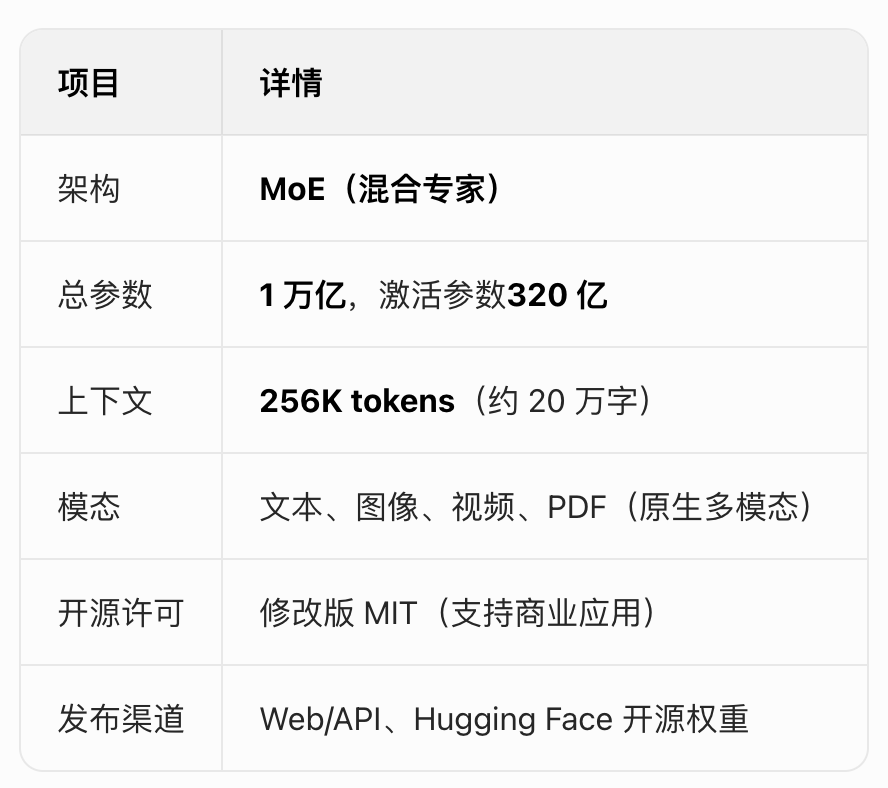
Kimi K2.5是月之暗面(Moonshot AI)于 2026 年 1 月 27 日发布的开源权重多模态旗舰大模型
定位为 "Kimi 迄今最智能、最全能的模型",核心突破在Agent 集群、原生多模态与编码能力,并以 MoE 架构实现高效推理
K2.5 强调文本和视觉的联合优化,通过文本-视觉预训练、零视觉SFT和联合文本-视觉强化学习等技术,提升编码、视觉、推理和智体任务等领域的性能。
K2.5引入了Agent Swarm框架,能动态分解复杂任务并并行执行,降低延迟达4.5倍,在多个基准测试中表现亮眼,接近国际顶尖闭源模型水平,还支持视觉编程、多模态输入输出等能力,是原生多模态模型的代表之一。
三大核心能力
Agent Swarm(智能体集群,研究预览)
基于PARL(并行智能体强化学习),动态拆解复杂任务,调度最多 100 个子智能体并行执行,支持1500 次工具调用
相比单智能体,宽搜场景延迟最高降4.5 倍,F1 从 72.8% 提升至 79.0%。适用于多公司调研、多页翻译、大型项目研发等并行场景
原生多模态理解
采用MoonViT3D视觉编码器与早期融合策略,统一处理视觉与文本 token
支持图像、视频、图文 PDF 输入,可完成 UI 设计转代码、视频内容分析、图表理解等任务
四模式推理与强编码
提供Instant(即时)/Thinking(思考)/Agent(单智能体)/Agent Swarm(集群) 四种模式
编码能力对标前沿模型,尤其擅长前端开发,配套Kimi Code可集成主流编辑器
与 K2 的关键差异
K2 为纯文本模型,K2.5 新增原生多模态(图像 / 视频 / PDF)
从 "单智能体长程执行" 升级为动态并行 Agent 集群,重构强化学习基建
统一架构,支持对话、复杂推理与自动化任务无缝切换
典型适用场景
后端 / 前端开发:API 设计、代码生成 / 调试、UI 稿转代码
复杂办公自动化:多文档整合、跨数据源调研、批量翻译
多模态内容处理:视频情节分析、图文 PDF 解析、图表生成
并行任务调度:需要拆解为子任务并高效并行完成的场景
小结
Kimi K2.5 以1T MoE+256K 上下文 + 原生多模态为底座
通过Agent Swarm将智能体从 "单兵作战" 升级为 "集群协作",是面向复杂知识工作的开源全能模型,兼顾性能与商用友好性
附录
什么是权重多模态
权重多模态 = 文本和图像/视频等,在模型底层就用同一套权重、同一个编码器一起学习
不是 "文本模型 + 视觉模型" 拼起来,而是天生就一起长大
解读
单一流架构:文本、图像、视频、音频,都被映射到同一个语义空间
共享 Transformer 权重:不是两套模型,而是共享底层权重一起训练
真正理解 "图文关系":模型不是分别看懂图、看懂字,而是直接理解图文之间的逻辑
比喻
普通多模态(后期拼接)
有个语文老师(文本模型),有个美术老师(视觉模型),各自教完,最后再把结果拼在一起→ 这叫多模态,但不是权重多模态
权重多模态(原生统一)
只有一个老师、一套教材,语文和美术从小一起学,文字、图片、视频在模型内部就是同一套表示、同一套权重→ 这才是权重多模态
为什么 Kimi K2.5 强调「权重多模态」
因为它代表:
更强的理解:图里的字、表格、图表、UI 都能精准看懂
更统一的推理:看图写代码、看视频总结、看 PDF 分析,一气呵成
不是外挂视觉,是原生多模态
MoE
含义
Mixture of Experts 混合专家
一个大模型里藏着很多 "小专家",每次只激活几个干活
普通大模型(Dense 稠密模型)
全班 100 个学生 都在
每做一道题,所有人一起算
算力消耗 = 100 人同时跑
优点:统一
缺点:巨费算力、巨慢、巨贵
MoE 混合专家模型
全班还是 100 个学生(总参数很大)
但老师出题后,只叫 2~4 个最擅长的学生来算
其他人休息、不参与计算
算力消耗 = 只算激活的那几个人
优点:参数超大、能力强,但速度快、省算力
模型分成很多个 Expert
每个专家擅长不同领域:代码、数学、语文、逻辑...
有一个 Gate(门控 / 路由)
它看一眼输入,决定这次激活哪几个专家
前向传播时
只有被选中的专家参与计算
其他参数不动、不占推理算力
MoE 的核心好处
总参数可以做得超大
比如 1 万亿参数,但每次只用到 30B
推理速度几乎不变
参数量翻 10 倍,速度不慢多少
能力更强、成本更低
适合做超长文本、多模态、复杂推理
GPT‑4、Kimi K2、Kimi K2.5、Llama 3 MoE 全都是 MoE 混合专家
它们宣传 1T 参数,不是唬人,是因为 MoE 允许把模型堆很大,又能跑得动
总结
普通稠密模型:人多一起干,又慢又贵
MoE 混合专家:人多但只叫高手干,又强又省算力
Agent 集群
一群 AI 组队干活,不是单打独斗
Agent 集群 = 一个总指挥 + 一群 AI 小助手
并行干活、互相配合、一起解决超级复杂任务
普通 AI Agent(单打独斗)
只有一个员工
所有事:写文案、写代码、查资料、画图、算数据...
全都一个人从头干到尾
任务复杂一点就乱、慢、容易错
Agent 集群(公司团队模式)
有一个 CEO(主智能体):负责拆解任务、分配工作
下面有 10~100 个员工(子智能体)
每个员工只干自己擅长的事:
有的查资料
有的写代码
有的算数学
有的分析表格
有的总结文本
大家并行干活,最后汇总结果
这就是 Agent Swarm / Agent 集群
主 Agent 把复杂问题拆成很多小任务
多 Agent 并行执行:同时派多个子 AI 去做,速度成倍提升
结果汇总:主 Agent 把所有结果整理成最终答案
swarm
swɔːm
n. 一大群(移动中的昆虫);(移动着的)一大群人;(多指发生在火山附近的)地震群;(天文)一大群小型天体同时在空中出现
v.(昆虫)成群飞行;(人)蜂涌,涌动;挤满,云集;成群地包围;爬(梯子等)
F1 分数,AI 回答准不准的核心评分
F1 = 0~100% 的分数,越高越准
AI 做任务(比如抽取信息、分类、回答问题),有两个关键:
- 查全率(Recall):别漏掉该找的东西
- 查准率(Precision):别乱编、别错
F1 就是这两个的综合平均分
- F1 高:又全又准
- F1 低:要么漏、要么错
F1 从 72.8% → 79.0%:用了 Agent 集群之后,AI 回答更准、漏得更少、正确率明显提升
PARL 并行 RL
PARL 并行 RL,专门做大规模、分布式、多智能体并行强化学习的核心能力
让成千上万个 Agent 同时跑、同时采数据、同时训练,把 RL 速度从 "蜗牛" 拉到 "火箭"
PARL 并行 RL = 用多机 / 多卡 / 多进程,让 N 个 Agent 同时跟环境交互、同时学策略,训练速度≈N 倍提升
为什么要并行 RL(痛点)
普通 RL 是单 Agent 串行:
一个 Agent → 一步一步试错 → 慢慢攒数据 → 慢慢更新模型
问题:慢、算力浪费、大任务根本跑不动
并行 RL 解决:
数据采集并行:N 个 Agent 同时跑,数据量 N 倍涨
训练并行:多 GPU / 多机一起算梯度、更新模型
结果:训练时间从几天→几小时,甚至几分钟
PARL 并行 RL 的核心架构
PARL 把并行拆成三大块,只要懂这 3 个角色:
-
三大核心组件(模块化)
Model:神经网络(策略 / 价值网络)
Algorithm:RL 算法(PPO/DQN/DDPG 等),负责更新模型
Agent:跟环境交互、采数据、把数据传给 Algorithm
-
并行模式(PARL 最牛的地方)
(1)数据并行(最常用)
每个 Worker 跑一个完整 Agent + 环境
所有 Worker 采的数据,汇总到中心节点更新模型
适合:多智能体、游戏、机器人、推荐系统
(2)异步并行(A3C 风格)
每个 Worker 独立采数据、独立更新本地模型
定期把本地梯度同步到全局模型
优点:无等待、吞吐极高;缺点:梯度可能有延迟
(3)分布式多机并行
跨多台服务器,每台跑多个 Worker
支持上千 Agent 同时训练,工业级规模