ReAct 框架详解:让大模型学会"一边思考,一边做事"
在 AI Agent(智能体)爆发的今天,我们经常听到一个词:ReAct。
它并不是那个著名的前端框架 React.js,而是 Re asoning + Acting(推理 + 行动)的缩写。
如果说 Chain of Thought (CoT) 让大模型学会了"三思而后行",那么 ReAct 则让大模型学会了"知行合一"。它是构建现代 Agent(包括我们在上一篇文章中提到的 Agentic RAG)最核心的基础模式。
本文将深入剖析 ReAct 框架的原理、工作流程,对比主流推理框架,并探讨如何在生产环境中保障其稳定性。最后,我们将手把手带你用 Python 实现一个旅游规划 Agent。
1. 为什么我们需要 ReAct?
在 ReAct 出现之前,大语言模型(LLM)主要面临两个极端的问题:
-
纯推理 (Reasoning Only): 模型通过 CoT(思维链)进行复杂的逻辑推演,但它是一个"缸中之脑",无法接触外部世界。
- 后果: 容易产生幻觉 (Hallucination)。例如,它可能会一本正经地编造一个不存在的实时新闻或过期的旅游攻略。
-
纯行动 (Acting Only): 模型被训练成直接输出 API 调用指令。
- 后果: 缺乏规划能力。如果第一步行动失败了(例如搜索无结果),模型往往不知道该怎么办,无法根据反馈调整策略。
ReAct 的核心洞察是: 人类在解决问题时,是推理 和行动交织进行的。我们不仅会思考,还会根据行动的结果修正我们的思考。
2. ReAct 的核心原理:三元循环
ReAct 框架将 LLM 的解决问题过程形式化为一个无限循环,直到任务解决: Thought (思考) -> Action (行动) -> Observation (观察)
1. Thought (思考/推理)
模型首先分析当前的情况、用户的目标,并决定下一步该做什么。这一步利用了 LLM 强大的逻辑推理能力。ReAct 的精髓在于,模型会把这个"思考过程"显式地写出来。
- 示例: "用户想去京都玩 3 天。我需要先查一下京都最近的天气,然后推荐适合这个天气的景点。"
2. Action (行动)
基于思考的结果,模型生成一个具体的行动指令。这通常是调用一个外部工具(Tool)。
- 示例:
Search["Kyoto weather forecast next 3 days"]
3. Observation (观察)
这是最关键的一步。行动产生的结果(API 的返回值、搜索到的网页片段)被反馈回模型。这是模型获取外部知识的唯一途径。
- 示例: "搜索结果显示:未来 3 天京都是晴天,气温 15-20 度。"
4. 循环 (Repeat)
模型结合新的观察结果,开始新一轮的 Thought。
- 新 Thought: "天气很好,适合户外活动。既然是 3 天,我可以安排第一天去伏见稻荷大社..."
2.5 图解 ReAct:从视觉角度理解循环
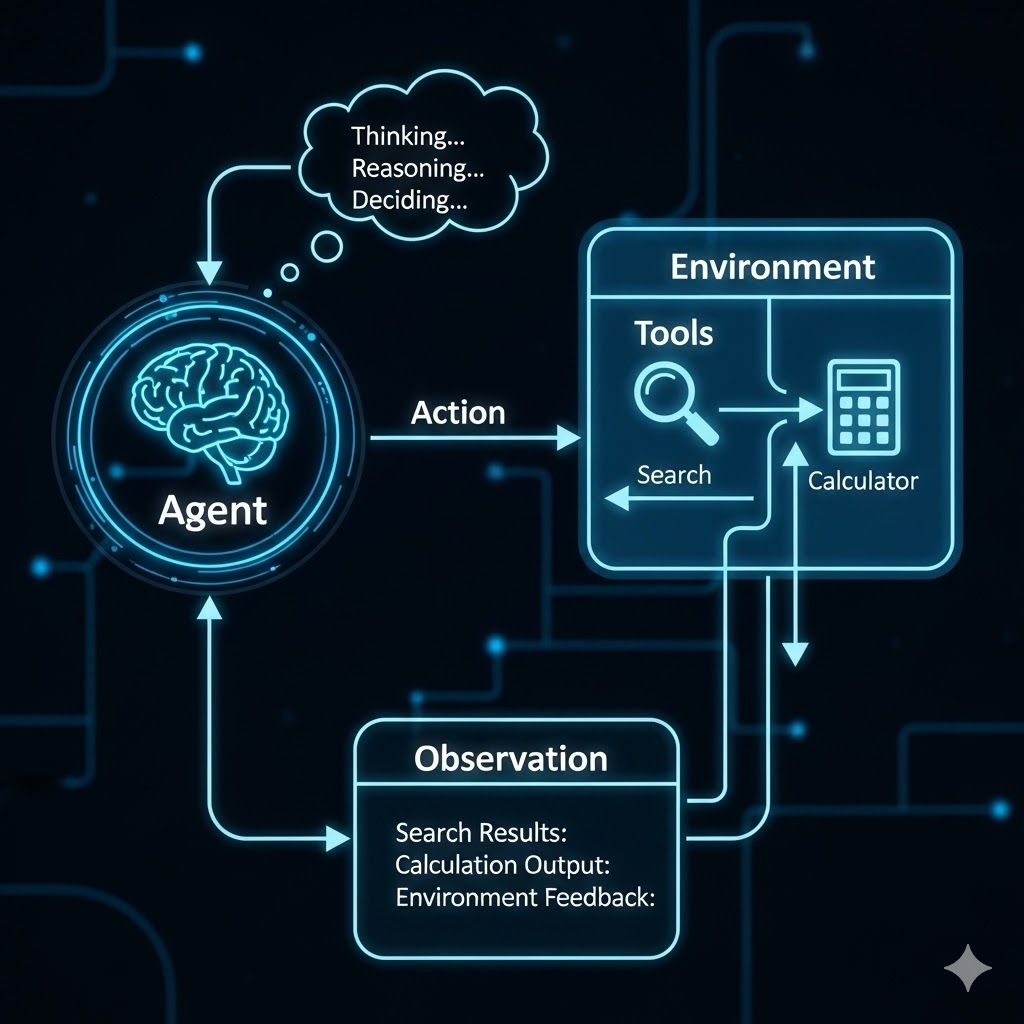
如果我们将 ReAct 的工作流程通过架构图展示出来,它构成了智能体的"认知地图":
-
Input / Task (输入/任务): 流程起点。
-
Agent / Model (智能体): 核心大脑,负责产生推理轨迹。
-
Action Request (行动请求): 从 Agent 指向外部工具的箭头。
-
Environment / Tools (环境/工具): 搜索引擎、数据库、计算器等。
-
Observation (观察/反馈): 从环境指回 Agent 的箭头,带回真实数据。
视觉流向总结: Agent 发出 Action -> 撞击 Environment -> 产生 Observation -> 回流给 Agent -> 触发新的 Thought。
3. ReAct 的"催眠术":Prompt 揭秘
你可能会问:"LLM 怎么知道要按照这个格式输出?"
答案在于 Prompt Engineering(提示词工程) 。在 ReAct Agent 启动前,我们会给它一段 System Prompt,其中包含了Few-Shot Examples(少样本示例)。
一个典型的 ReAct Prompt 看起来像这样(简化版):
尽你所能回答用户的问题。你可以使用以下工具:
[Search]: 搜索引擎,用于查找实时信息。
[Calculator]: 计算器,用于数学运算。
请使用以下格式:
Question: 需要回答的输入问题
Thought: 你应该思考下一步做什么
Action: 要采取的行动,必须是 [Search, Calculator] 之一
Action Input: 行动的具体输入
Observation: 行动的结果(由用户或环境提供)
... (重复 思考/行动/观察 N 次)
Thought: 我现在知道最终答案了
Final Answer: 原始问题的最终答案
Begin!
Question: 埃隆·马斯克的生日是哪天?
Thought: 我需要搜索埃隆·马斯克的生日。
Action: Search
Action Input: Elon Musk birthday
Observation: June 28, 1971
Thought: 我已经知道了答案。
Final Answer: 埃隆·马斯克出生于 1971 年 6 月 28 日。
Question: {user_input}通过这种"完形填空"式的训练,大模型学会了在遇到新问题时,也模仿这个 Thought -> Action -> Observation 的节奏。
4. ReAct 的优缺点分析
优点
-
鲁棒性强: 具有自我纠错能力。如果
Action 1没搜到结果,模型会在Thought 2中分析原因并尝试新关键词。 -
可解释性高: 我们可以清晰地看到模型的每一个思考步骤,不仅知道结果,还知道过程。
-
解决幻觉: 强迫模型基于
Observation(事实)说话,减少胡编乱造。
缺点
-
Token 消耗大: 每一轮循环都要把历史记录(越来越长)发给 LLM,成本和时间成倍增加。
-
延迟高: 串行处理导致响应速度慢。
-
死循环风险: 模型可能会陷入"搜索-失败-搜索-失败"的死循环,需要设置最大迭代次数(Max Iterations)。
5. 纵横对比:ReAct vs. CoT vs. ToT
在构建智能体时,我们经常会面临架构选择的难题。为什么 ReAct 能脱颖而出?我们将它与 CoT (思维链) 和 ToT (思维树) 进行对比:
1. CoT (Chain of Thought / 思维链)
-
核心机制: 依赖模型纯内部的知识库,进行线性的步骤推理(Step-by-step)。
-
局限性: "闭门造车"。一旦模型内部知识过时或缺失,它很容易产生"幻觉",一本正经地胡说八道。且无法获取实时信息(如天气、股价)。
-
适用场景: 纯逻辑数学题、常识推理。
2. ToT (Tree of Thoughts / 思维树)
-
核心机制: 像下棋一样,探索多种可能的路径,进行前瞻、回溯和自我评估,选择最优解。
-
局限性: "过度思考"。结构极其复杂,计算成本高昂,推理速度慢。对于大多数不需要穷举所有可能性的日常任务来说,杀鸡用牛刀。
-
适用场景: 创意写作、复杂的规划解谜。
3. ReAct (Reasoning + Acting)
-
核心机制: 知行合一 。采用
Think -> Act -> Obs循环。它不仅思考,还动手去查。它能够实时获取外部信息,并利用 Observation(环境反馈)来形成闭环,修正自己的认知。 -
优势: 有效解决了 CoT 的幻觉问题和 ToT 的成本问题,是目前性价比最高的通用 Agent 架构。
总结: CoT 和 ToT 的缺点在于它们都受限于模型内部。而 ReAct 的实用性在于它打破了模型与现实世界的隔阂。
6. 工程化挑战:抗幻觉机制与稳定性保障
虽然 ReAct 架构很优秀,但在生产环境(Production)中落地 Agent,我们还需要解决"稳定性"和"安全性"问题。这往往是面试中的核心考点。
1. 存在性验证 (Existence Verification)
永远不要轻信 LLM 的输出。
-
机制: 当 Agent 声称"找到了答案"或"引用了某文件"时,增加一层代码逻辑进行核对。
-
作用: 避免 Agent 虚构出一个不存在的文件名、链接或数据。
2. 预算熔断 (Budget Circuit Breaker)
防止 Agent 陷入死循环或过度消耗资源。
-
机制: 设置
Max Iterations(最大循环次数,如 10 次)和Max Execution Time(最大执行时间)。 -
作用: 防止 Agent 像一个钻牛角尖的人一样,在一个无解的问题上无限消耗 Token,导致账单爆炸。
3. 动态工具选择与物理一致性
-
动态工具: 根据当前场景(Context)动态加载合适的工具集,而不是把所有工具(如 100 个 API)一次性塞给模型,这会降低模型的注意力。
-
物理一致性校验: 在涉及现实世界逻辑时增加规则约束。
- 示例: 如果 Agent 安排行程,必须校验"从 A 地到 B 地"的交通时间是否合理,防止出现"上午 10 点在巴黎,上午 11 点就在纽约"这种物理上不可能的幻觉。
7. 总结
ReAct 框架是 AI Agent 的"操作系统"。它通过简单的 Prompt Engineering 技巧,解锁了 LLM 极其强大的通用问题解决能力。它是 AutoGPT、BabyAGI 以及 LangChain Agent 的基石。
8. 实战代码:使用 LangChain 构建旅游规划 Agent
下面是一个使用 Python 和 LangChain 框架实现的具体示例。我们将构建一个旅游规划助手,它拥有"搜索"和"计算"的能力。
场景: 用户想去巴黎玩 3 天,并想知道大概的预算。
依赖安装
pip install langchain langchain-openai google-search-results
python
import os
from langchain.agents import load_tools, initialize_agent, AgentType
from langchain_openai import ChatOpenAI
# 1. 配置 API Key (实际使用时请替换为你的 Key)
os.environ["OPENAI_API_KEY"] = "sk-..."
os.environ["SERPAPI_API_KEY"] = "..." # 用于 Google 搜索
# 2. 初始化大模型 (大脑)
# 使用 temperature=0 让模型输出更稳定,不做过多发散
llm = ChatOpenAI(model="gpt-4", temperature=0)
# 3. 加载工具 (双手)
# "serpapi": Google 搜索工具,用于查景点、查天气
# "llm-math": 数学计算工具,用于计算预算
tools = load_tools(["serpapi", "llm-math"], llm=llm)
# 4. 初始化 Agent (身体)
# AgentType.ZERO_SHOT_REACT_DESCRIPTION: 这是最标准的 ReAct 模式
# verbose=True: 让我们看到 Agent 的"内心独白" (Thought/Action/Observation)
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
handle_parsing_errors=True # 容错机制
)
# 5. 给 Agent 下达复杂任务
query = """
我想去巴黎玩 3 天。
请帮我做以下几件事:
1. 查一下下周巴黎的天气。
2. 推荐 3 个必去的博物馆。
3. 假设每个博物馆门票平均 20 欧元,计算 2 个人去这 3 个博物馆的总门票花费是多少?
"""
print(f"用户问题: {query}\n")
agent.invoke(query)