Join算法大比拼
本文致力于通过一个示例串联起几乎所有的连接算法,比如,简单嵌套循环连接(SNLJ)、页嵌套循环连接(PNLJ)、块嵌套循环连接(BNLJ)、索引嵌套连接(INLJ)排序-归并连接(SMJ)、Grace哈希连接(GraceHashJoin)等。
Cost Notation
- R : the number of pages to store
R - pRp_RpR : number of records per page of
R - ∣R∣|R|∣R∣ : the cardinality (number of records) of
R - ∣R∣=pR∗R|R| = p_R*R∣R∣=pR∗R
示例
假设 RAM 总是有 B=102B=102B=102 个帧可用。
Reserves (sid: int, bid: int, day: date, rname: string)
- R=1000R=1000R=1000,
- pR=100p_R=100pR=100,
- ∣R∣=100,000|R| = 100,000∣R∣=100,000
Sailors (sid: int, sname: string, rating: int, age: real)
- S=500S=500S=500,
- pS=80p_S=80pS=80,
- ∣S∣=40,000|S| = 40,000∣S∣=40,000
Simple Nested Loops Join
伪代码
txt
for each record r_i in R do
for each record s_j in S do
if \theta(r_i, s_j)
add <r_i, s_j> to result buffer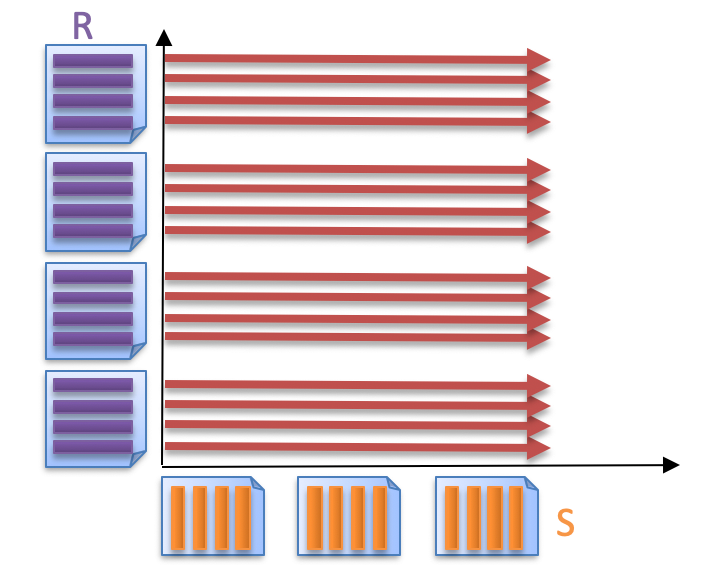
它的 IO 成本为:R+∣R∣∗S=1000+100000∗500=50001000≈5000万R + |R|*S=1000+100000*500=50001000\approx 5000 万R+∣R∣∗S=1000+100000∗500=50001000≈5000万
Page Nested Loop Join
伪代码
txt
for each rpage in R:
for each spage in S:
for each rtuple in rpage:
for each stuple in spage:
if join_condition(rtuple, stuple):
add <rtuple, stuple> to result buffer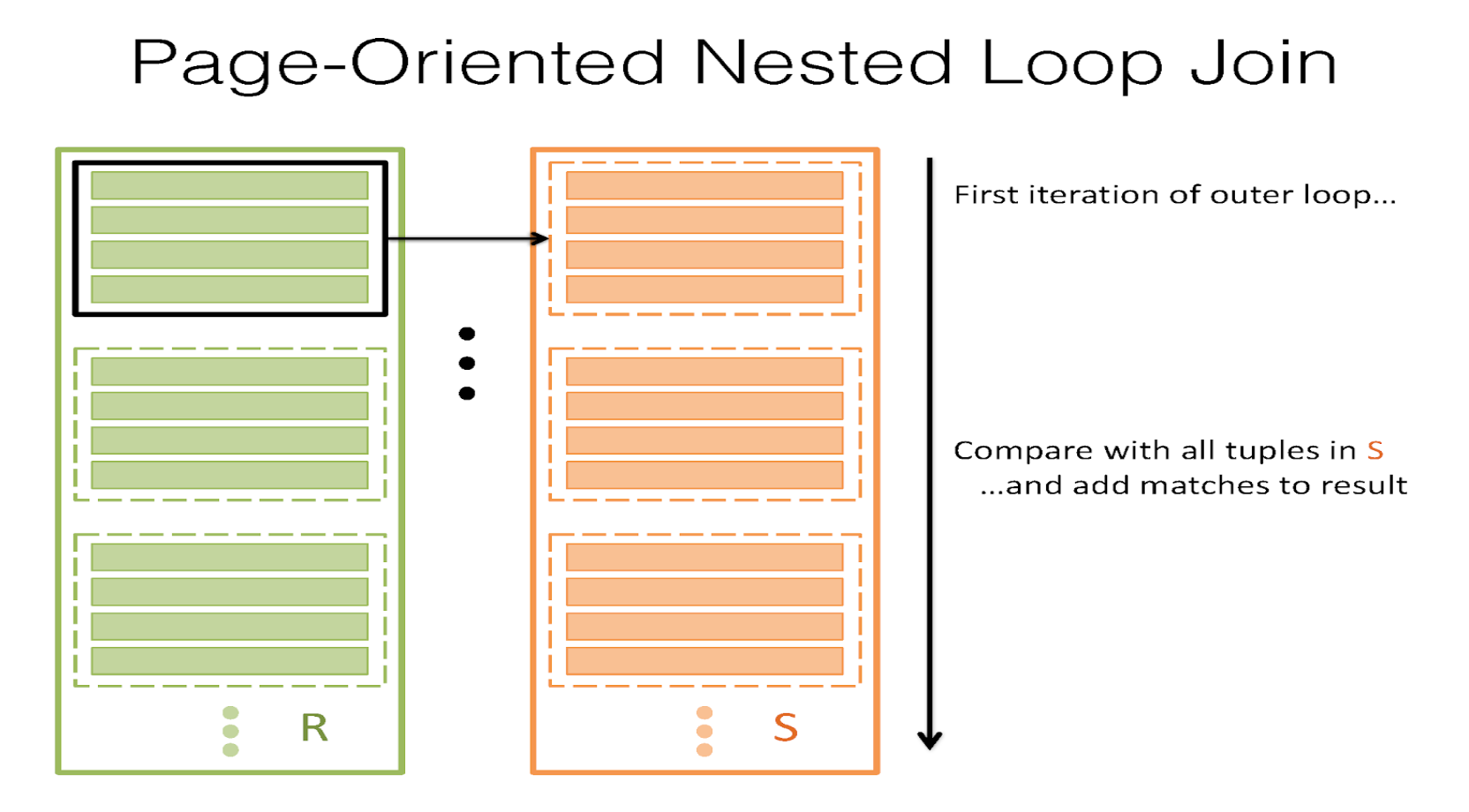
它的 IO 成本为:R+R∗S=1000+1000∗500=501000≈50万R + R * S = 1000 + 1000*500=501000 \approx 50万R+R∗S=1000+1000∗500=501000≈50万
Block Nested Loop Join
伪代码
txt
for each rchunk of B-2 pages of R:
for each spage of S:
for all matching tuples in spage and rchunk:
add <rtuple, stuple> to result buffer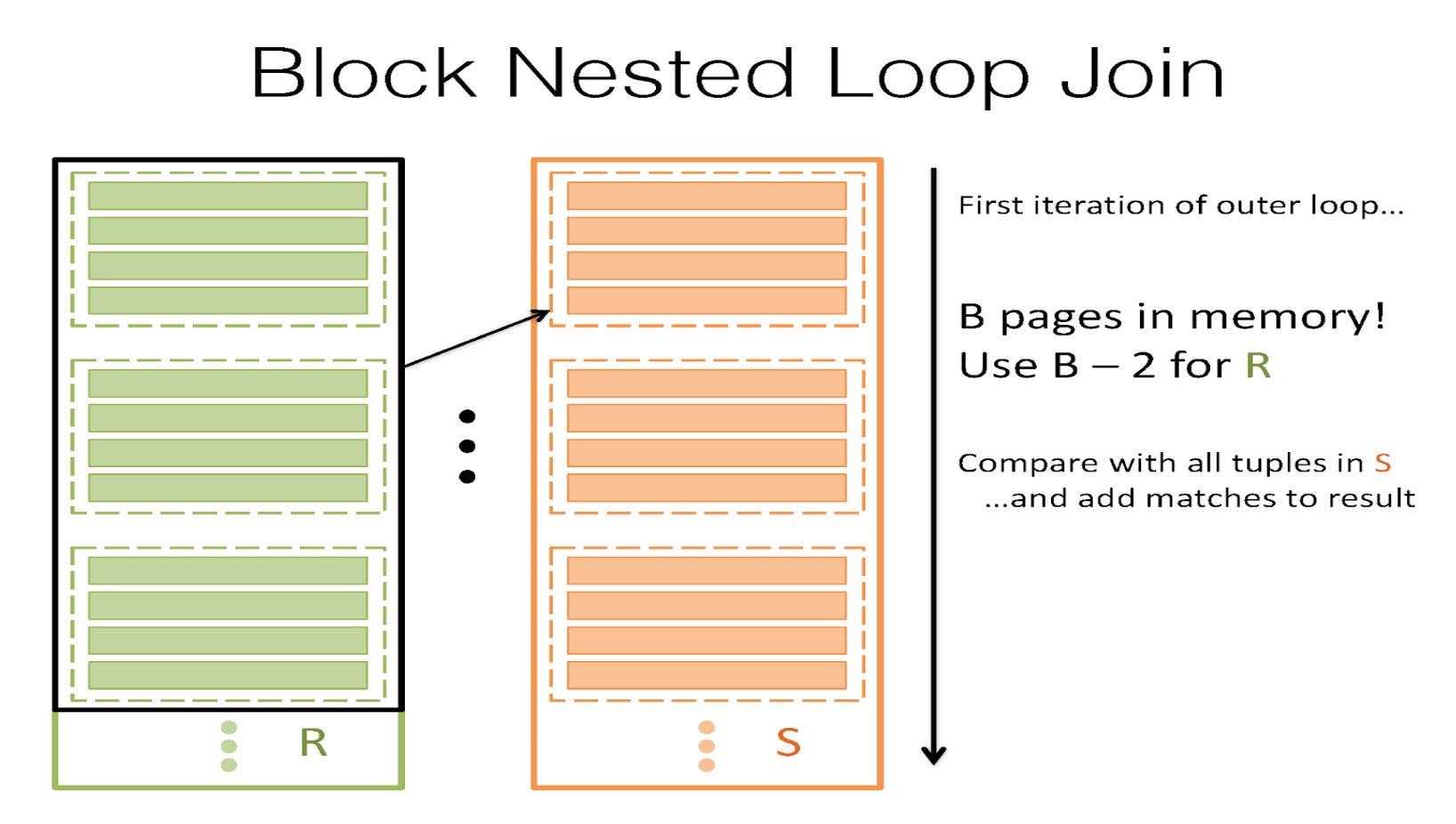
它的 IO 成本为:R+⌈RB−2⌉∗S=1000+⌈1000100⌉∗500=6000=6千R + \lceil\frac{R}{B-2}\rceil * S = 1000+ \lceil\frac{1000}{100}\rceil * 500=6000=6 千R+⌈B−2R⌉∗S=1000+⌈1001000⌉∗500=6000=6千
Index Nested Loops Join
伪代码
txt
for each tuple r_i in R do
for each tuple s_j in S where r_i == s_j do
add <r_i, s_j> to result它的 IO 成本公式为:R+R×从表 S 中查找匹配记录的成本R + R\times\text{从表 S 中查找匹配记录的成本}R+R×从表 S 中查找匹配记录的成本
对于方案 1,从表 S 中查找匹配记录的成本,等于从B+树的根遍历到叶子节点的 IO 次数,通常为 2-4 次。
对于方案 2 或者 3,从表 S 中查找匹配记录的成本分成两部分:
- 查找 RID(s)的成本:对 B+树来说,通常为 2-4 次 IO;
- 根据 RID 检索记录的成本:
- 聚簇索引:表
S中相匹配的记录所占的页数,每页对应 1 次 IO。 - 非聚簇索引:表
S中匹配的记录数,每条记录最多对应 1 次 IO。
- 聚簇索引:表
示例
Reserves (sid: int, bid: int, day: date, rname: string)
- R=1000R=1000R=1000,
- pR=100p_R=100pR=100,
- ∣R∣=100,000|R| = 100,000∣R∣=100,000
Sailors (sid: int, sname: string, rating: int, age: real)
- S=500S=500S=500,
- pS=80p_S=80pS=80,
- ∣S∣=40,000|S| = 40,000∣S∣=40,000
- 索引建在
sid上
假设sid对应的 B+树高度为 2。
因为sid是表Sailors的主键,所以,对表R中的每条记录,在表S中精准匹配 1 条记录。
对非聚簇索引来说,它的 IO 成本公式为 R+∣R∣∗(查找RID的成本+表S中匹配的记录数)=1000+100000∗(3+1)=401000≈40万R + |R| * (查找 RID的成本 + 表 S中匹配的记录数)=1000+100000*(3+1)=401000\approx 40 万R+∣R∣∗(查找RID的成本+表S中匹配的记录数)=1000+100000∗(3+1)=401000≈40万
对聚簇索引来说,它的 IO 成本公式为 R+∣R∣∗(查找RID的成本+表S中匹配的记录所占的页数)=1000+100000∗(3+1)=401000≈40万R + |R| * (查找 RID的成本 + 表 S中匹配的记录所占的页数)=1000+100000*(3+1)=401000\approx 40 万R+∣R∣∗(查找RID的成本+表S中匹配的记录所占的页数)=1000+100000∗(3+1)=401000≈40万
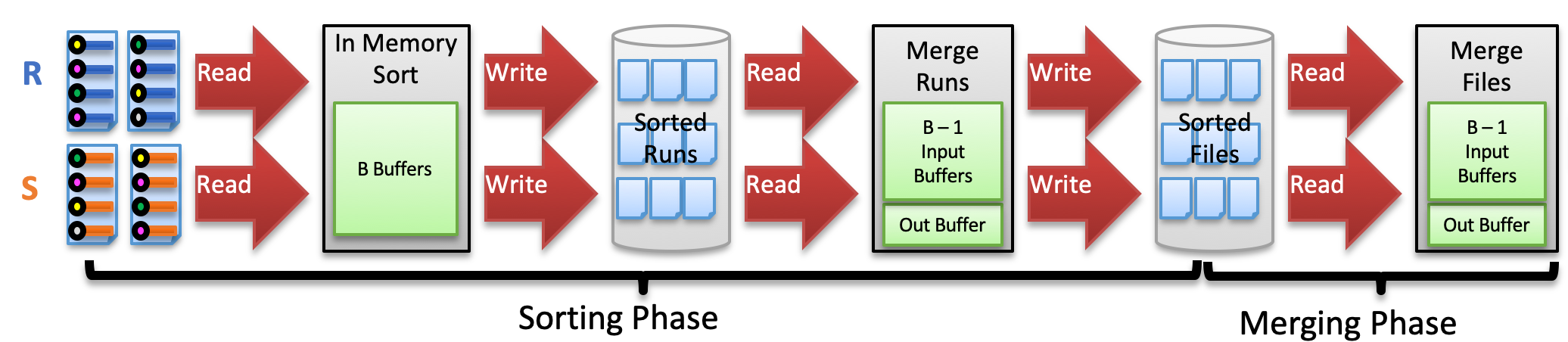
Sort-Merge Join
适用条件:等值连接、自然连接
分为两个阶段:
- 排序-归并阶段:分别将
R和S中的记录按照连接 key 排序,保证相同key 的所有记录都被连续存储 - 连接阶段:必须保证输入是已排好序的;归并扫描已排序的分区,输出匹配的记录
连接阶段的伪代码
txt
do {
if (!mark) {
while (r < s) { advance r }
while (r > s) { advance s }
// mark start of "block" of S
mark = s
}
if (r == s) {
result = <r, s>
advance s
yield result
}
else {
reset s to mark
advance r
mark = NULL
}
}
它的 IO 成本公式为R的排序成本+S的排序成本+(R+S)R 的排序成本+S 的排序成本+(R+S)R的排序成本+S的排序成本+(R+S)。
因为B(B−1)=102∗101≥R=1000B(B-1)=102*101\geq R=1000B(B−1)=102∗101≥R=1000,且 B(B−1)=102∗101≥S=500B(B-1)=102*101\geqS=500B(B−1)=102∗101≥S=500,所以,根据外部排序相关理论可知,R和S的排序均耗费 2 趟就可完成。从而,R的排序成本为2∗R∗2=2∗1000∗2=40002*R*2=2*1000*2=40002∗R∗2=2∗1000∗2=4000,S的排序成本为2∗S∗2=2∗500∗2=20002*S*2=2*500*2=20002∗S∗2=2∗500∗2=2000。
综上可得:Sort-Merge Join 的总 IO 成本为
4000+2000+1000+500=7500 4000+2000+1000+500=7500 4000+2000+1000+500=7500
注意:Sort-Merge Join相当于先排序后连接。
对比:先连接再排序的IO 成本
假设使用 BNLJ,则 Join的成本为S+⌈SB−2⌉∗R=500+5∗1000=5500S+\lceil\frac{S}{B-2}\rceil*R=500+5*1000=5500S+⌈B−2S⌉∗R=500+5∗1000=5500。
排序的成本为2∗R∗(1+⌈logB−1⌈RB⌉⌉)=2∗1000∗2=40002*R*(1+\lceil\log_{B-1}\lceil\frac{R}{B}\rceil\rceil)=2*1000*2=40002∗R∗(1+⌈logB−1⌈BR⌉⌉)=2∗1000∗2=4000。
综上可知,先连接后排序的总 IO 成本为5500+4000=95005500+4000=95005500+4000=9500。
Grace Hash Join
适用条件:等值连接、自然连接
两个阶段
- 分区并存储:将表
R和表S中的记录进行 hash 分区,并写盘- 保证给定key 的所有记录都在同一个分区
- 构建和探测:对每个分区构建和探测一张单独的哈希表
伪代码
txt
For Cur in {R, S}
For page in Cur
Read page into input buffer
For tup on page
Place tup in output buf hash_p(tup.joinkey)
If output buf full then flush to disk partition
Flush output bufs to disk partitions
For i in [0..(B-1))
For page in R_i
For tup on page
Build tup into memory hash_r(tup.joinkey)
For page in S_i
Read page into input buffer
For tup on page
Probe memory hash_r(tup.joinkey) for matches
Send all matches to output buffer
Flush output buffer if full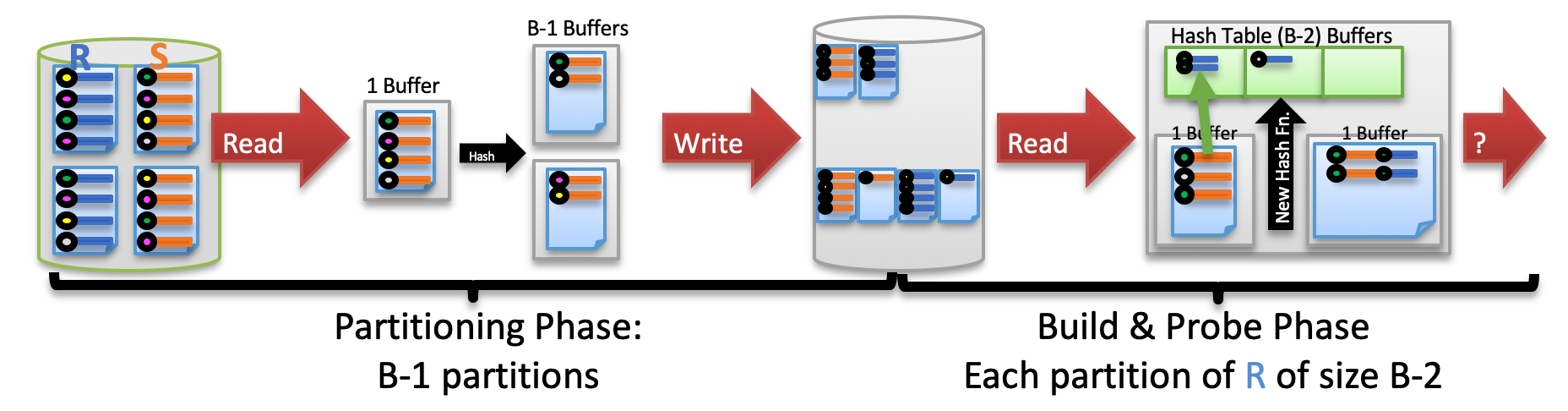
它的IO 成本公式为
分区阶段的成本+构建与探测阶段的成本分区阶段的成本+构建与探测阶段的成本分区阶段的成本+构建与探测阶段的成本
- 分区阶段的成本为2∗(R+S)=2∗(1000+500)=30002*(R+S)=2*(1000+500)=30002∗(R+S)=2∗(1000+500)=3000
- 构建与探测阶段的成本为R+S=1500R+S=1500R+S=1500
- 总 IO 成本为3000+1500=45003000+1500=45003000+1500=4500
内存要求
问题:为了能够对R与S执行 Grace Hash Join,它对内存有着怎样的要求?
- 假设
R是更小的表 - 分区阶段:每个分区的大小为RB−1\frac{R}{B-1}B−1R
- 构建与探测阶段:要保证分区能够放入B−2B-2B−2个帧里,需要满足RB−1<B−2\frac{R}{B-1}<B-2B−1R<B−2
- 即R<(B−1)(B−2)≈B2R<(B-1)(B-2)\approx B^2R<(B−1)(B−2)≈B2
总结
Join 算法 IO 成本汇总表
| 算法名称 | IO 成本公式 | 示例计算结果 | 近似量级 |
|---|---|---|---|
| SNLJ | R+∣R∣×SR + |R| \times SR+∣R∣×S | 50001000 | ≈ 5000 万 |
| PNLJ | R+R×SR + R \times SR+R×S | 501000 | ≈ 50 万 |
| INLJ | R+∣R∣×(查找RID成本+匹配检索成本)R + |R| \times (\text{查找RID成本} + \text{匹配检索成本})R+∣R∣×(查找RID成本+匹配检索成本) | 401000 | ≈ 40 万 |
| SMJ | 排序R+排序S+R+S\text{排序}R + \text{排序}S + R + S排序R+排序S+R+S | 7500 | ≈ 7.5 千 |
| BNLJ | R+⌈RB−2⌉×SR + \lceil\frac{R}{B-2}\rceil \times SR+⌈B−2R⌉×S | 6000 | ≈ 6 千 |
| GHJ | 2(R+S)+(R+S)2(R+S) + (R+S)2(R+S)+(R+S) | 4500 | ≈ 4.5 千 |
成本从高到低排序
- 简单嵌套循环 > 页嵌套循环 > 索引嵌套循环 > 排序-归并 > 块嵌套循环 > Grace 哈希连接