注:本文为 "摩尔线程开源生态" 简介,关注一下国产全功能 GPU 新体系。
略作重排,如有内容异常,请看原文。
2025 年 12 月,摩尔线程在上市 15 天后举办国内首届聚焦全功能 GPU 的开发者大会,发布以自主 MUSA 元计算统一计算架构为依托的全栈技术成果,覆盖 "芯 - 边 - 端 - 云" 的芯片、硬件、智算集群产品矩阵;2026 年 1-2 月,摩尔线程进一步开源 TileLangMUSA 项目,大幅降低国产 GPU 开发门槛。从 2020 年成立至今,摩尔线程历经五年技术淬炼,完成从硬件架构迭代到软件生态构建,再到开发者与产业协同的全链路布局,走出一条 "全栈自研 + 全场景覆盖 + 全生态共建" 的国产 GPU 自主创新路径,推动国产算力从 "能跑" 向 "跑得快、跑得稳、跑得值" 进阶。
一、MUSA 架构:五年迭代,花港架构定义全功能 GPU 新基准
MUSA(Metacomputing Unified System Architecture)是摩尔线程自主研发的元计算统一计算架构,覆盖芯片架构、指令集、编程模型、软件运行库及驱动程序框架全栈体系,历经五年发展已完整定义全功能 GPU 从芯片设计到软件生态的统一技术标准,可高效支持 AI 计算、图形渲染、物理仿真、科学计算、超高清视频编解码等全场景高性能计算。截至 2025 年 6 月,摩尔线程累计授权专利 514 项,其中发明专利 468 项,为架构提供全栈自主可控的技术支撑。
MUSA 硬件架构历经苏堤、春晓、曲院、平湖四代迭代,2025 年发布的第五代架构花港实现全方位技术突破,成为新一代全功能 GPU 的技术底座,技术特性包括:
- 算力与能效双提升:同等芯片面积下算力密度提升 50%,单位瓦特性能优化实现计算能效提升 10 倍,为大规模智算集群提供绿色算力底座;
- 全精度端到端计算:新增 FP4 计算支持,实现从 FP4、FP6、FP8 到 FP16、BF16、FP64 的全精度覆盖,适配 AI、HPC、图形等多场景计算需求;
- 低精度计算深度优化:新增 MTFP6/MTFP4 混合低精度端到端加速技术,原生支持 Attention 机制关键路径的矩阵 rowmax 计算,内置在线量化 / 反量化、随机舍入等硬件加速能力,大幅提升混合精度 SIMT 吞吐量,为 MT Transformer Engine 等下一代 AI 引擎提供底层支撑;
- 超大规模互联能力:通过自研 MTLink 高速互联技术,实现片间互联带宽 1314GB/s,支持十万卡级集群组网,为超大规模模型训练奠定基础;
- 图形与 AI 深度融合:内置 AI 生成式渲染架构(AGR)与增强型硬件光追引擎,完整支持 DirectX 12 Ultimate,实现图形渲染与智能计算的协同优化,推动 "光追 + AI 渲染" 新范式落地。
配套花港架构,摩尔线程同步推出 MUSA 软件栈 5.0,构建从编译器、算子库到 AI 框架的全栈工具链,完成软件生态的全面升级:
- 框架适配全面扩展:在 PyTorch、PaddlePaddle 基础上,新增对 JAX、TensorFlow 的原生支持,兼容 Megatron、DeepSpeed 训练框架,新增强化学习训练框架 MT VeRL;
- 推理引擎多元优化:深度调优自研 MTT 推理引擎与 TensorX,同时适配 SGLang、vLLM、Ollama 等新兴推理框架,满足不同场景的推理需求;
- 基础计算库效能突破:muDNN 计算库实现 GEMM/FlashAttention 效率超 98%,集群通信效率达 97%,编译器性能较上一代提升 3 倍;
- 编程语言创新升级:推出面向 AI + 渲染融合的 muLang,原生支持 MUSA C,发布 GPU 中间表示语言 MTX 1.0,同时深度兼容 TileLang、Triton 等高性能编程语言,提升开发者调优自由度;
- 生态开放持续推进:宣布逐步开源 MATE 算子库、MUTLASS、MT DeepEP 通信库、KUAE 云原生工具包等关键组件,向开发者社区开放底层技术能力。
二、芯边端云产品矩阵:花港架构下的全场景算力落地
基于花港架构,摩尔线程构建起覆盖 AI 训推、图形计算、端侧智能的芯片矩阵,并推出配套硬件产品,实现全功能 GPU 算力从云端到端侧的全场景落地,完成 "芯片 - 硬件" 的技术闭环。
1. 三大芯片:精准适配不同算力场景
摩尔线程发布三款基于花港架构的芯片,分别聚焦 AI 训推一体、图形计算、端侧智能,实现算力场景的精准覆盖:
- 华山芯片:定位 AI 训推一体全功能 GPU,支持 FP4 到 FP64 全精度计算,搭载 MTFP4/MTFP6 混合低精度加速技术,针对大模型训练做硬件级定制优化;集成新一代异步编程模型,支持常驻核函数、线程束特化,大幅提升并行计算效率,具备支撑万亿参数大模型训练的能力,成为国产 AI 基础设施的重要算力芯片;
- 庐山芯片:专攻高性能图形计算,相较上一代春晓架构 MTT S80,AI 计算性能提升 64 倍,光线追踪性能提升 50 倍,3A 游戏渲染性能提升 15 倍,显存容量提升 4 倍;引入 AI 生成式渲染架构(AGR)与全新硬件光追引擎,支持 DirectX 12 Ultimate,可满足 3A 游戏、工业设计、数字孪生等专业图形场景需求,标志着国产 GPU 在图形领域从 "追赶" 向 "参与技术标准定义" 进阶;
- 长江芯片:摩尔线程首款端侧智能 SoC 芯片,突破传统 PC / 服务器算力边界,面向具身智能、车载、AI 计算终端等端侧场景,提供 50 TOPS 异构 AI 算力,成为端侧智能算力的重要载体。
2. 两款端侧硬件:让全功能 GPU 算力触手可及
以长江芯片为核心,摩尔线程推出两款面向开发者的端侧硬件产品,实现全功能 GPU 算力的平民化落地,打造个人智算平台:
-
MTT AIBOOK:专为 AI 学习与开发者打造的个人智算平台,运行基于 Linux 内核的 MT AIOS 操作系统,支持虚拟化与安卓容器,可无缝兼容 Windows、安卓应用;预置完整 AI 开发环境与工具链,开箱即可开展大模型、Agent 开发,内置智能体 "小麦",支持 2K 高清渲染、本地大模型(MUSAChat72B)、端侧 ASR/TTS,同时预装智源悟界 Emu3.5 多模态模型,实现文本生图、图像编辑等多模态能力;

-
AICube:定位桌面级 AI 计算硬件,采用高性能紧凑设计,为开发者提供轻量化、高可用性的端侧算力支持,可高效处理复杂 AI 推理任务,成为端侧 AI 开发的重要工具。

三、夸娥 KUAE 2.0 万卡集群:国产超大规模智算的重要突破
超大规模智算集群是大模型训练的重要基础设施,摩尔线程在开发者大会上发布夸娥 KUAE 2.0 万卡智算集群,定位国产自主研发的 AI Foundry,实现国产 GPU 在超大规模智算领域的关键突破,成为支撑万亿参数大模型训练的技术底座,关键技术指标与工程化能力达到国际主流水平:
- 算力与组网能力:集群 FP8 浮点运算能力达 10Exa-FLOPS,支持十万卡级超大规模组网,十万卡集群训练效率达理想水平的 87%,与国际主流产品的差距仅 5%;
- 训练效率优化:在 Dense 大模型训练中算力利用率(MFU)达 60%,MOE 大模型达 40%,有效训练时间占比超 90%,训练线性扩展效率达 95%;基于原生 FP8 能力完整复现 DeepSeek V3 大模型训练流程,自研 FP8 GEMM 算力利用率高达 90%,Flash Attention 算力利用率超 95%,突破 FP8 累加精度等关键技术瓶颈;
- 推理性能标杆:与硅基流动深度合作,在 MTT S5000 智算卡上完成 DeepSeek V3 671B 满血版大模型深度适配与性能验证,FP8 低精度推理下单卡 Prefill 吞吐突破 4000 tokens/s,Decode 吞吐超 1000 tokens/s,创下国产 GPU 大模型推理性能新高;
- 下一代硬件布局 :前瞻性披露MTT C256 超节点架构规划,采用计算与交换一体化的高密设计,可系统性提升万卡集群在超大规模智算中心的能效比与训练效能,为下一代超大规模智算打造硬件基石。
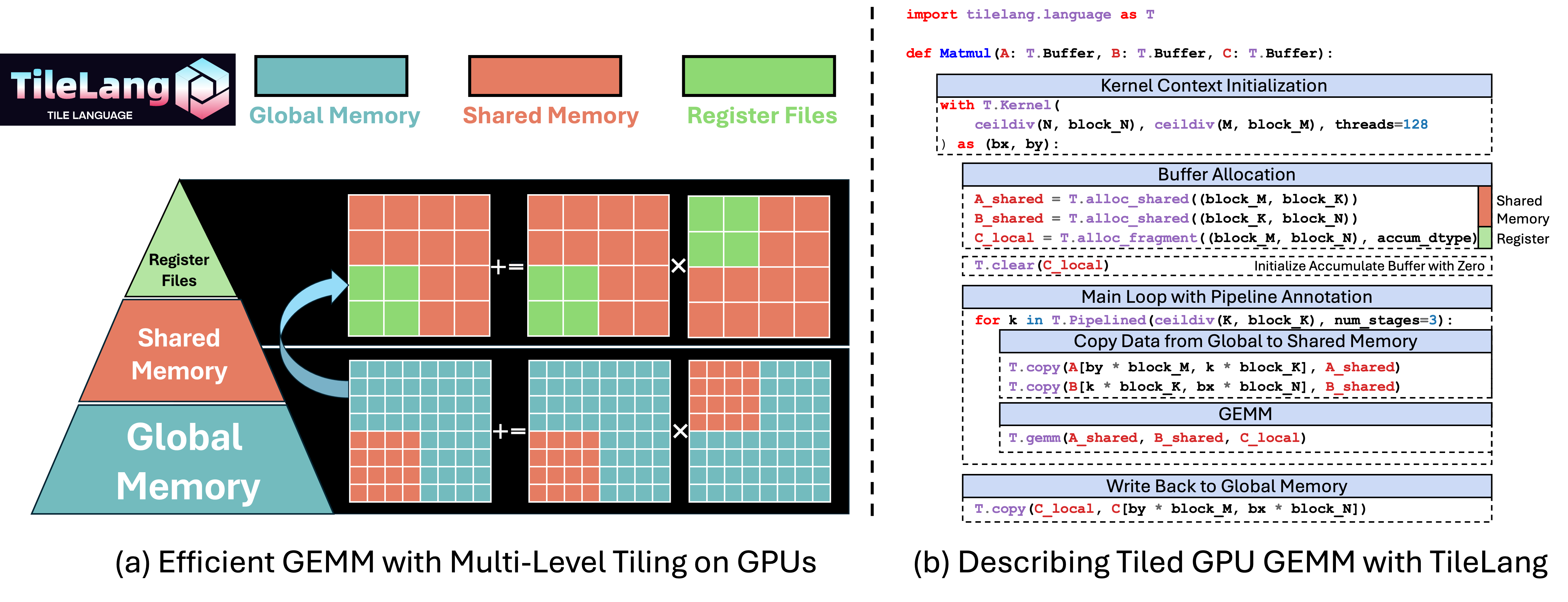
四、TileLangMUSA 开源:降低开发门槛,释放国产 GPU 计算潜力
2026 年 1-3 月,摩尔线程正式开源TileLangMUSA项目,实现对高性能 AI 算子编程语言 TileLang 的完整支持,验证 "高层语言 + 国产 GPU" 技术路线的可行性,成为摩尔线程构建开放算力生态的重要一步,设计目标是通过高层抽象与编译器优化,大幅降低国产 GPU 的开发与应用门槛,充分释放全功能 GPU 的计算潜力。
1. TileLangMUSA 技术特性
TileLang 是基于张量分块(Tiling)抽象的领域特定语言(DSL),采用声明式语法与类 Python 前端,开发者可通过接近数学公式的形式描述计算意图,由编译器自动完成循环优化、内存调度与代码生成,兼具开发效率与底层性能。摩尔线程打造的 TileLangMUSA 项目,实现 TileLang 与 MUSA 架构的深度融合,技术特性包括:
- 广泛的硬件兼容性:已在摩尔线程多代全功能 GPU 上完成功能验证,覆盖 MTT S5000、MTT S4000 等训推一体智算卡;
- MUSA 架构精准映射:编译器可自动调用 MUSA 的 MMA(矩阵乘累加)指令,充分发挥张量峰值算力;实现 TileLevel Pipeline 多级数据搬运优化,利用 MUSA 异步拷贝指令掩盖访存延迟;完整支持 Warp Specialization 特性,提升并行计算效率;
- 高可靠性保障:基于 MUSA 架构的 TileLang 原生算子单元测试覆盖率超 80%,为大规模工业应用提供技术保障;
- 零门槛迁移体验 :开发者完成环境配置后,可保留原有
import tilelang开发习惯,通过 Cython 编译后端直接在 MUSA 环境中运行 TileLang 代码,实现算子逻辑的无缝迁移。
2. 实测性能:开发效率与计算性能双提升
以大语言模型关键的 FlashAttention3 和 GEMM(通用矩阵乘)算子为测试对象,在 MTT S5000 上的实测结果显示,TileLangMUSA 实现开发效率与计算性能的双重突破:
- 开发效率提升 90%:相较手写 MUSA C++ 代码,TileLangMUSA 的代码量减少约 90%,代码逻辑更简洁,大幅降低算子开发与维护成本;
- 性能媲美手工优化:得益于编译器的自动化优化,生成的 GEMM 算子性能达手写优化版本的 95%,FlashAttention3 算子性能达手写优化版本的 85%;
- 自动化调优能力:内置 Autotuning 机制,可在 MUSA 架构上快速搜索最优分块策略(Tile Size)与流水线级数,轻松超越未经深度优化的基准实现。
3. 未来规划:打造国产算力统一加速平台
TileLangMUSA 的开源是摩尔线程构建开放算力生态的重要一步,基于此,摩尔线程计划持续推进技术迭代,打造覆盖从单算子到完整大模型的国产算力统一加速平台:
- 持续进行性能优化,开发更多 MUSA 架构定制扩展,使编译器生成代码性能稳定达到手写优化版本的 90% 以上;
- 深度集成 SGLang 等主流 AI 框架,实现 Transformer、MoE 等复杂模型架构的跨算子调度与全局优化,完成训练与推理场景的端到端无缝加速;
- 完善调试、性能分析等工具链,为开发者提供从算子开发到模型部署的全流程技术支持。
五、生态建设:开发者培育与产业协同,构建国产算力正向循环
GPU 行业的竞争围绕生态展开,摩尔线程以 "开放" 为设计理念,构建起 "开发者培育 + 产业协同" 的双重生态体系,形成从硬件到软件、从技术到应用的正向循环,推动 MUSA 生态融入千行百业。
1. 摩尔学院:培育国产 GPU 原生开发者
摩尔线程打造 MUSA 开发者成长平台摩尔学院,截至 2025 年 12 月已汇聚 20 万名开发者,目标培育百万规模的 MUSA 开发者社群:
- 提供从入门到大师的全体系专业课程,覆盖 MUSA 架构、芯片开发、AI 应用等多领域内容;
- 深入人才源头,与全国 200 所高校开展产教融合合作,共建联合实验室,通过 "繁星计划" 等开发者竞赛,培养懂国产架构的原生代开发者;
- 以 MTT AIBOOK、AICube 等硬件产品为载体,为开发者提供随时随地可接入的算力平台,降低开发门槛。
2. 产业协同:全场景覆盖,打造算力 + 行业解决方案
摩尔线程基于 MUSA 架构开展深度产业协同,生态覆盖工业智造、智慧医疗、数字孪生、智慧农业、6G 等多个领域,与行业伙伴共建基于国产算力的解决方案,而非简单的硬件供应:
- 与雪浪云合作打造工业智能解决方案,推动国产算力在工业智造领域的落地;
- 与推想医疗完成 AI 医疗软件国产化适配,实现国产 GPU 在智慧医疗场景的应用;
- 与泛联院共建 6G 智能云基站算力底座,探索 AI for 6G 的前沿应用;
- 布局具身智能、科学智能(AI4S)等前沿领域,发布 MT Lambda 具身智能仿真训练平台,深度融合物理、渲染与 AI 三大引擎,为前沿技术研发提供算力支撑。
六、发展定位:走出中国特色 GPU 之路,不做 "第二个英伟达"
自 2020 年成立以来,摩尔线程始终被贴上 "中国英伟达" 的标签,但通过此次开发者大会的全栈技术发布与后续的开源生态布局,摩尔线程彻底打破这一叙事框架,走出了一条独属于中国 GPU 产业的自主创新之路:
- 摒弃 "局部替代" 的发展思路,以 "全功能 GPU" 为设计锚点,区别于单纯的 AI 加速器,将 AI 能力深度嵌入图形渲染、物理仿真、量子计算等高价值垂直场景,实现从通用算力底座到产业纵深应用的延伸;
- 坚持 "全栈自研 + 全场景覆盖 + 全生态共建" 的发展路径,从硬件架构、芯片设计到软件栈、编程语言,再到开发者培育、产业协同,完成全链路技术自主,构建起独立于海外的国产算力生态;
- 推动国产 GPU 从 "能跑" 向 "愿意用" 进阶,通过全栈技术优化与生态建设,让开发者主动思考 "我的下一个项目,能不能全在 MUSA 生态里完成",这正是国产 GPU 产业的重要突破。
从五年前的 0 到 1,到如今构建起覆盖 "芯 - 边 - 端 - 云" 的全栈技术体系与开放的生态体系,摩尔线程用硬核技术成果证明,中国 GPU 的未来不是复刻别人的路径,而是成为最好的自己。随着 MUSA 架构的持续迭代、开源生态的不断完善,以及产业应用的深度落地,摩尔线程正成为多模态智能、具身智能时代的关键算力使能平台,为国产数字经济发展提供坚实的算力支撑。
TileLangMUSA 项目开源地址

- GitHub - MooreThreads/tilelang_musa: Domain-specific language designed to streamline the development of high-performance GPU/CPU/Accelerators kernels
https://github.com/MooreThreads/tilelang_musa
缩略词
GPU :Graphics Processing Unit,图形处理器
AI :Artificial Intelligence,人工智能
MUSA :Metacomputing Unified System Architecture,元计算统一计算架构
HPC :High Performance Computing,高性能计算
SIMT :Single Instruction Multiple Threads,单指令多线程
AGR :AI Generative Rendering,AI 生成式渲染架构
SoC :System on Chip,片上系统
TOPS :Tera Operations Per Second,万亿次运算每秒
ASR :Automatic Speech Recognition,自动语音识别
TTS :Text To Speech,文本转语音
MFU :Model FLOPS Utilization,模型浮点运算利用率
MoE :Mixture of Experts,混合专家模型
FP4 :4-bit Floating Point,4 位浮点精度
FP6 :6-bit Floating Point,6 位浮点精度
FP8 :8-bit Floating Point,8 位浮点精度
FP16 :16-bit Floating Point,16 位浮点精度
BF16 :BFloat16,脑浮点 16 位精度
FP64 :64-bit Floating Point,64 位浮点精度
MTFP4 :MooreThreads FP4,摩尔线程定制 4 位浮点精度
MTFP6 :MooreThreads FP6,摩尔线程定制 6 位浮点精度
GEMM :General Matrix Multiplication,通用矩阵乘法
MMA :Matrix Multiply-Accumulate,矩阵乘累加
DSL :Domain Specific Language,领域特定语言
IR :Intermediate Representation,中间表示
FLOPS :Floating Point Operations Per Second,浮点运算次数每秒
Exa-FLOPS :Exa Floating Point Operations Per Second,百亿亿次浮点运算每秒
AI4S :AI for Science,科学智能
6G :6th Generation Mobile Communication,第六代移动通信
muDNN :MooreThreads Deep Neural Network library,摩尔线程深度神经网络库
MTX:MooreThreads eXtensible IR,摩尔线程扩展中间表示
Ref:
- 摩尔线程的野心,不藏了
https://mp.weixin.qq.com/s/c3V0SznZchJS9rm8V6Rtag - 中国英伟达?不!从现在开始摩尔线程就是摩尔线程
https://mp.weixin.qq.com/s/e0xvyGZmUto0AurWi0E4bw - 刚刚,摩尔线程宣布开源!代码量暴降 90%
https://mp.weixin.qq.com/s/iNgsY4fs21xwYC6i4U8ZAg - 摩尔线程开源TileLang-MUSA,以高效算子开发释放全功能GPU计算潜力
摩尔线程开发者 2026年1月30日 18:18 湖南
https://mp.weixin.qq.com/s/R_P8kmYoevc1rbtMXsdm-w