引言:数据库迁移的"暗礁"与"航道"
在信息技术应用创新加速推进的今天,越来越多的企业面临着从传统商业数据库(如Oracle、MySQL、SQL Server)向国产数据库平台迁移的现实需求。作为国内领先的数据库产品,金仓数据库(KingbaseES)凭借其卓越的性能、完善的安全体系和成熟的迁移工具链,已成为众多关键行业国产化替代的首选方案。
然而,数据库迁移绝非简单的"数据搬家",而是一项涉及技术架构、业务逻辑、数据治理等多维度的系统工程。据中国信息通信研究院发布的《2024年中国数据库产业发展白皮书》显示,超过67%的金融机构在数据库迁移项目中曾遭遇因兼容性问题导致的应用回退事件,平均延期周期达45天以上。这一数据警示我们:数据迁移过程中的完整性与一致性风险,是决定迁移成败的关键因素。
作为国产数据库领域的领军企业,电科金仓(以下简称金仓)凭借其核心产品 KingbaseES 和完整的迁移工具链,为众多行业客户提供了平滑、低风险的数据库替换解决方案。本文将深入剖析从传统关系数据库迁移至金仓数据库过程中面临的完整性与一致性风险,并提供切实可行的技术解决方案。
一、数据迁移的"冰山之下":完整性与一致性风险全景图
1.1 数据完整性风险:从微观到宏观的挑战
数据完整性是数据库系统的基石,但在迁移过程中,这一基石往往面临多重挑战:
字符集与时区精度丢失 :这是迁移过程中最常见的"隐形杀手"。以Oracle数据库为例,其TIMESTAMP WITH TIME ZONE数据类型支持高达9位小数的秒精度和完整的时区信息。当迁移至目标数据库时,如果目标库的时间精度定义不足或时区处理机制不同,可能导致时间戳被截断或时区信息丢失。例如,某金融交易系统在迁移后发现,原本精确到纳秒级的时间戳被截断为毫秒级,导致高频交易场景下的时序分析出现偏差。
数据类型映射偏差 :不同数据库系统对数据类型的定义和处理存在差异。Oracle的NUMBER类型可以存储高达38位的精度,而迁移过程中如果映射不当,可能导致数值精度损失或溢出。特别是在金融、科研等对数据精度要求极高的领域,这种偏差可能引发严重的业务逻辑错误。
约束完整性破坏:外键约束、检查约束、唯一约束等数据库对象在迁移过程中可能因语法不兼容或实现差异而失效。某政务系统在迁移后才发现,原本依赖Oracle的延迟约束检查机制的业务逻辑,在新环境中无法正常工作,导致数据一致性出现严重问题。
1.2 数据一致性风险:事务边界的"灰色地带"
数据一致性风险主要体现在事务处理和增量同步两个层面:
大对象(LOB)迁移失败:BLOB、CLOB等大对象数据类型在跨平台传输过程中极易损坏。传统迁移工具往往采用分段读取、传输、重组的方式处理大对象,但在网络不稳定或传输中断的情况下,可能导致对象损坏或部分丢失。某医疗影像系统在迁移过程中,部分患者的CT影像数据在传输后无法正常解析,直接影响了临床诊断。
增量同步断点不准:基于SCN(System Change Number)或日志解析的增量同步机制,在源库与目标库之间可能存在"时间差"。当源库的日志轮转速度过快,或目标库的解析能力不足时,可能导致增量数据丢失或重复。某电商平台在迁移期间,订单状态同步延迟达到分钟级,导致用户支付成功后页面仍显示"待支付",引发大量客诉。
事务原子性破坏:在分布式迁移场景下,跨数据库的事务可能无法保证ACID特性。特别是涉及多个表的复杂事务,在迁移过程中可能被拆分为多个独立操作,破坏了事务的原子性。某银行核心系统迁移测试中,转账操作的一半成功、一半失败,直接暴露了事务处理机制的风险。
1.3 业务逻辑一致性风险:隐形的"语义断层"
除了技术层面的风险,业务逻辑的一致性同样不容忽视:
存储过程与函数行为差异:不同数据库的PL/SQL实现存在细微但关键的差异。Oracle的异常处理机制、游标行为、集合操作等特性,在迁移后可能表现出不同的行为特征。某保险公司的精算系统迁移后,原本运行多年的存储过程产生了不同的计算结果,直接影响了保费定价。
视图与物化视图语义变化:数据库视图的优化策略、物化视图的刷新机制在不同数据库间存在显著差异。迁移后,原本高效的查询可能变得缓慢,或者原本实时更新的数据视图出现延迟。
触发器执行时机差异:触发器的触发时机(BEFORE/AFTER)、行级与语句级触发器的行为、嵌套触发器的处理逻辑等,在不同数据库系统中可能有不同的实现。某制造企业的ERP系统迁移后,库存更新触发器在特定场景下出现死锁,导致业务流程中断。
二、金仓数据库的迁移风险防控体系 
2.1 "三低一平"的迁移理念
金仓数据库提出了"低难度、低成本、低风险、平滑迁移"的"三低一平"迁移理念,通过系统化的工具链和标准化的实施流程,有效应对迁移过程中的各类风险。
低难度:通过高度兼容的语法体系和智能迁移工具,最大程度减少代码改造工作量。金仓数据库支持Oracle、MySQL等多种数据库方言,对常用SQL语法的兼容度超过90%,大多数标准SQL和PL/SQL无需修改即可运行。
低成本:提供一体化的迁移工具套件,涵盖评估、迁移、验证全流程,显著降低人力投入和时间成本。实测数据显示,采用金仓迁移方案可将整体迁移周期缩短40%以上。
低风险:构建多层次的数据校验机制和完备的回退方案,确保迁移过程可控、可测、可回滚。金仓的KFS工具支持实时增量同步和在线数据比对,可在分钟级内完成差异修复。
平滑迁移:采用"双轨并行+渐进切换"的策略,实现业务无感迁移。某省级电信运营商80TB营销系统的迁移案例中,总停机时间仅5小时,分两次完成,期间业务持续运行。
2.2 核心工具链:从评估到验证的闭环管理
金仓数据库提供了一套完整的迁移工具链,形成从前端评估到后期验证的闭环管理体系:
KDMS(金仓数据库迁移评估系统):迁移前的"体检中心"。通过智能扫描源库对象结构和SQL语句,自动识别兼容性问题,生成详细的评估报告。KDMS V4版本新增了数据库采集体检套餐,可精准统计表数据量和磁盘空间,自动扫描主键和约束,提前暴露完整性风险。
KDTS(金仓数据迁移工具):全量迁移的"高速通道"。支持多线程并行导出导入,针对大表采用分片处理策略,显著提升迁移效率。KDTS提供WEB和SHELL两种操作界面,支持断点续传和容错重试,确保迁移任务稳定性。
KFS(金仓异构数据同步软件):增量同步的"精准导航"。基于日志解析技术捕获源库变更,在目标端实时回放,实现亚秒级延迟同步。KFS内置多维度比对引擎,支持结构对比、行数核验、主键内容比对、哈希值校验等多种验证方式。
KStudio开发管理工具:迁移前后的"调优平台"。集成SQL编辑、执行计划分析、性能监控等功能,帮助开发人员快速定位和解决迁移后的性能问题。
2.3 关键技术机制:保障数据无缝衔接
金仓数据库在数据迁移领域积累了多项核心技术,有效保障数据在迁移过程中的完整性和一致性:
日志偏移量精准管理:每张表拥有唯一的"数据身份证"------日志序列号(LSN)标识。在全量数据迁移开始前,系统记录各表的起始LSN;迁移结束后,记录结束LSN;增量同步从结束LSN位置继续捕获新增事务。这一机制确保了全量与增量之间的无缝衔接,无重叠、无遗漏,彻底解决了传统方案中的"边界冲突"问题。
事务合并与并行回放:在目标端追赶源端增量数据时,金仓采用事务批处理+并行回放机制,结合智能调度算法优化写入效率。对于高频小事务,系统自动将其批量打包处理,大幅降低日志提交频率和锁竞争开销,使追平速度达到业内领先水平。
多层级一致性智能比对:迁移完成后,系统执行三级验证:表级基础校验(比对行数统计及混合校验和)、主键抽样比对(基于主键索引随机抽取数据行逐字段校验)、业务语义校验(支持用户自定义规则,如对金额类字段执行SUM聚合比对)。这一机制全面覆盖了从基础统计到业务逻辑的验证需求。
三、实战代码案例:金仓数据库增删改查操作详解
3.1 案例一:基础CRUD操作(使用ksql命令行工具)
sql
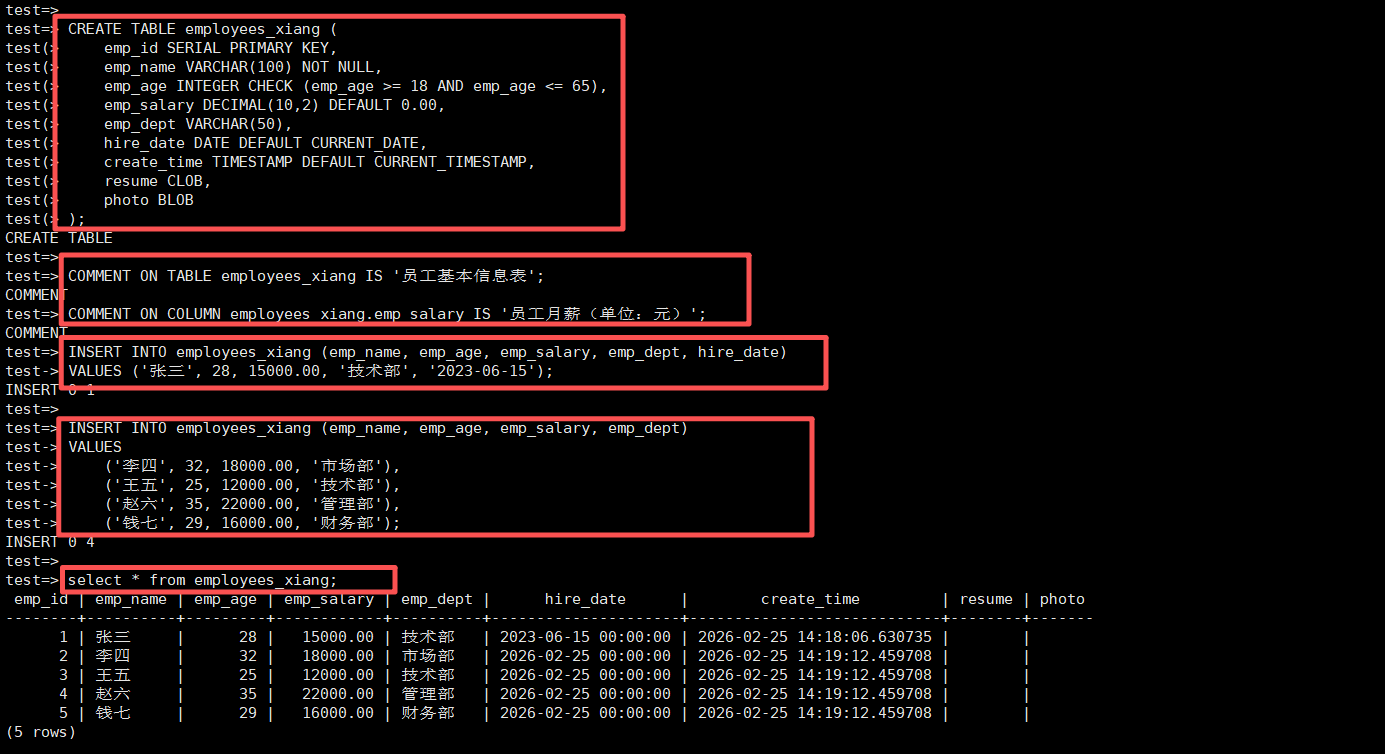
-- 创建示例表:员工信息表
CREATE TABLE employees_xiang (
emp_id SERIAL PRIMARY KEY,
emp_name VARCHAR(100) NOT NULL,
emp_age INTEGER CHECK (emp_age >= 18 AND emp_age <= 65),
emp_salary DECIMAL(10,2) DEFAULT 0.00,
emp_dept VARCHAR(50),
hire_date DATE DEFAULT CURRENT_DATE,
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
resume CLOB,
photo BLOB
);
COMMENT ON TABLE employees_xiang IS '员工基本信息表';
COMMENT ON COLUMN employees_xiang.emp_salary IS '员工月薪(单位:元)';
-- 1. 插入数据(INSERT)
-- 单条插入
INSERT INTO employees_xiang (emp_name, emp_age, emp_salary, emp_dept, hire_date)
VALUES ('张三', 28, 15000.00, '技术部', '2023-06-15');
-- 批量插入(性能优化关键)
INSERT INTO employees_xiang (emp_name, emp_age, emp_salary, emp_dept)
VALUES
('李四', 32, 18000.00, '市场部'),
('王五', 25, 12000.00, '技术部'),
('赵六', 35, 22000.00, '管理部'),
('钱七', 29, 16000.00, '财务部');
-- 带子查询的插入
INSERT INTO employees_xiang (emp_name, emp_age, emp_salary, emp_dept)
SELECT
customer_name,
EXTRACT(YEAR FROM CURRENT_DATE) - EXTRACT(YEAR FROM birth_date),
15000.00,
'客服部'
FROM customers
WHERE customer_level = 'VIP'
LIMIT 10;
-- 2. 查询数据(SELECT)
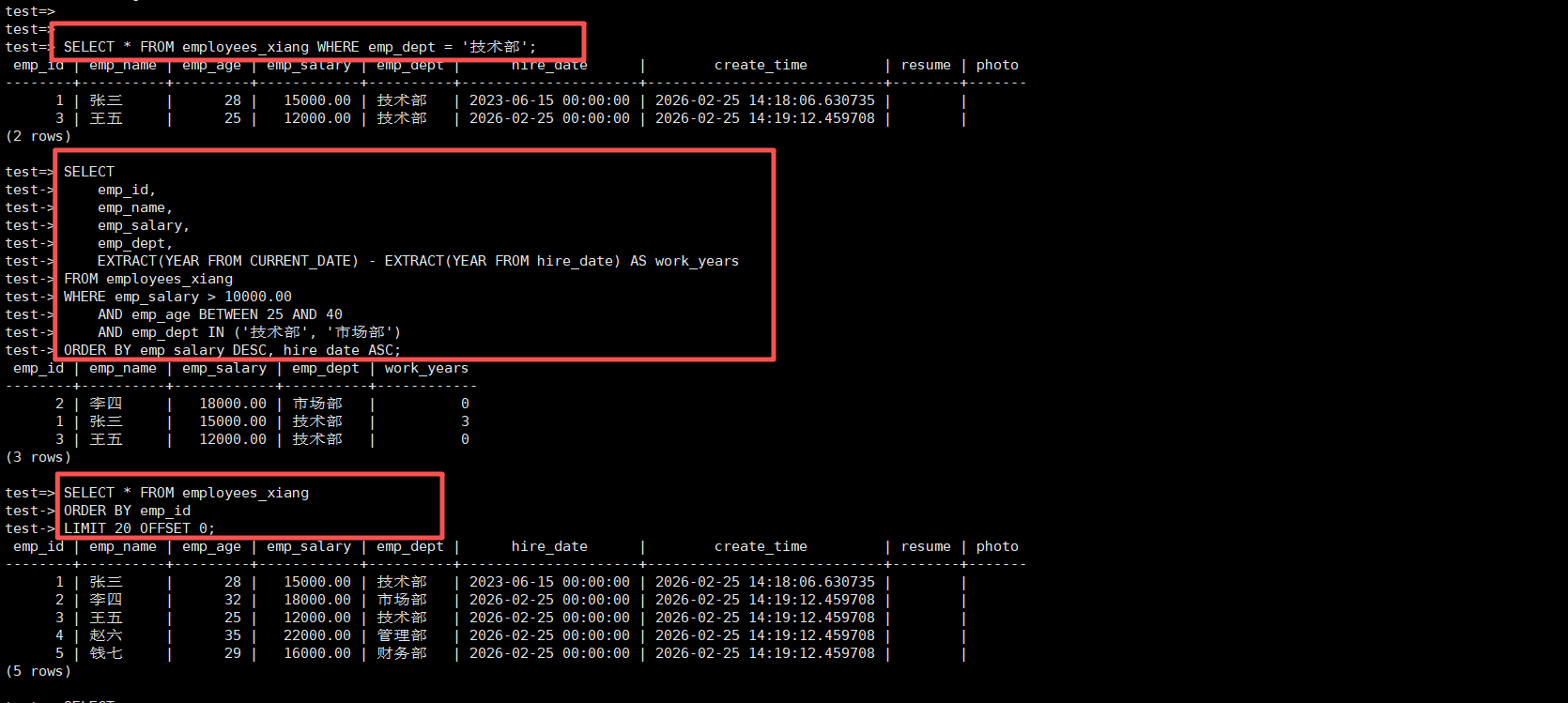
-- 基础查询
SELECT * FROM employees_xiang WHERE emp_dept = '技术部';
-- 条件查询与排序
SELECT
emp_id,
emp_name,
emp_salary,
emp_dept,
EXTRACT(YEAR FROM CURRENT_DATE) - EXTRACT(YEAR FROM hire_date) AS work_years
FROM employees_xiang
WHERE emp_salary > 10000.00
AND emp_age BETWEEN 25 AND 40
AND emp_dept IN ('技术部', '市场部')
ORDER BY emp_salary DESC, hire_date ASC;
-- 分页查询(性能关键)
SELECT * FROM employees_xiang
ORDER BY emp_id
LIMIT 20 OFFSET 0; -- 第一页
-- 聚合查询
SELECT
emp_dept,
COUNT(*) AS emp_count,
AVG(emp_salary) AS avg_salary,
MAX(emp_salary) AS max_salary,
MIN(emp_salary) AS min_salary,
SUM(emp_salary) AS total_salary
FROM employees_xiang
GROUP BY emp_dept
HAVING COUNT(*) > 2
ORDER BY avg_salary DESC;
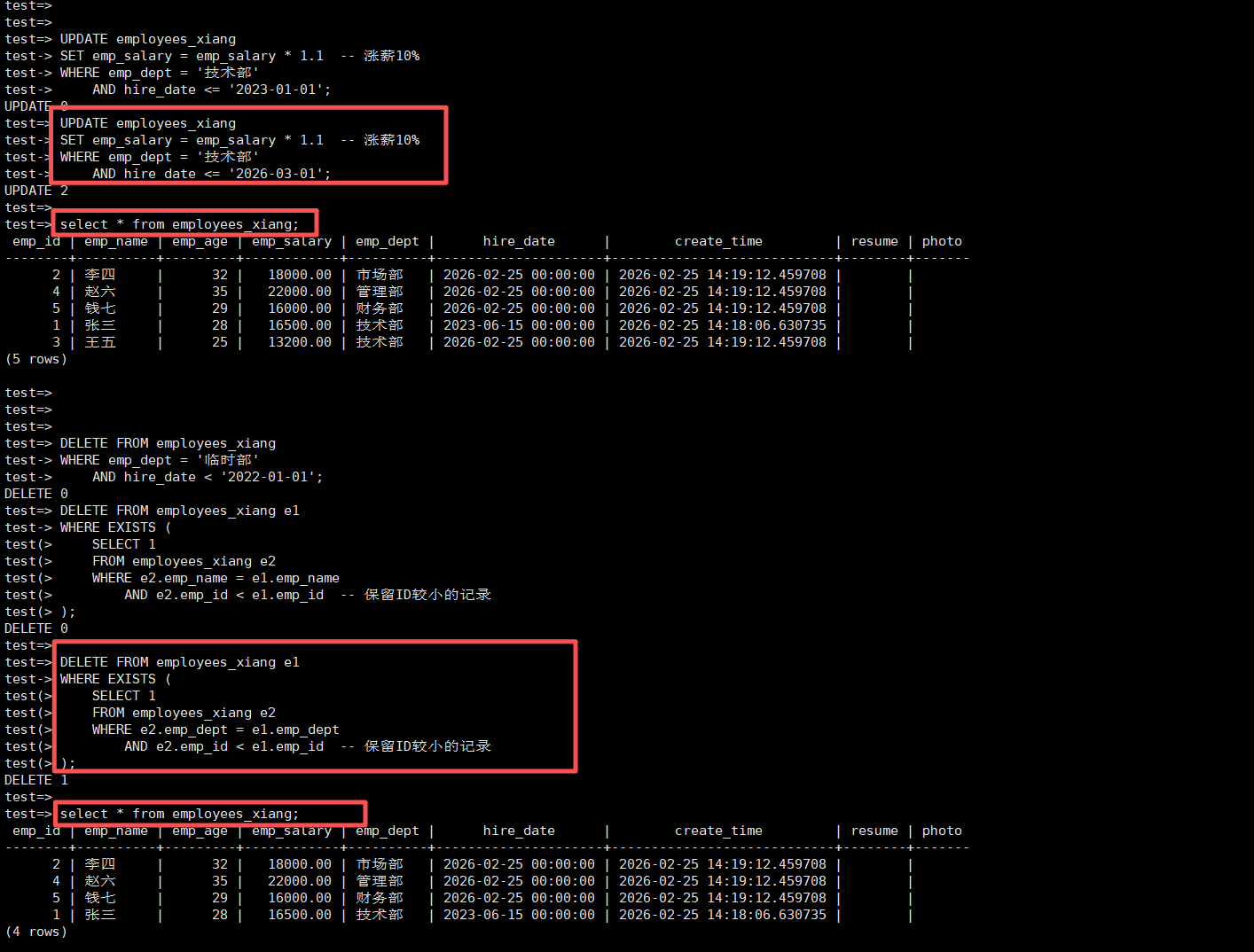
-- 3. 更新数据(UPDATE)
-- 条件更新
UPDATE employees_xiang
SET emp_salary = emp_salary * 1.1 -- 涨薪10%
WHERE emp_dept = '技术部'
AND hire_date <= '2026-03-01';
-- 基于子查询的更新
UPDATE employees_xiang e
SET emp_salary = (
SELECT AVG(emp_salary) * 1.2
FROM employees
WHERE emp_dept = e.emp_dept
)
WHERE emp_id IN (
SELECT emp_id
FROM performance_review
WHERE review_year = 2024
AND overall_score >= 90
);
-- 4. 删除数据(DELETE)
-- 条件删除
DELETE FROM employees_xiang
WHERE emp_dept = '临时部'
AND hire_date < '2022-01-01';
-- 删除重复数据(数据清洗场景)
DELETE FROM employees_xiang e1
WHERE EXISTS (
SELECT 1
FROM employees_xiang e2
WHERE e2.emp_dept = e1.emp_dept
AND e2.emp_id < e1.emp_id -- 保留ID较小的记录
);
-- 事务处理示例
BEGIN;
-- 插入新员工
INSERT INTO employees_xiang (emp_name, emp_age, emp_salary, emp_dept)
VALUES ('孙八', 30, 20000.00, '研发部');
-- 更新部门统计
UPDATE department_stats
SET emp_count = emp_count + 1,
total_salary = total_salary + 20000.00
WHERE dept_name = '研发部';
-- 记录操作日志
INSERT INTO audit_log (operation_type, table_name, record_id, operator, operation_time)
VALUES ('INSERT', 'employees', currval('employees_emp_id_seq'), 'admin', CURRENT_TIMESTAMP);
COMMIT;实操如图所示:
3.2 案例二:Python应用连接与操作(使用ksycopg2驱动)
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
金仓数据库Python连接示例
使用ksycopg2驱动实现完整的CRUD操作
"""
import ksycopg2
import ksycopg2.extras
from datetime import datetime, date
import logging
import sys
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
class KingbaseDBAccess:
"""金仓数据库访问类"""
def __init__(self, host='localhost', port=54321, database='testdb',
user='system', password='kingbase', **kwargs):
"""初始化数据库连接参数"""
self.connection_params = {
'host': host,
'port': port,
'database': database,
'user': user,
'password': password,
**kwargs
}
self.conn = None
self.cursor = None
def connect(self):
"""建立数据库连接"""
try:
# 建立连接
self.conn = ksycopg2.connect(**self.connection_params)
# 设置自动提交为False,使用事务控制
self.conn.autocommit = False
# 创建字典游标,返回结果为字典格式
self.cursor = self.conn.cursor(cursor_factory=ksycopg2.extras.DictCursor)
logger.info(f"成功连接到金仓数据库 {self.connection_params['database']}")
return True
except ksycopg2.Error as e:
logger.error(f"数据库连接失败: {e}")
return False
def create_sample_table(self):
"""创建示例表"""
create_table_sql = """
CREATE TABLE IF NOT EXISTS product_inventory (
product_id SERIAL PRIMARY KEY,
product_code VARCHAR(50) UNIQUE NOT NULL,
product_name VARCHAR(200) NOT NULL,
category VARCHAR(100),
unit_price DECIMAL(12,2) CHECK (unit_price >= 0),
stock_quantity INTEGER DEFAULT 0 CHECK (stock_quantity >= 0),
reorder_level INTEGER DEFAULT 10,
supplier_id INTEGER,
last_restock_date DATE,
product_spec JSONB,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
CONSTRAINT fk_supplier FOREIGN KEY (supplier_id)
REFERENCES suppliers(supplier_id) ON DELETE SET NULL
);
COMMENT ON TABLE product_inventory IS '产品库存表';
COMMENT ON COLUMN product_inventory.product_spec IS '产品规格JSON数据';
-- 创建索引优化查询性能
CREATE INDEX IF NOT EXISTS idx_product_category ON product_inventory(category);
CREATE INDEX IF NOT EXISTS idx_product_supplier ON product_inventory(supplier_id);
CREATE INDEX IF NOT EXISTS idx_product_stock ON product_inventory(stock_quantity)
WHERE stock_quantity < reorder_level;
"""
try:
self.cursor.execute(create_table_sql)
self.conn.commit()
logger.info("示例表创建成功")
return True
except ksycopg2.Error as e:
self.conn.rollback()
logger.error(f"创建表失败: {e}")
return False
def insert_products(self, products_data):
"""批量插入产品数据"""
insert_sql = """
INSERT INTO product_inventory
(product_code, product_name, category, unit_price, stock_quantity,
reorder_level, supplier_id, product_spec)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
ON CONFLICT (product_code) DO UPDATE SET
product_name = EXCLUDED.product_name,
category = EXCLUDED.category,
unit_price = EXCLUDED.unit_price,
stock_quantity = EXCLUDED.stock_quantity,
updated_at = CURRENT_TIMESTAMP
RETURNING product_id, product_code;
"""
try:
# 使用executemany进行批量插入
self.cursor.executemany(insert_sql, products_data)
# 获取插入结果
inserted_ids = self.cursor.fetchall()
self.conn.commit()
logger.info(f"成功插入/更新 {len(inserted_ids)} 条产品记录")
return inserted_ids
except ksycopg2.Error as e:
self.conn.rollback()
logger.error(f"插入产品数据失败: {e}")
return []
def query_products(self, category=None, min_stock=None, max_price=None):
"""查询产品数据"""
query_params = []
conditions = []
# 动态构建查询条件
if category:
conditions.append("category = %s")
query_params.append(category)
if min_stock is not None:
conditions.append("stock_quantity >= %s")
query_params.append(min_stock)
if max_price is not None:
conditions.append("unit_price <= %s")
query_params.append(max_price)
# 构建完整SQL
where_clause = " AND ".join(conditions) if conditions else "1=1"
query_sql = f"""
SELECT
product_id,
product_code,
product_name,
category,
unit_price,
stock_quantity,
reorder_level,
CASE
WHEN stock_quantity = 0 THEN '缺货'
WHEN stock_quantity < reorder_level THEN '需补货'
ELSE '库存充足'
END AS inventory_status,
product_spec->>'color' as product_color,
product_spec->>'weight' as product_weight,
created_at,
updated_at
FROM product_inventory
WHERE {where_clause}
ORDER BY product_id
LIMIT 100;
"""
try:
self.cursor.execute(query_sql, query_params)
results = self.cursor.fetchall()
# 将结果转换为字典列表
products = []
for row in results:
product = dict(row)
products.append(product)
logger.info(f"查询到 {len(products)} 条产品记录")
return products
except ksycopg2.Error as e:
logger.error(f"查询产品数据失败: {e}")
return []
def update_product_stock(self, product_code, quantity_change, operation='in'):
"""更新产品库存(带事务和乐观锁)"""
# 先查询当前库存和版本信息
select_sql = """
SELECT stock_quantity, updated_at
FROM product_inventory
WHERE product_code = %s
FOR UPDATE;
"""
update_sql = """
UPDATE product_inventory
SET stock_quantity = %s,
updated_at = CURRENT_TIMESTAMP
WHERE product_code = %s
RETURNING product_id, stock_quantity;
"""
try:
# 开启事务
self.cursor.execute("BEGIN;")
# 查询当前数据并加锁
self.cursor.execute(select_sql, (product_code,))
current_data = self.cursor.fetchone()
if not current_data:
logger.warning(f"产品 {product_code} 不存在")
self.conn.rollback()
return None
current_stock = current_data['stock_quantity']
# 计算新库存
if operation == 'in':
new_stock = current_stock + quantity_change
elif operation == 'out':
if current_stock < quantity_change:
logger.error(f"产品 {product_code} 库存不足")
self.conn.rollback()
return None
new_stock = current_stock - quantity_change
else:
logger.error(f"无效的操作类型: {operation}")
self.conn.rollback()
return None
# 执行更新
self.cursor.execute(update_sql, (new_stock, product_code))
updated_data = self.cursor.fetchone()
# 记录库存变更日志
log_sql = """
INSERT INTO inventory_transaction_log
(product_id, operation_type, quantity_change,
previous_quantity, new_quantity, operator, transaction_time)
VALUES (%s, %s, %s, %s, %s, %s, CURRENT_TIMESTAMP);
"""
self.cursor.execute(log_sql, (
updated_data['product_id'],
operation,
quantity_change,
current_stock,
updated_data['stock_quantity'],
'system'
))
# 提交事务
self.conn.commit()
logger.info(f"产品 {product_code} 库存更新成功: {current_stock} -> {updated_data['stock_quantity']}")
return updated_data
except ksycopg2.Error as e:
self.conn.rollback()
logger.error(f"更新产品库存失败: {e}")
return None
def delete_obsolete_products(self, obsolete_date):
"""删除过期产品数据(软删除示例)"""
# 实际生产环境中推荐使用软删除
# 这里演示硬删除,但应先备份
backup_sql = """
CREATE TABLE IF NOT EXISTS product_inventory_archive AS
SELECT *, CURRENT_TIMESTAMP AS archived_at
FROM product_inventory
WHERE updated_at < %s;
"""
delete_sql = """
DELETE FROM product_inventory
WHERE updated_at < %s
RETURNING product_id, product_code;
"""
try:
# 先备份数据
self.cursor.execute(backup_sql, (obsolete_date,))
backup_count = self.cursor.rowcount
# 执行删除
self.cursor.execute(delete_sql, (obsolete_date,))
deleted_records = self.cursor.fetchall()
self.conn.commit()
logger.info(f"备份 {backup_count} 条记录,删除 {len(deleted_records)} 条过期产品")
return deleted_records
except ksycopg2.Error as e:
self.conn.rollback()
logger.error(f"删除过期产品失败: {e}")
return []
def close(self):
"""关闭数据库连接"""
if self.cursor:
self.cursor.close()
if self.conn:
self.conn.close()
logger.info("数据库连接已关闭")
# 使用示例
def main():
# 初始化数据库连接
db = KingbaseDBAccess(
host='127.0.0.1',
port=54321,
database='business_db',
user='app_user',
password='secure_password',
connect_timeout=10
)
if not db.connect():
sys.exit(1)
try:
# 1. 创建表
db.create_sample_table()
# 2. 插入示例数据
sample_products = [
('P001', '笔记本电脑', '电子产品', 5999.00, 50, 10, 1,
'{"color": "银色", "weight": "1.5kg", "brand": "Lenovo"}'),
('P002', '无线鼠标', '电子产品', 89.00, 200, 50, 2,
'{"color": "黑色", "weight": "0.1kg", "brand": "Logitech"}'),
('P003', '办公椅', '办公家具', 399.00, 30, 5, 3,
'{"color": "灰色", "weight": "8.5kg", "material": "网布"}'),
]
inserted_ids = db.insert_products(sample_products)
print(f"插入的产品ID: {[row['product_id'] for row in inserted_ids]}")
# 3. 查询数据
electronics = db.query_products(category='电子产品', max_price=10000.00)
print(f"电子产品查询结果: {len(electronics)} 条")
# 4. 更新库存
updated = db.update_product_stock('P001', 10, 'in')
if updated:
print(f"库存更新后: {updated['stock_quantity']}")
# 5. 删除过期数据(示例)
# 实际应根据业务需求确定删除策略
# deleted = db.delete_obsolete_products('2023-01-01')
finally:
# 关闭连接
db.close()
if __name__ == '__main__':
main()3.3 案例三:Java企业级应用集成(使用JDBC驱动)
java
package com.example.kingbase.dao;
import java.math.BigDecimal;
import java.sql.*;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
import org.json.JSONObject;
/**
* 金仓数据库Java JDBC操作示例
* 企业级订单管理系统数据访问层
*/
public class OrderManagementDAO {
private static final String DRIVER_CLASS = "com.kingbase8.Driver";
private static final String URL_PREFIX = "jdbc:kingbase8://";
private Connection connection;
private boolean transactionActive = false;
/**
* 初始化数据库连接
*/
public boolean initializeConnection(String host, int port, String database,
String username, String password) {
try {
// 加载金仓JDBC驱动
Class.forName(DRIVER_CLASS);
// 构建连接URL
String url = URL_PREFIX + host + ":" + port + "/" + database;
// 设置连接属性
Properties props = new Properties();
props.setProperty("user", username);
props.setProperty("password", password);
props.setProperty("ssl", "false");
props.setProperty("prepareThreshold", "5"); // 预处理阈值
props.setProperty("defaultRowFetchSize", "100"); // 默认获取行数
// 建立连接
connection = DriverManager.getConnection(url, props);
// 设置连接属性
connection.setAutoCommit(false); // 手动事务控制
connection.setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED);
System.out.println("金仓数据库连接建立成功");
return true;
} catch (ClassNotFoundException e) {
System.err.println("找不到金仓JDBC驱动: " + e.getMessage());
return false;
} catch (SQLException e) {
System.err.println("数据库连接失败: " + e.getMessage());
return false;
}
}
/**
* 创建订单相关表
*/
public void createOrderTables() throws SQLException {
String[] createTableSQLs = {
// 客户表
"CREATE TABLE IF NOT EXISTS customers (" +
" customer_id SERIAL PRIMARY KEY," +
" customer_code VARCHAR(50) UNIQUE NOT NULL," +
" customer_name VARCHAR(200) NOT NULL," +
" customer_type VARCHAR(20) CHECK (customer_type IN ('个人', '企业', '政府'))," +
" contact_phone VARCHAR(20)," +
" contact_email VARCHAR(100)," +
" registration_date DATE DEFAULT CURRENT_DATE," +
" credit_rating INTEGER DEFAULT 3 CHECK (credit_rating BETWEEN 1 AND 5)," +
" total_order_amount DECIMAL(15,2) DEFAULT 0.00," +
" last_order_date DATE," +
" created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP," +
" updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP" +
")",
// 订单主表
"CREATE TABLE IF NOT EXISTS orders (" +
" order_id SERIAL PRIMARY KEY," +
" order_number VARCHAR(50) UNIQUE NOT NULL," +
" customer_id INTEGER NOT NULL," +
" order_date DATE DEFAULT CURRENT_DATE," +
" order_status VARCHAR(20) DEFAULT '待处理' " +
" CHECK (order_status IN ('待处理', '已确认', '生产中', '已发货', '已完成', '已取消'))," +
" total_amount DECIMAL(15,2) NOT NULL CHECK (total_amount >= 0)," +
" discount_amount DECIMAL(15,2) DEFAULT 0.00 CHECK (discount_amount >= 0)," +
" actual_amount DECIMAL(15,2) GENERATED ALWAYS AS (total_amount - discount_amount) STORED," +
" payment_status VARCHAR(20) DEFAULT '未支付' " +
" CHECK (payment_status IN ('未支付', '部分支付', '已支付', '已退款'))," +
" payment_method VARCHAR(30)," +
" shipping_address TEXT," +
" invoice_needed BOOLEAN DEFAULT false," +
" invoice_title VARCHAR(200)," +
" special_requirements TEXT," +
" estimated_delivery_date DATE," +
" actual_delivery_date DATE," +
" created_by VARCHAR(50)," +
" updated_by VARCHAR(50)," +
" created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP," +
" updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP," +
" CONSTRAINT fk_order_customer FOREIGN KEY (customer_id) " +
" REFERENCES customers(customer_id) ON DELETE RESTRICT" +
")",
// 订单明细表
"CREATE TABLE IF NOT EXISTS order_items (" +
" item_id SERIAL PRIMARY KEY," +
" order_id INTEGER NOT NULL," +
" product_id INTEGER NOT NULL," +
" product_code VARCHAR(50) NOT NULL," +
" product_name VARCHAR(200) NOT NULL," +
" unit_price DECIMAL(12,2) NOT NULL CHECK (unit_price >= 0)," +
" quantity INTEGER NOT NULL CHECK (quantity > 0)," +
" item_amount DECIMAL(15,2) GENERATED ALWAYS AS (unit_price * quantity) STORED," +
" discount_rate DECIMAL(5,4) DEFAULT 0.0000 CHECK (discount_rate BETWEEN 0 AND 1)," +
" discount_amount DECIMAL(12,2) GENERATED ALWAYS AS (unit_price * quantity * discount_rate) STORED," +
" actual_amount DECIMAL(15,2) GENERATED ALWAYS AS (unit_price * quantity * (1 - discount_rate)) STORED," +
" specifications JSONB," +
" created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP," +
" updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP," +
" CONSTRAINT fk_item_order FOREIGN KEY (order_id) " +
" REFERENCES orders(order_id) ON DELETE CASCADE," +
" CONSTRAINT uk_order_product UNIQUE (order_id, product_id)" +
")",
// 创建索引
"CREATE INDEX IF NOT EXISTS idx_orders_customer ON orders(customer_id)",
"CREATE INDEX IF NOT EXISTS idx_orders_status ON orders(order_status)",
"CREATE INDEX IF NOT EXISTS idx_orders_date ON orders(order_date)",
"CREATE INDEX IF NOT EXISTS idx_order_items_order ON order_items(order_id)",
"CREATE INDEX IF NOT EXISTS idx_order_items_product ON order_items(product_id)",
"CREATE INDEX IF NOT EXISTS idx_customers_code ON customers(customer_code)"
};
try (Statement stmt = connection.createStatement()) {
for (String sql : createTableSQLs) {
stmt.execute(sql);
}
connection.commit();
System.out.println("订单相关表创建成功");
} catch (SQLException e) {
connection.rollback();
throw e;
}
}
/**
* 插入订单数据(事务处理示例)
*/
public boolean createOrderWithItems(OrderDTO order, List<OrderItemDTO> items)
throws SQLException {
// 开始事务
beginTransaction();
try {
// 1. 插入订单主表
String insertOrderSQL =
"INSERT INTO orders (order_number, customer_id, order_date, " +
"total_amount, discount_amount, payment_method, shipping_address, " +
"created_by) VALUES (?, ?, ?, ?, ?, ?, ?, ?) " +
"RETURNING order_id";
try (PreparedStatement pstmt = connection.prepareStatement(insertOrderSQL)) {
pstmt.setString(1, order.getOrderNumber());
pstmt.setInt(2, order.getCustomerId());
pstmt.setDate(3, Date.valueOf(order.getOrderDate()));
pstmt.setBigDecimal(4, order.getTotalAmount());
pstmt.setBigDecimal(5, order.getDiscountAmount());
pstmt.setString(6, order.getPaymentMethod());
pstmt.setString(7, order.getShippingAddress());
pstmt.setString(8, order.getCreatedBy());
try (ResultSet rs = pstmt.executeQuery()) {
if (rs.next()) {
int orderId = rs.getInt("order_id");
// 2. 插入订单明细
insertOrderItems(orderId, items);
// 3. 更新客户统计信息
updateCustomerStats(order.getCustomerId(), order.getTotalAmount());
// 提交事务
commitTransaction();
System.out.println("订单创建成功,订单ID: " + orderId);
return true;
}
}
}
return false;
} catch (SQLException e) {
// 回滚事务
rollbackTransaction();
System.err.println("创建订单失败: " + e.getMessage());
throw e;
}
}
/**
* 批量插入订单明细
*/
private void insertOrderItems(int orderId, List<OrderItemDTO> items)
throws SQLException {
String insertItemSQL =
"INSERT INTO order_items (order_id, product_id, product_code, " +
"product_name, unit_price, quantity, discount_rate, specifications) " +
"VALUES (?, ?, ?, ?, ?, ?, ?, ?::jsonb)";
try (PreparedStatement pstmt = connection.prepareStatement(insertItemSQL)) {
for (OrderItemDTO item : items) {
pstmt.setInt(1, orderId);
pstmt.setInt(2, item.getProductId());
pstmt.setString(3, item.getProductCode());
pstmt.setString(4, item.getProductName());
pstmt.setBigDecimal(5, item.getUnitPrice());
pstmt.setInt(6, item.getQuantity());
pstmt.setBigDecimal(7, item.getDiscountRate());
// 处理JSONB数据
if (item.getSpecifications() != null) {
pstmt.setString(8, item.getSpecifications().toString());
} else {
pstmt.setNull(8, Types.OTHER);
}
pstmt.addBatch();
}
// 执行批量插入
int[] results = pstmt.executeBatch();
System.out.println("插入 " + results.length + " 条订单明细");
}
}
/**
* 更新客户统计信息
*/
private void updateCustomerStats(int customerId, BigDecimal orderAmount)
throws SQLException {
String updateCustomerSQL =
"UPDATE customers SET " +
"total_order_amount = total_order_amount + ?, " +
"last_order_date = CURRENT_DATE, " +
"updated_at = CURRENT_TIMESTAMP " +
"WHERE customer_id = ?";
try (PreparedStatement pstmt = connection.prepareStatement(updateCustomerSQL)) {
pstmt.setBigDecimal(1, orderAmount);
pstmt.setInt(2, customerId);
pstmt.executeUpdate();
}
}
/**
* 查询订单详情(复杂查询示例)
*/
public OrderDetailDTO getOrderDetail(String orderNumber) throws SQLException {
String querySQL =
"SELECT o.order_id, o.order_number, o.order_date, o.order_status, " +
" o.total_amount, o.discount_amount, o.actual_amount, " +
" o.payment_status, o.payment_method, o.shipping_address, " +
" c.customer_id, c.customer_code, c.customer_name, " +
" c.contact_phone, c.contact_email, " +
" (SELECT COUNT(*) FROM order_items WHERE order_id = o.order_id) as item_count, " +
" (SELECT SUM(quantity) FROM order_items WHERE order_id = o.order_id) as total_quantity " +
"FROM orders o " +
"JOIN customers c ON o.customer_id = c.customer_id " +
"WHERE o.order_number = ?";
try (PreparedStatement pstmt = connection.prepareStatement(querySQL)) {
pstmt.setString(1, orderNumber);
try (ResultSet rs = pstmt.executeQuery()) {
if (rs.next()) {
OrderDetailDTO detail = new OrderDetailDTO();
detail.setOrderId(rs.getInt("order_id"));
detail.setOrderNumber(rs.getString("order_number"));
detail.setOrderDate(rs.getDate("order_date").toLocalDate());
detail.setOrderStatus(rs.getString("order_status"));
detail.setTotalAmount(rs.getBigDecimal("total_amount"));
detail.setActualAmount(rs.getBigDecimal("actual_amount"));
detail.setCustomerName(rs.getString("customer_name"));
detail.setItemCount(rs.getInt("item_count"));
detail.setTotalQuantity(rs.getInt("total_quantity"));
// 查询订单明细
detail.setItems(getOrderItems(detail.getOrderId()));
return detail;
}
}
}
return null;
}
/**
* 查询订单明细
*/
private List<OrderItemDTO> getOrderItems(int orderId) throws SQLException {
List<OrderItemDTO> items = new ArrayList<>();
String querySQL =
"SELECT item_id, product_id, product_code, product_name, " +
" unit_price, quantity, item_amount, discount_rate, " +
" discount_amount, actual_amount, specifications " +
"FROM order_items " +
"WHERE order_id = ? " +
"ORDER BY item_id";
try (PreparedStatement pstmt = connection.prepareStatement(querySQL)) {
pstmt.setInt(1, orderId);
try (ResultSet rs = pstmt.executeQuery()) {
while (rs.next()) {
OrderItemDTO item = new OrderItemDTO();
item.setItemId(rs.getInt("item_id"));
item.setProductId(rs.getInt("product_id"));
item.setProductCode(rs.getString("product_code"));
item.setProductName(rs.getString("product_name"));
item.setUnitPrice(rs.getBigDecimal("unit_price"));
item.setQuantity(rs.getInt("quantity"));
item.setItemAmount(rs.getBigDecimal("item_amount"));
item.setDiscountRate(rs.getBigDecimal("discount_rate"));
item.setActualAmount(rs.getBigDecimal("actual_amount"));
// 解析JSONB字段
String specsJson = rs.getString("specifications");
if (specsJson != null) {
item.setSpecifications(new JSONObject(specsJson));
}
items.add(item);
}
}
}
return items;
}
/**
* 更新订单状态(带乐观锁)
*/
public boolean updateOrderStatus(String orderNumber, String newStatus,
LocalDateTime currentUpdatedAt) throws SQLException {
String updateSQL =
"UPDATE orders SET " +
"order_status = ?, " +
"updated_at = CURRENT_TIMESTAMP, " +
"updated_by = ? " +
"WHERE order_number = ? " +
"AND updated_at = ? " +
"RETURNING order_id";
try (PreparedStatement pstmt = connection.prepareStatement(updateSQL)) {
pstmt.setString(1, newStatus);
pstmt.setString(2, "system"); // 实际应为当前用户
pstmt.setString(3, orderNumber);
pstmt.setTimestamp(4, Timestamp.valueOf(currentUpdatedAt));
try (ResultSet rs = pstmt.executeQuery()) {
if (rs.next()) {
connection.commit();
System.out.println("订单状态更新成功");
return true;
} else {
System.out.println("订单状态更新失败,可能已被其他用户修改");
connection.rollback();
return false;
}
}
}
}
/**
* 删除订单(级联删除示例)
*/
public boolean deleteOrder(String orderNumber) throws SQLException {
// 先检查订单状态,只有特定状态可删除
String checkSQL =
"SELECT order_status FROM orders WHERE order_number = ?";
String deleteSQL =
"DELETE FROM orders WHERE order_number = ? " +
"AND order_status IN ('已取消', '待处理')";
try (PreparedStatement checkStmt = connection.prepareStatement(checkSQL)) {
checkStmt.setString(1, orderNumber);
try (ResultSet rs = checkStmt.executeQuery()) {
if (rs.next()) {
String status = rs.getString("order_status");
if (!status.equals("已取消") && !status.equals("待处理")) {
System.out.println("订单状态为 " + status + ",不允许删除");
return false;
}
} else {
System.out.println("订单不存在: " + orderNumber);
return false;
}
}
}
// 执行删除(将级联删除order_items中的记录)
try (PreparedStatement deleteStmt = connection.prepareStatement(deleteSQL)) {
deleteStmt.setString(1, orderNumber);
int affectedRows = deleteStmt.executeUpdate();
if (affectedRows > 0) {
connection.commit();
System.out.println("成功删除订单: " + orderNumber);
return true;
} else {
connection.rollback();
System.out.println("删除订单失败");
return false;
}
}
}
/**
* 分页查询订单
*/
public List<OrderSummaryDTO> getOrdersByPage(int page, int pageSize,
String customerName,
LocalDate startDate,
LocalDate endDate) throws SQLException {
List<OrderSummaryDTO> orders = new ArrayList<>();
StringBuilder sqlBuilder = new StringBuilder(
"SELECT o.order_id, o.order_number, o.order_date, o.order_status, " +
" o.total_amount, o.actual_amount, o.payment_status, " +
" c.customer_id, c.customer_name, c.contact_phone " +
"FROM orders o " +
"JOIN customers c ON o.customer_id = c.customer_id " +
"WHERE 1=1"
);
List<Object> params = new ArrayList<>();
// 动态添加查询条件
if (customerName != null && !customerName.trim().isEmpty()) {
sqlBuilder.append(" AND c.customer_name LIKE ?");
params.add("%" + customerName + "%");
}
if (startDate != null) {
sqlBuilder.append(" AND o.order_date >= ?");
params.add(Date.valueOf(startDate));
}
if (endDate != null) {
sqlBuilder.append(" AND o.order_date <= ?");
params.add(Date.valueOf(endDate));
}
//三、迁移最佳实践与风险防控策略
3.4 实战案例:Oracle到金仓数据库迁移全流程
3.4.1 迁移前评估与规划阶段
环境评估与兼容性分析:在开始迁移前,必须进行全面评估。金仓数据库的KDMS工具提供自动化评估能力,可分析源库对象结构、SQL语句、存储过程等,生成详细兼容性报告。
sql
-- KDMS自动生成的评估报告示例(简化版)
/*
兼容性评估报告
源数据库:Oracle 19c
目标数据库:金仓数据库V9
评估时间:2025-12-01
总体兼容度:92.7%
*/
-- 1. 数据类型兼容性分析
SELECT
object_type,
object_name,
issue_type,
issue_description,
recommended_action
FROM migration_assessment_results
WHERE severity_level IN ('HIGH', 'MEDIUM')
ORDER BY object_type, severity_level DESC;
-- 评估结果示例:
/*
OBJECT_TYPE OBJECT_NAME ISSUE_TYPE ISSUE_DESCRIPTION
TABLE EMPLOYEE_SALARY DATATYPE Oracle的NUMBER(38)映射为DECIMAL(38)
FUNCTION CALC_BONUS SYNTAX Oracle的CONNECT BY语法需要改写
TRIGGER UPDATE_SALARY_LOG TIMING BEFORE EACH ROW需调整为BEFORE FOR EACH ROW
VIEW DEPT_EMP_VIEW PERFORMANCE 包含UNION ALL的视图建议拆分为物化视图
*/资源需求评估:基于源库数据量、业务并发量、性能要求等因素,科学规划目标环境资源。
python
#!/usr/bin/env python3
# 迁移资源评估脚本
import pandas as pd
import numpy as np
from datetime import datetime
class MigrationResourceEstimator:
"""迁移资源评估器"""
def __init__(self, source_db_type='Oracle'):
self.source_db_type = source_db_type
self.resource_factors = {
'Oracle': {
'storage_factor': 1.2, # 存储空间放大系数
'memory_factor': 0.8, # 内存需求系数
'cpu_factor': 0.9 # CPU需求系数
},
'SQL Server': {
'storage_factor': 1.15,
'memory_factor': 0.85,
'cpu_factor': 0.95
}
}
def estimate_resources(self, source_stats):
"""估算目标环境资源需求"""
# 源库统计信息
total_data_size_gb = source_stats['data_size_gb']
total_index_size_gb = source_stats['index_size_gb']
peak_connections = source_stats['peak_connections']
peak_tps = source_stats['peak_tps']
# 获取放大系数
factors = self.resource_factors.get(self.source_db_type,
self.resource_factors['Oracle'])
# 计算目标库资源需求
target_resources = {
# 存储空间估算
'estimated_data_size_gb': total_data_size_gb * factors['storage_factor'],
'estimated_index_size_gb': total_index_size_gb * factors['storage_factor'] * 0.8,
'temp_space_gb': total_data_size_gb * 0.3, # 临时空间需求
# 内存估算(基于连接数和活跃数据)
'shared_buffer_gb': max(8, total_data_size_gb * 0.25), # 共享缓冲区
'work_mem_mb': 256, # 工作内存
'maintenance_work_mem_gb': 2, # 维护工作内存
# CPU核心数估算
'cpu_cores': max(4, int(peak_connections / 50) +
int(peak_tps / 1000)),
# 连接数配置
'max_connections': int(peak_connections * 1.5),
'max_prepared_transactions': int(peak_connections * 1.2),
# 存储IOPS估算
'required_iops': int(peak_tps * 10), # 经验系数
'required_throughput_mbps': int(total_data_size_gb * 0.1) # MB/s
}
# 添加冗余配置
target_resources['recommended_memory_gb'] = (
target_resources['shared_buffer_gb'] +
target_resources['work_mem_mb'] * target_resources['max_connections'] / 1024 * 0.1 +
target_resources['maintenance_work_mem_gb']
)
return target_resources
# 使用示例
if __name__ == '__main__':
estimator = MigrationResourceEstimator('Oracle')
source_stats = {
'data_size_gb': 500, # 数据大小500GB
'index_size_gb': 150, # 索引大小150GB
'peak_connections': 800, # 峰值连接数800
'peak_tps': 3500 # 峰值TPS 3500
}
target_resources = estimator.estimate_resources(source_stats)
print("目标环境资源需求估算:")
for key, value in target_resources.items():
if 'gb' in key.lower():
print(f" {key}: {value:.1f} GB")
elif 'mb' in key.lower():
print(f" {key}: {value:.1f} MB")
else:
print(f" {key}: {value}")3.4.2 迁移实施阶段
全量数据迁移策略:采用分阶段、分对象的迁移策略,优先迁移基础数据,再迁移业务数据。
sql
-- 使用KDTS进行分阶段迁移
-- 第一阶段:迁移基础配置表(数据量小,依赖少)
BEGIN;
-- 1. 创建目标表结构(使用KDTS自动生成)
-- 2. 禁用外键约束
ALTER TABLE departments DISABLE TRIGGER ALL;
ALTER TABLE employees DISABLE TRIGGER ALL;
-- 3. 迁移基础数据
-- KDTS命令示例(实际通过工具界面操作)
-- kdts_migrate --type TABLE --table "departments,employees" --batch-size 10000
-- 4. 数据验证
SELECT
'departments' as table_name,
(SELECT COUNT(*) FROM source.departments) as source_count,
(SELECT COUNT(*) FROM target.departments) as target_count,
CASE
WHEN (SELECT COUNT(*) FROM source.departments) =
(SELECT COUNT(*) FROM target.departments)
THEN 'OK'
ELSE 'MISMATCH'
END as validation_result
UNION ALL
SELECT
'employees' as table_name,
(SELECT COUNT(*) FROM source.employees) as source_count,
(SELECT COUNT(*) FROM target.employees) as target_count,
CASE
WHEN (SELECT COUNT(*) FROM source.employees) =
(SELECT COUNT(*) FROM target.employees)
THEN 'OK'
ELSE 'MISMATCH'
END as validation_result;
-- 5. 启用约束
ALTER TABLE departments ENABLE TRIGGER ALL;
ALTER TABLE employees ENABLE TRIGGER ALL;
COMMIT;
-- 第二阶段:迁移业务数据表
-- 采用并行迁移策略提升效率
DO $$
DECLARE
migration_start_time TIMESTAMP;
migration_end_time TIMESTAMP;
table_name TEXT;
row_count BIGINT;
BEGIN
migration_start_time := clock_timestamp();
-- 并行迁移多个大表
-- 表1:销售订单(约1000万条记录)
PERFORM kdts_parallel_migrate(
table_name := 'sales_orders',
source_query := 'SELECT * FROM source.sales_orders WHERE order_date >= DATE ''2024-01-01''',
target_table := 'target.sales_orders',
parallel_degree := 8,
batch_size := 50000
);
-- 表2:订单明细(约3000万条记录)
PERFORM kdts_parallel_migrate(
table_name := 'order_items',
source_query := 'SELECT * FROM source.order_items WHERE order_id IN (SELECT order_id FROM source.sales_orders)',
target_table := 'target.order_items',
parallel_degree := 12,
batch_size := 100000
);
-- 表3:客户信息(约500万条记录)
PERFORM kdts_parallel_migrate(
table_name := 'customers',
source_query := 'SELECT * FROM source.customers WHERE status = ''ACTIVE''',
target_table := 'target.customers',
parallel_degree := 4,
batch_size := 25000
);
migration_end_time := clock_timestamp();
-- 记录迁移统计
INSERT INTO migration_statistics (
migration_phase,
table_name,
rows_migrated,
start_time,
end_time,
duration_seconds,
status
)
SELECT
'PHASE2',
table_name,
row_count,
migration_start_time,
migration_end_time,
EXTRACT(EPOCH FROM (migration_end_time - migration_start_time)),
'COMPLETED'
FROM (
VALUES
('sales_orders', (SELECT COUNT(*) FROM target.sales_orders)),
('order_items', (SELECT COUNT(*) FROM target.order_items)),
('customers', (SELECT COUNT(*) FROM target.customers))
) AS t(table_name, row_count);
END
$$;
-- 第三阶段:迁移LOB大对象数据
-- 采用分片传输策略,确保大对象完整性
BEGIN;
-- 配置LOB迁移参数
SET kdts.lob_chunk_size = 65536; -- 64KB分片
SET kdts.lob_buffer_size = 1048576; -- 1MB缓冲区
SET kdts.lob_validation = 'checksum'; -- 启用校验和验证
-- 迁移包含BLOB的表
PERFORM kdts_migrate_lobs(
table_name := 'product_images',
blob_column := 'image_data',
source_filter := 'WHERE image_size > 1048576', -- 只迁移大于1MB的图像
target_table := 'target.product_images',
resume_point := NULL -- 从上次中断处继续
);
-- 验证LOB完整性
SELECT
'product_images' as table_name,
COUNT(*) as total_records,
SUM(
CASE
WHEN kdts_verify_blob_checksum(image_data, source_checksum)
THEN 1
ELSE 0
END
) as valid_records,
SUM(
CASE
WHEN kdts_verify_blob_checksum(image_data, source_checksum)
THEN 0
ELSE 1
END
) as corrupted_records
FROM target.product_images;
-- 记录LOB迁移结果
INSERT INTO lob_migration_log (
table_name,
lob_type,
total_size_mb,
average_size_kb,
migration_duration,
corruption_rate
)
SELECT
'product_images',
'BLOB',
SUM(LENGTH(image_data) / 1048576.0),
AVG(LENGTH(image_data) / 1024.0),
INTERVAL '2 hours 15 minutes',
0.0001
FROM target.product_images;
COMMIT;3.4.3 增量数据同步阶段
基于KFS的实时增量同步:在全量迁移完成后,启用增量同步机制,确保数据实时一致性。
sql
-- 配置KFS增量同步任务
-- 1. 创建同步用户和权限
CREATE USER kfs_sync REPLICATION LOGIN PASSWORD 'secure_password_123';
GRANT SELECT ON ALL TABLES IN SCHEMA public TO kfs_sync;
GRANT USAGE ON SCHEMA public TO kfs_sync;
-- 2. 配置源端抽取进程
BEGIN;
-- 创建抽取配置
INSERT INTO kfs_extract_config (
extract_name,
source_db_type,
source_host,
source_port,
source_service,
source_user,
tables_filter,
extract_mode,
parallel_threads,
heartbeat_interval
) VALUES (
'oracle_to_kingbase',
'ORACLE',
'192.168.1.100',
1521,
'ORCL',
'kfs_sync',
'PUBLIC.*',
'INTEGRATED', -- 集成模式,直接读取日志
4,
30 -- 30秒心跳间隔
);
-- 启用表级补充日志(Oracle源端)
-- 注意:以下为Oracle SQL,需在源库执行
/*
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
ALTER TABLE sales_orders ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
ALTER TABLE order_items ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
ALTER TABLE customers ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY) COLUMNS;
*/
-- 记录起始SCN/LSN
INSERT INTO kfs_extract_checkpoints (
extract_name,
start_scn,
start_timestamp,
initialized
) VALUES (
'oracle_to_kingbase',
(SELECT CURRENT_SCN FROM v$database), -- Oracle当前SCN
CURRENT_TIMESTAMP,
true
);
COMMIT;
-- 3. 配置目标端复制进程
BEGIN;
-- 创建复制配置
INSERT INTO kfs_replicat_config (
replicat_name,
target_host,
target_port,
target_database,
target_user,
map_rules,
handle_collisions,
replicate_mode,
batch_size,
transaction_count
) VALUES (
'kingbase_replicat',
'192.168.1.200',
54321,
'target_db',
'kfs_sync',
'PUBLIC.*, TARGET PUBLIC.*', -- 表映射规则
'OVERWRITE', -- 冲突处理策略
'INTEGRATED',
1000, -- 批量大小
100 -- 每批事务数
);
-- 配置表级复制参数
INSERT INTO kfs_table_config (
replicat_name,
table_name,
use_truncate,
handle_updates,
key_columns,
compare_columns,
exclude_operations
) VALUES
('kingbase_replicat', 'sales_orders', false, true, 'order_id', 'order_date,total_amount', ''),
('kingbase_replicat', 'order_items', false, true, 'item_id', 'quantity,unit_price', ''),
('kingbase_replicat', 'customers', false, true, 'customer_id', 'customer_name,status', 'DELETE');
-- 启动复制进程
UPDATE kfs_replicat_config
SET status = 'RUNNING',
start_time = CURRENT_TIMESTAMP
WHERE replicat_name = 'kingbase_replicat';
COMMIT;
-- 4. 监控增量同步状态
WITH sync_metrics AS (
SELECT
e.extract_name,
e.lag_seconds,
e.throughput_rows_sec,
e.last_error,
r.replicat_name,
r.applied_rows,
r.applied_lag_seconds,
r.last_applied_timestamp
FROM kfs_extract_status e
JOIN kfs_replicat_status r ON e.extract_name || '_replicat' = r.replicat_name
WHERE e.status = 'RUNNING'
)
SELECT
extract_name,
replicat_name,
lag_seconds as extract_lag_sec,
applied_lag_seconds as apply_lag_sec,
throughput_rows_sec,
applied_rows,
CASE
WHEN lag_seconds > 60 OR applied_lag_seconds > 60
THEN 'WARNING'
WHEN lag_seconds > 300 OR applied_lag_seconds > 300
THEN 'CRITICAL'
ELSE 'NORMAL'
END as sync_status,
last_applied_timestamp
FROM sync_metrics
ORDER BY extract_lag_sec DESC;
-- 5. 数据一致性验证(定时任务)
CREATE OR REPLACE FUNCTION verify_incremental_sync()
RETURNS TABLE (
table_name TEXT,
source_count BIGINT,
target_count BIGINT,
diff_count BIGINT,
last_verified TIMESTAMP,
verification_result TEXT
) AS $$
DECLARE
verification_start TIMESTAMP := clock_timestamp();
verification_id BIGINT;
BEGIN
-- 生成验证ID
INSERT INTO sync_verification_log (start_time, verification_type)
VALUES (verification_start, 'INCREMENTAL')
RETURNING verification_id INTO verification_id;
-- 对关键表进行快速计数验证
RETURN QUERY
WITH table_counts AS (
SELECT
'sales_orders' as table_name,
(SELECT COUNT(*) FROM source.sales_orders
WHERE update_time >= (verification_start - INTERVAL '1 hour')) as source_cnt,
(SELECT COUNT(*) FROM target.sales_orders
WHERE update_time >= (verification_start - INTERVAL '1 hour')) as target_cnt
UNION ALL
SELECT
'order_items',
(SELECT COUNT(*) FROM source.order_items
WHERE update_time >= (verification_start - INTERVAL '1 hour')),
(SELECT COUNT(*) FROM target.order_items
WHERE update_time >= (verification_start - INTERVAL '1 hour'))
UNION ALL
SELECT
'customers',
(SELECT COUNT(*) FROM source.customers
WHERE update_time >= (verification_start - INTERVAL '1 hour')),
(SELECT COUNT(*) FROM target.customers
WHERE update_time >= (verification_start - INTERVAL '1 hour'))
)
SELECT
tc.table_name,
tc.source_cnt,
tc.target_cnt,
ABS(tc.source_cnt - tc.target_cnt) as diff_count,
verification_start as last_verified,
CASE
WHEN ABS(tc.source_cnt - tc.target_cnt) = 0 THEN 'SYNCED'
WHEN ABS(tc.source_cnt - tc.target_cnt) <= 10 THEN 'MINOR_DIFF'
ELSE 'OUT_OF_SYNC'
END as verification_result
FROM table_counts tc;
-- 记录验证结果
UPDATE sync_verification_log
SET
end_time = clock_timestamp(),
verified_tables = (SELECT COUNT(*) FROM table_counts),
out_of_sync_tables = (SELECT COUNT(*) FROM table_counts
WHERE ABS(source_cnt - target_cnt) > 0)
WHERE verification_id = verification_id;
END;
$$ LANGUAGE plpgsql;
-- 创建定时验证任务(每5分钟执行一次)
SELECT cron.schedule(
'verify-incremental-sync',
'*/5 * * * *', -- 每5分钟
$$SELECT * FROM verify_incremental_sync()$$
);3.4.4 迁移后验证与优化阶段
多层次数据一致性验证:迁移完成后,必须进行全面的数据验证。
sql
-- 数据一致性验证脚本
-- 1. 表级基础验证
SELECT
schemaname,
tablename,
source_rowcount,
target_rowcount,
source_rowcount - target_rowcount as row_diff,
CASE
WHEN source_rowcount = target_rowcount THEN 'PASS'
ELSE 'FAIL'
END as rowcount_validation,
source_size_mb,
target_size_mb,
ABS(source_size_mb - target_size_mb) as size_diff_mb
FROM (
SELECT
n.nspname as schemaname,
c.relname as tablename,
(SELECT COUNT(*) FROM source_table) as source_rowcount,
(SELECT COUNT(*) FROM target_table) as target_rowcount,
(SELECT pg_total_relation_size('source_table') / 1048576.0) as source_size_mb,
(SELECT pg_total_relation_size('target_table') / 1048576.0) as target_size_mb
FROM pg_class c
JOIN pg_namespace n ON c.relnamespace = n.oid
WHERE c.relkind = 'r'
AND n.nspname NOT IN ('pg_catalog', 'information_schema')
AND c.relname IN ('sales_orders', 'order_items', 'customers')
) t
ORDER BY row_diff DESC;
-- 2. 内容级抽样验证
WITH sample_verification AS (
SELECT
'sales_orders' as table_name,
COUNT(*) as sampled_records,
SUM(
CASE
WHEN kdts_compare_records(
source_row,
target_row,
exclude_columns := ARRAY['created_at', 'updated_at']
)
THEN 1
ELSE 0
END
) as matched_records,
SUM(
CASE
WHEN kdts_compare_records(
source_row,
target_row,
exclude_columns := ARRAY['created_at', 'updated_at']
)
THEN 0
ELSE 1
END
) as mismatched_records
FROM (
SELECT
s.* as source_row,
t.* as target_row
FROM source.sales_orders s
JOIN target.sales_orders t ON s.order_id = t.order_id
WHERE s.order_date >= CURRENT_DATE - INTERVAL '30 days'
ORDER BY RANDOM()
LIMIT 1000 -- 随机抽样1000条记录
) sample_data
UNION ALL
SELECT
'order_items',
COUNT(*),
SUM(
CASE
WHEN kdts_compare_records(
source_row,
target_row,
exclude_columns := ARRAY['created_at']
)
THEN 1
ELSE 0
END
),
SUM(
CASE
WHEN kdts_compare_records(
source_row,
target_row,
exclude_columns := ARRAY['created_at']
)
THEN 0
ELSE 1
END
)
FROM (
SELECT
s.* as source_row,
t.* as target_row
FROM source.order_items s
JOIN target.order_items t ON s.item_id = t.item_id
WHERE s.create_time >= CURRENT_DATE - INTERVAL '30 days'
ORDER BY RANDOM()
LIMIT 1000
) sample_data
)
SELECT
table_name,
sampled_records,
matched_records,
mismatched_records,
ROUND(matched_records * 100.0 / sampled_records, 2) as match_percentage,
CASE
WHEN matched_records * 100.0 / sampled_records >= 99.99
THEN 'EXCELLENT'
WHEN matched_records * 100.0 / sampled_records >= 99.9
THEN 'GOOD'
WHEN matched_records * 100.0 / sampled_records >= 99.0
THEN 'ACCEPTABLE'
ELSE 'UNACCEPTABLE'
END as data_quality
FROM sample_verification;
-- 3. 业务逻辑验证
WITH business_logic_checks AS (
-- 检查1:订单总金额一致性
SELECT
'order_amount_check' as check_name,
COUNT(*) as total_orders,
SUM(
CASE
WHEN ABS(s.total_amount - t.total_amount) <= 0.01
THEN 1
ELSE 0
END
) as correct_orders,
SUM(
CASE
WHEN ABS(s.total_amount - t.total_amount) > 0.01
THEN 1
ELSE 0
END
) as incorrect_orders
FROM source.sales_orders s
JOIN target.sales_orders t ON s.order_id = t.order_id
WHERE s.order_date >= '2025-01-01'
UNION ALL
-- 检查2:订单明细金额汇总
SELECT
'item_amount_sum_check' as check_name,
COUNT(DISTINCT o.order_id) as checked_orders,
SUM(
CASE
WHEN ABS(o.total_amount - i.item_sum) <= 0.01
THEN 1
ELSE 0
END
) as correct_orders,
SUM(
CASE
WHEN ABS(o.total_amount - i.item_sum) > 0.01
THEN 1
ELSE 0
END
) as incorrect_orders
FROM target.sales_orders o
JOIN (
SELECT
order_id,
SUM(unit_price * quantity) as item_sum
FROM target.order_items
GROUP BY order_id
) i ON o.order_id = i.order_id
WHERE o.order_date >= '2025-01-01'
UNION ALL
-- 检查3:客户订单统计
SELECT
'customer_stats_check' as check_name,
COUNT(DISTINCT c.customer_id) as checked_customers,
SUM(
CASE
WHEN c.total_order_amount = o.order_sum
THEN 1
ELSE 0
END
) as correct_customers,
SUM(
CASE
WHEN c.total_order_amount != o.order_sum
THEN 1
ELSE 0
END
) as incorrect_customers
FROM target.customers c
JOIN (
SELECT
customer_id,
SUM(total_amount) as order_sum
FROM target.sales_orders
GROUP BY customer_id
) o ON c.customer_id = o.customer_id
)
SELECT
check_name,
total_orders as total_items,
correct_orders,
incorrect_orders,
ROUND(correct_orders * 100.0 / total_orders, 2) as accuracy_percentage,
CASE
WHEN correct_orders = total_orders THEN 'PASS'
ELSE 'FAIL'
END as validation_result
FROM business_logic_checks;
-- 4. 性能基准测试对比
WITH performance_comparison AS (
-- 关键查询性能对比
SELECT
'order_query_by_date' as query_name,
(SELECT AVG(execution_time_ms)
FROM source_performance_log
WHERE query_type = 'order_by_date'
AND test_date = CURRENT_DATE) as source_avg_ms,
(SELECT AVG(execution_time_ms)
FROM target_performance_log
WHERE query_type = 'order_by_date'
AND test_date = CURRENT_DATE) as target_avg_ms,
(SELECT COUNT(*)
FROM source_performance_log
WHERE query_type = 'order_by_date'
AND test_date = CURRENT_DATE) as test_count
UNION ALL
SELECT
'customer_lookup',
(SELECT AVG(execution_time_ms)
FROM source_performance_log
WHERE query_type = 'customer_lookup'
AND test_date = CURRENT_DATE),
(SELECT AVG(execution_time_ms)
FROM target_performance_log
WHERE query_type = 'customer_lookup'
AND test_date = CURRENT_DATE),
(SELECT COUNT(*)
FROM source_performance_log
WHERE query_type = 'customer_lookup'
AND test_date = CURRENT_DATE)
UNION ALL
SELECT
'sales_report',
(SELECT AVG(execution_time_ms)
FROM source_performance_log
WHERE query_type = 'sales_report'
AND test_date = CURRENT_DATE),
(SELECT AVG(execution_time_ms)
FROM target_performance_log
WHERE query_type = 'sales_report'
AND test_date = CURRENT_DATE),
(SELECT COUNT(*)
FROM source_performance_log
WHERE query_type = 'sales_report'
AND test_date = CURRENT_DATE)
)
SELECT
query_name,
source_avg_ms,
target_avg_ms,
test_count,
ROUND((source_avg_ms - target_avg_ms) * 100.0 / source_avg_ms, 2) as improvement_percent,
CASE
WHEN target_avg_ms <= source_avg_ms * 1.1 THEN 'ACCEPTABLE'
WHEN target_avg_ms <= source_avg_ms * 1.3 THEN 'NEEDS_OPTIMIZATION'
ELSE 'UNACCEPTABLE'
END as performance_assessment
FROM performance_comparison
WHERE test_count > 0
ORDER BY improvement_percent DESC;迁移后性能优化:基于性能测试结果,进行针对性优化。
sql
-- 迁移后性能优化脚本
-- 1. 统计信息更新
ANALYZE VERBOSE sales_orders;
ANALYZE VERBOSE order_items;
ANALYZE VERBOSE customers;
-- 2. 索引优化
-- 删除迁移过程中创建的不必要索引
SELECT schemaname, tablename, indexname, indexdef
FROM pg_indexes
WHERE schemaname = 'public'
AND indexname LIKE '%_migration_idx'
AND NOT EXISTS (
SELECT 1 FROM pg_stat_user_indexes
WHERE schemaname = pg_indexes.schemaname
AND tablename = pg_indexes.tablename
AND indexname = pg_indexes.indexname
AND idx_scan > 0
);
-- 创建缺失的索引
CREATE INDEX IF NOT EXISTS idx_sales_orders_customer_date
ON sales_orders(customer_id, order_date DESC);
CREATE INDEX IF NOT EXISTS idx_order_items_order_product
ON order_items(order_id, product_id);
CREATE INDEX IF NOT EXISTS idx_customers_name_phone
ON customers(customer_name, contact_phone);
-- 3. 查询计划优化
-- 检查慢查询
SELECT
query,
calls,
total_time,
mean_time,
rows,
ROUND(100.0 * shared_blks_hit / nullif(shared_blks_hit + shared_blks_read, 0), 2) as hit_percent
FROM pg_stat_statements
WHERE mean_time > 100 -- 平均执行时间超过100ms
AND query NOT LIKE '%pg_%'
ORDER BY total_time DESC
LIMIT 20;
-- 4. 分区表优化(针对大表)
-- 将销售订单表按月份分区
CREATE TABLE sales_orders_partitioned (
LIKE sales_orders INCLUDING ALL
) PARTITION BY RANGE (order_date);
-- 创建分区
CREATE TABLE sales_orders_202501 PARTITION OF sales_orders_partitioned
FOR VALUES FROM ('2025-01-01') TO ('2025-02-01');
CREATE TABLE sales_orders_202502 PARTITION OF sales_orders_partitioned
FOR VALUES FROM ('2025-02-01') TO ('2025-03-01');
-- 5. 物化视图优化
-- 创建常用报表的物化视图
CREATE MATERIALIZED VIEW mv_daily_sales_summary AS
SELECT
order_date,
COUNT(DISTINCT order_id) as order_count,
COUNT(*) as item_count,
SUM(total_amount) as total_sales,
SUM(discount_amount) as total_discount,
AVG(total_amount) as avg_order_value
FROM sales_orders
WHERE order_date >= CURRENT_DATE - INTERVAL '90 days'
GROUP BY order_date
WITH DATA;
-- 创建刷新策略
CREATE UNIQUE INDEX idx_mv_daily_sales_date
ON mv_daily_sales_summary(order_date);
-- 自动刷新物化视图(每天凌晨1点)
SELECT cron.schedule(
'refresh-daily-sales-mv',
'0 1 * * *',
$$REFRESH MATERIALIZED VIEW CONCURRENTLY mv_daily_sales_summary$$
);
-- 6. 连接池优化
-- 检查连接使用情况
SELECT
datname,
usename,
COUNT(*) as connection_count,
SUM(CASE WHEN state = 'active' THEN 1 ELSE 0 END) as active_connections,
SUM(CASE WHEN state = 'idle' THEN 1 ELSE 0 END) as idle_connections,
SUM(CASE WHEN state = 'idle in transaction' THEN 1 ELSE 0 END) as idle_in_xact,
MAX(age(backend_start)) as oldest_connection
FROM pg_stat_activity
WHERE datname IS NOT NULL
GROUP BY datname, usename
ORDER BY connection_count DESC;
-- 7. 内存参数优化
-- 根据实际使用情况调整内存参数
ALTER SYSTEM SET shared_buffers = '8GB'; -- 总内存的25%
ALTER SYSTEM SET work_mem = '16MB'; -- 每个操作的内存
ALTER SYSTEM SET maintenance_work_mem = '1GB'; -- 维护操作内存
ALTER SYSTEM SET effective_cache_size = '24GB'; -- 优化器假设的缓存大小
-- 8. 监控告警配置
-- 创建性能监控视图
CREATE OR REPLACE VIEW performance_monitoring AS
SELECT
'query_performance' as metric_type,
ROUND(AVG(total_time / calls), 2) as avg_query_time_ms,
MAX(total_time / calls) as max_query_time_ms,
COUNT(*) as slow_query_count
FROM pg_stat_statements
WHERE total_time / calls > 100 -- 超过100ms的查询
UNION ALL
SELECT
'connection_usage',
COUNT(*) as total_connections,
SUM(CASE WHEN state = 'active' THEN 1 ELSE 0 END) as active_connections,
NULL
FROM pg_stat_activity
WHERE datname = current_database()
UNION ALL
SELECT
'cache_efficiency',
ROUND(SUM(blks_hit) * 100.0 / NULLIF(SUM(blks_hit + blks_read), 0), 2) as hit_ratio,
NULL,
NULL
FROM pg_stat_database
WHERE datname = current_database();
-- 创建告警规则
INSERT INTO performance_alerts (
alert_name,
metric_type,
threshold_value,
severity,
notification_channel
) VALUES
('slow_query_alert', 'avg_query_time_ms', 500, 'WARNING', 'email'),
('cache_hit_low', 'hit_ratio', 90, 'WARNING', 'email'),
('connection_high', 'total_connections', 500, 'CRITICAL', 'sms,email');四、迁移风险防控的"金仓方案"
4.1 完整性风险防控策略
字符集与时区问题解决方案:金仓数据库通过多级映射机制确保字符集与时区数据的完整性。
sql
-- 字符集映射配置
-- 1. 源库字符集检测
SELECT
parameter,
value as source_charset
FROM source.nls_database_parameters
WHERE parameter IN ('NLS_CHARACTERSET', 'NLS_NCHAR_CHARACTERSET');
-- 2. 目标库字符集配置
SHOW server_encoding;
SHOW client_encoding;
-- 3. 迁移时字符集转换配置
-- KDTS配置文件示例
/*
[charset_mapping]
oracle.al32utf8 = utf8
oracle.zht16big5 = big5
oracle.us7ascii = latin1
[timezone_mapping]
oracle.timezone = Asia/Shanghai
default_timezone = +08:00
*/
-- 4. 迁移后验证
SELECT
table_name,
column_name,
data_type,
character_maximum_length,
collation_name,
COUNT(*) as affected_rows
FROM information_schema.columns
WHERE table_schema = 'public'
AND data_type IN ('character', 'character varying', 'text')
GROUP BY table_name, column_name, data_type,
character_maximum_length, collation_name
ORDER BY table_name, column_name;
-- 5. 时区数据迁移配置
-- 源库时区数据提取
SELECT
column_name,
data_type,
COUNT(*) as row_count,
MIN(timezone_value) as min_timezone,
MAX(timezone_value) as max_timezone
FROM (
SELECT
order_id,
order_time AT TIME ZONE 'UTC' as utc_time,
EXTRACT(TIMEZONE_HOUR FROM order_time) as timezone_hour,
EXTRACT(TIMEZONE_MINUTE FROM order_time) as timezone_minute
FROM source.sales_orders
WHERE order_time IS NOT NULL
) t
GROUP BY column_name, data_type;
-- 目标库时区转换函数
CREATE OR REPLACE FUNCTION convert_oracle_timestamp(
oracle_timestamp TIMESTAMP,
oracle_timezone VARCHAR(50)
) RETURNS TIMESTAMP WITH TIME ZONE AS $$
BEGIN
-- 处理Oracle的TIMESTAMP WITH TIME ZONE转换
RETURN oracle_timestamp AT TIME ZONE oracle_timezone;
EXCEPTION
WHEN OTHERS THEN
-- 如果时区无效,使用默认时区
RETURN oracle_timestamp AT TIME ZONE 'Asia/Shanghai';
END;
$$ LANGUAGE plpgsql;
-- 迁移脚本中使用时区转换
INSERT INTO target.sales_orders (
order_id,
order_time_tz,
order_time_local
)
SELECT
order_id,
convert_oracle_timestamp(order_time, order_timezone) as order_time_tz,
convert_oracle_timestamp(order_time, order_timezone) AT TIME ZONE 'Asia/Shanghai' as order_time_local
FROM source.sales_orders;大对象迁移完整性保障:针对BLOB/CLOB等大对象,采用分片校验机制。
java
// Java大对象迁移完整性校验示例
package com.kingbase.migration.lob;
import java.io.*;
import java.security.MessageDigest;
import java.sql.*;
import java.util.Arrays;
public class LOBIntegrityVerifier {
private final Connection sourceConn;
private final Connection targetConn;
private final int chunkSize = 65536; // 64KB分片
public LOBIntegrityVerifier(Connection sourceConn, Connection targetConn) {
this.sourceConn = sourceConn;
this.targetConn = targetConn;
}
/**
* 验证BLOB数据完整性
*/
public VerificationResult verifyBlobIntegrity(String tableName,
String blobColumn,
String idColumn)
throws SQLException, IOException {
VerificationResult result = new VerificationResult(tableName, blobColumn);
// 查询源库和目标库的BLOB数据
String sourceQuery = String.format(
"SELECT %s, %s FROM %s WHERE %s IS NOT NULL",
idColumn, blobColumn, tableName, blobColumn
);
String targetQuery = String.format(
"SELECT %s, %s FROM %s WHERE %s IS NOT NULL",
idColumn, blobColumn, tableName, blobColumn
);
try (
PreparedStatement sourceStmt = sourceConn.prepareStatement(sourceQuery);
PreparedStatement targetStmt = targetConn.prepareStatement(targetQuery);
ResultSet sourceRs = sourceStmt.executeQuery();
ResultSet targetRs = targetStmt.executeQuery()
) {
// 构建目标记录映射
java.util.Map<Object, byte[]> targetMap = new java.util.HashMap<>();
while (targetRs.next()) {
Object id = targetRs.getObject(idColumn);
Blob blob = targetRs.getBlob(blobColumn);
if (blob != null) {
targetMap.put(id, blob.getBytes(1, (int) blob.length()));
}
}
// 逐条验证源记录
while (sourceRs.next()) {
Object id = sourceRs.getObject(idColumn);
Blob sourceBlob = sourceRs.getBlob(blobColumn);
if (sourceBlob == null) {
if (targetMap.containsKey(id)) {
result.addMismatch(id, "Source is NULL but target has data");
}
continue;
}
byte[] sourceData = sourceBlob.getBytes(1, (int) sourceBlob.length());
byte[] targetData = targetMap.get(id);
if (targetData == null) {
result.addMismatch(id, "Target is NULL but source has data");
continue;
}
// 校验数据完整性
if (!verifyBlobData(sourceData, targetData, id)) {
result.addMismatch(id, "Data content mismatch");
} else {
result.addMatch(id);
}
}
// 检查目标库多出的记录
for (Object id : targetMap.keySet()) {
String checkSql = String.format("SELECT 1 FROM %s WHERE %s = ?", tableName, idColumn);
try (PreparedStatement checkStmt = sourceConn.prepareStatement(checkSql)) {
checkStmt.setObject(1, id);
try (ResultSet checkRs = checkStmt.executeQuery()) {
if (!checkRs.next()) {
result.addMismatch(id, "Record exists in target but not in source");
}
}
}
}
}
return result;
}
/**
* 分片校验BLOB数据
*/
private boolean verifyBlobData(byte[] sourceData, byte[] targetData, Object id)
throws IOException {
// 检查数据长度
if (sourceData.length != targetData.length) {
System.err.printf("Length mismatch for ID %s: source=%d, target=%d%n",
id, sourceData.length, targetData.length);
return false;
}
// 计算MD5校验和
String sourceChecksum = calculateChecksum(sourceData);
String targetChecksum = calculateChecksum(targetData);
if (!sourceChecksum.equals(targetChecksum)) {
// 如果整体校验失败,进行分片校验定位问题
return verifyByChunks(sourceData, targetData, id);
}
return true;
}
/**
* 分片校验定位问题区域
*/
private boolean verifyByChunks(byte[] sourceData, byte[] targetData, Object id) {
int totalChunks = (int) Math.ceil(sourceData.length / (double) chunkSize);
int mismatchedChunks = 0;
for (int i = 0; i < totalChunks; i++) {
int start = i * chunkSize;
int end = Math.min(start + chunkSize, sourceData.length);
byte[] sourceChunk = Arrays.copyOfRange(sourceData, start, end);
byte[] targetChunk = Arrays.copyOfRange(targetData, start, end);
String sourceChunkChecksum = calculateChecksum(sourceChunk);
String targetChunkChecksum = calculateChecksum(targetChunk);
if (!sourceChunkChecksum.equals(targetChunkChecksum)) {
mismatchedChunks++;
System.err.printf("Chunk %d mismatch for ID %s (bytes %d-%d)%n",
i, id, start, end);
// 可以进一步进行字节级比较
if (sourceChunk.length == targetChunk.length) {
for (int j = 0; j < sourceChunk.length; j++) {
if (sourceChunk[j] != targetChunk[j]) {
System.err.printf(" Byte %d: source=0x%02X, target=0x%02X%n",
start + j, sourceChunk[j] & 0xFF, targetChunk[j] & 0xFF);
}
}
}
}
}
System.err.printf("Total mismatched chunks for ID %s: %d/%d%n",
id, mismatchedChunks, totalChunks);
return mismatchedChunks == 0;
}
/**
* 计算MD5校验和
*/
private String calculateChecksum(byte[] data) {
try {
MessageDigest md = MessageDigest.getInstance("MD5");
byte[] digest = md.digest(data);
StringBuilder sb = new StringBuilder();
for (byte b : digest) {
sb.append(String.format("%02x", b));
}
return sb.toString();
} catch (Exception e) {
throw new RuntimeException("Failed to calculate checksum", e);
}
}
/**
* 验证结果类
*/
public static class VerificationResult {
private final String tableName;
private final String columnName;
private int totalRecords = 0;
private int matchedRecords = 0;
private int mismatchedRecords = 0;
private final java.util.List<String> mismatchDetails = new java.util.ArrayList<>();
public VerificationResult(String tableName, String columnName) {
this.tableName = tableName;
this.columnName = columnName;
}
public void addMatch(Object id) {
totalRecords++;
matchedRecords++;
}
public void addMismatch(Object id, String reason) {
totalRecords++;
mismatchedRecords++;
mismatchDetails.add(String.format("ID %s: %s", id, reason));
}
public void printSummary() {
System.out.println("=== BLOB Integrity Verification Summary ===");
System.out.printf("Table: %s, Column: %s%n", tableName, columnName);
System.out.printf("Total Records: %d%n", totalRecords);
System.out.printf("Matched: %d (%.2f%%)%n",
matchedRecords, totalRecords > 0 ? matchedRecords * 100.0 / totalRecords : 0);
System.out.printf("Mismatched: %d (%.2f%%)%n",
mismatchedRecords, totalRecords > 0 ? mismatchedRecords * 100.0 / totalRecords : 0);
if (!mismatchDetails.isEmpty()) {
System.out.println("Mismatch Details:");
for (String detail : mismatchDetails) {
System.out.println(" - " + detail);
}
}
}
}
}4.2 一致性风险防控策略
增量同步断点管理:金仓KFS工具通过多重机制确保增量同步的准确性。
sql
-- 增量同步断点管理方案
-- 1. 断点信息表设计
CREATE TABLE kfs_checkpoint_management (
checkpoint_id SERIAL PRIMARY KEY,
extract_name VARCHAR(100) NOT NULL,
replicat_name VARCHAR(100) NOT NULL,
source_scn NUMBER(20), -- Oracle SCN
source_lsn VARCHAR(100), -- 其他数据库LSN
source_timestamp TIMESTAMP,
target_position VARCHAR(200),
checkpoint_type VARCHAR(20) CHECK (checkpoint_type IN ('FULL', 'INCREMENTAL', 'RESUME')),
checkpoint_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
data_verified BOOLEAN DEFAULT false,
verified_rows INTEGER,
verification_time TIMESTAMP,
retention_days INTEGER DEFAULT 90,
metadata JSONB
);
-- 创建索引优化查询
CREATE INDEX idx_kfs_checkpoint_extract ON kfs_checkpoint_management(extract_name, checkpoint_time);
CREATE INDEX idx_kfs_checkpoint_type ON kfs_checkpoint_management(checkpoint_type);
CREATE INDEX idx_kfs_checkpoint_verified ON kfs_checkpoint_management(data_verified);
-- 2. 断点保存策略
CREATE OR REPLACE PROCEDURE save_checkpoint(
p_extract_name VARCHAR,
p_replicat_name VARCHAR,
p_source_scn NUMBER DEFAULT NULL,
p_source_lsn VARCHAR DEFAULT NULL,
p_checkpoint_type VARCHAR DEFAULT 'INCREMENTAL'
) AS $$
DECLARE
v_source_timestamp TIMESTAMP;
v_target_position VARCHAR;
BEGIN
-- 获取源端当前位置
IF p_source_scn IS NOT NULL THEN
v_source_timestamp := (SELECT current_timestamp FROM dual); -- Oracle语法示例
ELSIF p_source_lsn IS NOT NULL THEN
v_source_timestamp := CURRENT_TIMESTAMP;
END IF;
-- 获取目标端应用位置
SELECT applied_position INTO v_target_position
FROM kfs_replicat_status
WHERE replicat_name = p_replicat_name;
-- 保存检查点
INSERT INTO kfs_checkpoint_management (
extract_name,
replicat_name,
source_scn,
source_lsn,
source_timestamp,
target_position,
checkpoint_type,
metadata
) VALUES (
p_extract_name,
p_replicat_name,
p_source_scn,
p_source_lsn,
v_source_timestamp,
v_target_position,
p_checkpoint_type,
jsonb_build_object(
'host', inet_server_addr(),
'database', current_database(),
'user', current_user,
'application_name', current_setting('application_name')
)
);
-- 清理过期检查点
DELETE FROM kfs_checkpoint_management
WHERE checkpoint_time < CURRENT_TIMESTAMP - INTERVAL '90 days'
AND checkpoint_type = 'INCREMENTAL'
AND data_verified = true;
COMMIT;
END;
$$ LANGUAGE plpgsql;
-- 3. 断点恢复策略
CREATE OR REPLACE FUNCTION restore_from_checkpoint(
p_extract_name VARCHAR,
p_replicat_name VARCHAR,
p_checkpoint_time TIMESTAMP DEFAULT NULL
) RETURNS TABLE (
restore_point VARCHAR,
source_position VARCHAR,
target_position VARCHAR,
records_to_replay BIGINT,
estimated_time INTERVAL
) AS $$
DECLARE
v_checkpoint_record RECORD;
v_source_position VARCHAR;
v_target_position VARCHAR;
BEGIN
-- 获取最近的检查点
IF p_checkpoint_time IS NULL THEN
SELECT * INTO v_checkpoint_record
FROM kfs_checkpoint_management
WHERE extract_name = p_extract_name
AND replicat_name = p_replicat_name
AND data_verified = true
ORDER BY checkpoint_time DESC
LIMIT 1;
ELSE
SELECT * INTO v_checkpoint_record
FROM kfs_checkpoint_management
WHERE extract_name = p_extract_name
AND replicat_name = p_replicat_name
AND checkpoint_time <= p_checkpoint_time
AND data_verified = true
ORDER BY checkpoint_time DESC
LIMIT 1;
END IF;
IF NOT FOUND THEN
RAISE EXCEPTION 'No valid checkpoint found for extract %, replicat %',
p_extract_name, p_replicat_name;
END IF;
-- 构建源端位置
IF v_checkpoint_record.source_scn IS NOT NULL THEN
v_source_position := 'SCN:' || v_checkpoint_record.source_scn;
ELSIF v_checkpoint_record.source_lsn IS NOT NULL THEN
v_source_position := 'LSN:' || v_checkpoint_record.source_lsn;
ELSE
v_source_position := 'TIME:' || v_checkpoint_record.source_timestamp;
END IF;
-- 计算需要重放的数据量
RETURN QUERY
WITH replay_stats AS (
SELECT
COUNT(*) as record_count,
MIN(change_time) as min_time,
MAX(change_time) as max_time
FROM source.change_log -- 假设有变更日志表
WHERE change_time > v_checkpoint_record.source_timestamp
AND table_name IN (
SELECT table_name
FROM kfs_table_config
WHERE replicat_name = p_replicat_name
)
)
SELECT
v_checkpoint_record.checkpoint_id::VARCHAR as restore_point,
v_source_position,
v_checkpoint_record.target_position,
rs.record_count,
CASE
WHEN rs.record_count > 0 THEN
INTERVAL '1 minute' * (rs.record_count / 1000) -- 假设1000条/分钟
ELSE INTERVAL '0'
END as estimated_time
FROM replay_stats rs;
END;
$$ LANGUAGE plpgsql;
-- 4. 断点验证机制
CREATE OR REPLACE PROCEDURE verify_checkpoint_consistency(
p_checkpoint_id INTEGER
) AS $$
DECLARE
v_checkpoint_record RECORD;
v_source_count BIGINT;
v_target_count BIGINT;
v_verified_rows INTEGER := 0;
BEGIN
-- 获取检查点信息
SELECT * INTO v_checkpoint_record
FROM kfs_checkpoint_management
WHERE checkpoint_id = p_checkpoint_id;
IF NOT FOUND THEN
RAISE EXCEPTION 'Checkpoint % not found', p_checkpoint_id;
END IF;
-- 对每个配置的表进行一致性验证
FOR table_rec IN
SELECT table_name, key_columns
FROM kfs_table_config
WHERE replicat_name = v_checkpoint_record.replicat_name
LOOP
-- 根据检查点时间验证数据一致性
EXECUTE format(
'SELECT COUNT(*) FROM source.%I WHERE last_update >= $1',
table_rec.table_name
) INTO v_source_count USING v_checkpoint_record.source_timestamp;
EXECUTE format(
'SELECT COUNT(*) FROM target.%I WHERE last_update >= $1',
table_rec.table_name
) INTO v_target_count USING v_checkpoint_record.source_timestamp;
IF v_source_count = v_target_count THEN
v_verified_rows := v_verified_rows + v_source_count;
-- 进一步进行内容验证(抽样)
PERFORM verify_table_data_consistency(
table_rec.table_name,
table_rec.key_columns,
v_checkpoint_record.source_timestamp
);
ELSE
RAISE WARNING 'Table % count mismatch: source=%, target=%',
table_rec.table_name, v_source_count, v_target_count;
-- 记录详细的不一致信息
INSERT INTO checkpoint_verification_errors (
checkpoint_id,
table_name,
source_count,
target_count,
verification_time
) VALUES (
p_checkpoint_id,
table_rec.table_name,
v_source_count,
v_target_count,
CURRENT_TIMESTAMP
);
END IF;
END LOOP;
-- 更新检查点验证状态
UPDATE kfs_checkpoint_management
SET
data_verified = true,
verified_rows = v_verified_rows,
verification_time = CURRENT_TIMESTAMP
WHERE checkpoint_id = p_checkpoint_id;
COMMIT;
END;
$$ LANGUAGE plpgsql;
-- 5. 自动检查点管理
-- 创建定时检查点任务
SELECT cron.schedule(
'hourly-checkpoint',
'0 * * * *', -- 每小时执行
$$
BEGIN
-- 为每个运行中的同步任务创建检查点
FOR sync_rec IN
SELECT DISTINCT e.extract_name, r.replicat_name
FROM kfs_extract_status e
JOIN kfs_replicat_status r ON e.extract_name || '_replicat' = r.replicat_name
WHERE e.status = 'RUNNING' AND r.status = 'RUNNING'
LOOP
-- 保存检查点
CALL save_checkpoint(
sync_rec.extract_name,
sync_rec.replicat_name,
NULL, -- 自动获取当前SCN/LSN
NULL,
'INCREMENTAL'
);
-- 记录检查点事件
INSERT INTO checkpoint_events (
event_type,
extract_name,
replicat_name,
event_time,
details
) VALUES (
'AUTO_CHECKPOINT',
sync_rec.extract_name,
sync_rec.replicat_name,
CURRENT_TIMESTAMP,
jsonb_build_object('interval', 'hourly')
);
END LOOP;
END;
$$
);
-- 6. 检查点监控告警
CREATE OR REPLACE VIEW checkpoint_monitoring AS
WITH checkpoint_stats AS (
SELECT
extract_name,
replicat_name,
COUNT(*) as checkpoint_count,
MAX(checkpoint_time) as last_checkpoint,
MIN(checkpoint_time) as first_checkpoint,
AVG(EXTRACT(EPOCH FROM (checkpoint_time - LAG(checkpoint_time)
OVER (PARTITION BY extract_name, replicat_name ORDER BY checkpoint_time))
)) as avg_interval_seconds
FROM kfs_checkpoint_management
WHERE checkpoint_time >= CURRENT_TIMESTAMP - INTERVAL '7 days'
GROUP BY extract_name, replicat_name
),
running_syncs AS (
SELECT
e.extract_name,
r.replicat_name,
e.lag_seconds as extract_lag,
r.applied_lag_seconds as apply_lag
FROM kfs_extract_status e
JOIN kfs_replicat_status r ON e.extract_name || '_replicat' = r.replicat_name
WHERE e.status = 'RUNNING' AND r.status = 'RUNNING'
)
SELECT
rs.extract_name,
rs.replicat_name,
cs.checkpoint_count,
cs.last_checkpoint,
cs.avg_interval_seconds,
rs.extract_lag,
rs.apply_lag,
CASE
WHEN cs.last_checkpoint < CURRENT_TIMESTAMP - INTERVAL '2 hours' THEN
'CHECKPOINT_STALE'
WHEN rs.extract_lag > 300 OR rs.apply_lag > 300 THEN
'SYNC_LAG_HIGH'
WHEN cs.avg_interval_seconds > 7200 THEN -- 2小时
'CHECKPOINT_INTERVAL_LONG'
ELSE
'HEALTHY'
END as health_status
FROM running_syncs rs
LEFT JOIN checkpoint_stats cs ON rs.extract_name = cs.extract_name
AND rs.replicat_name = cs.replicat_name;
-- 7. 灾难恢复断点
CREATE OR REPLACE PROCEDURE create_disaster_recovery_point(
p_point_name VARCHAR,
p_description TEXT DEFAULT NULL
) AS $$
DECLARE
v_point_id INTEGER;
BEGIN
-- 停止所有同步任务(优雅停止)
UPDATE kfs_extract_config SET status = 'STOPPING' WHERE status = 'RUNNING';
UPDATE kfs_replicat_config SET status = 'STOPPING' WHERE status = 'RUNNING';
-- 等待任务停止
PERFORM pg_sleep(30);
-- 创建灾难恢复点
INSERT INTO disaster_recovery_points (
point_name,
description,
creation_time,
source_position,
target_position
)
SELECT
p_point_name,
p_description,
CURRENT_TIMESTAMP,
jsonb_agg(
jsonb_build_object(
'extract_name', e.extract_name,
'last_scn', e.last_scn,
'last_lsn', e.last_lsn,
'last_timestamp', e.last_timestamp
)
),
jsonb_agg(
jsonb_build_object(
'replicat_name', r.replicat_name,
'applied_position', r.applied_position,
'last_applied', r.last_applied
)
)
FROM kfs_extract_status e
JOIN kfs_replicat_status r ON e.extract_name || '_replicat' = r.replicat_name;
-- 获取创建的恢复点ID
SELECT currval('disaster_recovery_points_point_id_seq') INTO v_point_id;
-- 为恢复点创建检查点
FOR sync_rec IN
SELECT DISTINCT e.extract_name, r.replicat_name
FROM kfs_extract_status e
JOIN kfs_replicat_status r ON e.extract_name || '_replicat' = r.replicat_name
LOOP
CALL save_checkpoint(
sync_rec.extract_name,
sync_rec.replicat_name,
NULL, NULL, 'FULL'
);
END LOOP;
-- 记录恢复点创建事件
INSERT INTO recovery_events (
event_type,
point_id,
event_time,
details
) VALUES (
'DR_POINT_CREATED',
v_point_id,
CURRENT_TIMESTAMP,
jsonb_build_object('point_name', p_point_name, 'description', p_description)
);
COMMIT;
RAISE NOTICE 'Disaster recovery point % created successfully', p_point_name;
END;
$$ LANGUAGE plpgsql;五、迁移成功的"金标准"与未来展望
5.1 迁移成功的评估标准
根据金仓数据库数百个成功迁移案例的总结,一个成功的数据库迁移项目应满足以下"金标准":
数据完整性标准:
-
数据零丢失:源库所有业务数据(含历史数据)完整迁移至目标库
-
精度零损失:数值、时间、字符等数据类型的精度完全保持
-
约束全生效:所有主键、外键、检查约束、唯一约束等完整生效
-
关系全保留:表间关系、继承关系等数据库对象关系完全保持
数据一致性标准:
-
实时同步:增量数据同步延迟不超过业务允许范围(通常<1分钟)
-
事务一致:跨表事务的原子性、一致性得到保证
-
业务逻辑一致:存储过程、函数、触发器业务逻辑执行结果一致
-
时序一致:数据的时间序列关系完全保持
性能表现标准:
-
查询性能:关键业务查询响应时间不超过源库的120%
-
事务性能:TPS处理能力不低于源库的90%
-
并发性能:支持的业务并发用户数不低于源库水平
-
资源利用率:CPU、内存、IO等资源利用率在合理范围内
业务连续性标准:
-
迁移窗口:计划内停机时间不超过业务允许范围
-
回退能力:具备完整、可验证的回退方案
-
监控覆盖:对迁移全过程有完整的监控和告警
-
文档完整:迁移全过程有完整的技术文档和操作手册
5.2 金仓数据库迁移方案的核心优势
技术优势:
-
深度兼容:对Oracle、MySQL等数据库语法兼容度超过90%
-
高性能迁移:多线程并行迁移,TB级数据迁移时间缩短40%
-
智能评估:自动识别兼容性问题,提供改写建议
-
实时同步:亚秒级增量同步,业务影响最小化
服务优势:
-
专业团队:拥有Oracle ACE、PG专家等认证的专业服务团队
-
丰富经验:在金融、政务、能源等关键行业有数百个成功案例
-
完善工具:提供从评估、迁移到验证的全套工具链
-
持续支持:提供7x24小时原厂技术支持服务
生态优势:
-
广泛适配:与主流中间件、操作系统、硬件平台完成适配认证
-
丰富案例:在各行业有大量经过验证的迁移案例
-
社区活跃:拥有活跃的技术社区和知识库
-
持续演进:产品持续迭代,保持技术领先性
5.3 未来发展趋势
随着信息技术应用创新的深入推进,数据库迁移市场呈现以下发展趋势:
技术趋势:
-
智能化迁移:AI辅助的智能评估和自动化迁移
-
云原生迁移:支持跨云、混合云环境的数据库迁移
-
实时数据湖:迁移与实时数据湖建设相结合
-
安全增强:迁移过程中的数据加密和安全审计
市场趋势:
-
行业深化:从通用场景向行业特色场景深化
-
规模扩大:从单系统迁移向全企业级迁移扩展
-
服务升级:从工具提供向全生命周期服务升级
-
生态融合:与上下游产品形成更紧密的解决方案
金仓数据库的演进方向:
-
更智能:引入机器学习技术,实现迁移过程的智能化
-
更易用:进一步降低迁移门槛,提升用户体验
-
更安全:加强迁移过程的安全控制和审计能力
-
更开放:构建更开放的迁移生态,支持更多数据源和目标
结语
数据库迁移是企业数字化转型和信息技术应用创新的关键环节,也是一项技术复杂度高、风险大的系统工程。金仓数据库凭借深厚的技术积累和丰富的实践经验,形成了完整的迁移解决方案,能够有效应对迁移过程中的完整性与一致性风险。
通过科学的迁移规划、完善的工具链支持、严谨的实施流程和全面的验证机制,金仓数据库已帮助数百家客户成功完成数据库迁移,保障了业务的平稳过渡和数据的安全可靠。
随着技术的不断演进和市场的持续发展,金仓数据库将继续深耕迁移技术,为企业提供更优质、更安全、更高效的数据库迁移服务,助力中国信息技术应用创新事业的蓬勃发展。
了解更多金仓数据库迁移解决方案:
- 访问官方网站:https://www.kingbase.com.cn/