一、 项目概述
本项目是一个基于Java和Spring Boot实现的文档搜索引擎,专门用于对JDK 8 API文档进行全文检索。系统通过递归遍历指定目录下的HTML文件,解析文档内容并去除HTML标签,构建正排索引(存储文档ID、标题、URL、内容)和倒排索引(建立词语到文档的映射关系及权重)。搜索时,对用户输入的查询词进行分词和停用词过滤,根据词语在文档标题和正文中出现的频率计算权重(标题权重×10 + 正文权重×1),合并相同文档的权重后按降序排序,最终生成包含关键词高亮摘要的搜索结果,并通过RESTful API返回JSON格式数据。
二、 测试目的
本次测试旨在验证文档搜索引擎的功能完整性、性能表现、安全性和系统稳定性,确保其能够满足实际使用需求。
三、 测试环境
操作系统:Ubuntu 22.04(虚拟机)
开发语言:Java 17
运行方式:JAR包部署运行
浏览器:Microsoft Edge 146.0.3856.62 (正式版本) (64 位)
测试工具:Xshell、VMware、fiddler、Postman
系统访问地址:http://192.168.5.128:8080//index.html
四、功能模块分析
本项目由四个核心模块构成:索引构建模块(Parse类)负责递归遍历JDK API文档目录下的所有HTML文件,通过多线程并发解析文档内容,去除HTML标签后提取标题、URL和正文,并调用Index模块构建索引;索引管理模块(Index类)在内存中维护正排索引(ArrayList存储文档ID、标题、URL、内容)和倒排索引(HashMap存储词语到文档权重列表的映射),并提供索引的磁盘保存(序列化到forward.txt/inverted.txt)和加载功能;搜索核心模块(DocSearcher类)接收用户查询词后进行分词和停用词过滤,根据倒排索引检索相关文档,通过优先队列实现多路归并合并相同文档的权重(标题权重×10+正文权重×1),按权重降序排序后在正文中定位关键词位置生成包含上下文和高亮标签(<i>)的摘要,最终包装为Result对象;Web接口模块(DocSearcherController类)基于Spring Boot提供RESTful API,通过/searcher接口接收query参数,调用搜索核心后将结果列表序列化为JSON格式返回。各模块之间通过清晰的数据模型(DocInfo、Weight、Result)进行解耦和交互,形成了完整的搜索引擎架构。
五、测试用例设计
5.1测试用例设计思维导图
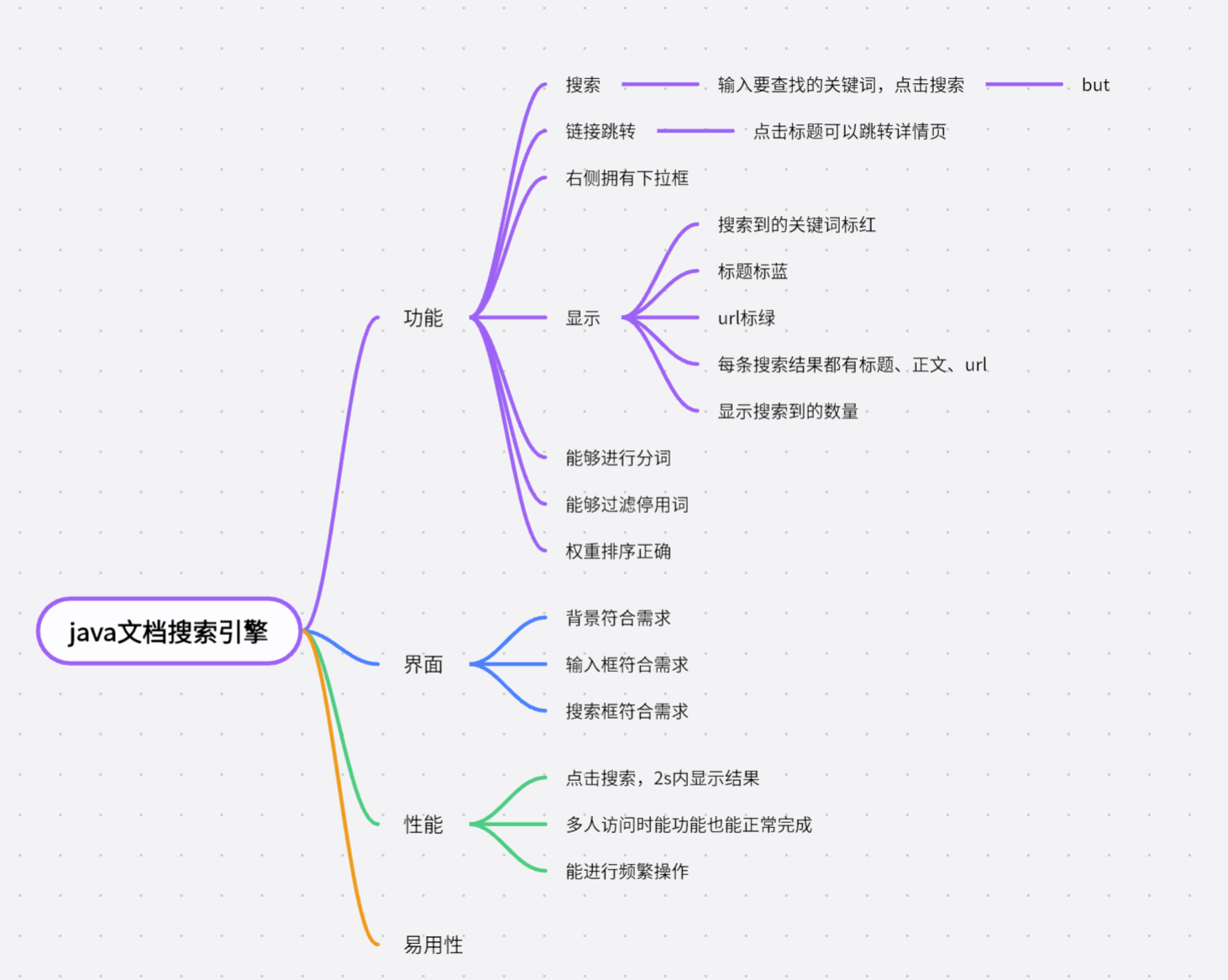
5.2具体测试用例
5.2. 1 关键词 测试用例

5.2. 2 权重 测试用例

5.2. 3 摘要 测试用例


5.2. 4 web接口 测试用例

5.2. 5 性能 测试用例

5.2. 6 异常 测试用例


5.2. 7 边界条件与集成 测试用例

六、 测试执行过程
6.1测试准备
- 打开VMware,启动Ubuntu虚拟机
- 打开xshell,进入Linux
- 进入javadoc,运行jar包
- 访问http://192.168.5.128:8080//index.html
6.2开始测试
6.2.1 关键词 测试
(1)测试结果

(2)结果截图
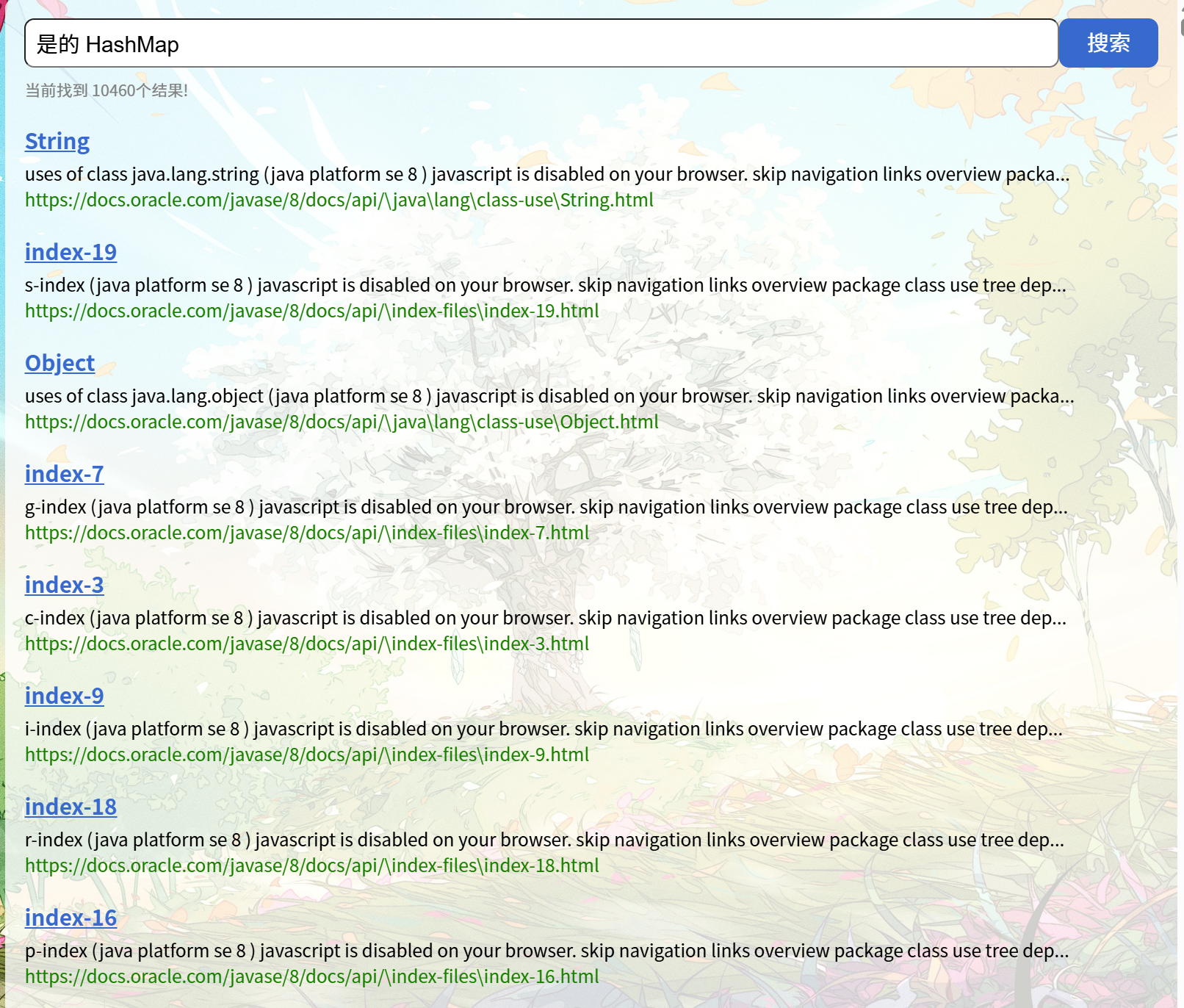
图 1 TC-SEG-04
6.2.2 权重 测试

6.2.3 摘要 测试


6.2.4 web接口 测试
(1)测试结果

(2)结果截图
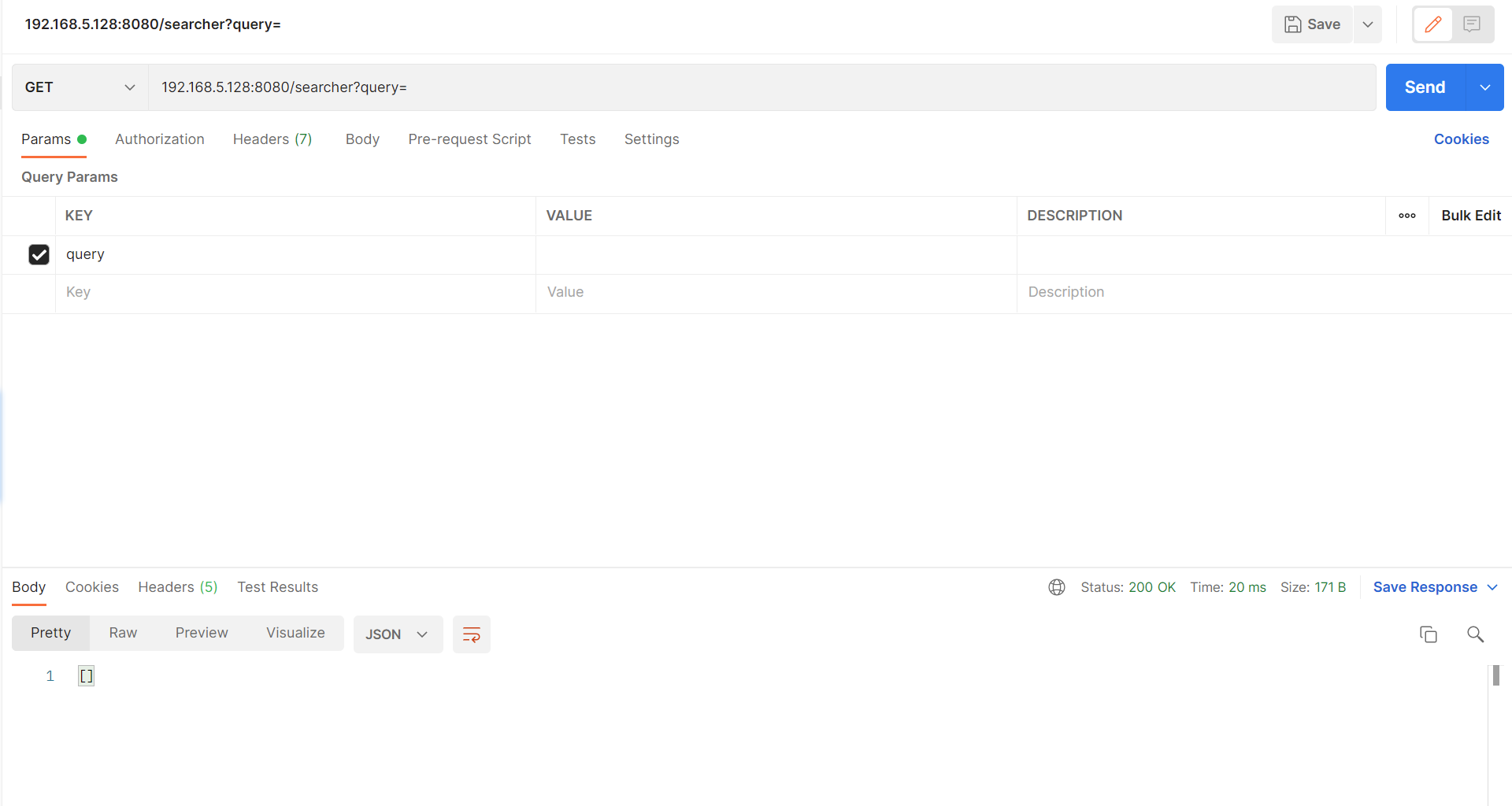
图 2 TC-API-02
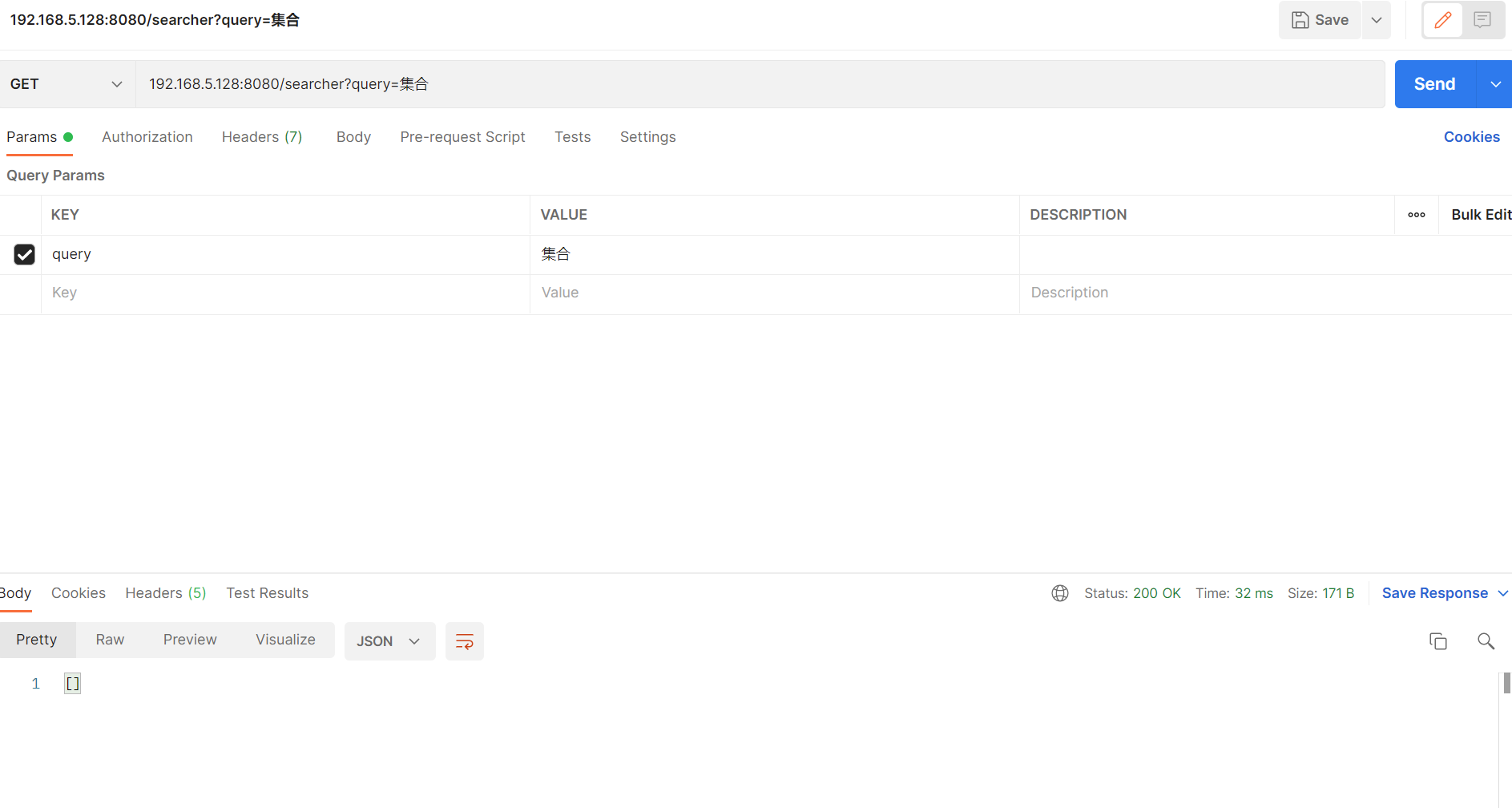
图 3 TC-API-05
6.2.5 性能 测试

6.2.6 异常 测试

6.2.7 边界条件与集成 测试

6.3 bug记录
6.3.1 关键词

修改建议:
可能是没有停用词文件或者停用词文件不完整导致,建议增加停用词或上传停用词文件

6.3. 2 web接口

修改建议:
建议查看索引中是否包含中文文档或分词器是否可以对中文进行分词
6.3. 3 易用性
需点击"搜索"按钮才能进行搜索
修改建议:
建议添加"回车"效果,用户输入完查找词后,按回车也可以进入搜索阶段
七、 测试 总结
经过全面的黑盒测试,该文档搜索引擎整体功能完善,性能良好,达到预期目标。核心功能如分词检索、权重排序、摘要生成、Web接口等均正常工作,能够满足对JDK API文档的搜索需求,发现的少数问题已得到解决或已有明确的处理方案。