很多人第一次认真做大模型应用,都会遇到一个相似的时刻。
你把需求写得很完整:背景、目标、约束、参考材料,一条不落。
结果模型的回答却开始变得奇怪:
有些关键点被忽略,
有些结论前后打架,
有些地方甚至像"没看到你的输入"。
直觉上我们会觉得:是不是 Prompt 还不够清楚?
但在不少场景里,真正的问题不是"写得不清楚",
而是你已经碰到了模型的上下文边界。

一、先把误解拿掉:限制的是 Token,不是字数
我们平时习惯看"多少字",
模型真正处理的是"多少 Token"。
这两者差别不小。
同样篇幅的内容,token 消耗可能完全不同:
- 中文文本通常更密
- 代码、表格、JSON 往往更耗窗口
- 多种格式混在一起时,增长尤其快
所以你看到的是"这段也不长",
模型看到的可能已经是"接近上限的输入序列"。
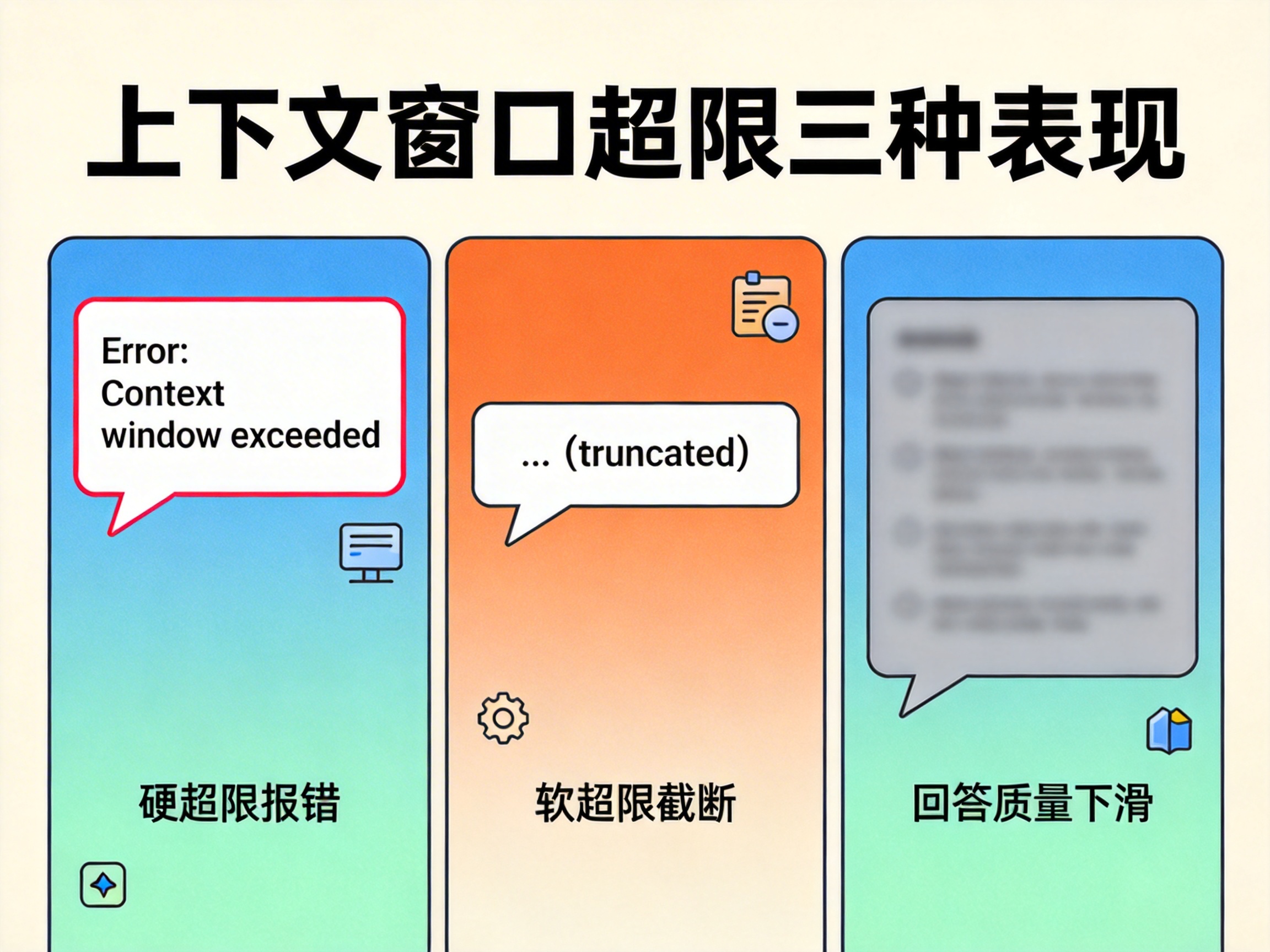
二、超出窗口后,不一定都会报错
很多人只把"报错"当成超限信号。
其实更常见的,是不报错但质量下滑。
大致会有三种表现:
第一种,硬超限:请求直接失败。
第二种,软超限:系统发生截断,你以为喂进去了,实际上关键上下文已经被丢掉。
第三种,最隐蔽:请求成功,但回答明显变钝,抓不住重点。
这也是为什么有时会出现一种很挫败的体验:
它像是"读了很多",但真正该记住的没有记住。
三、为什么一接近上限,答案就容易漂?
这背后不是玄学,而是信息负载问题。
当上下文越来越拥挤时:
- 重要约束会被噪声稀释
- 远距离关联更难稳定建立
- 指令优先级更容易混乱
于是你看到的结果就是:
同一个任务里,模型一会儿遵守规则,一会儿又偏离规则。
它并不是"突然不会了",
而是注意力资源已经不够支撑稳定推理。

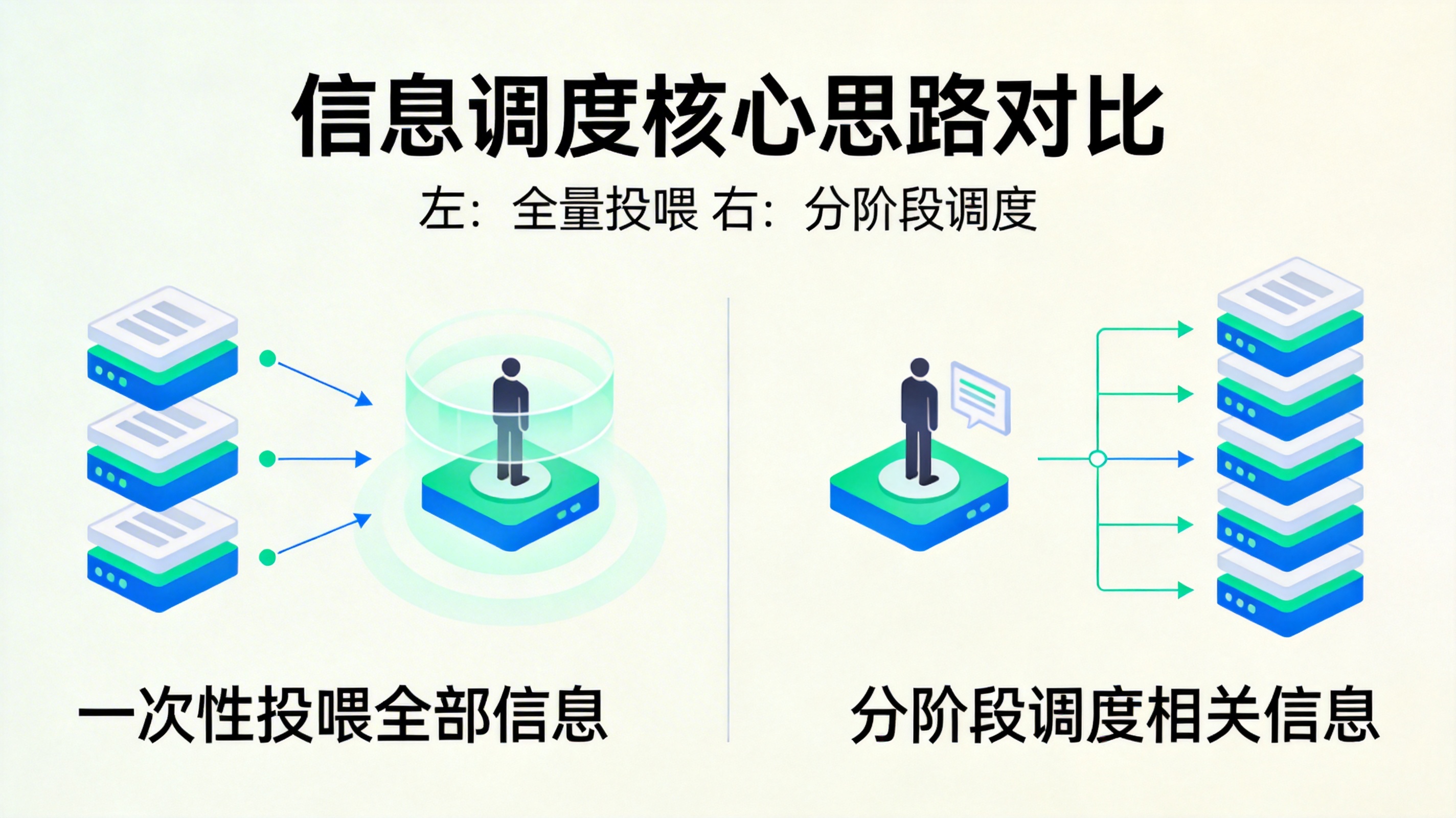
四、真正有效的方向:别再"加料",要开始"调度信息"
遇到超限时,最自然的反应是换更大窗口模型。
这当然有价值,但通常只是缓解,不是根治。
更稳定的思路是:
让模型在每一步只看到当前任务最相关的信息,
而不是一次性看到所有信息。
换句话说,
把问题从"塞得下多少",改成"该让它先看到什么"。
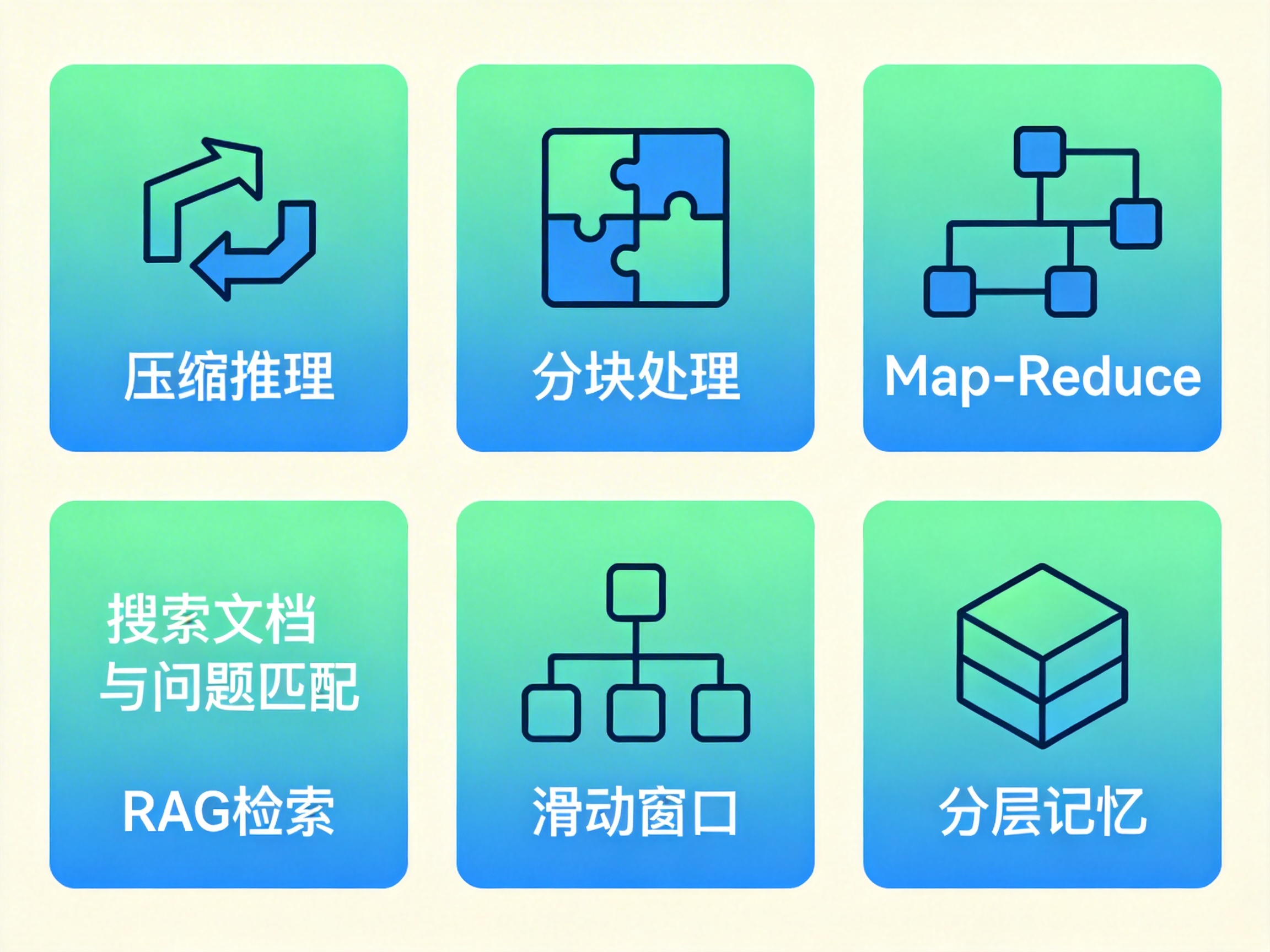
五、工程里最常用、也最稳的几种做法
1)先压缩,再推理
把原始材料先做一层结构化摘要,再进入主任务。
常用骨架:背景、目标、约束、关键事实、未决问题。
重点不是"越短越好",
而是"与决策相关的信息不能丢"。
2)分块处理,再全局汇总
面对长文档,不要一次吞完。
更稳的是:分块理解 → 块内提炼 → 全局合并 → 输出结果。
本质上是把一次高风险的大推理,拆成多次可控的小推理。
3)Map-Reduce 流程化
如果任务重复出现,这种方式特别实用。
先让每个片段回答同一问题(Map),
再统一合并、去重、处理冲突(Reduce)。
它的优势是结果稳定,流程可复用,还能并行提速。
4)用 RAG 替代"全文投喂"
资料很多时,最不该做的就是"全部贴进 Prompt"。
更好的方式是先检索相关片段,只注入命中的证据,再据此生成。
从工程角度看,这一步往往能显著降低噪声,提高答案一致性。
5)顺序任务用滑动窗口
日志排障、时间线分析、长对话追踪这类任务,依赖顺序。
可以采用固定窗口 + 向后滑动 + 重叠区保留的方式,避免语义断层。
6)把记忆做成分层,而不是历史全贴
"有记忆"不等于"把所有历史永久拼接"。
更合理的结构通常是:
- 短期记忆:当前任务必需上下文
- 工作记忆:阶段性摘要
- 长期记忆:外部存储,按需检索
模型不需要一直看见全部过去,
它需要的是在当前时刻看见最有用的过去。
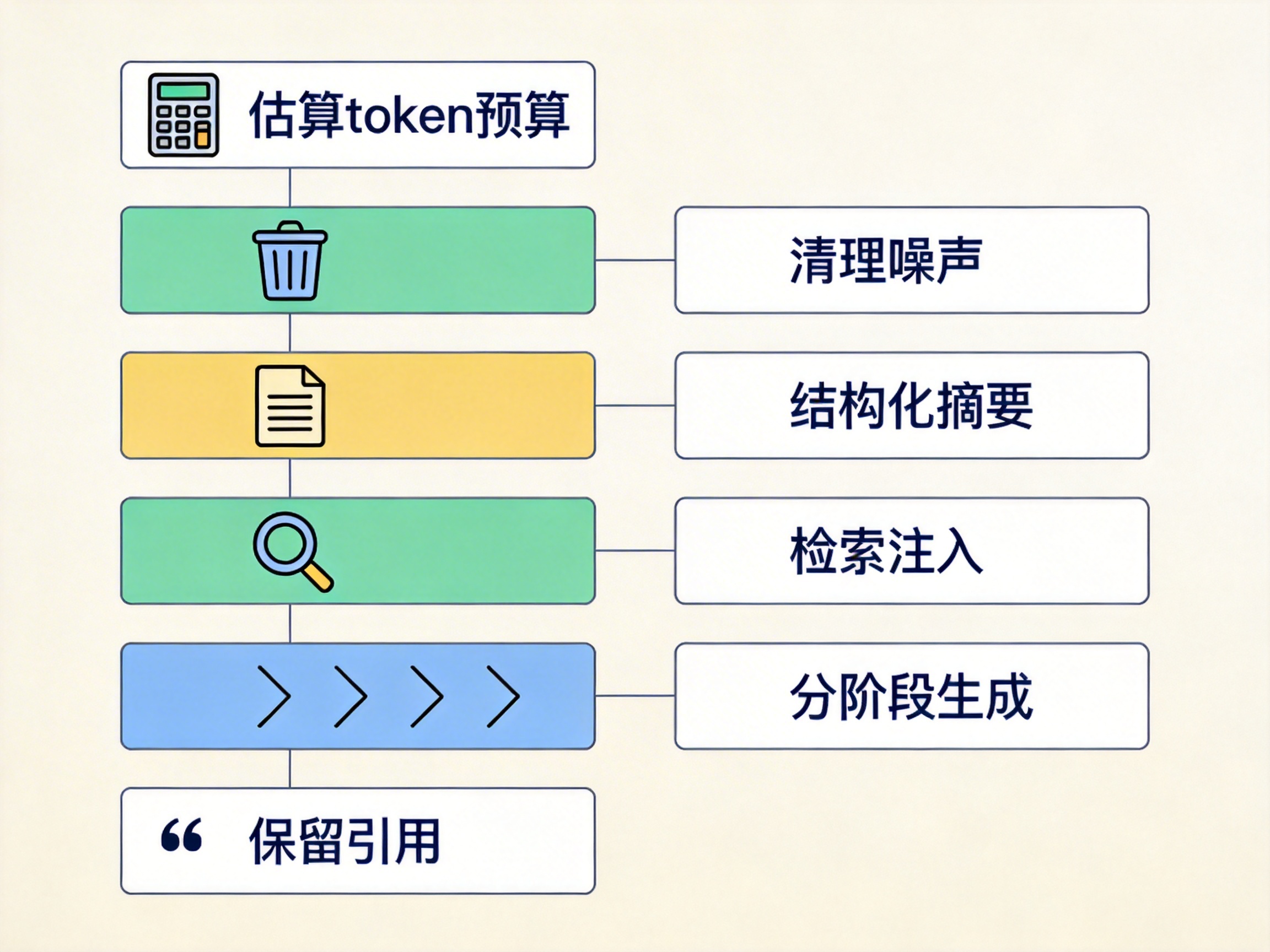
六、一个实用的处理顺序
当你怀疑 Prompt 太长,可以按这个顺序排查:
先估算 token 预算(输入、历史、输出分开看),
再清理噪声,
再做结构化摘要,
再改成检索注入,
必要时分阶段生成,
最后给关键结论保留引用,便于回查。
这套方法的价值在于:
它把"靠运气的回答质量",变成"可维护的信息流程"。
结尾
Prompt 超出上下文窗口,不是少见异常,而是大模型应用中的日常现实。
所以真正可靠的方案,从来不是和窗口硬碰硬,
而是提前设计好压缩、检索、分步和记忆分层。
如果把这件事浓缩成一句话:
当 Prompt 放不下时,应该优化的不是字数,而是信息结构。