文章目录
背景
最近在研究给 OpenClaw 配置一个更强悍的记忆系统,后面发现 OpenClaw 3.8 开始支持 qmd 作为记忆后端,于是自己在本地琢磨了一下,发现配置还是有些门道的,就写篇博客吧。
qmd 是一个本地化的搜索工具,结合了 BM25 全文搜索、向量语义搜索和 LLM 重排序,关键是模型都能本地运行,不需要联网!
环境
- 设备:Mac mini M4
- 内存:
16GB - GPU:
M4 - 系统:
macOS - OpenClaw 版本:
2026.3.8 - qmd 版本:
1.1.6
完整部署步骤
1.安装 bun
qmd 官方推荐用 bun 运行,我刚开始用 npm 安装出现了兼容性问题(node>=25 版本),但是目前 qmd 在最新的 v2.0.1 中兼容了 node 25 的兼容性问题,同学们可以尝试用 npm 装下。
bash
curl -fsSL https://bun.sh/install | bash2.安装 qmd
bash
bun install -g @tobilu/qmd3.下载模型文件
从 HuggingFace 下载官方示例中的 3 个 GGUF 模型文件,放到 ~/.cache/qmd/models/ 目录:
| 模型 | 用途 | 大小 |
|---|---|---|
| embeddinggemma-300M-Q8_0.gguf | 向量嵌入 | ~313MB |
| qwen3-reranker-0.6b-q8_0.gguf | 结果重排 | ~610MB |
| qmd-query-expansion-1.7B-q4_k_m.gguf | 查询扩展 | ~1.2GB |
虽然官方支持在首次启动 qmd 时自动下载这三个模型,但是国内特别特别慢,即使你配置了代理,也很慢,会一直出现转圈圈处在 loading 的状态,建议直接开代理在网页上下载。
如果你只想用 qmd 的
search关键词搜索能力,那么只需要下载第一个模型,但是这也失去了装 qmd 的意义。
4.源码修改与环境变量配置
qmd 官方默认只支持为向量模型 指定本地路径,不支持为结果重排 和查询扩展 模型设置,这里我看官方源码,最终找到了可以配置的地方,目前已经提交了 pr,看官方是否会合并吧。
修改 qmd 源码,文件路径参考:~/.bun/install/global/node_modules/@tobilu/qmd/dist/llm.js
通过 Model Configuration 进行定位,找到下面这段代码,把我这段覆盖上去就好了。
js
// =============================================================================
// Model Configuration
// =============================================================================
// HuggingFace model URIs for node-llama-cpp
// Format: hf:<user>/<repo>/<file>
// Override via QMD_EMBED_MODEL env var (e.g. hf:Qwen/Qwen3-Embedding-0.6B-GGUF/Qwen3-Embedding-0.6B-Q8_0.gguf)
const DEFAULT_EMBED_MODEL = process.env.QMD_EMBED_MODEL ?? "hf:ggml-org/embeddinggemma-300M-GGUF/embeddinggemma-300M-Q8_0.gguf";
const DEFAULT_RERANK_MODEL = process.env.QMD_RERANK_MODEL ?? "hf:ggml-org/Qwen3-Reranker-0.6B-Q8_0-GGUF/qwen3-reranker-0.6b-q8_0.gguf";
// const DEFAULT_GENERATE_MODEL = "hf:ggml-org/Qwen3-0.6B-GGUF/Qwen3-0.6B-Q8_0.gguf";
const DEFAULT_GENERATE_MODEL = process.env.QMD_GENERATE_MODEL ?? "hf:tobil/qmd-query-expansion-1.7B-gguf/qmd-query-expansion-1.7B-q4_k_m.gguf";源文件路径可能不一样,注意使用自己本地的路径。
修改完成后,配置环境变量,在 ~/.zshrc 中添加:
bash
# QMD 模型路径
export QMD_EMBED_MODEL="/Users/xxx/.cache/qmd/models/embeddinggemma-300M-Q8_0.gguf"
export QMD_RERANK_MODEL="/Users/xxx/.cache/qmd/models/qwen3-reranker-0.6b-q8_0.gguf"
export QMD_GENERATE_MODEL="/Users/xxx/.cache/qmd/models/qmd-query-expansion-1.7B-q4_k_m.gguf"本地的模型位置注意使用自己的,变量名称需要与源码中修改的进行映射,最后执行 source ~/.zshrc 让环境变量生效。
5.OpenClaw 配置
大家如果想要自己配置的话,可以参考 OpenClaw 的官方文档 ------ Memory 进行配置,这里给一版我的示例。
打开 OpenClaw 的配置文件: /Users/xxx/.openclaw/openclaw.json
在开始修改前,建议先备份当前的配置文件,然后再开始修改。
5.1.memorySearch
配置 JSON 路径:$.agents.defaults.
json
"memorySearch": {
"query": {
"hybrid": { // 混合搜索
"enabled": true, // 启用
"vectorWeight": 0.7, // 向量权重 70%
"textWeight": 0.3, // 文本权重 30%
"candidateMultiplier": 4, // 候选结果扩大4倍
"mmr": { // 最大边际相关性(多样性)
"enabled": true,
"lambda": 0.7 // 70%相关性 + 30%多样性
},
"temporalDecay": { // 时间衰减(近因效应)
"enabled": true,
"halfLifeDays": 30 // 30天半衰期
}
}
},
"cache": { // 嵌入缓存
"enabled": true,
"maxEntries": 50000
},
"store": { // 向量存储
"vector": {
"enabled": true // 使用 sqlite-vec 加速
}
}
}为了避免 JSON 格式问题,这里提供一个没有注释的版本,内容是完全一致的:
json
"memorySearch": {
"query": {
"hybrid": {
"enabled": true,
"vectorWeight": 0.7,
"textWeight": 0.3,
"candidateMultiplier": 4,
"mmr": {
"enabled": true,
"lambda": 0.7
},
"temporalDecay": {
"enabled": true,
"halfLifeDays": 30
}
}
},
"cache": {
"enabled": true,
"maxEntries": 50000
},
"store": {
"vector": {
"enabled": true
}
}
}| 配置 | 值 | 含义 |
|---|---|---|
| vectorWeight | 0.7 | 向量搜索贡献70%分数 |
| textWeight | 0.3 | 文本搜索贡献30%分数 |
| candidateMultiplier | 4 | 初筛4倍结果再精选 |
| mmr.lambda | 0.7 | 结果多样性权重 |
| temporalDecay | 30天 | 超过30天的记忆分数减半 |
注意 :这个配置在 search 模式下不生效,只在 query 模式下生效。
5.2.memory
配置 JSON 路径:$.
json
"memory": {
"backend": "qmd", // 使用 QMD 后端
"citations": "auto", // 自动显示引用
"qmd": {
"command": "qmd", // qmd 命令路径
"searchMode": "query", // 搜索模式:search/query/vsearch
"includeDefaultMemory": true, // 自动索引默认记忆文件
"update": {
"interval": "5m", // 更新间隔:5分钟
"debounceMs": 15000, // 防抖:15秒
"onBoot": true, // 启动时更新
"waitForBootSync": false // 启动时是否阻塞等待
},
"limits": {
"maxResults": 6, // 最多返回6条结果
"maxSnippetChars": 500, // 每个片段最多500字符
"maxInjectedChars": 2000, // 注入最多2000字符
"timeoutMs": 15000 // 超时15秒
},
"scope": {
"default": "allow", // 默认允许所有搜索
"rules": [] // 规则为空
}
}
}为了避免 JSON 格式问题,这里提供一个没有注释的版本,内容是完全一致的:
json
"memory": {
"backend": "qmd",
"citations": "auto",
"qmd": {
"command": "qmd",
"searchMode": "query",
"includeDefaultMemory": true,
"update": {
"interval": "5m",
"debounceMs": 15000,
"onBoot": true,
"waitForBootSync": false
},
"limits": {
"maxResults": 6,
"maxSnippetChars": 500,
"maxInjectedChars": 2000,
"timeoutMs": 10000
},
"scope": {
"default": "allow",
"rules": []
}
}| 配置项 | 值 | 说明 |
|---|---|---|
| searchMode | query | query=慢(Hybrid) / search=快(BM25) |
| onBoot | true | 启动时自动更新索引 |
| interval | 5m | 每5分钟增量更新 |
| debounceMs | 15000 | 文件变化15秒后才触发更新 |
| maxResults | 6 | 返回最多6条结果 |
| timeoutMs | 10000 | 搜索超时10秒 |
| scope | allow | 允许所有搜索(CLI也能用) |
这里说一下搜索模式,query 是用扩展模型自动对关键词进行衍生,然后进行混合搜索,最终进行重排序,按得分进行输出,但是如果 PC 性能不行的话,用 query 模式会很慢。
其次是 search 模式,就相当于百度的关键词搜索,所以抛开计算性能,query 模式是更推荐的,要不然查询扩展的模型相当于没装。
配置方面可以自己看官方文档 memory docx 自由修改,我这里不做过多的叙述了。
配置修改完成后,记得重启网关:
shell
openclaw gateway restart6.生成向量嵌入
将你想要构建记忆的存储目录添加到 qmd 中:
bash
qmd collection add ~/.openclaw/workspace --name qmd_memory开始构建向量:
bash
qmd embed -f首次运行会加载模型到 GPU,稍微需要等待一会儿,构建完成后,可以看状态:
bash
qmd status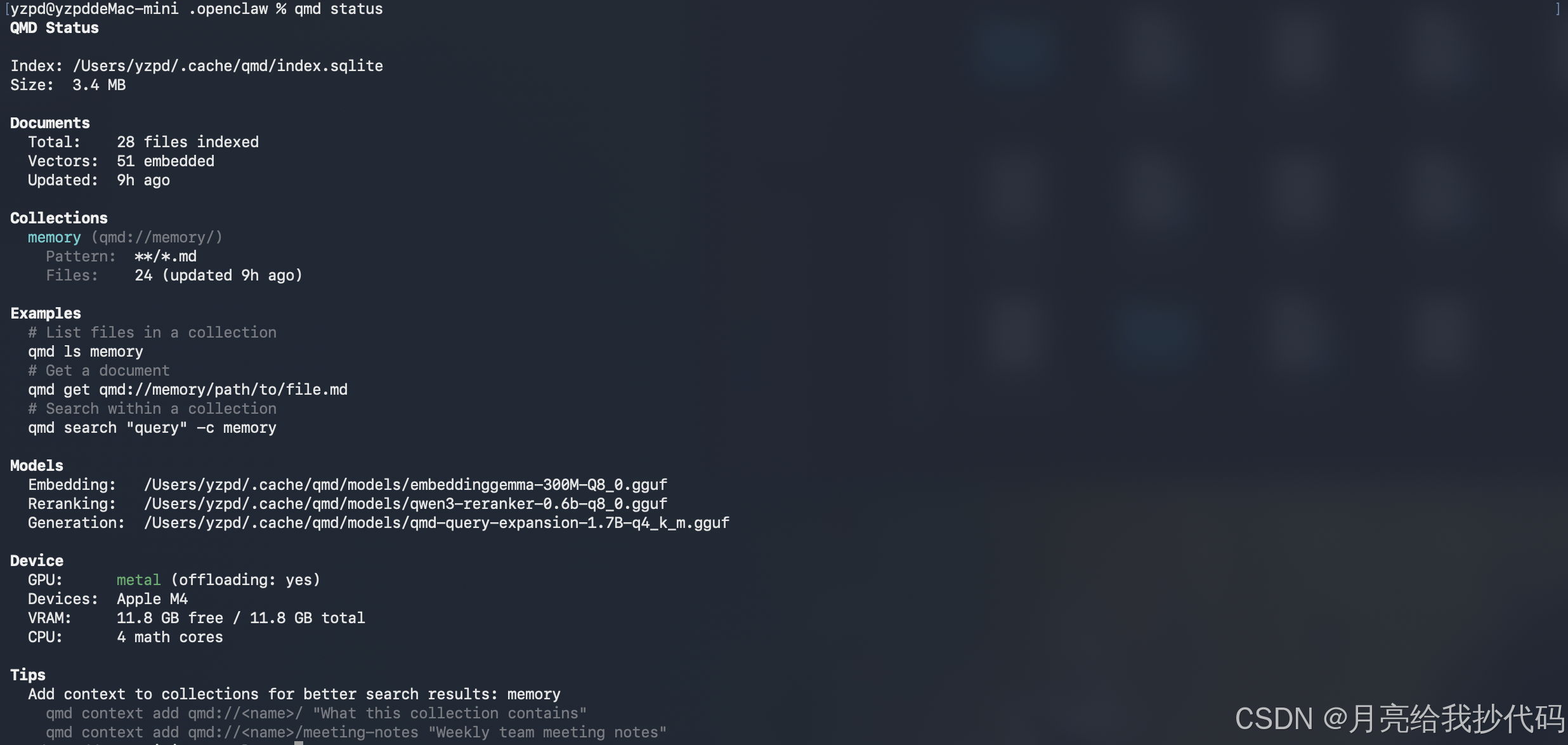
7.测试搜索
直接使用 qmd 命令进行测试:
bash
# 关键字搜索
qmd search "皮蛋"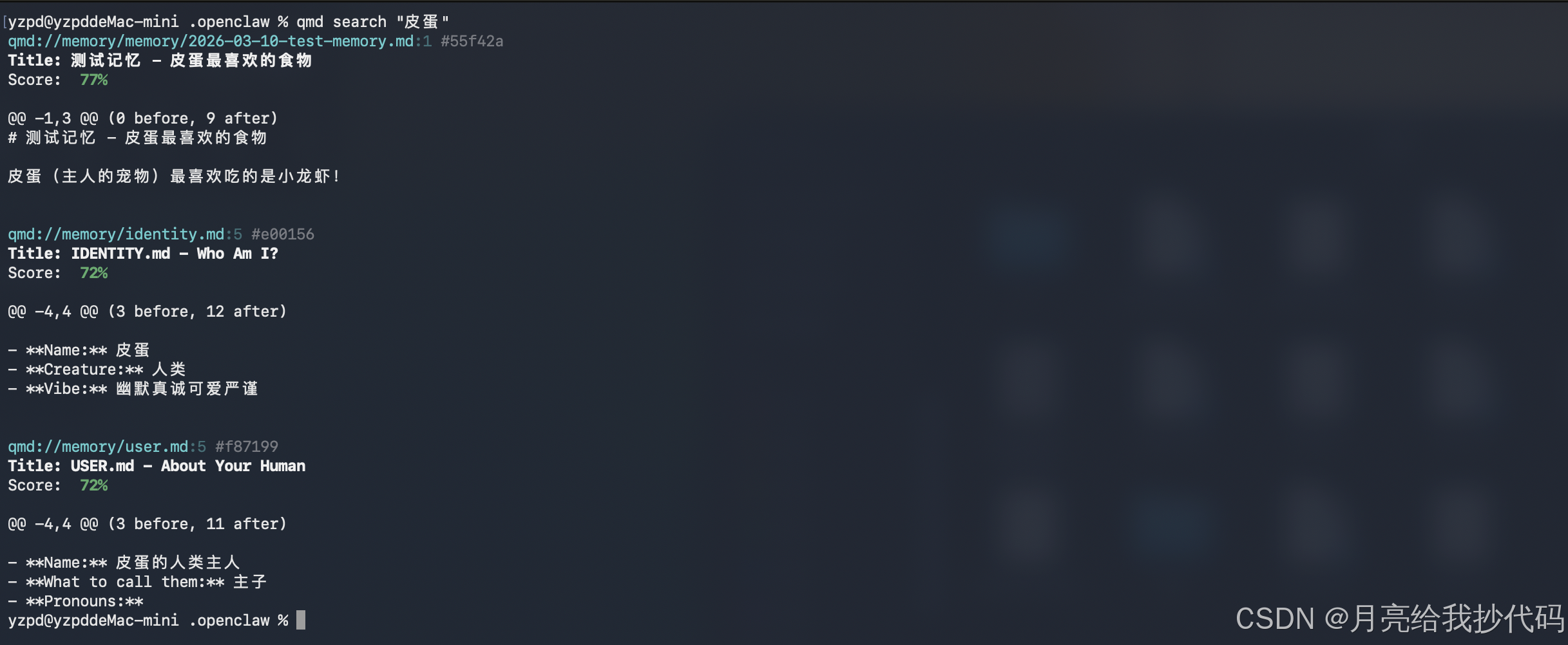
shell
# 语义搜索
qmd query "语义搜索"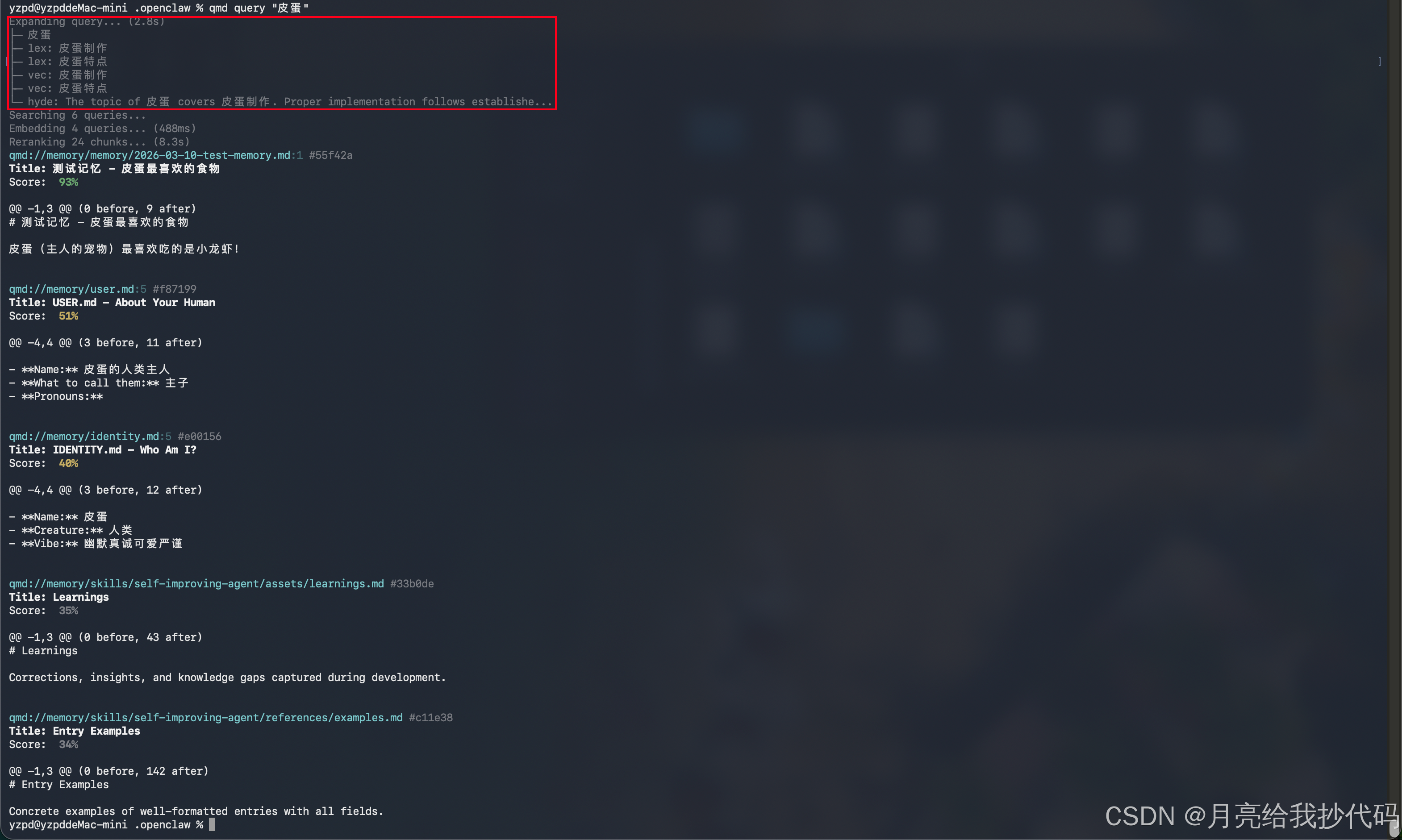
用 query 语义搜索时,可以从打印日志中看到,当我输入 皮蛋 关键词,qmd 先调用了语义扩展模型,花了 2.8s 去进行关键词扩展,然后开始查询构建向量,最终进行重排序,得出结果,按照相关度排序输出结果。
上面是直接通过 qmd 命令去使用了,现在使用 OpenClaw 进行查询:
shell
openclaw memory search "皮蛋"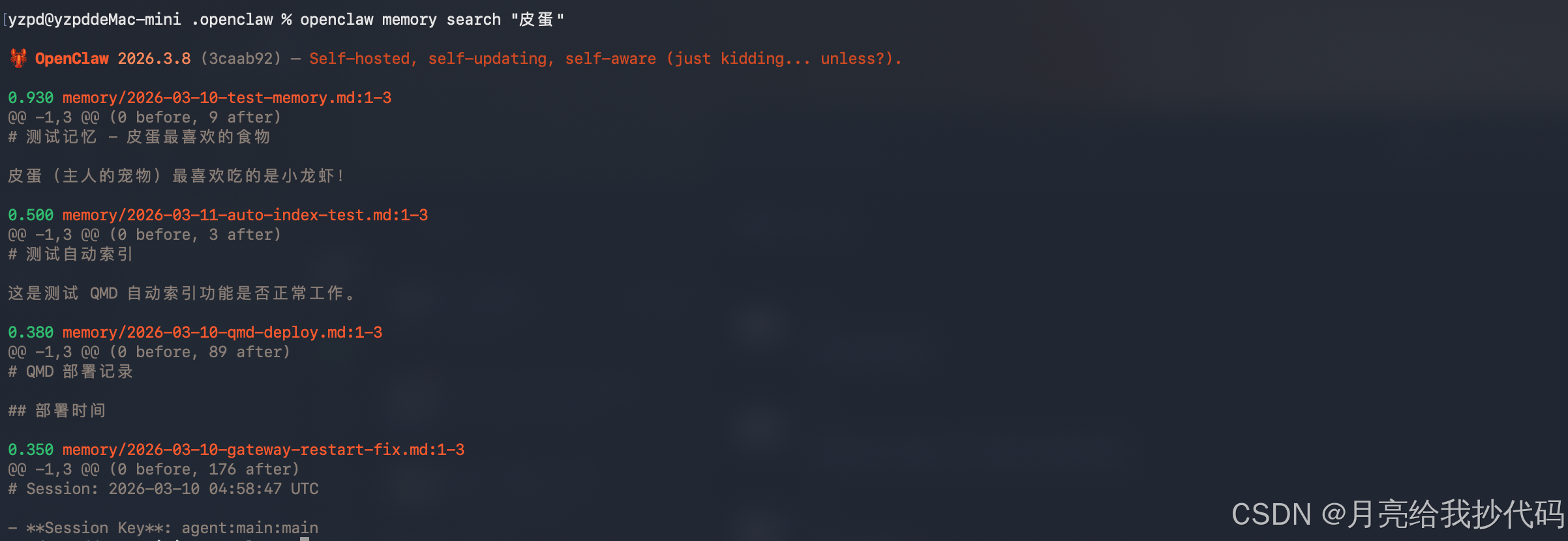
因为 OpenClaw 的 qmd 搜索模式在配置文件里面指定的是 query,所以这里直接用的就是语义搜索。
如果感觉搜索太慢,可以适当调低下面这两个配置项,JSON 路径引用如下:
shell
# openclaw.json
# 控制扩展数与结果数
$.memory.qmd.limits.maxResults: 5
# 控制候选倍数
$.agents.defaults.memorySearch.query.hybrid.candidateMultiplier: 3在输出前,会先扩展到 5*3 个候选项,同时重排过后最多输出 5 条记录作为结果。
总体配置到这里就结束了,后面可以自己在 AGENTS.md 里面写一些规则,控制在哪些时机去写入或者加载记忆。
关于 qmd 使用与配置的更多内容,请参考 Github qmd & OpenClaw Memory Docx ~
8.补充 skill
qmd v2.0.1 版本中出了官方的 skill,可以直接通过下面的命令进行安装:
shell
qmd skill install