前言
作者在求职的过程中,发现RAG这个知识点被提问的频率还是挺高的,恰好作者之前又实践过相关的项目,因此写下该文章 为了总结复习RAG的全流程和实现过程,希望对于不懂RAG的读者也能起到帮助的作用!
相关知识铺叙
LLM(Large Language Model,大语言模型): 是一种基于海量文本数据训练、能理解和生成人类语言的深度学习模型。
今天我所讲解的RAG 就是一项帮助LLM变得更强大的技术 捋一捋时间流程: 先有的LLM大模型 ,后续LLM的使用暴露出一些短板,RAG 正是为了填补这些短板而生,RAG诞生后,还启示了后续的FunctionCall和MCP。
RAG弥补了什么短板?
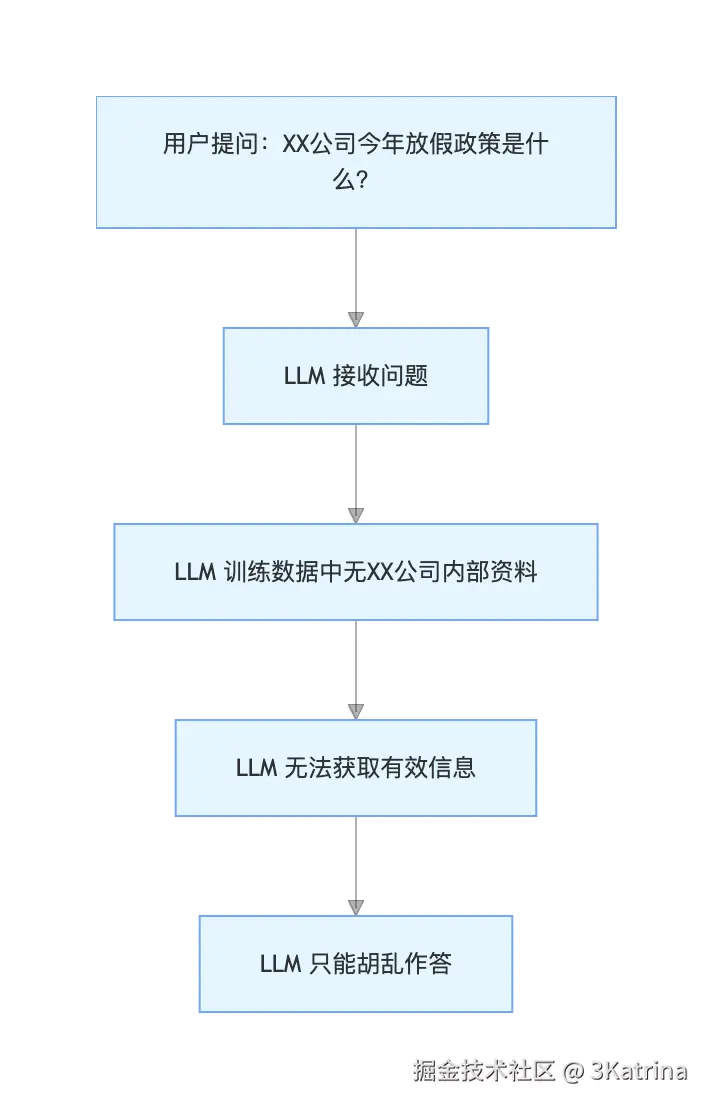
像 ChatGPT 、 DeepSeek 这样的通用大语言模型(LLM)对于一些最新的数据,或者公司内部的数据,没有办法进行回答,比如用户问:"请问XX公司的放假时期是什么时候?" LLM没有办法正确地回答用户
这是因为他们回答的内容只能参照他们已经训练过的数据,而最新的内容或者公司知识库他们没有办法得到,所以对于一些针对最新的内容或者公司内部的内容,因为没有参照,所以他们当然没有办法回答。
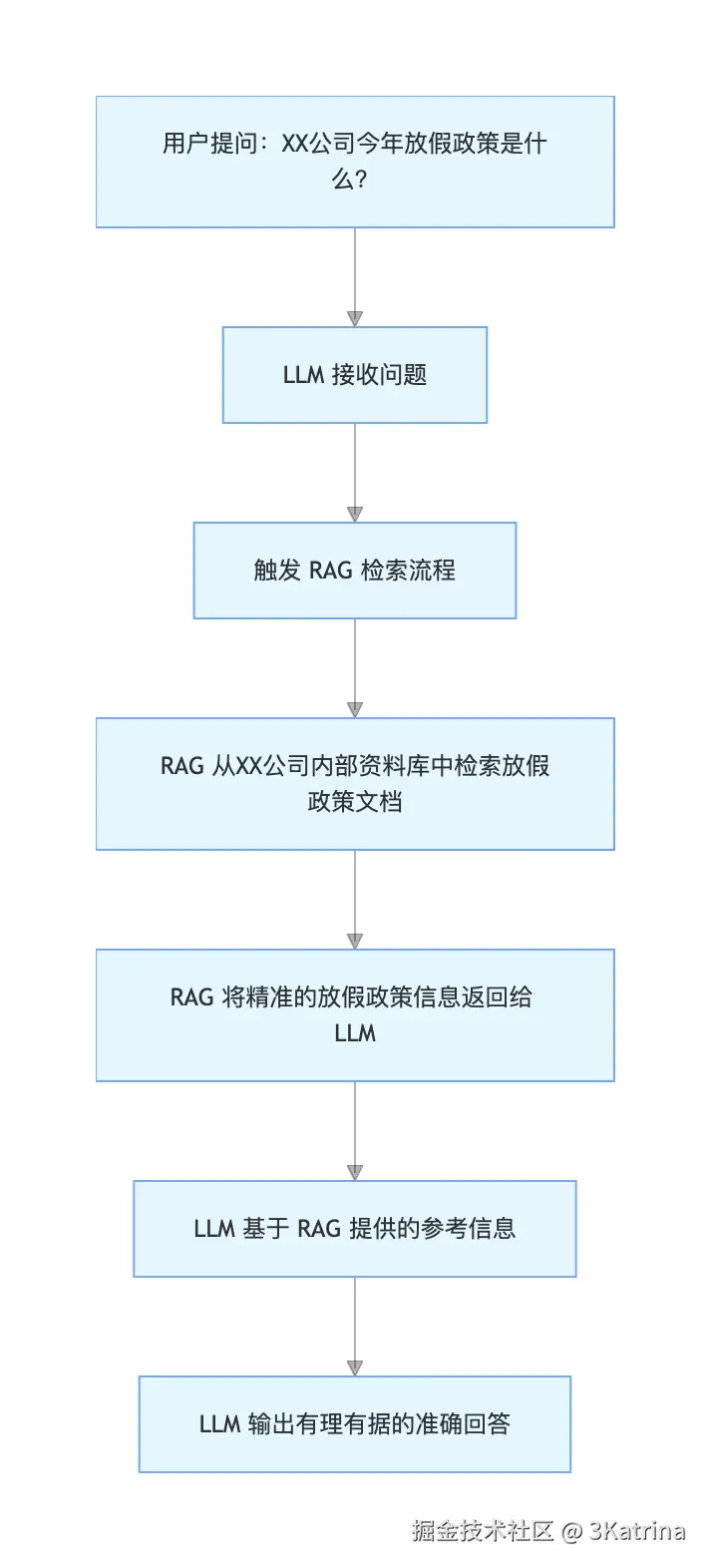
而今天,我想向大家介绍一个推动这些大语言模型变得更靠谱的技术------RAG(检索增强生成,Retrieval-Augmented Generation) 。它可以给LLM提供资料,使得完成下面的效果
无RAG的情况
当有了RAG后
RAG概念的提出
在2020年 Facebook AI Research(FAIR)团队发表一篇名为《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》的论文。这篇论文首次提出了 RAG 概念,并对该概念进行详细介绍和解释。
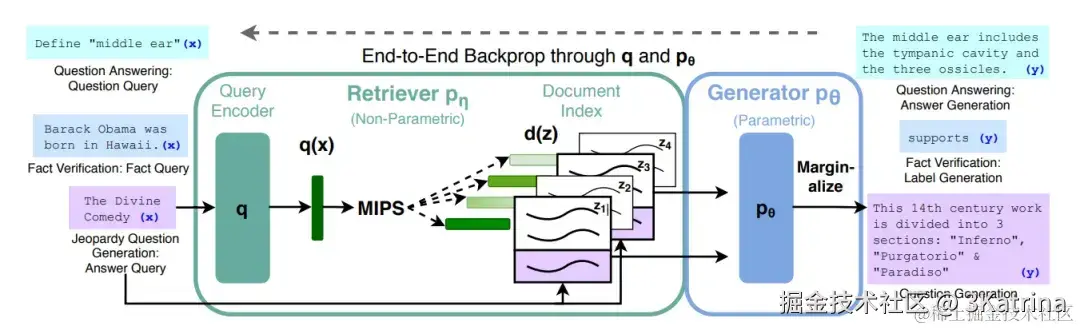 这样看是十分复杂的 但是本文 先不直接将里面的一些细枝末节给展开讲,这类偏理论的内容 很难讲好,听众可能也很难吸收
这样看是十分复杂的 但是本文 先不直接将里面的一些细枝末节给展开讲,这类偏理论的内容 很难讲好,听众可能也很难吸收
所以这篇文章以一个真实案例来贯穿全文,从研发的角度讲解 RAG 的全流程,相信能够给大家留下深刻的印象。
形象地理解RAG
这里我想先用AI生成的一个形象的例子帮大家先大概理解下RAG 从而构建起它在大家心中的印象。
大语言模型LLM就像一位天赋异禀但记性不太好的大学生,它的知识都来自于它 "上学时"(训练阶段)读过的书。一旦 "毕业",世界发生了新变化,它就不知道了。
而 RAG 就像是给这位大学生配了一位无所不知的图书管理员。
当大学生(LLM)遇到一个难题时(比如 "帮我总结一下新款小米SU7 的价格"),它之前没训练过新款小米su7的价格,所以自己可能不太清楚最新情况。这时,RAG 这位图书管理员就会立刻行动:
听懂问题:首先看用户想问什么,核心是获取新款小米SU7 的价格相关信息
跑向图书馆:然后,它以最快的速度跑进一个庞大的知识库(这个库可以是小米汽车官方发布资料、最新的汽车评测文章、行业分析报告等等)。精准查找:它在知识库里飞速查找与 "新款小米SU7" 最相关的资料,比如小米汽车的预售发布会内容、专业汽车媒体的试驾评测、官方公布的车型参数配置表等。从中筛选出关键信息--小米SU7的价格,递上小抄:最后,它把找到的最相关的几段资料递给我们的大学生,说:"嘿,这是你可能需要的资料,参考一下再回答吧!"
有了这些最新、最准确的 "小抄",大学生就能给出一个精彩、靠谱的答案了!
接下来我们就以研发的角度通过一个具体的案例进行讲解 , 帮助大家更深刻地理解RAG的全过程。
让我们来开始这段奇妙旅程吧!
检索的概念
检索就是从外部知识库中,精准找到和用户当前问题最相关的信息片段,相当于给大模型 "找参考书"。
检索可以分为两个过程:
1.知识库预处理(离线阶段)
把原始知识拆成小的文本片段,我们也称之为 chunk ;
将每个 chunk 转换成向量(Vector),存储到向量数据库。
2.实时检索(在线阶段)
用户提问
RAG把用户问题转换成向量;
在向量数据库中,用向量相似度算法找到和问题向量最匹配的 chunk
返回 Top-N 个最相关的 chunk 作为 "参考资料"。
简单科普:
向量(Vector),就是把文本信息(比如用户问题、知识库文档片段) 转换成的一串数字列表,核心作用是用数学方式衡量文本之间的「语义相似度」,让机器能精准找到和问题相关的资料。 对于两句话:
"小米 SU7 的续航里程是多少?"
"小米 SU7 满电情况下能跑多远?"
人类视角:一眼就知道这两个问题是同一个意思,都是在问 SU7 的续航能力。
机器视角:机器会逐字对比,发现两句话的用词差异很大 ------ 第一句有 "续航里程""多少",第二句有 "满电""跑多远",没有几个相同的词,于是判定这是两个完全不相关的问题。
那机器想要像人一样尽量理解这两句话的语义如何做呢?
所以就需要把这两个问题转换成向量
问题 1 "小米 SU7 的续航里程是多少?" → 向量 A:0.32, -0.15, 0.81, 0.09, ..., 0.27(一串数字)
问题 2 "小米 SU7 满电情况下能跑多远?" → 向量 B:0.31, -0.16, 0.80, 0.10, ..., 0.26(另一串数字)
这两串数字看起来差距是很小的 ------ 因为它们的语义是相同的。
案例
接下来让我用一个实际案例来 讲解检索的具体过程
首先需要有知识库,知识库一般都是很庞大的 由于这是一个DEMO 所以
在这个案例中,baijiahao.baidu.com/s?id=185375...
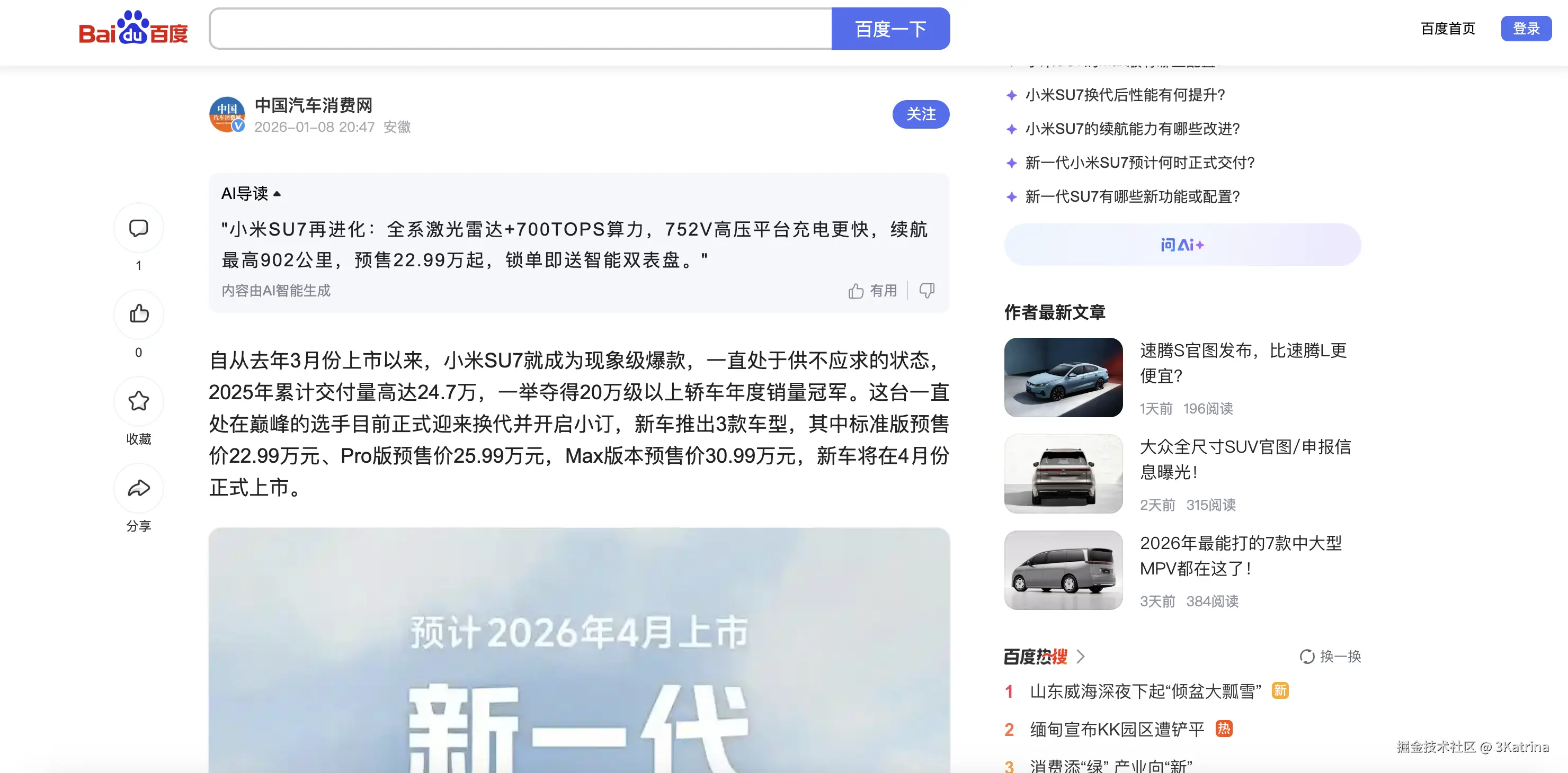 我们就把这段1200多字的文章当成知识库吧!
我们就把这段1200多字的文章当成知识库吧!
检索:知识库预处理
在预处理过程中,首先进行了分块处理: 将上面这段1200多个字的文章分成12块由部分内容组成的 chunk 数组

然后我们对 切割后的每个文章碎片(chunk)使用Embedding转化为向量
 可以清楚的看到每个 chunk 转换后的向量
可以清楚的看到每个 chunk 转换后的向量
 随后将其存入我们的向量数据库中:我用的是supabase这个向量数据库,可以很好地存储向量
随后将其存入我们的向量数据库中:我用的是supabase这个向量数据库,可以很好地存储向量
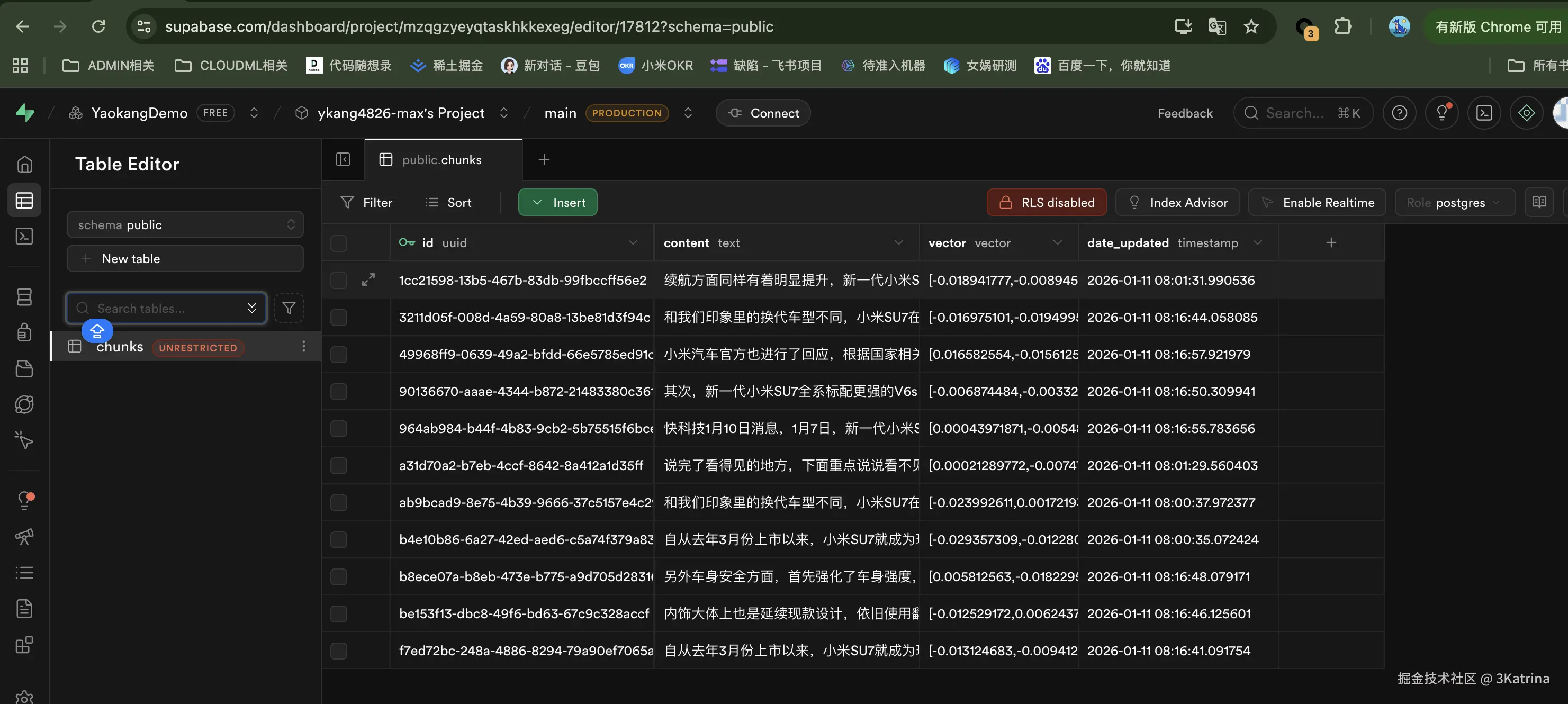 现在我们就模拟了 上面提到的 离线阶段:知识库预处理
现在我们就模拟了 上面提到的 离线阶段:知识库预处理
检索:在线提问阶段
第一个过程完成了,接下来让我来给大家展示下第二个过程 我们需要明确下这一步的目的: 在知识库的向量数据库中进行向量相似度算法,得到与用户prompt最相近的信息。
当用户提问时:

在得到用户输入的 prompt后 让我们 先将用户问题转换成向量
用户问题:"新款su7的续航怎么样" 这句话转换后的向量如下:
 转换后 我们就需要将用户转换后的向量 和 知识库向量进行比对 看看向量比对后返回的数据吧:
转换后 我们就需要将用户转换后的向量 和 知识库向量进行比对 看看向量比对后返回的数据吧:
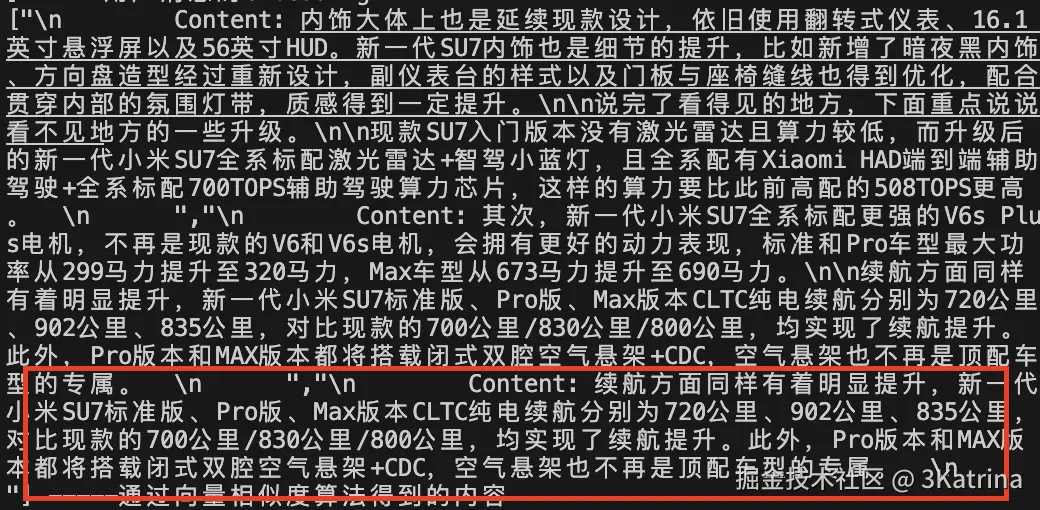
很明显:我们写的向量相似度算法还是挺靠谱的!在向量数据库中的众多 条数中找到和用户输入内容最相似前三条的内容了
这里也可以指定该向量相似度算法得到 前几条内容,完全可以根据人的需求制定,同样匹配的相似度也可以根据人的需求制定:给大家一个小巧思:什么业务场景下需要将相似度设置高一些?什么情况下需要将相似度设置低一些呢?
最后拿到比对之后 相似度的排序,我们就可以 返回 Top-N 个最相关的 Chunk 作为 "参考资料" ,我这个项目中就直接拿Top1的结果作为资料了哦
因此 检索过程就能够被很好地完成,整个链路还是不短的,让AI在此处做了个总结:
一、 离线知识库预处理阶段(提前完成) 文档分块(Chunking)将 1200 余字的小米 SU7 换代文章,切割成 12 个语义独立的文本片段(chunk) 向量转换(Embedding)对每个 chunk 分别使用 Embedding 模型,将文本转换成机器可计算的向量数据。 向量存储将所有 chunk 对应的向量存入 Supabase 向量数据库,完成知识库的初始化。 二、 在线实时检索阶段(用户提问时执行) 用户提问接收:获取用户问题:新款su7的续航怎么样。 问题向量转换:用和预处理阶段相同的 Embedding 模型,将用户问题转换成对应的向量。 向量相似度比对:在 Supabase 向量数据库中,通过向量相似度算法,计算问题向量与所有 chunk 向量的匹配度,筛选出相似度最高的 Top-N 个 chunk(本案例取 Top1)。 返回参考资料:将匹配度最高的 chunk 作为精准参考资料,提供给大模型生成回答。 整个流程的核心价值在于:让大模型无需预先训练小米 SU7 的专属数据,也能通过实时检索得到精准信息,避免胡编乱造。
增强
通过上面的步骤,我们此刻已经得到了 RAG 检索阶段 给我们的参考资料 那下面有了该参考资料 ,让我们看看增强阶段又是如何进行的呢?
增强阶段的核心作用
把检索到的相关 Chunk + 用户原始问题,整合成一个新的、更丰富的提示词(Prompt),传递给大模型。
执行步骤 Prompt 拼接:生成一个标准化的 Prompt 模板,格式通常是:
参考资料: {检索到的 Chunk 1} {检索到的 Chunk 2} ...
请根据参考资料,回答以下问题:{用户的原始问题} 要求:1. 必须基于参考资料回答;2. 不要编造信息;3. 语言简洁。 信息过滤与排序:对检索到的 Chunk 做过滤(去掉无关、重复的内容)和排序(把最相关的放在前面),避免给大模型传递冗余信息。
下面就是我在增强阶段具体的行为:
我叫AI帮我写了个提示词函数,将RAG检索到chunk和用户原本的提问信息进行结合,然后重新设置一个新的prompt,让LLM在工作时使用新的prompt。
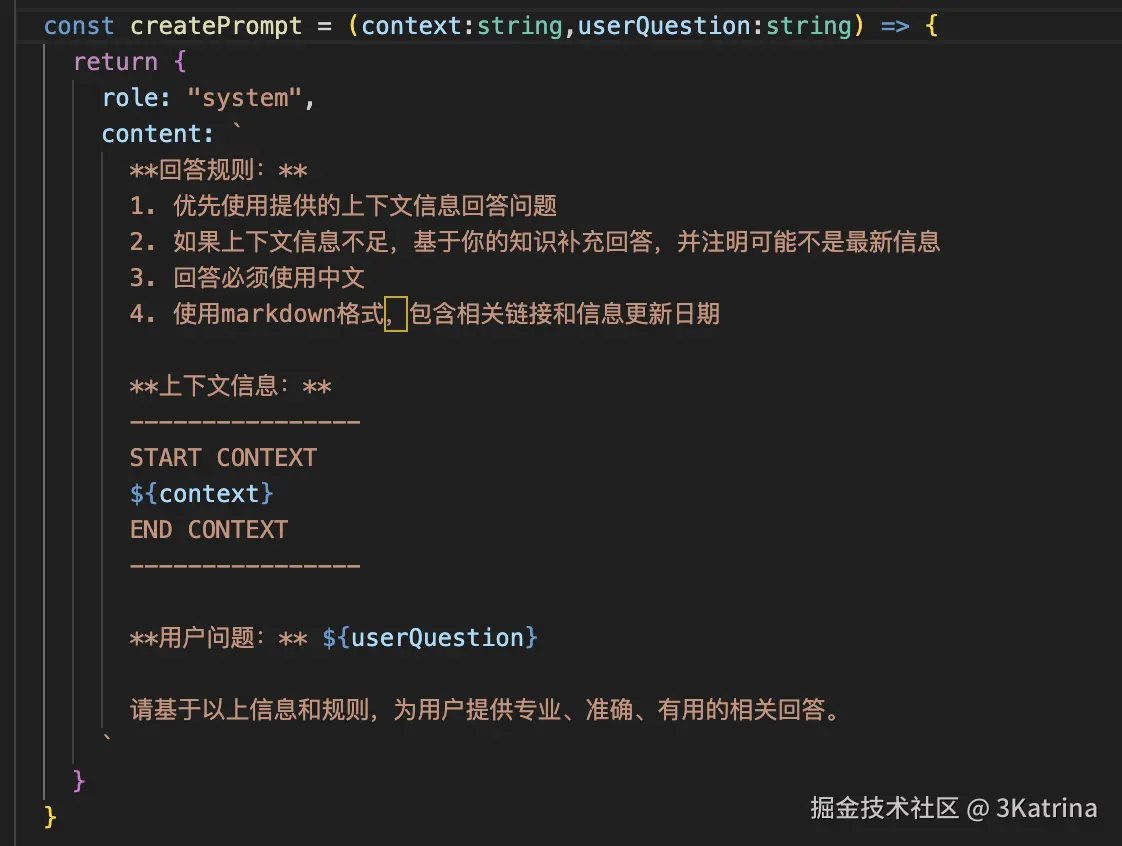
比如我问:"小米新款su7的续航怎么样?"
这个时候createPrompt返回的结果就是:
回答规则:
- 优先使用提供的上下文信息回答问题
- 如果上下文信息不足,基于你的知识补充回答,并注明可能不是最新信息
- 回答必须使用中文
- 使用markdown格式,包含相关链接和信息更新日期
上下文信息:
START CONTEXT ${续航方面同样有着明显提升,新一代小米SU7标准版、Pro版、Max版本CLTC纯电续航分别为720公里、902公里、835公里,对比现款的700公里/830公里/800公里,均实现了续航提升。此外,Pro版本和MAX版本都将搭载闭式双腔空气悬架+CDC,空气悬架也不再是顶配车型的专属。\n\n举报/反馈 \n ","\n } END CONTEXT
用户问题: ${小米新款su7的续航怎么样?}
请基于以上信息和规则,为用户提供专业、准确、有用的相关回答。
接着就是调用LLM,使用最新的 prmopt 了, 我这里用的是deepseek的模型
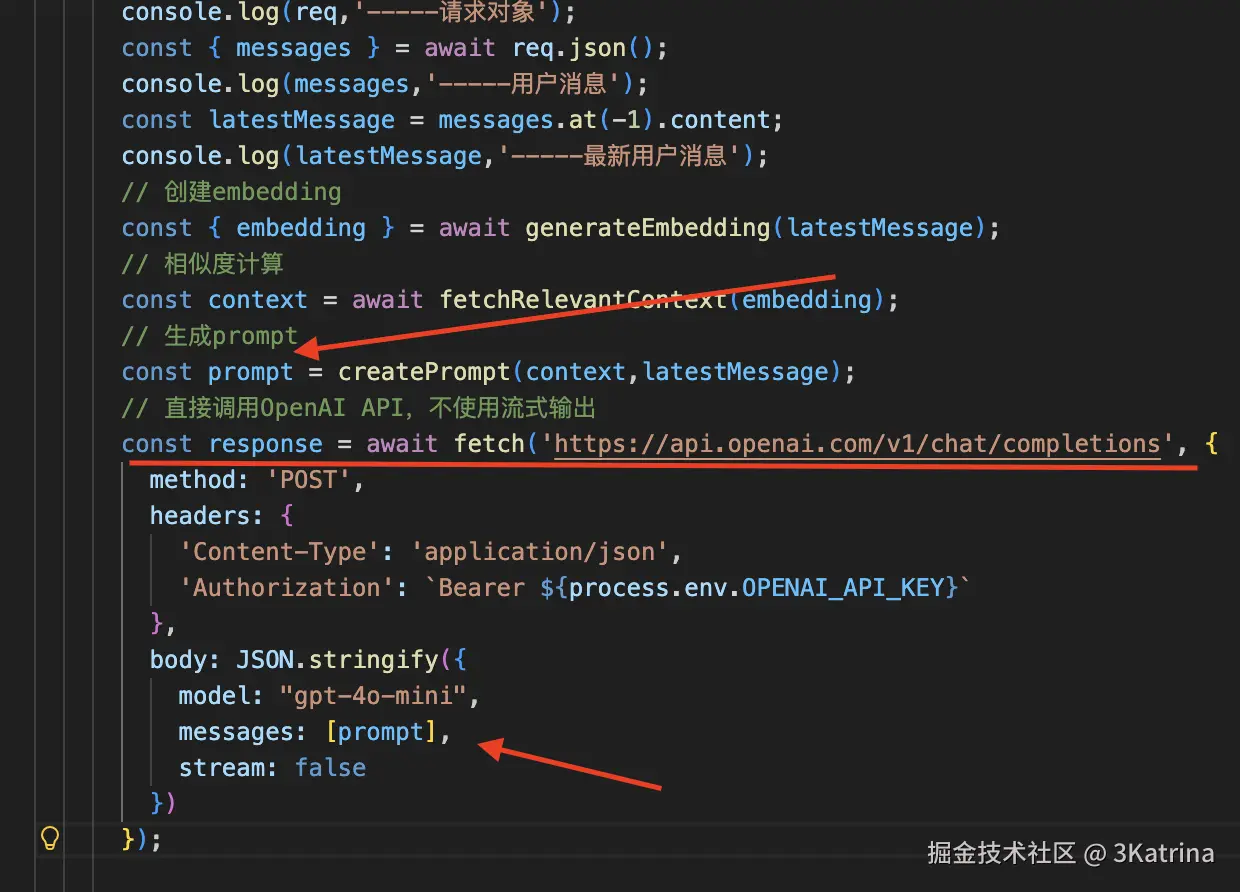 所以增强也是RAG工作很重要的一步
所以增强也是RAG工作很重要的一步
生成
生成就比较简单了! 大模型接收增强后的 Prompt,结合自身的语言理解能力,生成准确、有依据的回答。
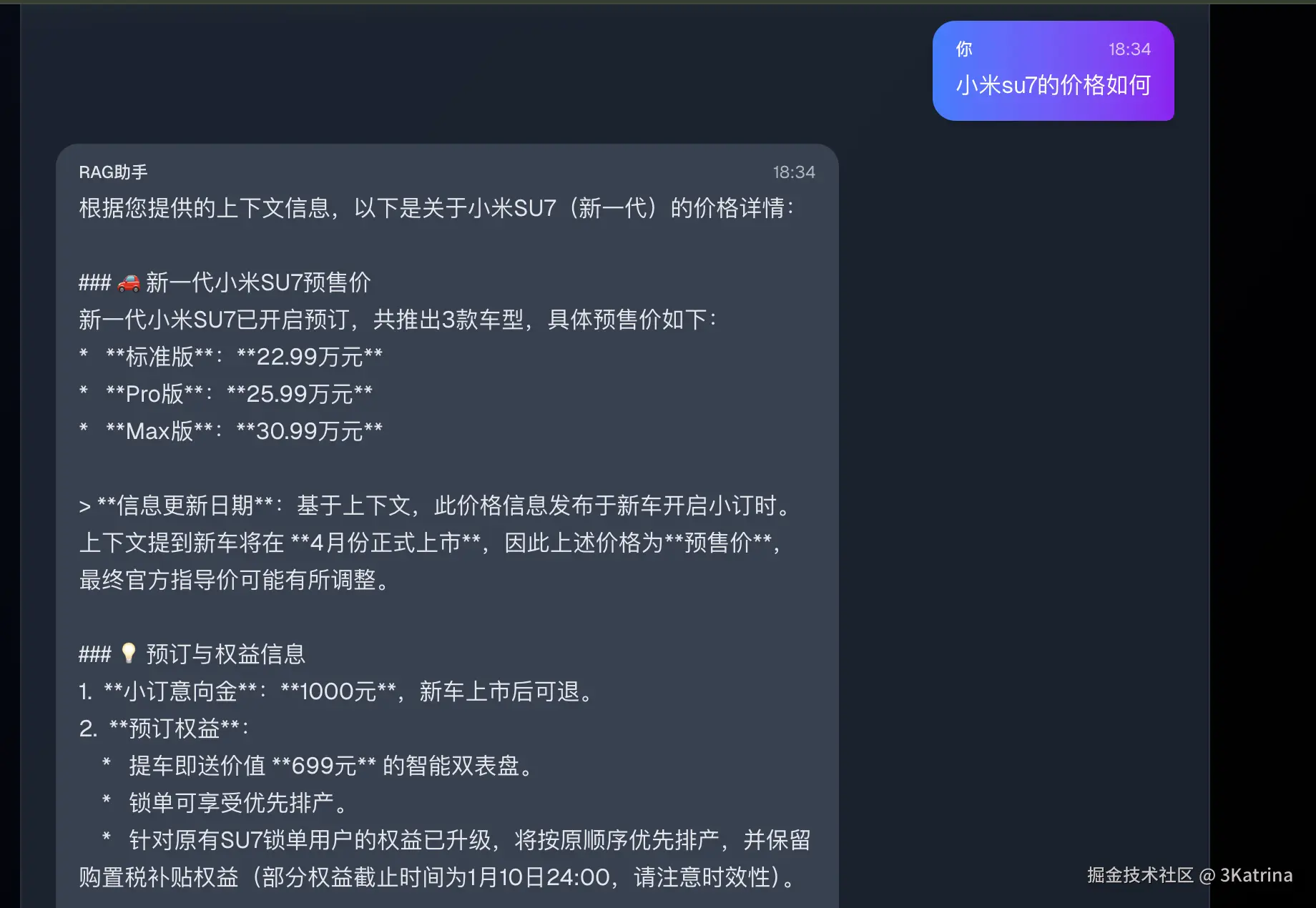
 现在大模型就具有了 获取实时信息的能力,
现在大模型就具有了 获取实时信息的能力,
关键特点
有据可依:回答基于外部知识库,不是模型 "凭空想象",准确性大幅提升; 个性化:可以结合不同的知识库,生成针对特定领域的回答(比如针对你开发的云平台,生成专属的技术支持回答)。
总结
通过上文一个具体案例的落地,我相信你对RAG也会有一个深刻的印象
在面试时 只需要清晰的表达RAG的相关概念,对于面试官提问的细节,只需要想起这个案例的一些实现,你就能牢牢掌握这个知识点