26年软著审核升级,有些雷区不能踩
一月开始,很多人应该都发现了,审核标准突然严格了好多!
今天就来聊一聊2026年软著审核的几个新变化,帮大家避坑。
一、开发痕迹必须保留
过去提交软著材料时,很多人习惯把代码整理得干干净净再提交。
但现在不太建议这样了!
26年的审核系统会计算代码的"熵值",如果发现所有文件创建时间完全一致、没有调试痕迹,直接打标 "疑似生成式补写"。
小玖建议在提交时,可以刻意保留一些注释和未使用的变量,但也避免包含大量无用的代码片段。
要是被系统标记了,还得补交Git提交记录或开发过程说明,那可就麻烦大了!
二、操作流程要完整
现在审核系统会模拟用户操作路径来验证代码。
比如说明书里有登录页、首页、数据看板页的截图,系统就会去代码里找对应的调用链:login() -> success() -> jumpToDashboard() -> DashboardActivity。
要是代码里缺少某个环节,比如登录成功后没有页面跳转逻辑,直接就会被驳回。
所以切记要确保每个界面截图都能在代码中找到完整的执行路径。
三、开源代码要合规
26年新增了开源协议合规性检查,如果项目代码里引用了GPL协议的开源代码,又没有独立重写,软著申请直接不予受理。
就算用了Apache-2.0或MIT代码,也得保留原版权声明。
四、界面代码要对应
这个升级点堪称"黑科技",专门针对游戏、工业软件等高价值项目。
系统会提取说明书截图的UI布局结构,然后去代码里找对应的布局文件进行比对。
要是截图画着精美界面,代码里只有控制台打印,直接判定为虚拟界面不予登记。
所以用简单代码去申请复杂软件的软著,这招在26年已经不太适用了。
五、如何应对?
既然发现问题,自然会有应对策略。
今年一月份,平台针对新规进行了专项调优。
玖涯软著AI在生成代码时,已经内置了应对新规的功能,能帮你生成符合要求的全套材料。
和一些基于智能体进行提示词工程开发的平台不同,玖涯软著深入模型层,对底层大模型进行了微调。
模型天生就具备生成符合软著申请规范代码的能力。
同时也不是简单的一次性生成代码,生成会对代码和文档进行多轮迭代,以最大程度保证生成代码的独立性。
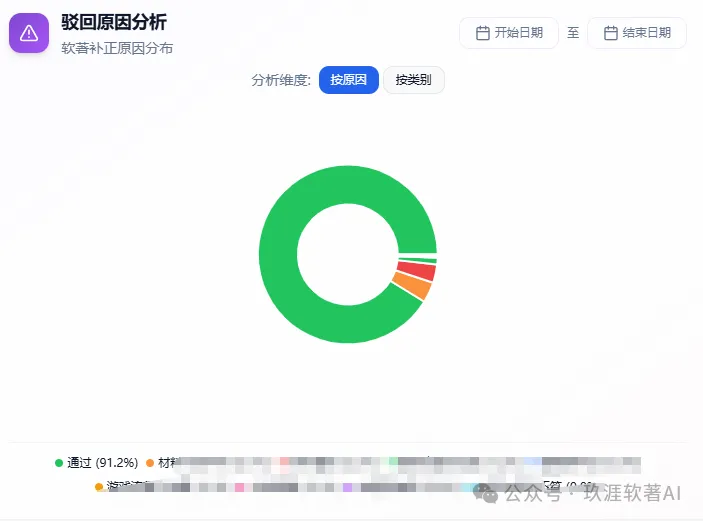
截止目前,系统上统计历史总通过率达91%。
申请技巧
有部分用户一次性买多份软著,同一方向生成多份软著材料,以为增加容错,提高下证率。
这样是行不通的。
同时大批量申请软著,很可能导致全部申请都被关联驳回。
这里建议每日申请软著数量不超过3份,这能最大保证通过率。