PgSQL的等值inner join选择率
PostgreSQL 的 join 选择率(join selectivity)机制是优化器估算连接结果行数,从而选择最优连接顺序与算法的核心。它依赖列统计信息(MCV、直方图、n_distinct、null_frac)和操作符注册的 oprjoin 函数(如 eqjoinsel)来计算不同连接类型的选择率,并在路径生成与成本估算中使用这些值。
MCV和等频直方图等知识可以查看:PgSQL技术内幕 - 优化器如何估算行数
估算等值连接(内连接)选择率的函数是eqjoinsel_inner,它的参数说明如下:
|-----------------------|---------------------|-------------------------------------------------|
| 参数 | 类型 | 含义 |
| opfuncoid | Oid | 等值操作符对应的函数 OID,用于调用实际比较函数 |
| collation | Oid | 排序规则 OID,传递给比较函数 |
| vardata1/vardata2 | VariableStatData * | 两侧变量的统计信息包装(包括 pg_statistic 元组、rel、ndistinct 等) |
| nd1/nd2 | double | 两侧变量的唯一值数量(ndistinct) |
| isdefault1/isdefault2 | bool | 标记 ndistinct 是否为默认估计值 |
| sslot1/sslot2 | AttStatsSlot * | 两侧的 MCV(Most Common Values)统计槽位 |
| stats1/stats2 | Form_pg_statistic | 两侧的 pg_statistic 表单结构(含 nullfrac 等) |
| have_mcvs1/have_mcvs2 | bool | 标记是否存在 MCV 列表 |
计算方法如下:
1)两边都 有 MCV(最常见值)列表
体现将元组分为热元组和冷元组,分别结算表1的热数据即MCV值的频率、表1的冷数据频率与表2热数据频率、表2的冷数据频率乘积,从而得到两个表的选择率结果。这样通过将冷元组和热元组分离,提高数据库连接选择率计算精度,从而提高连接基数估计,有利于给出最佳的连接顺序,从而提升复杂查询的性能。具体做法如下:
(1)遍历两侧 MCV 列表,用操作符函数逐对比较,找出匹配的 MCV 对,累加其频率乘积作为表1热元组频率*表2热元组频率结果。
(2)计算表1匹配频率和matchfreq1与未匹配 MCV 的频率和unmatchfreq1,计算表2匹配频率和matchfreq2与未匹配 MCV 的频率和unmatchfreq2。以及非 MCV 部分的频率 otherfreq1和otherfreq2。
(3)从两侧视角分别估算总选择率:匹配 MCV 部分 + 未匹配 MCV 与对方非 MCV 随机匹配部分 + 非 MCV 与对方未匹配 MCV+非 MCV 随机匹配部分。
(4)取两侧估计的较小值作为最终选择率,以保守估计。
具体逻辑如下图所示:

为什么表1热元组未匹配部分*表2冷元组一个元组频率可以作为选择率一部分?
从表1角度计算基于这样的假设:表1的未匹配MCV值会与表2的非MCV值随机匹配 , 表2的非MCV值在其不同值之间均匀分布 。所以表2 匹配概率为 otherfreq2 /(nd2 - sslot2->nvalues),其中otherfreq2为表2非MCV部分频率,nd2-sslot2->nvalues为表2非MCV部分值个数,这样就得到表2随机一个值的频率。
为什么otherfreq1*(otherfreq2+unmatchfreq2)/(nd2-nmatches)?
从表1的角度计算还基于这样的假设:表1的非MCV值与表2中未匹配 MCV + 非 MCV 值随机匹配,其中otherfreq1为表1非MCV值频率(冷元组频率),otherfreq2+unmatchfreq2为表2的非MCV值频率+MCV为匹配值频率,nd2-nmatches为表2的MCV未匹配个数+非MCV值个数。
这种方法在数据分布倾斜时能显著提高估计准确性。
2) 至少一侧无 MCV
使用简化公式:selec = (1 - nullfrac1) * (1 - nullfrac2) / max(nd1, nd2),即非空比例乘积除以较大 ndistinct,作为上界估计。
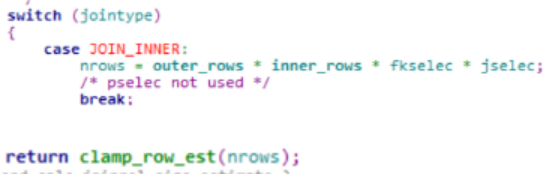
调用路径eqjoinsel(注册在 pg_proc.dat 中作为等值连接的 oprjoin 函数)根据 sjinfo->jointype 决定调用 eqjoinsel_inner(用于 INNER/LEFT/FULL)或 eqjoinsel_semi(用于 SEMI/ANTI)。
上面计算出选择率后,返回到calc_joinrel_size_estimate函数,外表行数*内表行数*inner join选择率计算出估算的基数: