文章目录
项目背景
核心目标:使用 Easy Dataset 对大批量文本自动构建标准化微调数据集。
项目实践:在前期工作中(Fandom Wiki 网站爬取文本信息踩坑实录),通过爬虫从 Doraemon Fandom Wiki 网站批量爬取了一批哆啦A梦漫画道具文本数据,现在要根据此类文本数据和 Easy Dataset 批量构建"xxx的作用是什么"的微调数据集。
工具使用:Easy Dataset 是一个开源 LLM 微调数据集自动化构建工具,以 GUI 实现 "文档解析 - 文本分块 - 问答生成 - 标签管理 - 数据导出 - 评估" 全流程闭环,大幅降低高质量领域数据的制作门槛。该工具存在 Windows 和 Linux 客户端,更方便安装和使用:https://github.com/ConardLi/easy-dataset
数据清洗
最终目的是要构建一批"xxx的作用是什么"的微调数据集,此处 xxx 为哆啦A梦的道具名,在爬虫阶段已经将道具名设置为 txt 文件名(一个 txt 文件为一个哆啦A梦道具)。
针对 Easy Dataset 自动构建问题,存在两种方式:
- 通过
项目设置------提示词设置------基础问题生成中的提示词设计,自动的从文本块中提炼问题集合。 - 通过
问题管理------问题模板的设置,批量对文本块设置相同的问题内容。
在该场景中,我们不需要从文本块中自动提炼问题集合,而仅需提取出道具名,从而构建"xxx的作用是什么"的单个问题即可,因此使用方式一并重新设置提示词。
为了便于大模型自动构建问题,在数据清洗阶段将"道具名:xxx"加入 txt 文件的第一行,并利用代码剔除文本信息中的部分无用信息,用于节省后续处理的 token 消耗:
python
import os
import re
def clean_text(text):
"""
根据要求清洗文本
"""
# 1. 将"(日语:xxx)"替换为空
# 使用非贪婪匹配 .*? 来匹配xxx部分
text = re.sub(r'(日语:.*?)', '', text)
# 2. 将"(注:内容来源为网页 Meta 描述)"替换为空,并删除之后的换行符
# \s* 匹配包括换行符在内的空白字符
text = re.sub(r'\(注:内容来源为网页 Meta 描述\)\s*', '', text)
# 3. 将"注意:下文记述作品情节,可能会降低欣赏原作的兴致。"替换为空,并删除之后的换行符
text = re.sub(r'注意:下文记述作品情节,可能会降低欣赏原作的兴致。\s*', '', text)
# 4. 将"记述作品情节在此处结束"替换为空,并删除之后的换行符
text = re.sub(r'记述作品情节在此处结束\s*', '', text)
return text
def main():
# 定义文件夹名称
input_folder = "哆啦A梦漫画道具"
output_folder = "哆啦A梦漫画道具-数据清洗"
# 检查输入文件夹是否存在
if not os.path.exists(input_folder):
print(f"错误:当前目录下未找到文件夹 '{input_folder}'")
return
# 创建输出文件夹(如果不存在的话)
if not os.path.exists(output_folder):
os.makedirs(output_folder)
print(f"已创建输出文件夹:'{output_folder}'")
# 遍历输入文件夹中的所有文件
files = os.listdir(input_folder)
# 筛选后缀为 .txt 的文件
txt_files = [f for f in files if f.endswith('.txt')]
if not txt_files:
print(f"在 '{input_folder}' 中没有找到任何 .txt 文件。")
return
count = 0
for filename in txt_files:
input_path = os.path.join(input_folder, filename)
output_path = os.path.join(output_folder, filename)
try:
# 读取文件内容,优先尝试 utf-8,失败则尝试 gbk
content = ""
try:
with open(input_path, 'r', encoding='utf-8') as f:
content = f.read()
except UnicodeDecodeError:
with open(input_path, 'r', encoding='gbk') as f:
content = f.read()
# 执行清洗
new_content = clean_text(content)
# --- 新增功能开始 ---
# 获取文件名(去掉.txt后缀)
tool_name = os.path.splitext(filename)[0]
# 拼接标题:第一行写入"道具名:xxx",然后换两行
header_text = f"道具名:{tool_name}\n\n"
# 将标题加在清洗后文本的最前面
final_content = header_text + new_content
# --- 新增功能结束 ---
# 写入新文件,统一使用 utf-8 编码保存
with open(output_path, 'w', encoding='utf-8') as f:
f.write(final_content)
print(f"成功处理: {filename}")
count += 1
except Exception as e:
print(f"处理文件 {filename} 时出错: {e}")
print("-" * 30)
print(f"处理完成!共处理了 {count} 个文件。")
print(f"清洗后的文件已保存在: {output_folder}")
if __name__ == "__main__":
main()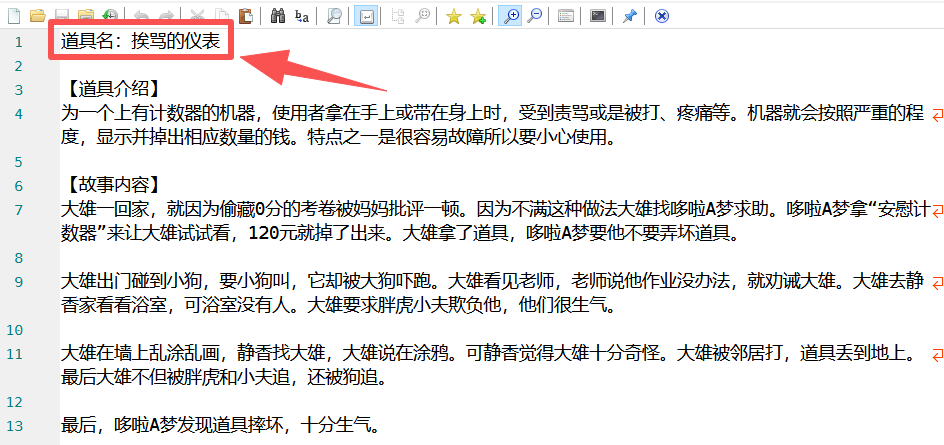
Easy Dataset 设置及使用
基础设置
使用 Easy Dataset 时,先创建项目,然后在项目设置中设置模型配置指定大模型,并可以在任务配置中设置文本分块设置(固定长度分块、自定义符号分块)等。软件可视化逻辑做的比较好,基础设置不再赘述,本项目中仅需设置模型配置环节。
数据处理
在数据源中上传文本数据,等待智能分割:
使用自动数据清洗,可以剔除分割文本中的无用信息和自动修正某些错误:
在更多------项目设置------内容生成------基础问题生成部分重新设置提示词,使其仅从文本中提取哆啦A梦道具名称并生成标准化问题:
bash
# Role: 哆啦A梦道具信息提取专家
## Profile:
- Description: 你是专门负责从文本中提取哆啦A梦道具名称并生成标准化问题的专家。
- Input Length: {{textLength}} 字
- Output Goal: 识别道具名称,并基于该名称生成一个特定格式的问题。
## Skills:
1. 能够从文本中准确识别哆啦A梦道具的名称(通常文本开头会有"道具名:xxx"的标记)。
2. 能够忽略故事情节、人物对话等无关信息,专注于实体名称提取。
3. 能够严格按照指定格式输出问题。
## Workflow:
1. **定位名称**:通读文本,查找"道具名:"标记,提取出该道具的具体名称。
2. **生成问题**:仅基于提取的道具名,构建一个格式为"[道具名]道具的作用是什么?"的问题。
## Constraints:
1. 只需生成 1 个问题,不要生成多个问题。
2. 问题格式必须严格遵守"[道具名]道具的作用是什么?",不得随意修改句式或添加多余词汇。
3. 输出必须为合法的 JSON 数组,数组中仅包含生成的这一个问题字符串。
4. 不要在问题中包含"根据文本"或"文中提到"等提示语,直接提问。
## Output Format:
- 使用合法的 JSON 数组,仅包含一个字符串元素。
- 字段必须使用英文双引号。
- 严格遵循以下结构:
```
["问题"]
```
## Output Example:
```
["天气决定表道具的作用是什么?"]
```
## Text to Analyze:
{{text}}在数据源中批量生成问题:
在问题管理中批量生成单轮对话数据集:
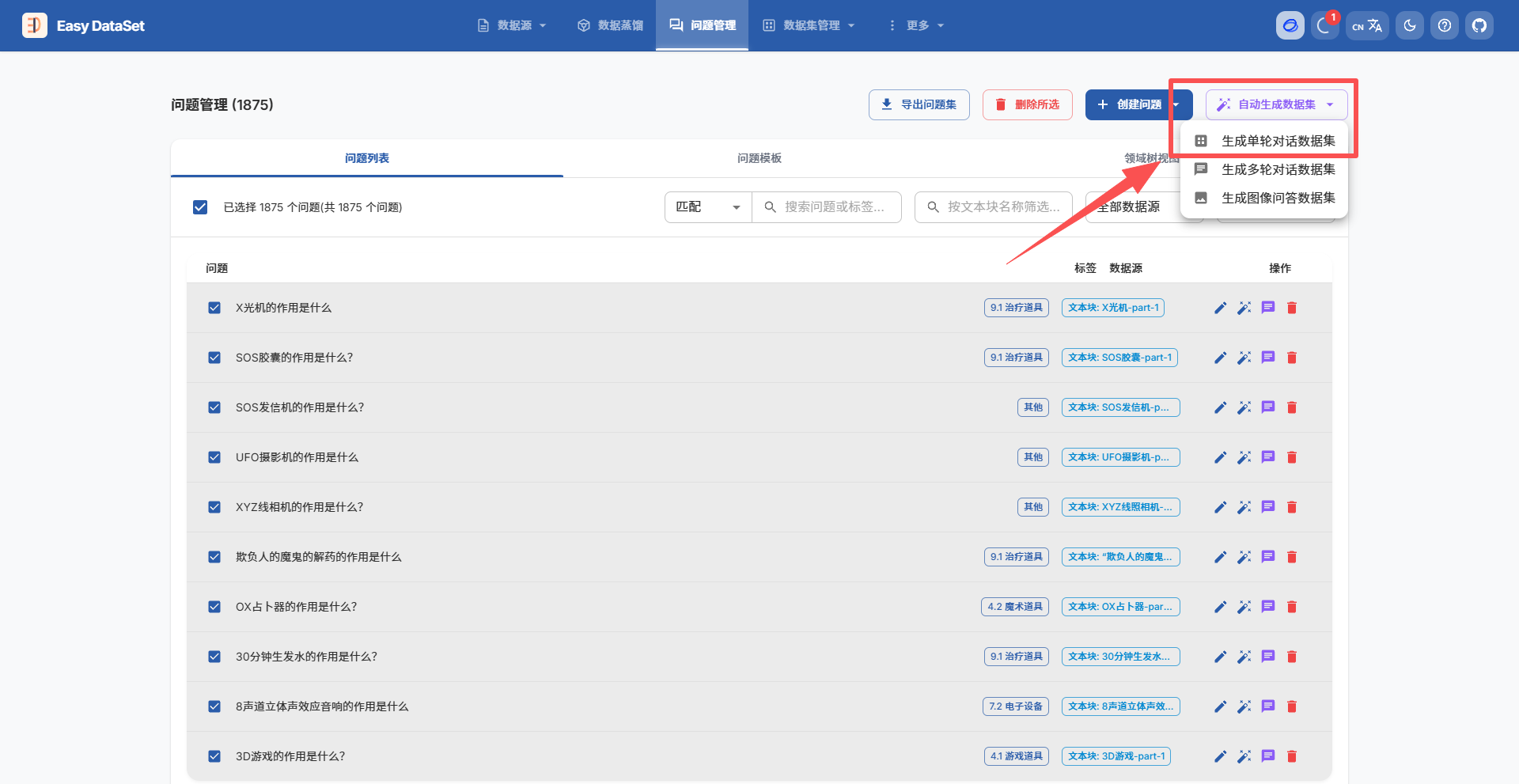
在数据集管理中使用自动质量评估对单轮对话数据集进行评价:
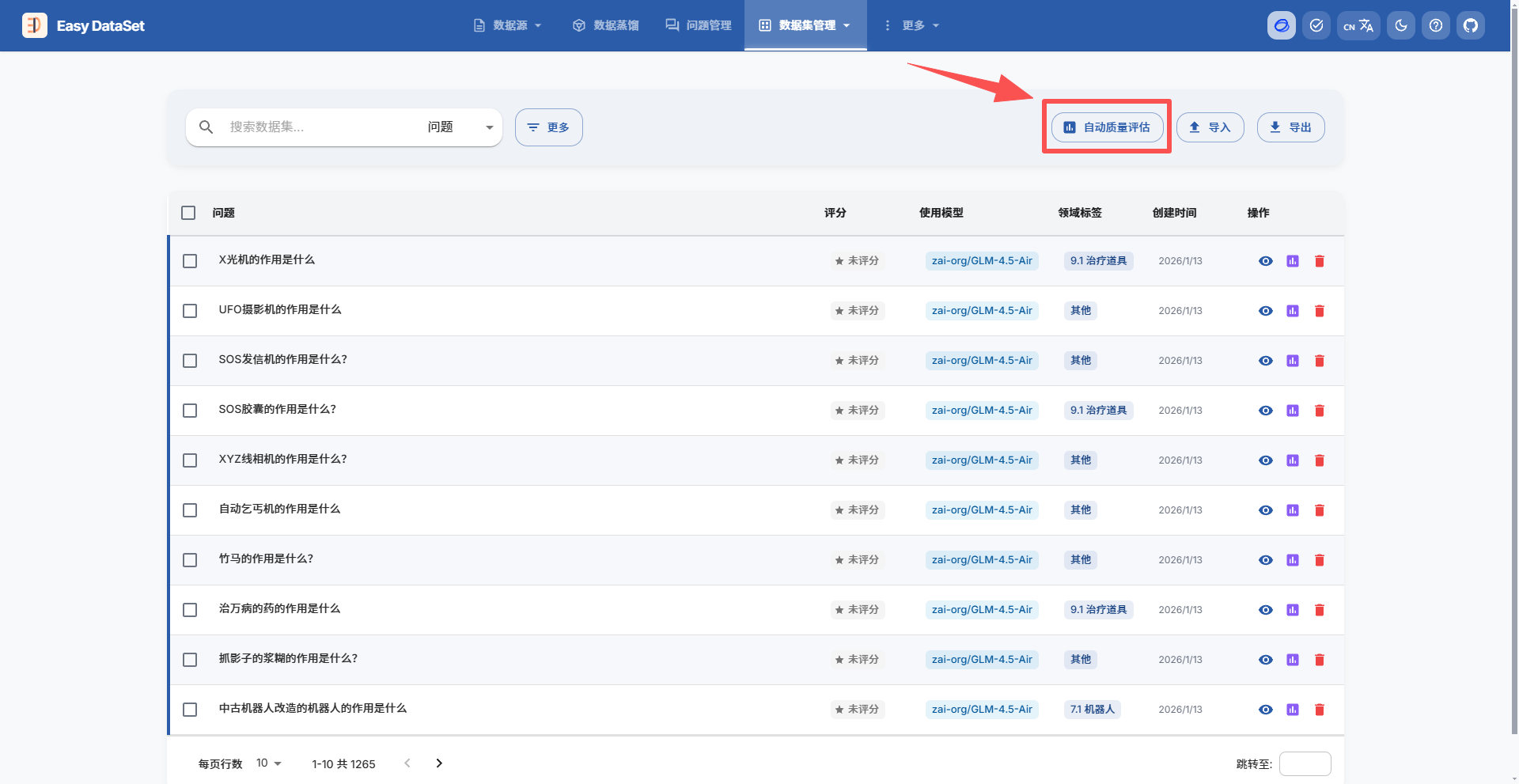
可以筛选评分较低的内容再进行针对性的修改:
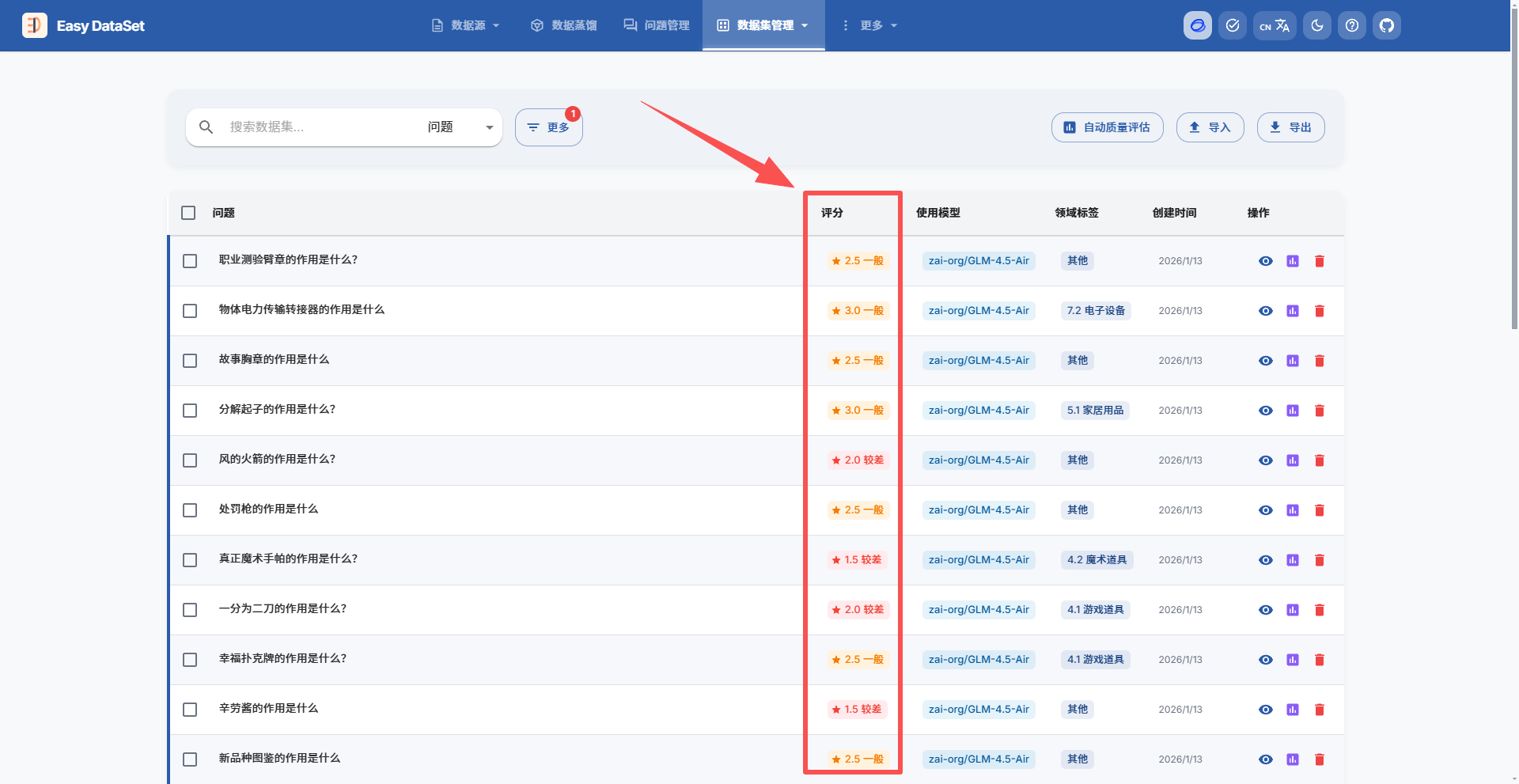
完成调整后使用导出即可:

此数据集已开源至 ModelScope:https://modelscope.cn/datasets/DragonLin/Doraemon_prop_function_dataset
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=e2hnqefd0gs