参考资料
- 如何在 AWS EC2 实例上通过"伪"嵌套虚拟化方案运行 Firecracker
- How to run Firecracker without KVM on cloud VMs
- 为AI Agent构建安全沙箱基础架构:在Amazon EKS上部署Kata Containers的最佳实践
- https://github.com/xzy0223/eks-kata-containers
- https://github.com/kata-containers/kata-containers/blob/main/docs/how-to/how-to-use-kata-containers-with-firecracker.md
Firecracker虚拟化相关问题
Firecracker可以实现启动microvm的需求,是否可以运行在m5类型的实例上,和bear metal相比有哪些区别?
- 普通的虚拟化
m5实例(如m5.large,m5.xlarge)无法运行 Firecracker,因为 AWS 的普通虚拟化实例不支持嵌套虚拟化(Nested Virtualization),即无法提供/dev/kvm。必须使用m5.metal(裸金属)实例 - Firecracker 强依赖于 Linux 的 KVM (Kernel-based Virtual Machine) 技术。要运行 KVM,CPU 必须暴露硬件虚拟化扩展(Intel VT-x 或 AMD-V)。对于普通的m5实例,AWS 目前在这些普通的 Guest OS 中屏蔽了硬件虚拟化指令集(VMX flags)
Firecracker使用KVM创建虚拟机如何体现?
- KVM 负责的 CPU 和内存虚拟化(利用硬件指令集),而 Firecracker 负责KVM 并处理 KVM 处理不了的 I/O 设备模拟。
- Firecracker 本身是一个运行在 Linux 用户态的进程(Binary),它无法直接操作 CPU 硬件的虚拟化功能(如 Intel VT-x 或 AMD-V)。Firecracker 启动时会打开
/dev/kvm这个设备文件,通过ioctl()系统调用向 KVM 发送指令创建虚拟机(在内核里给我开立一个独立的虚拟化上下文(Context),并给我一个文件句柄(Handle)来管理它) - 当内核收到
KVM_CREATE_VM指令时,分配struct kvm结构体,代表一个虚拟机的核心数据结构。初始化 MMU(内存管理单元)上下文,确保这个 VM 里的操作系统将来在访问它认为的"物理地址"时,KVM 能通过这套硬件加速的页表,正确地将其翻译成宿主机的真实物理内存地址。此后KVM 把这个新创建的struct kvm关联到发起调用的 Firecracker 进程(当 Firecracker 进程被杀掉时,这个虚拟机相关的内核资源也会被自动清理掉) - KVM 负责"配置"进程相关的独立的上下文VMCS (Virtual Machine Control Structure)(告诉 CPU 哪些指令需要拦截),而 CPU 硬件负责在运行时"监控"并在遇到这些指令时"触发" VM Exit
如果是x86平台,运行 KVM为什么要求CPU 必须暴露硬件虚拟化扩展Intel VT-x?
-
传统的 x86 架构有 4 个特权级别(Ring 0 到 Ring 3)。虚拟机里的操作系统(Guest OS)也认为自己是内核,它必须运行在 Ring 0 才能执行特权指令(如修改页表
CR3寄存器)。但是,宿主机(Host OS)已经占据了物理硬件的 Ring 0,绝不能把真正的 Ring 0 让给 Guest OS,否则宿主机就失去控制权了。 -
在 Intel VT-x 出现之前(如早期的 VMware Workstation),为了解决上述矛盾,虚拟化软件必须使用非常复杂的软件技术。
- 强行把 Guest OS 挪到 Ring 1 运行。当 Guest OS 在 Ring 1 试图执行一条特权指令(例如"关中断")时,CPU 会报错(抛出异常),因为只有 Ring 0 能做这个。虚拟化软件(VMM)捕获这个错误,然后模拟这条指令的效果,再告诉 Guest OS "你执行成功了"。
- 但是x86 指令集中有一部分指令是 "敏感但非特权" 的。意思是,这些指令如果不运行在 Ring 0,它不会报错,而是会静默失败或者表现出不同的行为(例如读取
CS寄存器)。 这就导致 VMM 无法捕获这些行为,Guest OS 会莫名其妙崩溃。 - 因此VMM 必须在指令执行前扫描并动态修改二进制代码(Binary Translation),这极大地牺牲了性能,且实现极其复杂。
-
KVM 利用 Intel VT-x 来抛弃复杂的软件模拟。引入了两个维度的操作,
- VMX Root Operation:宿主机(Host)运行的模式,宿主机运行在 VMX Root 的 Ring 0
- VMX Non-Root Operation:虚拟机(Guest)运行的模式,Guest OS 运行在 VMX Non-Root 的 Ring 0
- Guest OS 以为自己在 Ring 0,它执行特权指令时,CPU 硬件会自动判断
- 如果是普通指令,直接在硬件执行(速度极快,接近原生)。
- 如果是敏感指令(如涉及硬件控制),CPU 会强制暂停 Guest OS,触发 VM Exit,将控制权交还给 Host(KVM)。
- KVM的作用是配置好VMCS (Virtual Machine Control Structure),如果 Guest 使用这些寄存器就Exit
-
KVM出现后CPU 的虚拟化交给 CPU 硬件(VT-x)做,内存的虚拟化交给 CPU 硬件(EPT)做。KVM只负责在 Host 和 Guest 之间切换状态。
如果CPU会判断是否需要触发vm exit,那么要KVM来做什么?需要理解VM Entry/Exit 的生命周期循环
-
这里有两个角色需要认识
- KVM (软件/内核模块)的角色,决定虚拟机配置,决定在这个时间片虚拟机能够执行什么,当VM Exit时负责模拟结果
- CPU (硬件/VT-x)负责极速切换上下文,按照VMCS切换环境执行指令
-
KVM 提前配置好 VMCS,然后命令"CPU 进入虚拟机模式
-
在让 CPU 运行虚拟机之前,KVM 会通过指令向内存中的 VMCS (Virtual Machine Control Structure) 结构体填入数据
-
KVM 准备好后,执行一条汇编指令
VMLAUNCH(或VMRESUME)。此时 KVM 暂停工作,CPU 硬件接管一切。 CPU 读取 VMCS,瞬间保存 Host 寄存器,加载 Guest 寄存器,切换到 Non-Root 模式,虚拟机运行。 -
虚拟机执行普通加法指令时CPU 直接执行。 虚拟机执行类似写串口时 CPU 硬件警报,CPU 查阅 VMCS 发现这条指令被标记为需拦截
-
硬件自动切换 (VM Exit)
-
CPU 暂停 Guest 执行。
-
CPU 把 Guest 当前的寄存器状态、指令指针(停在哪一行)自动保存进 VMCS。
-
CPU 读取 VMCS 里的"Exit Reason"(退出原因),写上:
EXIT_REASON_IO_INSTRUCTION。 -
CPU 加载 Host 的寄存器状态,切换回 Root 模式。
-
CPU 将控制权交还给 KVM 代码(即刚才
VMLAUNCH指令的下一行)
-
-
KVM 读取 VMCS 里的 Exit Reason,发现是"写串口"。KVM(或者交给 QEMU/Firecracker)在软件层面模拟这个操作。比如把字符打印到宿主机的文件里。
-
KVM 修改 VMCS 中的 Guest RIP(指令指针)(假装刚才那条指令执行成功了)。KVM 再次执行
VMRESUME,回到VM Entry。再次KVM 暂停工作,CPU 硬件接管一切。CPU 读取 VMCS,瞬间保存 Host 寄存器,加载 Guest 寄存器,切换到 Non-Root 模式 -
从架构设计的角度来看,Hypervisor (KVM + Firecracker/QEMU) 对于 Guest OS 的角色,几乎完全等同于 Kernel 对于应用程序(User App)的角色
以发送网络包为例,如果KVM负责真正的工作,这个动作是通过宿主机的内核协议栈完成的吗,客户机的的内核如何工作和感知到这个动作呢?
- 如果每次发包都要触发 VM Exit(Guest -> Host)并进行完整寄存器模拟,性能会非常差。 Virtio 的核心思想是:宿主机和客户机商量好一块共享内存(Shared Memory),大家直接往里面填数据,减少上下文切换。这块共享内存区域被称为 Virtqueue (虚拟队列)
- 当发送网络请求时,Guest 内核的TCP/IP 协议栈处理数据,封装成以太网帧。Guest 网卡驱动 (virtio-net)将数据包的内存地址,填入 Virtqueue (共享内存环形缓冲区) 的"可用环"这一步是纯内存操作,不会触发 VM Exit。
- Guest 驱动执行一条特殊的 I/O 指令(如
PIO写特定端口,或MMIO写特定内存地址)。CPU 捕获到这个敏感指令,触发 VM Exit。CPU 暂停 Guest,切换回 Host (KVM)。 - KVM (Kernel)看到 Exit Reason 是"I/O 写",识别出这是属于 virtio-net 设备的通知。KVM 通过
ioeventfd机制唤醒在用户态睡眠的 Firecracker 进程。 - Firecracker (User Space)被唤醒后,去读取 Virtqueue (共享内存),看到了 Guest 刚才填入的数据包地址。Firecracker 宿主机上打开了一个特殊的字符设备文件,叫做 TAP 设备(例如
/dev/tap0)。Firecracker 调用宿主机的write()系统调用,把从共享内存里拿到的数据,写入这个 TAP 文件。 - Host 内核的TAP 驱动收到数据,会把这串数据伪装成从一根网线接收到的以太网帧。这个帧进入宿主机的网络协议栈(Network Stack)。宿主机内核根据路由表、iptables/nftables 规则、网桥配置(Bridge)进行处理。最后通过宿主机的物理网卡 (NIC) 发送出去。
- Firecracker 完成
write()操作后,知道包已经交给宿主机内核了。Firecracker通知 KVM给那个虚拟机发中断。KVM 设置 VMCS 中的中断注入字段。下次 CPU 进入虚拟机时,硬件会自动跳转到 Guest OS 的中断处理函数。Guest 驱动收到中断,读取 Virtqueue 的Used Ring,回收内存。
vm进程和host中的Firecracker进程指的是一个同进程吗?Firecracker 进程其实一直在两个身份之间极其快速地来回切换。
- 当 VM Exit 发生前Firecracker进程在运行虚拟机的 Linux Guest Kernel。
- 当 VM Exit 发生时,CPU 从 Guest OS 跳回了 Host OS,回到了 Firecracker 进程的代码空间。变为一个普通的、正在执行 Rust 代码的 Linux 进程
- 在这个过程中发生了4次CPU 特权级或运行模式的变更,但是这4 次切换自始至终都是在同一个 Firecracker 线程上下文中发生的
对比QEMU和Firecracker的区别?
- QEMU模拟各种硬件,而Firecracker只支持 Virtio但是速度快
- 例如磁盘模拟,Virtio让虚拟机以为自己有一块独立的硬盘,但实际上只是在宿主机上读写一个普通的文件。QEMU (全模拟 IDE/SATA 模式)会努力模拟一个真实的硬盘控制器(比如 Intel PIIX3 IDE 控制器)。它会模拟寄存器状态、模拟中断行为,甚至有些模拟器还会模拟磁盘旋转的延迟。Firecracker (Virtio 模式)Guest 直接把数据给它直接写文件。
| 特性 | Firecracker | QEMU |
|---|---|---|
| 本质 | 用户态进程 (Rust) | 用户态进程 (C语言) |
| CPU 虚拟化 | 必须依赖 KVM (硬件加速) | KVM (首选) 或 TCG (纯软件模拟) |
| 设备模型 | 仅支持 Virtio (网络/磁盘/键盘) | 模拟真实硬件 (E1000网卡, USB, 显卡, 声卡) + Virtio |
| 主板模拟 | 无 (MicroVM) | 完整 (i440fx / Q35 / ACPI) |
| 启动方式 | 直接跳转 Kernel | 完整的 BIOS -> Bootloader -> Kernel 流程 |
| 典型用途 | Lambda/Serverless, 容器隔离 | 运行 Windows, 传统 VPS, 跨架构模拟 |
EC2实例启动Firecracker虚拟机
启动metal实例,检查kvm设备
ls -l /dev/kvm获取二进制文件
shell
wget https://github.com/firecracker-microvm/firecracker/releases/download/v1.14.1/firecracker-v1.14.1-x86_64.tgz
tar -xzvf firecracker-v1.14.1-x86_64.tgz
mv firecracker-v1.14.1-x86_64 firecracker
chmod +x firecracker
sudo mv firecracker /usr/local/bin/准备 Kernel 和 RootFS,Firecracker需要一个未压缩的 Linux 内核 (vmlinux) 和一个根文件系统 (rootfs)
- vmlinux.bin内核在编译时剔除了所有不必要的驱动(没有 USB、没有显卡、没有蓝牙、没有复杂的电源管理),必须开启 Virtio 相关的驱动(
VIRTIO_NET,VIRTIO_BLK)。 - bionic.rootfs.ext4内部是单纯的磁盘镜像文件Ubuntu 18.04 (代号 Bionic) 的用户态文件。
shell
ARCH="$(uname -m)"
wget https://s3.amazonaws.com/spec.ccfc.min/img/quickstart_guide/${ARCH}/kernels/vmlinux.bin
wget https://s3.amazonaws.com/spec.ccfc.min/img/quickstart_guide/${ARCH}/rootfs/bionic.rootfs.ext4启动 Firecracker 进程,Firecracker 启动后是一个运行在后台的进程,它监听一个 Unix Socket 等待指令
shell
$ rm -f /tmp/Firecracker.socket
$ firecracker --api-sock /tmp/Firecracker.socket
2026-01-24T12:08:42.663881877 [anonymous-instance:main] Running Firecracker v1.14.1
2026-01-24T12:08:42.664033537 [anonymous-instance:main] Listening on API socket ("/tmp/Firecracker.socket").
2026-01-24T12:08:42.664338924 [anonymous-instance:fc_api] API server started.在另一个shell中配置并启动MicroVM,设置内核和rootfs
shell
curl --unix-socket /tmp/Firecracker.socket -i \
-X PUT 'http://localhost/boot-source' \
-H 'Accept: application/json' \
-H 'Content-Type: application/json' \
-d "{
\"kernel_image_path\": \"vmlinux.bin\",
\"boot_args\": \"console=ttyS0 reboot=k panic=1 pci=off\"
}"
curl --unix-socket /tmp/Firecracker.socket -i \
-X PUT 'http://localhost/drives/rootfs' \
-H 'Accept: application/json' \
-H 'Content-Type: application/json' \
-d "{
\"drive_id\": \"rootfs\",
\"path_on_host\": \"bionic.rootfs.ext4\",
\"is_root_device\": true,
\"is_read_only\": false
}"启动虚拟机
shell
curl --unix-socket /tmp/Firecracker.socket -i \
-X PUT 'http://localhost/actions' \
-H 'Accept: application/json' \
-H 'Content-Type: application/json' \
-d "{
\"action_type\": \"InstanceStart\"
}"启动完毕
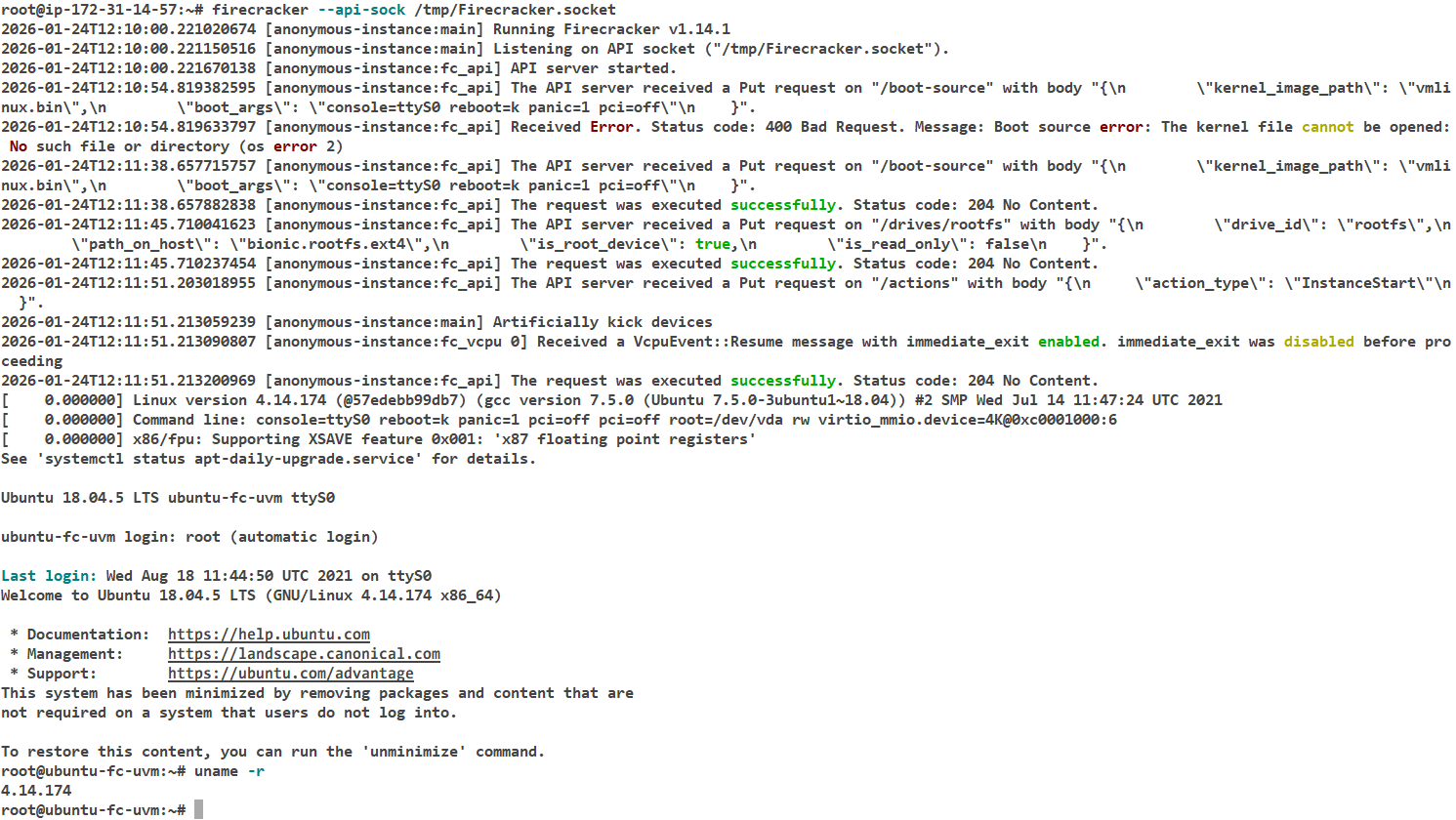
关闭虚拟机
shell
curl --unix-socket /tmp/firecracker.socket -i \
-X PUT 'http://localhost/actions' \
-H 'Accept: application/json' \
-H 'Content-Type: application/json' \
-d '{ "action_type": "SendCtrlAltDel" }'自定义Firecracker内核和rootfs
如何定制内核?
- 下载 Linux Kernel 源码
- 下载 Firecracker 官方提供的 MicroVM Kernel Config
- 编译:
make vmlinux
shell
wget https://mirrors.aliyun.com/linux-kernel/v6.x/linux-6.1.13.tar.xz
tar -xf linux-6.1.13.tar.xz
# https://github.com/firecracker-microvm/firecracker/blob/main/resources/guest_configs/microvm-kernel-ci-x86_64-6.1.config
mv microvm-kernel-ci-x86_64-6.1.config .config
apt update && apt install -y gcc make libssl-dev bc flex bison libelf-dev pkg-config
make -j$(nproc) vmlinux那么如何获取Rootfs?把 Docker 镜像转化为 ext4 文件
shell
dd if=/dev/zero of=rootfs.ext4 bs=1M count=500
mkfs.ext4 rootfs.ext4
mkdir /tmp/my-rootfs
sudo mount rootfs.ext4 /tmp/my-rootfs
docker run -d --name firecracker-rootfs public.ecr.aws/docker/library/alpine:latest tail -f /dev/null
docker exec firecracker-rootfs apk add --no-cache openrc util-linux
docker export firecracker-rootfs | sudo tar -xf - -C /tmp/my-rootfs
docker rm -f firecracker-rootfs
# 配置串口登录
sudo sh -c 'echo "ttyS0::respawn:/sbin/getty -L ttyS0 115200 vt100" >> /tmp/my-rootfs/etc/inittab'
# 配置 DNS
sudo sh -c 'echo "nameserver 8.8.8.8" > /tmp/my-rootfs/etc/resolv.conf'
sudo umount /tmp/my-rootfs启动vm
shell
curl --unix-socket /tmp/firecracker.socket -i \
-X PUT 'http://localhost/boot-source' \
-d "{
\"kernel_image_path\": \"/root/kernal6.1.13/vmlinux\",
\"boot_args\": \"console=ttyS0 reboot=k panic=1 pci=off root=/dev/vda rw init=/sbin/init random.trust_cpu=on\"
}"
curl --unix-socket /tmp/firecracker.socket -i \
-X PUT 'http://localhost/drives/rootfs' \
-d "{
\"drive_id\": \"rootfs\",
\"path_on_host\": \"/root/kernal6.1.13/rootfs.ext4\",
\"is_root_device\": true,
\"is_read_only\": false
}"
curl --unix-socket /tmp/firecracker.socket -i \
-X PUT 'http://localhost/actions' \
-d "{ \"action_type\": \"InstanceStart\" }"一直报错找不到设备。unknown-block(0,0) :这意味着内核试图挂载文件系统,但找不到你指定的设备(root=/dev/vda)。here are the available partitions: 为空:这证明内核在启动时,完全没有检测到任何硬盘。
shell
[ 0.126580] VFS: Cannot open root device "vda" or unknown-block(0,0): error -6
[ 0.127120] Please append a correct "root=" boot option; here are the available partitions:
[ 0.127769] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)
[ 0.128379] CPU: 0 PID: 1 Comm: swapper/0 Not tainted 6.1.13 #4检查发现编译配置开启了ACPI 。Firecracker 在 x86_64 下通常不提供完整的 ACPI 表(除非使用特定的引导加载程序流程,但你使用的是直连 vmlinux)。当内核开启 ACPI 支持时,它会优先尝试通过 ACPI 表来枚举硬件设备。当它找不到预期的 ACPI 信息时,往往会放弃后续的设备扫描,或者与 virtio_mmio 的命令行参数发现机制发生冲突。关闭ACPI,重新编译
./scripts/config --file .config --disable ACPI启动成功,忘记设置密码了,修改如下
sudo mount rootfs.ext4 /tmp/my-rootfs
sudo chroot /tmp/my-rootfs /bin/sh
passwd
exit
sudo umount /tmp/my-rootfs登录成功,查看磁盘大小
~# df -h
Filesystem Size Used Available Use% Mounted on
/dev/root 452.0M 16.7M 400.2M 4% /
devtmpfs 51.2M 0 51.2M 0% /dev
tmpfs 21.4M 12.0K 21.4M 0% /run
配置网络,在宿主机执行
-
tap0的作用是充当 VM 和宿主机之间的虚拟网线插口 -
VM 内部的 Alpine 认为
eth0是真正的网卡,于是它把数据封装成以太网帧(比如发给网关 MAC 地址) -
Firecracker 进程截获了 VM 发出的这些帧,通过文件描述符(tap0)把数据直接写入宿主机的
/dev/net/tun文件。 -
宿主机内核内核看到数据从
tap0出来,就像看到一张物理网卡收到了数据一样。因为配置了iptablesNAT,宿主机把这个包的源 IP 改成宿主机的 IP,发给路由器。
shell
# 1. 创建 tap0 设备
sudo ip tuntap add dev tap0 mode tap
sudo ip addr add 172.16.0.1/24 dev tap0
sudo ip link set tap0 up
# 2. 开启内核转发
sudo sh -c "echo 1 > /proc/sys/net/ipv4/ip_forward"
# 3. 配置 IPTables NAT (让 VM 能够伪装宿主机 IP 上网)
HOST_IFACE=$(ip route show default | awk '/default/ {print $5}')
echo "Using host interface: $HOST_IFACE"
sudo iptables -t nat -A POSTROUTING -o $HOST_IFACE -j MASQUERADE
sudo iptables -A FORWARD -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
sudo iptables -A FORWARD -i tap0 -o $HOST_IFACE -j ACCEPT在指定kernel和rootfs之后,执行为vm添加网络配置。随后启动vm
shell
curl --unix-socket /tmp/firecracker.socket -i \
-X PUT 'http://localhost/network-interfaces/eth0' \
-d "{
\"iface_id\": \"eth0\",
\"guest_mac\": \"AA:FC:00:00:00:01\",
\"host_dev_name\": \"tap0\"
}"guest os中执行如下命令配置网络
shell
# 赋予 IP (跟宿主机 tap0 在同网段)
ip addr add 172.16.0.2/24 dev eth0
ip link set eth0 up
ip route add default via 172.16.0.1随后测试连接成功
(none):~# ping bing.com
PING bing.com (150.171.27.10): 56 data bytes
64 bytes from 150.171.27.10: seq=0 ttl=96 time=81.811 ms或者可以通过如下配置启动,命令为firecracker --api-sock /tmp/firecracker.socket --config-file config.json
shell
{
"boot-source": {
"kernel_image_path": "/root/kernal6.1.13/vmlinux",
"boot_args": "console=ttyS0 reboot=k panic=1 root=/dev/vda"
},
"drives": [
{
"drive_id": "rootfs",
"path_on_host": "/root/kernal6.1.13/rootfs.ext4",
"is_root_device": true,
"is_read_only": false
}
],
"machine-config": {
"vcpu_count": 2,
"mem_size_mib": 512
}
}kata使用Firecracker后端一些问题
基于 EBS 的 Loop 设备配置 (EBS-based)的场景下,需要使用标准的 EBS 作为后端存储。通过在 Linux 系统中创建一个大文件并将其映射为 Loop 设备,进而构建 Device Mapper Thin Pool 供 Kata Containers 使用。
那么为什么kata需要底层存储呢?
- 在普通的 Docker 或 Kubernetes 容器中,通常通常直接使用宿主机的 OverlayFS 文件系统。而在Kata Containers + Firecracker的场景下,必须配置专门的底层存储(如 Device Mapper Thin Pool),因为每一个 Pod 实际上都是MicroVM,无法像普通进程那样直接、高效地读取宿主机的文件目录。
- Loop设备是Linux内核提供的一种虚拟块设备,它可以将普通文件映射为块设备
- 为了让虚拟机能启动并运行容器镜像,需要使用devmapper把容器镜像文件伪装成一块虚拟硬盘(块设备,Block Device)插给虚拟机。
- Thin Pool允许多个虚拟机共享同一份基础数据(只读的 Base Image),当某个 Agent 需要写数据时只会为它分配那一小块新产生的空间。即只占用实际存储数据所需的空间,而不是预先分配的空间。
kata vm启动不需要内核吗,为什么只需要配置镜像就可以?
-
Docker 容器镜像里面只有用户空间的文件。启动时直接借用宿主机(物理机)的内核来运行这些程序。而启动Kata 容器时,Kata 会从宿主机的特定目录加载一个预先编译好的、极度精简的 Linux 内核。把你的容器镜像(通过 Thin Pool 变成的块设备)挂载给上面那个内核,作为它的 根文件系统 (Rootfs)。这个 Guest Kernel 是特制的,它裁掉了 USB、蓝牙、声卡等驱动
-
当 Kubernetes 通知 Kata 启动一个容器时,Kata 的组件(
containerd-shim-kata-v2)会去读取自己的配置文件(通常在/etc/kata-containers/configuration.toml),找到默认的内核路径/usr/share/kata-containers/vmlinux.container。 -
Kata 启动 Firecracker 进程,并通过 Unix Socket 接口通知Firecracker 。
-
Firecracker 收到 Kata 的指令(通过 HTTP over Unix Socket 的
/boot-source接口)后将内核文件的二进制代码,直接映射(mmap)或者是拷贝到属于这个虚拟机的内存空间里(Guest Memory),并设置好虚拟 CPU 的寄存器(Instruction Pointer),指向内核代码的入口点。 -
Firecracker 没有BIOS和GRUB,自己做完了Bootloader 的工作并进入内核代码。
EKS集群的环境配置步骤
测试环境为EKS1.33和al2023优化AMI,磁盘大小100GB
创建loop设备和Thin Pool
shell
# 安装工具
dnf install -y bc device-mapper lvm2
# 创建目录
mkdir -p /var/lib/containerd/io.containerd.snapshotter.v1.devmapper
cd /var/lib/containerd/io.containerd.snapshotter.v1.devmapper
# 创建小容量稀疏文件
touch data meta
truncate -s 75G data
truncate -s 5G meta
# 挂载 Loop 设备
DATA_DEV=$(losetup --find --show data)
META_DEV=$(losetup --find --show meta)
# 创建 Thin Pool
SECTOR_SIZE=512
DATA_SIZE="$(blockdev --getsize64 -q ${DATA_DEV})"
LENGTH=$(bc <<< "${DATA_SIZE}/${SECTOR_SIZE}")
# 创建名为 'devpool' 的池
dmsetup create devpool --table "0 ${LENGTH} thin-pool ${META_DEV} ${DATA_DEV} 128 32768"
# 验证
dmsetup ls(恢复)使用如下命令删掉节点中存储设备并释放空间
shell
dmsetup remove devpool
losetup -d /dev/loopX
losetup -d /dev/loopY
rm /var/lib/containerd/io.containerd.snapshotter.v1.devmapper/data
rm /var/lib/containerd/io.containerd.snapshotter.v1.devmapper/meta配置containerd的devmapper插件
shell
cp /etc/containerd/config.toml /etc/containerd/config.toml.bak
cat >> /etc/containerd/config.toml << 'EOF'
[plugins."io.containerd.snapshotter.v1.devmapper"]
pool_name = "devpool"
root_path = "/var/lib/containerd/io.containerd.snapshotter.v1.devmapper"
base_image_size = "30GB"
discard_blocks = true
EOF
systemctl restart containerd
ctr plugins ls | grep devmapper
# io.containerd.snapshotter.v1 devmapper linux/amd64 ok安装kata运行时
shell
export VERSION=$(curl -sSL https://api.github.com/repos/kata-containers/kata-containers/releases/latest | jq .tag_name | tr -d '"')
export CHART="oci://ghcr.io/kata-containers/kata-deploy-charts/kata-deploy"
helm install kata-deploy "${CHART}" --version "${VERSION}"kata-deploy具体做了什么?
-
把运行 Kata 容器所需的所有核心组件(已经被打包在
kata-deploy的镜像里),复制到宿主机的/opt/kata/目录下,包括-
Hypervisor,Firecracker
-
Guest Kernel,虚拟机启动时用的 Linux 内核文件(vmlinux)
-
Rootfs 镜像虚拟机启动时的微型系统盘(initrd/image)
-
Containerd Shim,containerd-shim-kata-v2`,这是 containerd 和 Kata 虚拟机之间的通信接口
shell# cd /opt/kata/ # tree -L 3 . ├── VERSION ├── bin │ ├── cloud-hypervisor │ ├── containerd-shim-kata-v2 │ ├── Firecracker │ ├── jailer │ ├── kata-collect-data.sh │ ├── kata-monitor │ ├── kata-runtime │ ├── qemu-system-x86_64 │ ├── qemu-system-x86_64-snp-experimental │ └── qemu-system-x86_64-tdx-experimental ├── containerd │ └── config.d │ └── kata-deploy.toml ├── include │ ├── fdt.h │ ├── libfdt.h │ └── libfdt_env.h ├── lib │ ├── kata-qemu │ │ ├── libfdt.a │ │ └── pkgconfig │ ├── kata-qemu-snp-experimental │ │ ├── libfdt.a │ │ └── pkgconfig │ └── kata-qemu-tdx-experimental │ ├── libfdt.a │ └── pkgconfig ├── libexec │ ├── nydusd │ └── virtiofsd ├── runtime-rs │ └── bin │ └── containerd-shim-kata-v2 ├── share │ ├── bash-completion │ │ └── completions │ ├── defaults │ │ └── kata-containers │ ├── kata-containers │ │ ├── config-6.12.47-176-dragonball-experimental │ │ ├── config-6.18.5-176 │ │ ├── config-6.18.5-176-confidential │ │ ├── config-6.18.5-176-nvidia-gpu │ │ ├── config-6.18.5-176-nvidia-gpu-confidential │ │ ├── kata-alpine-3.22.initrd │ │ ├── kata-cbl-mariner-3.0-mariner.image │ │ ├── kata-containers-confidential.img -> kata-ubuntu-noble-confidential.image │ │ ├── kata-containers-initrd-confidential.img -> kata-ubuntu-noble-confidential.initrd │ │ ├── kata-containers-initrd-nvidia-gpu-confidential.img -> kata-ubuntu-noble-nvidia-gpu-confidential-590.48.01.initrd │ │ ├── kata-containers-initrd-nvidia-gpu.img -> kata-ubuntu-noble-nvidia-gpu-590.48.01.initrd │ │ ├── kata-containers-initrd.img -> kata-alpine-3.22.initrd │ │ ├── kata-containers-mariner.img -> kata-cbl-mariner-3.0-mariner.image │ │ ├── kata-containers-nvidia-gpu-confidential.img -> kata-ubuntu-noble-nvidia-gpu-confidential-590.48.01.image │ │ ├── kata-containers-nvidia-gpu.img -> kata-ubuntu-noble-nvidia-gpu-590.48.01.image │ │ ├── kata-containers.img -> kata-ubuntu-noble.image │ │ ├── kata-ubuntu-noble-confidential.image │ │ ├── kata-ubuntu-noble-confidential.initrd │ │ ├── kata-ubuntu-noble-nvidia-gpu-590.48.01.image │ │ ├── kata-ubuntu-noble-nvidia-gpu-590.48.01.initrd │ │ ├── kata-ubuntu-noble-nvidia-gpu-confidential-590.48.01.image │ │ ├── kata-ubuntu-noble-nvidia-gpu-confidential-590.48.01.initrd │ │ ├── kata-ubuntu-noble.image │ │ ├── root_hash.txt │ │ ├── vmlinux-6.12.47-176-dragonball-experimental │ │ ├── vmlinux-6.18.5-176 │ │ ├── vmlinux-6.18.5-176-confidential │ │ ├── vmlinux-6.18.5-176-nvidia-gpu │ │ ├── vmlinux-6.18.5-176-nvidia-gpu-confidential │ │ ├── vmlinux-confidential.container -> vmlinux-6.18.5-176-confidential │ │ ├── vmlinux-dragonball-experimental.container -> vmlinux-6.12.47-176-dragonball-experimental │ │ ├── vmlinux-nvidia-gpu-confidential.container -> vmlinux-6.18.5-176-nvidia-gpu-confidential │ │ ├── vmlinux-nvidia-gpu.container -> vmlinux-6.18.5-176-nvidia-gpu │ │ ├── vmlinux.container -> vmlinux-6.18.5-176 │ │ ├── vmlinuz-6.12.47-176-dragonball-experimental │ │ ├── vmlinuz-6.18.5-176 │ │ ├── vmlinuz-6.18.5-176-confidential │ │ ├── vmlinuz-6.18.5-176-nvidia-gpu │ │ ├── vmlinuz-6.18.5-176-nvidia-gpu-confidential │ │ ├── vmlinuz-confidential.container -> vmlinuz-6.18.5-176-confidential │ │ ├── vmlinuz-dragonball-experimental.container -> vmlinuz-6.12.47-176-dragonball-experimental │ │ ├── vmlinuz-nvidia-gpu-confidential.container -> vmlinuz-6.18.5-176-nvidia-gpu-confidential │ │ ├── vmlinuz-nvidia-gpu.container -> vmlinuz-6.18.5-176-nvidia-gpu │ │ └── vmlinuz.container -> vmlinuz-6.18.5-176 │ ├── kata-qemu │ │ └── qemu │ ├── kata-qemu-snp-experimental │ │ └── qemu │ ├── kata-qemu-tdx-experimental │ │ └── qemu │ └── ovmf │ ├── AMDSEV.fd │ ├── OVMF.fd │ └── OVMF.inteltdx.fd └── versions.yaml -
-
读取宿主机的
/etc/containerd/config.toml,并往里面注入 Kata 的配置。只管注入 Runtime,不影响 Devmapper 存储配置。例如toml[plugins."io.containerd.grpc.v1.cri".containerd.runtimes] [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.kata-fc] runtime_type = "io.containerd.kata.v2" # 这里会指向 Firecracker 的具体配置文件 options = { ConfigPath = "/opt/kata/share/defaults/kata-containers/configuration-fc.toml" } -
向 Kubernetes API Server 注册RuntimeClass,结果如下

-
给Node 打上一个标签
katacontainers.io/kata-runtime=true
kata-deploy运行日志如下
shell
Action:
install
Environment variables passed to this script
NODE_NAME: ip-192-168-6-172.cn-north-1.compute.internal
DEBUG: false
SHIMS_X86_64: clh cloud-hypervisor dragonball fc qemu qemu-coco-dev qemu-coco-dev-runtime-rs qemu-nvidia-gpu qemu-nvidia-gpu-snp qemu-nvidia-gpu-tdx qemu-runtime-rs qemu-snp qemu-tdx
SHIMS_AARCH64: clh cloud-hypervisor dragonball fc qemu qemu-cca qemu-nvidia-gpu
SHIMS_S390X: qemu qemu-coco-dev qemu-coco-dev-runtime-rs qemu-runtime-rs qemu-se qemu-se-runtime-rs
SHIMS_PPC64LE: qemu
DEFAULT_SHIM_X86_64: qemu
DEFAULT_SHIM_AARCH64: qemu
DEFAULT_SHIM_S390X: qemu
DEFAULT_SHIM_PPC64LE: qemu
ALLOWED_HYPERVISOR_ANNOTATIONS_X86_64:
ALLOWED_HYPERVISOR_ANNOTATIONS_AARCH64:
ALLOWED_HYPERVISOR_ANNOTATIONS_S390X:
ALLOWED_HYPERVISOR_ANNOTATIONS_PPC64LE:
SNAPSHOTTER_HANDLER_MAPPING_X86_64: fc:devmapper,qemu-coco-dev:nydus,qemu-coco-dev-runtime-rs:nydus,qemu-snp:nydus,qemu-tdx:nydus
SNAPSHOTTER_HANDLER_MAPPING_AARCH64: fc:devmapper,qemu-cca:nydus
SNAPSHOTTER_HANDLER_MAPPING_S390X: qemu-coco-dev:nydus,qemu-coco-dev-runtime-rs:nydus,qemu-se:nydus,qemu-se-runtime-rs:nydus
SNAPSHOTTER_HANDLER_MAPPING_PPC64LE:
AGENT_HTTPS_PROXY:
AGENT_NO_PROXY:
PULL_TYPE_MAPPING_X86_64: qemu-coco-dev:guest-pull,qemu-coco-dev-runtime-rs:guest-pull,qemu-nvidia-gpu-snp:guest-pull,qemu-nvidia-gpu-tdx:guest-pull,qemu-snp:guest-pull,qemu-tdx:guest-pull
PULL_TYPE_MAPPING_AARCH64: qemu-cca:guest-pull
PULL_TYPE_MAPPING_S390X: qemu-coco-dev:guest-pull,qemu-coco-dev-runtime-rs:guest-pull,qemu-se:guest-pull,qemu-se-runtime-rs:guest-pull
PULL_TYPE_MAPPING_PPC64LE:
INSTALLATION_PREFIX:
MULTI_INSTALL_SUFFIX:
HELM_POST_DELETE_HOOK: false
EXPERIMENTAL_SETUP_SNAPSHOTTER:
EXPERIMENTAL_FORCE_GUEST_PULL_X86_64: qemu-nvidia-gpu-snp,qemu-nvidia-gpu-tdx
EXPERIMENTAL_FORCE_GUEST_PULL_AARCH64:
EXPERIMENTAL_FORCE_GUEST_PULL_S390X:
EXPERIMENTAL_FORCE_GUEST_PULL_PPC64LE:
Validating the snapshotter-handler mapping: "fc:devmapper,qemu-coco-dev:nydus,qemu-coco-dev-runtime-rs:nydus,qemu-snp:nydus,qemu-tdx:nydus"
Using containerd drop-in files: true
copying kata artifacts onto host
WARN: Distro amzn 2023 does not support TDX and the TDX related runtime classes will not work in your cluster!
WARN: Distro amzn 2023 does not support TDX and the TDX related runtime classes will not work in your cluster!
Add Kata Containers as a supported runtime for containerd
node/ip-192-168-6-172.cn-north-1.compute.internal labeled在节点上检查一下containerd的配置文件,引入了/opt/kata/containerd/config.d/kata-deploy.toml
toml
# cat /etc/containerd/config.toml
version = 3
root = "/var/lib/containerd"
state = "/run/containerd"
imports = ["/opt/kata/containerd/config.d/kata-deploy.toml"]部署使用kata运行时的负载
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-deployment
spec:
replicas: 1
selector:
matchLabels:
app: redis
template:
metadata:
labels:
app: redis
spec:
runtimeClassName: kata-fc
containers:
- name: redis-container
image: public.ecr.aws/docker/library/redis:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 6379当调度到非预期实例时候的报错
shell
Warning FailedCreatePodSandBox 41s kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed to start sandbox "9afc683fd428c1ec0fb688835ae52d819b73abcc65cff897802124014ba4ea93": failed to
create containerd task: failed to create shim task: Failed to connect to Firecrackerinstance (timeout 10s)调度到metal节点报错,表明之前使用overlayfs 下载过镜像,后来配置了 devmapper,挂载了新的存储池,切换到 devmapper 或者重建 thin-pool 时,底层的数据找不到了
Warning Failed 40s (x53 over 15m) kubelet Error: failed to create containerd container: error unpacking image: apply layer error for "public.ecr.aws/docker/library/redis:latest": failed to extract layer sha
256:e0e6002570470d87b99366522e2deadfd07fd6abb0c481198c1e336f9117e5a6: failed to get reader from content store: content digest sha256:c02d17997ce3d2c82e082235ea0b5152d06ee659c4e2fabcf1e0079312f1bcde: not found 清理containerd并重启
shell
systemctl stop kubelet
systemctl stop containerd
rm -rf /var/lib/containerd
systemctl start containerd
systemctl start kubelet此后经过手动拉取镜像部署运行正常。那么如何确认pod使用的kata和Firecracker?
shell
# 宿主机内核
# uname -r
6.12.63-84.121.amzn2023.x86_64
# pod内核
# uname -r
6.18.5查看Firecracker进程如下
