1.stack和queue的实现
由于stack和queue的功能在vector和list中都存在,因此可以通过封装这两个容器中的一个来实现stack和queue,这种实现出的容器也叫容器适配器.
stack
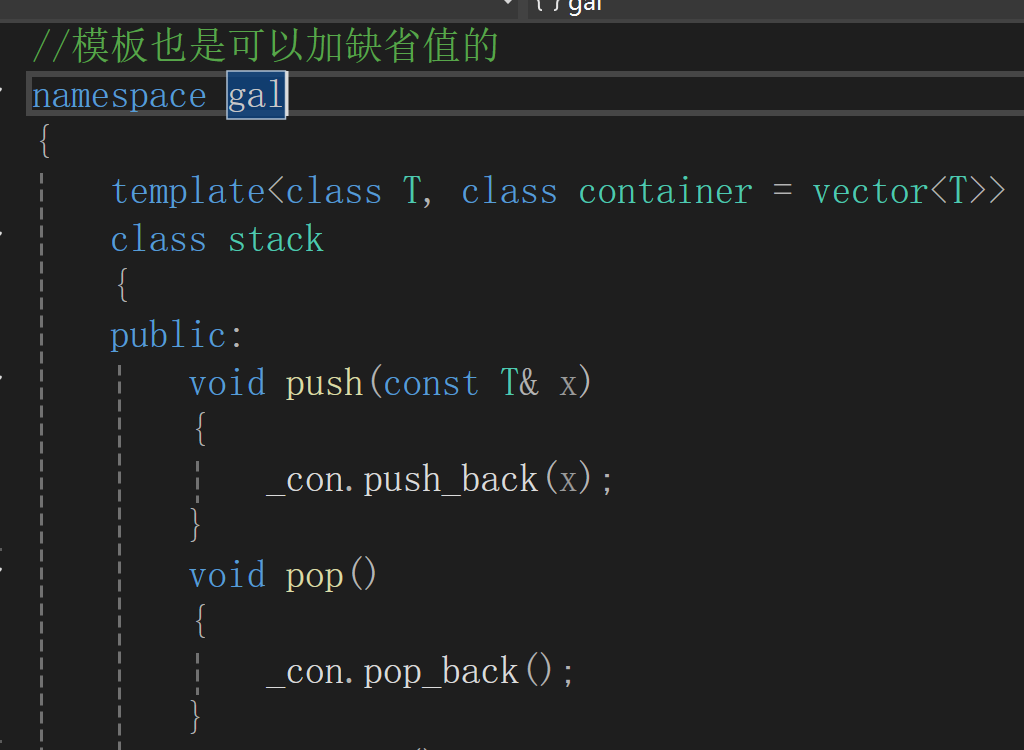
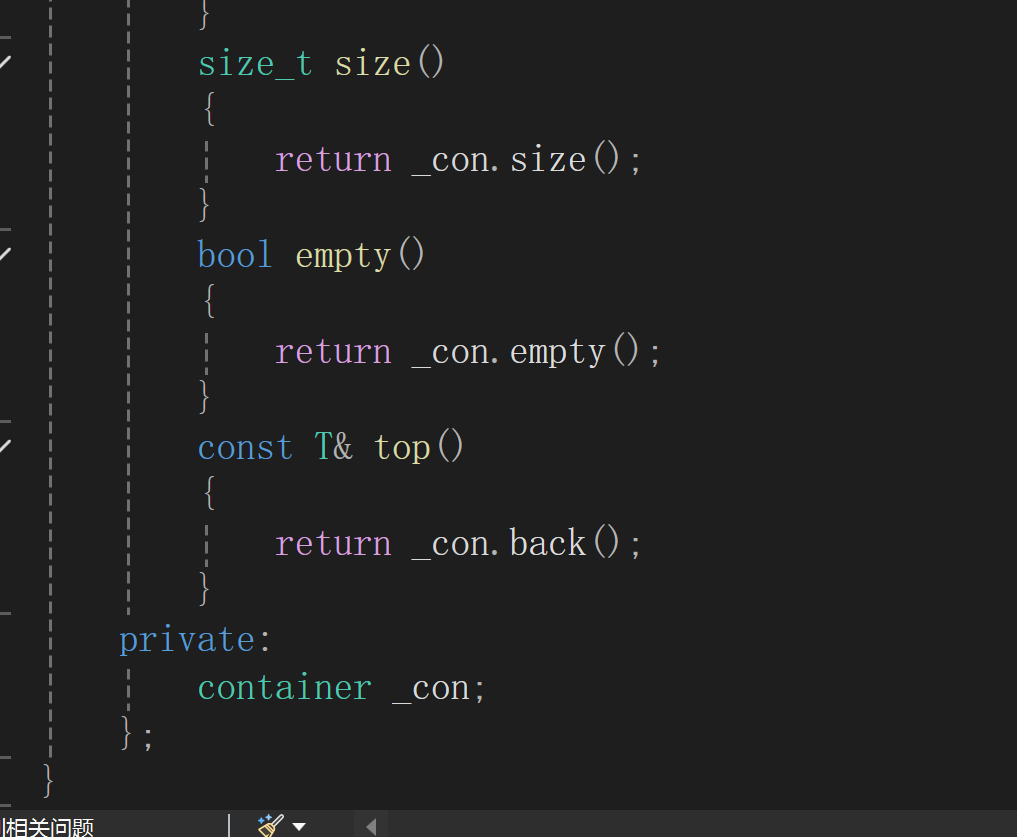
使用的函数必须是要确定是container中有的,因为由于按需实例化的机制,编译器是不会识别也无法识别出container中是否存在该调用函数的,是等该类已经被调用后才分析这些函数是否存在的.
且类模板内部的成员函数也是会按需实例化的,即不调用是不会实例化的.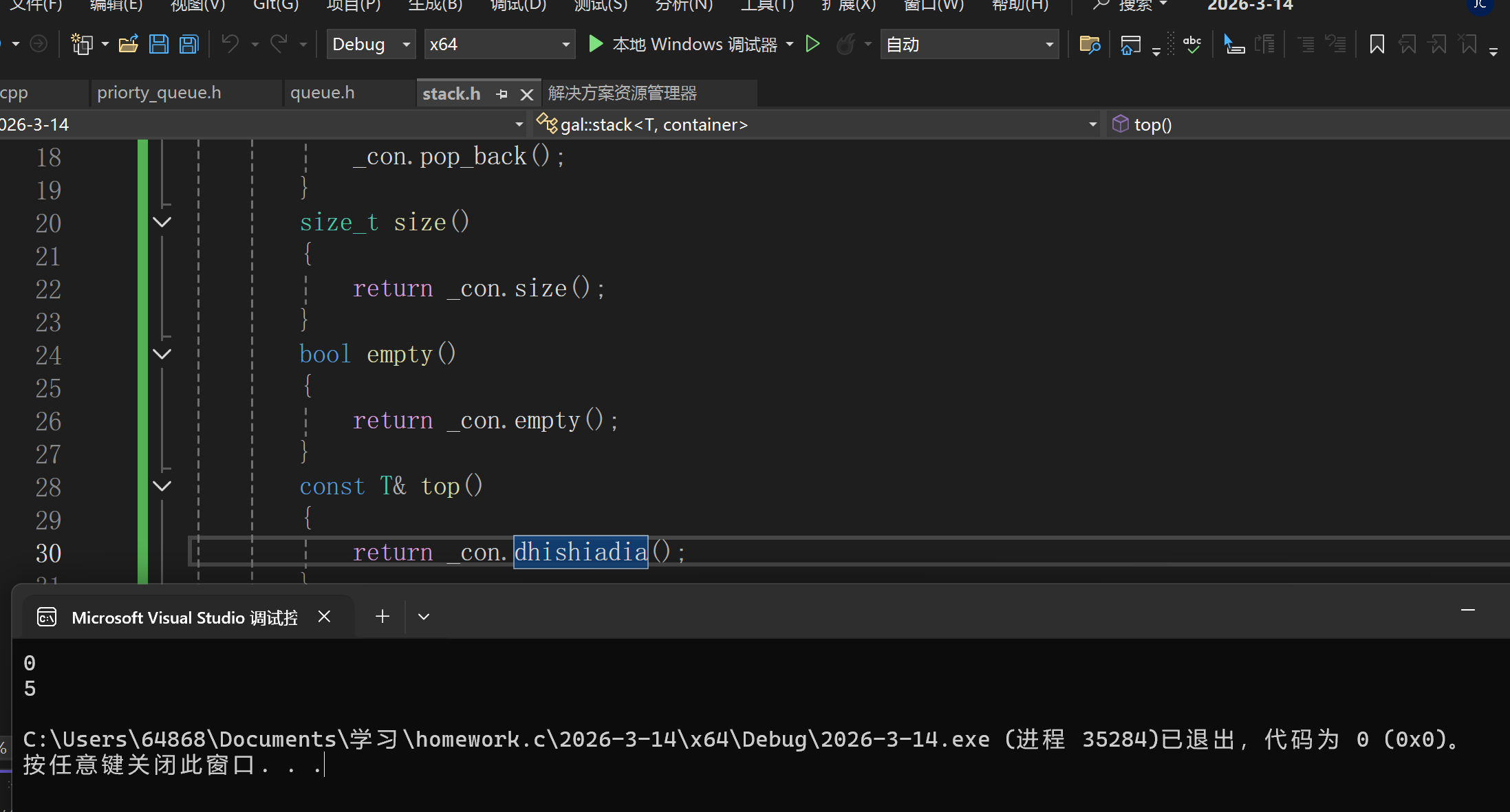
如此处,top中的函数已经是完全不存在的,但由于没用调用该函数(该类在main函数中是有调用的)
因此不会error.
推荐以后将自己的头文件放在using namespace std;的下面,以确保自己头文件中的std内容能正常展开.
queue

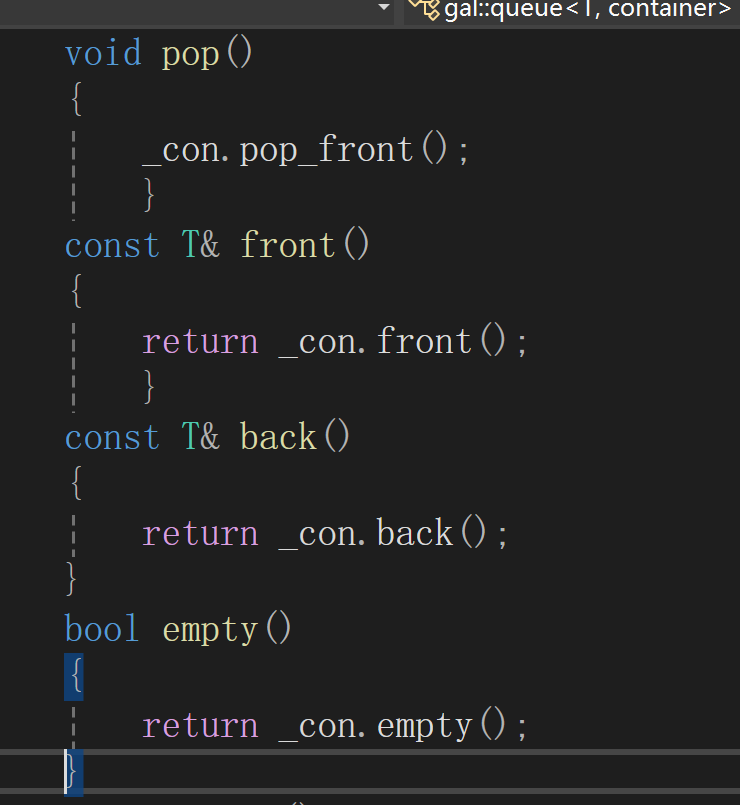
queue和stack是用其他容器改装来的,因此没有自己的迭代器.
2.首先来总结一下vector和list之间优缺点.
|----|----------------------|--------------------------|
| | vector | lis |
| 优点 | 尾插头插效率高,支持O(1)下标随机访问 | 按需申请空间,减少了扩容造成的效率下滑和空间浪费 |
| | 空间利用率高同时缓存利用率高 | 任意位置的插入删除都是O(1) |
| 缺点 | 空间扩容使造成的效率下滑和可能会空间浪费 | 不支持下标的随机访问 |
| | 头/中间位置的插入删除效率低 | 空间不连续,缓存利用率低 |
可以发现二者的优缺点是互补的,因此最好要综合利用.
3.deque
(1)物理空间结构: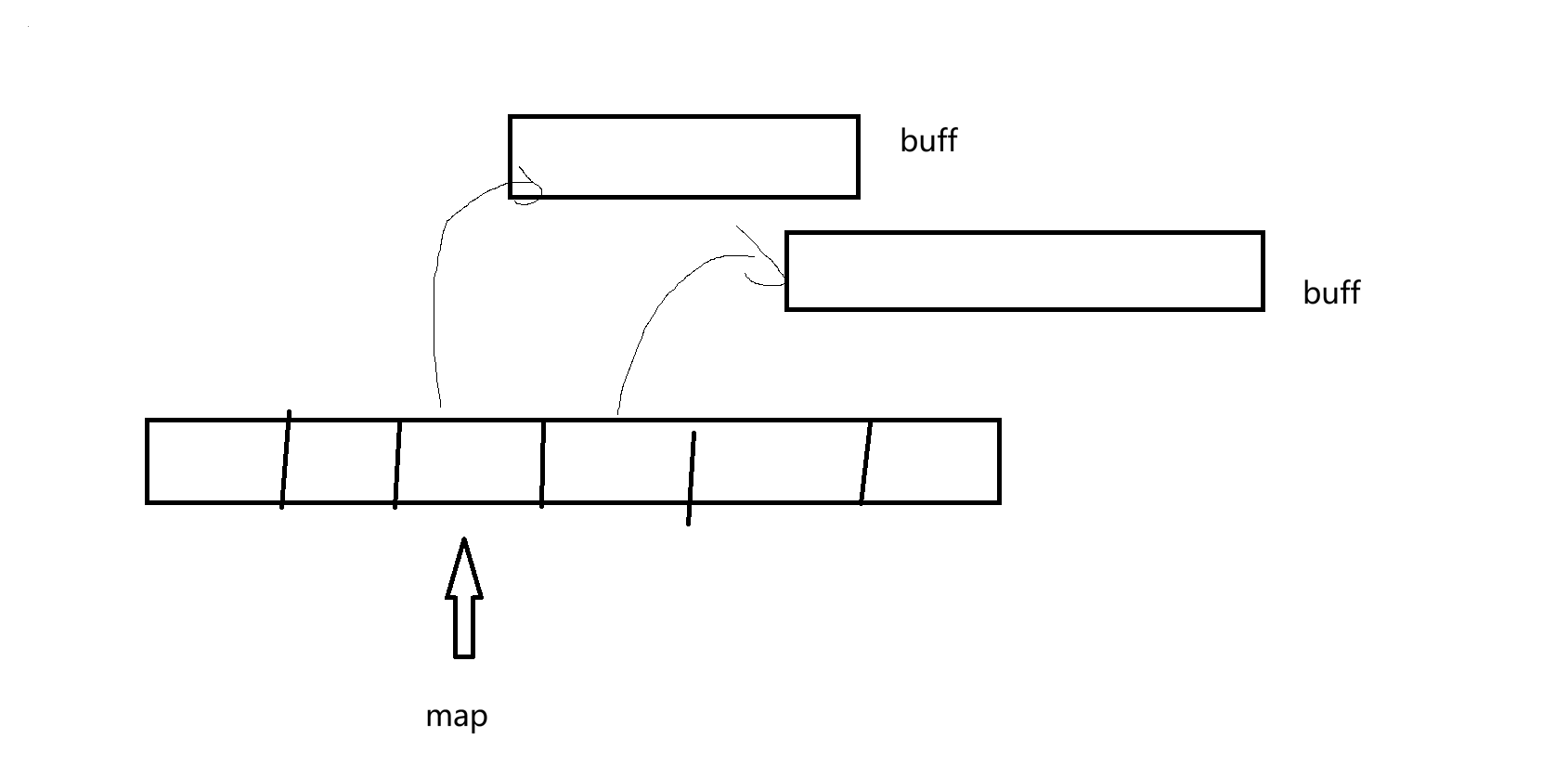
map是一个指针数组,里面的每一个指针指向一个固定空间的数组buff(本质就是一个二维数组)
(2)deque的迭代器
由四个指针封装的类构成(cur,first,last,node)
cur是指向一块buff空间的第一个元素的空间,first是指向一块buff空间的起始地址空间,last是指向buff结束地址的下一个空间.node是指向map中的一个空间(因此只有这个是二级指针)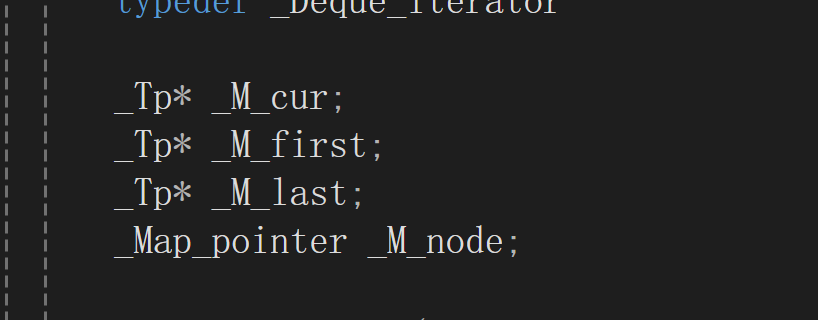
Map_pointer就是二级指针.
(3)deque的成员变量
由两个迭代器start,finsih,一个T**的map数组和一个size_t 的size.
map储存指向buff的指针,start指向map的第一个元素的地址,finish指向map的最后一个元素的地址.
size记录总元素个数.
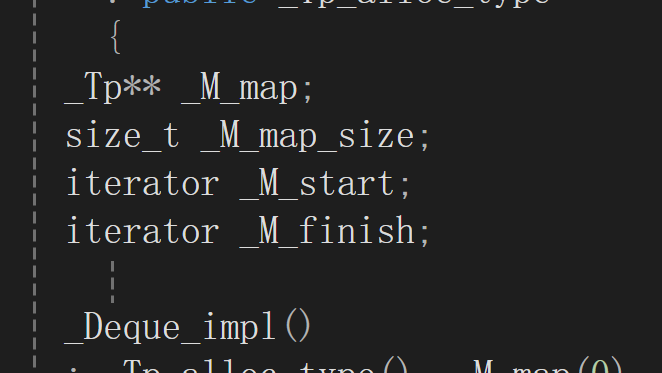
start中的cur指向第一个指针指向的buff的第一个数据,同时node指向指针数组的一个,last指向第一个指针指向的buff的最后一个空间的地址,first指向第一个指针指向的buff的第一个空间的地址.
finsih中的cur指向最后一个指针指向的buff的第一个数据,同时node指向指针数组的一个,last指向最后一个指针指向的buff的最后一个空间的地址,first指向最后一个指针指向的buff的第一个空间的地址.
(4)deque的遍历
首先用begin()和end()得到首尾的迭代器,然后从start中node指向的buff开始,从cur开始解引用然后++直到遇到last就结束.然后让node++进行迭代器的更新直到遍历完end()的空间.
对++的解释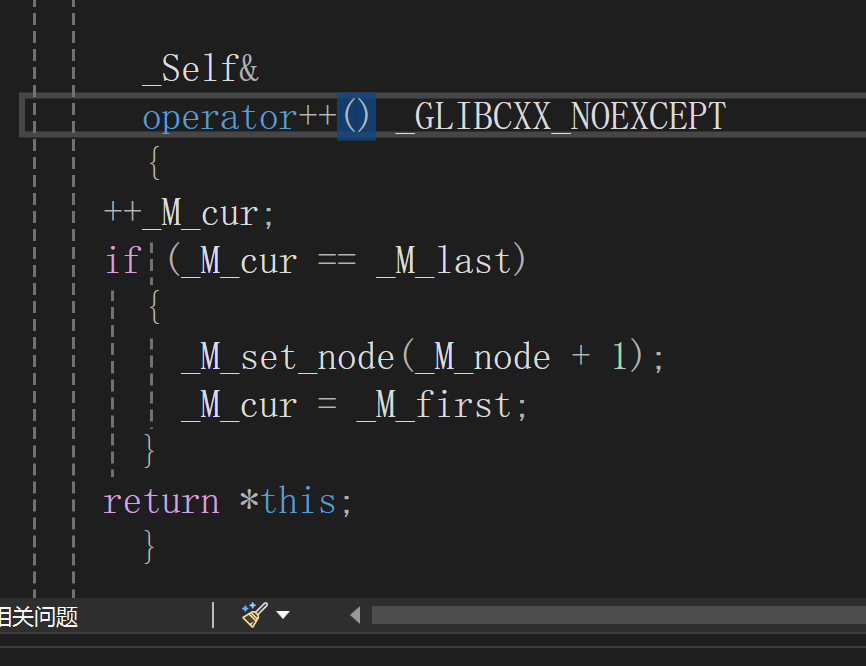
对cur++,如果cur==last就更新移动到下一个buff数组中.
对尾插的理解,当最后的buff满了时就开辟新空间然后更新finish迭代器即可.
对头插的理解,第一个buff满的时侯就在前面开一块新空间然后更新start迭代器即可.需要注意的是cur要从last的前一个数据开始存数据然后不断--来保证数据的正确排序.
对与\[\]重载的理解,设要解引用下标为i处的数据,每个buff大小为N,第一排空的空间数为M,有解引用的位置:
(1)N > M,解引用0M即可.
(2)N < M,设第x个buff中的第y个数据.有x = (i + M)/N,y = (i + M)%N.解引用xy即可.
总结deque的优缺点.
|----|-----------------------|
| | deque |
| 优点 | 头插尾插效率高,扩容次数少,缓存利用率优秀 |
| | 下标访问效率也可以 |
| 缺点 | 中间插入的效率很差 |
下面比较一下list,deque,vector的排序效率.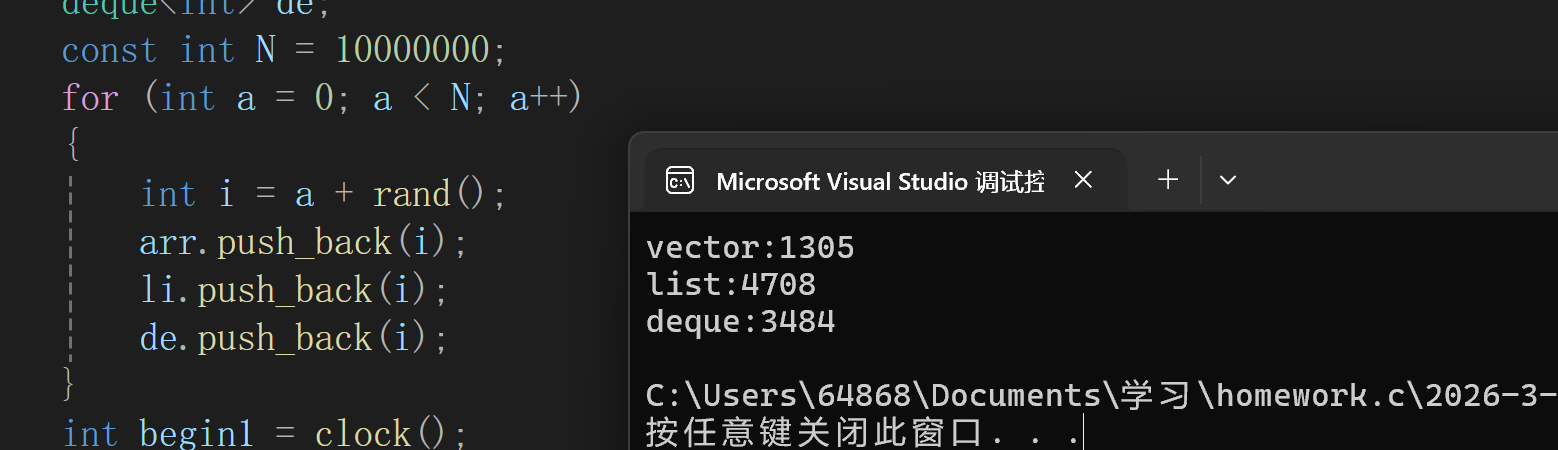
在realese环境下,少重复数据时排int类型vector有着遥遥领先的强度,deque比list好一点,list差的原因核心还是在缓存利用率低.deque不如vector在于\[\]更复杂.
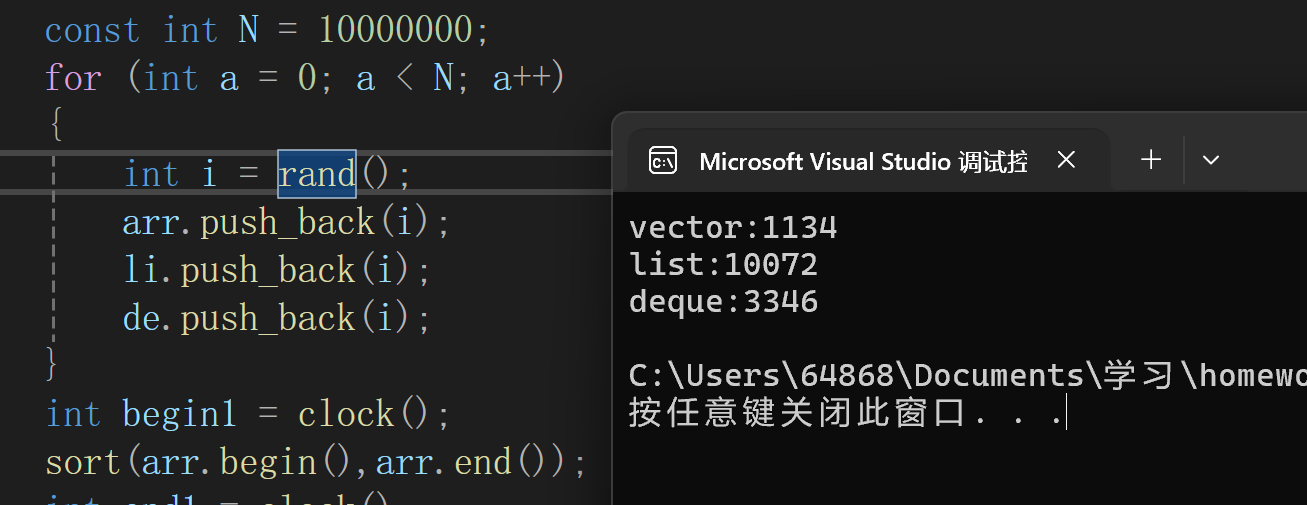
多重复时list的效率就大幅下降了,另外两个影响不大.
(sort需要\[\]重载和随机迭代器,因此list只能自己带sort)
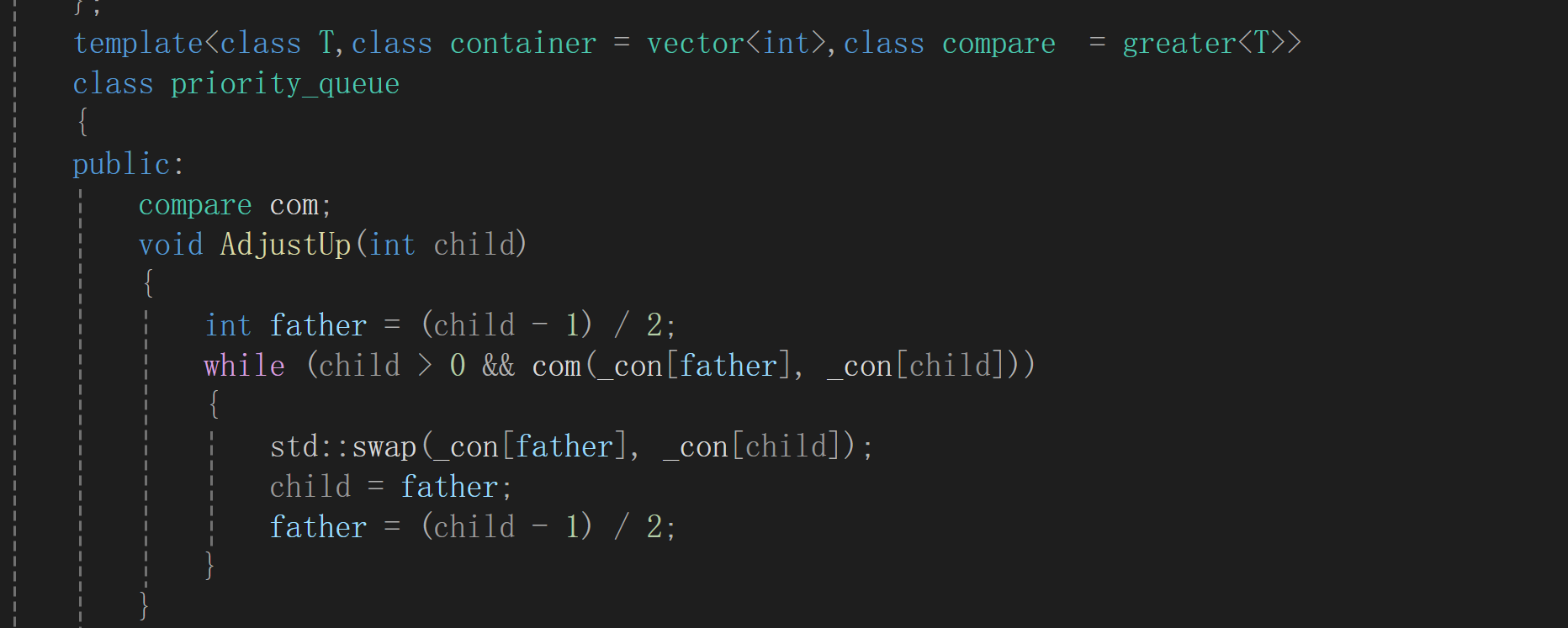
4.priority_queue
本质就是堆
实现:
成员变量
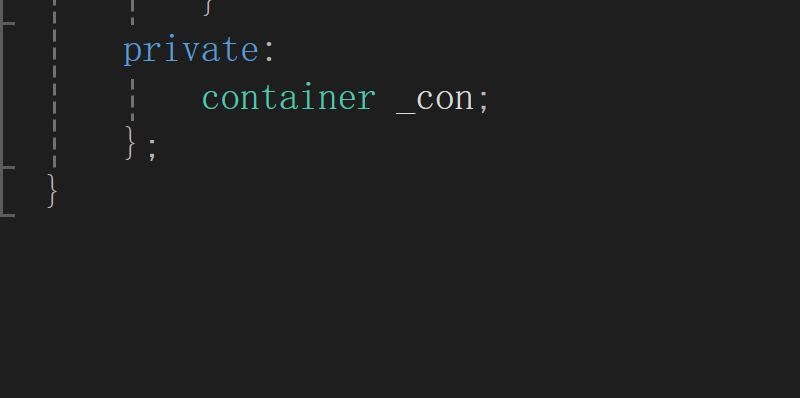
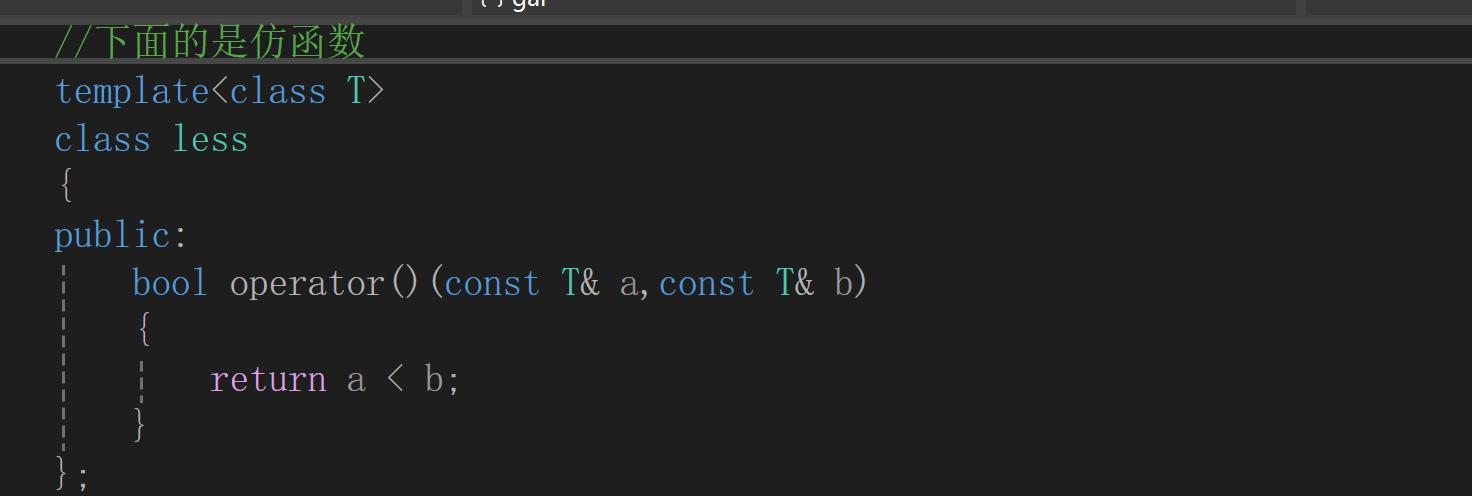
仿函数:建小堆
建大堆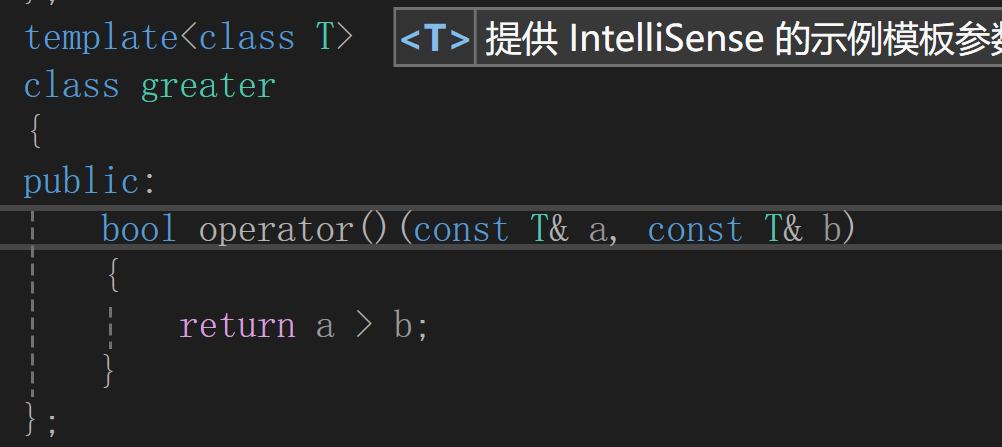
AdjustUp
push和top

AdjustDown

pop,size,empty
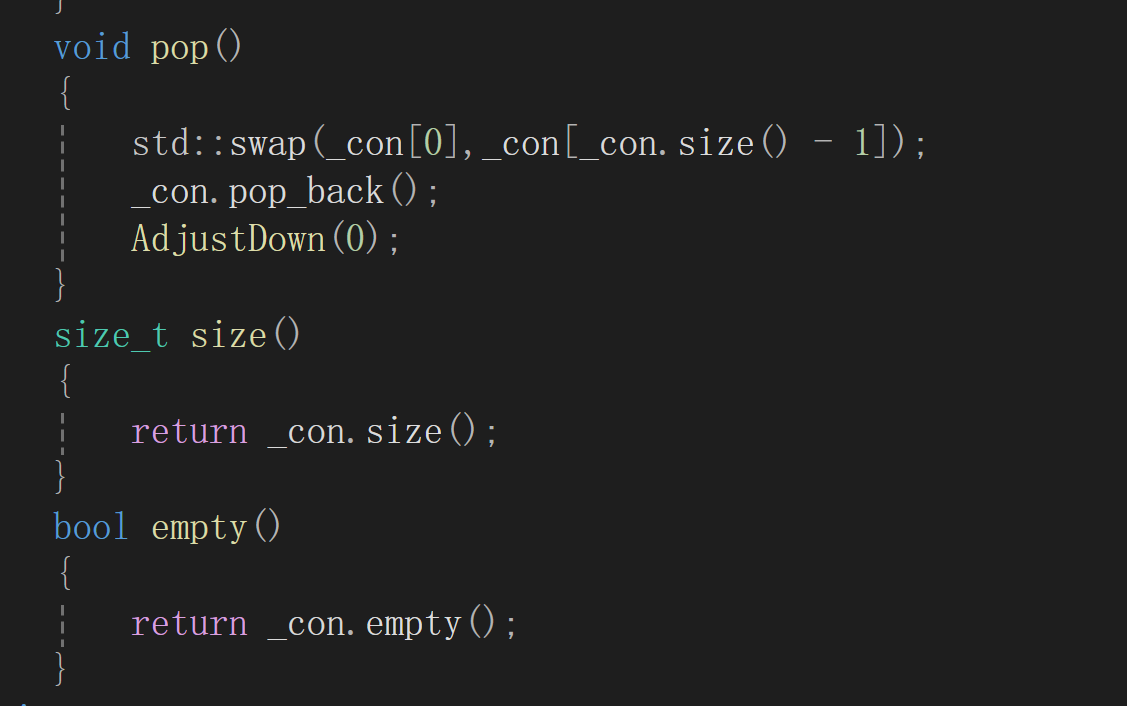
c++中的堆是用容器适配器实现的,要注意的是容器适配器无法调试(调试下会进入内部容器的代码中)如上面的代码使用vector实现的,调是会进入到vector的代码中.
点了一下push的调试进入vector的源代码中了.
下面对仿函数进行介绍
定义:本质是一个类(是一个空类),只重载了函数调用中的()
例子: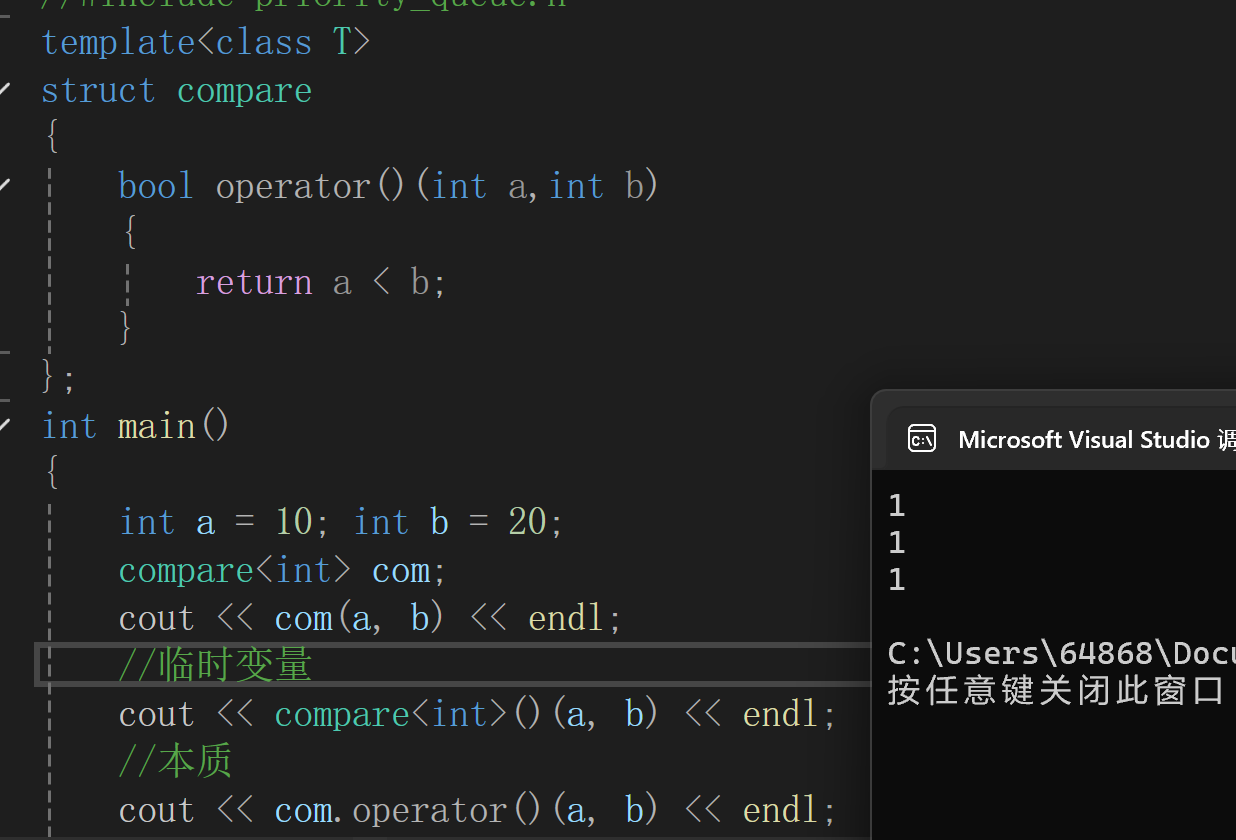
因此仿函数只是看的像函数,本质只是类的成员函数的调用.

此处就传了一个仿函数的类型,在内部创建了一个仿函数的变量,然后回调变量中的重载.
堆中默认less<T>(内部是小于号)为大堆,greater<T>(内部是大于号)为小堆.原因是堆中都是father在前,child在后进行比较.
给函数传仿函数时传的是变量less<T>().
给模板传时传的是类型less<int>.(在内部再创建的变量)
补充:c++库中的一些函数
sort.heap():两迭代器范围,内部是个堆才能使用,不然判错.
is.heap():判断是否为堆
make.heap():建堆
push.heap():两迭代器的范围,进行向上调整算法
pop.heap():两迭代器的范围,进行向下调整算法
支持随机迭代器且底层是连续空间的容器所能用的且以迭代器范围为参的.常规数组的指针范围也是成立的.
仿函数使用于比较大小的,所以可以用起来充当类类型的</>重载.
例子:
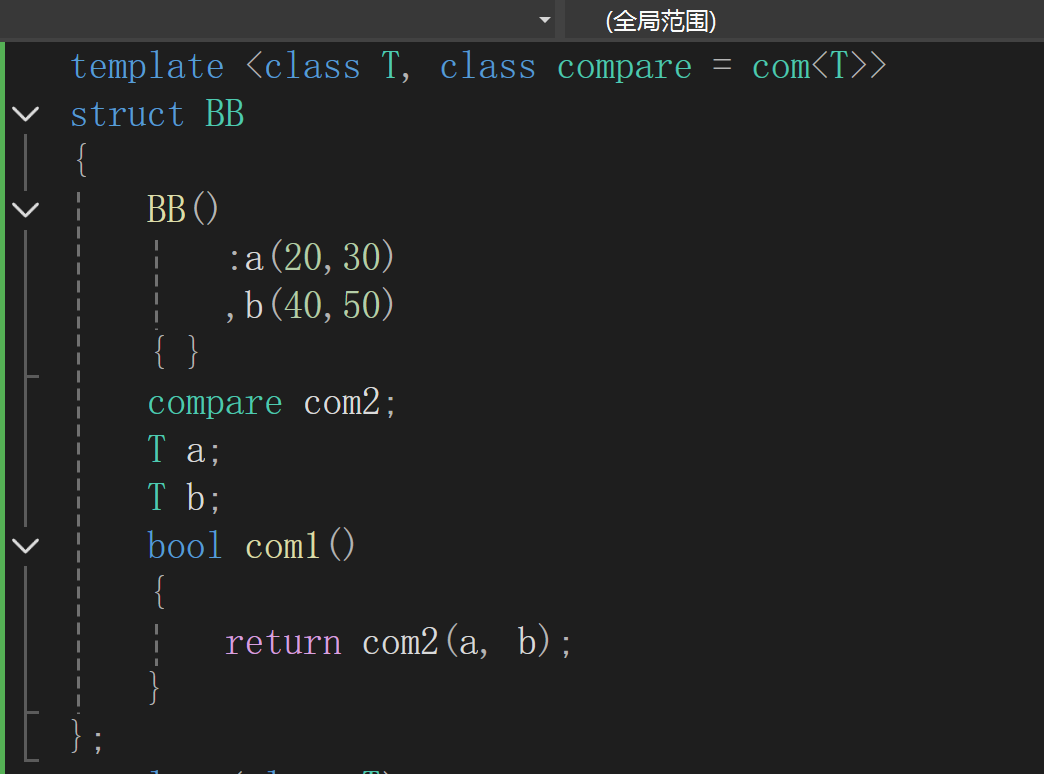

通过com来实现了比较的功能.但是上面的例子是涉及到类内部代码的,且效果比不过直接重载的效率.
仿函数的核心用途还是在于修改比较效果.例将>的情况改为<等.
实用在当现有的比较情况不如预期时:
例一个内部有>和<重载的模板类,由于储存对象的改变比较价值不同了(如储存的是指针,比较时也用的指针的值,但是我们想要的是用指针指向的值来进行比较,此时我们就可以自己设计一个仿函数来修改比较结果)
例: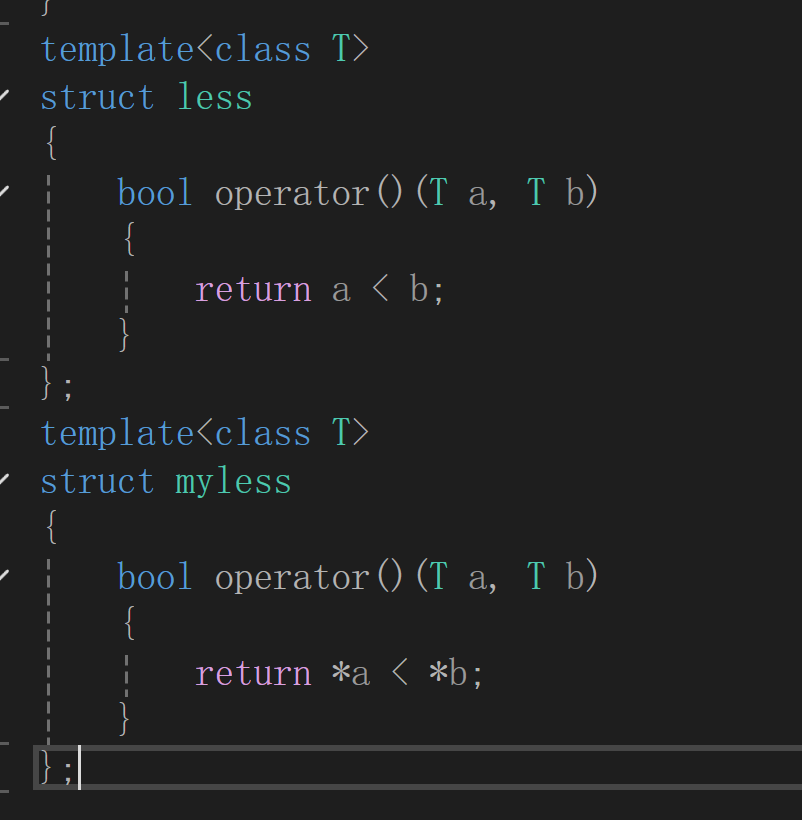
上面是编译器默认的仿函数,用指针的地址值来比较.下面是自己写的,用解引用的值进行比较.
通过传我们自己的反函数就可以实现比较价值的修改.