引言
在计算机网络的五层协议栈(或OSI七层模型)中,传输层(Transport Layer)起着承上启下的关键作用。它位于网络层之上、应用层之下。如果说网络层(如IP协议)的任务是像邮政系统一样,负责将数据包从全球互联网的一台主机尽可能送到另一台主机,那么传输层的任务则是确保这个数据包能够准确地交付给主机内特定的应用程序(进程)。
网络层解决了"主机到主机"(Host-to-Host)的通信问题,而传输层则进一步解决了"进程到进程"(Process-to-Process)的端到端通信问题。对于计算机专业的初学者而言,理解传输层,是理解应用程序如何利用网络进行通信的关键一步。
1. 传输层的演进历史与存在意义
早期的计算机网络,如ARPANET的初期,其通信协议(如NCP,网络控制程序)设计相对简单,它通常假设底层的网络传输是基本可靠的,并且每台主机上运行的应用数量非常有限。
然而,随着网络规模的扩大和异构网络互联的需求出现,科学家们意识到,底层的网络(尤其是当时的无线分组无线网或卫星网)可能是极不可靠的,会发生丢包、乱序和数据损坏。如果让每个应用程序都自己去处理这些复杂的错误恢复机制,将极大地增加应用开发的难度。
20世纪70年代,Vint Cerf和Bob Kahn在设计TCP/IP协议族时,做出了一个极其重要的架构决定:将可靠性传输的责任从网络核心边缘化,上移到端系统(End-System)中。这一设计哲学促成了传输层的独立。最初的传输控制协议(TCP)是一个庞大的单体协议,后来为了适应不同应用的需求(例如不需要可靠性但需要低延迟的语音通信),TCP被拆分成了提供可靠连接服务的TCP协议和提供无连接数据报服务的UDP协议。
传输层存在的根本意义在于:它向高层的应用层屏蔽了底层网络核心的复杂性和不可靠性,提供了一条逻辑上的、端到端的通信信道。
2. 传输层寻址与端口(Port)
要实现"进程到进程"的通信,首先要解决寻址问题。
2.1 问题背景:IP地址的局限性
我们知道,IP地址用于唯一标识网络中的一台主机。当一个数据包到达目的主机时,网络层的任务就完成了。但是,目的主机上可能同时运行着许多网络应用程序,例如一个Web服务器(Apache或Nginx)、一个邮件客户端、一个在线游戏的后台进程等。
操作系统如何知道接收到的数据包应该交给哪个进程处理呢?仅凭IP地址显然是不够的。传输层引入了"端口号"(Port Number)的概念来解决这个问题。
2.2 端口与套接字(Socket)
端口号是一个16位的整数,其取值范围是 000 到 655356553565535。端口号在主机内部唯一标识了一个网络进程(更准确地说是进程中的一个通信端点)。
我们可以用一个形象的比喻:IP地址就像是包含街道和门牌号的建筑物地址,它能确保邮件投递到正确的大楼;而端口号则像是大楼内部的房间号或收件人姓名,它确保邮件最终交到具体的人手中。
在实际通信中,连接的端点被称为套接字(Socket)。一个套接字由IP地址和端口号唯一确定。
Socket=(IP Address:Port Number) \text{Socket} = (\text{IP Address} : \text{Port Number}) Socket=(IP Address:Port Number)
例如,192.168.1.100:80 表示IP地址为 192.168.1.100 的主机上的80号端口。两个应用进程之间的通信,实际上就是两个套接字之间的通信。
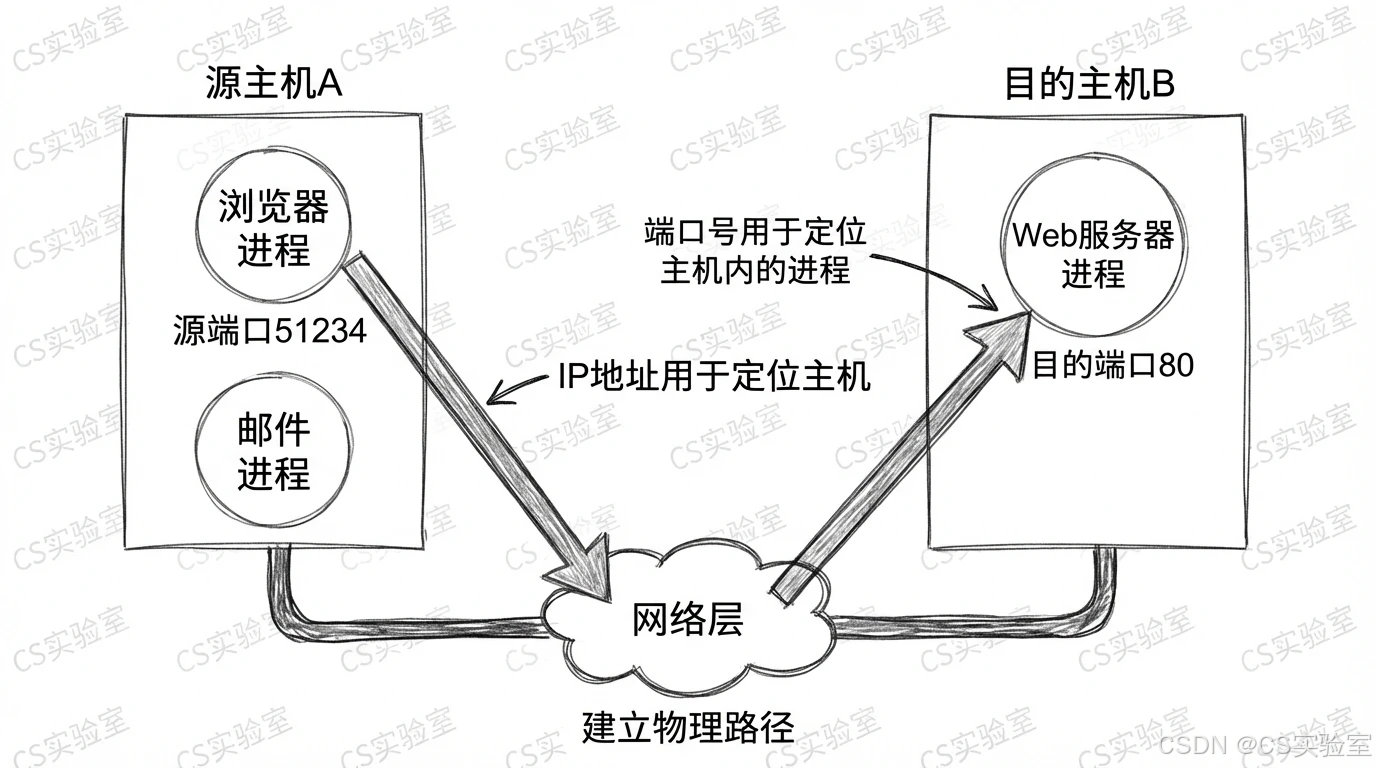
图 1:传输层寻址模型
2.3 端口号的分类
为了规范管理,16位的端口号被ICANN(互联网名称与数字地址分配机构)分为三大类:
-
熟知端口号(Well-known Ports,0 - 1023):
这些端口号被预留给最重要、最常用的系统级服务。例如:
- 端口 808080:HTTP(超文本传输协议,用于Web浏览)
- 端口 443443443:HTTPS(安全的HTTP)
- 端口 535353:DNS(域名系统)
- 端口 252525:SMTP(简单邮件传输协议,用于发送邮件)
在Linux/Unix系统中,通常只有root权限的进程才能绑定这些端口。
-
注册端口号(Registered Ports,1024 - 49151):
这些端口供用户进程或第三方应用注册使用,以避免冲突。例如,数据库MySQL默认使用 330633063306,微软的远程桌面协议RDP使用 338933893389。
-
动态或私有端口号(Dynamic/Private Ports,49152 - 65535):
这些端口号通常不固定分配给特定服务,而是由客户端操作系统在发起连接时动态选择作为源端口使用。当通信结束后,该端口会被释放供其他进程使用。
3. 传输层的核心功能
基于端口的寻址机制,传输层实现了其最基本的功能:复用与分用。此外,根据应用需求的不同,它还提供了不同质量的数据传输服务。
3.1 复用(Multiplexing)与分用(Demultiplexing)
这是传输层最基础的功能,存在于所有传输层协议中。
-
复用(发送端): 指发送方的传输层收集来自应用层不同进程的数据块,并为每个数据块封装上首部信息(包含关键的源端口号和目的端口号),然后将这些数据段传递给网络层发送出去的过程。这就像大楼的收发室收集各个办公室的信件,统一交给邮递员。
-
分用(接收端): 指接收方的传输层在收到网络层交上来的数据段后,检查首部中的目的端口号,然后将数据段正确地交付给该端口号所对应的应用进程的过程。这就像收发室收到一堆信件后,根据信封上的房间号分发给具体的人。
3.2 两种不同的服务模式:可靠与不可靠
在计算机网络的发展历程中,人们发现不同的应用对通信质量的要求是截然不同的。
- 文件传输、电子邮件、Web浏览等应用,要求数据必须绝对正确、无丢失、且按序到达。
- 实时语音、视频会议、在线直播等应用,对实时性要求极高,偶尔丢失几帧数据通常是可以容忍的,但无法容忍因等待重传而导致的长时间卡顿。
为了满足这两种对立的需求,传输层发展出了两个主要的协议:TCP和UDP。
3.2.1 用户数据报协议(UDP, User Datagram Protocol)
UDP提供的是一种无连接的、不可靠的数据传输服务。
- 原理简述: UDP非常简单,它几乎只在IP数据报之上增加了复用/分用功能以及简单的差错检测。发送数据前不需要建立连接。它即收即发,不保证数据包能到达,不保证按序到达,也不进行拥塞控制。
- 特点: header开销小(仅8字节),传输效率高,实时性好。
- 应用场景: DNS查询(要求快速响应)、实时流媒体(RTP)、在线游戏(对延迟敏感)。
3.2.2 传输控制协议(TCP, Transmission Control Protocol)
TCP提供的是一种面向连接的、可靠的字节流传输服务。
- 原理简述: TCP是互联网中最复杂的协议之一。它通过一系列复杂的机制在不可靠的网络层之上构建了可靠的通信信道。
- 面向连接: 通信前必须通过"三次握手"建立逻辑连接,通信结束后需要"四次挥手"释放连接。
- 可靠传输: 通过序列号、确认应答(ACK)、超时重传等机制确保数据无差错、不丢失、不重复、且按序到达。
- 流量控制(Flow Control): 通过滑动窗口机制,让发送方的发送速率匹配接收方的接收能力,防止接收缓冲区溢出。
- 拥塞控制(Congestion Control): 当网络出现拥塞时,TCP能够感知并主动降低发送速率,避免网络崩溃。
3.3 现代发展:QUIC协议的崛起
随着互联网应用对速度和安全性的要求日益提高,传统的TCP协议暴露出了一些局限性。例如,TCP建立连接和TLS安全握手需要多次往返交互,增加了延迟;TCP在处理丢包时可能会导致后续数据的阻塞(队头阻塞问题)。
近年来,由Google提出并最终被IETF标准化的QUIC协议(Quick UDP Internet Connections)成为了传输层的新星。QUIC在底层使用UDP协议,但在应用层(用户空间)实现了类似TCP的可靠性、拥塞控制,并集成了TLS加密。它极大地加快了连接建立速度,并解决了TCP的一些固有缺陷,目前已成为HTTP/3的标准传输层协议。这一发展趋势表明,传输层的功能正在向更高效、更灵活的方向演进,甚至模糊了传统的层级界限。
本章小结
传输层是计算机网络体系结构中连接通信子网和资源子网的关键层次。它通过引入端口号的概念,实现了从主机到主机的通信向进程到进程通信的跨越。理解传输层,核心在于掌握复用与分用的基本原理,以及TCP(可靠、面向连接)和UDP(不可靠、无连接)这两种截然不同的服务模型及其适用场景。随着网络技术的发展,如QUIC这样融合了多种优势的新协议也在不断重塑我们对传输层的认知。