在大模型从"实验室"走向"生产力"的过程中,显存溢出(OOM)和推理延迟始终是两大拦路虎。动辄几十 GB 的 FP16 模型,让单卡部署成了奢望。量化技术(Quantization) ,尤其是 INT8 与 INT4,通过极高的压缩比和硬件加速特性,已成为大模型工业化落地的"入场券"。
一、 量化核心:数据维度的"无损压缩"艺术
量化的核心并非简单的数值截断,而是通过数学映射,将高精度的浮点数(如 BF16/FP16 )映射到低精度的整数(INT8/INT4)。
1. 线性量化的数学逻辑
工业界主流采用的是线性量化(Linear Quantization) 。其核心公式为:
r=S⋅(q−Z)
其中, r 为原始浮点值, q 为量化后的整数, S(Scale)是缩放因子, Z(Zero Point)是零点偏移。
-
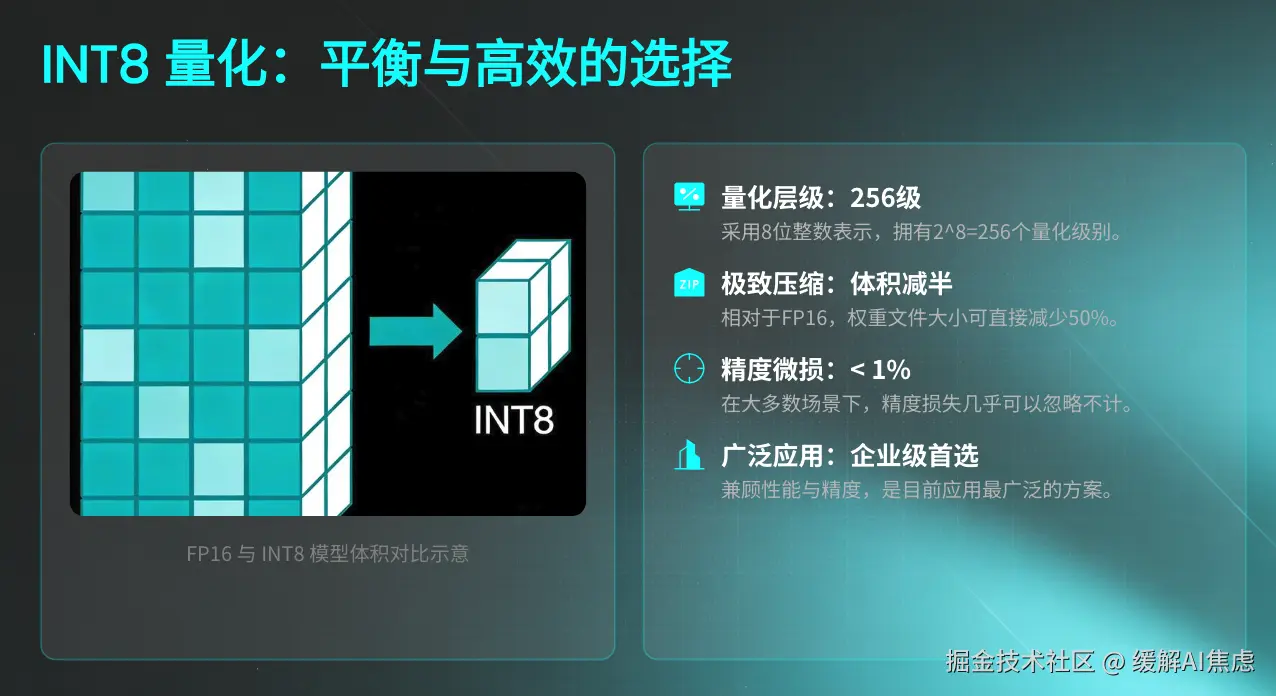
INT8 量化: 提供 256 个量化层级,权重压缩 50%(相对于 FP16),精度损失几乎可以忽略(通常 < 1%)。
-
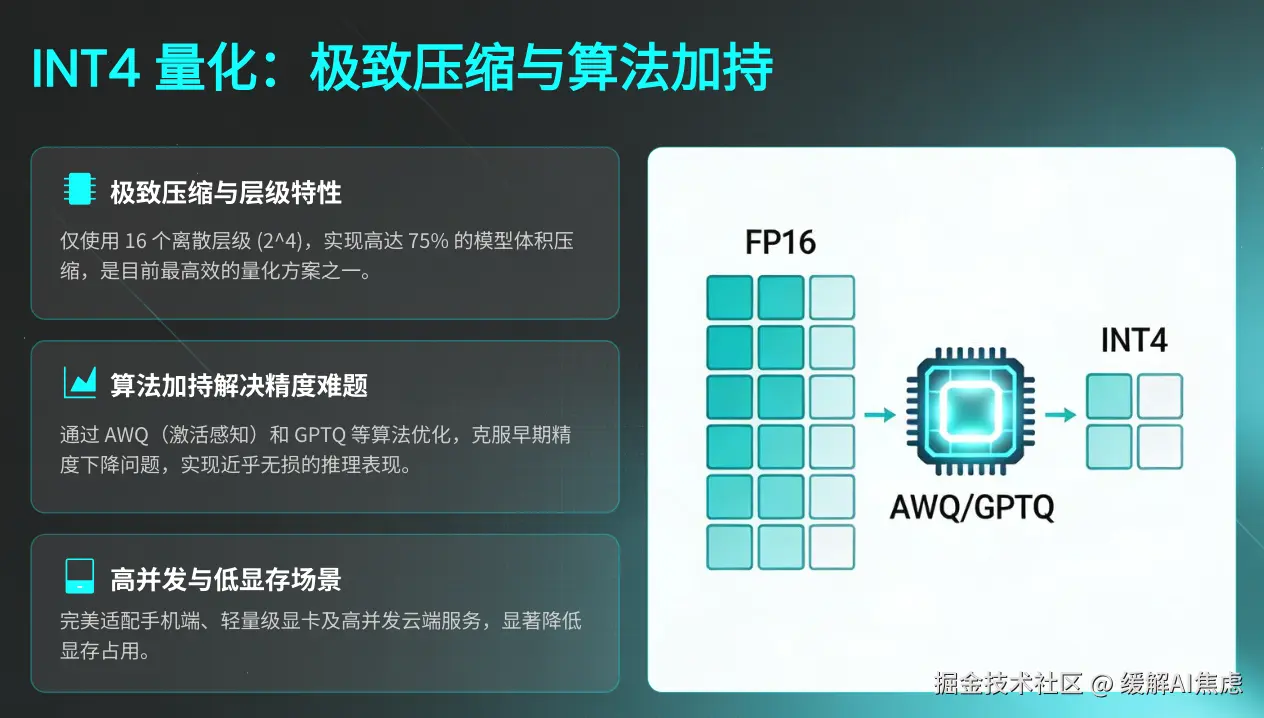
INT4 量化: 提供 16 个量化层级,压缩比高达 75%。在早期这会导致显著精度下降,但通过 AWQ(激活感知权重量化) 或 GPTQ 算法,INT4 已经能实现近乎无损的推理表现。
2. 两种主流技术路径
- PTQ(训练后量化): 最常用。模型训练好后,通过少量校准数据计算 Scale 和 Zero Point。优点是快,几分钟内完成。
- QAT(量化感知训练): 在训练阶段引入量化误差。虽然效果最好,但在百亿参数时代,其计算成本过高,目前正逐渐被高性能的 PTQ 算法(如 OmniQuant)取代。
二、 工具链实战:llama.cpp 与 Transformers/vLLM

目前大模型量化已形成两大生态:GGUF 生态 (主打端侧与 CPU)和 GPTQ/AWQ 生态(主打云端 GPU 加速)。
(一) llama.cpp:端侧部署的"六边形战士"
llama.cpp 凭借其自研的 GGUF 格式,彻底解决了大模型在 Mac、个人电脑和嵌入式设备上的运行难题。
- 核心优势: 极致轻量化,支持 K-Quants(混合精度量化)。它可以对模型中不同的层应用不同的量化位宽(如关键层用 Q5_K,次要层用 Q4_K),在同等显存下实现最高智力水平。
- 实操流程:
- 转换: 使用
convert_hf_to_gguf.py将 HuggingFace 模型转为 GGUF。 - 量化: 使用
./quantize工具进行量化。例如q4_k_m模式是目前公认的"神之配置"。 - 运行: 单个可执行文件即可启动,支持 CPU/GPU 混合推理。
(二) Transformers + vLLM:工业级云端加速
在服务器端,我们追求的是高吞吐。AWQ(Activation-aware Weight Quantization) 已成为目前的工业标准。
- 核心优势: 相比 bitsandbytes(仅节省显存不加速),AWQ 配合 vLLM 或 TensorRT-LLM 引擎,可以利用 GPU 的 Tensor Core 实现真正的 2x-3x 推理加速。
- 代码实现(Python):
ini
from transformers import AutoModelForCausalLM, AWQConfig
# 直接加载云端已量化好的模型
model = AutoModelForCausalLM.from_pretrained(
"TheBloke/Llama-3-8B-Instruct-AWQ",
torch_dtype="auto",
device_map="auto"
)
三、 深度对比:INT8 vs INT4 该选谁?
| 维度 | FP16 (基准) | INT8 量化 | INT4 (AWQ/GGUF) |
|---|---|---|---|
| 显存占用 (8B 模型) | ~16GB | ~8.5GB | ~5.2GB |
| 推理速度 | 1.0x | 1.2x - 1.5x | 2.5x - 4.0x |
| 精度保持 | 100% | > 99.5% | 98% - 99.3% |
| 推荐场景 | 模型微调、高精科研 | 常规企业级应用 | 手机端、轻量显卡、高并发云端 |
四、 避坑指南:量化部署的"潜规则"
-
别被"显存占用"骗了: 量化只能压缩权重 。推理时的 KV Cache (上下文记忆)依然占用大量显存。如果你的 Context 长度设为 32k,即使是 INT4 模型也可能因为 KV Cache 溢出而崩掉。建议同步开启 FlashAttention-2 优化。
-
量化不一定变快: 某些 INT8 方案(如 bitsandbytes)在推理时需要实时把数据解压回 FP16,这会导致推理变慢。真正要加速,请认准 AWQ、GPTQ 或 GGUF。
-
硬件决定上限:
- NVIDIA RTX 30/40 系列: 完美支持 INT4 推理加速。
- 旧款 GPU / 移动端 CPU: INT8 兼容性更好。
- Mac M 系列: GGUF 是神级选择。
五、 总结:从"能跑"到"好用"
量化技术已经走出了"牺牲精度换空间"的初级阶段。对于 2026 年的开发者而言:
- 如果你想在个人笔记本或边缘设备 部署,llama.cpp (GGUF Q4_K_M) 是不二之选。
- 如果你在服务器端构建高并发服务 ,vLLM + AWQ 是目前的性能天花板。
掌握量化,意味着你可以在 1000 元的显卡上跑出原本需要 10000 元显卡的性能。这是大模型迈向全民化、普及化的核心引擎。