前言
这两天一直在思考『七月具身』未来三年的目标,如今已定
- 2026,继续聚焦具身智能的场景落地与二开交付
- 2027,打造行业机器人以软硬一体化交付
- 2028,形成标品,卖软硬一体的解决方案
那未来十年呢
未来十年的目标应该是,为所有机器人造通用具身大脑,让所有机器人都可以自主感知 决策 执行
第一部分 HumanoidPF:Collision-Free Humanoid Traversal in Cluttered Indoor Scenes
1.1 引言与相关工作
1.1.1 引言
如原文所述,当机器人走进家庭场景后,那其需要在卧室、客厅和厨房之间频繁往返,以执行各类家务
- 而机器人面临的一个关键挑战,是在移动过程中避免与周围环境发生碰撞,从而防止对机器人本身或环境造成潜在损害
- 在杂乱的室内场景中,人形机器人可能需要跨越散落在地板上的物体、从低矮障碍物下方俯身通过,或挤过狭窄通道
这就要求机器人能够感知环境,并将具有多样空间布局和几何形态的障碍映射到相应的穿越技能上
尽管在复杂环境中的足式运动已经在四足机器人 1--13和人形机器人 14--24 方面取得了显著进展,现有工作在处理杂乱室内场景中的行走能力方面往往仍然受到限制(全空间障碍物布局以及复杂、逼真的几何形状),如表 I 所示

这些局限性共同表明,在进行碰撞规避时缺乏一种有效的人形体--障碍物关系表征:
- 现有工作 8--13、15、23 通常只在发生碰撞时才获得惩罚信号,导致监督既稀疏又滞后
这迫使强化学习(RL)依赖低效的试错式探索,因此亟需一种能够提供前瞻性且稠密指导的表征 - 传统表征在不考虑人形体--障碍物空间关系的情况下,将策略直接暴露于原始的高维环境测量之中,迫使策略通过隐式的运动学推理来推断通行决策
为弥合这些差距,作者提出了 Humanoid PotentialField(HumanoidPF)这一信息量丰富的表示,用于编码类人机器人与障碍物之间的关系,以实现避碰

受经典人工势场(Artificial Potential Fields, APF)25 的启发,HumanoidPF 将类人机器人如何受其周围环境影响以及应如何响应,++建模为一个连续且可微的梯度场,从而产生指向无碰撞运动方向的"虚拟力++"
如原论文所述,作者以两种互为补充的方式,将 HumanoidPF 无缝集成到穿越技能学习中
-
首先,HumanoidPF 作为策略的观测信号:通过在多个关键身体部位进行查询,它提供方向性线索,指示各个部位应如何运动以避开障碍并向目标推进
这样一来,策略可以直接在穿越决策层面进行推理,而不必从原始的高维视觉输入中间接推断避障行为 -
其次,HumanoidPF 简化了具备碰撞感知的奖励设计。该场在偏好的运动方向上诱导出一个分布,并鼓励策略将自身的运动与这一分布对齐
这为强化学习模型提供了具有前瞻性且足够的监督,同时在无需手动调节奖励的情况下,展现出很强的跨场景泛化能力此外,作者观察到,作为一种感知表征,HumanoidPF 在"从模拟到真实"(sim-to-real)方面呈现出令人惊讶的微小鸿沟
其连续场形式天然地充当低通感知滤波器,平滑掉孤立的感知伪影,从而促进鲁棒的模拟到真实迁移
为了让 HumanoidPF 在多样且具有挑战性的障碍物配置中学习通行与穿越能力,作者提出了一种混合场景生成策略,用于系统性地扩展训练场景的空间
- 具体而言,作者在逼真的三维室内数据集中裁剪得到的子场景基础上,程序化合成高度受限的障碍物进行增强,从而为机器人构造出一系列在现有数据集中极少出现的、高难度杂乱环境"课程"
这使得机器人能够获取丰富的避碰经验,并显著提升其在近碰撞和紧急情形下的鲁棒性 - 作者进一步将所提出的方法具体化为一个实用的远程操作系统,称为 Click-and-Traverse(CAT)
在该系统中,用户只需点击一个目标,就可以指挥仿人机器人安全穿越杂乱的室内环境。在仿真环境和逼真的真实世界室内场景中进行的大量实验验证了 HumanoidPF 的实际适用性,以及在多样化环境中的强泛化能力
1.1.2 相关工作
首先,对于复杂环境中的足式运动
-
足式机器人被期望能够在复杂环境中实现稳定运动,包括具有挑战性的地形和各种障碍物。四足机器人已经在高度具有挑战性的地形上 1--7,以及在狭窄或杂乱空间中 8--13 展示出鲁棒的跑酷能力
仿人机器人同样已经展现出在高度受限环境中导航的能力 14,以及应对高风险地形或障碍物的高级行走技能,例如上下楼梯、行走在平衡木上以及跨越跳石等 15--24
-
然而,现有关于仿人机器人研究的工作往往仅限于具有部分空间布局的障碍物(例如地形 15--22, 24,或悬垂障碍物 14),以及几何形状简单的障碍物(例如矩形块体 14--17, 20--22,或正多面体19, 23)
值得注意的是,尽管 Gallant 23 分别处理了地面、侧向以及头顶障碍物的布局,但并未考虑这些约束同时共存的情形
相比之下,HumanoidPF能够在杂乱的室内场景中运行,在这些场景中,全空间约束与高度复杂的几何形状共同存在。现有工作的对比以及HumanoidPF的方法如表 I 所示

其次,对于用于避障的人工势场法
人工势场 (Artificial Potential Field,APF)25 方法最初于20世纪80年代末提出,它通过生成虚拟力场来引导机械臂或移动机器人的运动以实现避障
受物理类比的启发,其目标位置被建模为一个吸引极,而障碍物则作为具有斥力的表面。传统上,人工势场(APF)已被广泛应用于移动机器人26--28和机器人机械臂29--31的二维路径规划中
然而,仅有少量研究在有限的形式下,将基于模型的四足机器人控制与 APF 结合起来,其做法是将质心32、33或足部关节34、35抽象为单个刚体,这不足以应对类人学习中复杂的规划与控制挑战
相比之下,作者提出 HumanoidPF,这是一种对 APF 的有原则的重新表述,专门为类人技能学习中的信息量丰富的感知与奖励精简而设计
1.2 HumanoidPF的完整方法论
作者研究在杂乱室内场景中无碰撞人形体穿越的问题
给定一个目标位置,以及一组室内障碍物
,人形体需要在不与
发生任何碰撞的情况下移动到
为了解决这一问题,人形体需要将其对周围障碍物的感知映射到相应的穿越技能上。HumanoidPF的方法可以分为两部分
- 首先在第III-A 节介绍的HumanoidPF 如何编码人形体与障碍物之间的关系,以促进人形体穿越学习
且将在第III-B节中进一步介绍如何利用作者提出的混合场景生成方法 - 为了在真实环境中部署,作者进一步将HumanoidPF具体实现为一种遥操作行走导航系统,其细节在第III-C节中给出
整体流程如图2所示

总之,作者学习一种视觉-运动策略,将多样的障碍物几何形状和空间布局映射为相应的全身穿越技能
++左:用于全身穿越学习的 HumanoidPF++
- 上)构建 HumanoidPF,即对 APF 的重新表述,使其适配人形机器人全身穿越
- 下)将其用作信息丰富的感知表征以及避碰奖励
++右:可扩展的训练与部署流程++
- 上)通过混合场景生成构建多样且具有挑战性的训练环境
- 中)并行训练多个专家策略,并将其蒸馏为单一通用策略
- 下)通过 Click-and-Traverse 实现从模拟到现实的部署,使在杂乱室内场景中的行走导航远程操控变得直观
第 III-A、III-B 和 III-C 节分别对用于穿越学习的HumanoidPF、可扩展训练以及部署流程进行详细说明
1.2.1 用于全身穿越学习的 HumanoidPF
作者在经典 APF(人工势场)方法的基础上进行了大幅扩展,以支持基于学习的全身人形机器人穿越能力
- 在 APF 中,目标位置
被建模为吸引源,障碍物
- 然而,以往工作将 APF直接应用于基于单刚体模型的控制,这难以满足人形机器人技能学习中高维度且强耦合的规划与控制需求
因此,作者提出 HumanoidPF,这是一种专为人形机器人定制的、对 APF 的有原则重构,它对人形机器人与障碍物之间的关系进行编码,以支持信息更为丰富的感知和更为简化的奖励设计
1.2.1.1 HumanoidPF 的构建
-
首先,构造吸引场
其中测地距离
测地距离本质上考虑了障碍物的几何形状,因此比简单的欧几里得距离提供更安全的引导 -
接下来,斥力场
其定义为
其中 -
最终的引导场是组合势函数的负梯度
随后在不同身体部位的位置进行查询,为每个身体部位对应的APF 二维可视化如图3 (a) 所示

尽管 APF 方法通常将机器人建模为单一刚体,但若直接应用于多关节仿人机器人,则可能在不同身体部位之间产生冲突
例如,当机器人正面遇到前方障碍物时,必须在向左或向右绕行之间做出决策。机体左侧和右侧的势场分别将其引导至相反的路径。在对称构型下,这些向量会相互抵消,从而导致一种多模态困境:机器人要么陷入局部极小值,要么表现出振荡行为
为解决这一问题,作者提出了一种优先级加权方案,根据各个身体部位对任务的贡献度,对其影响力设定不同的优先级
++优先级加权++
与将所有身体部位一视同仁不同,作者的优先级加权方案会根据各身体部位在整体运动中的作用来调整其影响力
为了建立连贯的全局引导,作者为根部身体部位(例如骨盆)分配更高的优先级,因为它在保持稳定性和方向上起着核心作用:
此外,一些身体部位在避障中更加关键,尤其是那些更接近潜在碰撞的位置
为此,作者基于带符号距离和身体部位
的笛卡尔速度
,以及一个缩放因子
,定义了一个动态碰撞紧迫度权重:
由此得到的HumanoidPF 定义为
该方案削弱了相互冲突的影响,并促进了协调的全身控制。尤其是,空间构型中的细微不对称会被选择性放大,从而无缝地解决多模态困境
1.2.1.2 基于 HumanoidPF 的地形穿越技能学习
++用于策略观测的HumanoidPF++
为了更好地让RL 策略了解人形体与障碍物之间的关系,作者利用HumanoidPF 构建一个紧凑且与任务相关的视觉观测。它在 个身体部位上进行采样
其中,每个编码了由障碍物和目标在身体部位
处诱导的局部方向引导,指示无碰撞运动
在关键身体部位对这些场进行采样,指定了人形机器人应如何引导其身体穿过环境,从而使策略能够基于通行决策进行推理,而不是从原始视觉数据中进行隐式推断 。原论文在第IV-A 节中对这一点进行了实证验证
- 用于观测的 HumanoidPF 通过将环境表示为一个连续的、空间聚合的场,进一步减轻了感知层面的仿真到真实(sim-to-real)差距,该场起到类似低通感知滤波器的作用
- 不同于保留细粒度几何细节且对局部微小扰动高度敏感的原始传感器表示,这种场的建模方式能够抑制孤立噪声,同时保留与穿越任务相关的主导空间梯度
因此,如第 IV-C 节中的实证结果所示,在真实世界部署时,细小的几何变化不会显著影响控制
++用于策略奖励的HumanoidPF++
为了简化奖励工程,作者采用HumanoidPF 来诱导具有前瞻性和密集性的指导,这种指导能够泛化到各种环境中
在每个时间步长,HumanoidPF 编码出期望运动方向的分布,策略则被优化以产生与该分布一致的动作,从而促进安全且灵巧的避碰行为
von Mises-Fisher (vMF) 分布用于在单位球面上对方向偏好进行建模,并且允许通过单个集中参数
来控制这种偏好的强度:
其中,表示人形身体部位的运动方向,
是归一化函数
和
直接从 HumanoidPF 推导得到
其中 是一个缩放因子。优先级较高的身体部位将接收到幅值更大的场向量
;相应地,
会增大,以加强与
的一致性;而对于优先级较低的身体部位,则相反
这样的优先级感知聚焦设计促进了全身动作的协调,同时提升了避碰行为,如图3 (b) 所示
在策略训练期间, 令第 个身体部位的运动方向为
, 其对应的先验方向为
且集中参数为
在假设各关节相互独立的情况下,整体身体运动先验和对数似然奖励表示为:
这种奖励形式++在不同场景之间表现出很强的泛化能力,而无需手动调参++,从而使得自动化训练流水线能够高效扩展到各种不同的环境中
1.2.2 在多样且具有挑战性的场景中实现可扩展训练
在通用的实际应用中,人形机器人需要在单一的统一策略下处理多样化的场景。为此,该策略需要在足够大且具有挑战性的室内场景数据集上进行训练,从而能够在真实的杂乱场景中实现泛化
- 因此,作者提出了一种混合场景生成方法,详见下文的1.2.2.1 混合场景生成(对应于原论文第III-B.1节)。该方法结合了真实 3D 室内场景的裁剪片段以保证结构逼真性,并通过程序化合成的障碍物来丰富高度具有挑战性的杂乱布局
- 此外,即便有 HumanoidPF,要在所有场景上直接学习一个统一策略仍然具有挑战性,其原因在于强化学习的样本效率较低
因此,作者采用了一种受 36、37 启发的从专家到通才(specialist-to-generalist)的训练策略,具体见下文的1.2.2.2 专家到通才训练(对应于原论文第 III-B.2 节)
1.2.2.1 混合场景生成
作者观察到,在大多数现有的方法中,高度具有挑战性的障碍布局只是一个长尾子集数据集 38--40,因为典型的室内场景具有有序的物体布局以及边界清晰的可行走区域。单纯扩大数据集规模并不能缓解这一问题
因此,作者提出了一种新的混合场景生成方案,将程序化合成的"极端"障碍物融入真实感的三维室内数据集中,在其中同时施加全空间约束
首先,对于真实 3D 室内场景的裁剪
为了在复杂且逼真的室内环境中实现良好的泛化能力,作者采用 3D-FRONT 38 数据集,该数据集包含结构上逼真的场景以及大规模高质量的家具物体,且有选择地裁剪并过滤场景块,用于策略训练
- 具体而言,作者首先将所有家具投影到地面上,并对所得的平面可行走区域进行半径为 0.1 m 的腐蚀操作,以考虑安全间隙
在剩余的可行走区域内,作者随机采样一个起始位置,并以该位置为中心裁剪一个 5 m ×5 m 的区域块
在训练过程中,目标位置将随机从以起始位置为圆心、半径为 2 m 的圆周上进行采样 - 作者首先在所有此类裁剪场景上训练专用策略,然后识别出穿越成功率较低的场景。通过实证被发现为不可通行的场景会被人工筛除
其次,对于程序生成的障碍物
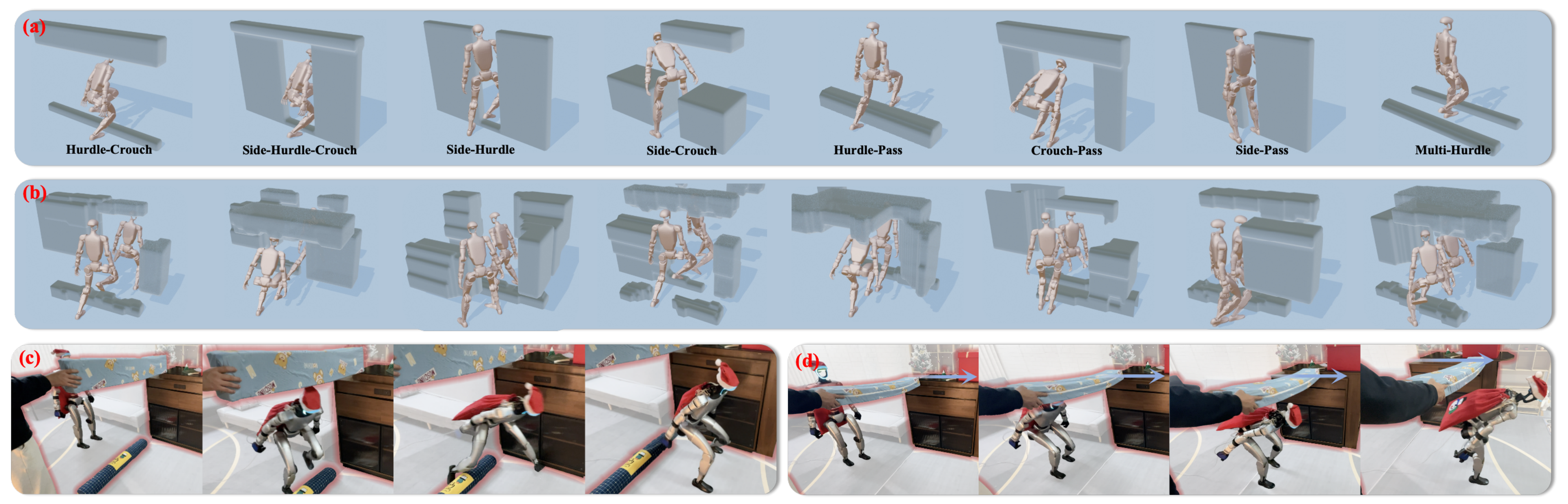
为了在 3D-FRONT 的裁剪场景基础上补充更具挑战性且更为杂乱的环境,作者程序化生成在空间全域(同时约束地面、侧向和头顶)施加限制的障碍物,有意针对高度受限的场景
-
具体而言,作者放置具有不同位置、尺寸和朝向的箱体,这些箱体可以从地面向上延伸、从天花板向下伸出,并紧密排列以形成狭窄的通行通道
-
为了打破结构规则性并增强几何真实性,作者对每个盒体施加随机的 SO(3) 旋转以及二维 Perlin 噪声。由此产生的伪影(如尖刺状表面或非流形区域),在进行网格转换之前,会在体素层面通过三维形态学闭运算和开运算加以缓解
机器人穿越生成障碍物的可视化结果如图 2 和图 4(b) 所示
-
为在策略训练过程中支持课程式学习,作者使用与布局无关的难度因子来控制障碍物的复杂度,例如箱子的数量和尺寸。随着难度提升,策略在日益具有挑战性的配置下逐步习得更加鲁棒的通行技能
1.2.2.2 专家到通才训练
// 待更