随着时间的推移越来越多的智能音箱正在走进千家万户,智能音箱对答如流的背后,那颗负责"听懂"与"回应"的芯片,才是真正的无名功臣。它不像屏幕或扬声器那样能被直接感知,却决定了每一次交互的流畅与智能。今天,让我一起聚焦一颗能够用在智能音箱AI上的交互芯片WT2606A,看看它为什么可以成为众多智能音箱的智慧核心。

一、WT2606A的应用场景
想象一个日常的场景:你对音箱说"播放周杰伦的歌",几乎在话音落下的瞬间,音乐便流淌而出。这电光火石的反应,并非简单的语音触发,而是一个复杂的本地与云端协同过程。WT2606A这类芯片的关键作用就体现在这个过程的起点------它需要以极低的功耗,7x24小时敏锐地捕捉那个唤醒词,并清晰地拾取随后一连串的指令,哪怕你正身处嘈杂的厨房。这就像一位时刻专注的贴身同声传译,既要听得清,更要听得准。
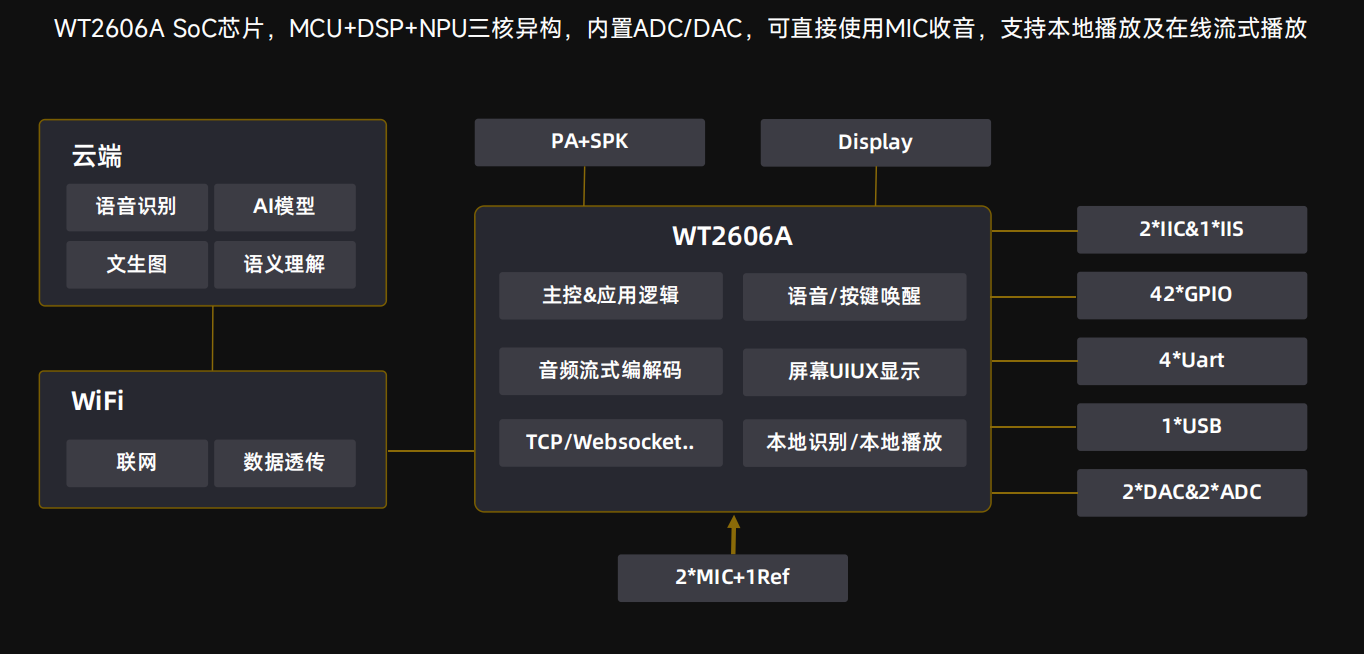
二、MCU和WT2606A怎么通讯
WT2606A采用QNF42脚封装,拥有42个GPIO口,支持IIC和IIS,支持URAT,2*ADC/2*ADC,阵列麦克风VAD降噪,通过TCP/WebSocket进行联网透传,支持WIFI集成蓝牙功能,MCU+DSP+NPU三核异构,内置ADC/DAC,可直接使用MIC收音,支持本地播放及在线流式播放,同时还支持cat.1。
说起WT2606A,它的设计思路相当清晰:为离线与在线融合的语音交互提供一套高度集成的单芯片方案。这意味着,它不仅要具备优秀的音频编解码能力,能处理高质量的语音输入与音频输出,更要内嵌一颗够用的AI处理单元,来驾驭本地的语音识别与唤醒模型。你或许会问,如今云端算力如此强大,为何还要强调本地处理?实际上,这关乎响应速度、用户隐私,以及在网络不稳时的基础体验。WT2606A能让一些简单指令(如"暂停"、"下一首")在设备端瞬间完成,无需等待云端往返,这种"零延迟"的爽快感,恰恰是用户体验的微妙分野。
当然,它的本事不止于"听"。在"说"的环节,WT2606A同样游刃有余。它支持多种高清音频格式解码,确保了智能音箱最终输出的音乐或语音回复,拥有饱满清晰的音质基底。这就好比一位优秀的广播员,不仅理解能力超群,嗓音也醇厚动人。一些制造商看中它的,正是这种音频前后端处理能力的平衡------用一颗芯片,统管了从"耳朵"到"嘴巴"的整个声音链路,让产品设计得以更简洁、更经济。
从市场的眼光来看,选择这样一颗专用芯片,更像是选择了一种务实的产品哲学。它不盲目追逐最顶级的算力参数,而是在功耗、成本、集成度与足够可用的AI性能之间,找到了一个精妙的平衡点。这让许多希望快速推出稳定可靠产品的品牌,找到了一个扎实的支点。毕竟,对大多数用户而言,智能音箱是否真正好用,不在于技术参数的炫技,而在于每一次唤醒都得到即时、准确的回应,在于它安静地融入生活,却总能默契地满足需求。
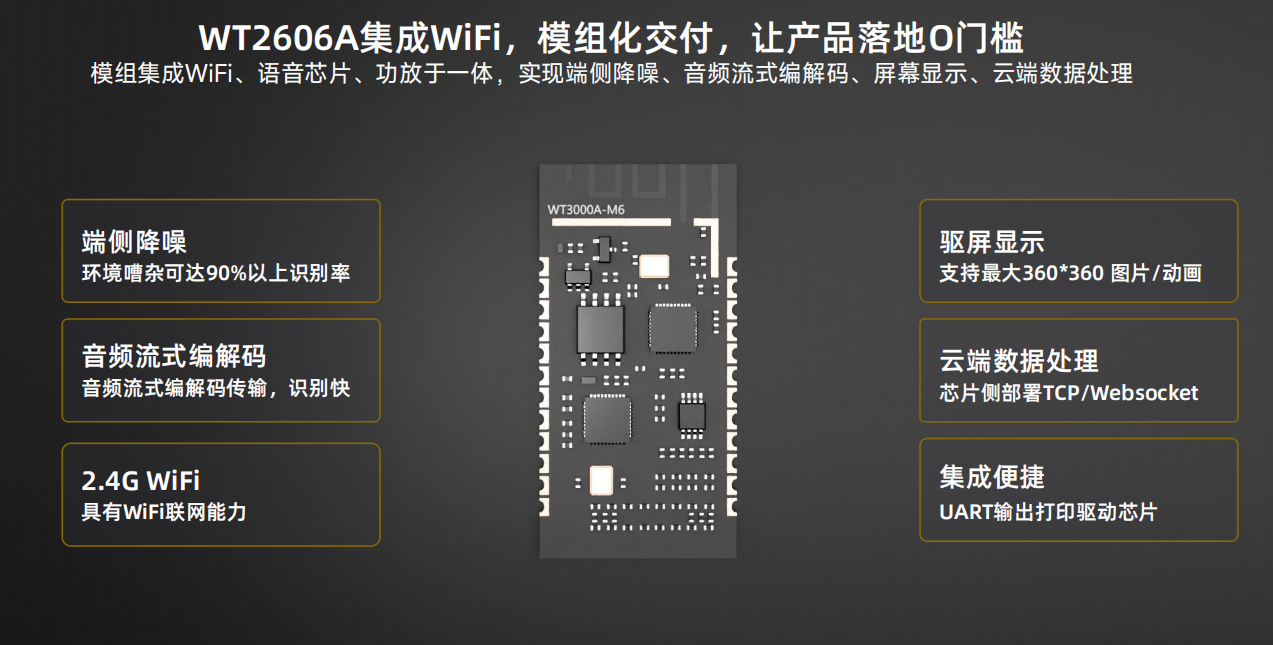
三、WT2606A应用智能音箱上有哪些亮点?
接口丰富,WT2606A采用QNF42脚的封装,有着丰富的GPIO口,同时采用Websocket流式传输,同时支持本地识别和本地播放,音频采用流式解码的方式,响应速度迅速让你几乎感受不到延迟。
四、云端大模型接口开放

WT2606A不仅仅支持市面上的公共大模型比如豆包、kimi等,还支持私有模型接入,给开发开放接入权限。
回过头看,WT2606A这样的芯片之所以能在一众方案中脱颖而出,或许正是因为它精准地锚定了智能音箱的本质:一个以声音为纽带、服务于日常的家庭成员。它的价值,不在于喧宾夺主,而在于如何让技术隐身,让交互本身变得无比自然。当芯片的运算悄然转化为一句恰到好处的回应或一首及时响起的歌曲时,它作为幕后核心的使命,才算真正达成。