前言
对于本文要介绍的Ψ0
- 首先,作者在大规模第一视角人类视频(约800 小时的人类视频数据)上对一个 VLM 主干进行自回归预训练,以获得具有良好泛化能力的视觉-动作表征
- 随后,再在高质量的人形机器人数据(30 小时的真实世界机器人数据)上后训练一个基于流(flow-based)的动作专家,用于学习精确的机器人关节控制
第一部分 Ψ0: An Open Foundation Model TowardsUniversal Humanoid Loco-Manipulation
1.1 引言与相关工作
1.1.1 引言
如原论文所说,大规模遥操作数据,对于人形机器人行走-操作任务来说在成本上极其高昂且在采集上极具挑战性
值得庆幸的是,人类第一视角视频提供了一种可扩展的替代方案,因为这类视频在无需进行机器人远程操控的前提下,就能捕获大量自然的运动模式以及丰富的行为层面的信息
然而,由于人类与机器人在形体结构上的巨大差异,直接将人类视频中的知识迁移到仿人机器人控制上并非易事
-
早期工作10, 40, 3 试图通过采用统一的人类中心状态-动作表示,从人类视频中进行学习。然而,由于人类与仿人机器人在本质上存在差异(包括动作频率、运动动力学以及自由度的不同),从这类异构数据中学习仍然具有挑战性
尽管这些方法采用了领域自适应 10 或将人类与机器人数据混合进行协同训练40 的策略,但用单一的整体策略去建模两种在本质上截然不同的动作分布,从根本上来说是次优的
其结果是,所学得的策略在控制仿人机器人执行复杂的、长时程任务时依然表现吃力 - 因此,作者研究一个根本性问题:如何有效地从人类第一视角视频中提炼运动先验和世界知识,从而支持人形机器人实现鲁棒的全身控制?
为此,来自1 南加州USC Physical Superintelligence (PSI) Lab、2 NVIDIA、3 WorldEngine的研究者提出了Ψ0一种新颖的多阶段训练范式

- 其paper地址为:Ψ0: An Open Foundation Model Towards Universal Humanoid Loco-Manipulation
其作者包括
Songlin Wei1*, Hongyi Jing1*, Boqian Li1*, Zhenyu Zhao1*, Jiageng Mao1 , Zhenhao Ni1 , Sicheng He1 , Jie Liu1 , Xiawei Liu1 , Kaidi Kang1 , Sheng Zang1 , Weiduo Yuan1 , Marco Pavone2 , Di Huang3 , Yue Wang1† - 其项目地址为
其github地址为
其对每个阶段设定不同的学习目标:
- 首先,作者在"人机统一动作空间"上预训练一个视觉语言模型VLM,使其能够预测下一步动作
该阶段的目标是让模型在各类丰富活动中学习任务层面的运动先验,同时学习与下游机器人任务对齐的视觉表征 -
随后,利用真实人形机器人数据,单独训练一个基于流模型的动作专家,使其能够直接在关节空间中预测动作序列
且作者将动作专家实现为一个多模态扩散Transformer(MM-DiT)15,该模型相比朴素的 DiT,这一模型更为强大
这个后训练阶段同时包含:在跨任务的人形数据上的与任务无关训练,以及在同域遥操作示范上的任务特定微调
在以 VLM 提供的视觉-语言特征作为条件的前提下,动作专家能够高效且并行地输出关节空间中的动作片段
该阶段使得动作专家能够捕捉到与具体形体相关的动力学特性。因此,只需要少量额外的真实机器人数据进行任务级的微调,模型便可以快速习得具有长时间跨度的灵巧行走-操控一体化技能
1.1.2 相关工作
首先,对于全身灵巧操作
近年来,类人机器人全身控制在诸多研究工作中取得了显著进展 42, 12, 26, 27, 16, 1, 45, 36
- 当前的类人机器人已经能够模仿多样的人体动作,如跑步、跳舞,甚至空翻
可尽管在运动能力方面的进展显著,研究者在实现与之相当水平的类人灵巧"行走-操作"(loco-manipulation)方面仍面临挑战 - LangWBC 37 和 LeVERB 39 提出了基于语言条件的全身控制策略,使类人机器人能够鲁棒地执行高层级、由语言指定的行为
然而,这些方法主要聚焦在行走与导航,对灵巧操作场景关注有限 - 与此并行,AMO 25 和 TWIST2 43 通过基于 VR 的遥操作实现类人机器人的全身控制,为采集"行走-操作"数据提供了一种高效框架
但它们更侧重于低层控制,而非学习适用于长时间尺度灵巧行走-操作任务的精确策略
另一方面,灵巧操作 18 由于需要高自由度控制,以及手掌与手指之间频繁的自遮挡而长期面临挑战,这些因素使得基于视觉的灵巧操作极其困难
- Being-H0 30 通过收集大量手-物体交互视频,并利用运动填补(motion-infilling)和轨迹平移(translation)等多种任务数据对预训练的 VLM 进行微调,从人类视频中进行学习
然而,该方法仅限于单臂的桌面操作 - 为了解决上述挑战,作者提出构建一个用于人形整体身体灵巧操作的统一 VLA 模型
其次,对于人形VLA
受基础模型非凡成功的启发,VLA(视觉语言动作模型)48, 24, 5, 44, 17, 38 作为一种有前景的研究方向逐渐兴起,被用于将人工智能带入物理世界
- π0系列5, 21 在具有挑战性的操作场景中展现出了卓越的泛化能力和鲁棒性,这些场景包括双臂操作和移动操作
GR00T 4 进一步开源了首个面向人形机器人的基础模型,该模型在由真实世界数据与从视频生成的合成数据构成的大规模混合数据上进行训练 - 然而,与这些工作相反,作者发现:相比于单纯扩展到海量、形态各异的跨载体数据规模,在更高质量数据上进行训练更加关键
故在本工作中,作者探索了一种用于训练人形 VLA 的新范式:利用大规模人类自视角视频数据,并辅以少量真实机器人交互数据
最后,对于从第一人称视频中学习
数据稀缺依然是训练 VLA 的根本瓶颈,因为遥操作数据的采集效率较低,且在规模化时成本高昂。相比之下,人类视频数据蕴含了丰富的人与物体交互的先验知识 33, 23, 41,因此提供了一种可扩展的替代方案
- 最新方法,如 EgoVLA 40 和 In-n-On 10,在人类视频与机器人数据上对模型进行联合训练,以预测统一的人类手腕与手部动作,随后在推理阶段通过逆运动学(IK)将这些预测映射为机器人动作
- 类似地,H-RDT 3 训练了一个大型 diffusiontransformer(DiT),在末端执行器空间中预测手臂与手部动作
然而,将人形机器人与非人形机器人数据混合起来端到端联合训练模型并非最优做法,因为模型必须同时学习两种本质上不同的动作分布 - 相反,作者指出了一条关键但被忽视的训练路径:在通过"下一步动作预测"完成预训练以学习任务语义和视觉表征之后,再对动作专家进行后训练,使其在关节空间中直接建模动作,从而避免联合训练带来的低效
1.2 Ψ0基础模型
在本节中,作者介绍Ψ0(Psi-Zero),一种用于类人灵巧运动操作的VLA 模型
给定自然语言任务指令 和当前观测
,作者的模型预测全身动作片段
- 观测
包含
当前的头部相机图像
和
全身本体感觉状态
包括上身关节状态、躯干横滚、俯仰、偏航以及底座高度 - 动作
其中
而
总之,作者采用基于RL 的控制策略25 来控制数据收集和策略评估全过程中的下肢和躯干关节
1.2.1 模型架构
Ψ0 是一个采用三重系统架构的基础模型,遵循以往工作21, 4
-
如图2 所示,高层策略由两个端到端训练的组件组成:
最终在以VLM 骨干网络的隐藏特征为条件的情况下,动作专家预测未来的全身动作片段
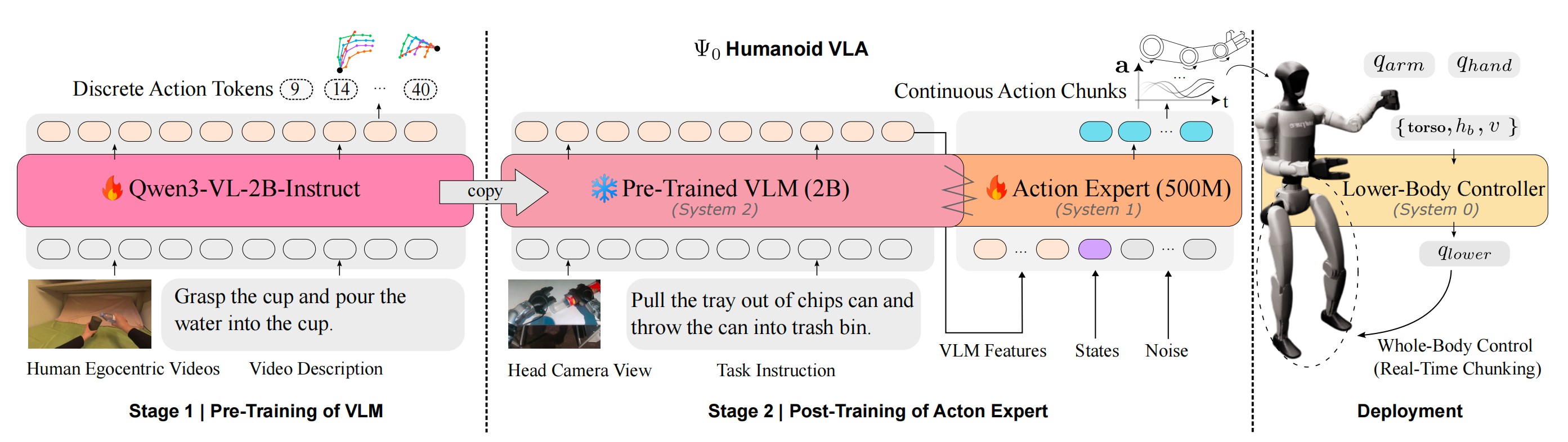
一个视觉-语言骨干网络作为system-2
作者使用最先进的视觉-语言基础模型Qwen3-VL-2B-Instruct2 作为system-2
和
一个多模态扩散Transformer(MM-DiT)动作专家作为system-1
动作专家被实现为一种基于流的MM-DiT,灵感来自Stable Diffu-sion 3 15,包含大约5 亿个参数。与朴素的基于DiT 的动作头相比,这种设计能够更高效地融合动作和视觉-语言特征 -
8 自由度的下肢动作
作者采用现成的控制器AMO 25
它将这些输入映射为15 自由度的下肢关节角
再加上28 自由度的上肢关节
1.2.2 训练方案:预训练、后训练、微调
作者提出了一种高效的训练方案,用于从人类视频和真实机器人数据中学习类人机器人行走-操作(loco-manipulation)技能
整体训练过程包含三个阶段:
- 第一阶段,在大规模、高质量且多样化的人类第一视角视频上预训练 VLM 主干网络;
- 第二阶段,在跨任务的真实类人机器人数据上对基于流的动作专家(flow-based actionexpert)进行后训练;
- 第三阶段,使用少量任务域内数据对该动作专家进行微调,从而实现对新任务的快速适应
首先,对于在第一人称人类视频上进行预训练
-
训练类人基础模型面临显著的数据稀缺瓶颈。相比真实世界机器人数据,人类第一人称视频的扩展成本要低得多,因此提供了一种很有前景的替代方案
因此,作者利用EgoDex 20,其中包含约829 小时的人类第一人称视频,记录了人手执行多种灵巧操作任务的过程
且为了进一步缓解人类视频与机器人观测之间的视觉差异,作者加入了Humanoid Everyday47,其中包含31 小时的类人数据,涵盖260 种多样任务,从人-物体交互到对可变形和关节物体的操作 -
且对人手和机器人末端执行器使用统一的动作表示
具体而言,任务空间中的48 自由度动作被定义为
其中每个
为其中
每个
这样的统一动作表示使人类数据和机器人数据的联合训练成为可能,并实现了稳定训练 -
然而,直接训练模型自回归地预测多个高维动作块在计算上非常昂贵,并且会极大地减慢预训练过程
作者的关键见解是,预训练VLM 骨干网络的目标是学习语言指令的任务语义以及用于下游真实机器人操作的视觉表征
对于这样的目标,预测单个下一步动作 就足够了因此,作者训练VLM 仅预测一个单步动作
作者使用FAST 34 将连续动作离散化为离散的token
即从 EgoDex 20 中随机抽取的 50 万条动作数据上训练 FAST tokenizer最终训练得到的分词器实现了平均L1 重建损失为0.005,并将每个动作序列从48 个token 压缩到可变token 长度
然后,++VLM 以自回归方式训练来预测下一个动作token++ ,即最大化
其次,对于在跨任务真实人形数据上的后训练
在训练完VLM 骨干网络后,作者冻结其参数并从头开始训练动作专家
以从VLM 骨干中提取的隐藏特征 和均匀采样的流动时间步
为条件,流匹配训练目标为------定义为公式2
其中 是高斯噪声,
是加噪后的动作
且作者改编了MM-DiT 架构15 来实现动作专家网络,如图3 所示
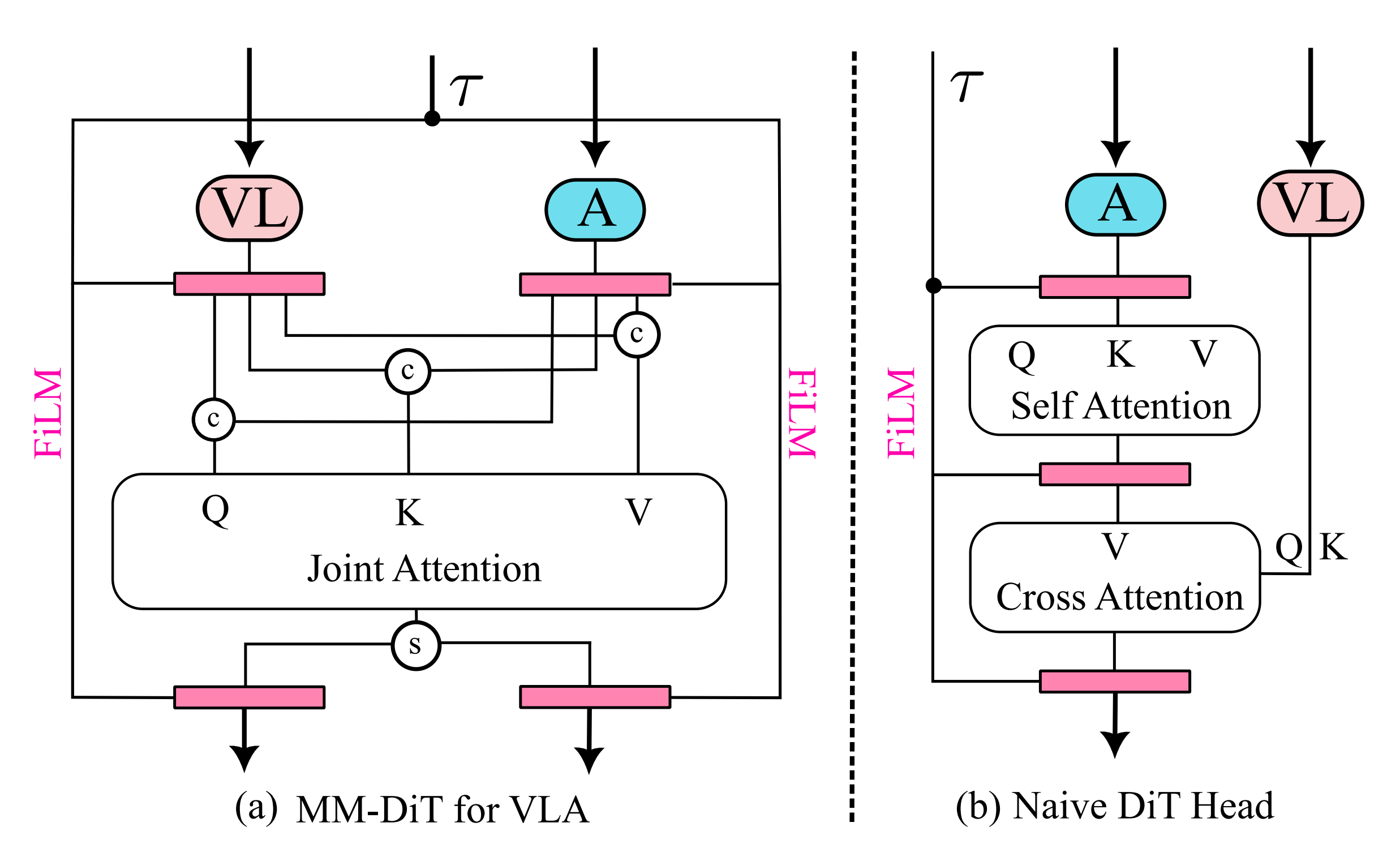
具体来说,模型使用时间条件特征 分别调制动作(A)特征和视觉-语言(VL)特征
在每个transformer 块中,动作token 和VL token 执行联合全局注意力,这相比于朴素的DiT 有利于更有效地融合视觉信息
最后,对于在域内遥操作数据上进行微调
在已经完成 VLM预训练和动作专家后训练的基础上,作者的模型可以使用少量域内数据进行端到端的进一步微调,从而快速学习长时域、高灵巧性的行走-操作一体化任务
- 比如在八个真实世界任务上对模型进行评估(如图 6所示)

每个任务都提出了不同的挑战:有的需要精确的机械臂协调,有的则要求长距离导航 - 大多数任务在 30Hz 频率下的步数超过 2,000 步,使其真正成为长时域任务
每个任务包含三到五个子任务,每个子任务对应一种技能,例如抓取或推动
1.2.2 实时动作分块RTC
人形机器人在控制过程中需要平滑且具备快速反应的能力,尤其是在执行长时域、灵巧操作任务时
然而,现有的VLA 通常包含数十亿个参数,这不可避免地由于推理延迟而引入" 停下来思考" 的行为
-
作者的Ψ0 模型同样包含超过25 亿个参数,单次前向传播大约需要160 ms
为了在存在这种延迟的情况下仍然实现平滑的策略展开,作者采用了训练阶段的实时分块(RTC),遵循文献7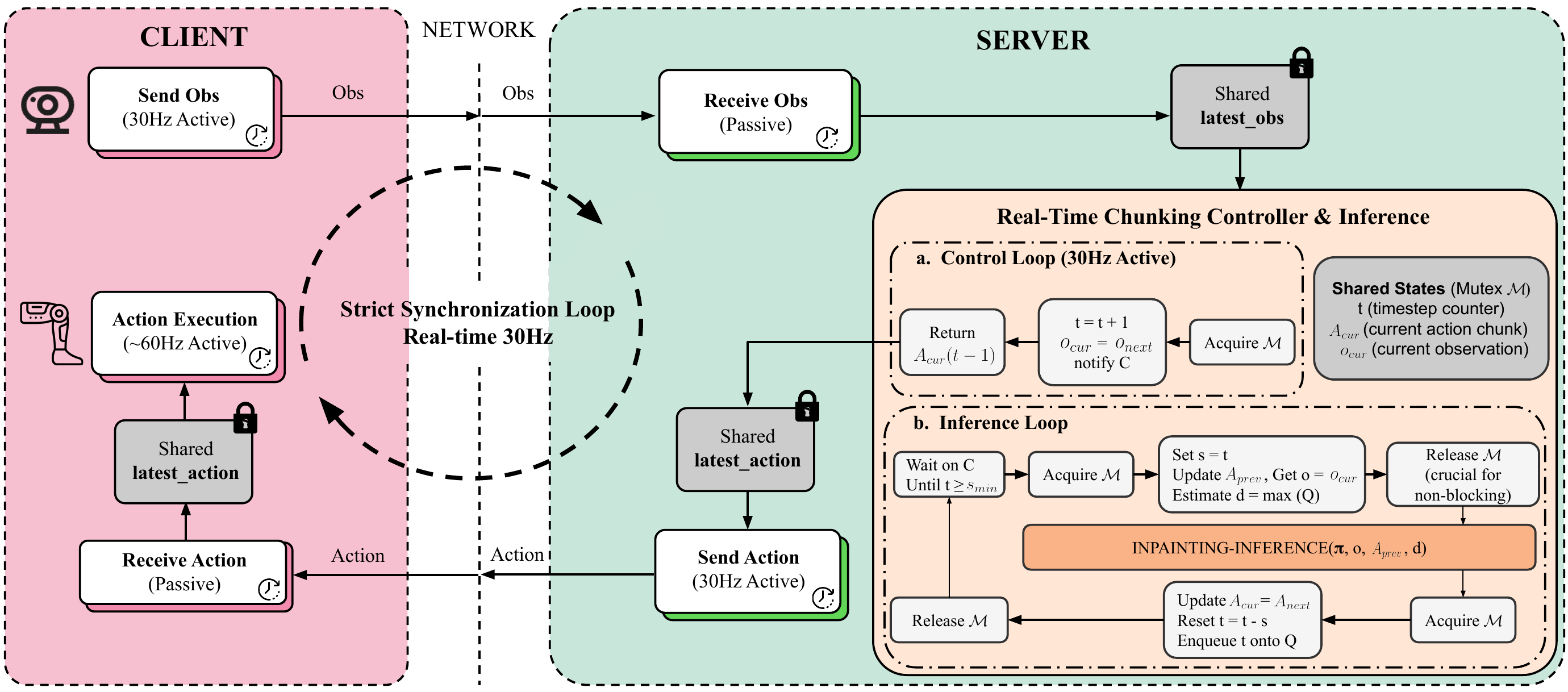
-
利用RTC,每次动作预测都以先前已经执行的动作块为条件,并输出一个一致的未来动作块,如图4 所示
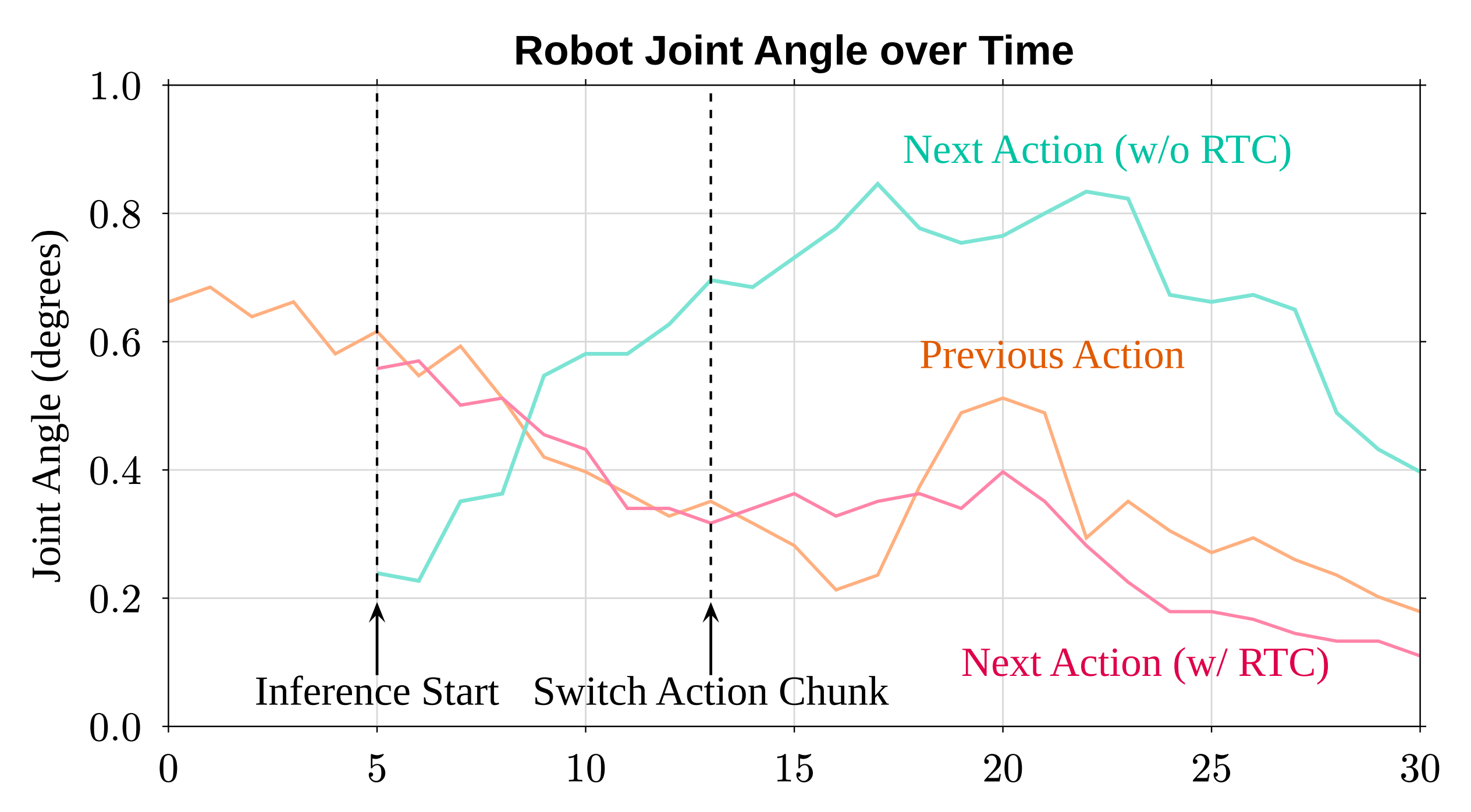
为了在训练过程中真实地模拟推理延迟,作者随机从前个token 中移除扩散噪声,并在式(2)
的损失计算中将其掩蔽
在这里,表示以时间步为单位的最大推理延迟,而H 和s 分别对应动作分块预测视界和执行视界
1.2.4 面向行走-操作一体化的远程操作定制
高效地学习一个长时域的步行--操作(loco-manipulation)任务,在很大程度上取决于用于微调的、同分布(in-domain)数据的质量
- 然而,现有的远程操作系统主要是为运动控制设计的,缺乏灵巧操作所需的稳定性和适应性
要为类人机器人实现有效的步行--操作远程控制系统,需要在全身表达能力、行走稳定性以及操作简洁性之间取得平衡 - 现有的端到端全身远程操作流水线 43, 31,通常是通过强化学习将人类全身动作直接映射为类人机器人控制信号,但由于跟踪信号存在噪声以及全身运动模式不稳定,这类方法往往鲁棒性有限
此外,这些系统依赖手持控制器,并将灵巧的手部控制降维为类似夹爪的低维指令,从而限制了操作的表达能力 - 另一方面,通过显式底座指令将操作与行走解耦的系统25 提升了下肢的稳定性,但通常需要额外的控制器或多名操作员,从而降低了其实用性
为了解决这些局限性,作者提出了一种定制的远程操作框架,该框架将上半身姿态跟踪、灵巧操作和运动控制指令明确解耦,同时仍支持单个操作员对整个人形机器人实施全身控制
-
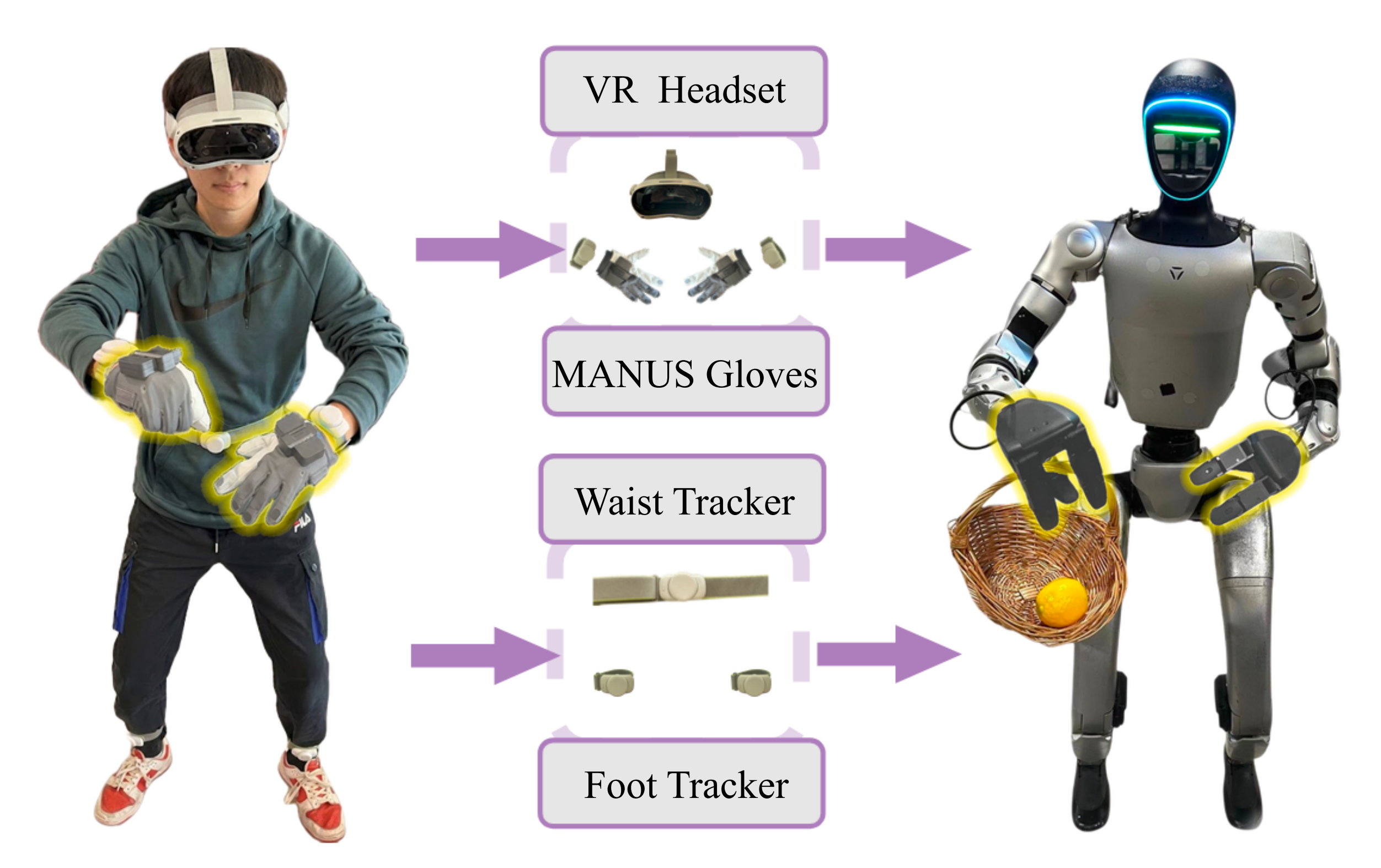
如图 5 所示,远程操作员的上半身姿态通过1PICO 头显 35 和2 手腕腕追踪器进行采集,并实现了一个多目标逆运动学求解器,用于计算人形机器人的手臂和躯干构型
-
通过使用一小套可穿戴追踪器,并将行走运动与原地的全身动作分离,作者的框架实现了由单一操作者完成的人形机器人远程操控,并在多样化任务场景中提升了行走运动的稳定性。
此外,2 腕部追踪器与3 MANUS 手套的组合缓解了基于视觉的 VR 追踪中常见的遮挡和视野外问题,从而实现了精准且可靠的上半身与手部追踪
这些设计选择共同支持在人形机器人上实现稳健且实用的全身远程操控,以完成复杂的行走-操作一体化任务
有意思的是,PICO 4 Ultra全能版Pro包含:腕部追踪器、腰部追踪器、腿部追踪器
1.3 实验
1.3.1 实现
首先,对于硬件平台
在所有真实环境实验中,作者使用Unitree G1 仿人平台,该平台为全身控制提供了29 个自由度
此外,每只手臂都配备了一只具有7 自由度的 Dex3-1 灵巧手
视觉观测由默认的头部安装式 Intel RealSense D435i 摄像头获取
其次,对于数据准备
-
EgoDex 数据集包含大约900M 帧,并为上半身人形体提供逐帧的全局变换矩阵,包括7 个脊柱关节、2 条手臂以及每只手的21 个关节
为提高*++预训练++*效率,所有动作都被转换到当前头部相机的坐标系中 ,并且将帧率上采样3 倍
由于EgoDex 中存在极端离群值,动作数值使用第1 和第99 分位数进行归一化
在预训练阶段作者省略状态输入 -
作者使用Humanoid Everyday 数据集47 进行与任务无关的++后训练++ ,该数据集包含大约300万帧真实世界遥操作数据
动作被表示为36 自由度的关节空间向量由于Humanoid Everyday 只提供上半身运动,作者以类似方式填充缺失的下半身动作分量
状态由当前帧中双手和手臂的28 自由度关节位置组成,并在未进行归一化的情况下输入模型
最后,对于训练细节
-
训练首先通过从 EgoDex 中随机采样500,000 个动作来拟合一个 FAST tokenizer开始
使用该分词器在保留的动作数据上的 L1 重构损失约为 0.005,相比使用原始开源 FAST tokenizer时的 0.01 有所提升
FAST tokenizer将每个动作序列压缩为 20 个token,从而加快后续训练的速度然后,作者在预训练阶段对 Qwen3-VL-2B-Instruct 2 进行微调,使用 64 张 A100 GPU 训练10 天
训练形式仅为下一步动作预测(next-action prediction),并且避免使用动作分块(action chunking)以降低计算开销
学习率固定为 0.0001,全局 batch size 为 1024 -
接下来,作者在 HumanoidEveryday 数据集上对包含约 5 亿参数的动作专家action expert进行后训练
在该阶段,VLM 主干网络被冻结,学习率固定为 0.0001,全局 batch size设为 2048。在单个包含 32 张 A100 GPU 的节点上,该阶段大约需要 30 小时 -
最后,作者仅针对每个下游任务对动作专家进行 40,000 步微调,使用余弦学习率调度器,初始学习率为 0.0001
1.3.2 真实环境人形机器人实验
第一,对于任务描述
如图 6 所示
- 作者在八个真实世界的长时域操作任务上评估 Ψ0,这些任务涵盖多样的日常场景
任务从简单交互(例如抓取与放置、推动和擦拭)到更加具有挑战性的灵巧操作,这些操作需要精确的手指---物体协调,包括旋转水龙和拉出芯片托盘 - 除上半身操作外,这些任务还涉及全身运动,如躯干旋转和下蹲,以及下肢行走和转向
整体而言,该评测在多个真实环境中,对模型在复杂长时域灵巧行走---操作(loco-manipulation)任务上的性能进行基准测试
第二,对于评估协议
作者为每个任务收集80 条遥操作轨迹。所有基线模型都在相同的数据集上进行微调,使用相同的图像观测以及相同的动作和状态表示
-
每个长时程任务由三到五个子任务组成,这些子任务涉及灵巧操作、双臂协同和移动
其结果是,策略可能会在早期子任务中失败,从而导致整个rollout 失败故为了充分评估每个基线的能力,评估者被允许进行干预并协助策略越过失败的子任务,以便执行可以继续
-
因此,作者除了报告整体任务成功率外,还报告各个子任务的成功率
对于每个任务,作者为每个模型执行10 次rollout 试验。仅当所有子任务都完成时,才认为一次rollout 是成功的
所有基线模型,包括Ψ0,都使用相同的客户端代码来控制机器人进行部署
第三,对于基线
作者针对最新的大多数开源基线,在真实世界环境下进行了全面的基准测试。作者投入了大量精力,为每一种方法复现尽可能优异的结果
-
π0.5:在具备双机械臂和夹爪的移动机器人平台上展现出很强的泛化能力
为适配人形机器人任务,作者将动作维度扩展到 36,并将动作分块大小设置为 16。相应线性层的检查点权重也进行了填充,以适配扩展后的动作空间
然而,已发布的模型与检查点仅支持 30 维的动作空间
且为弥合原始训练数据与人形机器人之间的形体差异(embodimentgap),作者将学习率从 1e-5 提高到 1e-4,并将全局 batch size 从 32 提升到 128------以获得更好的性能并确保公平对比
且作者对π0.5 DROID 检查点进行微调,并将其转换为 PyTorch 实现 - GR00T N1.6 :在抓取和行走-操作任务中表现出色,并具有稳健的空间泛化能力
作者在发布的代码中使用全部默认超参数进行微调
且从GR00T N1.6 3B 预训练检查点初始化模型,并在他们的遥操作数据上进行 20,000 步微调,在三块NVIDIA A100 GPU 上使用全局 batch size 为 24
学习率采用 1e-4 的 cosine 调度方案
由于官方代码库中尚未公开 GR00T N1.6 的 RTC 推理代码,作者采用标准的顺序推理方案:使用与最近一次已执行动作对应的观测来作为条件,预测后续动作 - InternVLA-M1 11:是一个用于空间指向与机器人控制的统一框架,展现出较强的空间推理能力
然而,它仅在空间推理和机械臂数据上进行了预训练,这限制了其在类人任务上的表现
作者从在 RT-1Bridge 数据集上预训练完成的检查点开始,冻结VLM 主干网络,并在单张 NVIDIA A100 GPU 上,以批大小 64 对动作头进行 30,000 步的微调
在作者的实验中,InternVLA-M1 在连续动作块之间表现出动作抖动,导致执行过程不稳定 - H-RDT:是一个拥有 20 亿参数的单个大型 DiT 动作专家模型
作者在一块 NVIDIA A100 GPU 上,以batch size 为 32 训练该模型 10,000 个训练步。得到的策略在不需要精细运动的任务上表现出色
然而,它在需要在多关节上实现高精度控制的操作任务中表现不佳 - EgoVLA:是一个视觉--语言--动作模型,使用 EgoDex 和其他数据源,对第一视角的人类操作视频进行预训练
由于其原始代码库只预测末端执行器的手腕和手部姿态,作者对动作解码器进行了适配,使其输出下游任务所需的机器人关节空间指令
作者在远程操作的下游任务上对预训练的 EgoVLA 进行微调,其训练配置与原始论文中报告的一致:训练 115 个epoch,有效 batch size 为 16×8×4
在作者的实验中,EgoVLA 在下肢动作指令上的表现有限,这很可能是因为其预训练主要侧重于上肢和手部操作技能的建模,没有为协同下肢运动提供足够强的先 - 扩散策略(DP)13:在视觉特征提取方面,作者采用预训练的ResNet-18 19 作为视觉编码器
且将学习率设置为1×10−4,全局批大小设置为32。训练在两块A100GPU 上进行40,000 步,每个任务的训练时间约为15 小时
作者观察到,尽管DP 可以较好地拟合训练数据,但在大多数任务上仍然失败
作者推测,基于UNet 的DP模型在视觉表征方面容量不足
在推理过程中,作者执行100 次迭代去噪步骤,将随机噪声逐步转换为可执行的轨迹 - 基于 Transformer 的动作分块(Action Chunking withTransformers,ACT)46
为了适应类人行走与操作任务,作者将动作头(action head)重新配置为输出 36 维动作,并将 chunk 大小调整为 100,同时将 Transformer模块初始化为 4 个编码器层和 1 个解码器层的配置,以与公开发布的 ACT 框架 9 保持一致
其他训练超参数(如学习率、批大小和训练步数)则与 DP 保持相同
第四,与基线方法的比较
如图 7 所示,作者的模型在所有基线方法之上取得了大幅领先
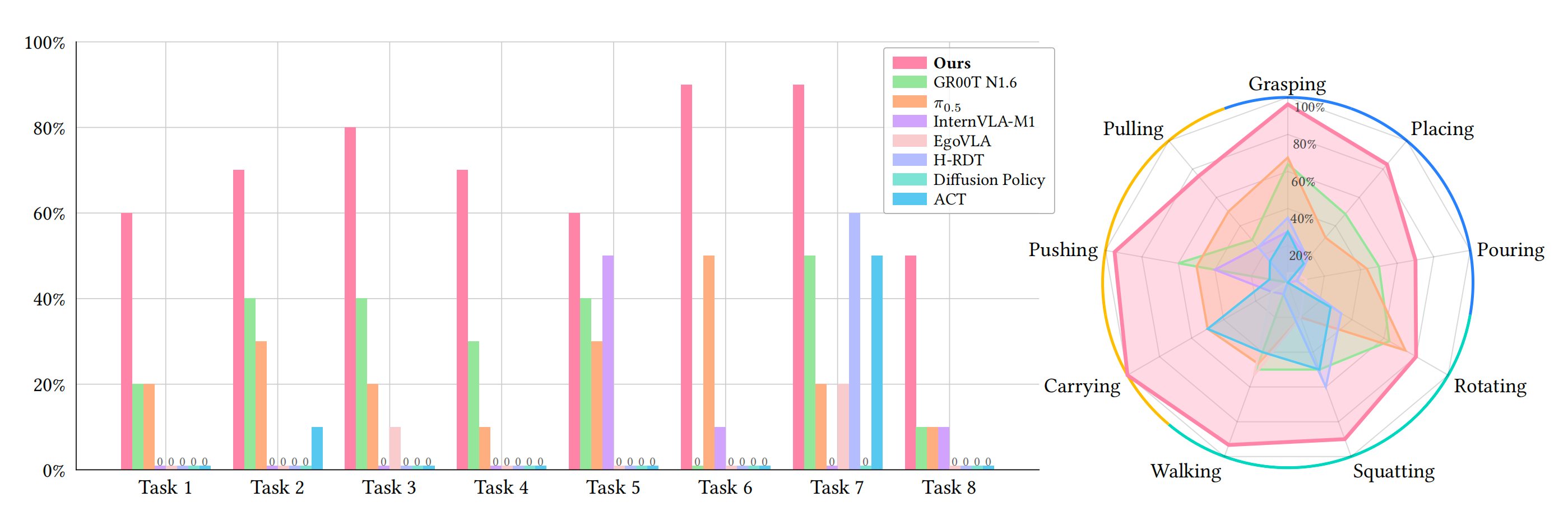
- 在全部八个长时域灵巧行走-操作任务中,作者的模型表现出最稳定的性能
值得注意的是,它在整体平均成功率上至少比第二佳基线 GR00T-N1.6 4(最新发布的人形基础模型)高出 40% - 这些结果突显了作者的训练范式在预训练和后训练阶段都仅使用相对少量机器人数据的前提下,依然具有显著效果
对此,作者将这一成功归功于独特的训练配方。一个关键的见解在于,在大规模的人类视频上对视觉语言模型进行预训练,使其能够学习到与下游操作任务相匹配的视觉表示,同时避免了对两个本质上截然不同的分布进行危险且困难的联合训练
利用从预训练 VLM 中提取的语言与视觉表征,作者进一步仅在联合空间中使用高质量真实机器人数据对动作专家进行后训练,从而使其能够学习到用于具身控制的强先验。更为详细的结果,包括各子任务的分阶段进展以及策略 rollout 视频,均在补充材料中给出
1.3.3 消融研究
由于算力和时间有限,作者在一项单一的真实世界任务上进行消融研究:将玩具捡起放入盒中并将盒子抬起
该任务由三个子任务组成:
- 使用右臂拾取玩具饺子并将其放入盒子
- 使用左臂拾取玩具河马并将其放入盒子
- 双臂一起搬运盒子
该任务包含多个执行阶段,要求策略既能处理单臂的抓取与放置,又能完成双臂协调
-
预训练与后训练的作用
首先,作者研究在他们的设定下,最初在文本生成任务上预训练的 Qwen3-VL VLM 的表现。如表 I 所示,在冻结预训练的 Qwen3-VL 主干网络、仅微调动作头的情况下性能最差,总体成功率仅为 0.2(如下表的第2行)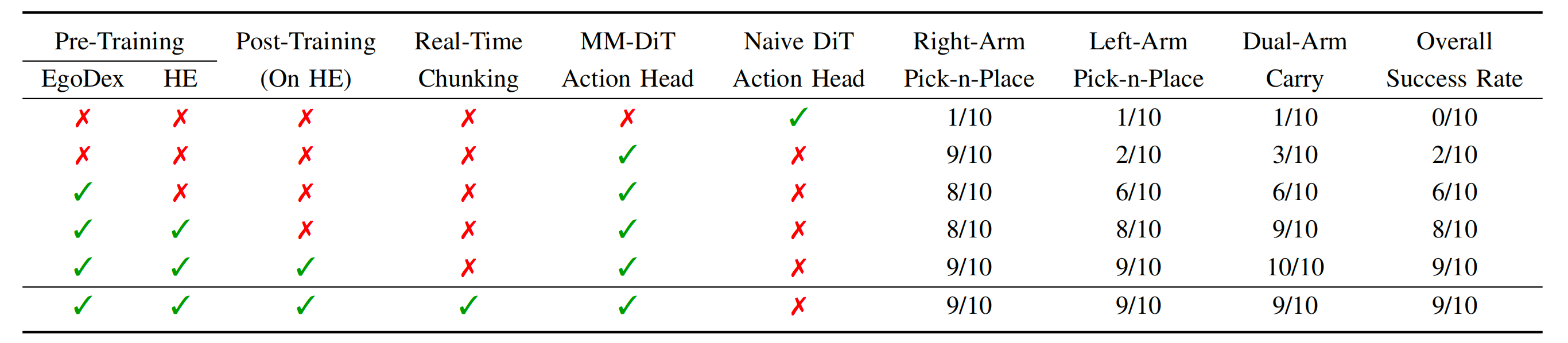
这个结果凸显了在人类数据上对 VLM 主干进行预训练以学习如何生成动作 token 的重要性。
而在 EgoDex 上进行任务空间下一步动作预测的预训练之后,模型性能有了显著提升值得注意的是,尽管 VLM主干被训练来预测的动作表征与下游动作头所使用的表征不同,将其监督为预测下一步 48 自由度(48-DoF)动作,仍然能够使模型学到对机器人任务有意义的视觉表征
这些发现表明了一条有效的路径:可以从大规模人类视频数据中进行学习,同时避免完全自回归式 VLM 动作生成所带来的推理时延此外
通过在高质量机器人数据上对动作专家进行后训练,整体性能进一步得到提升 -
MM-DiT 对比 Naive DiT
作者还通过将所提出的MM-DiT 动作头与用于动作预测的朴素 DiT 进行比较,来做消融实验以评估其有效性
结果表明,MM-DiT 始终优于该 DiT 变体
这一改进可归因于 MM-DiT 的双调制设计及其联合注意力机制,该机制将来自 VLM 主干的VL特征与动作A分支表示相结合
总之,作者的分析表明,直接套用最初为文本条件图像生成而设计的朴素 DiT,在用于视觉-语言(VL)引导的动作预测时,其条
约束能力较弱。关于动作专家的更多消融实验结果,详见补充材料 -
实时分块行为:由于模型规模庞大,VLA 通常推理速度较慢。当接收到一个用于生成动作的新查询时,推理可能需要超过 200 毫秒,在此期间类人机器人必须暂停以等待动作生成完成,从而在全身控制任务中引入抖动和不稳定行为
一个解决方案是测试阶段的实时分块(test-time real-time chunking)6。该方法在推理阶段对基于流(flow-based)的动作生成施加梯度引导,使未来生成的动作与过去的动作保持一致,从而实现关节指令的平滑执行
然而,作者发现模型在测试阶段无法被稳定地引导因此,作者实现了训练阶段的实时分块(training-timereal-time chunking)7
作者观察到,实时分块在策略执行过程中能减轻物理碰撞,并在不损害性能的前提下提升策略 rollout 的吞吐量
// 待更