这是 「AI是怎么回事」 系列的第
8篇。我一直很好奇 AI 到底是怎么工作的,于是花了很长时间去拆这个东西------手机为什么换了发型还能认出你,ChatGPT 回答你的那三秒钟里究竟在算什么,AI 为什么能通过律师考试却会一本正经地撒谎。这个系列就是我的探索笔记,发现了很多有意思的东西,想分享给你。觉得不错的话,欢迎分享+关注。

如果你从第 1 篇读到这里,恭喜------你现在对 AI 的理解,已经超过了绝大多数人。
不是因为你知道了什么"内幕",而是因为你真正理解了那些齿轮是怎么转的。
这一篇是第一章的收尾。我不会引入任何新概念------前面 7 篇已经把所有零件都摆在桌上了。今天要做的事只有一件:把这些零件组装起来,让你看到一台完整的机器是怎么运转的。
我们来回答一个具体的问题:当你在 ChatGPT 的对话框里打下"什么是量子力学?",然后按下回车,到你看到屏幕上开始逐字蹦出回答------这短短三秒钟里,到底发生了什么?
三秒钟的全景
先给你看完整的路线图,然后我们一站一站地走。
你打下一句话:"什么是量子力学?"
↓
[第一站:Token 化]
"什么" "是" "量子" "力学" "?"
↓
[第二站:词向量]
每个 Token 变成一串数字(比如 768 个数字)
↓
[第三站:Transformer]
注意力机制在这些数字之间寻找关系
↓
[第四站:神经网络]
数百层的"乘法+加法"运算
↓
[第五站:预测]
算出下一个最可能的词:"量子力学是..."
↓
[第六站:逐词生成]
一个词接一个词,组成完整回答
↓
你看到了 ChatGPT 的回答(大约 3 秒钟)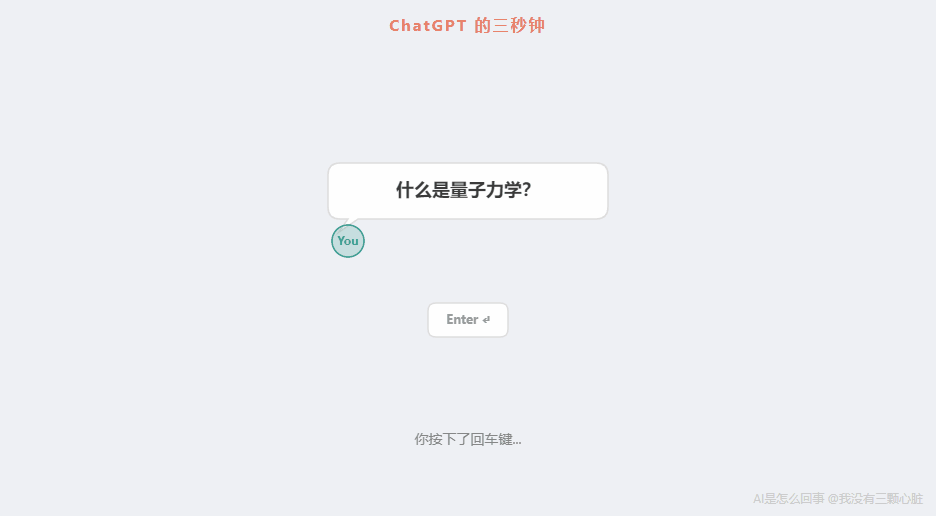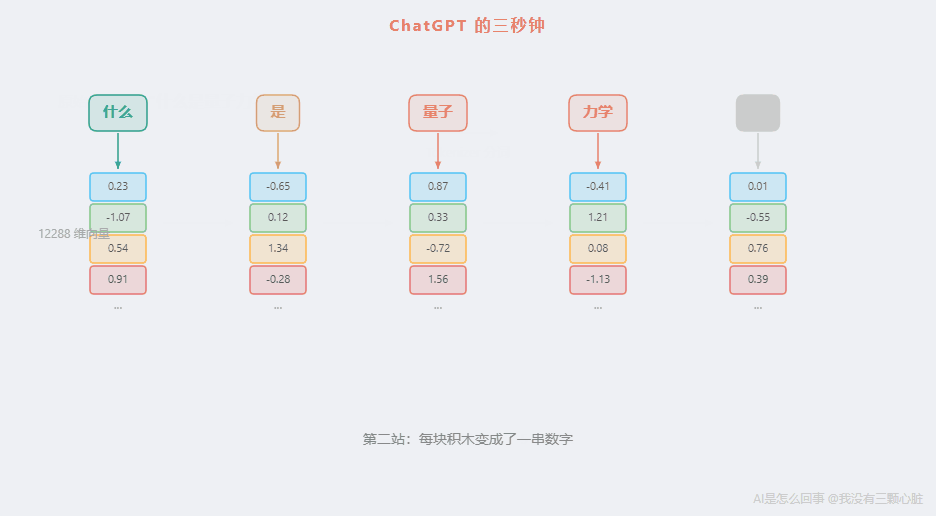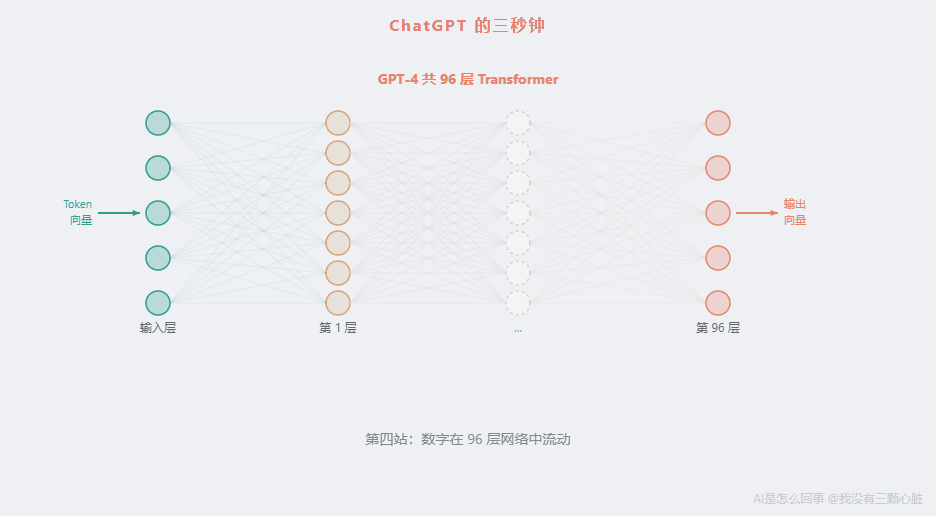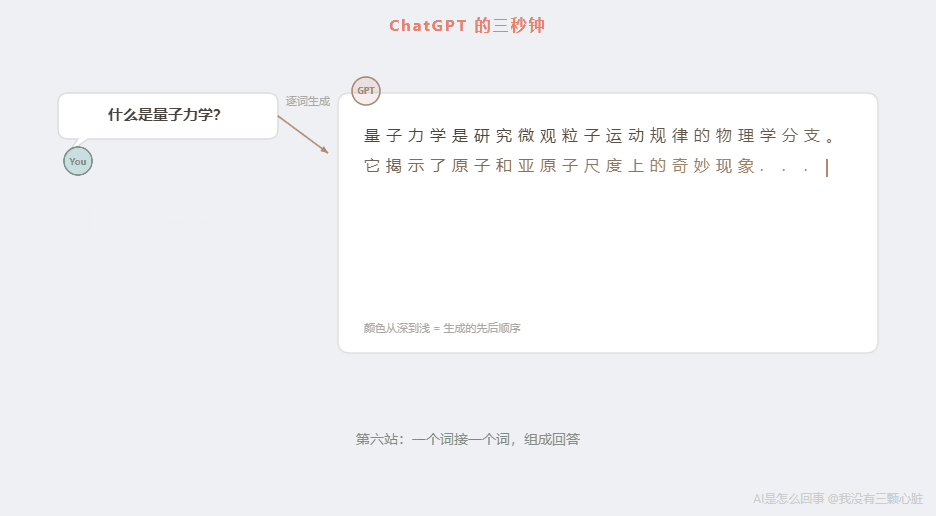
这张图可能看起来很简洁,但每一站背后,都是我们花了整整一篇文章才拆清楚的东西。
现在,让我带你一站一站地走一遍,同时串起前面 7 篇的全部知识。
第一站:你的话变成了碎片
你在输入框里打了"什么是量子力学?"这 7 个字。
但 ChatGPT 不认识中文。准确地说,它不认识任何人类语言------它只认识数字。
所以第一步,是把你的话拆成 AI 能处理的最小单位。这些单位叫做 Token。
如果你还记得第 2 篇的内容:Token 不完全等于"词"。它可能是一个字、一个词、甚至是一个词的一部分。怎么拆,取决于 AI 使用的"词表"------就像一本字典,字典里有的词就是一个 Token,没有的就要拆成更小的碎片。
"什么是量子力学?"可能会被拆成这样:
"什么" → Token #1
"是" → Token #2
"量子" → Token #3
"力学" → Token #4
"?" → Token #55 个 Token。就像把一个句子打碎成 5 块积木。
这一步纯粹是机械性的------查表、拆分,没有任何"理解"在里面。
第二站:碎片变成数字
现在 AI 手里有 5 个 Token。但 Token 只是一个"编号"------比如"量子"可能对应编号第 38721 号。一个编号本身没有任何含义。
这就是第 2 篇花了很大篇幅解释的事情:每个 Token 会被转换成一串数字,叫做词向量。
"量子"这个 Token,会被翻译成一串 768 个数字(也可能是更多------GPT-3 用的是 12288 维的向量)。类似这样:
"量子" → [0.23, -0.87,0.45,1.12, -0.34,0.67, ..., -0.91]
(768 个或更多数字)768 个数字,组成了一个高维空间中的一个"点"。
这些数字不是随便填的。还记得第 2 篇里那个让人惊叹的例子吗?
"国王" - "男人" + "女人" ≈ "王后"
能做到这件事,是因为这些词向量在训练过程中被精心调整过------意思相近的词,在这个 768 维空间里距离就近;意思不同的词,距离就远。"量子"和"物理"的距离,比"量子"和"炒菜"的距离近得多。
语义------人类觉得最"虚"的东西------在 AI 这里变成了可以测量的数字距离。
这一步之后,你的 5 个 Token 就变成了 5 组数字。或者说,768 维空间里的 5 个点。
第三站:注意力------找到词和词之间的关系
现在 AI 手里有 5 组数字。但这 5 组数字各自独立------"量子"不知道旁边站着"力学","什么"不知道后面跟着"是"。
一个句子的意思不只取决于里面有哪些词,更取决于词和词之间的关系。"我打了他"和"他打了我"用的是完全一样的词,但意思完全相反。
这就是第 6 篇讲的 Transformer 要解决的问题。
Transformer 的核心发明叫做注意力机制。 它做的事情是:对于每一个词,同时"看"句子里的所有其他词,然后算出"我应该关注谁"。
具体来说,当 AI 处理"量子"这个词时,注意力机制会做这样的计算:
- "量子"和"什么"的相关性 → 0.05(低------不太相关)
- "量子"和"是"的相关性 → 0.10(低------一般的连接词)
- "量子"和"力学"的相关性 → 0.75(高------"量子力学"是一个紧密的组合)
- "量子"和"?"的相关性 → 0.10(低------标点符号)
这些数字叫做注意力权重。权重高的词,在后续的计算中会产生更大的影响。
注意力机制的结果是:每个词的向量被"更新"了。更新后的"量子"不再只代表"量子"本身------它变成了"在'什么是量子力学?'这个句子里的量子"。它融合了上下文的信息。
这就是为什么同一个词"苹果",在"我吃了一个苹果"和"我买了一部苹果手机"里,经过注意力机制之后会变成完全不同的向量------因为注意力聚焦的词不同。
还记得第 6 篇里提到的,Transformer 之前的 AI(RNN)是怎么处理语言的吗?它像手指一个字一个字指着读------读到后面,前面说了什么就忘了。
Transformer 的革命性在于:它能同时看到全文。 不管你的问题有多长,注意力机制都能在所有的词之间建立联系。这就是为什么 ChatGPT 能处理好几千字甚至几万字的上下文------而早期的语言模型连一段话都记不住。
第四站:数百层的乘法和加法
注意力机制只是 Transformer 里的一个组件。一个完整的 Transformer 包含很多层(GPT-3 有 96 层),每一层都包括:
- 注意力机制------让词和词之间交换信息
- 前馈神经网络------对每个词的向量做进一步处理
而每一层的"进一步处理",说到底就是第 4 篇拆解过的东西:输入 x 权重 + 偏置 → 激活函数 → 输出。
没有魔法。就是乘法和加法。
如果你还记得第 4 篇的内容,一个"神经元"的全部工作就是:
输出 = 激活函数(输入 1 × 权重 1+ 输入 2 × 权重 2+ ... + 偏置)一层里有几千个这样的神经元,同时做这样的运算。然后把输出传给下一层。再做一轮乘法和加法。再传给下一层。
96 层。
每一层都在提取更高层次的"特征"------这和第 1 篇里讲的图像识别是同一个思想。在图像识别中:
像素 → 边缘 → 形状 → 部件 → 整体在语言处理中,层层叠加的效果类似:
单个词 → 词组关系 → 句子含义 → 段落逻辑 → 全文主旨前面几层可能在处理基础的语法结构:主语在哪?谓语在哪?这是一个疑问句。后面的层可能在处理更抽象的东西:用户在问一个物理概念的定义。再往后的层可能在整合:我需要用通俗的语言解释这个概念。
但我要强调一点------"可能"这个词很重要。没有人精确地知道每一层在做什么。我们知道的是:数据从一端输入,经过 96 层乘法和加法,从另一端输出了一个令人惊讶的好结果。至于中间到底发生了什么,这仍然是 AI 研究的前沿问题。
这就是第 4 篇的核心结论的真正含义:神经网络不是一个精心设计的、每一步都有明确目的的程序。它是一个通过训练自动涌现出能力的计算结构。
而这个结构的规模是惊人的。GPT-3 有 1750 亿个参数。每一个参数就是乘法运算里的一个"权重"数字。当你问它"什么是量子力学?",你的 5 个 Token 的向量,要和这 1750 亿个数字做运算。
1750 亿次乘法和加法。
在三秒钟之内。
第五站:预测------算出"最可能的下一个词"
经过 96 层的运算,AI 终于到了最后一步:从所有可能的词里,选出一个"最可能"是下一个词的词。
怎么选?
在最后一层的输出端,神经网络会给词表里的每一个 Token 都算出一个分数。GPT-3 的词表里大约有 50000 个 Token,所以最后一层会输出 50000 个分数。
这些分数经过一个叫做 Softmax 的函数处理后,会变成概率:
"量子" → 12.3%
"力学" → 8.7%
"是" → 15.1%
"物理" → 5.2%
"学" → 3.8%
...
"炒菜" → 0.0001%
...(剩下 49995 个 Token 的概率加起来占 55% 左右)然后 AI 从中选一个。
注意:它不一定选概率最高的那个。如果每次都选概率最高的,输出会非常无聊和重复。实际上,AI 会在最高概率的几个词里做一定程度的"随机抽样"------这就是为什么你问同一个问题两次,得到的回答往往不一样。
假设这一次它选了"量子"。
那么它的输出到目前为止是:"量子力学是...量子"------等等,还没说完。
第六站:逐词生成------一个词接一个词
这是很多人没有意识到的一点:ChatGPT 不是一次性生成整段回答的。它是一个词一个词地"蹦"出来的。
你有没有注意到,ChatGPT 回答问题时,文字是逐渐出现的,而不是"啪"一下全部显示?那不是故意做的打字效果------那是它真实的工作方式。
流程是这样的:
- 输入"什么是量子力学?" → 经过上面的全部步骤 → 输出第一个词"量子"
- 把"什么是量子力学?量子"作为新的输入 → 再走一遍全部步骤 → 输出第二个词"力学"
- 把"什么是量子力学?量子力学"作为新的输入 → 再走一遍 → 输出"是"
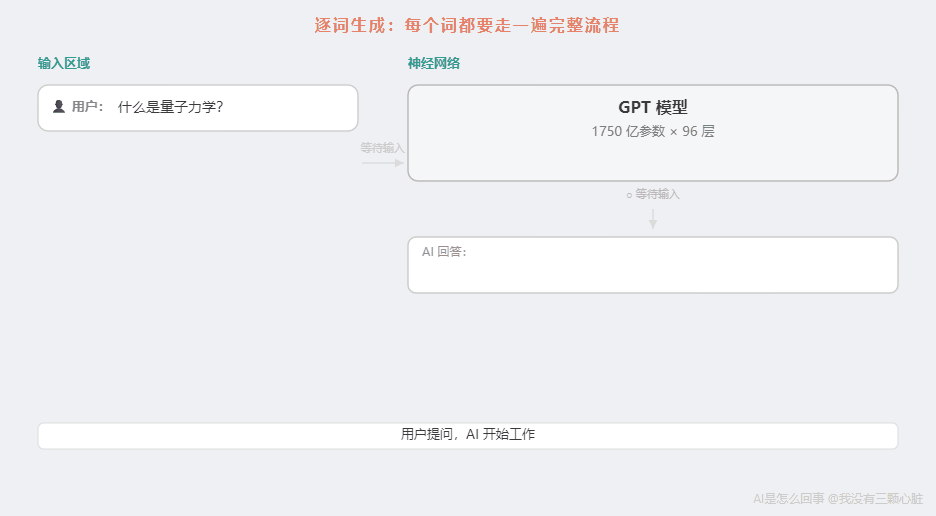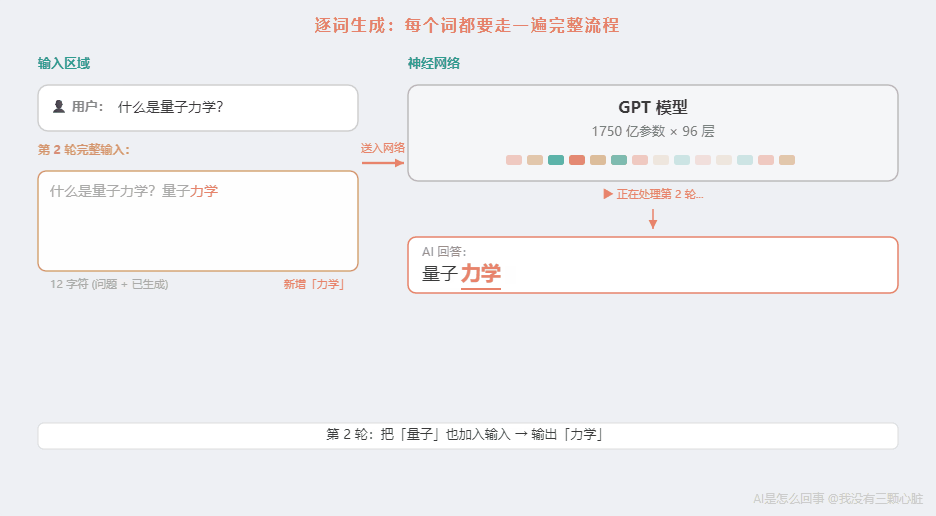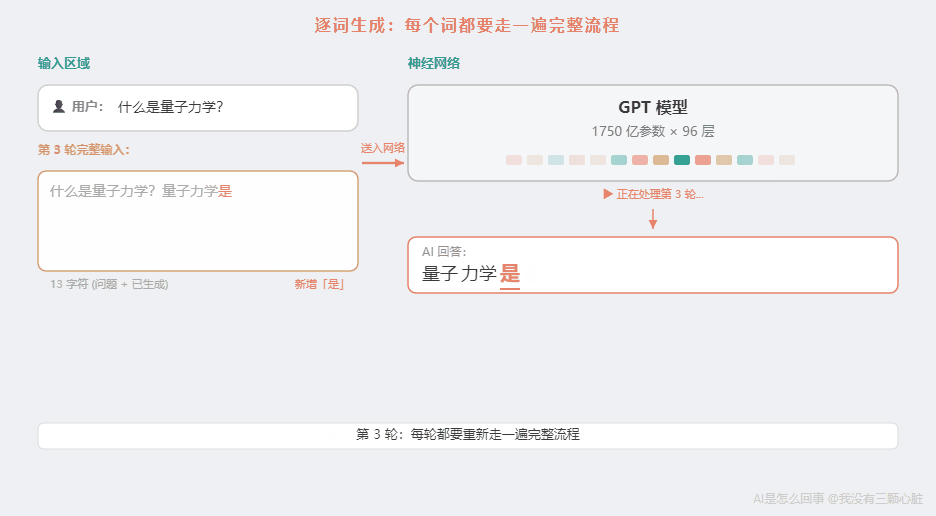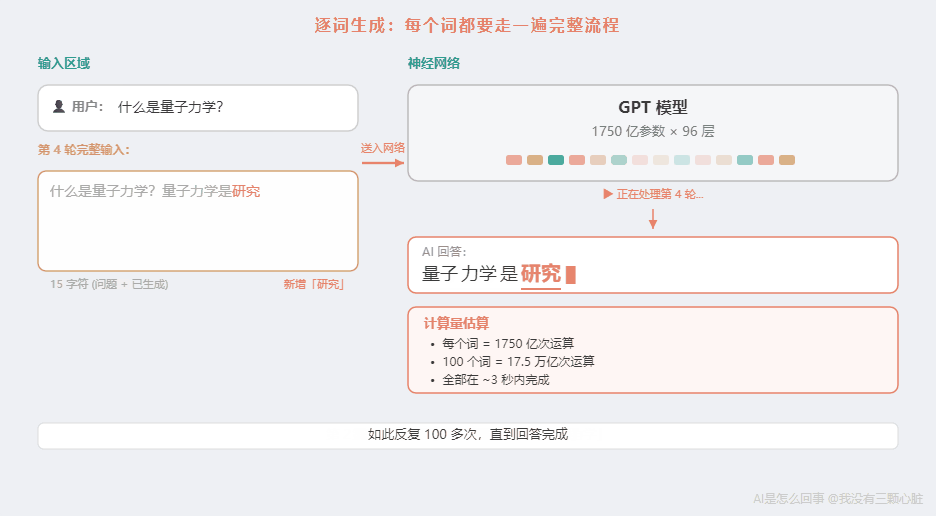
- 把"什么是量子力学?量子力学是"作为新的输入 → 再走一遍 → 输出"研究"
- ......
每生成一个词,就要把之前的所有内容重新输入,走一遍完整的流程。
一个 200 字的回答,大约有 100-150 个 Token。这意味着 AI 要做 100-150 次完整的"96 层乘法加法"运算。每一次都涉及 1750 亿个参数。
100 次 x1750 亿 = 17.5 万亿次运算。
在三秒钟里完成。
这就是第 5 篇里讲的 GPU 登场的原因。CPU 处理这种计算要几分钟甚至更久------但 GPU 擅长的就是"同时做大量简单的乘法和加法"。几千个 GPU 核心同时工作,把三分钟的计算压缩到三秒钟。
现在,让我们换一个角度看这三秒钟
上面我是沿着"一次回答"的流程来讲的。但这只是"运行"的部分。
要真正理解这三秒钟,你还需要知道:那 1750 亿个参数是怎么来的? 为什么它们恰好能让 AI 生成一个关于量子力学的、看起来像那么回事的回答?
答案在前面 7 篇里。现在,让我把每一篇的核心知识串起来,你会发现它们构成了一条清晰的因果链。
第一块拼图:一切数据都是数字(第 1-2 篇)
这是整个 AI 大厦的地基。
第 1 篇告诉我们:图片就是数字矩阵。 一张照片就是几百万个 0 到 255 之间的数字。手机认你的脸,不是真的在"看"你------是在比较两组数字有多接近。
第 2 篇告诉我们:文字也是数字。 通过 Token 化和词向量,每个词变成了一串 768 维的数字。"国王-男人+女人≈王后"这个经典例子说明,词和词之间的语义关系,被编码成了向量空间中的距离。
这是 AI 的第一个深刻洞察:这个世界上的一切信息------文字、图片、声音、视频------都可以变成数字。
而一旦变成了数字,数学就能处理它了。
你可能觉得这件事理所当然。但请想一想:在几十年前,"语义"被认为是只有人脑才能处理的东西。谁能想到,用 768 个数字就能捕捉一个词的"含义"?
这件事不是某个天才灵光一现想出来的。它是从海量数据中,用统计方法"学"出来的------哪些词经常出现在相似的上下文中,它们的向量就会在训练过程中逐渐靠近。
"语义"本身不存在于那 768 个数字里。存在的只是统计规律。但这些统计规律恰好和人类感受到的"意思相近"高度吻合。
第二块拼图:三要素齐了(第 3 篇)
有了"一切都能变成数字"的基础,下一个问题是:为什么不是在 1990 年、2000 年,而是在 2012 年之后,AI 才突然变厉害?
第 3 篇讲了这个故事。2012 年,AlexNet 把 ImageNet 图像识别的错误率从 26% 一口气降到了 15.3%------领先第二名超过 10 个百分点。用考试来类比:所有人在 74 分左右竞争,突然有人考了 85 分。
这不是因为某个算法的灵感。这是因为三个条件同时到位了:
- 数据------ImageNet 提供了 1400 万张标注好的图片
- 算力------GPU 让大规模并行计算成为可能
- 算法------深度神经网络(多层叠加的检测器)终于可以被有效训练了
缺少任何一个,这件事都不会发生。算法其实在 1980 年代就有了雏形,但没有数据和算力,它只是理论。数据在互联网时代逐渐积累起来了,但没有 GPU,就算有再多数据也没法在合理的时间内训练。GPU 本来是给游戏用的,但它"同时做大量简单计算"的特长恰好匹配了神经网络训练的需求。
三个齿轮同时咬合------AI 的引擎才真正启动。

这个三要素框架不只解释了 2012 年的突破,也解释了此后的每一次飞跃:更多的数据、更强的算力、更好的算法------三者螺旋上升,推动 AI 从"能认图"到"能对话"。
第三块拼图:神经网络就是乘法和加法(第 4 篇)
三要素里的"算法"到底是什么?
第 4 篇拆开了这个黑箱。答案可能让你意外:神经网络就是乘法和加法的层层叠加。
一个神经元做的事情极其简单:
输入 × 权重 + 偏置 → 激活函数 → 输出就是一道小学算术题。
但当你把几千个这样的神经元排成一层,再把几十层叠在一起,让上一层的输出变成下一层的输入------神奇的事情发生了。
第 1 篇讲的图像识别就是最好的例子:
像素 → 边缘 → 形状 → 部件 → 整体每一层做的计算都很简单------对应位置的数字相乘再加起来(还记得 Sobel 算子吗?那就是最原始的一层)。但层层叠加的效果,让 AI 可以从原始像素中"看到"一张人脸。
AlexNet 有 8 层、6000 万个参数。GPT-3 有 96 层、1750 亿个参数。原理完全一样------只是规模大了几千倍。
这是 AI 的第二个深刻洞察:简单运算的大规模叠加,可以产生极其复杂的行为。
没有任何一个参数"知道"量子力学是什么。但 1750 亿个参数组合在一起,统计上就能生成一段关于量子力学的、看起来颇为合理的文字。
第四块拼图:训练就是调参(第 5 篇)
那 1750 亿个参数是怎么得到的?谁决定了每一个参数应该是 0.0173 而不是 0.0289?
答案是:没有"谁"决定。是训练决定的。
第 5 篇详细拆解了训练的过程。让我用最简练的方式回顾:
- 一开始,所有参数都是随机的。 AI 输出的是乱码。
- 给 AI 看一段真实文本,比如:"量子力学是物理学的一个分支"。
- 遮住最后一个词("分支"),让 AI 根据前面的词猜这个词是什么。
- AI 猜了一个词------大概率猜错了,因为参数是随机的。
- 算出猜得有多离谱------这叫做损失函数,就是"预测"和"正确答案"之间的差距。
- 反向传播:从最后的错误出发,一层一层往回追溯,算出每一个参数对这个错误"贡献"了多少。
- 微调每一个参数------让错误变小一点点。每次调整幅度很小(比如 0.001),但对 1750 亿个参数同时做。
- 重复。 用几万亿个词的训练数据,重复这个过程几百万轮。
几百万轮之后,那些原本随机的参数逐渐稳定下来。不是因为有人告诉它"量子力学是物理的分支"------没有人教过它任何知识。它只是在反复的"猜词、对答案、微调"中,发现了人类语言中反复出现的统计模式。
这就是"训练"------本质上就是用海量数据+反向传播,把 1750 亿个随机数字调整到"很少猜错"的状态。
而这个过程之所以能在人的有生之年完成,是因为 GPU。第 5 篇里的类比:CPU 是一个大厨,一次做一道菜但做得很好;GPU 是一千个帮工,每个人只会做简单的活但可以同时干。训练神经网络恰好是"大量简单计算同时做"------GPU 的主场。
GPT-3 的训练据估计用了约一万块 GPU,耗时数月,消耗了几百万美元的算力成本。所有这些资源只做了一件事:把那 1750 亿个随机数字调整到合适的位置。
第五块拼图:Transformer 让 AI 能"同时看全文"(第 6 篇)
有了神经网络和训练方法,为什么不是在 2012 年就做出了 ChatGPT?
因为还差一个关键组件:Transformer。
第 6 篇讲了这个故事。2017 年之前,AI 处理语言用的是 RNN------它像手指一个字一个字指着读,读到后面就忘了前面。这就是为什么早期的机器翻译和聊天机器人总是"前言不搭后语"。
2017 年,Google 的一个团队发表了一篇论文:《Attention Is All You Need》。核心发明就是注意力机制------让 AI 在处理每个词时,同时"看"整段文字,找出相关的部分。
这个发明带来了三个改变:
- 能记住长文本------不再"读到后面忘了前面"
- 能并行计算------RNN 必须一个词一个词地算,Transformer 可以同时算所有词------训练速度飞跃
- 越大越好------模型越大、数据越多,效果就越好,而且似乎没有天花板
正是第三点,催生了"大力出奇迹"的路线:
2018 年 GPT-11.17 亿参数 "能读懂一些文字了"
2019 年 GPT-215 亿参数 "能写像样的文章了"
2020 年 GPT-31750 亿参数 "能对话了"
2022 年 ChatGPT GPT-3+ 人类反馈训练 "能好好说话了"从 1.17 亿到 1750 亿,参数量翻了 1500 倍。但核心架构没有变------都是 Transformer。变的只是规模。
ChatGPT 不是一个全新的发明------它是注意力机制这个想法被放大了一千五百倍之后的产物。
而那最后一步"人类反馈训练"(RLHF)也很重要:它让 AI 不只是"能说",而且"会说"------知道什么该说、什么不该说,知道怎么组织语言让人类满意。但本质没变------它仍然是在做"预测下一个最可能的词"。
第六块拼图:统计模式匹配不等于理解(第 7 篇)
如果你只读了前 6 篇,你可能会觉得 AI 非常了不起------它能认脸、能对话、能写文章。但第 7 篇给了你一盆冷水。
那个律师的故事你还记得吗?Steven Schwartz 在法庭上提交的 6 个判例全是 ChatGPT 编造的。他甚至问了 ChatGPT 这些判例是不是真的,ChatGPT 回答"是的"。
现在你已经知道了完整的原理,就能理解为什么会这样:
ChatGPT 不是在"回忆"它读过的法律文献。 它没有一个"事实数据库"可以查阅。它做的唯一一件事,就是基于前面的文字,计算出统计上最可能的下一个词。
当律师问"帮我查找支持这个观点的判例"时,ChatGPT 开始"续写"。在它的训练数据中,有大量的法律文书,它知道一个判例引用"应该长什么样"------有案件名称、有法院、有日期、有案号。于是它生成了一段"看起来像判例引用的文字"。
但"看起来像"和"是真的"之间有一条鸿沟。
第 7 篇还讲了对抗样本的故事:在一张熊猫图片上加一层人眼看不见的噪点,AI 就会以 99.3% 的置信度认为这是一只长臂猿。这进一步说明了 AI 在做的事情------数字运算,而非"看"。 那些微小的数字扰动改变了运算结果,尽管图片在人眼看来完全没变。
AI 的"聪明"和"犯傻"来自同一个源头:统计模式匹配。
匹配得好的时候,它看起来比人还聪明。匹配得不好的时候,它犯的错误让人匪夷所思。但不管哪种情况,它都没有在"理解"任何东西。它不知道量子力学是什么。它不知道判例是什么。它甚至不知道自己在"说话"。
它只知道一件事:根据前面的数字,计算下一个数字的概率分布。
七块拼图,一张完整的图景
现在,让我把这七块拼图拼在一起。
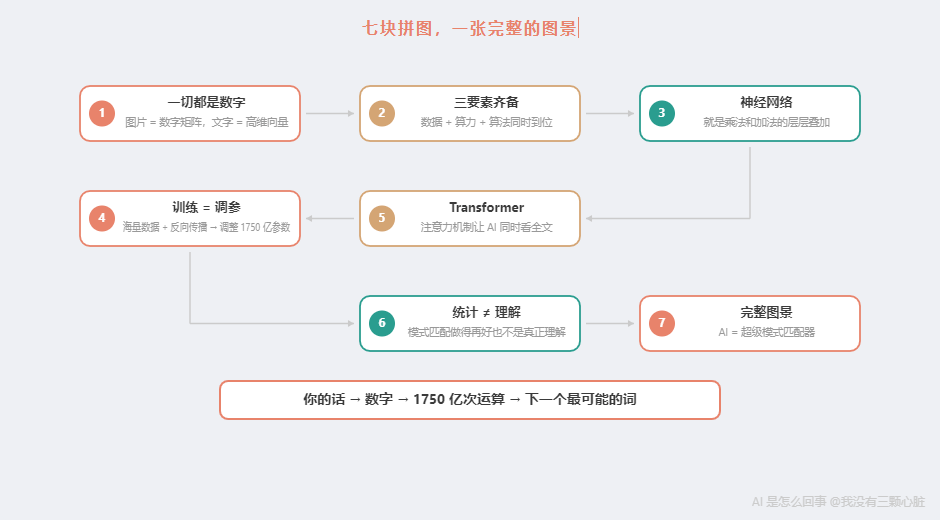
你问 ChatGPT"什么是量子力学?"的那三秒钟里:
- 你的话变成了数字(第 1-2 篇的知识)------Token 化和词向量把人类语言翻译成 AI 的母语:数字
- 数字在巨型网络中流动(第 4 篇的知识)------1750 亿个参数,96 层乘法和加法,逐层提取更高层次的"特征"
- 注意力机制在全文中寻找关系(第 6 篇的知识)------每一层的注意力机制让词和词之间交换信息,理解上下文
- 这些参数是从海量数据中训练出来的(第 5 篇的知识)------几万亿个词的文本,反向传播算法,几百万轮的微调,GPU 集群的算力
- 训练之所以有效,是因为三要素齐了(第 3 篇的知识)------数据、算力、算法的螺旋上升
- 最终输出的是"统计上最可能的下一个词" (第 7 篇的知识)------不是事实,不是理解,是概率
这就是 ChatGPT 回答你的三秒钟里,发生的全部事情。
没有理解。没有思考。没有知识库查询。没有"灵感"。
只有数字、乘法、加法,和统计概率。
核心结论:AI 的一句话定义
如果要用一句话概括前面 7 篇的全部内容,我会说:
AI 是一个超级模式匹配器。

它把世界上的一切------文字、图片、声音------转化为数字。
然后在海量数据中寻找统计模式。
最后用这些模式来"预测"输出。
仅此而已。
凡是能转化为模式识别的问题,AI 都可能做得比人好。 图像分类、语音识别、翻译、代码生成------这些任务的共同特点是:存在大量的数据,存在可学习的模式,输出可以被清楚地评判对错。
凡是需要真正"理解"的问题,AI 目前还做不到。 因果推理、常识判断、创造性思维、价值观判断------这些任务的共同特点是:不能简单地转化为"从数据中找模式"。
这不是 AI 的"缺陷"------这就是它的本质。
就像你不会抱怨计算器"不理解数学"------计算器做的事情就是按规则算数字。AI 做的事情就是在高维空间里匹配统计模式。它做这件事做到了人类望尘莫及的程度。但它做的只有这一件事。
带着这个理解上路
如果你真的消化了前面 7 篇的知识,你现在手里有了一个非常强大的工具:一个判断 AI 的基础框架。
用这个框架,你可以回答很多平时争论不休的问题:
"AI 会取代我的工作吗?"
→ 拆解你的工作:其中哪些部分是模式匹配(整理数据、套用模板、翻译文本),哪些部分需要理解(创造性决策、人际沟通、价值判断)?前者可能会被 AI 加速甚至替代,后者不会------至少在 AI 的底层原理不发生根本改变的情况下不会。
"AI 写的东西能信吗?"
→ AI 不在乎真假。它在乎的是"在训练数据的统计模式中,下一个最可能的词是什么"。如果事实和"统计上最可能的文字"一致,它就对了。如果不一致,它照样会自信满满地说出来------因为它不知道什么是"对"和"错"。关键信息永远要自己验证。
"AI 会有意识吗?"
→ 你现在知道 ChatGPT 在做什么了:1750 亿个数字的乘法和加法,预测下一个词的概率分布。这里面有"意识"吗?当然,这个问题目前没有定论------我们甚至不完全清楚人类的意识是怎么产生的。但至少你不再需要因为"AI 说话听起来很像人"就恐慌了。你知道那些像人的回答是怎么来的------统计模式匹配,不是"思考"。
"AI 会不会突然变得危险?"
→ 你在第 7 篇里已经看到了 AI 的脆弱性:一点像素噪声就能让它把熊猫认成长臂猿。AI 的"智能"是窄的------它在训练过的模式上表现惊人,在模式之外几乎毫无能力。这不意味着 AI 没有风险,但风险的性质和科幻电影里"AI 觉醒"完全不同------更现实的风险是人类过度信任 AI 的输出,就像那位律师一样。
下一章预告
理解了 AI 的本质,我们来看一个更实际的问题------
AI 在各个领域的真实能力边界到底在哪里?
ChatGPT 能通过律师资格考试,但分不清"谢谢你"是真心感谢还是讽刺。AI 能画出以假乱真的照片,但自动驾驶还搞不定一只突然窜出来的猫。
有没有一套简单的方法,让你面对任何 AI 产品时都能快速判断:这个靠谱吗?
下一篇,我们就来建立这套判断方法。
个人锚点
写完这 8 篇,我有一个很强的感受:了解 AI 的过程,其实是一个「祛魅」的过程。
你以为它很神秘,拆开一看,就是数字、乘法和统计。
第 1 篇的时候,我发现图片在 AI 眼里就是一堆 0 到 255 的数字------整个世界观都变了。第 2 篇的时候,我发现连"语义"这种虚无缥缈的东西都能用 768 个数字表示------又变了。第 4 篇的时候,我发现所谓"神经网络"就是乘法和加法------再变一次。到第 7 篇的时候,我发现 AI 会编造判例、会被一点噪声骗过------第四次改变。
每一次"变",都是一层神秘感的消退。
但这不意味着 AI 不了不起------恰恰相反,用这么"简单"的原理做到这些事情,本身就是人类智慧的奇迹。
一堆乘法和加法,只要叠加得足够多、在足够多的数据上训练得足够久,就能生成一段读起来头头是道的文章、画出一幅让人真假难辨的图画、翻译几十种语言。
这个奇迹的名字不是"人工智能"------它的名字是"统计学"和"工程学"。
理解这一点,你就不会盲目崇拜 AI,也不会盲目恐惧 AI。你会把它看成它本来的样子:一个极其强大的工具,有着清晰的能力边界,等着被正确地使用。
这,就是第一章想告诉你的全部事情。
第一章完整回顾
| 篇目 | 核心知识 | 一句话总结 |
|---|---|---|
| 第 1 篇 | 图片=数字矩阵,Sobel 算子,层层检测 | AI 看到的不是图片,是数字 |
| 第 2 篇 | Token,词向量,语义=距离 | AI 读到的不是文字,是高维空间的点 |
| 第 3 篇 | AlexNet,三要素(数据+算力+算法) | 2012 年不是进步,是换了赛道 |
| 第 4 篇 | 输入 x 权重+偏置→激活→输出 | 神经网络就是乘法和加法 |
| 第 5 篇 | 反向传播,过拟合,GPU 并行 | 训练就是用数据调参,GPU 负责算 |
| 第 6 篇 | 注意力机制,Transformer,GPT 系列 | Transformer 让 AI 能同时看全文 |
| 第 7 篇 | 幻觉,对抗样本,统计≠理解 | 模式匹配不等于理解 |
| 第 8 篇 | 全流程串联,核心结论 | AI 是超级模式匹配器 |
第一章的承诺: 读完这 8 篇,你将能够解释 AI 是怎么"看"图片和"读"文字的,理解神经网络是什么意思,知道训练具体在做什么,明白 2012 年和 2017 年为什么重要,以及理解 ChatGPT 为什么会"犯傻"。
现在,你能做到了吗?
如果能------欢迎来到第二章。
订阅
如果觉得有意思,欢迎关注我,后续文章也会持续更新。同步更新在个人博客和微信公众号
微信搜索"我没有三颗心脏"或者扫描二维码,即可订阅。
