文章目录
- 前言
- 一、工程配置
-
- 创建虚拟环境
- [当前工程环境选择python inceptor](#当前工程环境选择python inceptor)
- 示范(无验证过,但是可以大概知道这是干什么的)
-
- [Demo 目标:清洗和优化一组成语故事文本](#Demo 目标:清洗和优化一组成语故事文本)
- 第一步:准备环境(非常简单)
- 第二步:准备示例数据
- 第三步:创建清洗配方(Config)
- 第四步:运行清洗流程
- 第五步:查看清洗结果
- [结果分析:Data-Juicer 做了什么?](#结果分析:Data-Juicer 做了什么?)
- 资料获取

前言
博主介绍:✌目前全网粉丝4W+,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者、专注于Java后端技术领域。
涵盖技术内容:Java后端、大数据、算法、分布式微服务、中间件、前端、运维等。
博主所有博客文件目录索引:博客目录索引(持续更新)
CSDN搜索:长路
视频平台:b站-Coder长路
一、工程配置
创建虚拟环境
这是最安全且符合 Python 最佳实践的方法。虚拟环境会创建一个独立的隔离环境,不会影响系统级的 Python 环境。
创建虚拟环境:
shell
python3 -m venv myenv这会在当前目录下创建一个名为 myenv的虚拟环境文件夹。
激活虚拟环境:
shell
source myenv/bin/activate激活后,你的命令行提示符通常会显示环境名称(如 (myenv))。
在虚拟环境中安装包:
shell
python3 -m pip install py-data-juicer现在包会被安装到虚拟环境中,完全独立于系统环境。
使用后停用虚拟环境:
shell
deactivate当前工程环境选择python inceptor
创建了虚拟环境后,当前目录就有一个环境
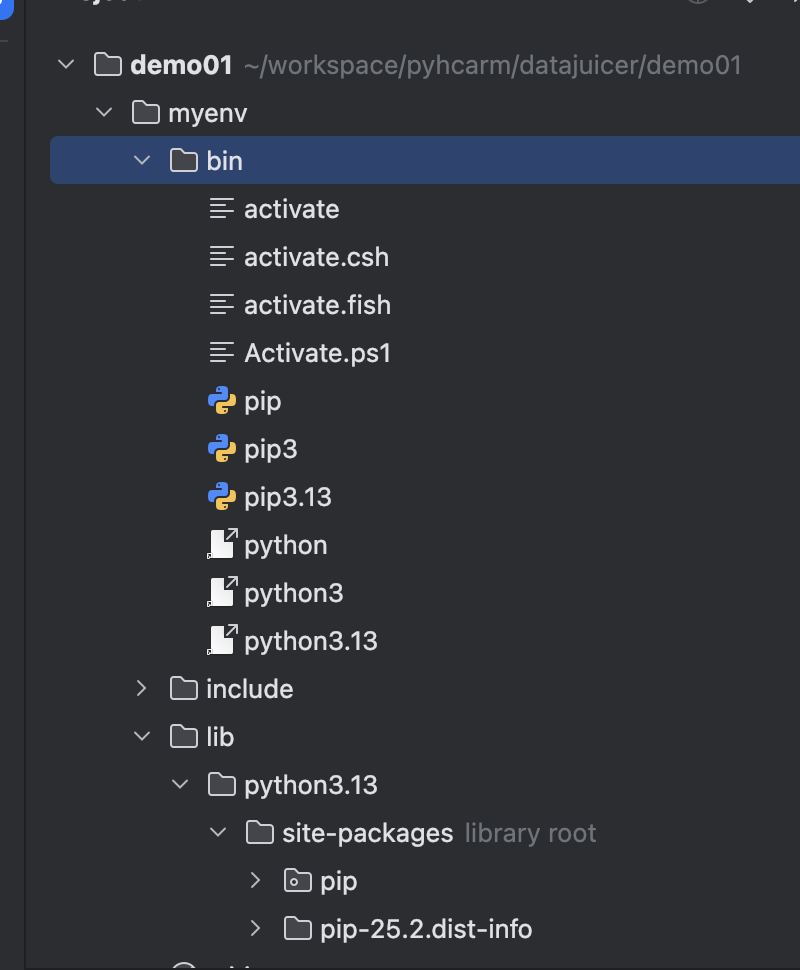
来配置下:
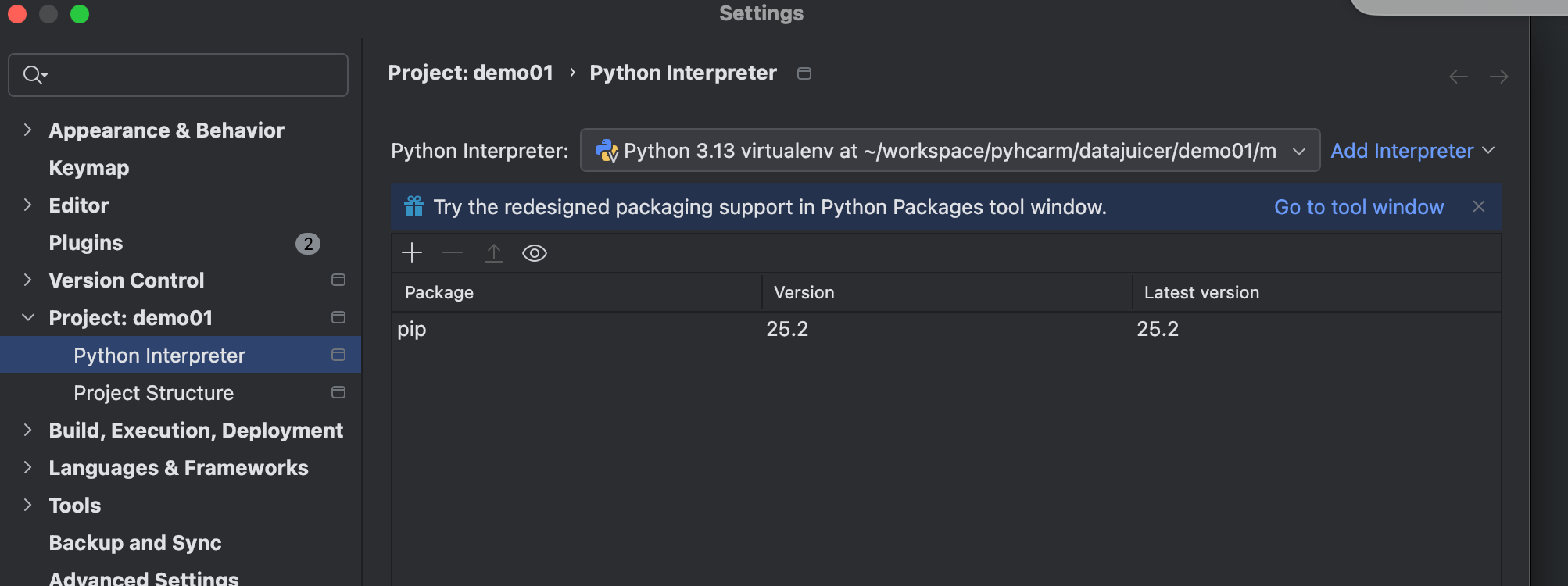
选择镜像源安装:
shell
python3 -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple py-data-juicer查看当前环境:
shell
python3 -m site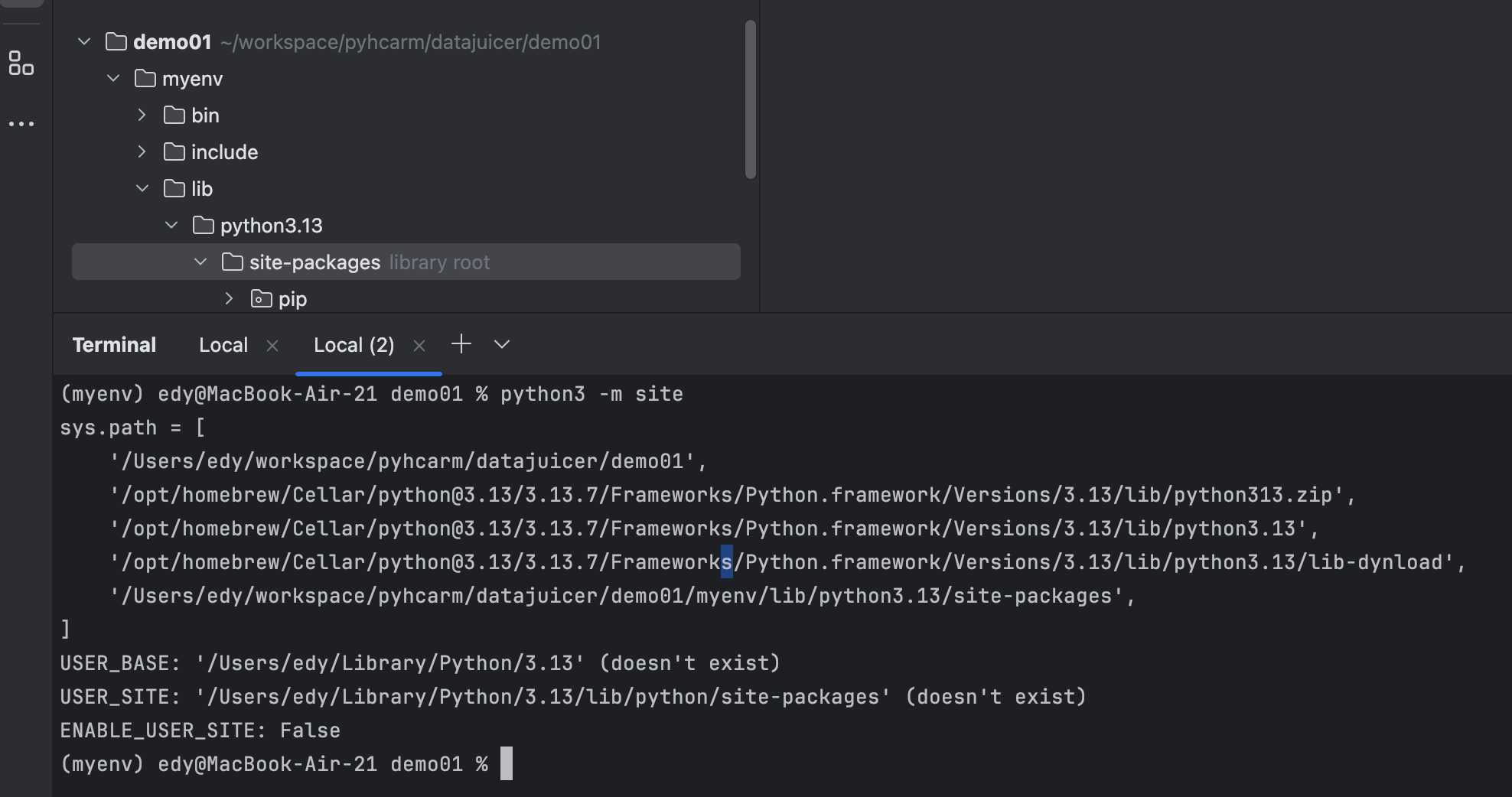
示范(无验证过,但是可以大概知道这是干什么的)
Demo 目标:清洗和优化一组成语故事文本
我们将模拟一个非常常见的场景:你从网上爬取或通过其他解析工具(比如火山引擎的PDF解析)得到了一批文本数据,但这些数据质量参差不齐,需要清洗后才能用于训练大模型。
第一步:准备环境(非常简单)
只需一行命令,即可安装 Data-Juicer 及其基础依赖。
plain
pip install py-data-juicer请注意:为了这个demo的简洁性,我们使用最轻量的安装方式。某些需要额外依赖的算子(如需要NLP模型进行质量评估的)可能无法运行,但这完全不影响我们体验核心功能。
第二步:准备示例数据
让我们创建一个包含一些"脏数据"的示例文件 dirty_data.jsonl。每一行是一个 JSON 对象,代表一条文本数据。
plain
# 创建并编辑我们的数据文件
cat > ./dirty_data.jsonl << EOF
{"text": "凿壁偷光\\n西汉时期,有个农民家的孩子叫匡衡。他小时候很想读书,可是家里穷,没钱上学。后来,他跟一个亲戚学认字,才有了看书的能力。 匡衡买不起书,只好借书来读。那个时候,书是非常贵重的,有书的人不肯轻易借给别人。匡衡就在农忙的时节,给有钱的人家打短工,不要工钱,只求人家借书给他看。\\n过了几年,匡衡长大了,成了家里的主要劳动力。他一天到晚在地里干活,只有中午歇晌的时候,才有工夫看一点书,所以一卷书常常要十天半月才能够读完。匡衡很着急,心里想:白天种庄稼,没有时间看书,我可以多利用一些晚上的时间来看书。可是匡衡家里很穷,买不起点灯的油,怎么办呢?\\n有一天晚上,匡衡躺在床上背白天读过的书。背着背着,突然看到东边的墙壁上透过来一线亮光。他嚯地站起来,走到墙壁边一看,啊!原来从壁缝里透过来的是邻居的灯光。于是,匡衡想了一个办法:他拿了一把小刀,把墙缝挖大了一些。这样,透过来的光亮也大了,他就凑着透进来的灯光,读起书来。\\n匡衡就是这样刻苦地学习,后来成了一个很有学问的人。\\n这个故事告诉我们,要努力学习知识。"}
{"text": " 刻舟求剑 这是一个关于楚国人的故事,他在坐船过江时,不小心把剑掉入了水中。 他在船上刻了一个记号,说:我的剑是从这里掉下去的。等船靠岸后,他从记号处跳下水去找剑,结果自然找不到。这个故事很愚蠢。 "}
{"text": "这是一篇无效的短文,内容质量很低,且长度不足。"}
{"text": "愚公移山。北山愚公,年且九十,面山而居。惩山北之塞,出入之迂也,遂率子孙荷担者三夫,叩石垦壤,箕畚运于渤海之尾。邻人京城氏之孀妻有遗男,始龀,跳往助之。寒暑易节,始一反焉。河曲智叟笑而止之曰:甚矣,汝之不惠!以残年余力,曾不能毁山之一毛,其如土石何?愚公长息曰:汝心之固,固不可彻,曾不若孀妻弱子。虽我之死,有子存焉;子又生孙,孙又生子;子又有子,子又有孙;子子孙孙无穷匮也,而山不加增,何苦而不平?河曲智叟亡以应。操蛇之神闻之,惧其不已也,告之于帝。帝感其诚,命夸娥氏二子负二山,一厝朔东,一厝雍南。自此,冀之南,汉之阴,无陇断焉。"}
{"text": "凿壁偷光\\n西汉时期,有个农民家的孩子叫匡衡。他小时候很想读书,可是家里穷,没钱上学。后来,他跟一个亲戚学认字,才有了看书的能力。 匡衡买不起书,只好借书来读。那个时候,书是非常贵重的,有书的人不肯轻易借给别人。匡衡就在农忙的时节,给有钱的人家打短工,不要工钱,只求人家借书给他看。\\n过了几年,匡衡长大了,成了家里的主要劳动力。他一天到晚在地里干活,只有中午歇晌的时候,才有工夫看一点书,所以一卷书常常要十天半月才能够读完。匡衡很着急,心里想:白天种庄稼,没有时间看书,我可以多利用一些晚上的时间来看书。可是匡衡家里很穷,买不起点灯的油,怎么办呢?\\n有一天晚上,匡衡躺在床上背白天读过的书。背着背着,突然看到东边的墙壁上透过来一线亮光。他嚯地站起来,走到墙壁边一看,啊!原来从壁缝里透过来的是邻居的灯光。于是,匡衡想了一个办法:他拿了一把小刀,把墙缝挖大了一些。这样,透过来的光亮也大了,他就凑着透进来的灯光,读起书来。\\n匡衡就是这样刻苦地学习,后来成了一个很有学问的人。\\n这个故事告诉我们,要努力学习知识。"}
EOF您会发现,我们故意制造了一些问题:
- 重复数据:第一条和第五条数据是完全一样的("凿壁偷光")。
- 格式混乱:第二条数据("刻舟求剑")前后有多余的空格,中间有多个空格。
- 低质量内容:第三条数据是毫无意义的短文本。第二条数据中还包含了主观评价"这个故事很愚蠢"。
- 语言不统一:第四条数据("愚公移山")是文言文,而其他是白话文。
第三步:创建清洗配方(Config)
Data-Juicer 的强大之处在于你可以通过一个配置文件(配方 )来定义清洗流程。让我们创建一个简单的配方文件 demo_config.yaml。
plain
# demo_config.yaml
process:
- text_cleaning: # 文本清理 mapper
- remove_comments: # 移除类似评论的内容 mapper
pattern: '这个故事很愚蠢|这个故事很差'
- text_length_filter: # 文本长度过滤器,过滤掉太短的文本
min_len: 10
max_len: 10000
- language_id_score_filter: # 语言识别过滤器,只保留中文文本
lang: 'zh'
- document_deduplicator: # 文档去重器,删除重复的文本
method: 'simhash'
threshold: 0.85
global:
text_keys: 'text' # 指定处理哪个字段,我们的是'text'第四步:运行清洗流程
现在,让我们施展魔法!在终端运行以下命令:
plain
data_juicer --config ./demo_config.yaml --dataset_path ./dirty_data.jsonl --export_path ./cleaned_data.jsonl--config: 指定我们的配方文件。--dataset_path: 指定输入数据。--export_path: 指定清洗后的输出文件。
等待几秒钟,流程就会执行完毕!
第五步:查看清洗结果
让我们查看清洗后的数据 cleaned_data.jsonl,并与原数据对比。
plain
# 查看清洗后的数据
cat ./cleaned_data.jsonl您会看到类似这样的输出(格式已美化):
plain
{"text": "凿壁偷光\n西汉时期,有个农民家的孩子叫匡衡。他小时候很想读书,可是家里穷,没钱上学。后来,他跟一个亲戚学认字,才有了看书的能力。 匡衡买不起书,只好借书来读。那个时候,书是非常贵重的,有书的人不肯轻易借给别人。匡衡就在农忙的时节,给有钱的人家打短工,不要工钱,只求人家借书给他看。\n过了几年,匡衡长大了,成了家里的主要劳动力。他一天到晚在地里干活,只有中午歇晌的时候,才有工夫看一点书,所以一卷书常常要十天半月才能够读完。匡衡很着急,心里想:白天种庄稼,没有时间看书,我可以多利用一些晚上的时间来看书。可是匡衡家里很穷,买不起点灯的油,怎么办呢?\n有一天晚上,匡衡躺在床上背白天读过的书。背着背着,突然看到东边的墙壁上透过来一线亮光。他嚯地站起来,走到墙壁边一看,啊!原来从壁缝里透过来的是邻居的灯光。于是,匡衡想了一个办法:他拿了一把小刀,把墙缝挖大了一些。这样,透过来的光亮也大了,他就凑着透进来的灯光,读起书来。\n匡衡就是这样刻苦地学习,后来成了一个很有学问的人。\n这个故事告诉我们,要努力学习知识。"}
{"text": "刻舟求剑 这是一个关于楚国人的故事,他在坐船过江时,不小心把剑掉入了水中。 他在船上刻了一个记号,说:我的剑是从这里掉下去的。等船靠岸后,他从记号处跳下水去找剑,结果自然找不到。"}
{"text": "愚公移山。北山愚公,年且九十,面山而居。惩山北之塞,出入之迂也,遂率子孙荷担者三夫,叩石垦壤,箕畚运于渤海之尾。邻人京城氏之孀妻有遗男,始龀,跳往助之。寒暑易节,始一反焉。河曲智叟笑而止之曰:甚矣,汝之不惠!以残年余力,曾不能毁山之一毛,其如土石何?愚公长息曰:汝心之固,固不可彻,曾不若孀妻弱子。虽我之死,有子存焉;子又生孙,孙又生子;子又有子,子又有孙;子子孙孙无穷匮也,而山不加增,何苦而不平?河曲智叟亡以应。操蛇之神闻之,惧其不已也,告之于帝。帝感其诚,命夸娥氏二子负二山,一厝朔东,一厝雍南。自此,冀之南,汉之阴,无陇断焉。"}结果分析:Data-Juicer 做了什么?
- 去重 (Deduplication):5条输入数据,输出只有3条。重复的"凿壁偷光"故事被自动删除了一条。
- 清理 (Cleaning):
-
- "刻舟求剑"故事前后多余的空格被修剪掉了。
- 故事中主观的评论句"这个故事很愚蠢。"也被成功移除。
- 过滤 (Filtering):
-
- 那条毫无意义的短文本"这是一篇无效的短文..."因为长度太短(
min_len: 10)被过滤掉了。 - 所有文本都被识别为中文,所以没有因为语言问题被过滤。
- 那条毫无意义的短文本"这是一篇无效的短文..."因为长度太短(
通过这个简单的demo,能直观地感受到 Data-Juicer 的核心能力:像一个流水线一样,对数据进行各种细粒度的清洗、过滤和标准化操作,最终产出更干净、更高质量的数据集。
可以尝试修改 demo_config.yaml文件,增删里面的算子,或者修改 dirty_data.jsonl里的内容,然后再次运行,亲眼看看不同的效果!这就是它的魅力所在。
资料获取
大家点赞、收藏、关注、评论啦~
精彩专栏推荐订阅:在下方专栏👇🏻
- 长路-文章目录汇总(算法、后端Java、前端、运维技术导航):博主所有博客导航索引汇总
- 开源项目Studio-Vue---校园工作室管理系统(含前后台,SpringBoot+Vue):博主个人独立项目,包含详细部署上线视频,已开源
- 学习与生活-专栏:可以了解博主的学习历程
- 算法专栏:算法收录
更多博客与资料可查看👇🏻获取联系方式👇🏻,🍅文末获取开发资源及更多资源博客获取🍅