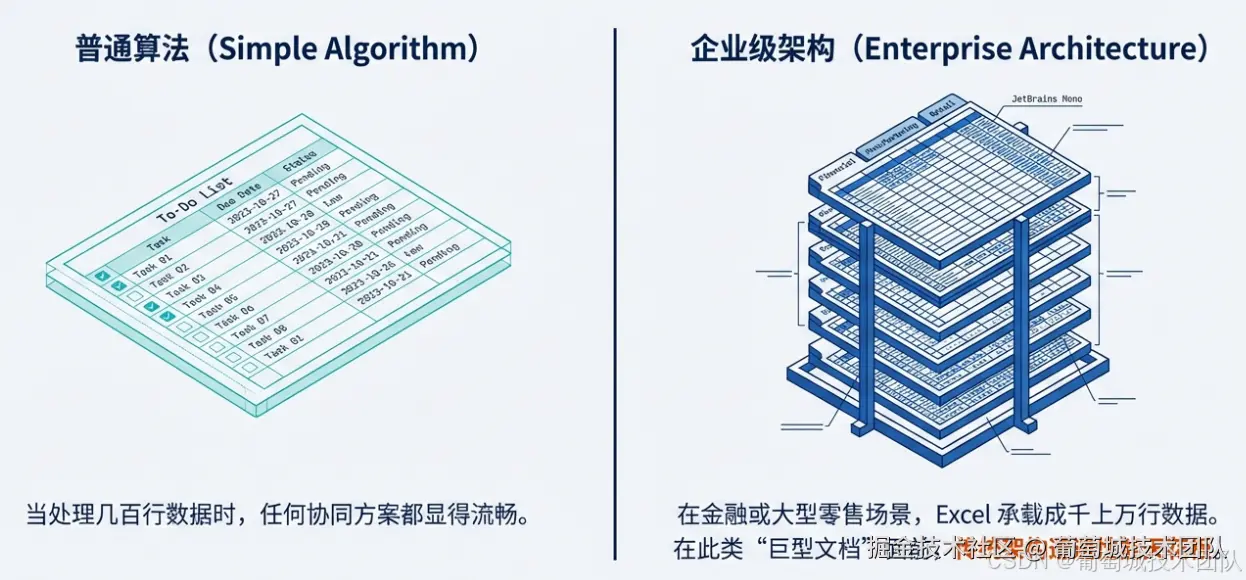
在实时协同的领域,流传着这样一句话:
"小文档看算法,大文档看架构。"
当我们在处理只有几百行数据的简单表格时,任何协同方案看起来都行云流水。但对于金融、制造或大型零售企业来说,Excel 往往承载着成千上万行数据、数百个工作表以及错综复杂的公式引用。在这种"巨型文档"面前,传统的协同架构往往会遭遇性能天花板:由于每次操作都要读写完整的文档快照(Snapshot),服务器 I/O 会不堪重负,用户侧则会感受到明显的指令延迟甚至卡顿。
作为系列文章的第四篇,我们将深入 SpreadJS 协同服务器的底层性能核心,为你揭秘专门为处理超大规模协作而设计的**"片段机制(Fragments)"**。
一、 传统模式的瓶颈:巨型快照带来的"重量级"负担
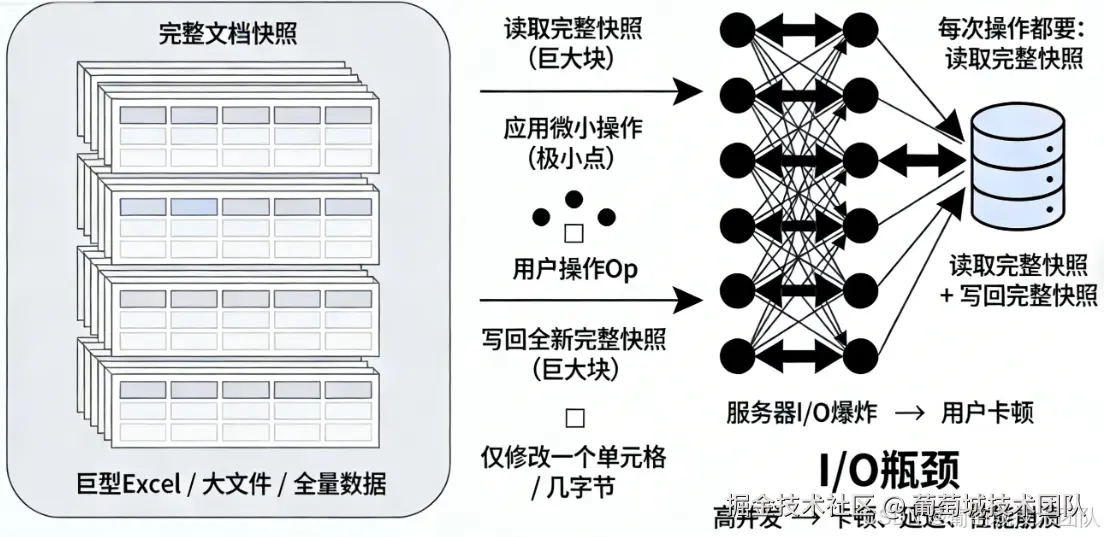
在深入片段机制之前,我们需要理解不使用该机制时,协同服务器是如何处理一次用户编辑(Op)的。
通常情况下,服务器处理操作的流程分为三步:
- 读取:从数据库中取出该文档当前的完整快照(例如一个包含 50 个 Sheet 的大工作簿)。
- 应用:在内存中将用户的 Op 应用到快照上,生成新版本。
- 写回:将更新后的完整快照再次保存到数据库。
如果这个快照的大小是 10MB,那么哪怕用户只是修改了一个单元格的值(Op 可能只有几字节),服务器也必须进行 10MB 的读操作和 10MB 的写操作。在高并发场景下,这种极高的 I/O 开销会迅速消耗服务器资源,导致响应速度断崖式下跌。
二、 什么是片段机制(Fragments)?
为了解决这一难题,SpreadJS 协同服务器引入了片段机制。这是一种高级服务器端功能,其核心思想是"化整为零,按需存取"。
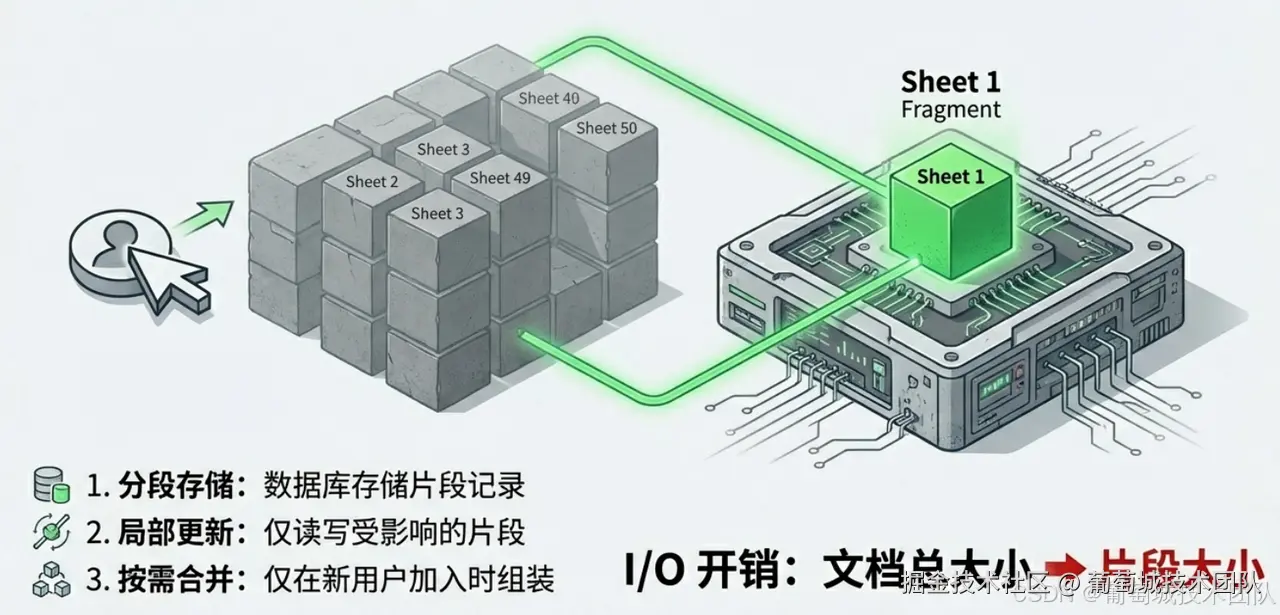
片段机制允许服务器将一个大型文档(如 Workbook)拆分为多个较小的、独立的片段(Fragments)。例如,我们可以将每一个工作表(Worksheet)定义为一个独立的片段。
片段机制的运作逻辑:
- 分段存储:文档在数据库中不再以一个巨大文件的形式存在,而是被拆解为多个片段记录。
- 局部更新 :当用户修改 Sheet1 的某个单元格时,服务器仅加载 Sheet1 对应的片段,应用变更后仅写回该片段。
- 按需合并:只有当新用户加入房间需要获取初始状态时,服务器才会将所有片段"组装"成一个完整的快照发送给客户端。
这种"外科手术式"的精确操作,将 I/O 开销从文档总大小降低到了受影响片段的大小,性能提升往往是量级式的。
三、 技术深度:在 OT 类型中实现片段化
片段机制通过扩展服务器端的 OT 类型(OT_Type) 接口实现。开发者需要实现以下三个核心方法:
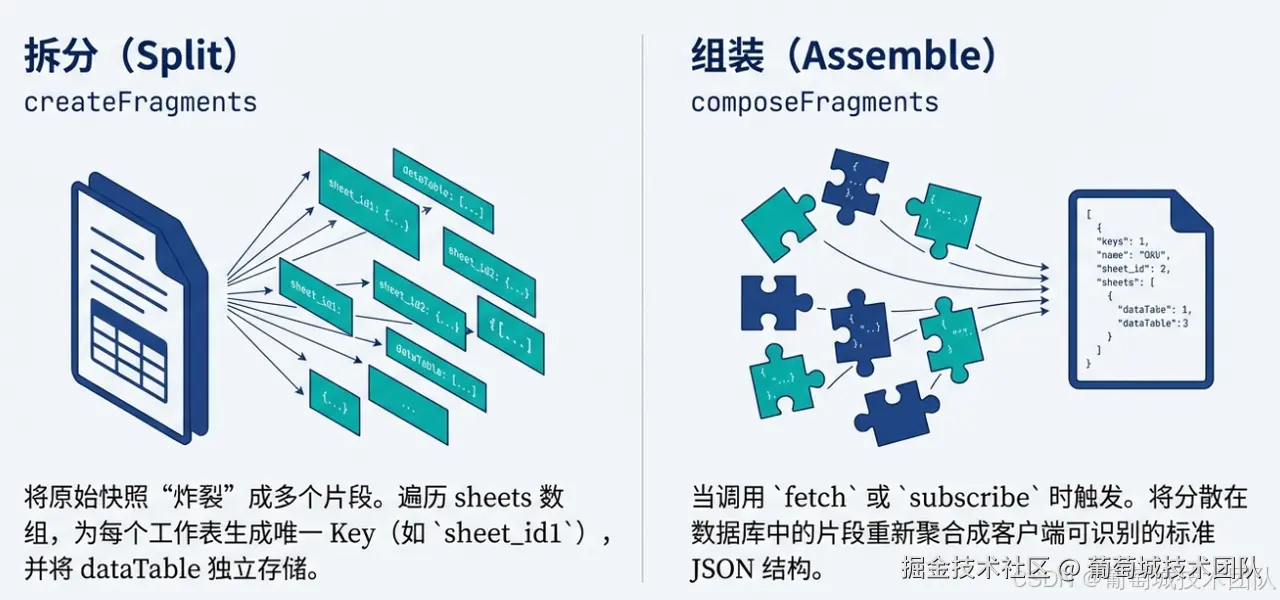
1. createFragments (拆分)
当一个新文档被创建时,该方法负责将原始快照数据"炸裂"成多个片段。
- 示例 :在工作簿场景下,我们可以遍历
sheets数组,为每个工作表生成一个 Key(如sheet_id1),并将对应的dataTable存入片段集合。
2. applyFragments (局部应用)
这是最核心的性能优化点。它不再接收整个快照,而是接收一个 ISnapshotFragmentsRequest 对象。
- API 特性 :开发者可以使用
request.getFragment(id)异步获取特定片段,使用request.updateFragment(id, data)更新它。 - 价值:如果 Op 只涉及 Sheet1,服务器绝不会去碰 Sheet2 到 Sheet50 的数据。
3. composeFragments (组装)
当客户端请求完整快照(如调用 fetch 或 subscribe)时,服务器调用此方法。
- 逻辑:它将分散在数据库中的片段重新聚合成客户端能够理解的完整 JSON 结构。
四、 性能对比:有无片段机制的代差
为了更直观地展示其价值,我们可以对比一下在处理大型工作簿时的表现:

结论:片段机制是 SpreadJS 支撑"企业级生产力"的关键。它确保了即使在处理 TB 级别的协作数据积累时,系统的响应延迟依然能维持在毫秒级。
五、 开发者如何启用片段机制?
片段机制是一项服务器端特有的技术,客户端对此是无感知的 。这意味着客户端依然使用完整的 SpreadJS 数据模型进行编辑,而性能优化的重任由后端 DocumentServices 承担。
在服务端初始化时,你可以通过配置 DocumentServices 来集成支持片段的自定义数据库适配器:
TypeScript
// 1. 定义支持片段的 OT 类型
const workbook_ot_with_fragments = {
uri: 'workbook-ot-type',
createFragments: (data) => { /* 拆分逻辑 */ },
applyFragments: async (request, op) => { /* 局部更新逻辑 */ },
composeFragments: (fragments) => { /* 合并逻辑 */ },
transform: (op1, op2, side) => { /* 冲突处理保持不变 */ }
};
// 2. 在 DocumentServices 中使用
const docService = new DocumentServices({
db: new PostgresAdapter(pool), // 使用持久化适配器支持片段存储
submitSnapshotBatchSize: 50 // 累积 50 个 Op 后更新快照片段
});
server.useFeature(OT.documentFeature(docService));六、 总结:为海量协作保驾护航
对于企业而言,协同办公的失败往往不是因为"功能不够",而是因为"速度太慢"。一旦协作出现延迟,用户对系统的信任感就会迅速流失。
SpreadJS 协同服务器的片段机制,通过对大规模文档的精细化治理,彻底解决了实时协作中的性能顽疾。它不仅提升了系统的吞吐量,更为企业构建超大型、高频交互的在线数据中台提供了坚实的技术底座。
现在,我们已经解决了通信(js-collaboration) 、一致性(OT) 、**协作感知(Presence)和性能(Fragments)**的问题。接下来的挑战是:在如此开放的协作环境下,如何确保只有授权用户能修改数据?如何防止误操作并实现精准的版本回溯?
下一篇文章,我们将进入系列第五篇:【安全与管控篇】协同不代表权限开放:深度定制协同环境下的权限与版本追踪。敬请期待。
技术要点回顾:
- 片段(Fragment):大型快照的子集,通常以工作表为单位。
- I/O 优化:片段机制通过减少单次 Op 的读写数据量,显著降低数据库压力。
- 核心 API :
createFragments、applyFragments、composeFragments。 - 适用场景:Sheet 数量多、单 Sheet 数据量大的企业级复杂报表。
