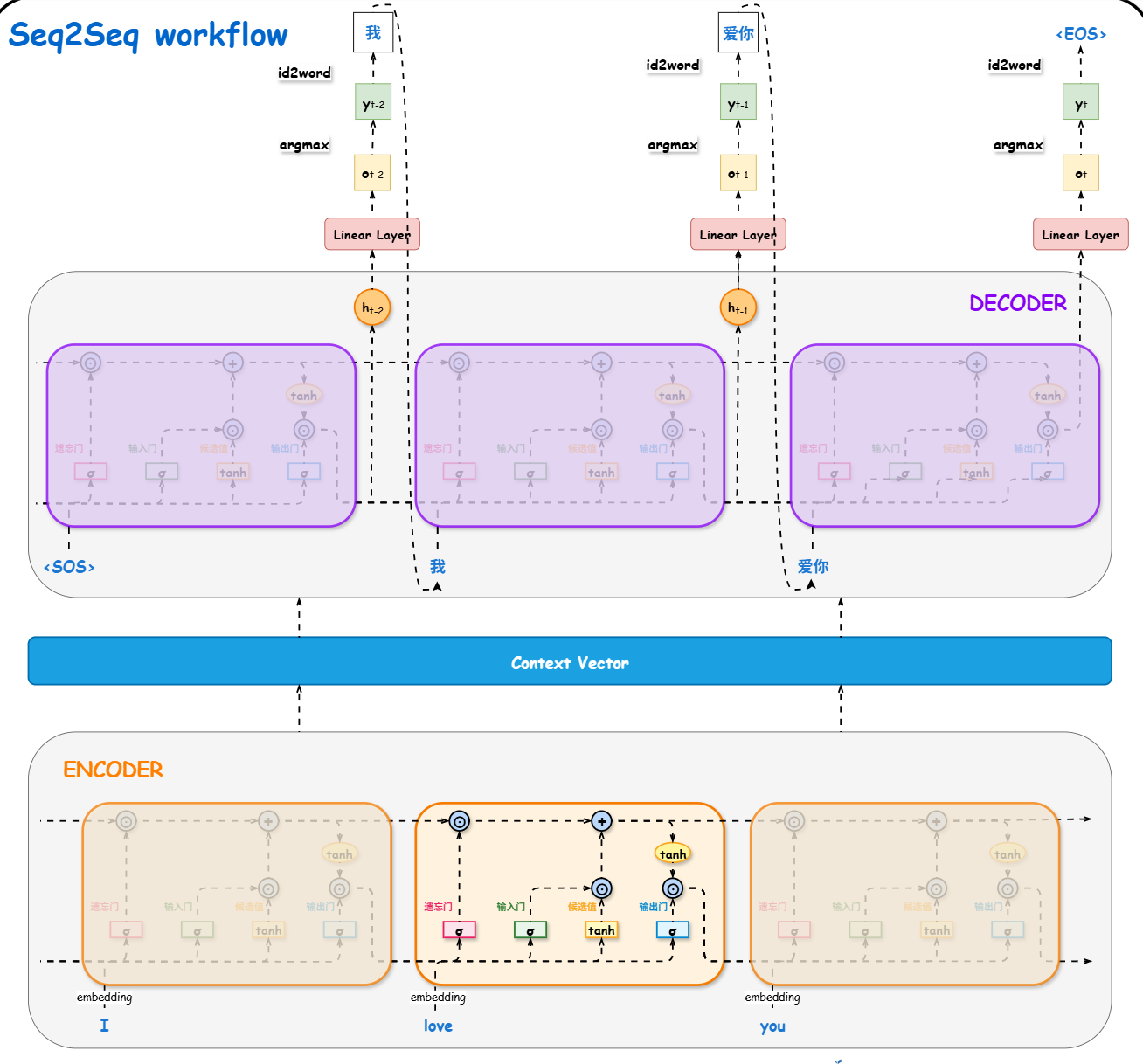
Seq2Seq架构
任务类别与seq2seq
- 多对一(Many-to-One):将整个序列信息压缩成一个特征向量,用于文本分类、情感分析等任务。
- 多对多(Many-to-Many, Aligned):为输入序列的每一个词元(Token)都生成一个对应的输出,如词性标注、命名实体识别等。
- 一对多(One-to-Many):从一个固定的输入(如一张图片、一个类别标签)生成一个可变长度的序列,例如图像描述生成、音乐生成等。
- 多对多(Many-to-Many, Unaligned):输入序列和输出序列的长度可能不相等 ,且元素之间没有严格的对齐关系。最典型的例子就是机器翻译。
2014年,研究者们提出了序列到序列(Sequence-to-Sequence, Seq2Seq) 架构,它成功地将一种通用的编码器-解码器(Encoder-Decoder) 架构应用于序列转换任务。
模型同样被拆分为两个组件,其中编码器 扮演"阅读和理解"的角色,负责接收整个输入序列,并将其信息压缩成一个固定长度的上下文向量(Context Vector) C,这个向量即为输入序列的"语义概要"。解码器则扮演"组织语言并生成"的角色,它接收上下文向量 C 作为初始信息,然后逐个生成输出序列中的词元。
编码器就是常规的LSTM架构,上下文变量C可以由每一个时间步的隐藏状态h经过线性变换或者平均池化得到,也可以是最后一个神经步的ht和ct。encoder可以用双向RNN以获得更丰富的表征。解码器用于作为生成器,其初始化依赖于上下文向量C,然后进入自回归生成阶段,<SOS>(也有称<BOS>)和C作为开始,直到生成<EOS>结束。
编码器和解码器的embedding共享问题: 若源语言和目标语言的词汇表彼此独立(如未采用联合子词/合并词表的英译中),通常选择不共享,否则是可以共享embedding的。
**上下文变量C在解码器中的交互:**1.作为初始化参数传入,但是对于长序列容易遗忘;2.不改变零向量的初始化状态,但是在每一个时间步进行拼接,改变了特征维度。3.C和h进行逐向量相加。
目标函数: 通常是交叉熵损失 Cross-Entropy Loss )会计算这个预测概率分布 pt 与真实目标 yt 之间的差异,它的本质是取出 ptpt 中对应真实词元 ytyt 的概率值并取负对数,即 Losst=−logpt(yt)。PyTorch 为例,通常需要调整维度(如将 (N, L, C) 展平或 permute 至 (N, C, L))以适配 CrossEntropyLoss 接口,并且需要忽略pad位置的损失。
训练与推理模式
**训练时使用教师强制 (Teacher Forcing),**在教师强制模式下,解码器在计算第 tt 步的输出时,它的输入不再是上一时刻的预测值 yt−1′,而是直接使用数据集中真实的标签值 yt−1。通过这种方式,解码器的每个时间步都能接收到正确的历史信息,避免了误差累积,能够显著提升收敛稳定性与速度。
推理时采用自回归 :解码器会以 CC 和 <SOS> 为初始输入生成第一个词元 y1,随后将 y1 作为下一时间步的输入生成 y2,不断将上一时刻的输出作为下一时刻的输入循环此过程,直到生成 <EOS> 标志或达到预设的最大输出长度时停止。实际上有可能采用束搜索。
代码实践
编码器代码
python
class Encoder(nn.Module):
def __init__(self, vocab_size, hidden_size, num_layers):
super(Encoder, self).__init__()
self.embedding = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=hidden_size
)
self.rnn = nn.LSTM(
input_size=hidden_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
bidirectional=False
)
def forward(self, x):
# x shape: (batch_size, seq_length)
embedded = self.embedding(x)
# 返回最终的隐藏状态和细胞状态作为上下文
_, (hidden, cell) = self.rnn(embedded)
return hidden, cell解码器代码
python
class Decoder(nn.Module):
def __init__(self, vocab_size, hidden_size, num_layers):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=hidden_size
)
self.rnn = nn.LSTM(
input_size=hidden_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True
)
self.fc = nn.Linear(in_features=hidden_size, out_features=vocab_size)
def forward(self, x, hidden, cell):
# x shape: (batch_size),只包含当前时间步的token
x = x.unsqueeze(1) # -> (batch_size, 1)
embedded = self.embedding(x)
# 接收上一步的状态 (hidden, cell),计算当前步
outputs, (hidden, cell) = self.rnn(embedded, (hidden, cell))
predictions = self.fc(outputs.squeeze(1)) # -> (batch_size, vocab_size)
return predictions, hidden, cellseq2seq整合代码
python
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super(Seq2Seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio=0.5):
batch_size = src.shape[0]
trg_len = trg.shape[1]
trg_vocab_size = self.decoder.fc.out_features
outputs = torch.zeros(batch_size, trg_len, trg_vocab_size).to(self.device)
hidden, cell = self.encoder(src)
# 第一个输入是 <SOS>
input = trg[:, 0]
for t in range(1, trg_len):
output, hidden, cell = self.decoder(input, hidden, cell)
outputs[:, t, :] = output
# 决定是否使用 Teacher Forcing
teacher_force = random.random() < teacher_forcing_ratio
top1 = output.argmax(1)
# 如果 teacher_force,下一个输入是真实值;否则是模型的预测值
input = trg[:, t] if teacher_force else top1
return outputsseq2seq架构应用空间广阔:语音识别(Audio-to-Text),图像描述生成(Image-to-Text),文本到语音(Text-to-Speech, TTS),问答系统(QA)。
应用瓶颈:信息稀释(传入的C,信息会逐渐变弱);缺乏倾向性:每一个词都获取的全量C,没有特别关注某一部分。
注意力机制
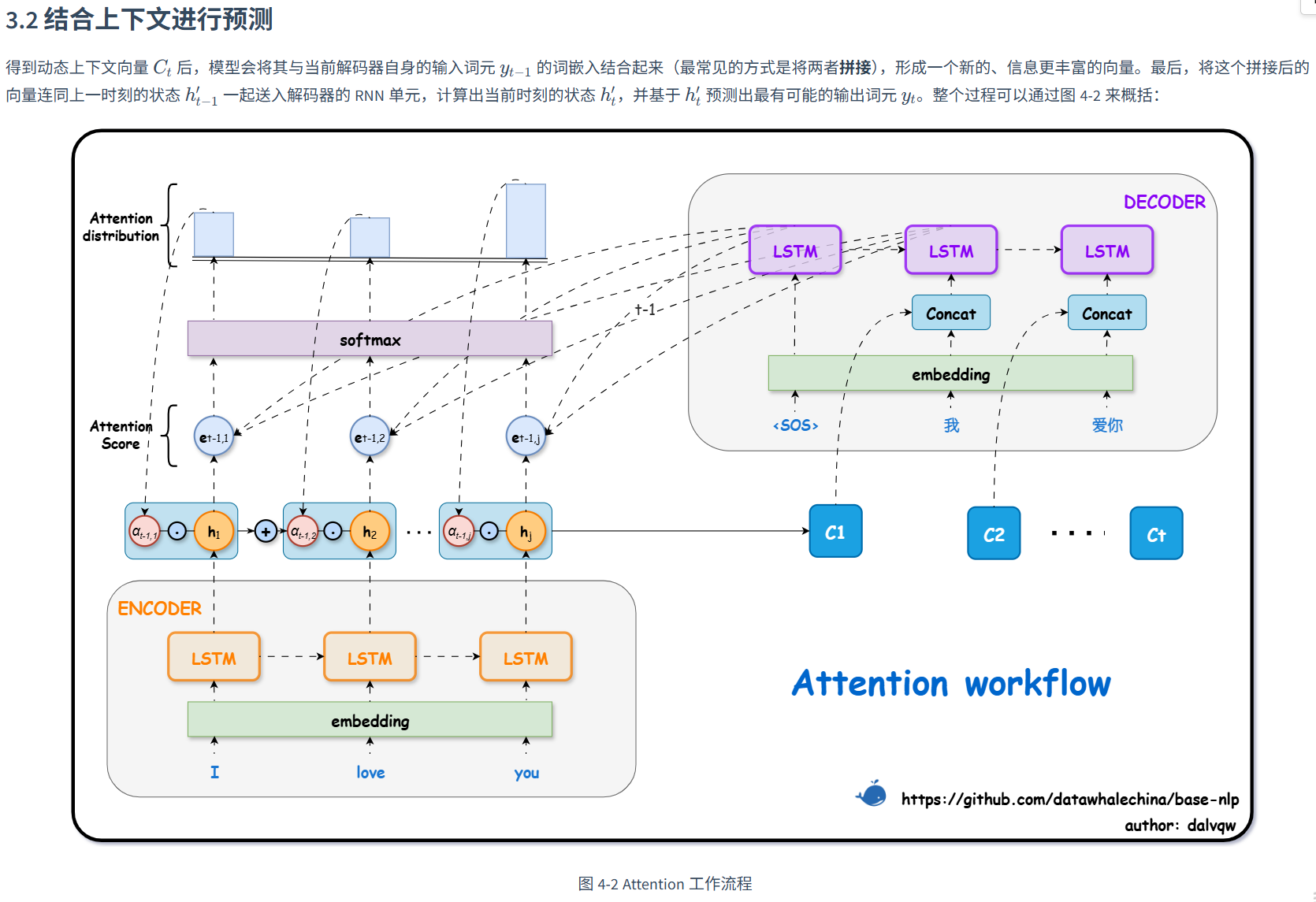
编码器 Encoder:forward 函数的返回值需要改变,除了最后一个时间步的隐藏状态 (hidden, cell),还需要返回所有时间步的输出 outputs
新增 Attention 模块 :创建一个独立的 nn.Module 类来实现注意力的计算逻辑。其 forward 方法接收解码器状态 (Query) 和编码器所有输出 (Keys/Values),返回计算得到的上下文向量。
解码器 Decoder:解码器的结构变化是最大的。它需要实例化一个 Attention 模块。解码器的 forward 函数通常以循环的方式逐个时间步解码,因为在第 tt 步计算注意力时需要依赖第 t−1步的解码器状态。需要强调的是,RNN 解码本身就是按时间步顺序计算,不能在时间维度并行,Attention 并未改变这一点。相较于"整序列一次性送入 RNN"的写法,逐步解码更便于在每步显式计算注意力并灵活插入教师强制等策略(按比例教师强制)。
注意力机制的类型:Soft Attention 所有 位置都计算一个注意力权重,这些权重是 0 到 1 之间的浮点数(经 Softmax 归一化),然后进行加权求和。开销极大,但是端到端可微。Hard Attention 在每一步只选择一个最相关的输入位置。可以看作是一种"非 0 即 1"的注意力分配,即选中的位置权重为 1,其他所有位置的权重均为 0。选择过程是离散的、不可微的,所以无法使用常规的反向传播算法进行训练,通常需要借助强化学习等更复杂的技巧。

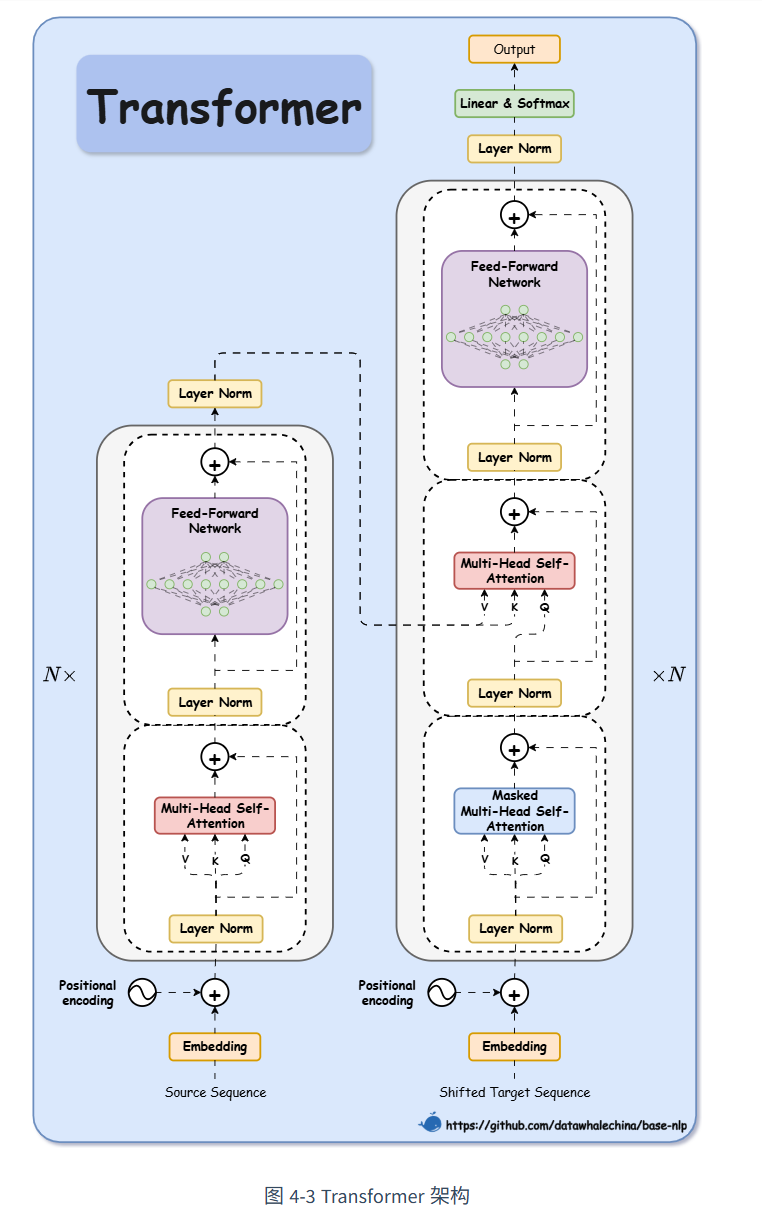
Transformer理解

位置编码

add& Layer norm