前言
如今具身技术迭代迅猛,26年春节期间,我会解读10篇最新论文,一为年后的加速应用/落地,琢磨方向、规划,二为同行提供借鉴,三为持续扩大影响力
- 言归正传,高可靠性、长时域的机器人操作传统上依赖大规模数据和算力来理解复杂的真实世界动力学
然而,χ0的作者指出,真实世界鲁棒性的首要瓶颈并不仅仅在于资源规模,而在于人类示范分布、策略所学习到的归纳偏置、以及测试时执行分布三者之间的分布偏移------这是一种系统性不一致性,会在多阶段任务中引发误差的级联累积 - χ0提出了一个Model Arithmetic,一种在权重空间进行融合的策略,可高效吸收不同示范所对应的多样化分布,范围从物体外观到状态变化
说的直白点,之所以关注到这个,是源于
-
我司年前在交付一个项目的时候,++想让机器人学会开各种柜门++,但因为柜门之间的差异比较大,故目前是针对不同的柜门微调不同的模型(哪怕是同一个VLA 也是各自独立微调同一个VLA),得到不同的权重
年前出差客户所在地的时候,我就在想,是否可以把开不同柜门的示范数据集,都给到同一个模型 ,然后得到一组权重,模型在面对不同柜门的时候,类似路由机制 去调用一组权重中 不同的权重部分 呢
即模型通过一个可学习的Router(路由网络),根据输入的视觉特征(比如柜门的材质、把手形状),动态选择激活哪个部分的权重
从而实现从:一个柜门一个模型,到一个模型针对不同柜门"路由调用"模型内部中的不同权重
------------
当然也可以为不同柜门训练不同的 LoRA 权重。在推理时,通过一个轻量级的分类器识别柜门类型,然后动态加载/挂载对应的 LoRAif detected == "cabinet": model.set_adapter("open_door_lora") elif detected == "button": model.set_adapter("press_button_lora") -
再比如开完柜门之后,需要移动下机器人再去按按钮,在我们把这个开柜门和按按钮串起来之前(之后会用同一个VLA串起来)
也是微调不同的模型去做不同的操作(开柜门和按按钮),那可否用开柜门、按按钮的示范数据集微调同一个模型,然后模型在需要开柜门、按按钮时,类似路由机制去调用同一个模型中一组权重中 不同的权重部分呢
第一部分 χ0: Resource-Aware Robust Manipulation viaTaming Distributional Inconsistencies
1.1 引言与相关工作
1.1.1 引言
如原论文所述,对于机器人而言,在稳健的策略执行中,决定性因素并不仅仅是规模本身。作者认为在现实世界中面向策略的广阔搜索空间内,阻碍稳健性的这个" 隐藏的魔鬼",是支配机器人学习三大支柱:
- 数据收集
- 模型训练
- 策略部署
这三者的分布之间的不一致性。这些不一致性并不会明显体现在成功率上,而是体现在执行的平滑性、系统吞吐量,以及成功完成任务所需的重试成本13, 8,69, 2, 31
作者将机器人学习流水线封装为贯穿整个研究周期的三个不同分布,以形式化后续分析
, 用于训练模仿策略的人类专家演示的分布
- 一个将状态映射到合理动作的映射器
在真实机器人部署过程中实际执行的动作轨迹的分布,它与策略输出的动作之间由于一定的延迟和物理限制而存在差异
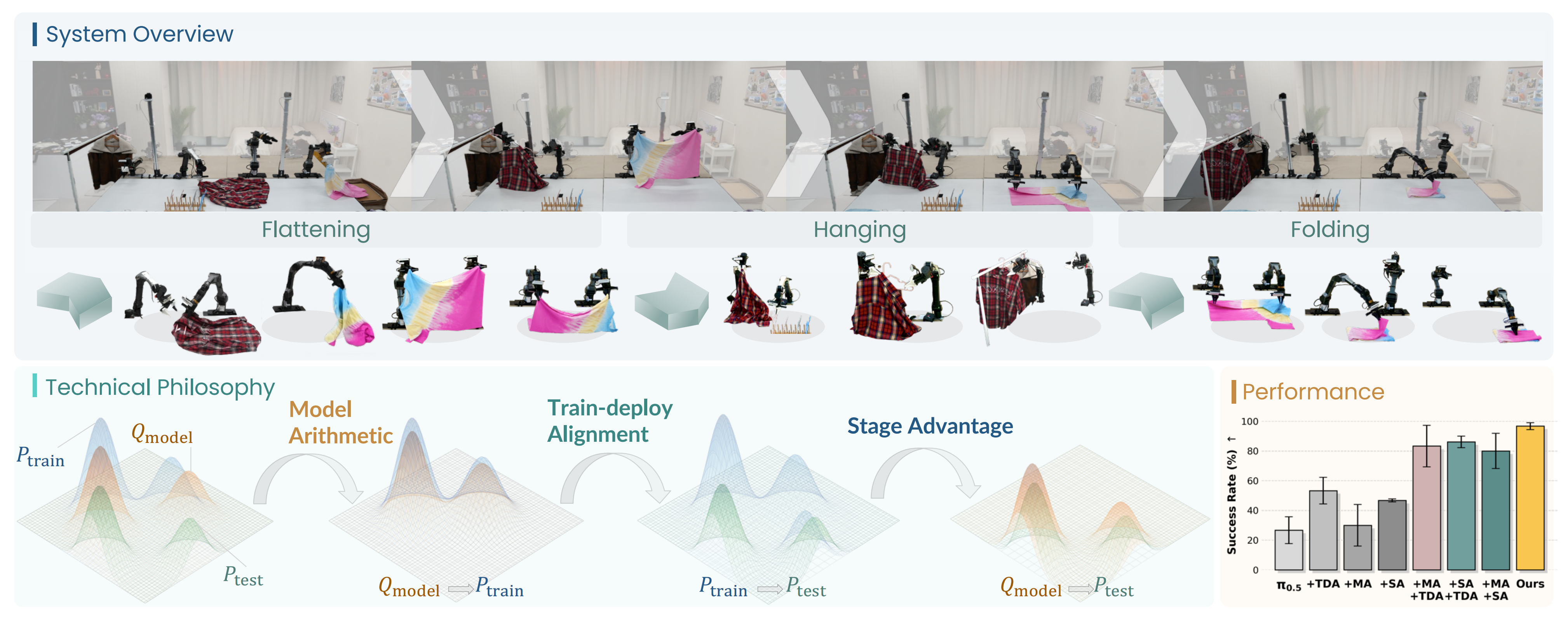
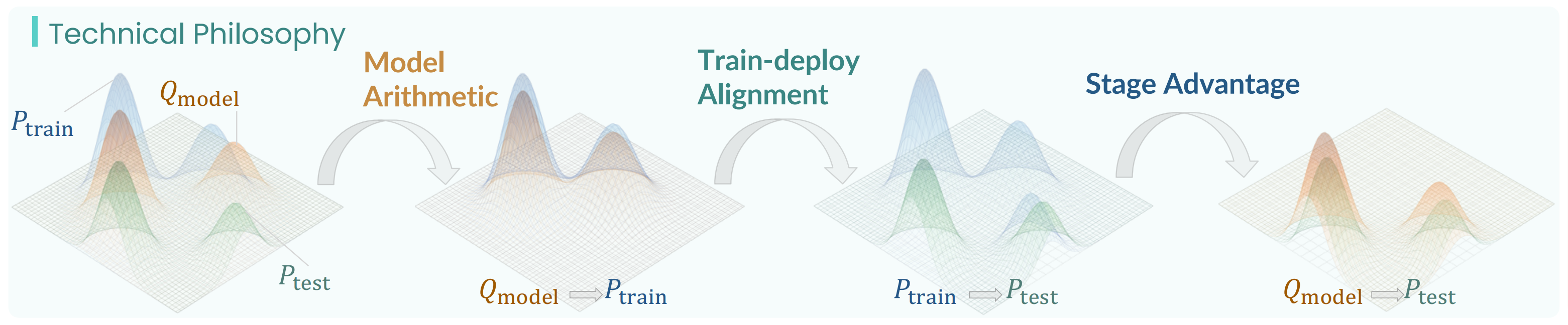
在真实世界中大规模部署已学习的策略表明,在该范式下存在三类系统性不一致,如图1所示
-
首先,由于任务维度极高,相对于完整的解流形,
-
其次,模型推理(
-
第三,尽管在推理过程中频繁发生失败,策略却缺乏故障恢复能力;即使遇到位于
既有文献通常通过数据集扩展 83,25,61、基于启发式或学习得到的增强 83,18,17,以及自适应学习 83,48,64 等策略来应对这些观测到的不一致
然而,将这些通用方法直接应用于机器人操作任务时,会受到一系列领域特定约束的阻碍:收集专家示范的成本极其高昂、从推理到执行存在显著时延,以及训练大规模模型所带来的计算负担
为弥合这一差距,来自的研究者提出 χ0,这一整体性框架旨在在物理机器人系统的约束条件下,系统性地消除这些分布失配问题
- 其paper地址为:χ0: Resource-Aware Robust Manipulation via Taming Distributional Inconsistencies
其作者包括
Checheng Yu, Chonghao Sima, Gangcheng Jiang, Hai Zhang, Haoguang Mai, Hongyang Li, Huijie Wang, Jin Chen, Kaiyang Wu, Li Chen, Lirui Zhao, Modi Shi, Ping Luo, Qingwen Bu, Shijia Peng, Tianyu Li, Yibo Yuan - 其blog地址为:mmlab.hk/research/kai0
其GitHub地址为:github.com/OpenDriveLab/kai0
具体而言,该方法建立在三个技术支柱之上,依次缓解这些不一致
- 模型算术(MA):train
MA 旨在将不同的数据子集(
这种方法通过简单地合并在不同
实验表明,MA 提供了一种资源高效的机制,可以在几乎所有指标上提升策略性能;作者发现,在 DAgger 数据上的验证损失可以作为对多个 checkpoint 进行加权的有效启发式指标 - 阶段优势(SA):model
为了在新的部署环境(
图1 展示了这样一个思想:SA 使
此外,SA 通过逐帧奖励建模缓解了先前非阶段方法(如π∗0.62)中固有的数值不稳定性 - Train-Deploy-Alignment (TDA):train
TDA 通过启发式 DAgger 和时空增强,将
作者进一步提出基于时间分块的平滑方法,以减轻推理-执行延迟并增强实时控制稳定性,在策略吞吐量和重试代价方面优于仅使用 RTC 的方法 5,76
且作者在图1中展示了这一思想,即
实验证明,在 TDA 中,DAgger 数据对于最大化成功率至关重要,但代价是更高的重试成本。这种权衡符合直觉:DAgger 样本在恢复场景中最有价值,这意味着更高的重试频率与最终任务成功率正相关。我们还观察到,时空增强只有在与控制优化结合时才是有效的,其中,我们提出的按时间分块的时间平滑与 RTC 5 是相互正交的
1.1.2 相关工作
首先,对于真实世界中的模仿学习与策略部署
- 模仿学习已经成为机器人操作的主流范式,从基于轻量级 Transformer 的策略 95, 16, 15, 92 扩展到基于大量机器人演示数据训练的基础 6, 34, 24, 9, 3, 2]
其中,π series 4,3,2 由于利用大规模预训练数据集而展现出很强的泛化能力而脱颖而出。然而,此类数据集的构建 33,58,8,30,79 需要投入大量资源 - 为提高数据效率,已有工作探索了DAgger 风格的数据聚合 62,32,27,2 和数据增强41,36,91,46
然而,DAgger 在策略 rollout 过程中需要实时人工监督 62,因此数据采集依然十分耗时 - 除此之外,真实世界的部署还给这些策略带来了独特挑战:推理与控制之间的延迟会导致模型输出与物理执行之间的不匹配
先前工作尝试通过执行端的优化 95,5,76 来缓解这一问题,但也引入了额外的推理开销
总之,现有方法往往只针对各个阶段,而不是在整个机器人学习周期:数据收集、模型训练和部署11,75 上联合施加分布一致性约束,作者通过 ,
,
形式化这一挑战,并提出χ0 来对它们进行全面对齐
其次,对于模型合并与权重插值
-
模型合并已成为从多个神经网络整合知识的一种高效策略。早期在计算机视觉和自然语言处理领域的工作表明,在超参数扰动检查点之间对模型权重进行插值84,或在针对不同任务微调后的模型之间进行权重插值 84,29,87,可以提升泛化能力和鲁棒性
-
近年来,这些技术已被扩展到大语言模型 1,89,35、规划 42 和机器人学习 80 等领域
这些方法通常依赖分布内指标来选择合并策略,而这可能无法充分考虑复杂操作任务中常见的幅度较小但关键的分布偏移与χ0的工作并行,RETAIN 88 将模型合并用于自适应 VLA 策略,在提升目标任务的分布外(OOD)泛化能力的同时,更好地保留通用型技能
-
χ0中的ModelArithmetic(MA,模型算术)------专门用于缓解由于专家示范有限、训练覆盖不完整而导致的模型偏差。即作者引入了一种使用 OOD 数据的新型验证协议------具体而言,是通过 DAgger 收集的恢复轨迹------以确保合并后的策略能够泛化到未见过的状态
此外,作者对多种策略合并方法进行了对比分析,包括统一加权、反损失加权、梯度下降和贪心搜索,以识别在减轻训练数据偏差方面最有效的综合方案
最后,对于长时程任务的优势估计
-
先前的工作已经探索了在长时间跨度任务中,将策略条件化在回报、价值和优势上以引导动作选择63, 19, 97, 85,37。这包括优势加权目标,例如优势加权回归(AWR),它使行为克隆偏向于优势更高的动作60
-
在这些思想的基础上,π∗0.6训练了一个分布式价值模型来估计状态-动作优势,并将其用于基于优势条件化的VLA 训练2
然,在实际应用中,一个关键限制是数值不稳定性:由价值差分计算得到的优势(advantages)可能非常嘈杂并且具有高方差,尤其是在具有长时程的真实世界动态环境下
χ0中的Stage Advantage 通过直接从成对观测中预测优势,并基于语义阶段对该信号进行条件化,从而获得更平滑、更稳定的监督信号;该信号还可以被离散化为策略学习所需的二元最优性指示器 12,2
1.1.3 预备知识与问题设定
为了形式化第I 节中介绍的分布式框架,作者考虑一个具有状态空间、动作空间
和时域
的有限期马尔可夫决策过程MDP
-
在固定环境参数化 ξ 下,轨迹
相应地,由随机策略
当策略π 不含歧义时缩写为P -
首先将Preal 定义为在成功完成任务的轨迹上的分布
令
利用 作者现在形式化支撑对齐目标的三个分布
- 训练分布
给定 - 模型
来学习得到62,57 - 最后, 真实机器人的执行通过将
其中
如上文中所讨论的,现实世界部署揭示了这些分布在不同阶段之间存在三种系统性不一致。作者将其归类为:
- 覆盖缺失:
- 时间不匹配:长时域任务在不同阶段会产生视觉上相似但语义上不同的状态,导致
- 失败级联:
而作者的方法试图通过有针对性的对齐策略来解决每一种不一致性,详见下文各节
1.2 χ0的完整方法论
如原论文所述,为了一致地解决上文中识别出的三种分布不一致问题,χ0提出了以下三大技术
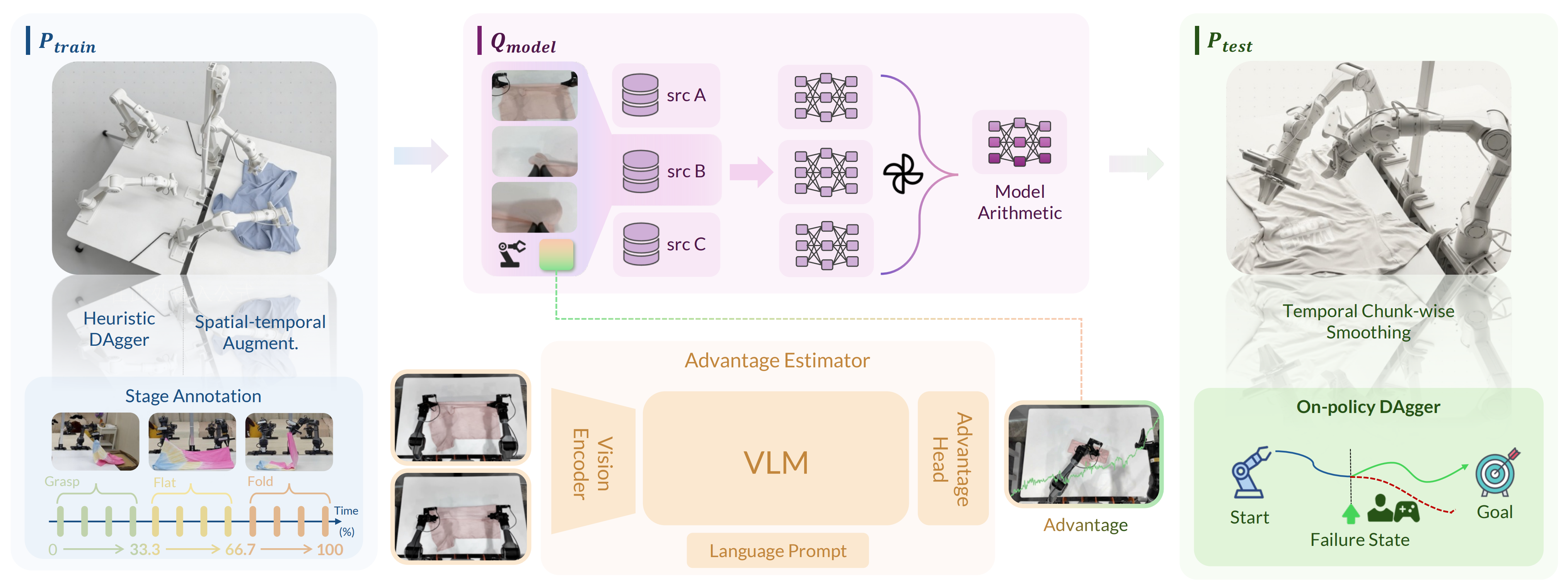
- Model Arithmetic通过在权重空间中合并在互补数据子集上训练的模型来扩展策略覆盖范围
- Stage Advantage 通过阶段感知的优势估计,在策略学习阶段解决时间错配问题,以实现稳定的长时序监督
- Train-Deploy-Alignment 通过推理优化和互补数据增强闭合部署与训练之间的循环
1.2.1 模型算术(Model Arithmetic):在不扩展数据规模的情况下,如何高效地缓解模型偏差
在初始数据收集阶段有限的专家示范导致Ptrain 中的覆盖不足,这进一步使学习到的策略偏向于狭窄的操作模式
- 为缓解这一问题,一个直接的解决方案是扩大量化专家示范数据,直到
- 因此,这引出了一个基本问题:在不扩展数据规模的情况下,如何高效地缓解模型偏差?
对此,作者提出了模型算术(Model Arithmetic, MA),这是一种在权重空间进行合并的策略,通过验证集上的优化来引导,将在互补数据子集上训练得到的策略进行组合
不同于需要显式路由机制和复杂训练设计的Mixture-of-Experts(MoE)方法68, 20,或者将模型输出进行组合的模型集成方法40**,MA 直接在参数层面进行合并,从而合成一个统一的策略
- 形式上,给定从
MA 在这些子集上独立训练策略 - 并通过插值来合成它们的模型权重:
MA 首先将训练数据集D 随机划分为互不重叠的子集,并在每个子集上分别训练策略。由于每个子集的覆盖范围有限,这些策略自然会收敛到解流形上的不同区域。关键挑战随之变为如何最优地合并这些策略
- 在实践中,关键的设计选择在于验证集的选取。作者有策略地构造了一个相对于所有训练子集(in-domain)都是分布外(OOD)的验证集,以确保对合并策略的无偏评估
- 具体而言,作者使用通过DAgger 62, 32 从在各个子集上训练的模型收集到的轨迹,因为这些恢复行为在任何原始训练数据中都自然缺失
基于该验证集,我们实现并对四种souping 策略进行了消融,以获得最终的θmerged��平均加权、反损失、梯度下降以及贪心搜索84------如图3 所示
// 待更