性能优化
Cocos Creator 性能优化需从 渲染 、逻辑 、资源 、内存 四大核心维度入手,覆盖从开发配置到上线调优的全流程。
一、渲染性能优化(最核心,直接影响帧率)
1.降低Draw Call
在游戏开发中,DrawCall 作为一个非常重要的性能指标,直接影响游戏的整体性能表现。
Draw call 就是 CPU 调用图形 API,比如 OpenGL,命令 GPU 进行图形绘制。
一次 Draw call 就代表一次图形绘制命令,由于 Draw call 带来的 CPU 及 GPU 的渲染状态切换 消耗,往往需要通过批次合并来降低 Draw call 的调用次数。
批次合并的本质就是在一帧的渲染过程中,保证连续节点的渲染状态一致,将尽可能多的节点数据合并一次性提交,从而减少绘图指令的调用次数,降低图形 API 调用带来的性能消耗,同时也可以避免 GPU 进行频繁的渲染状态切换。
1.1 静态合图
(1)在资源层面进行散图合并,保证相邻的节点使用的纹理都是同一张贴图,因为同一张图集的纹理状态都是一致的,所以能够达到渲染批次合并对纹理状态的要求。
(2)合并图集,cocos creator提供自动图集功能,或者使用第三方打包图集的工具,比如:TexturePacker 等。
划分图集最好可以尊选以下原则:
--- 由于不同平台对纹理尺寸有限制,最大尺寸最好控制在 2048 2048 以内。
-- 目前的图集解析已经去掉了大小必须是2的N次方限制了
--- 为了避免 UI 界面打开时图集资源过大导致加载缓慢的问题,通常将单个 UI 界面所使用的图片资源放入一个文件夹为该文件夹创建自动图集,即可保证同一界面使用的纹理图片资源一致。如果静态合图很大,但当前场景实际用到的只是其中很小一部分散图,则也可能造成*浪费,导致游戏加载时间延长和内存占用增多。
--- 游戏开发中常常将使用率频繁资源单独提取到一个common目录(通用资源)作为一张图集资源。(3) 对与Label组件,为了保证所有的 Label 节点使用相同的纹理,如果可以设计成BMFont,可以做到合批。通常会使用 BMFont 将要使用的 UI 文字提前进行打包,并使用引擎的自动图集与散图一起合并进一张大的纹理,即可与其他相邻的 Sprite 节点进行批次合并。
1.2 动态合图
静态合图除了占用空间的问题,静态合图的局限性还常常体现在动态文本的渲染过程,如 Label 组件在使用系统文本时,文本贴图是依据文本内容通过 Canvas 绘制动态生成,不能提前进行图集打包。
引擎也提供了动态合图的功能。在运行时,引擎通过将散图添加到动态图集中,来保证节点使用的纹理一致。由于动态图集使用的是默认纹理状态,所以只有当散图的纹理状态与动态图集的状态一致,才可参与到引擎的动态合图中。比如Label 组件目前提供三种 Cache Mode:NONE、BITMAP 和 CHAR。
- NONE 模式即 Label 的整个文本内容会进行一次绘制,并进行提交,但是并不参与动态合图。
- BITMAP 模式即 Label 的整个文本内容会进行一次绘制,并加入到动态图集中,以便进行批次合并。
- CHAR 模式即 Label 会将文本内容进行拆分,单个字符进行绘制,并将字符缓存到一张单独的字符图集中,下次遇到相同字符不再重新绘制。
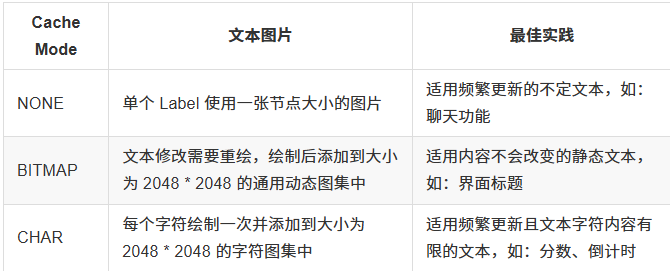
目前引擎的动态图集主要有两种,一种是为散图及使用 BITMAP 模式的文本提供的动态图集,最大数量为 5 张,尺寸为 2048 * 2048。
另外一种是为使用 CHAR 模式的文本提供的字符图集,单个场景只有一张,尺寸为 2048 * 2048,这两种动态图集在切换场景时会进行清理释放。由于动态图集空间有限,因此需要最佳化的利用。
动态合图开启:
Cocos Creator 在 v2.0 中加入了 动态合图的功能,它能在项目运行时动态的将贴图合并到一张大贴图中。当渲染一张贴图的时候,动态合图系统会自动检测这张贴图是否已经被加入到了动态合图系统,如果没有,并且此贴图又符合动态合图的条件,就会将此贴图合并到动态合图系统生成的大贴图中。
贴图限制
动态合图系统限制了能够进行合图的贴图大小,只有贴图宽高都小于 512 的贴图才可以进入到动态合图系统。用户可以根据需求修改这个限制:
2 影响合批操作
合批(动态合批 / 静态合批)的核心前提是 "渲染状态完全一致",任何破坏该一致性的操作都会导致合批失败。
材质是合批的 "基础通行证",只要两个物体的材质或着色器状态不同,100% 无法合批。
(1) 调整节点的透明度(opacity)
透明度会影响 GPU 的 "混合计算"(如 SRC_ALPHA * 源色 + DST_ALPHA * 目标色),不同透明度需要不同的混合参数,无法合批。
(2) 调整节点的混合模式(BlendMode)
混合模式定义了 "当前像素如何与已渲染像素混合",不同模式的 GPU 计算逻辑完全不同,必须拆批。
(3) 遮罩(Mask)影响
Mask 会开启 "模板测试(Stencil Test)",不同 Mask 的模板值(Stencil Value)不同,GPU 需分开处理裁剪区域。
(4) 抗锯齿(AntiAlias)状态
抗锯齿会增加 GPU 的采样计算,开关状态不同会导致渲染指令差异,无法合批。
(5) Z 轴排序或深度测试
--- 透明物体与不透明物体混合排列(透明物体需 "从后往前" 渲染,不透明物体 "从前往后",顺序冲突);
--- 部分物体开启 node.zIndex 强制排序,破坏合批的默认顺序。
合批要求物体按 "同一渲染顺序" 处理,Z 轴或 zIndex 差异会导致排序冲突,必须拆批以保证渲染正确。
二、逻辑代码优化(减少 CPU 占用,避免主线程阻塞)
CPU 主要处理游戏逻辑、脚本计算、对象管理,优化目标是 减少循环耗时、避免冗余计算、降低 GC(垃圾回收)频率。
1. 减少冗余计算与循环开销
(1)避免帧内重复计算
场景中不变的值(如屏幕宽高 cc.winSize、物体初始位置)缓存到变量,而非每帧在 update 中重复获取,复杂计算(如向量运算、距离判断)若结果不变,缓存到变量,避免每帧重复计算。或者可以建个N帧执行一次。
(2)优化循环逻辑
避免在 update 中遍历大量数组(如场景中所有敌人),若需遍历,优先用 for 循环(比 forEach 性能高),且缓存数组长度
javascript
// 坏:forEach 性能低,且每帧获取数组长度
update(dt) {
this.enemyList.forEach(enemy => { /* ... */ });
}
// 好:for 循环 + 缓存长度
update(dt) {
const len = this.enemyList.length; // 缓存长度
for (let i = 0; i < len; i++) {
const enemy = this.enemyList[i];
/* ... */
}
}动态数组(如 cc.NodePool 管理的对象)优先用 "对象池" 复用,避免每帧 push/pop 操作(数组扩容 / 缩容会触发 GC)。
2. 降低 GC 频率(垃圾回收会暂停主线程,导致卡顿)
(1)避免频繁创建临时对象
临时变量(如 cc.Vec2、cc.Color)缓存到成员变量,而非每帧创建。
javascript
// 坏:每帧创建新 Vec2,触发 GC
update(dt) {
const dir = new cc.Vec2(this.x, this.y); // 临时对象
}
// 好:缓存到成员变量,复用
onLoad() {
this.tempDir = new cc.Vec2(); // 初始化时创建
}
update(dt) {
this.tempDir.set(this.x, this.y); // 复用对象,不触发 GC
}字符串拼接用 cc.js.format 替代 +(+ 会创建临时字符串,cc.js.format 更高效)
javascript
// 坏:字符串拼接创建临时对象
const text = "分数:" + this.score;
// 好:复用格式化方法
const text = cc.js.format("分数:%d", this.score);(2)合理使用对象池(NodePool)
适用场景:频繁创建 / 销毁的物体(如子弹、敌人、粒子效果),用 NodePool 复用对象,避免每帧 cc.instantiate(创建对象)和 node.destroy(销毁对象)
3. 优化定时器与事件
(1)避免滥用 setTimeout/setInterval
优先用 Cocos 内置的 this.schedule(支持暂停 / 恢复,且与节点生命周期绑定,节点销毁时自动取消):
javascript
// 好:使用 schedule,节点销毁时自动停止
onLoad() {
// 每 0.5 秒执行一次,执行 10 次后停止
this.schedule(() => { /* ... */ }, 0.5, 9);
}
// 坏:setInterval 需手动清除,否则节点销毁后仍执行,导致内存泄漏
onLoad() {
this.timer = setInterval(() => { /* ... */ }, 500);
}
onDestroy() {
clearInterval(this.timer); // 需手动清除,容易遗漏
}(2)事件监听及时取消
node.on 绑定的事件,在 onDestroy 中用 node.off 取消,避免内存泄漏(如监听全局事件 cc.systemEvent.on,节点销毁后仍触发回调)。
三、资源优化(减少包体大小,降低加载耗时)
资源(纹理、模型 、音频、动画)是包体和内存的主要占用者,优化目标是 "小而精":按需加载、压缩体积、复用资源。
1. 纹理资源优化(占比最高,优先处理)
(1) 控制纹理分辨率
- UI 纹理:手机端 UI 图标分辨率 不超过 256x256,背景图不超过 1024x1024(根据屏幕分辨率适配,避免过度放大导致模糊)。
- 场景纹理:地面、建筑纹理分辨率不超过 2048x2048,且优先用 "重复纹理"(如地砖纹理设置 Wrap Mode 为 Repeat,1 张图覆盖大面积)。
(2) 使用 mipmap 优化远处纹理
场景中远处可见的纹理(如地形),在属性检查器勾选 生成 Mipmap,GPU 会自动加载低分辨率 mip 层,降低远处渲染压力(近处仍用高分辨率,不影响画质)。
2. 模型与动画优化
(1) 简化模型面数:
移动端模型面数:主角模型不超过 5000 面,敌人 / 道具不超过 1000 面(用 Blender、Maya 等工具减面,保留关键结构)。
(2) 动画资源优化:
用 Spine 替代帧动画:帧动画需大量纹理帧,体积大、内存占用高;Spine 动画仅存储骨骼数据,体积小、播放流畅(适合角色动画)。
3. 按需加载与资源释放
(1) 场景分块加载:
大场景(如开放世界)按 "区域" 分割为多个子场景,进入区域时用 cc.director.loadSceneAdditive 加载子场景,离开时用 cc.director.unloadScene 卸载,避免一次性加载所有资源。
(2) 资源释放时机:
场景切换时:在 onDestroy 中释放当前场景的资源(如 cc.resources.releaseAll() 释放所有已加载资源,或按路径释放指定资源)。
动态资源(如临时加载的道具纹理):使用后立即调用 cc.resources.release 释放,避免内存堆积。