这是 「AI是怎么回事」 系列的第 13 篇。我一直很好奇 AI 到底是怎么工作的,于是花了很长时间去拆这个东西------手机为什么换了发型还能认出你,ChatGPT 回答你的那三秒钟里究竟在算什么,AI 为什么能通过律师考试却会一本正经地撒谎。这个系列就是我的探索笔记,发现了很多有意思的东西,想分享给你。觉得不错的话,欢迎分享+关注。
第一次看到这个系列?从第1篇开始最顺畅,直接读这篇也没问题。

同一个 ChatGPT,同一个问题:
问法 A:"帮我写一封邮件。"
输出:一封平庸的模板邮件------"尊敬的 XX,您好!我写信是为了......"开头千篇一律,内容泛泛而谈,看起来像从模板库里复制粘贴的。
问法 B:"我是一个产品经理,需要给工程团队写一封邮件,说明本周需求变更的原因。变更原因是客户反馈了一个影响付款流程的紧急 bug。语气要专业但不生硬,控制在 200 字以内。"输出:一封精准、得体、语气恰到好处的邮件------开头直奔主题,说明变更原因,解释优先级调整的逻辑,结尾给出下一步行动计划。
为什么差距这么大?
不是因为 AI"更认真了"------AI 没有"认真"或"敷衍"的概念。也不是因为你说了什么魔法咒语。
而是因为你给了它完全不同的上下文。
前两章你获得了两样东西:一个定义(AI 是超级模式匹配器),一套判断工具(三问判断法)。从这一篇开始,我们进入第三章------和 AI 一起工作。你会发现一件有趣的事:所有"怎么用好 AI"的实用建议,答案都藏在我们已经学过的原理里。不需要新知识,只需要把旧知识换一个方向。
从一个核心问题开始:Prompt 到底是什么?
在 AI 的世界里,你输入给 AI 的那段文字有一个专门的名字------Prompt(提示词)。

网上有无数"Prompt 技巧大全"、"100 个万能 Prompt 模板"、"Prompt 工程师年薪百万"之类的文章。看起来,Prompt Engineering(提示词工程)像是一门玄学------某些特定的"咒语"能让 AI 表现得更好,但没人解释为什么。
这不符合我们这个系列的风格。我们不接受黑箱。
所以这一篇不是给你一本"Prompt 食谱"让你照着做。我要从原理层面回答一个问题:为什么有些问法就是比另一些管用?
答案只有一个,而且你已经知道了。
一个原理,四种表现
让我们回到第 6 篇讲过的注意力机制。
还记得"两个苹果"的例子吗?"我吃了一个红色的苹果"和"我买了一部苹果手机"------同一个词"苹果",因为上下文不同,AI 的注意力机制把它分别理解为水果和品牌。

Prompt 就是 AI 的上下文。
当你说"帮我写一封邮件",AI 看到的上下文只有这 7 个字。它的注意力机制几乎无从"对焦"------"邮件"是什么主题?写给谁?语气要怎样?长度多少?这些信息全部缺失。AI 怎么办?它只能靠训练数据中"写邮件"相关的统计模式来生成内容。而训练数据里有商务邮件、求职邮件、投诉邮件、情书......各种邮件的模式全部混在一起。没有足够的上下文来区分,AI 就只能输出一个"平均值"------一封什么场景都凑合、但什么场景都不精准的模板邮件。
但当你给出丰富的上下文------产品经理、工程团队、需求变更、专业但不生硬、200 字以内------注意力机制开始精准对焦,概率分布急剧收窄:
上下文少("帮我写一封邮件"):
可能的下一个词: 尊敬 您好 亲爱 Dear Hi ...
各自的概率: 0.12 0.11 0.09 0.08 0.07 ...
← 分布很"平",很多词概率差不多 →
上下文多("产品经理给工程团队写需求变更邮件"):
可能的下一个词: Hi 团队 各位 ... 亲爱
各自的概率: 0.35 0.28 0.15 ... 0.01
← 分布很"尖",少数词概率明显更高 →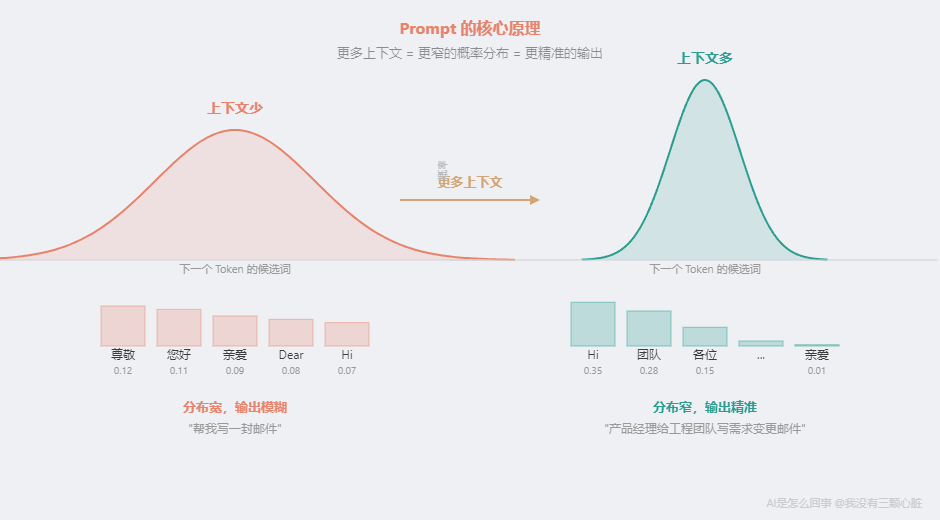
这就是整篇文章的核心公式:
更多上下文 = 更窄的概率分布 = 更精准的输出。
不是玄学,不是咒语,是注意力机制和概率分布在起作用。
接下来我要讲的四种 Prompt 技巧------给上下文、给例子、分步思考、角色设定------做的都是同一件事:用不同的方式缩窄 AI 的概率分布。 四条路,一个目的地。
技巧一:给上下文------直接缩窄概率分布
这是最基本也是最强的技巧,上面已经用邮件例子演示过了。
核心逻辑:你告诉 AI 的信息越多(读者是谁、目的是什么、风格要求、长度限制),注意力机制能"对焦"的锚点就越多,概率分布就越窄。
但注意:关键不是"长度",而是"有效上下文"。
让我用一个对比来展示什么叫"有效":
废话上下文(200 字但信息密度低):
"请你认真思考,仔细分析,给我一个高质量的、专业的、有深度的回答。这对我非常重要,请一定要做好。我想要一篇关于远程办公的文章。"
有效上下文(50 字但每句话都在缩窄概率分布):"你是 HR 顾问,写一篇面向中小企业老板的远程办公分析,800 字,每个观点配数据。"
前者写了 200 字,但 AI 能用来"对焦"的信息只有最后一句"关于远程办公的文章"------前面全是噪音。后者只有 50 字,但每一个词都在缩窄范围:HR 顾问锁定了语气,中小企业老板锁定了读者,800 字锁定了长度,配数据锁定了论证风格。
2024 年的研究发现,在 Prompt 中加入无关信息会显著降低输出质量------因为注意力机制会被无关内容分散,反而让概率分布变得更模糊。比如你在 Prompt 里加了一段"我最近工作压力很大,希望你能帮帮我"------AI 的注意力机制会分配一部分权重去处理这些情绪信息,反而在"远程办公分析"这个真正的任务上分了心。
原则:每一句话都应该在缩窄概率分布。如果一句话不能帮 AI 更好地"对焦",就不要加。
技巧二:给例子------用模式匹配来缩窄
第一章我们说过,AI 的核心能力是模式匹配。那么问题来了------如果你想让它匹配一个特定的模式,最直接的方法是什么?
给它看几个样本。
这个技巧在 AI 领域有专门的名字。根据你给的示例数量,分为三种:
- Zero-shot(零样本):不给任何例子,直接让 AI 做任务。"Zero"是零,"shot"在这里指"尝试"------让 AI 零次练习就上场。
- One-shot(单样本):给一个例子。
- Few-shot(少样本):给 2-5 个例子。"Few"就是"几个"的意思。
先看一个具体对比。
Zero-shot(不给例子):
请把下面这段产品描述翻译成营销文案。
产品描述:"这款蓝牙耳机支持主动降噪,续航时间 30 小时,重量仅 5 克。"
AI 的输出可能风格不定------有时写得像说明书,有时写得像广告语,有时写得像朋友圈。因为它不知道你要什么风格的"营销文案"。
Few-shot(给两个例子):
请把产品描述翻译成营销文案。以下是两个示例:
示例 1------
产品描述:"这款保温杯可保温 12 小时,316 不锈钢内胆,容量 500ml。"
营销文案:"从清晨第一口到深夜加班,你的咖啡始终是刚泡好的温度。"
示例 2------
产品描述:"这款台灯亮度可调 5 档,色温 3000K-6000K,无频闪。"
营销文案:"不是所有光都温柔,但这一盏是。从暖黄到冷白,你的眼睛说了算。"
现在请处理------
产品描述:"这款蓝牙耳机支持主动降噪,续航时间 30 小时,重量仅 5 克。"
AI 的输出会稳定地呈现出和示例一致的风格------场景化的语言、突出用户体验、句式简洁有力。
为什么? 因为两个例子就是两个"模式样本"。AI 的模式匹配能力会立刻捕捉到这些例子中的共同模式------什么句式、什么语气、什么结构------然后按照这个模式处理你的新输入。
就像你不需要告诉一个厨师"川菜的特点是麻辣鲜香、善用花椒和辣椒"------你只要给他看三道川菜,他就知道下一道该怎么做了。
这有严格的研究数据支持。 2020 年,OpenAI 发表了 GPT-3 论文"Language Models are Few-Shot Learners"。核心发现是:GPT-3 在阅读理解任务上,zero-shot 的表现是 59.8 分,而 few-shot 达到了 85 分------仅仅因为给了几个示例,成绩就从"勉强及格"跳到了"接近人类水平"。

更重要的是,模型越大,从示例中"抓取模式"的能力越强。 小模型给不给例子差别不大,但当模型参数量达到 1750 亿(GPT-3 的规模),zero-shot 和 few-shot 之间的差距急剧拉大。这说明 few-shot 的本质是"模式匹配"------模型越大,匹配能力越强,从几个例子中提取模式的效率就越高。
2024 年的一项大规模综述研究进一步证实了这一点:在"The Prompt Report"中,32 位来自 OpenAI、Google、斯坦福等机构的研究者系统分析了 1500 多篇关于 Prompt 的学术论文,发现 Few-shot Chain-of-Thought(少样本+思维链,下一节会讲)是效果最稳定、最强的 Prompt 技术。
所以:给例子有效,是因为你在利用 AI 最核心的能力------模式匹配。 几个例子就是几个"模式样本",AI 从中提取出模式,然后应用到新的输入上。
技巧三:分步思考------把大的概率空间拆成多个小的
这是所有 Prompt 技巧中最神奇、也最违反直觉的一个。
2022 年,Google 的研究者 Jason Wei 等人发表了一篇论文:"Chain-of-Thought Prompting Elicits Reasoning in Large Language Models"。
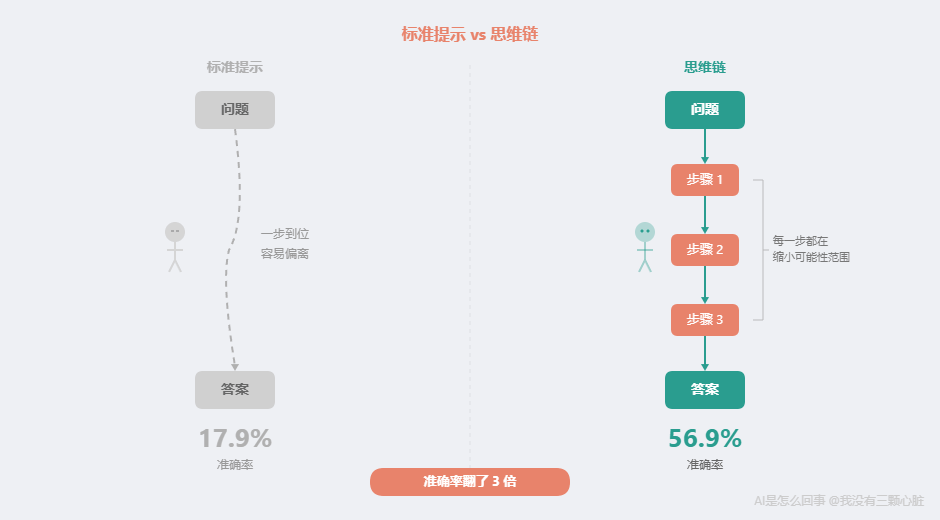
Chain of Thought(思维链,简称 CoT)的意思就是:让 AI 一步一步地展示自己的思考过程,而不是直接给出最终答案。

效果有多大?在 GSM8K(一个包含 8500 道小学数学应用题的测试集)上:
- 标准提示 (直接问答案):准确率约 17.9%
- 思维链提示 (让 AI 一步步想):准确率约 56.9%
从 17.9% 到 56.9%------准确率翻了三倍多。而且研究者做的唯一改变,就是在提示中增加了几个"展示解题步骤"的示例。
这是什么概念?相当于同一个学生、同一张试卷,只不过老师把要求从"直接写答案"改成了"请写出解题步骤"------成绩就从不及格变成了中上水平。
但为什么?AI 又没有"更认真地想"。
让我用一个具体的例子来展示。
标准提示(直接问):
问:小明有 5 个苹果,给了小红 2 个,然后妈妈又给了他 3 个。他现在有几个苹果?
答:6
AI 直接预测最终答案。如果它的"一步到位"预测错了,就没有纠正的机会了。
思维链提示(分步想):
问:小明有 5 个苹果,给了小红 2 个,然后妈妈又给了他 3 个。他现在有几个苹果?
让我一步一步来想。
第一步:小明开始有 5 个苹果。
第二步:给了小红 2 个,所以 5-2 = 3 个。
第三步:妈妈又给了他 3 个,所以 3+3 = 6 个。
答:6 个。
两种方式都得出了 6。但在更复杂的问题上,差距就出来了。
关键在于:当 AI 生成"第一步"的结果后,这个结果就成为了它生成"第二步"时的上下文。
还记得上面的核心公式吗?更多上下文 = 更窄的概率分布 = 更精准的输出。
思维链本质上是在做这件事:把一个复杂的大问题拆成多个简单的小步骤,每一步的输出都成为下一步的上下文。AI 不需要在"一步到位"的巨大可能性空间中猜答案,而是在每一步的小范围内做高精度的匹配。
更通俗地说:让 AI 直接跳到答案,就像让你从房间的一端蒙着眼睛直接走到对角------大概率会撞墙。但如果每走一步你都能睁眼确认一下方向,你就能顺利到达目的地。思维链就是让 AI 每走一步都"睁一次眼"。
后续研究进一步提升了效果。Wang 等人提出的"自洽性"(Self-Consistency)方法------让 AI 用不同的思路多想几遍,然后取最一致的答案------在 GSM8K 上又额外提升了 17.9 个百分点,达到约 74%。
Wei 等人的论文还发现了一个重要规律:思维链只在大模型上有效。 当模型参数量在 100 亿以下时,加不加思维链几乎没有区别;只有当参数量达到约 1000 亿时,思维链的效果才突然涌现出来。这和 GPT-3 论文中 few-shot 的发现类似------模式匹配能力需要达到一定的规模门槛,才能从中间步骤中有效地"抓取"模式。
技巧四:角色设定------偏移概率分布的中心
"你是一个资深律师。"
"假设你是一位有 20 年经验的数据分析师。"
"你是一个儿童教育专家,擅长用简单的语言解释复杂的概念。"
当你说"你是一个资深律师",这几个字进入了 AI 的上下文。注意力机制会把这段上下文和后续生成的每一个词做关联计算。结果是:AI 在训练数据中学到的大量"律师语境下的文本模式"------法律术语的使用方式、论证的逻辑结构、引用判例的习惯、严谨但不晦涩的表达风格------这些模式的权重被显著提升了。
不是 AI"变成了"律师,是它的输出概率分布偏向了法律领域的文本模式。 就像一个演员接到角色后,他不是真的变成了那个人,但他会调动自己积累的所有相关表演经验------动作、语气、表情------来呈现那个角色。AI 的角色设定做的是类似的事:调动训练数据中与该"角色"相关的文本模式。
但这里我必须诚实地告诉你一件事:角色设定的效果比很多人以为的要弱,而且在不同场景下差别很大。
2023 年的一项研究"When 'A Helpful Assistant' Is Not Really Helpful"系统测试了 162 种角色设定(涵盖 6 种人际关系和 8 个专业领域),在 4 个主流大语言模型上测试了 2410 道事实性问题。结果发现:对于事实性问题,添加角色设定并不能提升 AI 的准确率,有时甚至会导致准确率下降。
2025 年 Mollick 等人的研究"Playing Pretend: Expert Personas Don't Improve Factual Accuracy"进一步证实了这一点:在需要研究生水平知识的困难多选题上,给 AI 设定"物理学专家"或"法律专家"的角色,对答题准确率几乎没有影响。
如果你理解了原理,这就完全说得通:
角色设定调整的是"文本风格"的概率分布,不是"事实知识"的概率分布。
- 风格类任务(写一封律师风格的信、用儿童能懂的语言解释量子力学、以记者口吻写一篇报道)→ 角色设定非常有效,因为它直接调整了语气、结构、用词的模式
- 事实类任务(这道数学题答案是多少、某个历史事件发生在哪一年、某条法律的具体规定是什么)→ 角色设定几乎无效,因为事实不会因为"你是专家"就变得更准确
所以,角色设定不是万能的。它的真正作用是调整输出的"风格"和"框架"------当你需要特定领域的表达方式和思考结构时,角色设定很好用;当你需要事实准确性时,角色设定帮不了你。
四种技巧,一个本质
现在让我把四种技巧放在一起,你会看到它们的共同点:
| 技巧 | 做法 | 怎么缩窄概率分布 | 最适合的场景 |
|---|---|---|---|
| 给上下文 | 告诉 AI 读者是谁、目的、风格、长度 | 直接缩窄------提供更多锚点让注意力机制对焦 | 几乎所有场景 |
| 给例子 | 提供 2-3 个"输入→输出"的示例 | 用模式匹配缩窄------AI 从样本中提取模式并应用 | 需要特定格式、风格或结构的任务 |
| 分步思考 | 让 AI 展示中间推理步骤 | 拆分缩窄------把大空间拆成多个小空间逐步收敛 | 需要多步推理的任务(数学、逻辑) |
| 角色设定 | 给 AI 一个专业身份 | 偏移缩窄------把分布中心移向特定领域的模式 | 需要特定领域表达风格的任务 |
四种技巧不是互斥的,最好的 Prompt 往往是它们的组合。
实操对比:一个完整的例子
任务: 帮我写一篇关于"远程办公优缺点"的短文。
版本一:差的 Prompt
写一篇关于远程办公优缺点的文章。
AI 大概率输出: 一篇泛泛而谈的、教科书式的议论文------"远程办公有很多优点,比如节省通勤时间、提高灵活性。但也有缺点,比如缺乏面对面交流、容易感到孤独......"正确但无聊,像是从百度百科复制的。
为什么差? 上下文极少。AI 不知道读者是谁、目的是什么、要什么风格、多长。概率分布太宽,只能输出"平均值"。
版本二:好的 Prompt
你是一位资深的 HR 顾问,擅长用数据和案例说话。
请写一篇面向中小企业老板的短文(800 字左右),主题是"远程办公的优缺点"。
要求:
- 用具体的数据或案例支撑每一个观点(而非泛泛而谈)
- 优点和缺点各列 3 条,每条配一个具体案例或数据
- 最后给出一条针对中小企业的实操建议
- 语气专业但易读,避免学术化的表达
示例风格参考:
"根据 Buffer 2023 年的远程工作报告,71% 的远程工作者表示工作与生活的平衡是最大的优势------但同一份报告也显示,24% 的人认为'孤独感'是最大的挑战。"
AI 大概率输出: 一篇有数据支撑、结构清晰、语气恰当、面向特定读者的专业短文。
为什么好? 让我逐一拆解这个 Prompt 用到了哪些技巧,以及每一条背后的原理:
| Prompt 的组成部分 | 用到的技巧 | 背后的原理 |
|---|---|---|
| "你是一位资深的 HR 顾问" | 角色设定 | 让输出概率分布偏向人力资源领域的专业表达模式 |
| "面向中小企业老板""800 字" | 给上下文 | 缩窄概率分布------读者画像限定了用词和深度,字数限定了结构 |
| "用具体数据""每条配案例" | 给上下文+约束 | 进一步缩窄概率分布------排除"泛泛而谈"的模式,偏向"有论据支撑"的模式 |
| 示例风格参考 | Few-shot | 用一个例子锁定具体的文本模式------数据引用的格式、对比的句式、"但"字转折 |
每一条改进,都在做同一件事:给 AI 提供更精准的上下文,让概率分布变得更窄、输出变得更精准。
Prompt 有没有完全不管用的情况?
有。
如果任务本身不是模式匹配能解决的,再好的 Prompt 也没用。
比如你问 AI"证明黎曼假设"------这需要真正的数学创新,不是模式匹配能解决的。
再比如你问 AI"2024 年 12 月 15 日北京的天气如何?"------虽然现在很多 AI 产品(ChatGPT、Google AI Overview、Perplexity)已经接入了搜索功能,能帮你查到实时信息,但这不是 Prompt 的功劳,也不是语言模型本身的能力。那是工程师在模型外面接了一根"搜索管道"------模型自己依然不知道今天的天气,它只是学会了"什么时候该去查一下"。Prompt 能调整的,始终只是模型内部的概率分布,而不是给它凭空增加新能力。
Prompt Engineering 的边界,就是 AI 能力的边界。 好的 Prompt 能让 AI 在它擅长的范围内发挥到极致,但不能让它超越模式匹配本身的局限。
AI 越来越聪明了,以后还需要学 Prompt 吗?
确实,从 GPT-3 到 GPT-4 到更新的模型,AI 对模糊 Prompt 的处理能力在不断提升------同样一句"帮我写封邮件",新模型可能会主动追问你"写给谁?什么场景?",或者自动推测一些上下文。
但核心逻辑不会变:AI 的输出质量取决于它获得的上下文质量。 即使 AI 越来越善于从少量上下文中推断,给它更丰富、更精准的上下文仍然会带来更好的结果。
这和"相机越来越智能了,摄影师还需要学构图吗?"是一样的道理。自动模式可以拍出"还不错"的照片,但懂构图的人用手动模式能拍出"惊艳"的作品。理解原理的人,永远比只按快门的人能获得更好的结果。
更重要的是:一旦你理解了"Prompt 就是给 AI 提供上下文,让概率分布变窄"这个原理,你就不需要背任何模板了。你可以根据任何新的场景、新的 AI 模型,自己设计出有效的 Prompt。模板会过时,原理不会。
个人锚点
如果你之前也在网上收集过各种"万能 Prompt 模板",有时候套上模板效果不错,有时候完全不管用却不知道为什么------那么现在回头看第 6 篇的注意力机制,一切就串起来了。
Prompt 就是上下文,上下文决定注意力分配,注意力分配决定输出。
一旦理解了这个原理,你就不需要背任何模板了。每次写 Prompt 之前,问自己一个问题就够了:「AI 现在缺什么信息?如果它是一个能力很强但对我的情况一无所知的助手,我需要告诉它什么,它才能给我想要的东西?」
如果你也试过这个思路,你可能会发现它从来不会让你失望。因为它不是一个"技巧",它是从原理出发的思维方式。
理解了原理,你就能自己发明技巧。这比背一百个模板有用得多。
一句话回顾
Prompt Engineering 不是玄学,是利用 AI 的模式匹配特性------给它更好的上下文,它就给你更好的输出。四种核心技巧(给上下文、给例子、分步思考、角色设定)做的都是同一件事:缩窄 AI 的概率分布,让输出更精准。
下一篇预告
学会了怎么让 AI"听懂"你的话,但有一个更关键的问题还没回答:
AI 给你的回答,你该信几分?
上一篇讲的是"怎么给 AI 更好的输入"。下一篇,我们要讲"怎么处理 AI 的输出"------它说的话什么时候能信、什么时候不能信?你该怎么和一个"能力很强但完全不靠谱"的助手高效协作?
答案同样藏在原理里。
参考资料
- Wei, J., et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS 2022 . https://arxiv.org/abs/2201.11903 --- CoT 论文原文,PaLM 540B 在 GSM8K 上从 17.9% 提升到 56.9%
- Brown, T.B., et al. (2020). Language Models are Few-Shot Learners. NeurIPS 2020 . https://arxiv.org/abs/2005.14165 --- GPT-3 论文,展示了 few-shot 学习的强大效果
- Wang, X., et al. (2022). Self-Consistency Improves Chain of Thought Reasoning in Language Models. https://arxiv.org/abs/2203.11171 --- 自洽性方法在 GSM8K 上额外提升 17.9 个百分点
- Schulhoff, S., et al. (2024). The Prompt Report: A Systematic Survey of Prompting Techniques. https://arxiv.org/abs/2406.06608 --- 32 位研究者系统分析 1500+ 篇 Prompt 论文,Few-shot CoT 效果最稳定
- Zheng, S., et al. (2023). When "A Helpful Assistant" Is Not Really Helpful: Personas in System Prompts Do Not Improve Performances of Large Language Models. https://arxiv.org/abs/2311.10054 --- 162 种角色设定在事实性问题上无效果
- Mollick, E., et al. (2025). Playing Pretend: Expert Personas Don't Improve Factual Accuracy. SSRN . https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5879722 --- 专家角色设定不提升事实准确率
- MLOps Community. (2024). The Impact of Prompt Bloat on LLM Output Quality. https://mlops.community/the-impact-of-prompt-bloat-on-llm-output-quality/ --- 无关信息降低输出质量的研究
订阅
如果觉得有意思,欢迎关注我,后续文章也会持续更新。同步更新在个人博客和微信公众号
微信搜索"我没有三颗心脏"或者扫描二维码,即可订阅。
