue
事件队列
Dispatcher
调度器
EventHandler
事件处理器
EdgeProcessor
边处理器
6. GraphEngine.run
启动执行 7. 将root节点入队 8. Worker循环 9. Worker执行节点 10. 事件放入EventQueue 11. Dispatcher处理事件 12. EventHandler处理 NodeRunSucceededEvent
NodeRunFailedEvent
其他事件类型
13. EdgeProcessor
处理出边 14. 下游节点入队 错误处理
结束执行
15. 输出结果
GraphRunSucceededEvent
关键步骤详细解析
步骤 1-2:DSL 解析为 DAG
位置 :api/core/workflow/graph/graph.py
python
# 输入示例:DSL 配置
graph_config = {
"nodes": [
{
"id": "start",
"type": "custom",
"data": {
"type": "start",
"title": "开始"
}
},
{
"id": "llm_node",
"type": "custom",
"data": {
"type": "llm",
"title": "LLM节点"
}
}
],
"edges": [
{
"source": "start",
"target": "llm_node",
"sourceHandle": "source"
}
]
}
python
# Graph.init() 关键代码解析
@classmethod
def init(cls, *, graph_config: Mapping[str, object],
node_factory: NodeFactory,
root_node_id: str | None = None) -> Graph:
"""
【核心功能】将 DSL 配置解析为 Graph 对象
参数:
graph_config: 用户的工作流配置(JSON)
node_factory: 节点工厂,用于创建具体节点实例
root_node_id: 可选的起始节点ID
返回:
Graph: 包含节点、边、拓扑关系的图对象
"""
# ========== 步骤 1:提取配置 ==========
edge_configs = graph_config.get("edges", []) # 获取边配置列表
node_configs = graph_config.get("nodes", []) # 获取节点配置列表
# ========== 步骤 2:解析节点配置 ==========
# 将节点列表转为字典:{node_id: node_config}
node_configs_map = cls._parse_node_configs(node_configs)
# ========== 步骤 3:找到根节点 ==========
# 根节点:没有入边的节点,优先选择 START 类型
root_node_id = cls._find_root_node_id(
node_configs_map, edge_configs, root_node_id
)
# ========== 步骤 4:构建边和拓扑关系 ==========
# 返回三个字典:
# - edges: {edge_id: Edge对象}
# - in_edges: {node_id: [入边ID列表]}
# - out_edges: {node_id: [出边ID列表]}
edges, in_edges, out_edges = cls._build_edges(edge_configs)
# ========== 步骤 5:创建节点实例 ==========
# 使用 node_factory 将配置转为实际的 Node 对象
nodes = cls._create_node_instances(node_configs_map, node_factory)
# ========== 步骤 6:特殊处理 ==========
# 将失败分支节点提升为分支执行类型
cls._promote_fail_branch_nodes(nodes)
# 获取根节点实例
root_node = nodes[root_node_id]
# 标记非活跃的根分支为跳过状态
cls._mark_inactive_root_branches(
nodes, edges, in_edges, out_edges, root_node_id
)
# ========== 步骤 7:创建 Graph 对象 ==========
graph = cls(
nodes=nodes, # 所有节点
edges=edges, # 所有边
in_edges=in_edges, # 入边映射
out_edges=out_edges, # 出边映射
root_node=root_node # 根节点
)
# ========== 步骤 8:验证图结构 ==========
get_graph_validator().validate(graph)
return graph关键注释:
_parse_node_configs: 将节点列表转为字典,方便通过 ID 查找_find_root_node_id: 找到执行入口(START 节点或无入边的节点)_build_edges: 构建 DAG 的拓扑结构(入边、出边映射)_create_node_instances: 根据节点类型创建具体实例(LLM、Tool 等)
步骤 3-4:创建执行引擎
位置 :api/core/workflow/workflow_entry.py
python
class WorkflowEntry:
"""
【核心功能】工作流执行入口
作用:连接 Graph(静态结构)和 GraphEngine(动态执行)
"""
def __init__(self, tenant_id: str, app_id: str, workflow_id: str,
graph_config: Mapping[str, Any], graph: Graph,
user_id: str, user_from: UserFrom, invoke_from: InvokeFrom,
call_depth: int, variable_pool: VariablePool,
graph_runtime_state: GraphRuntimeState,
command_channel: CommandChannel | None = None) -> None:
"""
初始化工作流入口
重要参数:
graph: 已解析的 DAG 图
graph_runtime_state: 运行时状态(变量池、执行状态等)
command_channel: 命令通道(用于暂停、终止等外部控制)
"""
# ========== 检查调用深度(防止无限递归) ==========
workflow_call_max_depth = dify_config.WORKFLOW_CALL_MAX_DEPTH
if call_depth > workflow_call_max_depth:
raise ValueError(f"达到最大调用深度 {workflow_call_max_depth}")
# ========== 创建命令通道(用于外部控制) ==========
if command_channel is None:
command_channel = InMemoryChannel() # 默认内存通道
self.command_channel = command_channel
# ========== 创建 GraphEngine(核心执行引擎) ==========
self.graph_engine = GraphEngine(
workflow_id=workflow_id,
graph=graph, # 传入 DAG 图
graph_runtime_state=graph_runtime_state, # 运行时状态
command_channel=command_channel, # 命令通道
)
# ========== 添加执行层(Layers) ==========
# Layer 是插件式扩展,用于增强功能
# 1. Debug 日志层(开发模式)
if dify_config.DEBUG:
debug_layer = DebugLoggingLayer(
level="DEBUG",
include_inputs=True,
include_outputs=True,
)
self.graph_engine.layer(debug_layer)
# 2. 执行限制层(防止超时/步骤过多)
limits_layer = ExecutionLimitsLayer(
max_steps=dify_config.WORKFLOW_MAX_EXECUTION_STEPS, # 最大步骤数
max_time=dify_config.WORKFLOW_MAX_EXECUTION_TIME # 最大执行时间
)
self.graph_engine.layer(limits_layer)
# 3. 可观测性层(追踪和监控)
if dify_config.ENABLE_OTEL:
self.graph_engine.layer(ObservabilityLayer())
def run(self) -> Generator[GraphEngineEvent, None, None]:
"""
【核心功能】执行工作流
返回:事件生成器(流式返回执行过程)
"""
graph_engine = self.graph_engine
try:
# 运行工作流,返回事件流
generator = graph_engine.run()
yield from generator # 流式返回事件
except GenerateTaskStoppedError:
pass # 用户主动停止
except Exception as e:
logger.exception("工作流执行时发生未知错误")
yield GraphRunFailedEvent(error=str(e))步骤 5:GraphEngine 初始化子系统
位置 :api/core/workflow/graph_engine/graph_engine.py
python
class GraphEngine:
"""
【核心功能】基于队列的图执行引擎
架构特点:
- 模块化:职责分离到各个子系统
- 多线程:Worker 并行执行节点
- 事件驱动:通过事件队列协调
"""
def __init__(self, workflow_id: str, graph: Graph,
graph_runtime_state: GraphRuntimeState,
command_channel: CommandChannel,
min_workers: int | None = None,
max_workers: int | None = None) -> None:
"""
初始化执行引擎及所有子系统
"""
# ========== 核心数据 ==========
self._stop_event = threading.Event() # 停止信号
self._graph = graph # DAG 图
self._graph_runtime_state = graph_runtime_state # 运行时状态
self._command_channel = command_channel # 命令通道
# 配置运行时状态
self._graph_runtime_state.stop_event = self._stop_event
self._graph_runtime_state.configure(graph=graph)
# ========== 执行队列 ==========
# 1. 就绪队列:存放可以执行的节点 ID
self._ready_queue = graph_runtime_state.ready_queue
# 2. 事件队列:存放节点执行产生的事件
self._event_queue: queue.Queue[GraphNodeEventBase] = queue.Queue()
# ========== 状态管理器 ==========
# 统一管理节点状态转换和队列操作
self._state_manager = GraphStateManager(
self._graph, self._ready_queue
)
# ========== 事件管理器 ==========
# 收集和发送事件
self._event_manager = EventManager()
# ========== 错误处理器 ==========
# 处理节点执行失败
self._error_handler = ErrorHandler(
self._graph, self._graph_execution
)
# ========== 图遍历组件 ==========
# 1. 跳过传播器:传播节点跳过状态
self._skip_propagator = SkipPropagator(
graph=self._graph,
state_manager=self._state_manager,
)
# 2. 边处理器:处理边的遍历和下游节点触发
self._edge_processor = EdgeProcessor(
graph=self._graph,
state_manager=self._state_manager,
response_coordinator=self._response_coordinator,
skip_propagator=self._skip_propagator,
)
# ========== 命令处理器 ==========
# 处理外部命令(暂停、终止等)
self._command_processor = CommandProcessor(
command_channel=self._command_channel,
graph_execution=self._graph_execution,
)
# 注册命令处理器
self._command_processor.register_handler(
AbortCommand, AbortCommandHandler()
)
self._command_processor.register_handler(
PauseCommand, PauseCommandHandler()
)
# ========== Worker 线程池 ==========
# 捕获 Flask 上下文(用于多线程)
flask_app = None
try:
app = current_app._get_current_object()
if isinstance(app, Flask):
flask_app = app
except RuntimeError:
pass
# 捕获上下文变量
context_vars = contextvars.copy_context()
# 创建 Worker 线程池
self._worker_pool = WorkerPool(
ready_queue=self._ready_queue, # 从这里取节点
event_queue=self._event_queue, # 放事件到这里
graph=self._graph,
layers=self._layers,
flask_app=flask_app,
context_vars=context_vars,
min_workers=min_workers, # 最小线程数
max_workers=max_workers, # 最大线程数
stop_event=self._stop_event,
)
# ========== 执行协调器 ==========
# 协调整体执行生命周期
self._execution_coordinator = ExecutionCoordinator(
graph_execution=self._graph_execution,
state_manager=self._state_manager,
command_processor=self._command_processor,
worker_pool=self._worker_pool,
)
# ========== 事件处理注册器 ==========
# 处理所有节点执行事件
self._event_handler_registry = EventHandler(
graph=self._graph,
graph_runtime_state=self._graph_runtime_state,
graph_execution=self._graph_execution,
response_coordinator=self._response_coordinator,
event_collector=self._event_manager,
edge_processor=self._edge_processor,
state_manager=self._state_manager,
error_handler=self._error_handler,
)
# ========== 调度器 ==========
# 从事件队列取事件并分发处理
self._dispatcher = Dispatcher(
event_queue=self._event_queue,
event_handler=self._event_handler_registry,
execution_coordinator=self._execution_coordinator,
event_emitter=self._event_manager,
stop_event=self._stop_event,
)子系统职责说明:
| 子系统 | 职责 |
|---|---|
| ReadyQueue | 存储可执行的节点 ID(FIFO 队列) |
| EventQueue | 存储节点产生的事件 |
| WorkerPool | 管理多个 Worker 线程并行执行节点 |
| StateManager | 管理节点状态和队列操作 |
| EventManager | 收集和发送事件 |
| EdgeProcessor | 处理边遍历,找到下游节点 |
| ErrorHandler | 处理节点失败(重试、降级等) |
| Dispatcher | 从事件队列取事件并分发 |
| EventHandler | 根据事件类型执行相应逻辑 |
步骤 6-7:启动执行
位置 :api/core/workflow/graph_engine/graph_engine.py
python
def run(self) -> Generator[GraphEngineEvent, None, None]:
"""
【核心功能】执行图
返回:事件生成器(流式返回)
"""
try:
# ========== 初始化层 ==========
self._initialize_layers()
# ========== 判断是否恢复执行 ==========
is_resume = self._graph_execution.started
if not is_resume:
self._graph_execution.start() # 首次执行
else:
self._graph_execution.paused = False # 恢复执行
# ========== 发送启动事件 ==========
start_event = GraphRunStartedEvent()
self._event_manager.notify_layers(start_event)
yield start_event
# ========== 启动执行子系统 ==========
self._start_execution(resume=is_resume)
# ========== 流式返回事件 ==========
yield from self._event_manager.emit_events()
# ========== 处理完成状态 ==========
if self._graph_execution.is_paused:
# 暂停
yield GraphRunPausedEvent(...)
elif self._graph_execution.aborted:
# 终止
yield GraphRunAbortedEvent(...)
elif self._graph_execution.has_error:
# 失败
if self._graph_execution.error:
raise self._graph_execution.error
else:
# 成功
outputs = self._graph_runtime_state.outputs
yield GraphRunSucceededEvent(outputs=outputs)
except Exception as e:
yield GraphRunFailedEvent(error=str(e))
raise
finally:
self._stop_execution()
def _start_execution(self, *, resume: bool = False) -> None:
"""
【核心功能】启动执行子系统
"""
self._stop_event.clear()
# ========== 启动 Worker 线程池 ==========
self._worker_pool.start()
# ========== 注册响应节点 ==========
for node in self._graph.nodes.values():
if node.execution_type == NodeExecutionType.RESPONSE:
self._response_coordinator.register(node.id)
if not resume:
# ========== 首次执行:将根节点入队 ==========
root_node = self._graph.root_node
self._state_manager.enqueue_node(root_node.id) # 放入就绪队列
self._state_manager.start_execution(root_node.id) # 标记为执行中
else:
# ========== 恢复执行:将暂停的节点入队 ==========
paused_nodes = self._graph_runtime_state.consume_paused_nodes()
for node_id in paused_nodes:
self._state_manager.enqueue_node(node_id)
self._state_manager.start_execution(node_id)
# ========== 启动调度器 ==========
self._dispatcher.start()步骤 8-10:Worker 执行节点
位置 :api/core/workflow/graph_engine/worker.py
python
class Worker(threading.Thread):
"""
【核心功能】Worker 线程,从就绪队列取节点并执行
"""
def run(self) -> None:
"""
Worker 主循环
"""
while not self._stop_event.is_set():
# ========== 从就绪队列获取节点 ID ==========
try:
node_id = self._ready_queue.get(timeout=0.1)
except queue.Empty:
continue # 队列空,继续等待
# ========== 记录任务时间 ==========
self._last_task_time = time.time()
# ========== 获取节点实例 ==========
node = self._graph.nodes[node_id]
try:
# ========== 执行节点 ==========
self._execute_node(node)
self._ready_queue.task_done() # 标记任务完成
except Exception as e:
# ========== 执行失败,生成错误事件 ==========
error_event = NodeRunFailedEvent(
id=str(uuid4()),
node_id=node.id,
node_type=node.node_type,
error=str(e),
start_at=datetime.now(),
)
self._event_queue.put(error_event)
def _execute_node(self, node: Node) -> None:
"""
【核心功能】执行单个节点
流程:
1. 调用 Layer 的 on_node_run_start 钩子
2. 调用 node.run() 执行节点逻辑
3. 将节点产生的事件放入事件队列
4. 调用 Layer 的 on_node_run_end 钩子
"""
node.ensure_execution_id()
error: Exception | None = None
# ========== 执行前钩子 ==========
self._invoke_node_run_start_hooks(node)
try:
# ========== 执行节点,获取事件生成器 ==========
node_events = node.run() # 返回生成器
# ========== 将所有事件放入事件队列 ==========
for event in node_events:
self._event_queue.put(event)
# 事件示例:
# - NodeRunStartedEvent: 节点开始执行
# - NodeRunStreamChunkEvent: 流式输出块
# - NodeRunSucceededEvent: 节点成功
# - NodeRunFailedEvent: 节点失败
except Exception as exc:
error = exc
raise
finally:
# ========== 执行后钩子 ==========
self._invoke_node_run_end_hooks(node, error)节点执行示例:
假设执行一个 LLM 节点:
python
# node.run() 返回的事件流:
[
NodeRunStartedEvent(node_id="llm_1", ...),
NodeRunStreamChunkEvent(chunk="Hello", ...),
NodeRunStreamChunkEvent(chunk=" world", ...),
NodeRunSucceededEvent(
node_id="llm_1",
outputs={"output": "Hello world"},
...
)
]步骤 11-12:Dispatcher 调度和 EventHandler 处理
位置 :api/core/workflow/graph_engine/orchestration/dispatcher.py
python
class Dispatcher:
"""
【核心功能】调度器,从事件队列取事件并分发处理
"""
def _dispatcher_loop(self) -> None:
"""
调度器主循环
"""
try:
self._process_commands() # 处理命令
# ========== 主循环 ==========
while not self._stop_event.is_set():
# 检查是否应该停止
if (self._execution_coordinator.aborted or
self._execution_coordinator.paused or
self._execution_coordinator.execution_complete):
break
# 检查是否需要扩缩容 Worker
self._execution_coordinator.check_scaling()
try:
# ========== 从事件队列获取事件 ==========
event = self._event_queue.get(timeout=0.1)
# ========== 分发事件到 EventHandler ==========
self._event_handler.dispatch(event)
self._event_queue.task_done()
# ========== 处理命令(如暂停、终止) ==========
self._process_commands(event)
except queue.Empty:
time.sleep(0.1) # 队列空,短暂休眠
# ========== 处理剩余事件 ==========
self._process_commands()
while True:
try:
event = self._event_queue.get(block=False)
self._event_handler.dispatch(event)
self._event_queue.task_done()
except queue.Empty:
break
except Exception as e:
logger.exception("Dispatcher 错误")
self._execution_coordinator.mark_failed(e)
finally:
self._execution_coordinator.mark_complete()
if self._event_emitter:
self._event_emitter.mark_complete()位置 :api/core/workflow/graph_engine/event_management/event_handlers.py
python
class EventHandler:
"""
【核心功能】事件处理注册器
根据事件类型调用相应的处理逻辑
"""
@singledispatchmethod
def _dispatch(self, event: GraphNodeEventBase) -> None:
"""默认处理器"""
self._event_collector.collect(event)
logger.warning(f"未处理的事件类型: {type(event).__name__}")
@_dispatch.register
def _(self, event: NodeRunStartedEvent) -> None:
"""
【处理】节点开始事件
"""
# 记录执行
node_execution = self._graph_execution.get_or_create_node_execution(
event.node_id
)
node_execution.mark_started(event.id)
# 增加步骤计数
self._graph_runtime_state.increment_node_run_steps()
# 追踪节点执行(用于流式响应排序)
self._response_coordinator.track_node_execution(
event.node_id, event.id
)
# 收集事件(返回给用户)
self._event_collector.collect(event)
@_dispatch.register
def _(self, event: NodeRunSucceededEvent) -> None:
"""
【处理】节点成功事件(最重要)
流程:
1. 更新执行状态
2. 存储节点输出到变量池
3. 处理出边,找到下游节点
4. 将下游节点入队
5. 收集事件
"""
# ========== 1. 更新执行状态 ==========
node_execution = self._graph_execution.get_or_create_node_execution(
event.node_id
)
node_execution.mark_taken() # 标记为已执行
# 累计 token 使用量
self._accumulate_node_usage(event.node_run_result.llm_usage)
# ========== 2. 存储节点输出到变量池 ==========
self._store_node_outputs(
event.node_id,
event.node_run_result.outputs
)
# 示例:outputs = {"output": "Hello world"}
# 存储为:variable_pool["llm_1.output"] = "Hello world"
# ========== 3. 处理响应流 ==========
streaming_events = self._response_coordinator.intercept_event(event)
for stream_event in streaming_events:
self._event_collector.collect(stream_event)
# ========== 4. 处理出边,找到下游节点 ==========
node = self._graph.nodes[event.node_id]
if node.execution_type == NodeExecutionType.BRANCH:
# 分支节点:只激活选中的分支
ready_nodes, edge_events = self._edge_processor.handle_branch_completion(
event.node_id,
event.node_run_result.edge_source_handle
)
else:
# 普通节点:激活所有下游节点
ready_nodes, edge_events = self._edge_processor.process_node_success(
event.node_id
)
# 收集边事件
for edge_event in edge_events:
self._event_collector.collect(edge_event)
# ========== 5. 将下游节点入队 ==========
for node_id in ready_nodes:
self._state_manager.enqueue_node(node_id) # 放入就绪队列
self._state_manager.start_execution(node_id) # 标记执行中
# ========== 6. 标记当前节点完成 ==========
self._state_manager.finish_execution(event.node_id)
# ========== 7. 更新响应输出 ==========
if node.execution_type == NodeExecutionType.RESPONSE:
self._update_response_outputs(event.node_run_result.outputs)
# ========== 8. 收集事件 ==========
self._event_collector.collect(event)
@_dispatch.register
def _(self, event: NodeRunFailedEvent) -> None:
"""
【处理】节点失败事件
流程:
1. 记录失败
2. 调用错误处理器(重试、降级等)
3. 根据策略决定:重试、继续、终止
"""
# 更新状态
node_execution = self._graph_execution.get_or_create_node_execution(
event.node_id
)
node_execution.mark_failed(event.error)
self._graph_execution.record_node_failure()
# 调用错误处理器
result = self._error_handler.handle_node_failure(event)
if result:
# 返回了新事件(如重试事件),递归处理
self.dispatch(result)
else:
# 终止执行
self._graph_execution.fail(RuntimeError(event.error))
self._event_collector.collect(event)
self._state_manager.finish_execution(event.node_id)步骤 13-14:EdgeProcessor 处理边和下游节点
位置 :api/core/workflow/graph_engine/graph_traversal/edge_processor.py
python
class EdgeProcessor:
"""
【核心功能】处理边的遍历和下游节点的触发
"""
def process_node_success(self, node_id: str,
selected_handle: str | None = None
) -> tuple[Sequence[str], Sequence[NodeRunStreamChunkEvent]]:
"""
【核心功能】处理节点成功后的出边
返回:
- ready_nodes: 可以执行的下游节点列表
- streaming_events: 边产生的流式事件
"""
node = self._graph.nodes[node_id]
if node.execution_type == NodeExecutionType.BRANCH:
# 分支节点:只处理选中的分支
return self._process_branch_node_edges(node_id, selected_handle)
else:
# 普通节点:处理所有出边
return self._process_non_branch_node_edges(node_id)
def _process_non_branch_node_edges(self, node_id: str):
"""
处理普通节点的出边
"""
ready_nodes: list[str] = []
all_streaming_events: list[NodeRunStreamChunkEvent] = []
# ========== 获取所有出边 ==========
outgoing_edges = self._graph.get_outgoing_edges(node_id)
# ========== 处理每条边 ==========
for edge in outgoing_edges:
nodes, events = self._process_taken_edge(edge)
ready_nodes.extend(nodes)
all_streaming_events.extend(events)
return ready_nodes, all_streaming_events
def _process_taken_edge(self, edge: Edge):
"""
【核心功能】处理一条被选中的边
流程:
1. 标记边为已选中
2. 通知响应协调器
3. 检查下游节点是否就绪
"""
# ========== 1. 标记边为已选中 ==========
self._state_manager.mark_edge_taken(edge.id)
# ========== 2. 通知响应协调器(用于流式响应) ==========
streaming_events = self._response_coordinator.on_edge_taken(edge.id)
# ========== 3. 检查下游节点是否就绪 ==========
ready_nodes: list[str] = []
if self._state_manager.is_node_ready(edge.head):
# 下游节点的所有入边都已完成,可以执行
ready_nodes.append(edge.head)
return ready_nodes, streaming_events就绪条件判断示例:
edge1
edge2
节点A
节点C
节点B
节点 C 的就绪条件:
edge1和edge2都被标记为TAKEN- 即:A 和 B 都执行成功后,C 才会进入就绪队列
完整示例演示
示例工作流 DSL
json
{
"nodes": [
{
"id": "start",
"data": {"type": "start", "title": "开始"}
},
{
"id": "llm_1",
"data": {
"type": "llm",
"title": "LLM节点1",
"prompt": "你好"
}
},
{
"id": "llm_2",
"data": {
"type": "llm",
"title": "LLM节点2",
"prompt": "世界"
}
},
{
"id": "code_1",
"data": {
"type": "code",
"title": "合并结果",
"code": "return llm_1.output + llm_2.output"
}
}
],
"edges": [
{"source": "start", "target": "llm_1"},
{"source": "start", "target": "llm_2"},
{"source": "llm_1", "target": "code_1"},
{"source": "llm_2", "target": "code_1"}
]
}执行流程图
edge1
edge2
edge3
edge4
开始节点
LLM节点1
LLM节点2
代码节点
!!!执行时序图
EdgeProcessor EventHandler Dispatcher EventQueue Worker2 Worker1 ReadyQueue GraphEngine WorkflowEntry 用户 EdgeProcessor EventHandler Dispatcher EventQueue Worker2 Worker1 ReadyQueue GraphEngine WorkflowEntry 用户 队列: "start" 队列: "llm_1", "llm_2" par 并行执行 edge3=TAKEN, edge4=WAITING code_1 未就绪 edge3=TAKEN, edge4=TAKEN code_1 就绪! 队列空,执行完成 调用 run() graph_engine.run() enqueue("start") 启动 Worker1 启动 Worker2 启动 Dispatcher get() "start" 执行 start 节点 put(NodeRunStartedEvent) put(NodeRunSucceededEvent) get() NodeRunStartedEvent dispatch(event) 收集事件 get() NodeRunSucceededEvent dispatch(event) process_node_success("start") "llm_1", "llm_2" enqueue("llm_1") enqueue("llm_2") get() "llm_1" 执行 llm_1 put(NodeRunSucceededEvent) get() "llm_2" 执行 llm_2 put(NodeRunSucceededEvent) get() NodeRunSucceededEvent(llm_1) dispatch(event) process_node_success("llm_1") 检查 code_1 是否就绪 get() NodeRunSucceededEvent(llm_2) dispatch(event) process_node_success("llm_2") 检查 code_1 是否就绪 "code_1" enqueue("code_1") get() "code_1" 执行 code_1 put(NodeRunSucceededEvent) get() NodeRunSucceededEvent(code_1) dispatch(event) process_node_success("code_1") \[\] mark_complete() yield GraphRunSucceededEvent
关键时间点的状态快照
T1: 执行 start 节点后
python
# 就绪队列
ready_queue = ["llm_1", "llm_2"]
# 边状态
edges = {
"edge1": EdgeState.TAKEN,
"edge2": EdgeState.TAKEN,
"edge3": EdgeState.WAITING,
"edge4": EdgeState.WAITING,
}
# 节点状态
nodes = {
"start": NodeState.SUCCEEDED,
"llm_1": NodeState.PENDING,
"llm_2": NodeState.PENDING,
"code_1": NodeState.WAITING,
}T2: llm_1 执行完成,llm_2 还在执行
python
# 就绪队列
ready_queue = [] # llm_2 还在执行
# 边状态
edges = {
"edge1": EdgeState.TAKEN,
"edge2": EdgeState.TAKEN,
"edge3": EdgeState.TAKEN, # ✓
"edge4": EdgeState.WAITING, # ✗ 还在等待
}
# 节点状态
nodes = {
"start": NodeState.SUCCEEDED,
"llm_1": NodeState.SUCCEEDED,
"llm_2": NodeState.RUNNING, # 还在运行
"code_1": NodeState.WAITING, # 等待 edge4
}T3: llm_2 也执行完成
python
# 就绪队列
ready_queue = ["code_1"] # ✓ code_1 可以执行了
# 边状态
edges = {
"edge1": EdgeState.TAKEN,
"edge2": EdgeState.TAKEN,
"edge3": EdgeState.TAKEN, # ✓
"edge4": EdgeState.TAKEN, # ✓ 所有入边都完成
}
# 节点状态
nodes = {
"start": NodeState.SUCCEEDED,
"llm_1": NodeState.SUCCEEDED,
"llm_2": NodeState.SUCCEEDED,
"code_1": NodeState.PENDING, # 可以执行
}
# 变量池
variable_pool = {
("llm_1", "output"): "你好回复",
("llm_2", "output"): "世界回复",
}核心概念总结
队列模型
plain
┌─────────────┐
│ ReadyQueue │ 存储可执行的节点 ID
└──────┬──────┘
│ get()
▼
┌────────┐
│ Worker │ 执行节点
└────┬───┘
│ put(event)
▼
┌──────────────┐
│ EventQueue │ 存储节点产生的事件
└──────┬───────┘
│ get()
▼
┌───────────┐
│Dispatcher │ 分发事件
└─────┬─────┘
│ dispatch()
▼
┌────────────────┐
│ EventHandler │ 处理事件逻辑
└────────────────┘节点就绪条件
普通节点: 所有入边都为 TAKEN 状态
分支节点: 选中分支的边为 TAKEN,其他边为 SKIPPED
示例代码:
python
def is_node_ready(self, node_id: str) -> bool:
"""判断节点是否就绪"""
incoming_edges = self._graph.get_incoming_edges(node_id)
if not incoming_edges:
return False # 没有入边,不应该在这里
for edge in incoming_edges:
if edge.state not in (NodeState.TAKEN, NodeState.SKIPPED):
return False # 有边还未处理
return True # 所有入边都已处理事件类型
| 事件类型 | 触发时机 | 处理逻辑 |
|---|---|---|
NodeRunStartedEvent |
节点开始执行 | 记录开始时间、执行 ID |
NodeRunStreamChunkEvent |
流式输出 | 转发给用户 |
NodeRunSucceededEvent |
节点成功 | 存储输出、处理出边、触发下游 |
NodeRunFailedEvent |
节点失败 | 错误处理、重试或终止 |
NodeRunRetryEvent |
节点重试 | 重新入队 |
NodeRunExceptionEvent |
节点异常(有降级策略) | 使用默认值或走失败分支 |
变量池
python
# 变量池是一个字典,key 是 (node_id, variable_name)
variable_pool = {
("start", "query"): "用户输入",
("llm_1", "output"): "LLM输出",
("code_1", "result"): {"data": 123},
}
# 节点可以通过变量选择器访问其他节点的输出
# 例如:llm_1.output 会被解析为 variable_pool[("llm_1", "output")]关键设计模式
- 生产者-消费者模式
- Worker(生产者)→ EventQueue → Dispatcher(消费者)
- ** 单例分发模式**
- 使用
@singledispatchmethod根据事件类型分发
- 使用
- 责任链模式
- Layer 机制:Debug → Limits → Observability
- 状态机模式
- 节点状态:WAITING → PENDING → RUNNING → SUCCEEDED/FAILED
- 观察者模式
- EventManager 收集事件并通知订阅者(Layers)
变量池实现详解:基于 Node ID 的双层索引结构
要点总结
操作总结
- 双层索引 :
{node_id: {variable_name: Variable}} - 选择器机制 :
[node_id, variable_name, ...]灵活访问 - 自动类型转换:任意值 → Segment → Variable
- 嵌套访问支持:对象属性、数组索引、文件属性
- 特殊节点 :
sys,env,conversation等预定义 ID - O(1) 查询:双重哈希定位,性能优异
- 深拷贝保护 :
get_by_prefix()返回副本,避免意外修改
变量池的优势
- **解耦节点:**节点间不直接传递数据,通过变量池中转
- **支持并行:**多个节点可同时读取变量池(只要依赖满足)
- **易于调试:**可以随时查看变量池状态
- **支持暂停恢复:**变量池可序列化保存
全流程的时序图
Dispatcher EventQueue VariablePool Node节点 Worker线程 WorkerPool GraphEngine WorkflowEntry 用户 Dispatcher EventQueue VariablePool Node节点 Worker线程 WorkerPool GraphEngine WorkflowEntry 用户 loop 执行循环 run() 启动工作流 run() 执行图引擎 start() 启动线程池 创建工作线程 start() 启动调度器 将Start节点入队 get() 取节点ID run() 执行节点 get(upstream_node, var) 读取输入 返回变量值 执行业务逻辑(LLM/API等) add(node_id, output, result) 写入结果 返回事件 put(event) 放入事件队列 get() 取事件 处理事件,计算下游节点 将下游节点入队 执行完成 提取最终输出 返回结果事件 返回翻译结果
全流程的流程图
是
否
用户输入: 翻译 Hello
WorkflowEntry.init
创建 VariablePool
初始化用户输入
创建 GraphEngine
加载工作流图
WorkflowEntry.run
GraphEngine.run
启动 WorkerPool
创建工作线程
根节点入队
ReadyQueue.put
Dispatcher 启动
监听事件
Worker 取节点执行
ReadyQueue.get
Node.run
执行节点逻辑
从 VariablePool
读取输入变量
执行业务逻辑
如调用 LLM
结果写入 VariablePool
variable_pool.add
发送事件到
EventQueue
Dispatcher 处理事件
EventHandler.dispatch
EdgeProcessor
计算下游节点
还有下游节点?
GraphEngine 完成
生成最终输出
从 VariablePool 提取
返回给用户: Hello的翻译
核心数据结构
双层字典架构
python
# 变量池的核心数据结构
variable_dictionary: defaultdict[
str, # 第一层 key:node_id
dict[str, VariableUnion] # 第二层:{variable_name: Variable对象}
]可视化结构
plain
VariablePool
│
├─ variable_dictionary (双层字典)
│ │
│ ├─ "start" (Node ID - 第一层)
│ │ ├─ "query": StringVariable(value="用户输入")
│ │ └─ "files": ArrayFileVariable(value=[...])
│ │
│ ├─ "llm_1" (Node ID - 第一层)
│ │ ├─ "output": StringVariable(value="LLM输出内容")
│ │ └─ "usage": ObjectVariable(value={tokens: 100})
│ │
│ ├─ "code_1" (Node ID - 第一层)
│ │ └─ "result": ObjectVariable(value={data: [...]})
│ │
│ ├─ "sys" (系统变量 - 特殊 Node ID)
│ │ ├─ "user_id": StringVariable(value="user_123")
│ │ ├─ "app_id": StringVariable(value="app_456")
│ │ └─ "workflow_id": StringVariable(value="wf_789")
│ │
│ ├─ "env" (环境变量 - 特殊 Node ID)
│ │ └─ "api_key": StringVariable(value="sk-...")
│ │
│ └─ "conversation" (对话变量 - 特殊 Node ID)
│ └─ "history": ArrayObjectVariable(value=[...])
│
├─ user_inputs: {"query": "你好", "temperature": 0.7}
├─ system_variables: SystemVariable(...)
├─ environment_variables: [...]
└─ conversation_variables: [...]
plain
┌─────────────────────────────────────────────────────────┐
│ VariablePool │
├─────────────────────────────────────────────────────────┤
│ │
│ variable_dictionary (defaultdict) │
│ │ │
│ ├─ "sys" ──────────────────────┐ │
│ │ ├─ "user_id": Variable │ 系统变量 │
│ │ ├─ "app_id": Variable │ │
│ │ └─ "workflow_id": Variable │ │
│ │ │ │
│ ├─ "env" ──────────────────────┤ │
│ │ ├─ "API_KEY": Variable │ 环境变量 │
│ │ └─ "MODEL": Variable │ │
│ │ │ │
│ ├─ "start" ────────────────────┤ │
│ │ ├─ "query": Variable │ START节点输出 │
│ │ └─ "files": Variable │ │
│ │ │ │
│ ├─ "llm_1" ────────────────────┤ │
│ │ ├─ "output": Variable │ LLM节点输出 │
│ │ └─ "usage": Variable │ │
│ │ │ │
│ └─ "code_1" ───────────────────┤ │
│ └─ "result": Variable │ CODE节点输出 │
│ │ │
└──────────────────────────────────┴──────────────────────┘
访问路径示例:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
pool.get(["llm_1", "output"])
└─┬──┘ └──┬───┘
│ └─ 第二层索引:variable_name
└────────── 第一层索引:node_id
pool.get(["code_1", "result", "keywords", "0"])
└──┬───┘ └──┬───┘ └───┬────┘ └┬┘
│ │ │ └─ 数组索引
│ │ └───────── 对象属性
│ └───────────────────第二层索引
└────────────────────────────第一层索引变量选择器(Selector)机制
Selector 的定义
Selector 是一个序列(通常是 tuple 或 list),用于定位变量:
python
# 基本选择器格式
selector = [node_id, variable_name]
# 示例
selector = ["llm_1", "output"] # 定位到 llm_1 节点的 output 变量
selector = ["sys", "user_id"] # 定位到系统变量 user_id扩展选择器(支持嵌套访问)
python
# 访问对象属性
selector = ["llm_1", "metadata", "model"]
# 等价于:variable_pool["llm_1"]["metadata"].value["model"]
# 访问文件属性
selector = ["start", "file", "name"]
# 等价于:variable_pool["start"]["file"].name
# 访问深层嵌套
selector = ["code_1", "result", "data", "items", "0"]
# 等价于:variable_pool["code_1"]["result"]["data"]["items"][0]核心方法详解
add() - 添加变量
python
def add(self, selector: Sequence[str], value: Any, /):
"""
【核心功能】添加变量到变量池
参数:
selector: 变量选择器 [node_id, variable_name]
value: 变量值(支持多种类型)
步骤:
1. 验证 selector 长度(必须为 2)
2. 将 value 转换为 Variable 对象
3. 分解 selector 为 (node_id, name)
4. 存入双层字典
"""
# ========== 步骤 1:验证选择器长度 ==========
if len(selector) != SELECTORS_LENGTH: # SELECTORS_LENGTH = 2
raise ValueError(
f"Invalid selector: expected 2 elements (node_id, variable_name), "
f"got {len(selector)} elements"
)
# ========== 步骤 2:值类型转换 ==========
# 2.1 如果已经是 Variable 对象,直接使用
if isinstance(value, Variable):
variable = value
# 2.2 如果是 Segment 对象,转换为 Variable
elif isinstance(value, Segment):
variable = variable_factory.segment_to_variable(
segment=value,
selector=selector
)
# 2.3 普通值(str, int, dict, list 等),先转为 Segment,再转为 Variable
else:
segment = variable_factory.build_segment(value)
variable = variable_factory.segment_to_variable(
segment=segment,
selector=selector
)
# ========== 步骤 3:分解选择器 ==========
node_id, name = self._selector_to_keys(selector)
# 例如:["llm_1", "output"] -> node_id="llm_1", name="output"
# ========== 步骤 4:存入双层字典 ==========
self.variable_dictionary[node_id][name] = variable
# 结果:variable_dictionary["llm_1"]["output"] = StringVariable(...)示例:
python
# 示例 1:添加字符串
pool.add(["llm_1", "output"], "Hello world")
# 内部转换流程:
# "Hello world"
# -> StringSegment(value="Hello world")
# -> StringVariable(name="output", value="Hello world", selector=["llm_1", "output"])
# 示例 2:添加对象
pool.add(["code_1", "result"], {"score": 95, "status": "success"})
# 内部转换流程:
# {"score": 95, "status": "success"}
# -> ObjectSegment(value={...})
# -> ObjectVariable(name="result", value={...})
# 示例 3:添加文件
file = File(filename="doc.pdf", ...)
pool.add(["start", "file"], file)
# 内部转换流程:
# File对象
# -> FileSegment(value=File(...))
# -> FileVariable(name="file", value=File(...))get() - 获取变量
python
def get(self, selector: Sequence[str], /) -> Segment | None:
"""
【核心功能】从变量池获取变量值
支持:
- 简单访问:[node_id, variable_name]
- 嵌套访问:[node_id, variable_name, attr1, attr2, ...]
返回:
Segment 对象或 None
"""
# ========== 步骤 1:验证选择器长度 ==========
if len(selector) < SELECTORS_LENGTH: # 至少 2 个元素
return None
# ========== 步骤 2:分解选择器并查找节点 ==========
node_id, name = self._selector_to_keys(selector)
# 例如:["llm_1", "output", "text"] -> node_id="llm_1", name="output"
# 获取节点字典
node_map = self.variable_dictionary.get(node_id)
if node_map is None:
return None # 节点不存在
# 获取变量
segment: Segment | None = node_map.get(name)
if segment is None:
return None # 变量不存在
# ========== 步骤 3:简单访问(selector 长度为 2) ==========
if len(selector) == 2:
return segment # 直接返回整个 Segment
# ========== 步骤 4:文件属性访问 ==========
if isinstance(segment, FileSegment):
attr = selector[2]
# 验证是否为有效的文件属性(name, url, size, type 等)
if attr not in {item.value for item in FileAttribute}:
return None
attr = FileAttribute(attr)
# 使用文件管理器获取属性值
attr_value = file_manager.get_attr(file=segment.value, attr=attr)
return variable_factory.build_segment(attr_value)
# ========== 步骤 5:嵌套对象访问 ==========
# 遍历剩余的选择器路径
result: Any = segment
for attr in selector[2:]:
# 提取实际值(如果是 ObjectSegment,提取 .value)
result = self._extract_value(result)
# 获取嵌套属性
result = self._get_nested_attribute(result, attr)
if result is None:
return None # 路径中断
# ========== 步骤 6:返回结果 ==========
# 确保返回的是 Segment 对象
return result if isinstance(result, Segment) else variable_factory.build_segment(result)
def _extract_value(self, obj: Any):
"""提取 ObjectSegment 的实际值"""
return obj.value if isinstance(obj, ObjectSegment) else obj
def _get_nested_attribute(self, obj: Mapping[str, Any], attr: str) -> Segment | None:
"""从字典中获取嵌套属性"""
if not isinstance(obj, dict) or attr not in obj:
return None
return variable_factory.build_segment(obj.get(attr))示例:
python
# 准备数据
pool.add(["llm_1", "output"], "Hello world")
pool.add(["code_1", "result"], {
"score": 95,
"details": {
"accuracy": 0.98,
"items": ["item1", "item2"]
}
})
pool.add(["start", "file"], File(filename="doc.pdf", url="http://..."))
# 示例 1:简单访问
segment = pool.get(["llm_1", "output"])
# 返回:StringSegment(value="Hello world")
print(segment.value) # "Hello world"
# 示例 2:对象属性访问
segment = pool.get(["code_1", "result", "score"])
# 访问路径:variable_dictionary["code_1"]["result"].value["score"]
# 返回:IntegerSegment(value=95)
print(segment.value) # 95
# 示例 3:深层嵌套访问
segment = pool.get(["code_1", "result", "details", "accuracy"])
# 访问路径:
# 1. variable_dictionary["code_1"]["result"] -> ObjectSegment
# 2. .value["details"] -> {"accuracy": 0.98, "items": [...]}
# 3. ["accuracy"] -> 0.98
# 返回:FloatSegment(value=0.98)
print(segment.value) # 0.98
# 示例 4:文件属性访问
segment = pool.get(["start", "file", "name"])
# 特殊处理:FileSegment 支持属性访问
# 返回:StringSegment(value="doc.pdf")
print(segment.value) # "doc.pdf"
segment = pool.get(["start", "file", "url"])
# 返回:StringSegment(value="http://...")
print(segment.value) # "http://..."
# 示例 5:不存在的路径
segment = pool.get(["code_1", "result", "non_exist"])
# 返回:Noneremove() - 移除变量
python
def remove(self, selector: Sequence[str], /):
"""
【核心功能】从变量池移除变量
支持两种模式:
1. 移除整个节点:selector = [node_id]
2. 移除特定变量:selector = [node_id, variable_name]
"""
if not selector:
return
# ========== 模式 1:移除整个节点 ==========
if len(selector) == 1:
# 清空该节点的所有变量
self.variable_dictionary[selector[0]] = {}
return
# ========== 模式 2:移除特定变量 ==========
node_id, name = self._selector_to_keys(selector)
self.variable_dictionary[node_id].pop(name, None)示例:
python
# 准备数据
pool.add(["llm_1", "output"], "Hello")
pool.add(["llm_1", "usage"], {"tokens": 100})
pool.add(["llm_2", "output"], "World")
# 示例 1:移除特定变量
pool.remove(["llm_1", "output"])
# 结果:variable_dictionary["llm_1"] 只剩下 {"usage": ...}
# 示例 2:移除整个节点
pool.remove(["llm_1"])
# 结果:variable_dictionary["llm_1"] = {}get_by_prefix() - 按节点前缀获取所有变量
python
def get_by_prefix(self, prefix: str, /) -> Mapping[str, object]:
"""
【核心功能】获取某个节点的所有变量
参数:
prefix: 节点 ID
返回:
字典:{variable_name: value} (深拷贝)
"""
# ========== 步骤 1:获取节点字典 ==========
nodes = self.variable_dictionary.get(prefix)
if not nodes:
return {}
# ========== 步骤 2:提取所有变量值 ==========
result: dict[str, object] = {}
for key, variable in nodes.items():
value = variable.value # 提取 Variable 的实际值
result[key] = deepcopy(value) # 深拷贝,避免外部修改
return result示例:
python
# 准备数据
pool.add(["llm_1", "output"], "Hello world")
pool.add(["llm_1", "usage"], {"tokens": 100, "cost": 0.002})
pool.add(["llm_1", "model"], "gpt-4")
# 获取 llm_1 节点的所有变量
all_vars = pool.get_by_prefix("llm_1")
# 返回:
# {
# "output": "Hello world",
# "usage": {"tokens": 100, "cost": 0.002},
# "model": "gpt-4"
# }
print(all_vars["output"]) # "Hello world"
print(all_vars["usage"]["tokens"]) # 100特殊节点 ID
Dify 使用一些预定义的特殊节点 ID 来存储系统级变量:
python
# 常量定义
SYSTEM_VARIABLE_NODE_ID = "sys"
ENVIRONMENT_VARIABLE_NODE_ID = "env"
CONVERSATION_VARIABLE_NODE_ID = "conversation"
RAG_PIPELINE_VARIABLE_NODE_ID = "rag_pipeline"系统变量(sys)
python
# 系统变量在初始化时自动添加
def _add_system_variables(self, system_variable: SystemVariable):
"""将系统变量添加到变量池"""
sys_var_mapping = system_variable.to_dict()
for key, value in sys_var_mapping.items():
if value is None:
continue
selector = (SYSTEM_VARIABLE_NODE_ID, key) # ("sys", key)
if self._has(selector):
continue # 已存在,不覆盖
self.add(selector, value)
# 使用示例
user_id = pool.get(["sys", "user_id"])
app_id = pool.get(["sys", "app_id"])
workflow_id = pool.get(["sys", "workflow_id"])系统变量列表:
sys.user_id: 用户 IDsys.app_id: 应用 IDsys.workflow_id: 工作流 IDsys.workflow_run_id: 工作流执行 IDsys.query: 用户查询(聊天模式)sys.conversation_id: 对话 IDsys.dialogue_count: 对话轮数sys.files: 上传的文件列表
环境变量(env)
python
# 环境变量在初始化时自动添加
for var in self.environment_variables:
self.add((ENVIRONMENT_VARIABLE_NODE_ID, var.name), var)
# 使用示例
api_key = pool.get(["env", "OPENAI_API_KEY"])
db_url = pool.get(["env", "DATABASE_URL"])对话变量(conversation)
python
# 对话变量在初始化时自动添加
for var in self.conversation_variables:
self.add((CONVERSATION_VARIABLE_NODE_ID, var.name), var)
# 使用示例
history = pool.get(["conversation", "chat_history"])
context = pool.get(["conversation", "context"])完整示例流程:变量池的生命周期
python
from core.workflow.runtime import VariablePool
from core.workflow.system_variable import SystemVariable
# ========== 1. 初始化变量池 ==========
system_vars = SystemVariable(
user_id="user_123",
app_id="app_456",
workflow_id="wf_789",
query="解释量子计算",
)
env_vars = [
StringVariable(name="API_KEY", value="sk-xxx"),
StringVariable(name="MODEL", value="gpt-4"),
]
pool = VariablePool(
system_variables=system_vars,
environment_variables=env_vars,
user_inputs={"temperature": 0.7, "max_tokens": 1000}
)
# 此时变量池结构:
# {
# "sys": {
# "user_id": StringVariable("user_123"),
# "app_id": StringVariable("app_456"),
# "workflow_id": StringVariable("wf_789"),
# "query": StringVariable("解释量子计算"),
# },
# "env": {
# "API_KEY": StringVariable("sk-xxx"),
# "MODEL": StringVariable("gpt-4"),
# }
# }
# ========== 2. 执行 START 节点 ==========
# START 节点通常会添加用户输入到变量池
pool.add(["start", "query"], "解释量子计算")
pool.add(["start", "files"], [])
# ========== 3. 执行 LLM 节点 ==========
# LLM 节点从变量池读取输入
query = pool.get(["start", "query"])
model = pool.get(["env", "MODEL"])
# 模拟 LLM 调用
llm_output = "量子计算是利用量子力学原理进行计算的技术..."
llm_usage = {"tokens": 150, "cost": 0.003}
# LLM 节点将输出写入变量池
pool.add(["llm_1", "output"], llm_output)
pool.add(["llm_1", "usage"], llm_usage)
# ========== 4. 执行 CODE 节点 ==========
# CODE 节点读取 LLM 输出
llm_result = pool.get(["llm_1", "output"])
# 处理逻辑
code_result = {
"summary": llm_result.value[:50] + "...",
"word_count": len(llm_result.value),
"keywords": ["量子", "计算", "量子力学"]
}
# 写入结果
pool.add(["code_1", "result"], code_result)
# ========== 5. 访问嵌套数据 ==========
# 获取关键词列表的第一个元素
first_keyword = pool.get(["code_1", "result", "keywords", "0"])
print(first_keyword.value) # "量子"
# 获取字数统计
word_count = pool.get(["code_1", "result", "word_count"])
print(word_count.value) # 整数
# ========== 6. 批量获取节点输出 ==========
llm_outputs = pool.get_by_prefix("llm_1")
# 返回:
# {
# "output": "量子计算是...",
# "usage": {"tokens": 150, "cost": 0.003}
# }
# ========== 7. 清理(可选) ==========
pool.remove(["llm_1", "output"]) # 移除单个变量
pool.remove(["code_1"]) # 移除整个节点索引性能分析
时间复杂度
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
add(selector, value) |
O(1) | 直接哈希定位 |
get(selector) |
O(1) + O(k) | O(1) 定位 + O(k) 嵌套访问 |
remove(selector) |
O(1) | 直接哈希删除 |
get_by_prefix(node_id) |
O(n) | n = 该节点的变量数 |
其中 k 是嵌套访问的深度。
空间复杂度
- 双层字典 :O(N × M)
- N = 节点数量
- M = 每个节点的平均变量数
为什么使用双层索引?
优势:
✅ 局部性好:同一节点的变量聚集在一起,缓存友好
✅ 查询高效:两次哈希查找即可定位变量(O(1))
✅ 按节点管理:可以快速获取/删除整个节点的所有变量
✅ 避免冲突 :不同节点可以有同名变量(如多个 LLM 节点都有 output)
✅ 扩展性强:支持嵌套访问,无需修改底层结构
对比单层字典:
python
# ❌ 单层字典(不推荐)
variable_dictionary = {
"start.query": Variable(...),
"llm_1.output": Variable(...),
"llm_1.usage": Variable(...),
}
# 问题:
# - 字符串拼接性能差
# - 不支持按节点批量操作
# - 嵌套访问困难
# ✅ 双层字典(当前实现)
variable_dictionary = {
"start": {"query": Variable(...)},
"llm_1": {"output": Variable(...), "usage": Variable(...)},
}
# 优势:
# - 哈希查找快
# - 支持 get_by_prefix("llm_1")
# - 结构清晰状态持久化详解:PostgreSQL + 事件驱动持久化
架构概览
Dify 采用事件驱动的持久化架构,通过监听工作流执行过程中的事件来增量持久化状态。
plain
┌──────────────────────────────────────────────────────────┐
│ GraphEngine │
│ │
│ ┌─────────────┐ ┌──────────────┐ │
│ │ Worker │─────→│ EventQueue │ │
│ └─────────────┘ └──────┬───────┘ │
│ │ │
│ ▼ │
│ ┌──────────────┐ │
│ │ Dispatcher │ │
│ └──────┬───────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────┐ │
│ │ EventManager │ │
│ │ (通知所有 Layers)│ │
│ └──────┬───────────┘ │
└──────────────────────────────┼──────────────────────────┘
│
▼
┌──────────────────────┐
│ WorkflowPersistence │ ← GraphEngineLayer
│ Layer │
└──────────┬───────────┘
│
┌──────────────┴─────────────┐
▼ ▼
┌──────────────────────┐ ┌──────────────────────┐
│ WorkflowExecution │ │ WorkflowNodeExecution│
│ Repository │ │ Repository │
└──────────┬───────────┘ └──────────┬───────────┘
│ │
▼ ▼
┌─────────────┐ ┌─────────────────┐
│ WorkflowRun │ │WorkflowNodeExec │
│ (表) │ │ Model (表) │
└─────────────┘ └─────────────────┘
│ │
└────────────┬───────────────┘
▼
┌──────────────────┐
│ PostgreSQL │
└──────────────────┘架构图
plain
┌──────────────────────────────────────────────────┐
│ GraphEngine (事件驱动引擎) │
└──────────────────┬───────────────────────────────┘
│
┌─────────┴─────────┐
│ EventManager │
│ (事件管理器) │
└─────────┬─────────┘
│
│ notify_layers(event)
│
↓
┌─────────────────────┐
│ PersistenceLayer │
│ (持久化层) │
└─────────┬───────────┘
│
│ on_event(event)
│
┌─────────┴─────────┐
│ │
↓ ↓
WorkflowExecution WorkflowNodeExecution
Repository Repository
│ │
│ │
┌────┴────┐ ┌────┴────┐
│ │ │ │
↓ ↓ ↓ ↓
SQLAlchemy Logstore Celery ...
Repository Repository Repository
│ │ │
└────┬────┴────┬────┘
│ │
↓ ↓
PostgreSQL Aliyun SLS执行流程可视化
plain
时刻T0: 用户请求
↓
时刻T1: WorkflowEntry.run() 被调用
├─ GraphEngine 初始化
├─ PersistenceLayer 初始化
└─ GraphEngine.run() 启动
↓
时刻T2: GraphRunStartedEvent
├─ EventManager 收集事件
├─ PersistenceLayer 监听到事件
└─ PostgreSQL 写入: WorkflowRun (status=running)
↓
时刻T3: start节点入队
├─ ReadyQueue.put("start")
└─ Worker线程从队列取出"start"
↓
时刻T4: start节点开始执行
├─ NodeRunStartedEvent
├─ PersistenceLayer 写入: WorkflowNodeExecution (node_id=start, status=running)
└─ start.run() 执行
↓
时刻T5: start节点执行成功
├─ NodeRunSucceededEvent
├─ PersistenceLayer 更新: WorkflowNodeExecution (status=succeeded)
├─ EdgeProcessor 处理边: start → llm
└─ ReadyQueue.put("llm")
↓
时刻T6: llm节点开始执行
├─ NodeRunStartedEvent
├─ PersistenceLayer 写入: WorkflowNodeExecution (node_id=llm, status=running)
└─ llm.run() 调用GPT-3.5
↓
... (等待LLM响应) ...
↓
时刻T7: llm节点流式输出
├─ NodeRunStreamChunkEvent (多次)
└─ 前端实时显示生成的文本
↓
时刻T8: llm节点执行成功
├─ NodeRunSucceededEvent
├─ PersistenceLayer 更新: WorkflowNodeExecution (status=succeeded, outputs={text: "..."})
├─ EdgeProcessor 处理边: llm → end
└─ ReadyQueue.put("end")
↓
时刻T9: end节点开始执行
├─ NodeRunStartedEvent
├─ PersistenceLayer 写入: WorkflowNodeExecution (node_id=end, status=running)
└─ end.run() 执行
↓
时刻T10: end节点执行成功
├─ NodeRunSucceededEvent
├─ PersistenceLayer 更新: WorkflowNodeExecution (status=succeeded)
└─ EdgeProcessor: 没有更多边
↓
时刻T11: 工作流执行完成
├─ GraphRunSucceededEvent
├─ PersistenceLayer 更新: WorkflowRun (status=succeeded, outputs={answer: "..."})
└─ EventManager.mark_complete()
↓
时刻T12: 返回最终结果给用户持久化详细流程
PostgreSQL Repository PersistenceLayer EventManager 事件产生 PostgreSQL Repository PersistenceLayer EventManager 事件产生 节点执行产生事件 收集事件 通知Layer 创建领域实体 调用Repository 转换模型 数据库操作 节点执行完成 NodeRunStartedEvent collect(event) on_event(event) WorkflowNodeExecution.new() save(execution) _to_db_model(execution) session.merge(db_model) commit success saved handled NodeRunSucceededEvent on_event(event) save(execution) session.merge(db_model) commit success
!!!核心组件职责总结
| 组件 | 职责 | 输入 | 输出 |
|---|---|---|---|
| WorkflowEntry | 调度入口 | 用户请求 | 事件流 |
| GraphEngine | 协调引擎 | 图结构+状态 | 事件流 |
| WorkerPool | 并行执行 | 节点ID | 节点事件 |
| Dispatcher | 事件调度 | 事件队列 | 分发给EventHandler |
| EventHandler | 事件处理 | 事件 | 状态更新+触发下一个节点 |
| EventManager | 事件管理 | 事件 | 通知Layer+发射事件 |
| PersistenceLayer | 状态持久化 | 事件 | 数据库写入 |
| Repository | 数据访问 | 领域实体 | 数据库操作 |
设计模式总结
| 模式 | 应用位置 | 作用 |
|---|---|---|
| 门面模式 | WorkflowEntry | 简化外部调用 |
| 生产者-消费者 | ReadyQueue + Worker | 解耦节点执行 |
| 观察者模式 | EventManager + Layer | 事件通知 |
| 单分派模式 | EventHandler._dispatch | 事件路由 |
| Repository模式 | Repository | 抽象数据访问 |
| Layer模式 | GraphEngineLayer | 扩展功能 |
| 事件溯源 | 全局 | 状态管理 |
| 领域驱动设计 | 领域实体 | 业务逻辑与数据分离 |
数据库模型
WorkflowRun(工作流执行记录)
python
class WorkflowRun(Base):
"""
工作流执行的主记录表
存储:工作流执行的元数据和最终结果
"""
__tablename__ = "workflow_runs"
# ========== 核心字段 ==========
id: str # UUID - 执行 ID
tenant_id: str # 租户 ID(多租户隔离)
app_id: str # 应用 ID
workflow_id: str # 工作流 ID
# ========== 执行信息 ==========
type: str # 工作流类型:workflow / chatflow
triggered_from: str # 触发源:debugging / app-run
version: str # 工作流版本号
graph: str | None # 工作流 DSL 配置(JSON 字符串)
# ========== 输入输出 ==========
inputs: str | None # 输入参数(JSON 字符串)
outputs: str | None # 输出结果(JSON 字符串)
# ========== 状态信息 ==========
status: str # 状态:running / succeeded / failed / stopped / paused
error: str | None # 错误信息
# ========== 统计信息 ==========
elapsed_time: float # 执行耗时(秒)
total_tokens: int # 总 token 数
total_steps: int # 总执行步骤数
exceptions_count: int # 异常节点数
# ========== 时间信息 ==========
created_at: datetime # 创建时间(开始时间)
finished_at: datetime | None # 完成时间
# ========== 创建者信息 ==========
created_by_role: str # 创建者角色:account / end_user
created_by: str # 创建者 ID示例数据:
json
{
"id": "09b3e04c-f9ae-404c-ad82-290b8d7bd382",
"tenant_id": "tenant_123",
"app_id": "app_456",
"workflow_id": "wf_789",
"type": "workflow",
"triggered_from": "app-run",
"version": "2024-01-14T10:30:00",
"graph": "{\"nodes\": [...], \"edges\": [...]}",
"inputs": "{\"query\": \"解释量子计算\"}",
"outputs": "{\"answer\": \"量子计算是...\"}",
"status": "succeeded",
"error": null,
"elapsed_time": 3.45,
"total_tokens": 150,
"total_steps": 3,
"exceptions_count": 0,
"created_at": "2024-01-14 10:30:00",
"finished_at": "2024-01-14 10:30:03",
"created_by_role": "account",
"created_by": "user_abc"
}WorkflowNodeExecutionModel(节点执行记录)
python
class WorkflowNodeExecutionModel(Base):
"""
节点执行的详细记录表
存储:每个节点执行的详细信息(输入、输出、过程数据)
"""
__tablename__ = "workflow_node_executions"
# ========== 核心字段 ==========
id: str # UUID - 记录 ID
node_execution_id: str | None # 节点执行 ID(用于引用)
tenant_id: str # 租户 ID
app_id: str # 应用 ID
workflow_id: str # 工作流 ID
# ========== 关联关系 ==========
workflow_run_id: str | None # 所属工作流执行 ID
triggered_from: str # 触发源:single-step / workflow-run
index: int # 执行序号(用于排序)
predecessor_node_id: str | None # 前驱节点 ID
# ========== 节点信息 ==========
node_id: str # 节点 ID(如:llm_1)
node_type: str # 节点类型(如:llm, code, tool)
title: str # 节点标题
# ========== 执行数据 ==========
inputs: str | None # 输入数据(JSON 字符串,可能被截断)
process_data: str | None # 过程数据(JSON 字符串,可能被截断)
outputs: str | None # 输出数据(JSON 字符串,可能被截断)
# ========== 状态信息 ==========
status: str # 状态:running / succeeded / failed / retry
error: str | None # 错误信息
elapsed_time: float # 执行耗时(秒)
# ========== 元数据 ==========
execution_metadata: str | None # 执行元数据(JSON),如:
# - total_tokens
# - total_price
# - currency
# - iteration_id
# - loop_id
# ========== 时间信息 ==========
created_at: datetime # 创建时间(节点开始时间)
finished_at: datetime | None # 完成时间
# ========== 创建者信息 ==========
created_by_role: str # 创建者角色
created_by: str # 创建者 ID
# ========== 关联关系(ORM) ==========
offload_data: list[WorkflowNodeExecutionOffload] # 卸载数据(大数据)索引设计:
python
# 索引 1:按工作流执行查询
Index("workflow_node_execution_workflow_run_idx",
"tenant_id", "app_id", "workflow_id",
"triggered_from", "workflow_run_id")
# 索引 2:按节点查询历史
Index("workflow_node_execution_node_run_idx",
"tenant_id", "app_id", "workflow_id",
"triggered_from", "node_id")
# 索引 3:按执行 ID 查询
Index("workflow_node_execution_id_idx",
"tenant_id", "app_id", "workflow_id",
"triggered_from", "node_execution_id")WorkflowNodeExecutionOffload(大数据卸载表)
python
class WorkflowNodeExecutionOffload(Base):
"""
大数据卸载表
用途:当节点的 inputs/outputs/process_data 超过阈值时,
完整数据存储到对象存储(如 S3),数据库只保存截断版本
"""
__tablename__ = "workflow_node_execution_offload"
id: str # UUID - 卸载记录 ID
created_at: datetime # 创建时间
tenant_id: str # 租户 ID
app_id: str # 应用 ID
node_execution_id: str | None # 关联的节点执行 ID
type_: ExecutionOffLoadType # 卸载类型:INPUTS / OUTPUTS / PROCESS_DATA
file_id: str # 对象存储中的文件 ID
# 关联关系(ORM)
file: UploadFile # 文件记录
execution: WorkflowNodeExecutionModel # 节点执行记录卸载策略:
python
# 配置阈值(来自 dify_config)
WORKFLOW_VARIABLE_TRUNCATION_MAX_SIZE = 1024 * 1024 # 1MB
WORKFLOW_VARIABLE_TRUNCATION_ARRAY_LENGTH = 100 # 数组最大 100 个元素
WORKFLOW_VARIABLE_TRUNCATION_STRING_LENGTH = 10000 # 字符串最大 10000 字符
# 判断是否需要卸载
if data_size > MAX_SIZE:
# 1. 截断数据(保留摘要)
truncated_data = truncator.truncate(original_data)
# 2. 完整数据上传到对象存储
file = upload_to_storage(original_data)
# 3. 数据库存储截断版本
db_model.inputs = json.dumps(truncated_data)
# 4. 创建卸载记录
offload = WorkflowNodeExecutionOffload(
type_=ExecutionOffLoadType.INPUTS,
file_id=file.id
)事件驱动持久化层
工作流持久化层 WorkflowPersistenceLayer
python
class WorkflowPersistenceLayer(GraphEngineLayer):
"""
【核心功能】工作流持久化层
作用:
1. 监听 GraphEngine 产生的事件
2. 根据事件类型更新数据库状态
3. 实现增量持久化,避免阻塞执行
特点:
- 事件驱动:不主动查询,被动响应事件
- 增量更新:只在状态变化时写入
- 异步友好:在独立线程中处理
"""
def __init__(
self,
*,
application_generate_entity,
workflow_info: PersistenceWorkflowInfo,
workflow_execution_repository: WorkflowExecutionRepository,
workflow_node_execution_repository: WorkflowNodeExecutionRepository,
trace_manager: TraceQueueManager | None = None,
) -> None:
"""
初始化持久化层
参数:
workflow_info: 工作流静态信息(ID、版本、DSL)
workflow_execution_repository: 工作流执行仓库
workflow_node_execution_repository: 节点执行仓库
trace_manager: 追踪管理器(用于 OTel)
"""
self._workflow_info = workflow_info
self._workflow_execution_repository = workflow_execution_repository
self._workflow_node_execution_repository = workflow_node_execution_repository
self._trace_manager = trace_manager
# ========== 内存缓存 ==========
self._workflow_execution: WorkflowExecution | None = None
self._node_execution_cache: dict[str, WorkflowNodeExecution] = {}
self._node_snapshots: dict[str, _NodeRuntimeSnapshot] = {}
self._node_sequence: int = 0
def on_event(self, event: GraphEngineEvent) -> None:
"""
【核心方法】事件处理分发器
根据事件类型调用相应的处理方法
"""
# ========== 工作流级别事件 ==========
if isinstance(event, GraphRunStartedEvent):
self._handle_graph_run_started()
return
if isinstance(event, GraphRunSucceededEvent):
self._handle_graph_run_succeeded(event)
return
if isinstance(event, GraphRunFailedEvent):
self._handle_graph_run_failed(event)
return
if isinstance(event, GraphRunAbortedEvent):
self._handle_graph_run_aborted(event)
return
if isinstance(event, GraphRunPausedEvent):
self._handle_graph_run_paused(event)
return
# ========== 节点级别事件 ==========
if isinstance(event, NodeRunStartedEvent):
self._handle_node_started(event)
return
if isinstance(event, NodeRunSucceededEvent):
self._handle_node_succeeded(event)
return
if isinstance(event, NodeRunFailedEvent):
self._handle_node_failed(event)
return
if isinstance(event, NodeRunRetryEvent):
self._handle_node_retry(event)
return
if isinstance(event, NodeRunExceptionEvent):
self._handle_node_exception(event)
return工作流级别事件处理
python
def _handle_graph_run_started(self) -> None:
"""
【事件】工作流开始
动作:
1. 创建 WorkflowExecution 领域对象
2. 持久化到数据库
3. 缓存到内存
"""
execution_id = self._get_execution_id() # 从系统变量获取
# ========== 创建领域对象 ==========
workflow_execution = WorkflowExecution.new(
id_=execution_id,
workflow_id=self._workflow_info.workflow_id,
workflow_type=self._workflow_info.workflow_type,
workflow_version=self._workflow_info.version,
graph=self._workflow_info.graph_data, # 工作流 DSL
inputs=self._prepare_workflow_inputs(), # 输入参数
started_at=naive_utc_now(),
)
# 此时状态: status = WorkflowExecutionStatus.RUNNING
# ========== 持久化 ==========
self._workflow_execution_repository.save(workflow_execution)
# ========== 缓存 ==========
self._workflow_execution = workflow_execution
# 数据库记录示例:
# INSERT INTO workflow_runs (
# id, tenant_id, app_id, workflow_id, status, inputs, created_at
# ) VALUES (
# 'exec_123', 'tenant_1', 'app_1', 'wf_1',
# 'running', '{"query": "..."}', NOW()
# );
def _handle_graph_run_succeeded(self, event: GraphRunSucceededEvent) -> None:
"""
【事件】工作流成功完成
动作:
1. 更新输出结果
2. 更新状态为 SUCCEEDED
3. 更新统计信息(tokens、steps、耗时)
4. 持久化
5. 触发追踪任务
"""
execution = self._get_workflow_execution()
# ========== 更新状态 ==========
execution.outputs = event.outputs # 最终输出
execution.status = WorkflowExecutionStatus.SUCCEEDED
# ========== 更新统计信息 ==========
self._populate_completion_statistics(execution)
# 内部逻辑:
# - execution.finished_at = now()
# - execution.total_tokens = runtime_state.total_tokens
# - execution.total_steps = runtime_state.node_run_steps
# ========== 持久化 ==========
self._workflow_execution_repository.save(execution)
# ========== 触发追踪 ==========
self._enqueue_trace_task(execution) # 发送到 OTel
# 数据库更新示例:
# UPDATE workflow_runs SET
# status = 'succeeded',
# outputs = '{"answer": "..."}',
# finished_at = NOW(),
# elapsed_time = 3.45,
# total_tokens = 150,
# total_steps = 3
# WHERE id = 'exec_123';
def _handle_graph_run_failed(self, event: GraphRunFailedEvent) -> None:
"""
【事件】工作流执行失败
动作:
1. 更新状态为 FAILED
2. 记录错误信息
3. 标记所有运行中的节点为失败
4. 持久化
"""
execution = self._get_workflow_execution()
execution.status = WorkflowExecutionStatus.FAILED
execution.error_message = event.error
execution.exceptions_count = event.exceptions_count
self._populate_completion_statistics(execution)
# ========== 处理运行中的节点 ==========
self._fail_running_node_executions(error_message=event.error)
# ========== 持久化 ==========
self._workflow_execution_repository.save(execution)
self._enqueue_trace_task(execution)节点级别事件处理
python
def _handle_node_started(self, event: NodeRunStartedEvent) -> None:
"""
【事件】节点开始执行
动作:
1. 创建 WorkflowNodeExecution 领域对象
2. 立即持久化(状态=RUNNING)
3. 缓存到内存
"""
execution = self._get_workflow_execution()
# ========== 准备元数据 ==========
metadata = {
WorkflowNodeExecutionMetadataKey.ITERATION_ID: event.in_iteration_id,
WorkflowNodeExecutionMetadataKey.LOOP_ID: event.in_loop_id,
}
# ========== 创建领域对象 ==========
domain_execution = WorkflowNodeExecution(
id=event.id, # 执行 ID
node_execution_id=event.id,
workflow_id=execution.workflow_id,
workflow_execution_id=execution.id_,
predecessor_node_id=event.predecessor_node_id, # 前驱节点
index=self._next_node_sequence(), # 自增序号
node_id=event.node_id, # 节点 ID(如:llm_1)
node_type=event.node_type, # 节点类型
title=event.node_title, # 节点标题
status=WorkflowNodeExecutionStatus.RUNNING, # 状态:运行中
metadata=metadata,
created_at=event.start_at, # 开始时间
)
# ========== 持久化 ==========
self._node_execution_cache[event.id] = domain_execution
self._workflow_node_execution_repository.save(domain_execution)
# ========== 缓存快照 ==========
snapshot = _NodeRuntimeSnapshot(
node_id=event.node_id,
title=event.node_title,
predecessor_node_id=event.predecessor_node_id,
iteration_id=event.in_iteration_id,
loop_id=event.in_loop_id,
created_at=event.start_at,
)
self._node_snapshots[event.id] = snapshot
# 数据库插入示例:
# INSERT INTO workflow_node_executions (
# id, workflow_run_id, node_id, node_type,
# title, status, index, created_at
# ) VALUES (
# 'node_exec_1', 'exec_123', 'llm_1', 'llm',
# 'LLM节点', 'running', 1, NOW()
# );
def _handle_node_succeeded(self, event: NodeRunSucceededEvent) -> None:
"""
【事件】节点执行成功
动作:
1. 更新状态为 SUCCEEDED
2. 存储输入、输出、过程数据
3. 计算耗时
4. 持久化(包括大数据卸载)
"""
domain_execution = self._get_node_execution(event.id)
self._update_node_execution(
domain_execution,
event.node_run_result, # 包含 inputs, outputs, process_data
WorkflowNodeExecutionStatus.SUCCEEDED
)
def _update_node_execution(
self,
domain_execution: WorkflowNodeExecution,
node_result: NodeRunResult,
status: WorkflowNodeExecutionStatus,
*,
error: str | None = None,
update_outputs: bool = True,
) -> None:
"""
【核心方法】更新节点执行记录
"""
# ========== 计算耗时 ==========
finished_at = naive_utc_now()
snapshot = self._node_snapshots.get(domain_execution.id)
start_at = snapshot.created_at if snapshot else domain_execution.created_at
domain_execution.elapsed_time = (finished_at - start_at).total_seconds()
# ========== 更新状态 ==========
domain_execution.status = status
domain_execution.finished_at = finished_at
if error:
domain_execution.error = error
# ========== 更新执行数据 ==========
if update_outputs:
domain_execution.update_from_mapping(
inputs=node_result.inputs, # 节点输入
process_data=node_result.process_data, # 过程数据
outputs=node_result.outputs, # 节点输出
metadata=node_result.metadata, # 元数据(tokens等)
)
# ========== 两阶段持久化 ==========
# 阶段 1:保存基本信息
self._workflow_node_execution_repository.save(domain_execution)
# 阶段 2:保存执行数据(可能触发大数据卸载)
self._workflow_node_execution_repository.save_execution_data(domain_execution)
# 数据库更新示例:
# UPDATE workflow_node_executions SET
# status = 'succeeded',
# inputs = '{"query": "..."}',
# outputs = '{"output": "..."}',
# finished_at = NOW(),
# elapsed_time = 1.23
# WHERE id = 'node_exec_1';Repository 模式实现
SQLAlchemyWorkflowExecutionRepository
python
class SQLAlchemyWorkflowExecutionRepository(WorkflowExecutionRepository):
"""
工作流执行仓库(SQLAlchemy 实现)
职责:
- 领域对象与数据库模型之间的转换
- 数据库CRUD操作
- 内存缓存管理
- 多租户隔离
"""
def __init__(
self,
session_factory: sessionmaker | Engine,
user: Union[Account, EndUser],
app_id: str | None,
triggered_from: WorkflowRunTriggeredFrom | None,
):
self._session_factory = session_factory
self._tenant_id = extract_tenant_id(user)
self._app_id = app_id
self._triggered_from = triggered_from
self._creator_user_id = user.id
self._creator_user_role = (
CreatorUserRole.ACCOUNT
if isinstance(user, Account)
else CreatorUserRole.END_USER
)
# ========== 内存缓存 ==========
self._execution_cache: dict[str, WorkflowRun] = {}
def save(self, execution: WorkflowExecution):
"""
【核心方法】保存工作流执行记录
步骤:
1. 领域对象 → 数据库模型
2. 使用 SQLAlchemy merge(自动判断 INSERT/UPDATE)
3. 更新内存缓存
"""
# ========== 步骤 1:转换模型 ==========
db_model = self._to_db_model(execution)
# ========== 步骤 2:持久化 ==========
with self._session_factory() as session:
# merge 方法会自动判断是插入还是更新
# - 如果 ID 存在:UPDATE
# - 如果 ID 不存在:INSERT
session.merge(db_model)
session.commit()
# ========== 步骤 3:更新缓存 ==========
self._execution_cache[db_model.id] = db_model
def _to_db_model(self, domain_model: WorkflowExecution) -> WorkflowRun:
"""
【转换】领域对象 → 数据库模型
"""
db_model = WorkflowRun()
# 基本字段
db_model.id = domain_model.id_
db_model.workflow_id = domain_model.workflow_id
db_model.type = domain_model.workflow_type
db_model.version = domain_model.workflow_version
# JSON 字段(序列化)
db_model.graph = json.dumps(domain_model.graph)
db_model.inputs = json.dumps(domain_model.inputs)
db_model.outputs = json.dumps(
WorkflowRuntimeTypeConverter().to_json_encodable(domain_model.outputs)
)
# 状态字段
db_model.status = domain_model.status
db_model.error = domain_model.error_message or None
# 统计字段
db_model.total_tokens = domain_model.total_tokens
db_model.total_steps = domain_model.total_steps
db_model.exceptions_count = domain_model.exceptions_count
# 时间字段
db_model.created_at = domain_model.started_at
db_model.finished_at = domain_model.finished_at
if domain_model.finished_at:
db_model.elapsed_time = (
domain_model.finished_at - domain_model.started_at
).total_seconds()
# 多租户字段(从构造函数注入)
db_model.tenant_id = self._tenant_id
db_model.app_id = self._app_id
db_model.triggered_from = self._triggered_from
db_model.created_by_role = self._creator_user_role
db_model.created_by = self._creator_user_id
return db_modelSQLAlchemyWorkflowNodeExecutionRepository
python
class SQLAlchemyWorkflowNodeExecutionRepository(WorkflowNodeExecutionRepository):
"""
节点执行仓库(SQLAlchemy 实现)
特殊功能:
- 大数据截断和卸载
- 并发数据加载
- 重试机制(处理 UUID 冲突)
"""
def save(self, execution: WorkflowNodeExecution) -> None:
"""
【核心方法】保存节点执行记录(基本信息)
注意:此方法只保存基本字段,不处理大数据
大数据由 save_execution_data() 处理
"""
db_model = self._to_db_model(execution)
# ========== 重试机制(处理 UUID 冲突) ==========
@retry(
stop=stop_after_attempt(3),
retry=retry_if_exception(self._is_duplicate_key_error),
reraise=True,
)
def _save_with_retry():
try:
self._persist_to_database(db_model)
except IntegrityError as e:
if self._is_duplicate_key_error(e):
# 生成新的 UUID v7 并重试
self._regenerate_id_on_duplicate(execution, db_model)
raise
else:
raise
_save_with_retry()
# 更新缓存
if db_model.node_execution_id:
self._node_execution_cache[db_model.node_execution_id] = db_model
def save_execution_data(self, execution: WorkflowNodeExecution):
"""
【核心方法】保存节点执行数据(inputs, outputs, process_data)
特点:
1. 检查数据大小
2. 超过阈值则截断并卸载到对象存储
3. 数据库只保存截断版本
"""
domain_model = execution
# ========== 加载现有记录 ==========
with self._session_factory(expire_on_commit=False) as session:
query = WorkflowNodeExecutionModel.preload_offload_data(
select(WorkflowNodeExecutionModel)
).where(WorkflowNodeExecutionModel.id == domain_model.id)
db_model = session.execute(query).scalars().first()
if db_model is None:
db_model = self._to_db_model(domain_model)
offload_data = db_model.offload_data or []
# ========== 处理 inputs ==========
if domain_model.inputs is not None:
result = self._truncate_and_upload(
domain_model.inputs,
domain_model.id,
ExecutionOffLoadType.INPUTS,
)
if result is not None:
# 数据被截断,需要卸载
db_model.inputs = self._json_encode(result.truncated_value)
domain_model.set_truncated_inputs(result.truncated_value)
offload_data = _replace_or_append_offload(offload_data, result.offload)
else:
# 数据未超阈值,直接存储
db_model.inputs = self._json_encode(domain_model.inputs)
# ========== 处理 outputs(同理) ==========
if domain_model.outputs is not None:
result = self._truncate_and_upload(
domain_model.outputs,
domain_model.id,
ExecutionOffLoadType.OUTPUTS,
)
if result is not None:
db_model.outputs = self._json_encode(result.truncated_value)
domain_model.set_truncated_outputs(result.truncated_value)
offload_data = _replace_or_append_offload(offload_data, result.offload)
else:
db_model.outputs = self._json_encode(domain_model.outputs)
# ========== 处理 process_data(同理) ==========
if domain_model.process_data is not None:
result = self._truncate_and_upload(
domain_model.process_data,
domain_model.id,
ExecutionOffLoadType.PROCESS_DATA,
)
if result is not None:
db_model.process_data = self._json_encode(result.truncated_value)
domain_model.set_truncated_process_data(result.truncated_value)
offload_data = _replace_or_append_offload(offload_data, result.offload)
else:
db_model.process_data = self._json_encode(domain_model.process_data)
# ========== 更新卸载数据 ==========
db_model.offload_data = offload_data
# ========== 持久化 ==========
with self._session_factory() as session, session.begin():
session.merge(db_model)
session.flush()
def _truncate_and_upload(
self,
values: Mapping[str, Any] | None,
execution_id: str,
type_: ExecutionOffLoadType,
) -> _InputsOutputsTruncationResult | None:
"""
【核心方法】截断并上传大数据
返回:
None:数据未超阈值
Result:包含截断版本、文件、卸载记录
"""
if values is None:
return None
# ========== 步骤 1:JSON 序列化 ==========
converter = WorkflowRuntimeTypeConverter()
json_encodable_value = converter.to_json_encodable(values)
# ========== 步骤 2:截断检查 ==========
truncator = self._create_truncator()
truncated_values, truncated = truncator.truncate_variable_mapping(
json_encodable_value
)
if not truncated:
return None # 未超阈值,无需卸载
# ========== 步骤 3:上传完整数据到对象存储 ==========
value_json = json.dumps(json_encodable_value, sort_keys=True)
upload_file = self._file_service.upload_file(
filename=f"node_execution_{execution_id}_{type_.value}.json",
content=value_json.encode("utf-8"),
mimetype="application/json",
user=self._user,
)
# ========== 步骤 4:创建卸载记录 ==========
offload = WorkflowNodeExecutionOffload(
id=uuidv7(),
tenant_id=self._tenant_id,
app_id=self._app_id,
node_execution_id=execution_id,
type_=type_,
file_id=upload_file.id,
)
return _InputsOutputsTruncationResult(
truncated_value=truncated_values,
file=upload_file,
offload=offload,
)完整执行流程示例
场景:执行一个包含 3 个节点的工作流
plain
工作流:START → LLM → CODE时序图
ObjectStorage PostgreSQL NodeExecRepo WorkflowExecRepo PersistenceLayer GraphEngine ObjectStorage PostgreSQL NodeExecRepo WorkflowExecRepo PersistenceLayer GraphEngine 工作流开始 START 节点开始 START 节点成功 LLM 节点开始 LLM 节点成功 CODE 节点开始 CODE 节点成功 工作流成功 GraphRunStartedEvent save(WorkflowExecution) INSERT INTO workflow_runs OK NodeRunStartedEvent(start) save(NodeExecution) INSERT INTO workflow_node_executions OK NodeRunSucceededEvent(start) save_execution_data(start) 检查数据大小 UPDATE workflow_node_executions OK NodeRunStartedEvent(llm_1) save(NodeExecution) INSERT INTO workflow_node_executions OK NodeRunSucceededEvent(llm_1) save_execution_data(llm_1) 数据超过1MB!需要卸载 上传完整数据 file_id: abc123 UPDATE workflow_node_executions (保存截断版本) INSERT INTO workflow_node_execution_offload OK NodeRunStartedEvent(code_1) save(NodeExecution) INSERT INTO workflow_node_executions OK NodeRunSucceededEvent(code_1) save_execution_data(code_1) UPDATE workflow_node_executions OK GraphRunSucceededEvent save(WorkflowExecution) UPDATE workflow_runs (status=succeeded) OK
数据库记录快照
T1: 工作流开始后
sql
-- workflow_runs 表
SELECT id, status, inputs, outputs, created_at, finished_at
FROM workflow_runs
WHERE id = 'exec_123';
/*
id | status | inputs | outputs | created_at | finished_at
-----------+---------+---------------------------+---------+---------------------+------------
exec_123 | running | {"query": "解释量子计算"} | NULL | 2024-01-14 10:30:00 | NULL
*/
-- workflow_node_executions 表(空)
SELECT COUNT(*) FROM workflow_node_executions WHERE workflow_run_id = 'exec_123';
-- 结果:0T2: START 节点执行完成后
sql
SELECT id, node_id, status, inputs, outputs, created_at, finished_at
FROM workflow_node_executions
WHERE workflow_run_id = 'exec_123'
ORDER BY index;
/*
id | node_id | status | inputs | outputs | created_at | finished_at
-------------+---------+-----------+-----------------------------+-----------------------------+---------------------+---------------------
node_exec_1 | start | succeeded | {} | {"query": "解释量子计算"} | 2024-01-14 10:30:00 | 2024-01-14 10:30:00
*/T3: LLM 节点执行完成后(大数据卸载)
sql
-- 节点执行记录(截断版本)
SELECT id, node_id, status,
LENGTH(inputs), LENGTH(outputs),
created_at, finished_at
FROM workflow_node_executions
WHERE workflow_run_id = 'exec_123' AND node_id = 'llm_1';
/*
id | node_id | status | LENGTH(inputs) | LENGTH(outputs) | created_at | finished_at
-------------+---------+-----------+----------------+-----------------+---------------------+---------------------
node_exec_2 | llm_1 | succeeded | 512 | 2048 | 2024-01-14 10:30:01 | 2024-01-14 10:30:03
*/
-- 注意:outputs 被截断到 2048 字节
-- 卸载记录
SELECT id, node_execution_id, type_, file_id
FROM workflow_node_execution_offload
WHERE node_execution_id = 'node_exec_2';
/*
id | node_execution_id | type_ | file_id
-------------+-------------------+---------+----------
offload_1 | node_exec_2 | OUTPUTS | file_456
*/
-- 完整数据在对象存储中:s3://bucket/uploads/file_456.jsonT4: 工作流完成后
sql
-- 工作流记录(最终状态)
SELECT id, status, outputs, total_tokens, total_steps,
created_at, finished_at, elapsed_time
FROM workflow_runs
WHERE id = 'exec_123';
/*
id | status | outputs | total_tokens | total_steps | created_at | finished_at | elapsed_time
-----------+-----------+------------------------------+--------------+-------------+---------------------+---------------------+-------------
exec_123 | succeeded | {"answer": "量子计算是..."} | 150 | 3 | 2024-01-14 10:30:00 | 2024-01-14 10:30:05 | 5.0
*/
-- 所有节点执行记录
SELECT index, node_id, node_type, status, elapsed_time
FROM workflow_node_executions
WHERE workflow_run_id = 'exec_123'
ORDER BY index;
/*
index | node_id | node_type | status | elapsed_time
------+---------+-----------+-----------+-------------
1 | start | start | succeeded | 0.05
2 | llm_1 | llm | succeeded | 2.34
3 | code_1 | code | succeeded | 0.12
*/核心特性总结
1. 事件驱动架构
plain
✅ 优势:
- 解耦:执行引擎和持久化层独立
- 实时:状态变化立即写入
- 可追溯:完整的事件历史
- 可扩展:通过 Layer 添加新功能
❌ 劣势:
- 复杂度:需要维护事件处理逻辑
- 一致性:需要确保事件顺序2. 增量持久化
plain
节点开始 → INSERT (status=running, inputs=NULL, outputs=NULL)
节点执行中 → (无数据库操作,避免频繁写入)
节点完成 → UPDATE (status=succeeded, inputs={...}, outputs={...})3. 大数据卸载
plain
数据 < 1MB → 直接存储在 PostgreSQL
数据 ≥ 1MB → PostgreSQL 存储截断版本 + S3 存储完整数据4. 多租户隔离
plain
所有查询都带 tenant_id 过滤
Repository 在构造时注入 tenant_id
确保数据安全隔离5. 内存缓存
plain
减少数据库查询
提高执行性能
在事件处理中复用缓存数据6. 重试机制
plain
处理 UUID 冲突(UUID v7 基于时间戳可能冲突)
自动重新生成 ID 并重试
最多重试 3 次与传统事件溯源的对比
| 特性 | Dify 实现 | 传统 Event Sourcing |
|---|---|---|
| 事件存储 | 不存储事件,只存储最终状态 | 存储所有事件 |
| 状态恢复 | 直接从数据库读取最终状态 | 从事件流重放 |
| 持久化方式 | 监听事件→更新状态 | 追加事件到事件流 |
| 查询性能 | 快速(直接查询状态表) | 慢(需要重放事件或使用物化视图) |
| 历史追溯 | 有限(只有节点执行历史) | 完整(所有事件都被记录) |
| 复杂度 | 中等 | 高 |
| 适用场景 | 工作流执行追踪 | 需要完整审计日志的场景 |
Dify 的选择:
- ✅ 更简单的实现
- ✅ 更好的查询性能
- ✅ 足够的追溯能力(节点级别)
- ❌ 不支持完整的事件回放
- ❌ 无法重建任意时间点的状态
这个设计在实用性 和复杂度之间取得了很好的平衡!
事件驱动架构深度分析:生产者-消费者模式
总结
Dify 的事件驱动架构是一个经典的生产者-消费者模式,通过以下设计实现了高效的工作流执行:
- 多生产者(Workers)→ 单消费者(Dispatcher):避免消费端竞态
- 双队列设计:ReadyQueue(任务)+ EventQueue(事件)解耦执行和处理
- 无界队列 + 动态扩缩容:在吞吐量和资源之间取得平衡
- 线程池管理:根据负载自动调整 Worker 数量
- 事件驱动持久化:通过监听事件实现增量状态保存
这个架构在实用性、性能和可维护性之间取得了很好的平衡
整体架构图
plain
┌─────────────────────────────────────────────────────────────────────┐
│ GraphEngine │
│ │
│ ┌──────────────────────────────────────────────────────────────┐ │
│ │ 生产者集群 │ │
│ │ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ │
│ │ │Worker-1 │ │Worker-2 │ │Worker-3 │ │Worker-N │ │ │
│ │ │(Thread) │ │(Thread) │ │(Thread) │ │(Thread) │ ... │ │
│ │ └────┬────┘ └────┬────┘ └────┬────┘ └────┬────┘ │ │
│ │ │ │ │ │ │ │
│ │ │ get() │ get() │ get() │ get() │ │
│ │ ▼ ▼ ▼ ▼ │ │
│ │ ┌──────────────────────────────────────────────────────┐ │ │
│ │ │ ReadyQueue (FIFO) │ │ │
│ │ │ ["llm_1", "code_1", "tool_1", ...] │ │ │
│ │ │ ↑ 节点 ID 队列 (无界 Queue) │ │ │
│ │ └──────────────────────────────────────────────────────┘ │ │
│ │ │ │
│ │ │ │ │ │ │ │
│ │ │ put() │ put() │ put() │ put() │ │
│ │ ▼ ▼ ▼ ▼ │ │
│ │ ┌──────────────────────────────────────────────────────┐ │ │
│ │ │ EventQueue (FIFO) │ │ │
│ │ │ [NodeStarted, StreamChunk, NodeSucceeded, ...] │ │ │
│ │ │ ↑ 事件对象队列 (无界 Queue) │ │ │
│ │ └──────────────────────────────────────────────────────┘ │ │
│ └──────────────────────────────────────────────────────────────┘ │
│ │ │
│ │ get() │
│ ▼ │
│ ┌──────────────────────────────────────────────────────────────┐ │
│ │ 消费者 │ │
│ │ ┌──────────────────────────────────────────────────────┐ │ │
│ │ │ Dispatcher (Thread) │ │ │
│ │ │ - 从 EventQueue 取事件 │ │ │
│ │ │ - 分发给 EventHandler │ │ │
│ │ │ - 通知 EventManager │ │ │
│ │ └──────────────────────────────────────────────────────┘ │ │
│ └──────────────────────────────────────────────────────────────┘ │
│ │ │
│ │ dispatch() │
│ ▼ │
│ ┌──────────────────────────────────────────────────────────────┐ │
│ │ EventHandler (单例, 非线程) │ │
│ │ - 根据事件类型路由 │ │
│ │ - 更新状态、处理边、入队下游节点 │ │
│ └──────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────┘线程模型详解
线程架构
plain
主线程 (调用 graph_engine.run())
│
├─> 启动 WorkerPool (N 个 Worker 线程)
│ │
│ ├─> Worker-1 线程 ──┐
│ ├─> Worker-2 线程 ──┤
│ ├─> Worker-3 线程 ──┼─> 并行执行节点,产生事件
│ └─> Worker-N 线程 ──┘
│
├─> 启动 Dispatcher 线程
│ └─> 消费事件,分发处理
│
└─> 进入 EventManager.emit_events()
└─> 作为生成器,向用户流式返回事件线程安全保证
python
# 使用 Python 标准库的线程安全队列
import queue
# ReadyQueue:多生产者(StateManager)、多消费者(Workers)
ready_queue = queue.Queue() # 线程安全的 FIFO 队列
# EventQueue:多生产者(Workers)、单消费者(Dispatcher)
event_queue = queue.Queue() # 线程安全的 FIFO 队列
# queue.Queue 内部使用锁机制保证线程安全:
# - self.mutex: threading.Lock()
# - self.not_empty: threading.Condition(self.mutex)
# - self.not_full: threading.Condition(self.mutex)生产者:Worker 线程池
Worker 生命周期
python
class Worker(threading.Thread):
"""
【生产者】Worker 线程
职责:
1. 从 ReadyQueue 获取节点 ID
2. 执行节点逻辑
3. 将生成的事件放入 EventQueue
"""
def run(self) -> None:
"""
【核心方法】Worker 主循环
流程:
1. 从 ReadyQueue 阻塞获取节点 ID(带超时)
2. 执行节点
3. 将所有事件 put 到 EventQueue
4. 标记任务完成
5. 循环直到停止信号
"""
while not self._stop_event.is_set():
# ========== 步骤 1:获取节点 ID ==========
try:
# 阻塞等待,超时 0.1 秒
# 这样可以定期检查 stop_event
node_id = self._ready_queue.get(timeout=0.1)
except queue.Empty:
continue # 队列空,继续等待
# ========== 步骤 2:记录活动时间 ==========
self._last_task_time = time.time()
# ========== 步骤 3:获取节点实例 ==========
node = self._graph.nodes[node_id]
try:
# ========== 步骤 4:执行节点 ==========
self._execute_node(node)
# ========== 步骤 5:标记任务完成 ==========
self._ready_queue.task_done()
except Exception as e:
# ========== 步骤 6:异常处理 ==========
# 即使节点执行失败,也要产生错误事件
error_event = NodeRunFailedEvent(
id=str(uuid4()),
node_id=node.id,
node_type=node.node_type,
error=str(e),
start_at=datetime.now(),
)
self._event_queue.put(error_event)
def _execute_node(self, node: Node) -> None:
"""
【核心方法】执行单个节点
流程:
1. 调用前置钩子(Layers)
2. 调用 node.run(),获取事件生成器
3. 遍历事件生成器,将每个事件 put 到 EventQueue
4. 调用后置钩子(Layers)
"""
node.ensure_execution_id()
error: Exception | None = None
# ========== 前置钩子 ==========
self._invoke_node_run_start_hooks(node)
try:
# ========== 执行节点,获取事件生成器 ==========
node_events = node.run() # Generator[GraphNodeEventBase, None, None]
# ========== 遍历事件,逐个放入 EventQueue ==========
for event in node_events:
# 非阻塞 put(因为 EventQueue 是无界的)
self._event_queue.put(event)
# 关键点:这里是同步 put,不会阻塞
# 因为 queue.Queue(maxsize=0) 是无界队列
except Exception as exc:
error = exc
raise
finally:
# ========== 后置钩子 ==========
self._invoke_node_run_end_hooks(node, error)事件生成示例
python
# 节点执行产生的事件序列
node_events = node.run() # 返回生成器
# 示例:LLM 节点产生的事件流
events = [
NodeRunStartedEvent(
id="exec_1",
node_id="llm_1",
node_type="llm",
start_at=datetime.now(),
),
NodeRunStreamChunkEvent(
id="exec_1",
node_id="llm_1",
chunk="Hello",
from_variable_selector=["llm_1", "output"],
),
NodeRunStreamChunkEvent(
id="exec_1",
node_id="llm_1",
chunk=" world",
from_variable_selector=["llm_1", "output"],
),
NodeRunSucceededEvent(
id="exec_1",
node_id="llm_1",
node_run_result=NodeRunResult(
outputs={"output": "Hello world"},
llm_usage=LLMUsage(tokens=10),
),
),
]
# Worker 将这些事件逐个放入 EventQueue
for event in events:
self._event_queue.put(event) # 线程安全的 put3. Worker 池动态扩缩容
python
class WorkerPool:
"""
【核心功能】Worker 池管理
特点:
1. 动态扩缩容:根据队列深度自动调整 Worker 数量
2. 最小/最大限制:避免资源浪费和过载
3. 空闲检测:移除长时间空闲的 Worker
"""
def check_and_scale(self) -> None:
"""
【核心方法】检查并执行扩缩容
触发时机:Dispatcher 在每次循环时调用
"""
with self._lock:
if not self._running:
return
# ========== 收集指标 ==========
current_count = len(self._workers) # 当前 Worker 数
queue_depth = self._ready_queue.qsize() # 队列深度
# 统计 Worker 状态
idle_count = sum(1 for w in self._workers if w.is_idle)
active_count = current_count - idle_count
# ========== 尝试扩容 ==========
self._try_scale_up(queue_depth, current_count)
# ========== 尝试缩容 ==========
self._try_scale_down(queue_depth, current_count, active_count, idle_count)
def _try_scale_up(self, queue_depth: int, current_count: int) -> bool:
"""
【扩容策略】
条件:
1. 队列深度 > 阈值(默认 5)
2. 当前 Worker 数 < 最大值(默认 10)
动作:
- 创建 1 个新 Worker
"""
if queue_depth > self._scale_up_threshold and current_count < self._max_workers:
self._create_worker()
logger.debug(
"Scaled up workers: %d -> %d (queue_depth=%d)",
current_count,
len(self._workers),
queue_depth,
)
return True
return False
def _try_scale_down(
self,
queue_depth: int,
current_count: int,
active_count: int,
idle_count: int
) -> bool:
"""
【缩容策略】
条件:
1. 当前 Worker 数 > 最小值(默认 2)
2. 有空闲 Worker
3. 满足以下任一:
- 队列深度 <= 活跃 Worker 数(能处理得过来)
- 空闲 Worker 数 > 活跃 Worker 数(太多闲置)
- 队列为空且有空闲 Worker
动作:
- 移除 1 个空闲时间超过阈值(默认 30 秒)的 Worker
"""
if current_count <= self._min_workers or idle_count == 0:
return False
# 检查是否有多余容量
has_excess_capacity = (
queue_depth <= active_count # 活跃 Worker 能处理当前队列
or idle_count > active_count # 空闲的比工作的还多
or (queue_depth == 0 and idle_count > 0) # 没活干了
)
if not has_excess_capacity:
return False
# 找到空闲超过阈值的 Worker
for worker in self._workers:
if worker.is_idle and worker.idle_duration >= self._scale_down_idle_time:
# 检查移除后是否还能处理队列
remaining = current_count - 1
if remaining >= self._min_workers and remaining >= max(1, queue_depth // 2):
self._remove_worker(worker, worker.worker_id)
logger.debug(
"Scaled down: removed idle worker (idle for %.1fs)",
worker.idle_duration,
)
return True
break
return False扩缩容示例:
plain
时刻 T0: 启动
- Workers: 2 (最小值)
- ReadyQueue: []
时刻 T1: 10 个节点入队
- Workers: 2
- ReadyQueue: [n1, n2, n3, n4, n5, n6, n7, n8, n9, n10]
- queue_depth (10) > threshold (5)
- 动作:扩容到 3 个 Worker
时刻 T2: 继续处理
- Workers: 3
- ReadyQueue: [n4, n5, n6, n7, n8, n9, n10]
- queue_depth (7) > threshold (5)
- 动作:扩容到 4 个 Worker
时刻 T3: 处理完成
- Workers: 4
- ReadyQueue: []
- 3 个 Worker 空闲超过 30 秒
- 动作:缩容到 3 个 Worker
时刻 T4: 继续空闲
- Workers: 3
- ReadyQueue: []
- 1 个 Worker 空闲超过 30 秒
- 动作:缩容到 2 个 Worker(最小值)队列机制详解
ReadyQueue(节点就绪队列)
python
class InMemoryReadyQueue(ReadyQueue):
"""
【核心功能】节点就绪队列
特点:
1. 基于 queue.Queue(线程安全)
2. 无界队列(maxsize=0)
3. FIFO 顺序
4. 支持序列化(用于暂停/恢复)
"""
def __init__(self, maxsize: int = 0) -> None:
# maxsize=0 表示无界队列
self._queue: queue.Queue[str] = queue.Queue(maxsize=maxsize)
def put(self, item: str) -> None:
"""
【入队】添加节点 ID
调用者:StateManager(在 EventHandler 中)
时机:
- 工作流开始时,root 节点入队
- 节点成功后,下游就绪节点入队
特点:非阻塞(无界队列)
"""
self._queue.put(item) # 永不阻塞
def get(self, timeout: float | None = None) -> str:
"""
【出队】获取节点 ID
调用者:Worker 线程
行为:
- timeout=None:永久阻塞直到有元素
- timeout=0.1:最多等待 0.1 秒,超时抛出 queue.Empty
Workers 使用 timeout=0.1,这样可以:
1. 定期检查 stop_event
2. 避免永久阻塞
"""
if timeout is None:
return self._queue.get(block=True) # 永久阻塞
return self._queue.get(timeout=timeout) # 超时阻塞
def task_done(self) -> None:
"""
【完成标记】通知队列任务完成
调用者:Worker 线程
用途:配合 join() 等待所有任务完成
"""
self._queue.task_done()
def qsize(self) -> int:
"""
【队列深度】获取当前队列大小
调用者:WorkerPool(用于扩缩容决策)
注意:这是近似值,不保证精确(因为多线程)
"""
return self._queue.qsize()ReadyQueue 流转示例:
plain
初始状态:
ReadyQueue: []
工作流开始 → root 节点入队:
ReadyQueue: ["start"]
Worker-1 获取并执行 start:
ReadyQueue: []
start 成功 → 下游节点 llm_1, llm_2 入队:
ReadyQueue: ["llm_1", "llm_2"]
Worker-1 获取 llm_1:
ReadyQueue: ["llm_2"]
Worker-2 获取 llm_2:
ReadyQueue: []
llm_1 和 llm_2 都成功 → code_1 就绪(所有入边完成)→ 入队:
ReadyQueue: ["code_1"]
Worker-1 获取 code_1:
ReadyQueue: []
code_1 成功 → 无下游节点:
ReadyQueue: [] # 执行完成EventQueue(事件队列)
python
# EventQueue 在 GraphEngine.__init__ 中创建
self._event_queue: queue.Queue[GraphNodeEventBase] = queue.Queue()
# 特点:
# 1. 无界队列(maxsize=0)
# 2. 线程安全
# 3. FIFO 顺序
# 4. 多生产者(Workers)→ 单消费者(Dispatcher)EventQueue 流转示例:
plain
初始状态:
EventQueue: []
Worker-1 执行 llm_1 节点,产生事件:
EventQueue: [
NodeRunStartedEvent(llm_1),
NodeRunStreamChunkEvent(llm_1, "Hello"),
NodeRunStreamChunkEvent(llm_1, " world"),
NodeRunSucceededEvent(llm_1)
]
Dispatcher 消费第一个事件:
EventQueue: [
NodeRunStreamChunkEvent(llm_1, "Hello"),
NodeRunStreamChunkEvent(llm_1, " world"),
NodeRunSucceededEvent(llm_1)
]
Worker-2 同时执行 llm_2,产生事件(并发):
EventQueue: [
NodeRunStreamChunkEvent(llm_1, "Hello"),
NodeRunStreamChunkEvent(llm_1, " world"),
NodeRunSucceededEvent(llm_1),
NodeRunStartedEvent(llm_2), # ← 插队进来
NodeRunStreamChunkEvent(llm_2, "Hi"),
]
注意:事件顺序可能交错,但每个节点的事件内部顺序不变消费者:Dispatcher 线程
Dispatcher 生命周期
python
class Dispatcher:
"""
【消费者】Dispatcher 线程
职责:
1. 从 EventQueue 获取事件
2. 分发给 EventHandler 处理
3. 检查执行状态(完成、终止、暂停)
4. 触发 WorkerPool 扩缩容
"""
def start(self) -> None:
"""启动 Dispatcher 线程"""
if self._thread and self._thread.is_alive():
return
self._start_time = time.time()
self._thread = threading.Thread(
target=self._dispatcher_loop,
name="GraphDispatcher",
daemon=True # 守护线程
)
self._thread.start()
def _dispatcher_loop(self) -> None:
"""
【核心方法】Dispatcher 主循环
流程:
1. 处理命令(暂停、终止)
2. 主循环:
a. 检查是否应该停止
b. 触发扩缩容检查
c. 从 EventQueue 获取事件
d. 分发事件到 EventHandler
e. 处理命令
3. 清空剩余事件
4. 标记执行完成
"""
try:
# ========== 初始命令处理 ==========
self._process_commands()
# ========== 主循环 ==========
while not self._stop_event.is_set():
# --- 检查是否应该停止 ---
if (
self._execution_coordinator.aborted
or self._execution_coordinator.paused
or self._execution_coordinator.execution_complete
):
break
# --- 触发 Worker 池扩缩容检查 ---
self._execution_coordinator.check_scaling()
try:
# --- 从 EventQueue 获取事件(带超时)---
event = self._event_queue.get(timeout=0.1)
# --- 分发事件 ---
self._event_handler.dispatch(event)
# --- 标记事件处理完成 ---
self._event_queue.task_done()
# --- 处理命令(如暂停、终止)---
self._process_commands(event)
except queue.Empty:
# 队列空,短暂休眠
time.sleep(0.1)
# ========== 清空剩余事件 ==========
# 执行停止后,仍需处理队列中剩余的事件
self._process_commands()
while True:
try:
event = self._event_queue.get(block=False) # 非阻塞
self._event_handler.dispatch(event)
self._event_queue.task_done()
except queue.Empty:
break
except Exception as e:
logger.exception("Dispatcher error")
self._execution_coordinator.mark_failed(e)
finally:
# ========== 标记执行完成 ==========
self._execution_coordinator.mark_complete()
if self._event_emitter:
self._event_emitter.mark_complete()事件分发机制
python
# EventHandler 使用单分发模式(singledispatch)
class EventHandler:
"""
【核心功能】事件处理器
特点:
1. 使用 @singledispatchmethod 根据事件类型路由
2. 在 Dispatcher 线程中同步执行(非多线程)
3. 处理业务逻辑:更新状态、处理边、入队节点
"""
def dispatch(self, event: GraphNodeEventBase) -> None:
"""
【入口】分发事件
流程:
1. 检查是否在循环/迭代中(特殊处理)
2. 调用 _dispatch 根据类型路由
"""
# 循环/迭代中的事件直接收集,不处理
if event.in_loop_id or event.in_iteration_id:
self._event_collector.collect(event)
return
return self._dispatch(event)
@singledispatchmethod
def _dispatch(self, event: GraphNodeEventBase) -> None:
"""默认处理器"""
self._event_collector.collect(event)
logger.warning("Unhandled event type: %s", type(event).__name__)
@_dispatch.register
def _(self, event: NodeRunSucceededEvent) -> None:
"""
【处理】节点成功事件
步骤:
1. 更新执行状态
2. 存储输出到变量池
3. 处理出边,找到就绪的下游节点
4. 将就绪节点入队 ReadyQueue
5. 收集事件到 EventManager
"""
# 更新领域模型
node_execution = self._graph_execution.get_or_create_node_execution(event.node_id)
node_execution.mark_taken()
# 存储输出
self._store_node_outputs(event.node_id, event.node_run_result.outputs)
# 处理边
node = self._graph.nodes[event.node_id]
if node.execution_type == NodeExecutionType.BRANCH:
ready_nodes, _ = self._edge_processor.handle_branch_completion(
event.node_id, event.node_run_result.edge_source_handle
)
else:
ready_nodes, _ = self._edge_processor.process_node_success(event.node_id)
# 将就绪节点入队(这里触发 ReadyQueue.put)
for node_id in ready_nodes:
self._state_manager.enqueue_node(node_id) # ← put 到 ReadyQueue
self._state_manager.start_execution(node_id)
# 标记完成
self._state_manager.finish_execution(event.node_id)
# 收集事件
self._event_collector.collect(event)背压(Backpressure)机制
无背压设计
python
# Dify 使用无界队列,没有显式的背压机制
ready_queue = queue.Queue(maxsize=0) # 无界
event_queue = queue.Queue(maxsize=0) # 无界
# 优点:
# ✅ 简单:不需要处理队列满的情况
# ✅ 高吞吐:生产者永不阻塞
# ✅ 解耦:生产者和消费者完全异步
# 缺点:
# ❌ 内存风险:如果消费速度 < 生产速度,队列会无限增长
# ❌ 无流控:无法限制生产速度隐式背压:扩缩容
python
# 虽然没有显式背压,但通过动态扩缩容实现了隐式流控
class WorkerPool:
def check_and_scale(self):
queue_depth = self._ready_queue.qsize()
# 当队列深度 > 阈值时,增加 Worker
if queue_depth > self._scale_up_threshold:
self._create_worker()
# 结果:更多 Worker → 更快消费 → 队列深度下降
# 当队列为空且有空闲 Worker 时,减少 Worker
if queue_depth == 0 and idle_count > 0:
self._remove_idle_worker()
# 结果:减少资源浪费内存保护机制
python
# 虽然队列无界,但有其他保护机制
# 1. 执行步骤限制
max_steps = dify_config.WORKFLOW_MAX_EXECUTION_STEPS # 默认 500
# 如果执行超过 500 步,终止执行
# 2. 执行时间限制
max_time = dify_config.WORKFLOW_MAX_EXECUTION_TIME # 默认 1200 秒
# 如果执行超过 1200 秒,终止执行
# 3. 变量大小限制
max_variable_size = dify_config.WORKFLOW_VARIABLE_TRUNCATION_MAX_SIZE # 1MB
# 超过 1MB 的变量会被卸载到对象存储
# 4. Worker 数量限制
max_workers = dify_config.GRAPH_ENGINE_MAX_WORKERS # 默认 10
# 最多 10 个并发 Worker完整数据流示例
场景:执行包含 2 个并行 LLM 节点的工作流
plain
工作流 DAG:
START
/ \
LLM-1 LLM-2
\ /
CODE!!时序图(包含StateManager)
EventHandler Dispatcher EventQueue Worker-2 Worker-1 ReadyQueue StateManager EventHandler Dispatcher EventQueue Worker-2 Worker-1 ReadyQueue StateManager 工作流开始 "start" \[\] Started, Succeeded "llm-1", "llm-2" par Worker-1 和 Worker-2 并行执行 事件交错: Started(llm-1), Started(llm-2), Chunk(llm-1), Chunk(llm-2), ... loop Dispatcher 逐个处理事件 llm-1 和 llm-2 都成功后 put("start") get(timeout=0.1) "start" 执行 START 节点 put(NodeRunStartedEvent) put(NodeRunSucceededEvent) get(timeout=0.1) NodeRunStartedEvent dispatch(Started) 处理开始事件 get(timeout=0.1) NodeRunSucceededEvent dispatch(Succeeded) 处理边,发现 llm-1, llm-2 就绪 enqueue_node("llm-1") enqueue_node("llm-2") put("llm-1") put("llm-2") get(timeout=0.1) "llm-1" 执行 LLM-1 put(NodeRunStartedEvent) put(StreamChunk("Hello")) put(StreamChunk(" from LLM-1")) put(NodeRunSucceededEvent) get(timeout=0.1) "llm-2" 执行 LLM-2 put(NodeRunStartedEvent) put(StreamChunk("Hi")) put(StreamChunk(" from LLM-2")) put(NodeRunSucceededEvent) get(timeout=0.1) Event dispatch(Event) 检查 CODE 节点: 所有入边都完成了! enqueue_node("code") put("code") get(timeout=0.1) "code" 执行 CODE 节点 put(NodeRunStartedEvent) put(NodeRunSucceededEvent) get(timeout=0.1) NodeRunSucceededEvent dispatch(Succeeded) 无下游节点,执行完成
核心优势与权衡
优势
plain
✅ 高吞吐:
- 无界队列,生产者永不阻塞
- 多 Worker 并行执行
- 动态扩缩容
✅ 解耦:
- 生产者和消费者完全异步
- 通过队列通信,无需直接交互
✅ 容错:
- Worker 崩溃不影响其他 Worker
- 事件处理失败不影响事件生成
✅ 可观测:
- 所有状态变化都通过事件表达
- 完整的事件流可追溯
✅ 扩展性:
- 通过 Layer 机制添加新功能
- 不修改核心流程权衡的艺术
plain
❌ 内存风险:
- 无界队列可能无限增长
- 缓解:执行步骤/时间限制
❌ 事件顺序:
- 并行 Worker 产生的事件可能交错
- 缓解:ResponseCoordinator 重排序流式输出
❌ 无法精确控制并发:
- 只能通过 min/max_workers 粗调
- 缓解:动态扩缩容自动调整
❌ 调试复杂:
- 多线程异步执行,难以调试
- 缓解:DebugLoggingLayer 记录详细日志对比其他模式
| 模式 | Dify 实现 | 其他选择 | 优劣 |
|---|---|---|---|
| 队列类型 | 无界队列 | 有界队列 | ✅ 简单 ❌ 内存风险 |
| 背压 | 无显式背压 | 有背压(阻塞生产者) | ✅ 高吞吐 ❌ 无流控 |
| 线程模型 | 线程池 | 协程/Actor | ✅ 简单 ❌ 线程开销 |
| 事件处理 | 单线程消费 | 多线程消费 | ✅ 避免竞态 ❌ 单点瓶颈 |
| 扩缩容 | 动态 | 固定 | ✅ 资源高效 ❌ 复杂度 |
变量隔离机制:命名空间 + 不可变性
整体架构图
plain
┌────────────────────────────────────────────────────────────────┐
│ 变量隔离机制 │
│ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ 第一层:命名空间隔离(Node ID) │ │
│ │ │ │
│ │ VariablePool = { │ │
│ │ "start": { │ │
│ │ "query": Variable(value="用户输入") │ │
│ │ }, │ │
│ │ "llm_1": { │ │
│ │ "output": Variable(value="LLM输出") │ │
│ │ }, │ │
│ │ "code_1": { │ │
│ │ "result": Variable(value={...}) │ │
│ │ } │ │
│ │ } │ │
│ │ │ │
│ │ ✅ 每个节点有独立命名空间 │ │
│ │ ✅ 不同节点可以有同名变量(如都有"output") │ │
│ └──────────────────────────────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ 第二层:Segment 不可变性(Pydantic frozen) │ │
│ │ │ │
│ │ class Segment(BaseModel): │ │
│ │ model_config = ConfigDict(frozen=True) # 冻结! │ │
│ │ value_type: SegmentType │ │
│ │ value: Any │ │
│ │ │ │
│ │ ✅ Segment 对象一旦创建,不可修改 │ │
│ │ ✅ 修改需要创建新实例 │ │
│ └──────────────────────────────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ 第三层:深拷贝隔离(防御式编程) │ │
│ │ │ │
│ │ 读取:deepcopy(value) │ │
│ │ 写入:deepcopy(value) │ │
│ │ │ │
│ │ ✅ 读取时返回副本,外部修改不影响原值 │ │
│ │ ✅ 写入时存储副本,外部修改不影响存储值 │ │
│ └──────────────────────────────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ 第四层:只读包装器(权限控制) │ │
│ │ │ │
│ │ ReadOnlyVariablePoolWrapper │ │
│ │ ReadOnlyGraphRuntimeStateWrapper │ │
│ │ │ │
│ │ ✅ Layer 只能读,不能写 │ │
│ │ ✅ 防止插件或扩展破坏状态 │ │
│ └──────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘隔离机制对比表
| 隔离层级 | 机制 | 作用 | 优点 | 缺点 |
|---|---|---|---|---|
| 第一层:命名空间 | Node ID 双层字典 | 节点间变量隔离 | ✅ 清晰的命名空间 ✅ 支持同名变量 ✅ 易于理解 | ❌ 需要显式指定 Node ID |
| 第二层:不可变性 | Pydantic frozen | Segment 对象不可变 | ✅ 线程安全 ✅ 可预测 ✅ 可缓存 | ❌ 修改需创建新实例 ❌ 轻微性能开销 |
| 第三层:深拷贝 | copy.deepcopy() | 读写时完全隔离 | ✅ 彻底隔离 ✅ 防止意外修改 ✅ 简化并发 | ❌ 性能开销大 ❌ 内存消耗多 |
| 第四层:只读包装器 | Wrapper 模式 | 权限控制 | ✅ 防止插件破坏 ✅ 类型安全 ✅ 编译时检查 | ❌ 增加抽象层 ❌ 轻微复杂度 |
简单的问答工作流场景:
plain
节点A写入变量
↓
data = {"count": 100} ────┐
│ deepcopy
↓
VariablePool["node_a"]["output"] = {"count": 100} ← 存储副本
│
┌──────────────┼──────────────┐
│ │ │
节点B读取 │ 节点C读取 │ 节点D读取 │
↓ │ ↓ │ ↓ │
deepcopy │ deepcopy │ deepcopy │
↓ │ ↓ │ ↓ │
{"count":100} {"count":100} {"count":100} ← 三个独立副本
│ │ │
修改为200 修改为300 修改为400
↓ ↓ ↓
不影响池 不影响池 不影响池
🎯 关键:无论怎么修改副本,原始池中的数据永远是{"count": 100}关键函数调用链路图
GraphRuntimeState Node节点 VariablePool GraphEngine WorkflowEntry 👤 用户 GraphRuntimeState Node节点 VariablePool GraphEngine WorkflowEntry 👤 用户 初始化阶段 执行阶段 变量池状态: {sys: {...}, start: {query: ...}} 处理:调用LLM 变量池状态: {..., llm_1: {text: ...}} 处理:格式化文本 变量池最终状态: {..., format_1: {formatted: ...}} 1. 发起请求 + 用户输入 2. 创建VariablePool add("sys", ..., 系统变量) 3. 创建GraphRuntimeState 包装variable_pool 4. 创建GraphEngine 传入graph_runtime_state 5. 执行Start节点 6. add("start", "query", 用户输入) 7. 执行LLM节点 8. 通过graph_runtime_state 访问variable_pool 9. get("start", "query") 10. 返回deepcopy副本 11. 返回变量值 12. add("llm_1", "text", LLM响应) 13. 执行格式化节点 14. get("llm_1", "text") 15. 返回deepcopy副本 16. add("format_1", "formatted", 结果) 17. 执行完成 18. 返回结果
第一层:命名空间隔离
双层字典结构
python
class VariablePool(BaseModel):
"""
【核心数据结构】双层字典
第一层 key:Node ID(命名空间)
第二层 key:变量名
value:Variable 对象
"""
variable_dictionary: defaultdict[
str, # 第一层:Node ID
dict[str, VariableUnion] # 第二层:{变量名: Variable}
] = Field(
description="Variables mapping",
default=defaultdict(dict),
)可视化示例:
python
# 实际存储结构
variable_dictionary = {
# ========== START 节点的命名空间 ==========
"start": {
"query": StringVariable(
name="query",
value="解释量子计算",
selector=["start", "query"]
),
"files": ArrayFileVariable(
name="files",
value=[],
selector=["start", "files"]
)
},
# ========== LLM-1 节点的命名空间 ==========
"llm_1": {
"output": StringVariable(
name="output",
value="量子计算是利用量子力学原理...",
selector=["llm_1", "output"]
),
"usage": ObjectVariable(
name="usage",
value={"tokens": 150, "cost": 0.003},
selector=["llm_1", "usage"]
)
},
# ========== LLM-2 节点的命名空间(也有 output!) ==========
"llm_2": {
"output": StringVariable( # 同名变量,但在不同命名空间
name="output",
value="另一个 LLM 的输出",
selector=["llm_2", "output"]
),
"usage": ObjectVariable(
name="usage",
value={"tokens": 200, "cost": 0.004},
selector=["llm_2", "usage"]
)
},
# ========== CODE 节点的命名空间 ==========
"code_1": {
"result": ObjectVariable(
name="result",
value={"combined": "...", "score": 95},
selector=["code_1", "result"]
)
},
# ========== 系统变量的命名空间(特殊) ==========
"sys": {
"user_id": StringVariable(
name="user_id",
value="user_123",
selector=["sys", "user_id"]
),
"app_id": StringVariable(
name="app_id",
value="app_456",
selector=["sys", "app_id"]
)
},
# ========== 环境变量的命名空间(特殊) ==========
"env": {
"OPENAI_API_KEY": StringVariable(
name="OPENAI_API_KEY",
value="sk-...",
selector=["env", "OPENAI_API_KEY"]
)
}
}变量选择器(Selector)
python
"""
变量选择器是一个路径,用于精确定位变量
格式:[node_id, variable_name, attr1, attr2, ...]
示例:
- ["start", "query"] → 访问 START 节点的 query 变量
- ["llm_1", "output"] → 访问 LLM-1 节点的 output 变量
- ["llm_2", "output"] → 访问 LLM-2 节点的 output 变量(不冲突!)
- ["code_1", "result", "score"] → 访问嵌套属性
- ["sys", "user_id"] → 访问系统变量
"""
# 访问示例
def access_variable_example():
pool = VariablePool(...)
# ========== 访问不同节点的同名变量 ==========
llm1_output = pool.get(["llm_1", "output"])
# 返回:StringVariable(value="量子计算是...")
llm2_output = pool.get(["llm_2", "output"])
# 返回:StringVariable(value="另一个 LLM 的输出")
# 这两个变量完全独立,互不影响!
# ========== 访问嵌套属性 ==========
score = pool.get(["code_1", "result", "score"])
# 访问路径:
# 1. variable_dictionary["code_1"]["result"] → ObjectVariable
# 2. .value["score"] → 95
# 返回:IntegerSegment(value=95)命名空间冲突解决
python
# ✅ 允许:不同节点有同名变量
pool.add(["llm_1", "output"], "Output from LLM 1")
pool.add(["llm_2", "output"], "Output from LLM 2")
# 完全独立,互不干扰
# ✅ 允许:同一节点多次更新变量
pool.add(["llm_1", "output"], "Initial output")
pool.add(["llm_1", "output"], "Updated output") # 覆盖
# variable_dictionary["llm_1"]["output"] 被更新
# ❌ 不允许:跨节点覆盖
# 不存在这种情况,因为 Node ID 强制隔离
# ❌ 不允许:直接访问其他节点私有数据(通过设计限制)
# 节点只能通过变量选择器显式访问其他节点的输出第二层:Segment 不可变性
Pydantic frozen 配置
python
class Segment(BaseModel):
"""
【核心特性】不可变 Segment
使用 Pydantic 的 frozen=True 配置,使对象不可变
"""
# ========== 关键配置:冻结模型 ==========
model_config = ConfigDict(frozen=True)
value_type: SegmentType # 值类型(STRING, INTEGER, OBJECT 等)
value: Any # 实际值
@field_validator("value_type")
@classmethod
def validate_value_type(cls, value):
"""
【验证器】确保 value_type 不可修改
即使尝试修改,也会抛出错误
"""
if value != cls.model_fields["value_type"].default:
raise ValueError("Cannot modify 'value_type'")
return value不可变性示例
python
from core.variables.segments import StringSegment, IntegerSegment
# ========== 创建 Segment ==========
segment = StringSegment(value="Hello World")
# ========== 尝试修改(会失败)==========
try:
segment.value = "Modified" # ❌ 错误!
except Exception as e:
print(e)
# 输出:ValidationError: Instance is frozen
try:
segment.value_type = SegmentType.INTEGER # ❌ 错误!
except Exception as e:
print(e)
# 输出:ValidationError: Instance is frozen
# ========== 正确做法:创建新实例 ==========
new_segment = StringSegment(value="Modified") # ✅ 正确
# ========== Segment 子类都是不可变的 ==========
string_seg = StringSegment(value="text") # 不可变
integer_seg = IntegerSegment(value=42) # 不可变
object_seg = ObjectSegment(value={"a": 1}) # 不可变
array_seg = ArrayStringSegment(value=["a"]) # 不可变
file_seg = FileSegment(value=File(...)) # 不可变不可变性的好处
python
"""
✅ 好处 1:线程安全
- 多个线程可以安全地读取同一个 Segment
- 不需要锁机制
✅ 好处 2:可预测性
- Segment 的值不会意外改变
- 易于调试和追踪
✅ 好处 3:可缓存
- 可以安全地缓存 Segment 对象
- 不用担心被修改
✅ 好处 4:防御式编程
- 防止外部代码破坏内部状态
- 提高系统健壮性
"""
# 示例:多线程安全访问
from threading import Thread
segment = StringSegment(value="Shared Value")
def worker1():
# 读取 segment(安全)
value = segment.value
# 不能修改 segment(受保护)
# segment.value = "Modified" # ❌ 会失败
def worker2():
# 读取 segment(安全)
value = segment.value
# 同样不能修改
# 两个线程可以安全地并发访问
t1 = Thread(target=worker1)
t2 = Thread(target=worker2)
t1.start()
t2.start()第三层:深拷贝隔离
深拷贝策略
python
from copy import deepcopy
class GraphRuntimeState:
"""
【核心策略】所有读写操作都使用深拷贝
目的:
1. 读取时返回副本,外部修改不影响原值
2. 写入时存储副本,外部修改不影响存储值
"""
def __init__(self, outputs: dict[str, object] | None = None):
# ========== 写入时深拷贝 ==========
self._outputs = deepcopy(outputs) if outputs is not None else {}
@property
def outputs(self) -> dict[str, Any]:
"""
【读取】返回深拷贝
外部修改返回的字典不会影响内部状态
"""
return deepcopy(self._outputs)
@outputs.setter
def outputs(self, value: dict[str, Any]) -> None:
"""
【写入】存储深拷贝
外部持有的引用修改不会影响存储值
"""
self._outputs = deepcopy(value)
def set_output(self, key: str, value: object) -> None:
"""
【设置单个输出】存储深拷贝
"""
self._outputs[key] = deepcopy(value)
def get_output(self, key: str, default: object = None) -> object:
"""
【获取单个输出】返回深拷贝
"""
return deepcopy(self._outputs.get(key, default))
def update_outputs(self, updates: dict[str, object]) -> None:
"""
【批量更新】每个值都深拷贝
"""
for key, value in updates.items():
self._outputs[key] = deepcopy(value)深拷贝示例
python
# ========== 示例 1:读取保护 ==========
state = GraphRuntimeState()
state.set_output("result", {"score": 95, "status": "success"})
# 读取输出
output = state.get_output("result")
print(output) # {"score": 95, "status": "success"}
# 外部修改
output["score"] = 0
output["hacked"] = True
# 内部状态未被影响!
internal = state.get_output("result")
print(internal) # {"score": 95, "status": "success"} ✅ 未受影响
# ========== 示例 2:写入保护 ==========
data = {"items": [1, 2, 3], "total": 3}
# 写入状态
state.set_output("data", data)
# 外部修改
data["items"].append(4)
data["total"] = 4
# 内部状态未被影响!
stored = state.get_output("data")
print(stored) # {"items": [1, 2, 3], "total": 3} ✅ 未受影响
# ========== 示例 3:嵌套对象保护 ==========
nested = {
"level1": {
"level2": {
"level3": {"value": "deep"}
}
}
}
state.set_output("nested", nested)
# 深层修改
nested["level1"]["level2"]["level3"]["value"] = "hacked"
# 内部状态仍然安全
stored_nested = state.get_output("nested")
print(stored_nested["level1"]["level2"]["level3"]["value"])
# 输出:"deep" ✅ 未受影响VariablePool 中的深拷贝
python
class VariablePool(BaseModel):
"""变量池也使用深拷贝策略"""
def get_by_prefix(self, prefix: str, /) -> Mapping[str, object]:
"""
【按前缀获取】返回节点所有变量的深拷贝
用途:获取某个节点的所有变量
"""
nodes = self.variable_dictionary.get(prefix)
if not nodes:
return {}
result: dict[str, object] = {}
for key, variable in nodes.items():
value = variable.value
# ========== 深拷贝每个值 ==========
result[key] = deepcopy(value)
return result
# 使用示例
pool = VariablePool(...)
pool.add(["llm_1", "output"], "LLM output text")
pool.add(["llm_1", "usage"], {"tokens": 100})
# 获取 llm_1 的所有变量
llm1_vars = pool.get_by_prefix("llm_1")
# 返回:{"output": "LLM output text", "usage": {"tokens": 100}}
# 外部修改
llm1_vars["usage"]["tokens"] = 999
# 内部未受影响
original = pool.get_by_prefix("llm_1")
print(original["usage"]["tokens"]) # 100 ✅ 未受影响深拷贝的性能考虑
python
"""
❌ 缺点:性能开销
- deepcopy 对于大对象很慢
- 每次读写都拷贝,增加内存和 CPU 开销
✅ 优点:安全性
- 完全隔离,杜绝意外修改
- 简化并发控制
🎯 Dify 的权衡:
- 优先考虑安全性和正确性
- 工作流节点的数据量通常不大(KB-MB 级别)
- 大数据有卸载机制(见前文"状态持久化"章节)
- 性能瓶颈在节点执行(LLM、工具调用),不在变量拷贝
"""
# 性能优化示例:只在必要时深拷贝
class OptimizedAccess:
"""某些场景可以优化"""
def get_immutable_value(self, key: str) -> str:
"""
如果返回不可变类型(str, int, float, tuple),
可以不深拷贝
"""
value = self._data[key]
if isinstance(value, (str, int, float, bool, type(None), tuple)):
return value # 不可变类型,无需拷贝
else:
return deepcopy(value) # 可变类型,必须拷贝第四层:只读包装器
ReadOnlyVariablePoolWrapper
python
class ReadOnlyVariablePoolWrapper:
"""
【核心功能】变量池的只读包装器
用途:
- 提供给 Layer 使用
- 防止 Layer 修改变量池
- 所有读取都返回深拷贝
"""
def __init__(self, variable_pool: VariablePool) -> None:
self._variable_pool = variable_pool
def get(self, selector: Sequence[str], /) -> Segment | None:
"""
【读取变量】返回深拷贝
注意:
1. 调用内部 variable_pool.get()
2. 对结果进行 deepcopy
3. 双重保护(Segment 不可变 + 深拷贝)
"""
value = self._variable_pool.get(selector)
return deepcopy(value) if value is not None else None
# ✅ 返回的是副本,外部修改不影响原值
def get_all_by_node(self, node_id: str) -> Mapping[str, object]:
"""
【获取节点所有变量】返回深拷贝
返回:{variable_name: value} 字典
"""
variables: dict[str, object] = {}
if node_id in self._variable_pool.variable_dictionary:
for key, variable in self._variable_pool.variable_dictionary[node_id].items():
# ========== 深拷贝每个变量的值 ==========
variables[key] = deepcopy(variable.value)
return variables
def get_by_prefix(self, prefix: str) -> Mapping[str, object]:
"""
【按前缀获取】委托给内部实现
内部已经做了深拷贝,这里直接返回
"""
return self._variable_pool.get_by_prefix(prefix)
# ========== 没有 add, remove, update 方法!==========
# Layer 无法修改变量池ReadOnlyGraphRuntimeStateWrapper
python
class ReadOnlyGraphRuntimeStateWrapper:
"""
【核心功能】运行时状态的只读包装器
用途:
- 提供给 Layer 使用
- Layer 只能读取状态,不能修改
- 防止插件破坏执行状态
"""
def __init__(self, state: GraphRuntimeState) -> None:
self._state = state
# ========== 包装变量池 ==========
self._variable_pool_wrapper = ReadOnlyVariablePoolWrapper(
state.variable_pool
)
@property
def variable_pool(self) -> ReadOnlyVariablePoolWrapper:
"""
【只读变量池】返回包装器
Layer 通过这个访问变量池,只能读不能写
"""
return self._variable_pool_wrapper
@property
def outputs(self) -> dict[str, Any]:
"""
【只读输出】返回深拷贝
Layer 获取的是副本,修改不影响原值
"""
return deepcopy(self._state.outputs)
@property
def llm_usage(self) -> LLMUsage:
"""
【只读 LLM 使用量】返回副本
使用 Pydantic 的 model_copy()
"""
return self._state.llm_usage.model_copy()
# ========== 只提供读取方法 ==========
@property
def start_at(self) -> float:
return self._state.start_at
@property
def total_tokens(self) -> int:
return self._state.total_tokens
@property
def node_run_steps(self) -> int:
return self._state.node_run_steps
def get_output(self, key: str, default: Any = None) -> Any:
"""获取单个输出(深拷贝)"""
return self._state.get_output(key, default)
# ========== 没有任何写入方法!==========
# 没有 set_output, update_outputs, 等方法
# Layer 无法修改状态使用示例
python
# ========== Layer 中使用只读包装器 ==========
class MyCustomLayer(GraphEngineLayer):
"""自定义 Layer"""
def on_node_run_start(self, node: Node) -> None:
"""节点开始时的钩子"""
# ========== 访问只读状态 ==========
readonly_state = self.graph_runtime_state
# 类型:ReadOnlyGraphRuntimeStateWrapper
# ✅ 可以读取
total_tokens = readonly_state.total_tokens
outputs = readonly_state.outputs
# ✅ 可以访问变量池(只读)
readonly_pool = readonly_state.variable_pool
user_id = readonly_pool.get(["sys", "user_id"])
# ❌ 不能修改(没有这些方法)
# readonly_state.set_output("key", "value") # 编译错误!
# readonly_pool.add(["node", "var"], "value") # 编译错误!
# ========== 即使尝试修改返回的副本 ==========
outputs = readonly_state.outputs # 这是副本
outputs["hacked"] = True # 只修改了副本
# 内部状态未受影响
original = readonly_state.outputs
print("hacked" in original) # False ✅ 安全
# ========== 对比:EventHandler 中使用可写状态 ==========
class EventHandler:
"""事件处理器(内部组件)"""
def __init__(self, graph_runtime_state: GraphRuntimeState):
# ========== 直接访问可写状态 ==========
self._graph_runtime_state = graph_runtime_state
# 类型:GraphRuntimeState(可读可写)
def handle_node_success(self, event):
# ✅ 可以读取
outputs = self._graph_runtime_state.outputs
# ✅ 可以修改(内部组件有权限)
self._graph_runtime_state.set_output("answer", "Hello")
self._graph_runtime_state.variable_pool.add(
["llm_1", "output"], "LLM output"
)
self._graph_runtime_state.increment_node_run_steps()完整隔离流程示例
场景:两个并行 LLM 节点修改同名变量
python
"""
工作流:
START
/ \
LLM-1 LLM-2 (都输出 "output" 变量)
\ /
CODE (读取两个 LLM 的输出)
"""
# ========== 初始化变量池 ==========
pool = VariablePool(...)
# ========== START 节点执行,写入变量 ==========
pool.add(["start", "query"], "解释量子计算")
# ========== LLM-1 执行(Worker-1 线程) ==========
def worker1_execute_llm1():
# 1. 读取输入(深拷贝)
query = pool.get(["start", "query"])
print(f"LLM-1 读取: {query.value}") # "解释量子计算"
# 2. 执行 LLM(模拟)
llm1_output = "量子计算是利用量子力学原理进行计算的技术..."
# 3. 写入输出(深拷贝,命名空间隔离)
pool.add(["llm_1", "output"], llm1_output)
# ✅ 存储在 variable_dictionary["llm_1"]["output"]
# ========== LLM-2 执行(Worker-2 线程,并发) ==========
def worker2_execute_llm2():
# 1. 读取输入(深拷贝)
query = pool.get(["start", "query"])
print(f"LLM-2 读取: {query.value}") # "解释量子计算"
# 2. 执行 LLM(模拟)
llm2_output = "量子计算利用量子比特进行并行计算..."
# 3. 写入输出(深拷贝,命名空间隔离)
pool.add(["llm_2", "output"], llm2_output)
# ✅ 存储在 variable_dictionary["llm_2"]["output"]
# ✅ 与 llm_1 的 output 完全独立!
# ========== 并行执行 ==========
import threading
t1 = threading.Thread(target=worker1_execute_llm1)
t2 = threading.Thread(target=worker2_execute_llm2)
t1.start()
t2.start()
t1.join()
t2.join()
# ========== CODE 节点执行,读取两个 LLM 的输出 ==========
def execute_code_node():
# 读取两个 LLM 的输出(命名空间隔离)
llm1_output = pool.get(["llm_1", "output"])
llm2_output = pool.get(["llm_2", "output"])
print(f"LLM-1 输出: {llm1_output.value[:30]}...")
# 输出:"量子计算是利用量子力学原理进行计算的技术..."
print(f"LLM-2 输出: {llm2_output.value[:30]}...")
# 输出:"量子计算利用量子比特进行并行计算..."
# ✅ 两个输出完全独立,没有冲突!
# 合并结果
combined = f"{llm1_output.value}\n\n{llm2_output.value}"
pool.add(["code_1", "result"], {"combined": combined})
execute_code_node()
# ========== 验证隔离性 ==========
print("\n最终变量池状态:")
print(f"llm_1.output: {pool.get(['llm_1', 'output']).value[:30]}...")
print(f"llm_2.output: {pool.get(['llm_2', 'output']).value[:30]}...")
print(f"两个变量完全独立!")输出:
plain
LLM-1 读取: 解释量子计算
LLM-2 读取: 解释量子计算
LLM-1 输出: 量子计算是利用量子力学原理进行计算的技术...
LLM-2 输出: 量子计算利用量子比特进行并行计算...
最终变量池状态:
llm_1.output: 量子计算是利用量子力学原理进行计算的技术...
llm_2.output: 量子计算利用量子比特进行并行计算...
两个变量完全独立!核心优势总结
多线程安全
python
✅ Worker 线程可以并发读写变量池
✅ Segment 不可变保证线程安全
✅ 深拷贝避免共享可变状态
✅ 命名空间隔离避免竞争条件防御式编程
python
✅ Layer 无法破坏内部状态(只读包装器)
✅ 外部修改不影响内部值(深拷贝)
✅ 节点间完全隔离(命名空间)
✅ 对象创建后不可变(Pydantic frozen)可调试性
python
✅ 变量池状态可序列化(dumps/loads)
✅ 每个节点的变量独立可查
✅ 历史值不会被意外覆盖
✅ 状态变化可追踪可扩展性
python
✅ Layer 可以安全读取状态
✅ 插件不能破坏核心状态
✅ 支持暂停/恢复(状态完整序列化)
✅ 支持分布式执行(状态可传输)工程实战与故障应对
竞态冲突:读写锁 + 单线程写入
核心问题
在多线程并发执行环境中,多个 Worker 线程同时访问共享状态(Graph 节点状态、边状态、执行追踪)和事件队列,会产生竞态条件:
- 读读冲突:多线程同时读取状态(无危险,但需要保证数据一致性)
- 读写冲突:一个线程读取状态,同时另一个线程修改状态
- 写写冲突:多个线程同时修改状态
架构设计:读写锁 + 状态隔离
** 自定义读写锁(ReadWriteLock)**
设计特点:
- 读锁可重入:多个线程可以同时持有读锁
- 写锁独占:写锁必须等待所有读锁释放
- 公平性 :写锁等待时使用
wait(),避免饥饿
python
class ReadWriteLock:
"""
读写锁:允许多个读者同时读,但写入时必须独占
"""
def __init__(self) -> None:
self._read_ready = threading.Condition(threading.RLock()) # 条件变量
self._readers = 0 # 当前读者数量
def acquire_read(self) -> None:
"""
获取读锁
- 多个线程可以同时持有读锁
"""
_ = self._read_ready.acquire()
try:
self._readers += 1 # 读者数量+1
finally:
self._read_ready.release()
def release_read(self) -> None:
"""
释放读锁
- 当最后一个读者离开时,通知等待的写者
"""
_ = self._read_ready.acquire()
try:
self._readers -= 1
if self._readers == 0: # 最后一个读者
self._read_ready.notify_all() # 通知写者可以进入
finally:
self._read_ready.release()
def acquire_write(self) -> None:
"""
获取写锁
- 必须等待所有读者离开
- 写者独占访问
"""
_ = self._read_ready.acquire()
while self._readers > 0: # 等待所有读者离开
_ = self._read_ready.wait()
def release_write(self) -> None:
"""
释放写锁
"""
self._read_ready.release()
@contextmanager
def read_lock(self):
"""上下文管理器:自动获取和释放读锁"""
self.acquire_read()
try:
yield
finally:
self.release_read()
@contextmanager
def write_lock(self):
"""上下文管理器:自动获取和释放写锁"""
self.acquire_write()
try:
yield
finally:
self.release_write()** EventManager 的事件收集与分发**
关键设计:
- 写入用 write_lock:确保事件列表的原子性追加
- 通知层在锁外:最小化锁持有时间,避免阻塞其他线程
- 读取用 read_lock:多个线程可以同时读取事件
python
class EventManager:
"""
事件管理器:收集和分发工作流执行事件
- 使用读写锁保证线程安全
"""
def __init__(self) -> None:
self._events: list[GraphEngineEvent] = [] # 事件列表
self._lock = ReadWriteLock() # ⚡ 读写锁
self._layers: list[GraphEngineLayer] = []
self._execution_complete = threading.Event()
def collect(self, event: GraphEngineEvent) -> None:
"""
收集事件(写操作)
- 使用写锁,确保单线程写入
"""
# ========== 🔒 关键:使用写锁保护事件列表 ==========
with self._lock.write_lock():
self._events.append(event) # 单线程写入
# ========== 💡 重要:锁外通知层,避免死锁 ==========
# 通知层不需要锁保护,避免阻塞其他读/写线程
self._notify_layers(event)
def _get_new_events(self, start_index: int) -> list[GraphEngineEvent]:
"""
获取新事件(读操作)
- 使用读锁,允许多线程同时读取
"""
# ========== 🔓 关键:使用读锁允许并发读取 ==========
with self._lock.read_lock():
return list(self._events[start_index:]) # 多线程读取
def _event_count(self) -> int:
"""
获取事件数量(读操作)
"""
with self._lock.read_lock():
return len(self._events)GraphStateManager 的可重入锁(RLock)
为什么用 RLock(可重入锁)?
- 同一线程可以多次获取锁(重入),而不会死锁(区别于Lock)
- RLock 内部有一个「计数器」,acquire () 的调用次数,必须等于 release () 的调用次数,锁才算真正释放。
- 「谁上锁,谁解锁」(归属原则,和 Lock 一致)
- 有些业务逻辑中,同一个线程需要对同一个共享资源进行「多次连续的修改操作」,每次操作都需要加锁保证安全,用 Lock 会卡死,用 RLock 可以放心加锁。
- RLock 完全兼容 Lock 的所有功能,Lock 能做的,RLock 都能做; RLock 不会出现「自己卡死自己」的死锁问题,容错率极高;RLock 的性能损耗微乎其微,在日常开发中,这个损耗完全可以忽略不计;你永远不知道自己的代码会不会被别人修改、会不会出现嵌套调用,用 RLock 能提前规避死锁风险。
- 避免死锁:一个方法调用另一个已加锁的方法
- 例如:
enqueue_node()调用时已持有锁,内部调用get_node_state()也需要锁
python
@final
class GraphStateManager:
def __init__(self, graph: Graph, ready_queue: ReadyQueue) -> None:
"""
Initialize the state manager.
Args:
graph: The workflow graph
ready_queue: Queue for nodes ready to execute
"""
self._graph = graph
self._ready_queue = ready_queue
self._lock = threading.RLock()
# Execution tracking state
self._executing_nodes: set[str] = set()
# ============= Node State Operations =============
def enqueue_node(self, node_id: str) -> None:
"""
Mark a node as TAKEN and add it to the ready queue.
This combines the state transition and enqueueing operations
that always occur together when preparing a node for execution.
Args:
node_id: The ID of the node to enqueue
"""
with self._lock:
self._graph.nodes[node_id].state = NodeState.TAKEN
self._ready_queue.put(node_id)单线程写入:Dispatcher 的独占写入权
python
# Dispatcher 是唯一的"消费者"线程,负责:
# 1. 从 EventQueue 读取事件(只有它读取)
# 2. 调用 EventHandler 处理事件
# 3. 更新 GraphRuntimeState(通过 StateManager)设计原理:
- Worker 线程 :只写入
EventQueue(生产者) - Dispatcher 线程 :只读取
EventQueue并处理(消费者) - State 修改集中化 :所有状态修改都由 Dispatcher 通过
StateManager进行
竞态冲突防护总结
| 组件 | 锁类型 | 保护内容 | 并发策略 |
|---|---|---|---|
| EventManager | ReadWriteLock | 事件列表 | 多读单写 |
| GraphStateManager | RLock | 节点/边状态、执行集合 | 可重入互斥 |
| WorkerPool | RLock | Worker 列表、动态扩缩容 | 可重入互斥 |
| ReadyQueue | Queue 内置锁 | 任务队列 | 线程安全队列 |
| EventQueue | Queue 内置锁 | 事件队列 | 线程安全队列 |
资源管控:三重限制 + 主动中断
三重限制层次
** 工作流级别限制(ExecutionLimitsLayer)**
限制说明:
- 最大步骤数:默认 500 步,防止无限循环
- 最大执行时间:默认 1200 秒(20 分钟),防止长时间挂起
- 最大调用深度:默认 5 层,防止递归溢出
python
def __init__(self, max_steps: int, max_time: int) -> None:
"""
Initialize the execution limits layer.
Args:
max_steps: Maximum number of steps allowed
max_time: Maximum execution time in seconds allowed
"""
super().__init__()
self.max_steps = max_steps
self.max_time = max_time
# Runtime tracking
self.start_time: float | None = None
self.step_count = 0
self.logger = logging.getLogger(__name__)
# State tracking
python
# Check step limit when node execution completes
if isinstance(event, NodeRunSucceededEvent | NodeRunFailedEvent):
if self._reached_step_limitation():
self._send_abort_command(LimitType.STEP_LIMIT)
if self._reached_time_limitation():
self._send_abort_command(LimitType.TIME_LIMIT)默认配置:
python
WORKFLOW_MAX_EXECUTION_STEPS: PositiveInt = Field(
description="Maximum number of steps allowed in a single workflow execution",
default=500,
)
WORKFLOW_MAX_EXECUTION_TIME: PositiveInt = Field(
description="Maximum execution time in seconds for a single workflow",
default=1200,
)
WORKFLOW_CALL_MAX_DEPTH: PositiveInt = Field(
description="Maximum allowed depth for nested workflow calls",
default=5,
)变量级别限制(变量截断)
防护目标:
- 防止单个变量占用过大内存
- 防止数据库存储溢出
- 超大数据自动 offload 到对象存储(S3)
python
class WorkflowVariableTruncationConfig(BaseSettings):
WORKFLOW_VARIABLE_TRUNCATION_MAX_SIZE: PositiveInt = Field(
# 1000 KiB
1024_000,
description="Maximum size for variable to trigger final truncation.",
)
WORKFLOW_VARIABLE_TRUNCATION_STRING_LENGTH: PositiveInt = Field(
100000,
description="maximum length for string to trigger tuncation, measure in number of characters",
)
WORKFLOW_VARIABLE_TRUNCATION_ARRAY_LENGTH: PositiveInt = Field(
1000,
description="maximum length for array to trigger truncation.",
)代码节点输出限制(CodeNodeLimits)
关键防护点:
- 字符串长度限制:防止内存溢出
- 数值范围限制:防止溢出和精度损失
- 数组长度限制:防止拒绝服务攻击(DoS)
- 嵌套深度限制:防止递归栈溢出
- 空字节过滤 :
value.replace("\x00", ""),防止注入攻击
python
from dataclasses import dataclass
@dataclass(frozen=True)
class CodeNodeLimits:
max_string_length: int
max_number: int | float
min_number: int | float
max_precision: int
max_depth: int
max_number_array_length: int
max_string_array_length: int
max_object_array_length: int
python
def _check_string(self, value: str | None, variable: str) -> str | None:
"""
Check string
:param value: value
:param variable: variable
:return:
"""
if value is None:
return None
if len(value) > self._limits.max_string_length:
raise OutputValidationError(
f"The length of output variable `{variable}` must be"
f" less than {self._limits.max_string_length} characters"
)
return value.replace("\x00", "")
def _check_boolean(self, value: bool | None, variable: str) -> bool | None:
if value is None:
return None
return value
def _check_number(self, value: int | float | None, variable: str) -> int | float | None:
"""
Check number
:param value: value
:param variable: variable
:return:
"""
if value is None:
return None
if value > self._limits.max_number or value < self._limits.min_number:
raise OutputValidationError(
f"Output variable `{variable}` is out of range,"
f" it must be between {self._limits.min_number} and {self._limits.max_number}."
)
if isinstance(value, float):
decimal_value = Decimal(str(value)).normalize()
precision = -decimal_value.as_tuple().exponent if decimal_value.as_tuple().exponent < 0 else 0 # type: ignore[operator]
# raise error if precision is too high
if precision > self._limits.max_precision:
raise OutputValidationError(
f"Output variable `{variable}` has too high precision,"
f" it must be less than {self._limits.max_precision} digits."
)
return value主动中断机制:命令通道 + Abort 处理
中断流程:
- 检测限制违反 → 发送
AbortCommand - Dispatcher 接收命令 → 标记
graph_execution.aborted = True - 停止 Worker 线程 →
worker_pool.stop() - 清理执行状态 →
state_manager.clear_executing() - 触发清理钩子 → 释放资源、记录日志
** Abort 命令发送**
python
def _send_abort_command(self, limit_type: LimitType) -> None:
"""
Send abort command due to limit violation.
Args:
limit_type: Type of limit exceeded
"""
if not self.command_channel or not self._execution_started or self._execution_ended or self._abort_sent:
return
# Format detailed reason message
if limit_type == LimitType.STEP_LIMIT:
reason = f"Maximum execution steps exceeded: {self.step_count} > {self.max_steps}"
elif limit_type == LimitType.TIME_LIMIT:
elapsed_time = time.time() - self.start_time if self.start_time else 0
reason = f"Maximum execution time exceeded: {elapsed_time:.2f}s > {self.max_time}s"
self.logger.warning("Execution limit exceeded: %s", reason)
try:
# Send abort command to the engine
abort_command = AbortCommand(command_type=CommandType.ABORT, reason=reason)
self.command_channel.send_command(abort_command)
# Mark that abort has been sent to prevent duplicate commands
self._abort_sent = True
self.logger.debug("Abort command sent to engine")
except Exception:
self.logger.exception("Failed to send abort command")Abort 命令处理
python
def handle_pause_if_needed(self) -> None:
"""If the execution has been paused, stop workers immediately."""
if not self._graph_execution.is_paused:
return
self._worker_pool.stop()
self._state_manager.clear_executing()
def handle_abort_if_needed(self) -> None:
"""If the execution has been aborted, stop workers immediately."""
if not self._graph_execution.aborted:
return
self._worker_pool.stop()
self._state_manager.clear_executing()WorkerPool 动态扩缩容(资源弹性)
扩缩容策略:
- 扩容条件 :
queue_depth > scale_up_threshold(默认 5)且未达到max_workers - 缩容条件 :有空闲 Worker 且
idle_time > scale_down_idle_time(默认 10 秒) - 最小/最大工作线程 :
min_workers=1, max_workers=5(默认)
python
def _try_scale_up(self, queue_depth: int, current_count: int) -> bool:
"""
Try to scale up workers if needed.
Args:
queue_depth: Current queue depth
current_count: Current number of workers
Returns:
True if scaled up, False otherwise
"""
if queue_depth > self._scale_up_threshold and current_count < self._max_workers:
old_count = current_count
self._create_worker()
logger.debug(
"Scaled up workers: %d -> %d (queue_depth=%d exceeded threshold=%d)",
old_count,
len(self._workers),
queue_depth,
self._scale_up_threshold,
)
return True
return False红队安全思维:越权与溢出防护
租户隔离:Tenant ID 强制校验
防护机制:
- 每个工作流执行必须携带
<font style="color:#DF2A3F;">tenant_id</font> - 所有数据库查询都带
<font style="color:#DF2A3F;">tenant_id</font>过滤 - 防止跨租户数据访问
python
call_depth: int,
variable_pool: VariablePool,
graph_runtime_state: GraphRuntimeState,
command_channel: CommandChannel | None = None,
) -> None:
"""
Init workflow entry
:param tenant_id: tenant id
:param app_id: app id
:param workflow_id: workflow id
:param workflow_type: workflow type
:param graph_config: workflow graph config
:param graph: workflow graph
:param user_id: user id
:param user_from: user from
:param invoke_from: invoke from
:param call_depth: call depth
:param variable_pool: variable pool
:param graph_runtime_state: pre-created graph runtime state
:param command_channel: command channel for external control (optional, defaults to InMemoryChannel)
:param thread_pool_id: thread pool id
"""
# check call depth
workflow_call_max_depth = dify_config.WORKFLOW_CALL_MAX_DEPTH
if call_depth > workflow_call_max_depth:
raise ValueError(f"Max workflow call depth {workflow_call_max_depth} reached.")代码示例:
python
# 数据库查询都包含 tenant_id 过滤
workflow_run = WorkflowRun.query.filter_by(
tenant_id=tenant_id,
id=workflow_run_id
).first()代码执行沙箱(Sandbox Isolation):远程沙箱执行
安全隔离:
- 远程执行:代码在独立的沙箱容器中执行(不在主进程)
- API Key 认证:防止未授权调用
- 超时限制:防止长时间占用资源
- 网络隔离:可配置是否允许网络访问
python
def execute_code(cls, language: CodeLanguage, preload: str, code: str) -> str:
"""
Execute code
:param language: code language
:param preload: the preload script
:param code: code
:return:
"""
url = code_execution_endpoint_url / "v1" / "sandbox" / "run"
headers = {"X-Api-Key": dify_config.CODE_EXECUTION_API_KEY}
data = {
"language": cls.code_language_to_running_language.get(language),
"code": code,
"preload": preload,
"enable_network": True,
}
timeout = httpx.Timeout(
connect=dify_config.CODE_EXECUTION_CONNECT_TIMEOUT,
read=dify_config.CODE_EXECUTION_READ_TIMEOUT,
write=dify_config.CODE_EXECUTION_WRITE_TIMEOUT,
pool=None,
)
client = get_pooled_http_client(_CODE_EXECUTOR_CLIENT_KEY, _build_code_executor_client)
try:
response = client.post(
str(url),
json=data,
headers=headers,
timeout=timeout,
)
if response.status_code == 503:
raise CodeExecutionError("Code execution service is unavailable")
elif response.status_code != 200:
raise Exception(
f"Failed to execute code, got status code {response.status_code},"
f" please check if the sandbox service is running"
)
except CodeExecutionError as e:
raise e
except Exception as e:
raise CodeExecutionError(
"Failed to execute code, which is likely a network issue,"
" please check if the sandbox service is running."
f" ( Error: {str(e)} )"
)防止调用栈溢出
python
# check call depth
workflow_call_max_depth = dify_config.WORKFLOW_CALL_MAX_DEPTH
if call_depth > workflow_call_max_depth:
raise ValueError(f"Max workflow call depth {workflow_call_max_depth} reached.")防护目标:
- 防止递归工作流无限调用
- 默认最大深度 5 层
- 超过限制立即抛出异常
输入验证与注入防护
空字节过滤
python
# 代码节点输出检查
return value.replace("\x00", "") # 防止空字节注入Graph 配置验证
验证规则:
- 节点存在性检查:所有边的起点和终点节点必须存在
- 根节点有效性:根节点必须存在且在 Graph 中
- 触发节点互斥:Trigger 节点不能与 Start 节点共存
python
def validate(self, graph: Graph) -> Sequence[GraphValidationIssue]:
"""Validate the provided graph and return any discovered issues."""
...
@dataclass(frozen=True, slots=True)
class _EdgeEndpointValidator:
"""Ensures all edges reference existing nodes."""
missing_node_code: str = "MISSING_NODE"
def validate(self, graph: Graph) -> Sequence[GraphValidationIssue]:
issues: list[GraphValidationIssue] = []!!!红队安全矩阵
| 攻击面 | 潜在威胁 | 防护措施 | 代码位置 |
|---|---|---|---|
| 跨租户访问 | 数据泄露 | 强制 tenant_id 校验 |
所有数据库查询 |
| 无限递归 | 栈溢出、DoS | WORKFLOW_CALL_MAX_DEPTH=5 |
workflow_entry.py |
| 无限循环 | DoS | MAX_EXECUTION_STEPS=500 |
execution_limits.py |
| 内存溢出 | OOM | 变量截断 + Offload | truncation.py |
| 代码注入 | RCE | 远程沙箱 + API Key | code_executor.py |
| 空字节注入 | 数据损坏 | replace("\x00", "") |
code_node.py |
| 精度溢出 | 数据损坏 | max_precision 限制 |
code_node.py |
| 网络攻击 | SSRF | 沙箱网络隔离 | code_executor.py |
| 竞态条件 | 数据不一致 | 读写锁 + RLock | event_manager.py |
5. 关键代码注释版本
ExecutionLimitsLayer(限制层)
python
@final
class ExecutionLimitsLayer(GraphEngineLayer):
"""
工作流执行限制层
监控指标:
- step_count:节点执行步数
- execution_time:总执行时间
触发条件:
- step_count > max_steps(默认 500)
- execution_time > max_time(默认 1200 秒)
应对措施:
- 发送 AbortCommand 到 CommandChannel
- 停止所有 Worker 线程
- 清理执行状态并持久化错误
"""
def on_event(self, event: GraphEngineEvent) -> None:
"""事件监听:每次节点执行完成后检查限制"""
if not self._execution_started or self._execution_ended or self._abort_sent:
return
# 步骤计数:每个节点启动时 +1
if isinstance(event, NodeRunStartedEvent):
self.step_count += 1
# 限制检查:每个节点完成后检查
if isinstance(event, NodeRunSucceededEvent | NodeRunFailedEvent):
if self._reached_step_limitation():
self._send_abort_command(LimitType.STEP_LIMIT)
if self._reached_time_limitation():
self._send_abort_command(LimitType.TIME_LIMIT)GraphStateManager(状态管理器)
python
@final
class GraphStateManager:
"""
图状态管理器:使用 RLock 保护共享状态
保护资源:
- _graph.nodes:节点状态字典
- _graph.edges:边状态字典
- _executing_nodes:正在执行的节点集合
并发策略:
- RLock(可重入锁):同一线程可重复获取
- 所有状态修改都在锁内进行
- 避免死锁:方法调用嵌套时可重入
"""
def enqueue_node(self, node_id: str) -> None:
"""入队节点:原子操作(状态修改 + 队列入队)"""
with self._lock: # 临界区开始
self._graph.nodes[node_id].state = NodeState.TAKEN
self._ready_queue.put(node_id)
# 临界区结束
def is_execution_complete(self) -> bool:
"""检查执行完成:ReadyQueue 为空 且 无执行中节点"""
with self._lock:
return self._ready_queue.empty() and len(self._executing_nodes) == 0CodeNode 输出验证
python
def _check_string(self, value: str | None, variable: str) -> str | None:
"""
字符串输出验证:防止内存溢出和注入攻击
防护措施:
1. 长度限制:max_string_length(默认 100,000)
2. 空字节过滤:replace("\x00", "")
攻击场景:
- 恶意代码节点返回超长字符串 → DoS
- 返回带空字节的字符串 → SQL 注入、日志污染
"""
if value is None:
return None
# 长度检查
if len(value) > self._limits.max_string_length:
raise OutputValidationError(
f"Output variable `{variable}` exceeds max length {self._limits.max_string_length}"
)
# 空字节过滤(红队思维:防止二次注入)
return value.replace("\x00", "")
def _check_number(self, value: int | float | None, variable: str) -> int | float | None:
"""
数值输出验证:防止精度溢出和范围越界
防护措施:
1. 范围限制:min_number ~ max_number
2. 精度限制:max_precision(小数位数)
攻击场景:
- 返回极大/极小数值 → 溢出、精度损失
- 返回高精度浮点数 → 存储空间浪费、计算误差
"""
if value is None:
return None
# 范围检查
if value > self._limits.max_number or value < self._limits.min_number:
raise OutputValidationError(f"Value {value} out of range")
# 精度检查(仅针对浮点数)
if isinstance(value, float):
decimal_value = Decimal(str(value)).normalize()
precision = -decimal_value.as_tuple().exponent if decimal_value.as_tuple().exponent < 0 else 0
if precision > self._limits.max_precision:
raise OutputValidationError(f"Precision {precision} exceeds limit {self._limits.max_precision}")
return value标准化回答话术(300字以内)
如何设计一个工业级 LLM 应用的工作流引擎?
"可从四个核心维度来设计这个系统:DAG 调度、变量池隔离、并行执行原子性、以及兜底防护。"
- DAG 调度算法选择:"首先采用 ** 拓扑排序 + 事件驱动**** 的混合模式。具体来说**
- 数据结构 :使用 邻接表存储 DAG,维护每个节点的入边集合(in-edges)和出边集合(out-edges)。
- 调度策略 :实现 就绪队列 (Ready Queue),当节点的所有前驱节点执行完毕时自动入队。这里不用传统的 Kahn 算法全图扫描,而是通过 事件驱动 动态更新:每当节点完成,遍历其出边,检查后继节点的入度是否降为0。
- 优势 :时间复杂度 O(V+E),且天然支持 断点续传 ------ 只需持久化就绪队列和已完成节点集合。"
- **节点隔离策略(变量池):变量池采用 ****双层哈希索引 + 命名空间隔离 **设计:
- 存储结构 :
Dict[node_id, Dict[variable_name, Variable]],第一层按节点ID分片,第二层存储该节点的所有输出变量。 - 访问控制 :引入 Variable Selector 机制(类似 JSONPath),节点必须在 DSL 中显式声明依赖(如
{``{node1.output}}),运行时仅能访问白名单变量。 - 不可变性 :所有复杂对象(Object/Array)返回时执行 深拷贝(Deep Copy),避免多个节点持有同一引用导致的数据竞争。
- 类型系统:强制类型(File、String、Number、Object、Array),在变量池层面拦截类型不匹配的传递。"
- 存储结构 :
- 并行执行下的原子性保障:生产和消费者模式的多线程协作。这是工业场景最复杂的部分:
- 并行模型 :采用 Worker 线程池(默认动态伸缩,min=1, max=CPU核心数),从就绪队列并行拉取独立节点执行。
- 原子性保证 :
- 节点执行并行,但变量写入串行化 ------ Worker 执行完成后不直接写变量池,而是发送
NodeSucceededEvent到 单线程 Dispatcher,由它统一更新变量池。 - 使用 读写锁(ReadWriteLock)保护事件缓冲区:多个 Worker 可并发读取变量(读锁),但只有 Dispatcher 能写入(写锁独占)。
- 节点执行并行,但变量写入串行化 ------ Worker 执行完成后不直接写变量池,而是发送
- 分布式场景 :如果跨机器部署,可升级为 Redis 分布式锁 + 版本号 ,在写入前检查
node_execution_id是否匹配。
- 死循环与内存泄露的工程化兜底:实施三重防护:
- 执行步数限制 (防止死循环):默认
max_steps=500,每启动一个节点step_count++。超过阈值后,通过 Command Channel 发送AbortCommand,强制终止工作流 - 执行时间限制 (防止无限挂起):默认
max_time=1200s(20分钟),使用 Execution Limits Layer 监听每个节点完成事件,检查time.time() - start_time。超时同样触发AbortCommand - 嵌套调用深度限制 (防止栈溢出):工作流支持子工作流调用时,限制
call_depth <= 5" - 变量大小限制 (防止 OOM):单个变量最大 200KB(
MAX_VARIABLE_SIZE)。在变量池add()方法中校验len(json.dumps(value)),超过则拒绝写入或截断。对于 File 类型,只存储元数据(URL、MIME、Size),实际二进制数据存储在对象存储(S3/OSS) - 代码节点输出限制:字符串长度限制 :防止内存溢出;数值范围限制 :防止溢出和精度损失;数组长度限制 :防止拒绝服务攻击(DoS);空字节过滤 :
value.replace("\x00", ""),防止注入攻击
- 执行步数限制 (防止死循环):默认
实际故障案例:生产环境遇到过一个典型问题,某个 HTTP Request 节点因目标服务超时导致整个工作流卡死
问题根因 :Worker 线程在等待 requests.get(timeout=None),就绪队列无法感知,导致后续节点无法调度。
解决方案:
- 节点级超时 :在 Node 基类增加
node_timeout配置(默认 300s),使用signal.alarm()或concurrent.futures.TimeoutError强制中断 - 健康检查:Dispatcher 每 10s 检查 Worker 心跳,超过 60s 无响应则标记为 Zombie,触发 Worker 替换
- 优雅降级 :支持节点设置
error_strategy=FAIL_BRANCH,失败时自动走备用分支,而非直接中止全流程