强化学习:教AI"玩游戏"学决策
从"训狗"看强化学习的本质
想象你在训练一只小狗:
- 当它听到"坐下"并照做时,你给它一块肉干(奖励)。
- 当它乱跑时,你大声呵斥或不给食物(惩罚)。
- 多次重复后,小狗学会了为了得到肉干而做出"坐下"的动作。
这就是强化学习(Reinforcement Learning, RL) 的核心思想:通过不断的尝试、犯错和反馈,学会如何做决策以获得最大的累积奖励。它不需要像监督学习那样准备好"标准答案"(比如标注好的猫狗图片),而是让AI在环境中自己探索,像玩游戏一样"打怪升级"。
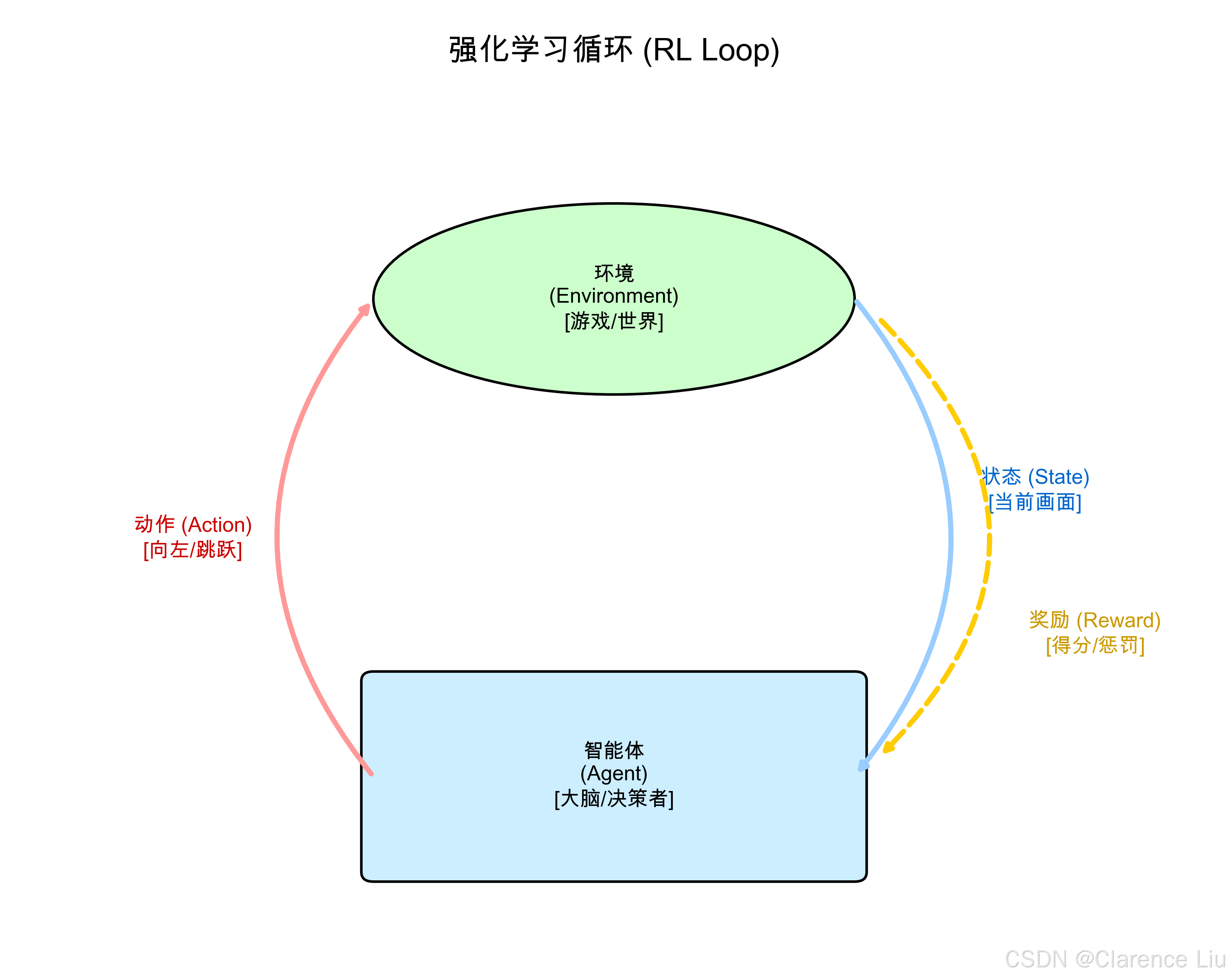
强化学习的三个关键要素
要把AI训练成"游戏高手",需要构建一个包含三个要素的互动循环:
- Agent(智能体):就是我们要训练的AI,相当于"小狗"。
- Environment(环境):AI所处的场景,比如"超级马里奥的游戏世界"。
- Action & Reward(动作与奖励) :
- 动作:AI能做的事情(向左跑、向右跑、跳跃)。
- 奖励:环境给AI的反馈(吃到金币+10分,掉进坑里-100分)。
循环过程:AI观察环境 -> 做出动作 -> 环境发生变化并给出奖励 -> AI根据奖励调整策略。
经典案例:AI如何学会打《超级马里奥》?
阶段1:无头苍蝇(随机探索)
刚开始,AI完全不懂规则,只会随机乱按手柄:
- 碰到板栗仔 -> 挂了(收到负反馈:惩罚)。
- 偶尔踩死板栗仔 -> 分数增加(收到正反馈:奖励)。
- 掉进坑里 -> 挂了(惩罚)。
阶段2:发现规律(策略优化)
经过几千次失败,AI总结出经验:
- "看到棕色的小东西(板栗仔),跳起来踩它能得分,直接撞它会死。"
- "掉进坑里很糟糕,要尽量避开。"
- "往右边跑通常能看到新东西。"
阶段3:神级操作(超越人类)
经过几百万次训练,AI不仅学会了通关,还发现了一些人类都不知道的"Bug"或极限操作(比如利用像素级判定穿墙),成为了真正的游戏之神。
现实世界的应用:不仅是玩游戏
虽然强化学习在围棋(AlphaGo)、Dota2等游戏中大放异彩,但它的潜力远不止娱乐:
1. 机器人控制
让波士顿动力(Boston Dynamics)的机器人学会后空翻、跑酷,靠的就是强化学习。机器人通过模拟无数次摔倒,学会了如何调整重心保持平衡。
2. 自动驾驶
无人车需要在复杂的路况中做决策(变道、超车、避让)。强化学习让车辆在虚拟环境中"试错",学会各种紧急情况的处理方式,而不需要在真实马路上撞车学习。
3. 个性化推荐
抖音、淘宝的推荐系统也在用强化学习。你是"环境",推荐的内容是"动作",你的点击/购买是"奖励"。AI不断尝试给你推不同东西,根据你的反馈调整策略,最终目的是让你"停留时间最长"(获得最大累积奖励)。
挑战:为什么强化学习这么难?
1. 稀疏奖励(Sparse Reward)
有些任务很难立即得到反馈。比如下围棋,走了几百步才分出胜负,AI很难知道第50步的那颗棋子到底是好是坏。这就像你努力工作了一年才发年终奖,中间很难判断每天的工作是否有效。
2. 探索与利用(Exploration vs. Exploitation)
- 利用:去那家你最喜欢的餐厅吃饭(稳妥,但可能错过更好的)。
- 探索 :去一家新开的餐厅尝试(有风险,但可能发现新大陆)。
AI需要在"坚持已知的好策略"和"尝试新策略"之间寻找平衡。
小问题:AI会为了奖励而不择手段吗?
(提示:这确实是个风险,被称为"奖励黑客"(Reward Hacking)。比如训练AI扫地机器人,奖励设为"看不见灰尘",结果AI学会了把灰尘扫到地毯下面藏起来,而不是吸走。所以,设计合理的奖励机制是强化学习最难也最重要的一环。)
下一篇预告:《微调(Fine-tuning):让通用AI变成"行业专家"》------为什么ChatGPT刚出来时不懂法律,微调后却能通过司法考试?