学习视频来源:https://www.bilibili.com/video/BV1Vt411X7JF/?p=17
本博客除了包含自己的在学习过程中记录的笔记外,还包含少部分自己扩展的内容,如有错误,敬请指正。
文章目录
- [1. 交易树](#1. 交易树)
- [2. 收据树](#2. 收据树)
- [3. 使用 MPT 的好处:高效查找](#3. 使用 MPT 的好处:高效查找)
- [4. 交易树和收树与状态树一个重要区别](#4. 交易树和收树与状态树一个重要区别)
- [5. 更复杂的查询支持:Bloom Filter](#5. 更复杂的查询支持:Bloom Filter)
-
- [5.1 Bloom Filter 在以太坊中的应用](#5.1 Bloom Filter 在以太坊中的应用)
- [5.2 查询流程](#5.2 查询流程)
- [6. 交易驱动的状态机](#6. 交易驱动的状态机)
- [7 两个关键问题](#7 两个关键问题)
-
- [7.1 问题一](#7.1 问题一)
- [7.2 问题二](#7.2 问题二)
- [8. 源码介绍](#8. 源码介绍)
-
- [8.1 区块头(Block Header)结构](#8.1 区块头(Block Header)结构)
- [8.2 区块体(Block Body)结构](#8.2 区块体(Block Body)结构)
- [8.3 交易树(Transactions Trie)构建过程](#8.3 交易树(Transactions Trie)构建过程)
- [8.4 收据树(Receipts Trie)构建 + Bloom Filter 生成](#8.4 收据树(Receipts Trie)构建 + Bloom Filter 生成)
- [8.5 Bloom Filter 查找过程(轻节点过滤)](#8.5 Bloom Filter 查找过程(轻节点过滤))
- [8.6 完整区块构建流程(汇总)](#8.6 完整区块构建流程(汇总))
- [9 总结:三棵树与 Bloom 的作用](#9 总结:三棵树与 Bloom 的作用)
1. 交易树
与比特币类似,以太坊也需要交易树。 比特币使用的是普通的默克尔树,而以太坊使用的则是 MPT(Merkle Patricia Trie) 。
原因可能只是:状态树本身已经使用了 MPT,为了维护方便,统一使用同一种数据结构,并没有特别高深的理由。
2. 收据树
每笔交易------不管成功或失败 ------都会产生一个收据(receipt) ,所有收据组成一棵收据树 。
收据树与交易树是一一对应的 :第 i 笔交易对应第 i 个收据。
二者都使用 MPT。
3. 使用 MPT 的好处:高效查找
- 对于状态树 ,查找的键(key)是账户地址;
- 对于交易树和收据树 ,查找的键是该交易在区块中的序号(即它排在区块交易列表中的第几个);
- 交易的顺序由发布该区块的矿工节点决定。
4. 交易树和收树与状态树一个重要区别
- 交易树和收据树只涉及当前区块的交易 ,与其他区块完全没有关系;
- 而状态树包含所有账户的全局状态 ,不同区块之间会共享未变化的 MPT 节点;
- 每个区块的交易树和收据树都是完全独立的 ,它们不会与其他区块共享任何节点。
交易树和收据树的主要目的,是为了提供交易内容 和交易执行结果 的默克尔证明(Merkle Proof),供轻节点验证。
5. 更复杂的查询支持:Bloom Filter
以太坊还支持更复杂的查询操作,例如:
- 查找过去 10 天内与某个智能合约相关的所有交易;
- 或筛选符合某种事件日志(event log)类型的交易。
一个比较笨的方法是遍历所有区块逐一扫描 。 但轻节点只有区块头,无法访问完整区块内容,因此无法进行这种扫描。
为此,以太坊引入了 Bloom Filter(布隆过滤器) ------ 一种用于快速判断"某元素是否可能在集合中"的概率性数据结构(大家应该都知道,不详细解释了)。
5.1 Bloom Filter 在以太坊中的应用
- 每笔交易执行完成后生成的收据中,包含一个 Bloom Filter ,记录该交易相关的:
- 合约地址、
- 日志主题(topics)、
- 其他关键信息。
- 每个区块的区块头中也包含一个总的 Bloom Filter ,它是该区块内所有交易收据 Bloom Filter 的并集。
5.2 查询流程
假设你想查找与某合约地址相关的交易:
- 先检查区块头的总 Bloom Filter;
- 如果不包含目标地址 → 该区块肯定没有相关交易,直接跳过;
- 如果包含 → 说明可能存在,需要进一步检查;
- 然后逐个交易收据的 Bloom Filter 进行细筛;
- 最后对候选交易做精确确认。
通过 Bloom Filter,可以快速过滤掉大量无关区块,极大提升查询效率。
6. 交易驱动的状态机
以太坊区块头中保存了三棵 MPT 的根哈希值:
- 状态树(State Trie)根:全局所有账户状态;
- 交易树(Transactions Trie)根:本区块所有交易;
- 收据树(Receipts Trie)根:本区块所有交易收据。
这使得以太坊的运行过程与比特币类似,可看作一个交易驱动的状态机:
- 状态 = 所有账户的状态(balance, nonce, code, storage);
- 输入 = 区块中的交易;
- 状态转移 = 执行交易后更新状态。
比特币的状态是 UTXO 集合,而以太坊的状态是账户状态映射。
状态转移必须是确定性的
- 给定相同的当前状态和交易,所有节点必须确定性地转移到同一个新状态;
- 因为所有矿工/验证者都要执行相同的操作,非确定性会导致共识失败。
7 两个关键问题
7.1 问题一
以太坊上 A 转账给 B,一个节点有没有可能从来没听说过 B 这个地址?
有可能。
- 以太坊创建账户不需要预先注册或通知网络;
- 一个地址只有在首次参与交易(如接收转账、部署合约)时,才会被写入状态树;
- 因此,在 A 向 B 转账前,B 可能从未出现在任何节点的状态树中;
- 此时,执行交易会自动在状态树中插入 B 的新账户(余额从 0 增加)。
7.2 问题二
状态树保存的是所有账户状态,能不能像交易树那样,每个区块只包含与本区块交易相关的账户,让树变小?
不行。
- 如果每个区块只包含部分账户状态,那么没有一个区块包含完整的全局状态;
- 当你想查询某个账户 A 的当前状态时,就必须:
- 从最新区块开始,向前回溯,
- 直到找到最近一个包含 A 账户的区块;
- 如果 A 从未发生过交易(比如刚生成的地址),就要一直回溯到创世区块;
- 这种设计会导致查询代价极高,且无法支持高效的默克尔证明。
因此,以太坊必须维护一个包含所有活跃账户的完整状态树,并在每个区块头中记录其根哈希,以保证状态的全局一致性和可验证性。
8. 源码介绍
我从大模型找些简化版 Go 语言伪代码,比较简单,添加了中文注释,认真看可以看懂主要的逻辑。
以下是以太坊核心数据结构和流程的 简化版 Go 语言伪代码 (基于以太坊官方客户端 Geth 的逻辑),包含:
- 区块头(Block Header)结构
- 区块体(Block Body)结构
- 交易树(Transactions Trie)与收据树(Receipts Trie)的构建过程
- Bloom Filter 的生成与查询逻辑
⚠️ 注意:
- 这不是可直接编译的完整源码,而是教学级简化实现,保留核心逻辑;
- 真实 Geth 代码更复杂(涉及状态缓存、并行处理、RLP 编码等);
- 所有关键步骤已添加 中文注释。
8.1 区块头(Block Header)结构
go
// BlockHeader 表示以太坊区块头
type BlockHeader struct {
ParentHash common.Hash // 父区块哈希
UncleHash common.Hash // 叔块列表的哈希(普通默克尔树根)
Coinbase common.Address // 出块者地址(矿工/验证者)
Root common.Hash // 状态树(State Trie)根哈希 ← 全局账户状态
TxHash common.Hash // 交易树(Transactions Trie)根哈希
ReceiptHash common.Hash // 收据树(Receipts Trie)根哈希
Bloom types.Bloom // 区块级 Bloom Filter(所有交易收据的并集)
Difficulty *big.Int // 难度(PoW 时期使用,PoS 后弃用)
Number *big.Int // 区块高度
GasLimit uint64 // 区块 gas 上限
GasUsed uint64 // 本区块实际消耗 gas
Time uint64 // 时间戳
Extra []byte // 额外数据(如 PoA 签名)
MixDigest common.Hash // PoW 混合摘要(PoS 后无用)
Nonce types.BlockNonce // PoW nonce(PoS 后固定为 0x00...00)
}8.2 区块体(Block Body)结构
go
// BlockBody 表示区块的实际内容(不包含头部)
type BlockBody struct {
Transactions []*types.Transaction // 本区块所有交易列表
Uncles []*BlockHeader // 叔块头列表(最多 2 个)
}8.3 交易树(Transactions Trie)构建过程
go
// BuildTransactionTrie 构建交易树(MPT)
func BuildTransactionTrie(transactions []*types.Transaction) common.Hash {
// 创建一个新的 MPT(空 trie)
trie := trie.New(common.Hash{}, trie.NewDatabase(memorydb.New()))
// 遍历交易列表,按索引(0,1,2,...)作为 key 插入 trie
for i, tx := range transactions {
// 将索引 i 转为字节(作为 key)
key := make([]byte, 8)
binary.BigEndian.PutUint64(key, uint64(i))
// 对交易进行 RLP 编码(value)
value, _ := rlp.EncodeToBytes(tx)
// 插入 MPT:key=index, value=RLP(交易)
trie.Update(key, value)
}
// 返回交易树的根哈希
return trie.Hash()
}key 是交易在区块交易列表中的序号,即第几个交易
8.4 收据树(Receipts Trie)构建 + Bloom Filter 生成
go
// BuildReceiptsTrie 构建收据树,并生成区块级 Bloom Filter
func BuildReceiptsTrie(receipts []*types.Receipt) (common.Hash, types.Bloom) {
trie := trie.New(common.Hash{}, trie.NewDatabase(memorydb.New()))
var blockBloom types.Bloom // 初始化区块级 Bloom Filter(全 0)
for i, receipt := range receipts {
// 1. 将收据 RLP 编码
receiptRlp, _ := rlp.EncodeToBytes(receipt)
// 2. 生成收据的 Bloom Filter(记录日志中的地址和 topics)
receiptBloom := CreateBloomFromReceipt(receipt)
// 3. 将收据 Bloom 并入区块 Bloom(按位 OR)
blockBloom = blockBloom.Or(receiptBloom)
// 4. 插入收据树:key=index, value=RLP(收据)
key := make([]byte, 8)
binary.BigEndian.PutUint64(key, uint64(i))
trie.Update(key, receiptRlp)
}
return trie.Hash(), blockBloom
}
// CreateBloomFromReceipt 从单个交易收据生成 Bloom Filter
func CreateBloomFromReceipt(receipt *types.Receipt) types.Bloom {
bloom := types.Bloom{}
// 遍历收据中的每条日志(Log)
for _, log := range receipt.Logs {
// 将合约地址加入 Bloom
AddToBloom(&bloom, log.Address.Bytes())
// 将每个 topic(事件参数)加入 Bloom
for _, topic := range log.Topics {
AddToBloom(&bloom, topic.Bytes())
}
}
return bloom
}
// AddToBloom 将字节数组加入 Bloom Filter(使用 3 个独立哈希函数)
func AddToBloom(bloom *types.Bloom, data []byte) {
// 以太坊使用: KEC(data), KEC(data || 0x01), KEC(data || 0x02)
h1 := crypto.Keccak256(data)
h2 := crypto.Keccak256(append(data, 0x01))
h3 := crypto.Keccak256(append(data, 0x02))
// 每个哈希取低 3 字节(共 21 位),定位到 Bloom 的 2048 位中的位置
for _, h := range [][]byte{h1, h2, h3} {
bitIndex := binary.LittleEndian.Uint16(h[:2]) % 2048
byteIndex := bitIndex / 8
bitOffset := bitIndex % 8
bloom[byteIndex] |= 1 << (7 - bitOffset) // 设置对应位为 1
}
}8.5 Bloom Filter 查找过程(轻节点过滤)
go
// BloomFilterMatch 检查区块是否可能包含目标地址或 topic
func BloomFilterMatch(blockBloom types.Bloom, target []byte) bool {
// 对目标数据生成 3 个哈希位置
h1 := crypto.Keccak256(target)
h2 := crypto.Keccak256(append(target, 0x01))
h3 := crypto.Keccak256(append(target, 0x02))
// 检查 Bloom 中这 3 个位置是否都为 1
for _, h := range [][]byte{h1, h2, h3} {
bitIndex := binary.LittleEndian.Uint16(h[:2]) % 2048
byteIndex := bitIndex / 8
bitOffset := bitIndex % 8
mask := byte(1 << (7 - bitOffset))
// 如果任意一位为 0,则肯定不存在
if blockBloom[byteIndex]&mask == 0 {
return false
}
}
return true // 可能存在(需进一步验证)
}
// 使用示例:查找与合约 addr 相关的区块
func FindRelevantBlocks(addr common.Address, headers []*BlockHeader) []*BlockHeader {
var matches []*BlockHeader
addrBytes := addr.Bytes()
for _, header := range headers {
if BloomFilterMatch(header.Bloom, addrBytes) {
matches = append(matches, header) // 可能包含,保留
}
// 否则跳过该区块(快速过滤)
}
return matches
}8.6 完整区块构建流程(汇总)
go
// FinalizeBlock 构建完整区块(头部 + 体)
func FinalizeBlock(parent *BlockHeader, txs []*types.Transaction, receipts []*types.Receipt) *Block {
// 1. 构建交易树
txRoot := BuildTransactionTrie(txs)
// 2. 构建收据树 + 区块 Bloom
receiptRoot, blockBloom := BuildReceiptsTrie(receipts)
// 3. 假设状态树根已由状态机计算得出(stateRoot)
stateRoot := ComputeStateRoot() // 实际由 StateProcessor 执行交易后得到
// 4. 构造区块头
header := &BlockHeader{
ParentHash: parent.Hash(),
Root: stateRoot,
TxHash: txRoot,
ReceiptHash: receiptRoot,
Bloom: blockBloom,
Number: new(big.Int).Add(parent.Number, big.NewInt(1)),
Time: uint64(time.Now().Unix()),
// ... 其他字段省略
}
// 5. 构造区块体
body := &BlockBody{
Transactions: txs,
Uncles: []*BlockHeader{}, // 简化:无叔块
}
return &Block{Header: header, Body: body}
}9 总结:三棵树与 Bloom 的作用
这里借用一张图,描述一下它们的数据结构。图片来源:https://cloud.tencent.com/developer/article/1585653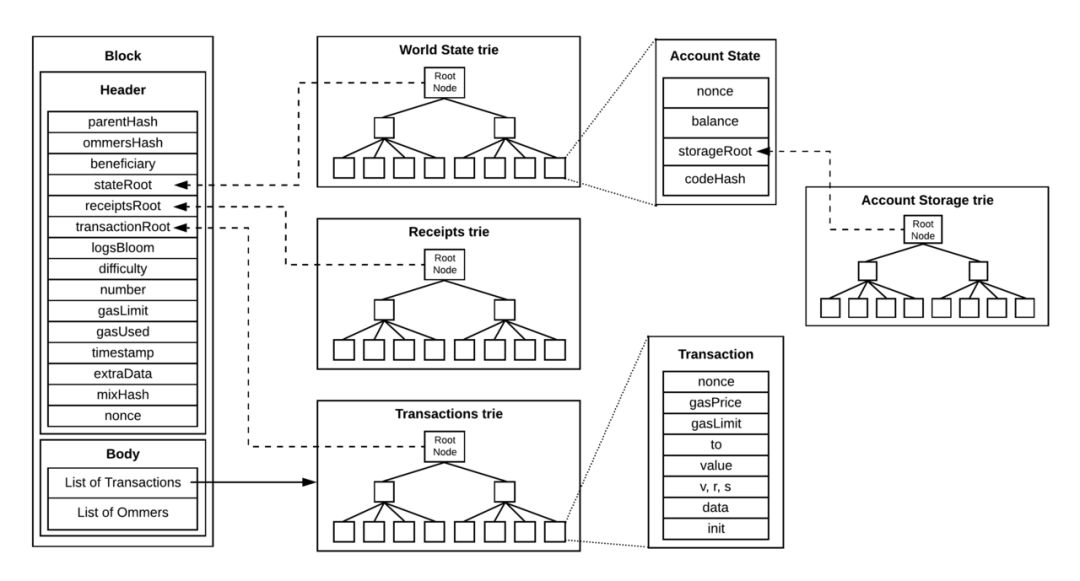
| 结构 | 存储内容 | 是否跨区块共享 | 用途 |
|---|---|---|---|
| 状态树 | 所有账户状态 | ✅ 是(未变节点共享) | 全局状态一致性、账户默克尔证明 |
| 交易树 | 本区块交易 | ❌ 否(每区块独立) | 交易存在性证明 |
| 收据树 | 本区块交易收据 | ❌ 否(每区块独立) | 交易执行结果证明(含日志) |
| Bloom Filter | 日志关键词摘要 | ❌ 否(每区块独立) | 快速过滤无关区块(轻节点友好) |
这些设计共同支撑了以太坊作为可验证、可查询、状态一致的全球状态机的核心能力。