

今夜不看春晚看代码!阿里开源 Qwen3.5-Plus,性能硬刚闭源顶流。
当全网都在集五福、晒年夜饭时,阿里"源神"在除夕夜悄悄放了个大招。
千问 3.5 系列旗舰模型 Qwen3.5-Plus 正式开源。这不是一次常规的版本号迭代,而是一次架构级的代际跃迁。
在刚刚公布的基准测试中,Qwen3.5-Plus 在 MMLU-Pro 知识推理评测中拿下 87.8 分 (超越 GPT-5.2),在博士级难题 GPQA 中斩获 88.4 分 (高于 Claude 4.5),更在指令遵循 IFBench 中以 76.5 分刷新全球纪录。
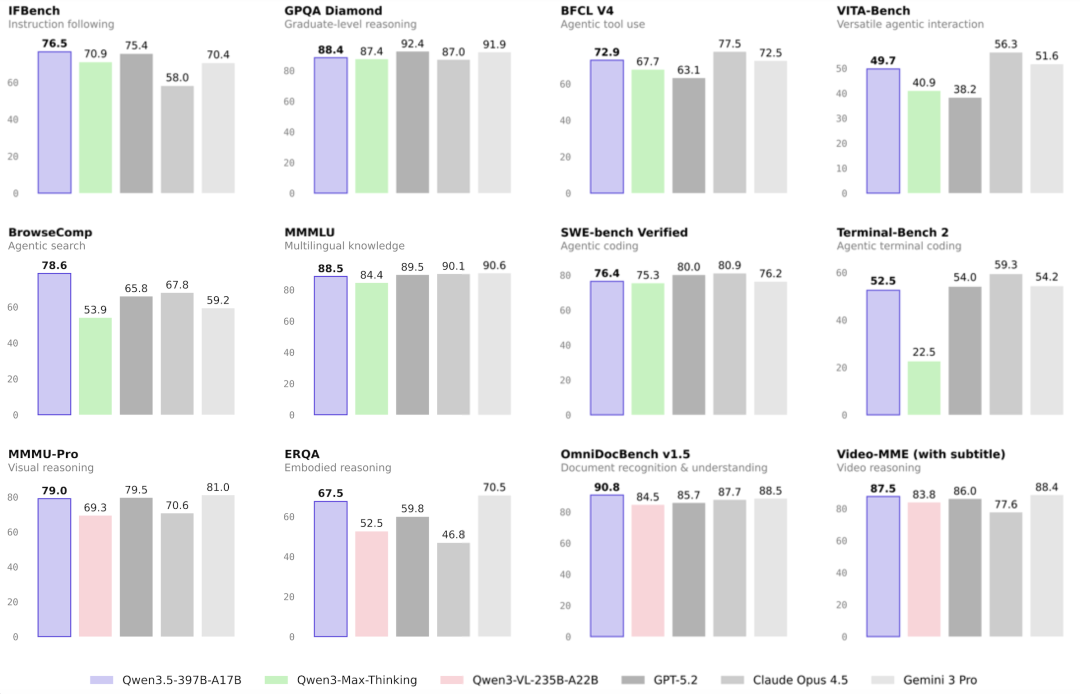
〓 Qwen3.5-397B-A17B 在推理、编程、智能体能力与多模态理解等全方位基准评估中表现优异
除了性能硬刚闭源顶流,Qwen3.5-Plus 最大的突破在于架构效率。它首次将 NeurIPS 2025 最佳论文(Gated Attention)的技术原理真正应用到了大规模开源模型中。
结合极致稀疏的 MoE 架构(总参数 397B,激活 17B),该模型实现了部署显存占用直接降低 60%。

〓 在 32k/256k 上下文长度下,Qwen3.5-397B-A17B 的解码吞吐量分别是 Qwen3-Max 的 8.6 倍和 19.0 倍。
用更聪明的架构,让大模型同时拥有了顶级闭源模型的智商和开源模型的性价比。
以下是我们的抢先实测与深度技术拆解。
实测:Qwen3.5-Plus 的原生超能力
Qwen3.5-Plus 给人的第一印象是直觉惊人。它并非在纯文本模型上简单外挂视觉模块,而是基于超大规模的文本、图像、视频混合数据进行原生预训练。
这种架构差异,在处理跨模态隐喻、复杂 Agent 任务及长程逻辑时表现得尤为明显。
既然是除夕,我们决定来一场马年谐音梗挑战。
面对一张鲨鱼骑马的图,Qwen3.5-Plus 像个懂梗的段子手,仅用 5 秒 就脱口而出:"这是沙琪玛(鲨+骑+马)"。
看到一群数字 2 围着马,它也能秒懂这是二维码(2+围+马)。
但这还不算什么。面对这张更复杂的图,模型陷入了长达 37.3 秒的深度思考。
它没有急于给出答案,而是一层层剥离视觉符号。最终精准破译了这是"马王堆"。
至于"黑芝麻"、"青梅竹马"这些更绕的梗,它也全都没放过。
这种从直觉秒懂到慢思考推理的跨越,说明它真的打通了视觉和语言文化的任督二脉。
这背后得益于千问 3.5 将支持语言扩展至 201 种 ,并将词表大小从 150k 扩容至 250k ------这一升级让小语种和特定文化符号的编码效率最高提升了 60%,从而能捕捉到更细腻的跨文化语义差异。
过年少不了看电影,我们顺手让它预测一下 2026 年春节档的电影票房。
Qwen3.5-Plus 立刻开启了打工人模式,自己去联网搜索、去重数据、交叉验证,甚至还分析了社交媒体上的情绪风向。
最终,它交出了一份有模有样的专业研报,核心影片表、票房预测、风险预警一应俱全。
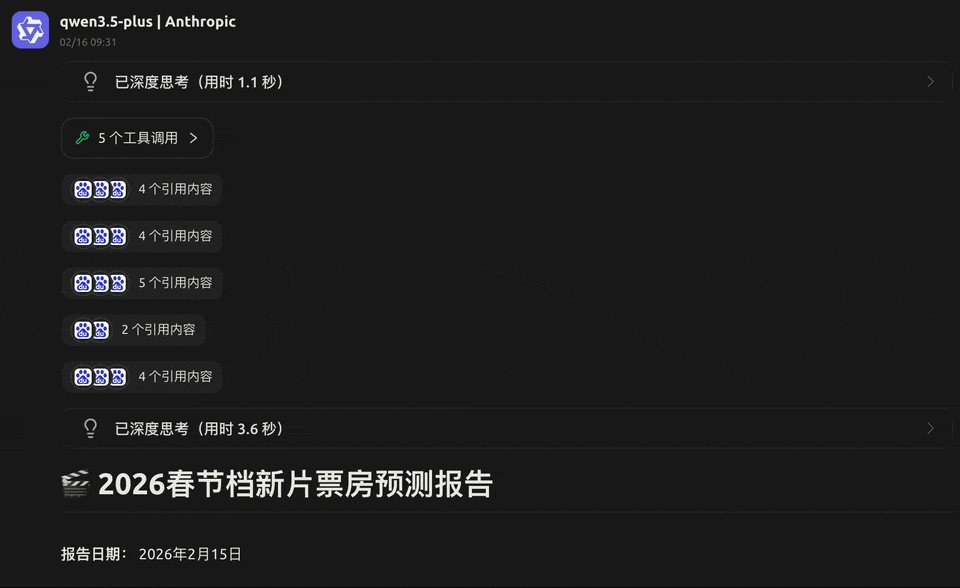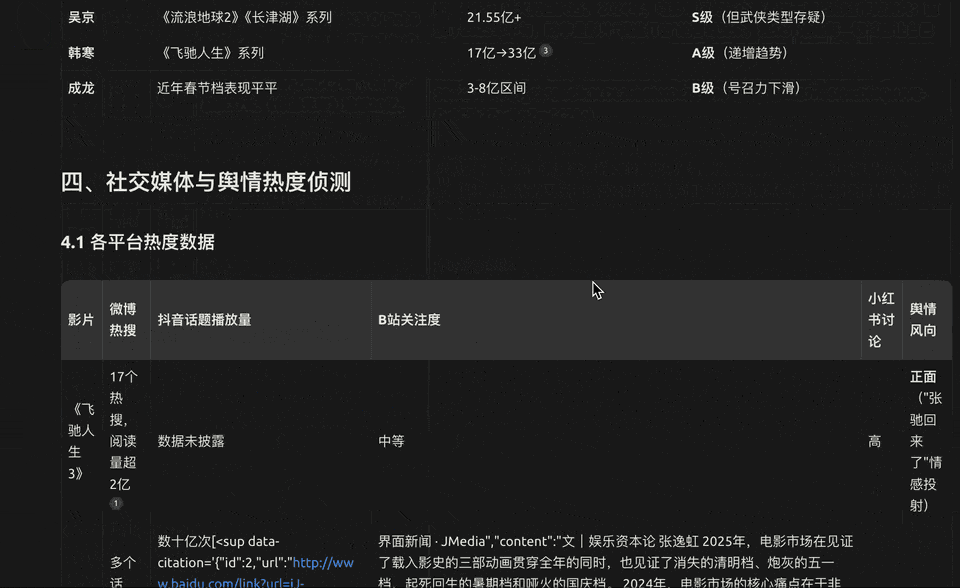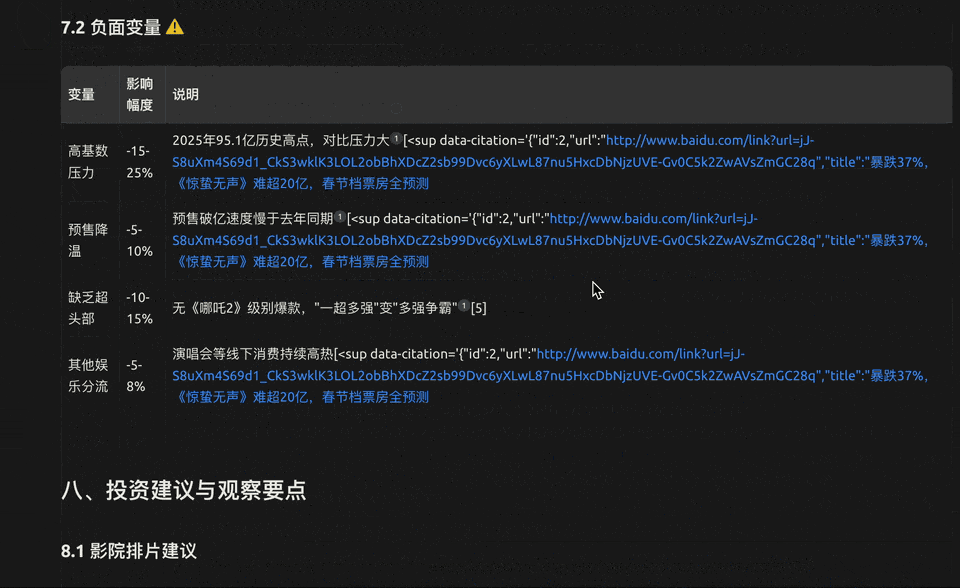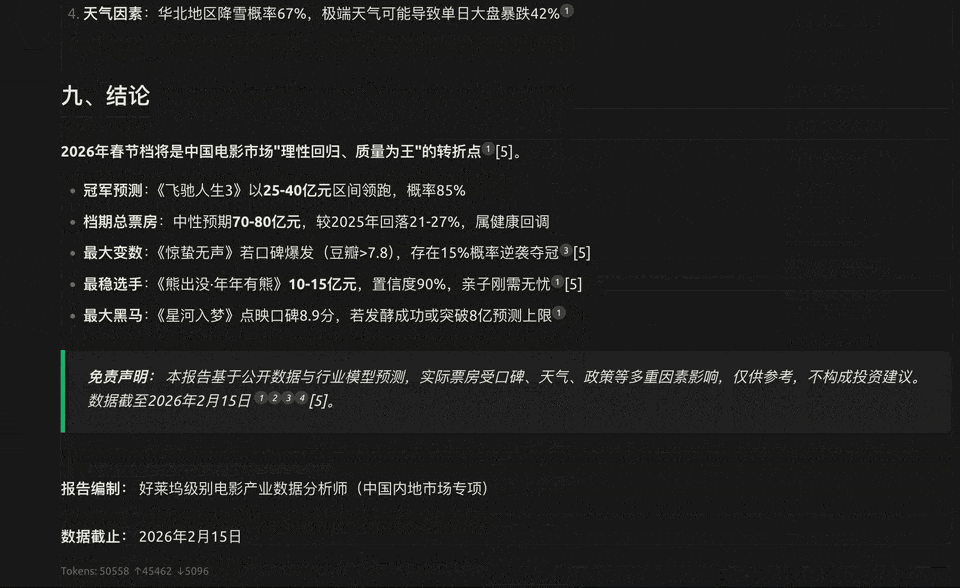
〓 模型经历了搜索、清洗、去重、分析的完整异步流程,展现了强大的任务规划能力。
在数学领域的空间直觉测试中,我们给模型看了三张 2D 投影图。
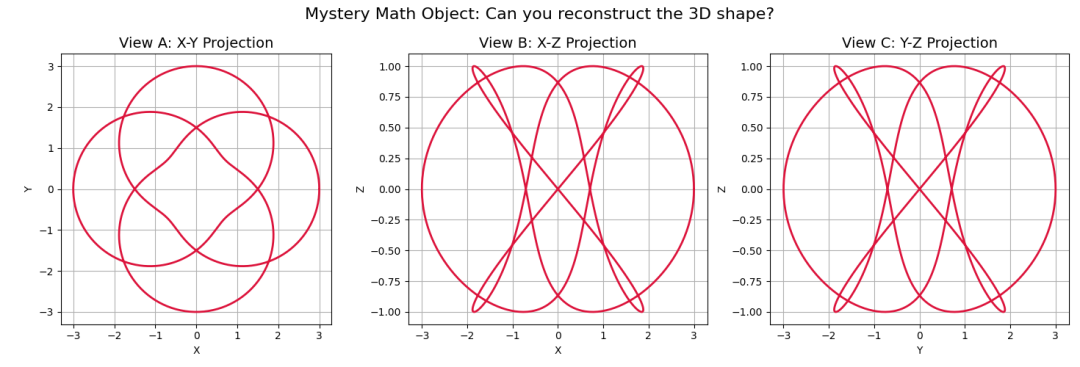
Qwen3.5-Plus 通过这三个侧面,准确推断出这是拓扑学中的环面结(Torus Knot),甚至推导出了核心参数 p=3, q=4,反手就写了一段 Python 代码把它画了出来。
这证明它脑子里是真的有 3D 空间几何直觉,而不只是在数像素点。
最后,再来一个一句话写游戏的极限挑战。用 Three.js 给我写一个 3D 魔方,要能玩,还要能自动还原。
Qwen3.5-Plus 二话不说,直接生成了数百行代码,构建了一个完整的 3D 互动魔方。
更有意思的是,第一次生成时自动还原按钮有点小 bug,我们只回了一句"Solve 按钮没反应",它只用了 6 秒钟就精准定位了漏掉的状态数组,光速修复了 bug。
这种在几百行代码里不迷路、逻辑严密还能快速 debug 的能力,确实有点东西。

技术拆解
Qwen3.5-Plus 之所以能以 397B 的参数量硬刚万亿模型,核心在于其对 Transformer 底层架构的深度重构。
门控注意力:给模型装上水龙头
NeurIPS 2025 最佳论文《Gated Attention for Large Language Models》的技术原理,是本次 Qwen3.5-Plus 性能跃升的关键原因之一。
传统 Transformer 的注意力机制存在低秩瓶颈,且 Softmax 的归一化特性导致模型被迫关注无关信息。
千问团队在 SDPA(缩放点积注意力)输出后引入了一个头专属的 Sigmoid 门控(Head-Specific Sigmoid Gate)。
〓 在 SDPA 输出端引入门控机制(G1),引入了非线性与输入相关的稀疏性
这一设计解决了两个核心难题:
消除注意力黑洞(Attention Sink):传统模型中,首个 Token 往往莫名占据大量注意力(平均 46.7%)。门控机制将这一比例降至 4.8%。
模型不再将注意力浪费在无关信息上------这也解释了为什么在魔方案例中,模型处理几百行代码时依然能保持逻辑严密,没有出现注意力涣散。
〓 对比可见,Gated Attention 成功消除了传统模型中普遍存在的注意力黑洞现象
消除巨量激活(Massive Activation):中间层激活值的峰值从 1053 大幅降低至 94。这不仅提升了训练稳定性 ,更为低精度量化提供了安全空间。
〓 门控分数的分布高度稀疏,意味着模型学会了该省则省,主动过滤无效信息
MoE 架构:17B 激活参数的秘密
Qwen3.5-Plus 采用稀疏混合专家(MoE)架构,总参数 397B,但推理时激活参数仅 17B (A17B) 。
结合多 Token 预测技术,其推理效率实现了质的飞跃:
-
在 32K 常用上下文场景,推理吞吐量提升 8.6 倍;
-
在 256K 超长上下文场景,推理吞吐量更是激增 19 倍。
这解决了 MoE 模型在长文本推理中的痛点,让长文档分析和长视频理解具备了实时性。
原生多模态:视觉语言的深度融合
Qwen3.5-Plus 从预训练第一天起,就是在超大规模混合数据上学习的。
为了解决不同模态训练效率不均的问题,团队采用了解耦并行策略,配合稀疏激活机制,使得混合数据的训练吞吐量几近 100% 持平纯文本训练。
同时,模型在训练和推理阶段统一部署了 FP8 精度 。这一策略使激活内存减少了约 50%,大幅降低了部署门槛。
智能体大脑:异步强化学习
为了让模型更像一个"人"去解决复杂问题,Qwen 团队构建了大规模异步强化学习框架 (Asynchronous RL)。该框架支持 400B+ 参数模型的训练,实现了端到端 3-5 倍的加速。
正是得益于此,Qwen3.5-Plus 才能在 BFCL-V4 等 Agent 评测中展现出超越 GPT-5.2 的任务规划与执行能力。
结语
在卷参数的时代,阿里选择了卷架构。
Qwen3.5-Plus 的发布证明了,通过 Gated Attention 和 MoE 的精细化设计,大模型可以在性能不降反升的前提下,大幅降低算力门槛。
性价比杀手:阿里云百炼 API 价格低至 0.8 元/百万 Token(仅为Gemini 3 Pro的 1/18);
开源的胜利:截至目前,千问系列模型全球下载量已突破 10 亿次。
在这个除夕夜,Qwen3.5-Plus 不仅是一份给开发者的技术大礼,更是对全球最强开源这一头衔的有力捍卫。
🔍
现在,在**「知乎」**也能找到我们了
进入知乎首页搜索**「PaperWeekly」**
点击**「关注」**订阅我们的专栏吧
·
