文章目录
- [1. 引言](#1. 引言)
- [2. ChatMemory 概念与架构](#2. ChatMemory 概念与架构)
-
- [2.1 什么是 ChatMemory?](#2.1 什么是 ChatMemory?)
- [2.2 ChatMemory 的架构](#2.2 ChatMemory 的架构)
- [2.3 核心接口](#2.3 核心接口)
- [3. InMemoryChatMemoryRepository:内存存储实现](#3. InMemoryChatMemoryRepository:内存存储实现)
-
- [3.1 工作原理](#3.1 工作原理)
- [3.2 配置方式](#3.2 配置方式)
- [3.3 实现细节分析](#3.3 实现细节分析)
- [3.4 与后续演进的关系](#3.4 与后续演进的关系)
- [4. MessageWindowChatMemory:滑动窗口策略](#4. MessageWindowChatMemory:滑动窗口策略)
-
- [4.1 什么是滑动窗口?](#4.1 什么是滑动窗口?)
- [4.2 为什么需要滑动窗口?](#4.2 为什么需要滑动窗口?)
- [4.3 配置滑动窗口大小](#4.3 配置滑动窗口大小)
- [5. MessageChatMemoryAdvisor:使用 ChatMemory](#5. MessageChatMemoryAdvisor:使用 ChatMemory)
-
- [5.1 什么是 MessageChatMemoryAdvisor?](#5.1 什么是 MessageChatMemoryAdvisor?)
- [5.2 完整使用示例](#5.2 完整使用示例)
- [5.3 执行流程详解](#5.3 执行流程详解)
-
- 核心机制深度解析
-
- [1. 自动上下文注入 (Context Augmentation)](#1. 自动上下文注入 (Context Augmentation))
- [2. "阅后即焚"与持久化](#2. “阅后即焚”与持久化)
- [3. 窗口控制 (Windowing)](#3. 窗口控制 (Windowing))
- [5.4 通过 chatId 实现会话隔离](#5.4 通过 chatId 实现会话隔离)
- [6. Advisor 机制详解](#6. Advisor 机制详解)
-
- [6.1 什么是 Advisor?](#6.1 什么是 Advisor?)
- [6.2 CallAdvisor 接口](#6.2 CallAdvisor 接口)
- [6.3 CallAdvisorChain 拦截链](#6.3 CallAdvisorChain 拦截链)
- [6.4 多 Advisor 执行顺序](#6.4 多 Advisor 执行顺序)
- [7. 自定义 Advisor 实现](#7. 自定义 Advisor 实现)
- [8. ChatMemory 和 Advisor 的协作](#8. ChatMemory 和 Advisor 的协作)
-
- [8.1 MessageChatMemoryAdvisor 的内部实现原理](#8.1 MessageChatMemoryAdvisor 的内部实现原理)
- [8.2 多 Advisor 协作示例](#8.2 多 Advisor 协作示例)
- [9. 实际应用中的最佳实践](#9. 实际应用中的最佳实践)
-
- [9.1 多轮对话实现](#9.1 多轮对话实现)
- [9.2 带有身份的对话](#9.2 带有身份的对话)
- [9.3 监控和日志](#9.3 监控和日志)
- [10. 总结](#10. 总结)
-
- [10.1 关键概念回顾](#10.1 关键概念回顾)
- [10.2 ChatMemory vs Advisor 的分工](#10.2 ChatMemory vs Advisor 的分工)
- [10.3 学习路径建议](#10.3 学习路径建议)
- [10.4 性能和成本考虑](#10.4 性能和成本考虑)
- 附录:常见问题
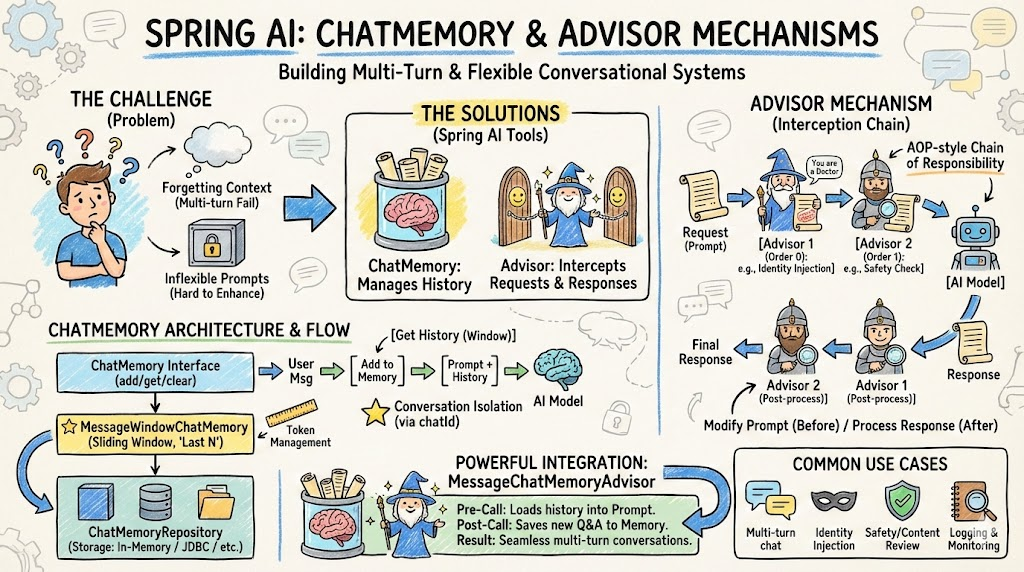
详细讲解 Spring AI 中的聊天记忆(ChatMemory)机制和顾问拦截(Advisor)模式,以及如何通过这两个核心概念构建多轮对话和灵活的提示词增强系统。
1. 引言
在构建 AI 对话应用时,我们经常面临两个核心问题:
-
如何记住对话历史? 用户与 AI 的对话是连续的,AI 需要理解之前的上下文才能给出更准确的回答。简单的单轮问答无法满足现实需求。在传统 Web 应用中,我们使用 Session 和 Cookie 来追踪用户状态。在 AI 对话系统中,我们需要类似的机制来记住用户和 AI 之间的对话历史,这样 AI 才能给出符合上下文的回答。
-
如何灵活修改请求和响应? 在调用大模型之前,我们可能需要增强提示词(添加系统提示、用户身份等);在调用之后,我们可能需要处理或转换响应。例如,某个用户是医学专家,我们希望在系统提示中注入"你是一位医学领域的专家";或者我们希望在响应中添加参考文献、评分等额外信息。
Spring AI 通过两个优雅的机制解决了这两个问题:
- ChatMemory(聊天记忆):自动管理对话历史,支持内存存储和数据库持久化
- Advisor(顾问):基于 AOP 思想,提供请求/响应拦截能力
这两个机制虽然职能不同,但配合使用能够构建强大而灵活的对话系统。
本文将深入讲解这两个机制的原理、用法和最佳实践,帮助开发者理解和运用这些核心功能。
2. ChatMemory 概念与架构
2.1 什么是 ChatMemory?
ChatMemory 是 Spring AI 中管理聊天历史的核心组件。它的职责是:
- 存储:记录用户和 AI 的对话历史
- 检索:在生成新的回答时,将相关的历史消息加入上下文
- 隔离:通过对话 ID(Conversation ID)实现不同用户/会话的隔离
- 管理:实现滑动窗口、记忆容量控制等策略
2.2 ChatMemory 的架构
Spring AI 中 ChatMemory 的架构分为三层:
java
┌─────────────────────────────────────┐
│ ChatMemory 接口 │
│ - add() │
│ - get() │
│ - clear() │
└──────────────┬──────────────────────┘
│
┌──────────────▼──────────────────────┐
│ MessageWindowChatMemory │
│ (实现滑动窗口策略) │
│ - 限制消息数量 │
│ - FIFO 淘汰机制 │
└──────────────┬──────────────────────┘
│
┌──────────────▼──────────────────────┐
│ ChatMemoryRepository │
│ (底层存储实现) │
│ - InMemoryChatMemoryRepository │
│ - JdbcChatMemoryRepository │
│ - ElasticsearchChatMemoryRepository│
└─────────────────────────────────────┘2.3 核心接口
java
public interface ChatMemory {
// 向指定对话添加消息
void add(String conversationId, List<Message> messages);
// 从指定对话获取消息
List<Message> get(String conversationId, int lastN);
// 清空指定对话的消息
void clear(String conversationId);
}
public interface ChatMemoryRepository {
// 这是真正的存储实现接口
void add(String conversationId, Message message);
List<Message> get(String conversationId, int lastN);
void clear(String conversationId);
}3. InMemoryChatMemoryRepository:内存存储实现
3.1 工作原理
InMemoryChatMemoryRepository 是最简单的实现,所有对话历史都存储在应用内存中。它内部维护一个 ConcurrentHashMap,键是对话 ID(conversationId),值是该对话的所有消息列表:
java
// 内部结构示意
private Map<String, List<Message>> conversationMap;
// conversationId -> 对话消息列表
// "user123_chat1" -> [Message1, Message2, Message3, ...]
// "user456_chat2" -> [Message4, Message5, ...]当调用 add() 方法时,InMemoryChatMemoryRepository 将新消息追加到对应 conversationId 的列表中:
java
Timeline:
时刻 1: user123 问"今天几号?"
→ store: {"user123": [UserMessage("今天几号?")]}
时刻 2: AI 回答"今天是 2月12号"
→ store: {"user123": [UserMessage("今天几号?"), AssistantMessage("今天是 2月12号")]}
时刻 3: user123 问"天气怎么样?"
→ store: {"user123": [UserMessage("今天几号?"), AssistantMessage("今天是 2月12号"), UserMessage("天气怎么样?")]}当调用 get(conversationId, lastN) 方法时,它返回最近 N 条消息。这里的 lastN 通常由 MessageWindowChatMemory 指定。
优点:
- 实现简单,无需外部依赖(无需数据库、Redis 等)
- 速度快,完全在内存中,无 I/O 操作
- 开发测试方便,快速验证想法
缺点:
- 应用重启后数据丢失,用户的对话历史无法恢复
- 无法在分布式环境中共享,多个应用实例之间无法共享对话历史
- 内存占用随着对话增多而增加,长期运行的应用可能面临内存压力
- 无法处理大规模用户场景
3.2 配置方式
在 Spring AI 中配置内存存储非常简单。在我们的 SpringAIApplication 配置类中:
java
@Bean
public ChatMemory chatMemory() {
// 创建内存存储库
InMemoryChatMemoryRepository inMemoryChatMemoryRepository =
new InMemoryChatMemoryRepository();
// 包装成 MessageWindowChatMemory
// 默认窗口大小为 10 条消息
return MessageWindowChatMemory.builder()
.chatMemoryRepository(inMemoryChatMemoryRepository)
.build();
}这个 Bean 会被 Spring 容器管理,在任何地方都可以通过 @Autowired 注入使用。
3.3 实现细节分析
InMemoryChatMemoryRepository 的核心实现逻辑大致如下
java
package org.springframework.ai.chat.memory;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import org.springframework.ai.chat.messages.Message;
import org.springframework.util.Assert;
/**
* An in-memory implementation of {@link ChatMemoryRepository}.
*
* @author Thomas Vitale
* @since 1.0.0
*/
public final class InMemoryChatMemoryRepository implements ChatMemoryRepository {
Map<String, List<Message>> chatMemoryStore = new ConcurrentHashMap<>();
@Override
public List<String> findConversationIds() {
return new ArrayList<>(this.chatMemoryStore.keySet());
}
@Override
public List<Message> findByConversationId(String conversationId) {
Assert.hasText(conversationId, "conversationId cannot be null or empty");
List<Message> messages = this.chatMemoryStore.get(conversationId);
return messages != null ? new ArrayList<>(messages) : List.of();
}
@Override
public void saveAll(String conversationId, List<Message> messages) {
Assert.hasText(conversationId, "conversationId cannot be null or empty");
Assert.notNull(messages, "messages cannot be null");
Assert.noNullElements(messages, "messages cannot contain null elements");
this.chatMemoryStore.put(conversationId, messages);
}
@Override
public void deleteByConversationId(String conversationId) {
Assert.hasText(conversationId, "conversationId cannot be null or empty");
this.chatMemoryStore.remove(conversationId);
}
}一个基于内存的聊天记录存储库:
- 功能:管理多个对话的聊天消息,支持增删查操作
- 核心结构 :使用
ConcurrentHashMap存储<对话ID, 消息列表>映射 - 线程安全:通过并发集合保证多线程环境下的数据一致性
- 主要方法 :
findConversationIds():获取所有对话IDfindByConversationId():根据ID查询消息列表saveAll():保存指定对话的所有消息deleteByConversationId():删除指定对话的全部记录
- 参数校验 :使用Spring的
Assert工具确保输入有效性
3.4 与后续演进的关系
InMemoryChatMemoryRepository会演进为使用 JdbcChatMemoryRepository,将对话历史持久化到 MySQL 数据库,从而支持:
- 应用重启后的数据恢复
- 分布式环境中的数据共享
- 更大规模的用户和对话数据
这种渐进式的演进展示了 Spring AI 架构的灵活性------只需要替换 Repository 实现,其他代码无需改动。
4. MessageWindowChatMemory:滑动窗口策略
4.1 什么是滑动窗口?
MessageWindowChatMemory 实现了滑动窗口策略,即在 get() 时只返回最近 N 条消息。
java
对话历史(按时间排序):
Message1 (最久)
Message2
Message3
Message4
Message5
Message6
Message7 (最新)
设置 lastN=3,get() 返回:
Message5
Message6
Message74.2 为什么需要滑动窗口?
- 控制上下文长度:大模型对输入 token 数有限制,我们不能把所有对话历史都传给模型
- 成本优化:更少的 token 意味着更低的 API 成本
- 性能提升:减少不相关的历史信息,让模型专注于最近的对话
- 质量改善:过长的上下文反而可能降低模型的回答质量
4.3 配置滑动窗口大小
java
@Bean
public ChatMemory chatMemory() {
return MessageWindowChatMemory.builder()
.chatMemoryRepository(new InMemoryChatMemoryRepository())
.windowSize(10) // 保留最近 10 条消息
.build();
}默认窗口大小是 10 条消息,可根据实际需求调整。
5. MessageChatMemoryAdvisor:使用 ChatMemory
5.1 什么是 MessageChatMemoryAdvisor?
MessageChatMemoryAdvisor 是 Spring AI 中内置的一个 Advisor,专门用于在对话流程中集成 ChatMemory。它的职责是:
- 对话前:将之前的对话历史从 ChatMemory 中加载出来,添加到 Prompt 中
- 对话后:将新的用户问题和 AI 回答保存到 ChatMemory 中
5.2 完整使用示例
java
@GetMapping("/memory")
public String memory(@RequestParam("chatId") String chatId,
@RequestParam("question") String question) {
return chatClient
.prompt()
// 添加 MessageChatMemoryAdvisor
.advisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
// 设置对话 ID,实现会话隔离
.advisors(advisorSpec -> advisorSpec.params(
Map.of(ChatMemory.CONVERSATION_ID, chatId)
))
// 用户问题
.user(question)
// 调用大模型
.call()
.content();
}5.3 执行流程详解
当上面这个接口被调用时,完整的执行流程如下:
java
1. 用户发起请求:/memory?chatId=user123&question=天气怎么样?
2. MessageChatMemoryAdvisor 在对话前执行:
- 从 ChatMemory 中获取对话 ID 为 "user123" 的历史消息
- 假设历史是:
* User: 今天几号?
* Assistant: 今天是 2月12号
- 将这些历史消息自动添加到 Prompt 中
3. 增强后的 Prompt 结构:
┌─────────────────────────────────┐
│ System Message │
│ (默认系统提示) │
├─────────────────────────────────┤
│ History │
│ User: 今天几号? │
│ Assistant: 今天是 2月12号 │
├─────────────────────────────────┤
│ Current User Message │
│ User: 天气怎么样? │
└─────────────────────────────────┘
4. 调用大模型(Qwen3-max):
- 模型看到了完整的对话历史
- 能够理解上下文并给出准确回答
- Response: 根据历史和当前问题,给出回答
5. MessageChatMemoryAdvisor 在对话后执行:
- 将用户问题添加到 ChatMemory:
* Message(User, "天气怎么样?")
- 将 AI 回答添加到 ChatMemory:
* Message(Assistant, "根据天气预报...")
- 后续对话就能看到这些新消息了
6. 返回 AI 的回答给前端如下时序图详细展示了 Spring AI 中 MessageChatMemoryAdvisor 如何作为"拦截器"介入对话生命周期,实现自动化的上下文管理。
大语言模型 (Qwen3-max) ChatMemory (In-Memory/Redis) MessageChatMemoryAdvisor 用户 大语言模型 (Qwen3-max) ChatMemory (In-Memory/Redis) MessageChatMemoryAdvisor 用户 1. 前置处理 (Before Call) 2. 增强 Prompt 并调用 3. 后置处理 (After Call) 4. 响应返回 发起请求 (chatId="user123", "天气怎么样?") 1 get("user123") 获取历史消息 2 返回: User: 今天几号?, Assistant: 2月12号 3 拼接 历史消息 + 当前消息 4 发送增强后的完整 Context 5 返回 AI 回答: "今天天气晴朗..." 6 add("user123", 当前 User 消息) 7 add("user123", 当前 Assistant 回答) 8 返回最终回答 9
核心机制深度解析
1. 自动上下文注入 (Context Augmentation)
Advisor 的核心价值在于它让开发者无需手动维护消息列表。在第 4 步中,它自动完成了消息的合路:
- System Message: 保持模型行为。
- History: 提供记忆,让模型知道"2月12号"这个时间背景。
- Current Message: 用户的即时需求。
2. "阅后即焚"与持久化
在第 8-9 步中,Advisor 会在 LLM 成功响应后,将这一轮新的对话对(Pair)异步或同步地存入存储介质。Spring AI 支持多种 ChatMemory 实现:
- InMemoryChatMemory: 适用于简单测试或 Demo。
- Cassandra/RedisChatMemory: 适用于生产环境,支持分布式和持久化。
3. 窗口控制 (Windowing)
虽然你的示例显示了全部历史,但在实际应用中,MessageChatMemoryAdvisor 通常会配置一个 last-n-messages 参数。
💡 贴士: 如果不限制长度,随着对话增加,Prompt 会迅速超出 LLM 的 Token 上限。
5.4 通过 chatId 实现会话隔离
chatId 是实现多用户、多会话隔离的关键:
java
用户 A 的会话:
chatId = "userA_chat_001"
对话历史:["你好", "今天天气如何", ...]
用户 B 的会话:
chatId = "userB_chat_001"
对话历史:["Hi", "Tell me a joke", ...]
用户 A 的第二个会话:
chatId = "userA_chat_002"
对话历史:["新建对话", ...]
ChatMemory 内部存储:
{
"userA_chat_001": [Message1, Message2, ...],
"userB_chat_001": [Message3, Message4, ...],
"userA_chat_002": [Message5, ...]
}每个 chatId 对应一个独立的对话线程,彼此不干扰。
6. Advisor 机制详解
6.1 什么是 Advisor?
Advisor 是 Spring AI 借鉴 AOP(面向切面编程)思想设计的拦截机制。它允许开发者在以下时机干预对话流程:
- 对话前:修改 Prompt、添加系统信息、注入上下文
- 对话后:处理、转换、验证或增强 AI 的回答
Advisor 的核心是职责链模式(Chain of Responsibility),支持多个 Advisor 串联执行。
6.2 CallAdvisor 接口
java
public interface CallAdvisor {
/**
* 拦截 ChatClient 的调用
* @param chatClientRequest 包含 Prompt 等信息的请求对象
* @param callAdvisorChain 调用链,用于传递给下一个 Advisor
* @return 修改或原始的响应
*/
ChatClientResponse adviseCall(
ChatClientRequest chatClientRequest,
CallAdvisorChain callAdvisorChain
);
/**
* Advisor 的名称,用于日志和调试
*/
String getName();
/**
* 执行顺序,数字越小越先执行
* 默认值:Advisor.DEFAULT_ORDER (0)
*/
int getOrder();
}6.3 CallAdvisorChain 拦截链
CallAdvisorChain 是职责链模式的实现,它负责按照 getOrder() 的升序依次调用多个 Advisor:
java
public interface CallAdvisorChain {
/**
* 将控制权传递给下一个 Advisor
*/
ChatClientResponse nextCall(ChatClientRequest request);
}6.4 多 Advisor 执行顺序
当多个 Advisor 同时配置时,Spring AI 按照 getOrder() 值的升序执行:
java
chatClient
.prompt()
.advisors(advisorA) // getOrder() = 0
.advisors(advisorB) // getOrder() = 1
.advisors(advisorC) // getOrder() = 2
.user("问题")
.call()
执行顺序:
advisorA.adviseCall()
↓
advisorB.adviseCall()
↓
advisorC.adviseCall()
↓
chatClient.call()
↓
advisorC 返回响应
↓
advisorB 返回响应
↓
advisorA 返回响应
↓
最终响应返回给用户这种设计使得 Advisor 既可以修改请求,也可以修改响应,形成了一个完整的拦截链。
7. 自定义 Advisor 实现
7.1 完整示例:ArtisanCallAroundAdvisor
自定义 Advisor:
java
static class ArtisanCallAroundAdvisor implements CallAdvisor {
@Override
public ChatClientResponse adviseCall(
ChatClientRequest chatClientRequest,
CallAdvisorChain callAdvisorChain) {
// 对话前
System.out.println("before...");
// 获取原始 Prompt
Prompt prompt = chatClientRequest.prompt();
// 增强系统提示词
Prompt enhancedPrompt = prompt.augmentSystemMessage("我是周瑜");
// 创建修改后的请求
ChatClientRequest modifiedRequest = chatClientRequest
.mutate()
.prompt(enhancedPrompt)
.build();
// 传递给下一个 Advisor 或调用大模型
ChatClientResponse advisedResponse = callAdvisorChain.nextCall(modifiedRequest);
// 对话后
System.out.println("after...");
return advisedResponse;
}
@Override
public String getName() {
return this.getClass().getSimpleName();
}
@Override
public int getOrder() {
// 数字越小,越先执行
return 0;
}
}7.2 使用自定义 Advisor
java
@GetMapping("/advisor")
public String advisor(String question) {
return this.chatClient
.prompt()
.advisors(new ArtisanCallAroundAdvisor())
.user(question)
.call()
.content();
}7.3 artisanCallAroundAdvisor 的执行过程
当调用 /advisor?question=你是谁? 时:
java
1. chatClient 开始处理请求
2. artisanCallAroundAdvisor.adviseCall() 被调用
3. 打印 "before..."
4. 原始 Prompt:
System: [默认系统提示]
User: 你是谁?
5. 增强后的 Prompt:
System: [默认系统提示]\n我是周瑜
User: 你是谁?
6. 调用链继续,最终调用 Qwen3-max 大模型
- 模型看到了增强后的系统提示
- 会回答:"我是周瑜,一位 AI 助手..."
7. 返回响应
8. 打印 "after..."
9. 返回最终结果给客户端如下图展示 Spring AI 中自定义 Advisor(拦截器模式)执行流程的时序图。它体现了在请求发送给大模型之前和之后,如何通过 AOP(面向切面编程)思想对 Prompt 进行动态增强。
日志/控制台 Qwen3-max LLM artisanCallAroundAdvisor ChatClient 日志/控制台 Qwen3-max LLM artisanCallAroundAdvisor ChatClient 1. 进入拦截链路 2. 前置处理 (Before) 3. Prompt 动态增强 4. 模型交互 System: 默认\n我是周瑜 User: 你是谁? 5. 后置处理 (After) 6. 结果回传 adviseCall(request) 1 打印 "before..." 2 注入 "我是周瑜" 到 System Message 3 发送增强后的 Prompt 4 返回: "我是周瑜,一位 AI 助手..." 5 打印 "after..." 6 返回最终响应内容 7
核心原理解析
- 环绕通知 (Around Advice) :
adviseCall()方法模拟了标准 AOP 的环绕行为。它完全控制了从ChatClient到Model的传递过程,允许你在请求发出前修改PromptRequest,在响应返回后修改ChatResponse。 - System Prompt 注入:在第 5 步中,通过在系统消息末尾追加身份说明,强行改变了模型的角色设定。这比在用户消息中手动添加前缀更加优雅且不容易被模型忽略。
- 可插拔性 :Advisor 是 Spring AI 的核心设计之一。你可以轻松地将
artisanCallAroundAdvisor注册到特定的ChatClient实例中,而无需修改具体的业务调用逻辑。
这种模式的常见用途
这种 Advisor 模式在企业开发中还常用于:
- 敏感词过滤 :在
before阶段检查用户输入,在after阶段脱敏 AI 回答。 - Token 消耗统计 :在
after阶段记录当前请求消耗的输入/输出 Token 数量。 - 多租户隔离:动态地根据当前上下文为请求注入特定的 API Key。
7.4 Advisor 的常见应用场景
场景 1:注入身份信息
java
public ChatClientResponse adviseCall(
ChatClientRequest request,
CallAdvisorChain chain) {
Prompt prompt = request.prompt()
.augmentSystemMessage("你是一个医学专家,擅长诊断疾病");
return chain.nextCall(request.mutate().prompt(prompt).build());
}场景 2:添加安全约束
java
public ChatClientResponse adviseCall(
ChatClientRequest request,
CallAdvisorChain chain) {
Prompt prompt = request.prompt()
.augmentSystemMessage("不要讨论政治、宗教等敏感话题");
return chain.nextCall(request.mutate().prompt(prompt).build());
}场景 3:响应内容审查
java
public ChatClientResponse adviseCall(
ChatClientRequest request,
CallAdvisorChain chain) {
ChatClientResponse response = chain.nextCall(request);
String content = response.getResult().getOutput().getContent();
// 对响应内容进行处理
if (content.contains("不允许的词")) {
// 过滤或修改响应
}
return response;
}场景 4:性能监控和日志
java
public ChatClientResponse adviseCall(
ChatClientRequest request,
CallAdvisorChain chain) {
long startTime = System.currentTimeMillis();
ChatClientResponse response = chain.nextCall(request);
long duration = System.currentTimeMillis() - startTime;
logger.info("模型调用耗时: {}ms", duration);
return response;
}8. ChatMemory 和 Advisor 的协作
MessageChatMemoryAdvisor 是 Advisor 机制的最佳实践示例,它展示了如何将 ChatMemory 集成到对话流程中:
8.1 MessageChatMemoryAdvisor 的内部实现原理
可以推断其工作原理:
java
public class MessageChatMemoryAdvisor implements CallAdvisor {
private final ChatMemory chatMemory;
@Override
public ChatClientResponse adviseCall(
ChatClientRequest request,
CallAdvisorChain chain) {
// 1. 获取对话 ID
String conversationId = request.params().get(ChatMemory.CONVERSATION_ID);
// 2. 从 ChatMemory 加载历史消息
List<Message> historyMessages = chatMemory.get(conversationId, 10);
// 3. 将历史消息添加到 Prompt 中
Prompt originalPrompt = request.prompt();
Prompt enhancedPrompt = originalPrompt.addMessages(historyMessages);
// 4. 创建修改后的请求
ChatClientRequest modifiedRequest = request.mutate()
.prompt(enhancedPrompt)
.build();
// 5. 调用下一个 Advisor 或大模型
ChatClientResponse response = chain.nextCall(modifiedRequest);
// 6. 保存新消息到 ChatMemory
Message userMessage = new Message(MessageType.USER,
request.prompt().getUserMessage().getContent());
Message assistantMessage = new Message(MessageType.ASSISTANT,
response.getResult().getOutput().getContent());
chatMemory.add(conversationId, List.of(userMessage, assistantMessage));
return response;
}
@Override
public String getName() {
return "MessageChatMemoryAdvisor";
}
@Override
public int getOrder() {
// 默认值使得它在大多数其他 Advisor 前执行
return Integer.MIN_VALUE + 1000;
}
}8.2 多 Advisor 协作示例
在实际应用中,我们经常需要多个 Advisor 协作。比如在 /ragAdvisor2 接口中:
java
@GetMapping("/ragAdvisor2")
public String ragAdvisor2(@RequestParam("chatId") String chatId,
@RequestParam("question") String question) {
return chatClient
.prompt()
// Advisor 1: RAG 增强
.advisors(retrievalAugmentationAdvisor) // order: 0
// Advisor 2: 记忆管理
.advisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
// order: Integer.MIN_VALUE + 1000
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, chatId))
.user(question)
.call()
.content();
}
clike
执行顺序(order 升序):
1. MessageChatMemoryAdvisor (order: 很小)
- 加载历史对话
2. RetrievalAugmentationAdvisor (order: 0)
- 向量搜索
- 检索相关文档
3. 大模型调用
- 看到完整的:历史对话 + 检索的文档 + 当前问题
4. RetrievalAugmentationAdvisor 返回
5. MessageChatMemoryAdvisor 保存新消息
- 注意:保存的是 RAG 增强后的完整 Prompt 信息代码中有一个重要的注释,说明了 order 的影响:
java
// .order(1) // 默认 MessageChatMemoryAdvisor 的 order 为
// Integer.MIN_VALUE+1000,会排在 RetrievalAugmentationAdvisor 的前面,
// 导致 chatMemory 中存的是原始的 query,而不是 RAG 增强后的 query,
// 可以调整 order 为 1,使得排在 RetrievalAugmentationAdvisor 的后面,
// RetrievalAugmentationAdvisor 的 order 默认为 0,从而使得 chatMemory
// 中存的是 RAG 增强后的 query这个细节说明了在多 Advisor 场景中,order 的设置至关重要。
9. 实际应用中的最佳实践
9.1 多轮对话实现
java
@GetMapping("/multi-turn-chat")
public String multiTurnChat(@RequestParam("chatId") String chatId,
@RequestParam("question") String question) {
return chatClient
.prompt()
.system("你是一个友好的客服助手,尽可能给出准确和有帮助的答案")
.advisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, chatId))
.user(question)
.call()
.content();
}前端可以这样使用:
javascript
// 会话 1
fetch('/multi-turn-chat?chatId=session_001&question=春天有什么好吃的?')
// 会话 1 的对话历史不会混入会话 2
// 会话 2
fetch('/multi-turn-chat?chatId=session_002&question=夏天去哪里玩?')
// 彼此独立9.2 带有身份的对话
java
@GetMapping("/doctor-chat")
public String doctorChat(@RequestParam("chatId") String chatId,
@RequestParam("question") String question) {
return chatClient
.prompt()
.advisors(new DoctorIdentityAdvisor()) // order: 0
.advisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, chatId))
.user(question)
.call()
.content();
}
static class DoctorIdentityAdvisor implements CallAdvisor {
@Override
public ChatClientResponse adviseCall(
ChatClientRequest request,
CallAdvisorChain chain) {
Prompt prompt = request.prompt()
.augmentSystemMessage("你是一位有 20 年临床经验的医生," +
"专长是内科疾病诊断。" +
"在给出建议前,请先详细询问患者的症状。");
return chain.nextCall(request.mutate().prompt(prompt).build());
}
@Override
public String getName() {
return "DoctorIdentityAdvisor";
}
@Override
public int getOrder() {
return 0;
}
}9.3 监控和日志
java
static class LoggingAdvisor implements CallAdvisor {
private static final Logger logger = LoggerFactory.getLogger(LoggingAdvisor.class);
@Override
public ChatClientResponse adviseCall(
ChatClientRequest request,
CallAdvisorChain chain) {
long startTime = System.currentTimeMillis();
String userMessage = request.prompt().getUserMessage().getContent();
logger.info("开始调用大模型,用户问题: {}", userMessage);
ChatClientResponse response = chain.nextCall(request);
long duration = System.currentTimeMillis() - startTime;
logger.info("大模型调用完成,耗时: {}ms", duration);
return response;
}
@Override
public String getName() {
return "LoggingAdvisor";
}
@Override
public int getOrder() {
// 最后执行,不影响其他 Advisor
return Integer.MAX_VALUE;
}
}10. 总结
10.1 关键概念回顾
| 概念 | 作用 | 核心类 |
|---|---|---|
| ChatMemory | 管理聊天历史,支持多会话隔离 | ChatMemory, ChatMemoryRepository |
| MessageWindowChatMemory | 实现滑动窗口策略,限制消息数量 | MessageWindowChatMemory |
| InMemoryChatMemoryRepository | 在内存中存储对话历史 | InMemoryChatMemoryRepository |
| Advisor | 拦截 ChatClient 调用,修改请求和响应 | CallAdvisor, CallAdvisorChain |
| MessageChatMemoryAdvisor | 内置的 Advisor,集成 ChatMemory | MessageChatMemoryAdvisor |
10.2 ChatMemory vs Advisor 的分工
- ChatMemory:专注于"数据"(对话历史的存储和检索)
- Advisor:专注于"流程"(请求和响应的拦截和修改)
两者结合,形成了一个强大的对话系统基础设施。
10.3 学习路径建议
- 入门级:使用 InMemoryChatMemoryRepository + MessageChatMemoryAdvisor,实现简单的多轮对话
- 进阶:自定义 Advisor,实现身份注入、安全约束等功能
- 高级:多 Advisor 协作,结合 RAG、向量搜索等技术,构建复杂的对话系统
- 生产:使用 JdbcChatMemoryRepository,持久化到数据库,支持应用重启后的对话恢复
10.4 性能和成本考虑
- 内存占用:使用滑动窗口限制消息数量,避免内存溢出
- API 成本:更少的上下文 token 意味着更低的成本,合理设置窗口大小很重要
- 响应速度:历史消息的加载和保存有一定开销,但相比模型调用可以忽略不计
- 数据库:生产环境建议使用 JdbcChatMemoryRepository,支持分布式部署
附录:常见问题
Q1: ChatMemory 中的消息什么时候被删除?
A: 有两种情况:
- 滑动窗口:get() 时自动只返回最近 N 条消息
- 显式清空:调用 clear(conversationId) 方法
但历史消息本身不会自动删除,除非手动清空。如果需要自动过期策略,应该在 Repository 实现中添加。
Q2: 能否在一个 Advisor 中访问 ChatMemory?
A: 可以,Advisor 的 adviseCall() 方法可以访问任何 Spring Bean:
java
@Component
static class CustomAdvisor implements CallAdvisor {
@Autowired
private ChatMemory chatMemory;
@Override
public ChatClientResponse adviseCall(
ChatClientRequest request,
CallAdvisorChain chain) {
// 可以访问 ChatMemory
List<Message> history = chatMemory.get(conversationId, 5);
return chain.nextCall(request);
}
}Q3: 多个 Advisor 修改 Prompt 会怎样?
A: 它们会逐个应用,每个 Advisor 都在前一个的基础上进行修改:
java
原始 Prompt:
System: []
User: 问题
Advisor1 增强:
System: [身份信息]
User: 问题
Advisor2 增强:
System: [身份信息]\n[安全约束]
User: 问题
Advisor3 增强:
System: [身份信息]\n[安全约束]\n[上下文]
User: 问题Q4: ChatMemory 中的 conversationId 如何生成?
A: 由调用方指定,通常可以:
- 使用用户 ID
- 使用会话 UUID(UUID.randomUUID())
- 使用业务 ID(如订单号、问题 ticket 号)
只要保证同一个对话的所有请求使用相同的 chatId 即可。
参考资源:
- Spring AI 官方文档:https://docs.spring.io/spring-ai/
- Spring AI GitHub 仓库:https://github.com/spring-projects/spring-ai
