哈喽,各位CSDN的技术伙伴们,大家好!👋
我是缴鸿剑Jackson,一个在分布式系统与大数据领域摸爬滚打的"搬砖工"。很高兴能在CSDN这个优质的技术社区和大家相遇。
今天想和大家深入聊聊Apache Kafka。作为当前业界最流行的分布式消息引擎和流处理平台,Kafka凭借其高吞吐、低延迟、高可靠等特性,已经成为了现代大数据生态和微服务架构中不可或缺的核心组件。无论是做日志收集、用户行为追踪,还是构建数据管道和实时流计算应用,我们几乎都能看到Kafka的身影。
很多初学者在面对Kafka时,可能会被它的架构设计(如Producer、Broker、Consumer、ZooKeeper的关系)、复杂的参数配置以及Exactly-once语义等高级特性所"劝退"。即使是有经验的开发者,在实际生产环境中也常常会遇到消息丢失、重复消费、分区rebalance异常、集群性能调优等各种棘手问题。
在这篇文章里,我不会只停留在简单的API调用层面,而是会结合我自己的踩坑经验,带你从源码级别剖析Kafka的核心运行机制。我会重点拆解以下内容:
架构基石: 一张图看懂Kafka集群的完整工作流。
存储揭秘: 日志分段(LogSegment)与索引文件是如何工作的?
一致性核心: HW与LEO的精妙设计如何保证数据不丢?
性能之谜: 零拷贝(Zero-Copy)技术到底快在哪里?
如果你正在学习Kafka,或者在项目中遇到了瓶颈,不妨花15分钟静下心来读一读。相信我,读完这篇文章,你会对Kafka有一个全新的、更立体的认识。
觉得内容有用的朋友,记得点赞、收藏、关注三连支持一下,你的鼓励是我持续输出高质量干货的最大动力!
目录
一.定义
1.官方解释
- 超过80%的财富100强公司信任并使用kafka
- Apache Kafka是一个开源分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用程序。
2.大白话
Kafka 是一个超级快递分拨中心。
收快递(生产者):各种系统(App、网站)把数据(用户点击、订单)像快递一样扔给 Kafka。
暂存(存储):Kafka 把快递按顺序堆在货架上(磁盘),存多久都行,不会丢。
发快递(消费者):其他系统(大数据分析、推荐系统)啥时候有空,就来 Kafka 这里取走自己需要的快递。
核心价值 :它像一个巨大的缓冲漏斗。上游系统狂扔数据不怕把下游搞崩,下游系统可以按自己的节奏慢慢处理。
二.谁在用kafka
- 制造业:10个中有10个
- 银行:10个中有7个
- 保险:10个中有10个
- 电信:10个中有8个
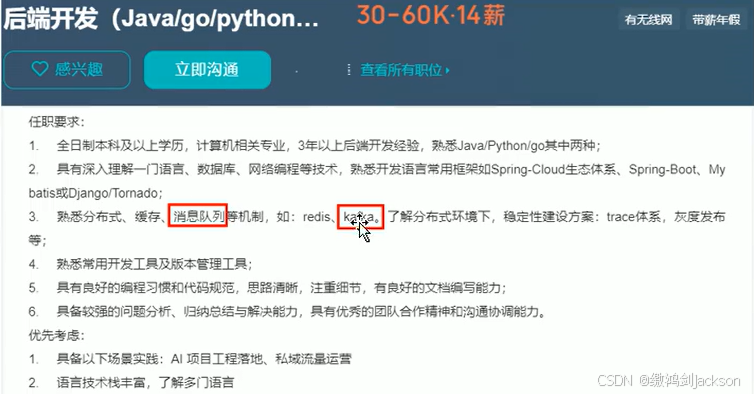
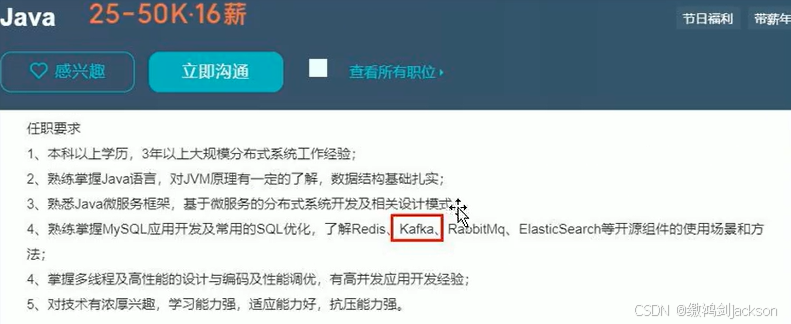
除此之外,我们在找工作的时候,很多公司也要求掌握kafka
三.kafka的起源
稍微了解一下即可,不用记
1.kafka最初由LinkedIn(领英:全球最大的面向职场人士的社交网站)设计开发的,是为了解决LinkedIn的数据管道问题,用于LinkedIn网站的活动流数据和运营数据处理工具
- 活动流数据:页面访问量、被查看页面内容方面的信息以及搜索情况等内容;
- 运营数据:服务器的性能数据(CPU、IO使用率、请求时间、服务日志等数据);
2.刚开始LinkedIn采用的是ActiveMQ来进行数据交换,大约在2010年前后,那时的ActiveMQ还远远无法满足LinkedIn对数据交换传输的要求,经常由于各种缺陷而导致消息阻塞或者服务无法正常访问,为了解决这个问题,LinkedIn决定研发自己的消息传递系统,当时LinkedIn的首席架构师jay kreps便开始组织团队进行消息传递系统的研发;
四.kafka名字的由来
由于Kafka的架构师jay kreps非常喜欢franz kafka(弗兰茨·卡夫卡)(是奥匈帝国一位使用德语的小说家和短篇犹太人故事家,被评论家们认为是20世纪作家中最具影响力的一位),并且觉得Kafka这个名字很酷,因此把这一款消息传递系统取名为Kafka;
大师门取名字也是根据自己的喜好来取名,在我们看来有可能感觉很随意!
五.kafka的发展历程
- 2010年底,Kafka在Github上开源,初始版本为0.7.0;
- 2011年7月,因为备受关注,被纳入Apache孵化器项目;
- 2012年10月,Kafka从Apache孵化器项目毕业,成为Apache顶级项目;
- 2014年,jay kreps(kafka的架构师)离开LinkedIn, 成立confluent公司,此后LinkedIn和confluent成为kafka的核心代码贡献组织,致力于Kafka的版本迭代升级和推广应用;
六.kafka版本迭代演进

以上就是本篇文章的全部内容,喜欢的话可以留个免费的关注呦~~~