注:本文为 "语言谱系" 相关合辑。
英文引文,机翻未校。
如有内容异常,请看原文。
A very short introduction to the linguistic Tree Model
语言谱系树模型极简导论
VON MARIA ZIELENBACH · VERÖFFENTLICHT 29/08/2023 · AKTUALISIERT 20/04/2024
170 years ago historical linguistics and the way we think about languages was changed forever (well, kind of). On August 15 1853, German philologist August Schleicher finished his paper „Die ersten Spaltungen des indogermanischen Urvolkes" (‚The first splits of the Indo-European people'). It is widely regarded as the beginning of one of the most important models in historical linguistics: the Tree Model. This model assumes that languages develop through separation from older languages. The development can be depicted in the form of a tree. In this blogpost, I will discuss the basic assumptions of the Tree Model. I will also explain why the Tree Model is often attributed to Schleicher, even though he was not the first to come up with it.
170 年前,历史语言学以及人们对语言的认知方式发生了永久性改变(至少在一定程度上如此)。1853 年 8 月 15 日,德国语文学家奥古斯特·施莱歇尔完成了论文《印欧原始族群的最初分化》。该文普遍被视作历史语言学中重要模型之一------谱系树模型的开端。该模型认为,语言通过从更古老语言中分离的方式演化,这一演化过程可通过树形结构呈现。本文将探讨谱系树模型的基本设定,同时说明为何该模型常被归为施莱歇尔的成果,尽管他并非首个提出该模型的学者。
If you are already familiar with the Tree Model you may want to have a look at my workshop on different models of language diversification:
若你已熟悉谱系树模型,可参阅笔者关于语言分化不同模型的研讨材料:
More on models of language diversification

Schleicher memorial in Sonneberg (Thuringia, Germany)
德国图林根州松讷贝格的施莱歇尔纪念像
What is the Tree Model?
何为谱系树模型?
The most basic assumption of the Tree Model is that some languages are related to each other while others are not. You probably know that e.g., English, German and Dutch are related to each other, as are Italian, Spanish and French. Turkish, Mandarin Chinese and Finnish, on the other hand, are not related to these languages.
谱系树模型最基础的设定为:部分语言之间存在亲缘关系,另一部分语言则无此关联。例如英语、德语、荷兰语彼此同源,意大利语、西班牙语、法语亦彼此同源;而土耳其语、汉语普通话、芬兰语与上述语言均无亲缘关系。
Related languages use similar words and grammatical features. The crucial criterium for relatedness according to the Tree Model is not similarity but the development from a common ancestor. Italian, Spanish and French all derive from Vulgar Latin, the spoken form of Latin. English, German and Dutch can be traced back to a common Proto-Germanic language. Both Proto-Germanic and Latin eventually developed from a common ancestor called Proto-Indo-European. They therefore belong to the Indo-European languages.
有亲缘关系的语言会使用相近的词汇与语法特征。依据谱系树模型,判定亲缘关系的依据并非相似性,而是源自共同祖语的演化历程。意大利语、西班牙语、法语均演化自通俗拉丁语,即拉丁语的口语形式;英语、德语、荷兰语可追溯至共同的原始日耳曼语。原始日耳曼语与拉丁语最终均演化自原始印欧语这一共同祖语,因此同属印欧语系。
Turkish, Chinese and Finnish most likely do not share a common ancestor with the Indo-European languages. If they do, our current methods do not allow for us to attest that.
土耳其语、汉语、芬兰语极大概率与印欧语系无共同祖语;即便存在共同祖语,现有研究方法也无法予以证实。
According to the Tree Model, a language diversifies into multiple languages when the original speaker community splits up into several new communities. Schleicher expressed this in the following way:
依据谱系树模型,当原始语言社群分化为多个新社群时,单一语言便会分化为多种语言。施莱歇尔对此作出如下表述:
"From the way how all Indo-European languages are related to each other, one has rightly deduced, that they come from a common source, that one nation, the Indo-European people, over time split into those eight people, of which each in similar manner further differentiated until finally the diversity of our era came into being."
(Schleicher 1853: 786, my translation) "从所有印欧语言的亲缘关系中可合理推知,这些语言源自同一源头。印欧族群这一单一民族随时间推移分化为八个族群,各支系又以相似方式持续分化,最终形成了当代的语言格局。"
(施莱歇尔,1853:786,笔者译)
Imagine a speaker community, i.e., a group of people who speak the same language, living in a village at the foot of a mountain range. One day a part of this community decides to cross the mountains, hoping for a better life . After the crossing, the 'mountain group' no longer has any contact to the original speaker community. Going back and forth is too difficult. From now on, the language of the original speaker community in the village and the language of the 'mountain group' develop independently. Just like the social group split up, the language split as well.
不妨设想一个语言社群,即使用同一语言的群体,居住在山脉脚下的村落中。某日,社群中的一部分人决定翻越山脉,谋求更好的生活。翻山之后,"山地群体"与原始社群彻底失去联系,往返通行极为困难。自此,村落中原始社群的语言与"山地群体"的语言开始独立演化。社会群体的分化同步带来了语言的分化。
When more members of the original speaker community leave the village and move to a nearby river, the community and language further splits up. Maybe some members of the 'mountain group' decide to travel further towards the sea, another split.
当原始社群中更多人离开村落,迁居至邻近河流区域时,社群与语言会进一步分化;"山地群体"中的部分人或许会继续向沿海地区迁徙,形成又一次分化。
We can depict the splits in our imaginary community in a diagram and voilà: we have a Tree (that is upside down and looks more like a bush, actually):
我们可将这一假想社群的分化过程绘制成图表,由此便得到了一棵树(实际为倒置形态,外观更接近灌木丛):
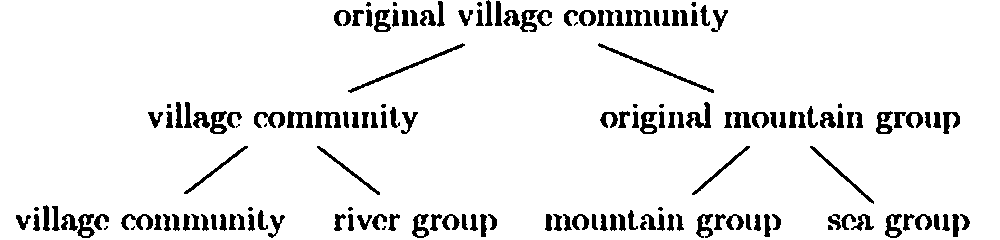
The language of the original village community is the common ancestor of all new languages, including the language of the descendants of those people who never left the village. The languages of the mountain group and the sea group share an additional common ancestor: the language of the original mountain group. This ancestor language is not shared with the languages of the village community and the river group since their speakers never crossed the mountains.
原始村落社群的语言是所有新语言的共同祖语,包括从未离开村落者后裔所使用的语言。山地群体与沿海群体的语言另有一层共同祖语,即原始山地群体的语言;该祖语不为村落社群与河流群体的语言共有,因这两个群体的使用者从未翻越山脉。
In the early days of the Tree Model, splits of peoples and languages were equated. We can see this in Schleicher's first Tree for Indo-European. It does not depict languages like German, Celtic or Greek but peoples like "Deutsche" 'Germans', "Celten" 'Celts' and "Griechen" 'Greeks'.
谱系树模型发展初期,族群分化与语言分化被等同看待。施莱歇尔绘制的首幅印欧语谱系树便体现了这一点,图中未标注德语、凯尔特语、希腊语等语言,而是标注德意志人、凯尔特人、希腊人等族群。
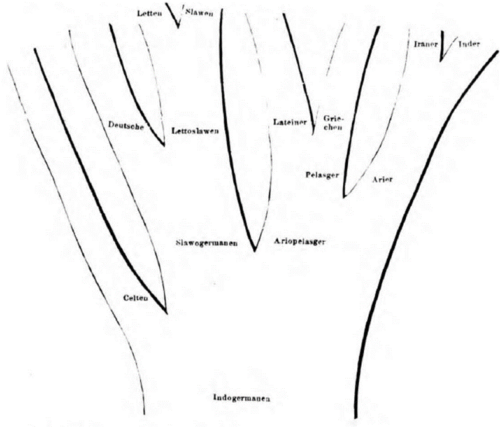
Schleicher's Tree of the Indo-European languages (1853)
施莱歇尔的印欧语谱系树(1853)
Today, the connection between peoples and languages is considered to be more complex. Migrations of peoples are not necessarily identical to the development of the languages they speak today. For example, the ancestors of many people who today live in France and speak French used to speak Celtic languages. Schleicher's second Tree for Indo-European already shows languages, not peoples.
如今,族群与语言的关联被认为更为复杂。族群迁徙并不必然等同于其当代所用语言的演化。例如现今居住在法国、使用法语的人群,其祖先曾使用凯尔特语。施莱歇尔绘制的第二幅印欧语谱系树已改为标注语言,而非族群。
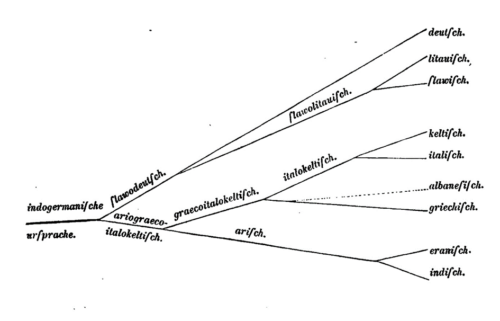
Schleicher's (1861: 7) second Tree of the Indo-European languages
施莱歇尔的第二幅印欧语谱系树(1861:7)
Below you see a modern Tree for Indo-European. The common ancestor of all languages in the Tree is usually depicted at the top. The lines (called branches ) symbolize the splits. You can trace the lines with your finger and get from Proto-Indo-European to Germanic to West Germanic and then finally to Old English and English.
下图为现代印欧语谱系树。树中所有语言的共同祖语通常置于顶端,线条(称为分支)象征分化过程。可沿线条追溯,从原始印欧语依次至日耳曼语族、西日耳曼语支,最终到古英语与现代英语。
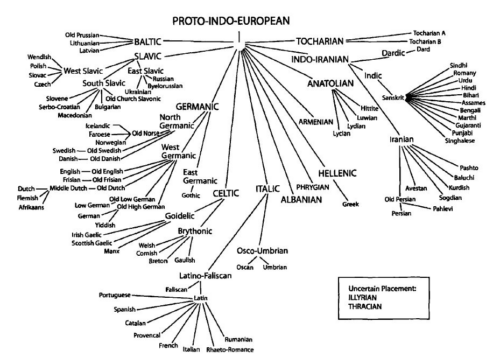
Modern Tree of the Indo-European languages (Anthony 2007: 12)
现代印欧语谱系树(安东尼,2007:12)
How do we create linguistic Trees?
语言谱系树如何构建?
How do we know which languages are related and belong into one Tree? In short: by language comparison.
如何判定哪些语言具有亲缘关系、可归入同一谱系树?简而言之:通过语言比较。
The intuitive answer to this question for you may be: Languages that closely resemble each other are related. And indeed, related languages often show similarities in vocabulary and grammar. But the crucial point is that these similarities must be systematic.
人们对此的直观判断或许是:高度相似的语言具有亲缘关系。事实上,有亲缘关系的语言常在词汇与语法上呈现相似性,但关键前提是这类相似性必须具备系统性。
Have a look at the words from the oldest attested Indo-European languages of each branch:
观察印欧语系各分支最早有文献记载语言的相关词汇:
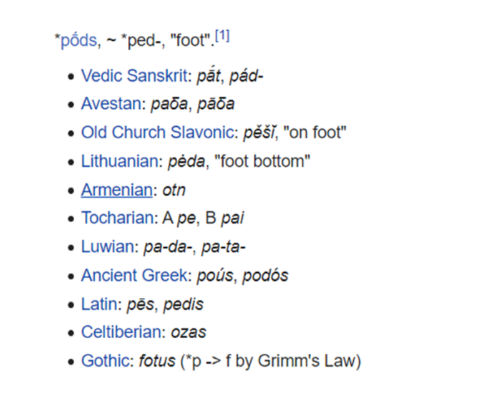
<https://en.wikipedia.org/wiki/Indo-European_sound_laws>
You may notice the following things:
可观察到如下特征:
-
Almost all words start with a
<p>. Except for Gothic, which has<f>, and Armenian and Celtic, which have no consonant at the beginning of the word.几乎所有词汇均以字母 p 开头,仅哥特语以 f 开头,亚美尼亚语与凯尔特语词首无辅音。
-
After that some vowel follows.
辅音后接元音
-
Then follows
<t>,<d>,<s>or no consonant.元音后为 t 、d 、s 或无辅音。
It is obvious that the words are similar. Language relationship is not determined by accidental similarities though. The similarities must be systematic (regular ). For example, Gothic always has an <f> at the beginning of a word where the other languages in the sample have a <p>. Such systematic agreements in sounds are called sound correspondences and they are the most important factor for the Historical Comparative Method . The Historical Comparative Method is the systematic comparison of languages in order to find systematic correspondences in sounds and grammar.
这些词汇的相似性显而易见,但语言亲缘关系并非由偶然相似性判定,相似性必须具备系统性(规律性 )。例如样本中其他语言以 p 开头的词汇,哥特语均以 f 开头。这类语音上的系统性对应关系称为语音对应规律 ,也是历史比较法的重要依据。历史比较法通过系统比较语言,探寻语音与语法层面的系统性对应关系。
Non-systematic similarities between languages are often due to borrowing. For example, Finnish borrowed the word for 'king' kuningas from a Germanic language long ago. The similarity between this word in Finnish and the Germanic languages does not mean that Finnish is a Germanic language.
语言间的非系统性相似性多源于语言借用。例如芬兰语中表示"国王"的 kuningas 一词,很早便借自日耳曼语族语言。该词在芬兰语与日耳曼语中的相似性,并不代表芬兰语属于日耳曼语族。
Sound correspondences result from the shared ancestry of related languages. The new languages continued the words of the ancestor language. When words in different languages developed from the same word in the ancestor language, as in the example with 'foot' words above, we call them cognates . English foot and German Fuß are cognate to Ancient Greek poús or Latin pēs . Such words are inherited from the ancestor language while words such as Finnish kuningas are borrowed . The 'foot'-example also shows that cognates do not have to be obviously similar to each other. Armenian otn does not look like the words in the other languages at all, but thanks to the Historical Comparative Method we know that we have regular sound correspondences in front of us (e.g. Armenian always starts with no consonant where the cognates in the other languages start with a <p>).
语音对应规律源于亲缘语言的共同祖语,新语言会承袭祖语词汇。当不同语言中的词汇演化自祖语中的同一词汇时(如上述表示"脚"的词汇),这类词汇称为同源词 。英语 foot 、德语 Fuß 与古希腊语 poús 、拉丁语 pēs 互为同源词,这类词汇从祖语中承袭 而来,而芬兰语 kuningas 这类词汇则为借用 。"脚"的案例同时说明,同源词未必具备直观相似性。亚美尼亚语 otn 与其他语言中的对应词汇外观差异极大,但借助历史比较法可证实其间存在规律性语音对应(例如其他语言同源词以 p 开头时,亚美尼亚语对应词汇词首均无辅音)。
Besides sound correspondences, agreements in grammar are also used under the Historical Comparative Method. Have a look at the verbal paradigm (verb forms) in Sanskrit, Ancient Greek and Gothic and see if you can find similarities.
除语音对应规律外,历史比较法还会依据语法层面的共性。观察梵语、古希腊语、哥特语的动词变位体系,判断其中是否存在相似性。

(Fortson 2004: 85)
For example, the forms of the second person singular ("you") end with an <-s> in all languages. This is because grammar is also inherited from a common ancestor. The endings are cognate.
例如三种语言中第二人称单数("你")的动词形式均以 -s 结尾,这是因为语法特征同样从共同祖语中承袭而来,这类词尾属于同源形式。
I mentioned above that Gothic has <f> where the other Indo-European languages have <p>. This sound change occurred in all Germanic languages. It distinguishes the Germanic languages from the other Indo-European languages.
前文提及,其他印欧语言以 p 开头的词汇,哥特语均以 f 开头。这一音变现象发生于所有日耳曼语族语言,成为日耳曼语族与其他印欧语言的区分标志。

https://de.wikipedia.org/wiki/Germanische_Sprachen#Gesamtgermanische_Nomina
Shared innovations like this one allow us to further subgroup languages which belong to one language family. Both changes in sounds and grammar are informative about which languages developed together for a while before they split. Shared innovations cannot be traced back to the common ancestor of all related languages but occur in a certain subgroup of languages.
这类共同创新特征可用于对同一语系的语言进行次级分类。语音与语法层面的创新,均可反映哪些语言在分化前曾共同演化。共同创新无法追溯至所有亲缘语言的共同祖语,仅出现于特定语言分支中。
The Historical Comparative Method is the traditional way to create linguistic Trees. But there are more methods. In recent years, Bayesian Phylogenetics has gained popularity. Following this method, large amounts of cognates are processed by a computer that uses Bayesian statistics to detect similarities and create a Tree. Such Trees may be based on a different method but the main assumptions of the Tree Model stay the same.
历史比较法是构建语言谱系树的传统方法,此外还存在其他方法。近年来,贝叶斯系统发育学方法逐渐普及。该方法通过计算机处理海量同源词数据,运用贝叶斯统计识别语言相似性并生成谱系树。这类谱系树虽采用不同方法构建,但谱系树模型的基本设定保持不变。
In summary, linguistic Trees depict changes (innovations) within groups of related languages. All related languages developed from a common ancestor language. But this is only part of the history of a language. I already mentioned that speakers can adopt (borrow) words, and also grammatical features, from other languages when they come into contact with speakers of this language. Contact is not depicted in a Tree. For example, English borrowed a huge amount of vocabulary from French and in this way differs from the other Germanic languages. You won't find the intense contact between English and French in a Tree because the Tree Model is 'blind' for this kind of relationship between languages.
综上,语言谱系树呈现亲缘语言群体内部的演变(创新)过程,所有亲缘语言均演化自同一祖语。但这仅为语言历史的一部分。前文已提及,语言使用者在与其他语言使用者发生接触时,会从对方语言中吸纳(借用)词汇乃至语法特征,而语言接触无法在谱系树中体现。例如英语从法语中借用了大量词汇,由此与其他日耳曼语族语言产生差异;谱系树无法反映英语与法语间的密切接触,因该模型对这类语言关联不具备表征能力。
In reality, languages often do not split abruptly from a common ancestor, as the branching in a Tree suggests. Speakers tend to have contact for a while after they moved apart.
现实中,语言通常不会如谱系树分支所示,从共同祖语中突然分化;社群分离后,使用者往往仍会保持一段时间的语言接触。
Linguistic Trees are only a model of language history, which is based on certain theoretical assumptions. They are not an exhaustive history of all languages depicted in a Tree.
语言谱系树仅是基于特定理论设定的语言历史模型,无法完整呈现所涵盖语言的全部演化历程。
How did the Tree Model develop?
谱系树模型的发展历程
Finally, a brief history of the Tree Model. I said in the introduction that August Schleicher is often seen as the "father" of the Tree Model. Even the street sign of a street named after Schleicher in Sonneberg (Thuringia, Germany) says so.
最后简述谱系树模型的发展历史。引言中提到,奥古斯特·施莱歇尔常被视作谱系树模型的"创立者",德国图林根州松讷贝格市以其命名的街道标识亦如此标注。
Schleicherstraße in Sonneberg ("Founder of the Tree Model in comparative linguistics")
松讷贝格市的施莱歇尔街(标注文字:"比较语言学谱系树模型创立者")
But Schleicher only summarized in his 1853 article what many scholars already new at this time (he says so himself in the article). The depiction of language history in the form of a tree goes back at least to the 17th century. Look at this beautiful tree by Gallet from ~1880.
但施莱歇尔在 1853 年的论文中,仅是总结了当时学界已有的共识(他在文中亦明确提及这一点)。以树形结构呈现语言历史的做法,最早可追溯至 17 世纪。下图为加莱约 1880 年左右绘制的精美语言谱系树。
Language tree by Gallet (ca. 1880)
加莱约绘制的语言谱系树(约 1880 年)
The basic assumption of the Tree Model that languages develop from older languages does not go back to Schleicher either. In 1786, Sir William Jones presented his theory on the shared origin of Sanskrit (Old Indian) and several ancient European languages such as Latin and Ancient Greek. Especially one passage is now infamous among linguists:
谱系树模型中"语言由更古老语言演化而来"的基本设定,同样并非施莱歇尔首创。1786 年,威廉·琼斯爵士提出理论,认为梵语(古印度语)与拉丁语、古希腊语等多种欧洲古代语言具有共同起源。其中一段论述在语言学界广为流传:
"The Sanscrit language, whatever be its antiquity, is of a wonderful structure; more perfect than the Greek, more copious than the Latin, and more exquisitely refined than either, yet bearing to both of them a stronger affinity, both in the roots of verbs and the forms of grammar, than could possibly have been produced by accident; so strong indeed, that no philologer could examine them all three, without believing them to have sprung from some common source, which, perhaps, no longer exists; there is a similar reason, though not quite so forcible, for supposing that both the Gothic and the Celtic, though blended with a very different idiom, though blended with a very different idiom, had the same origin with the Sanscrit; and the old Persian might be added to the same family ...."
(Sir William Jones 1786)
"梵语无论年代如何久远,其结构都精妙绝伦:比希腊语更完备,比拉丁语更丰富,比二者更精致典雅,却在动词词根与语法形式上与这两种语言存在极强关联,这种关联绝非偶然。任何语文学家考察这三种语言后,都会相信它们源自同一源头,该源头或许已不复存在。基于相似理由(尽管说服力稍弱),可推断哥特语与凯尔特语虽融入迥异语言特征,仍与梵语同源,古波斯语亦可归入同一语系......"
(威廉·琼斯爵士,1786)
Jones is basically saying the same thing as Schleicher did 70 years later. Schleicher built on the work his predecessors and colleagues had already done. His main contribution in 1853 was the summary of the state of the art at this point in time.
琼斯的基本观点与 70 年后的施莱歇尔基本一致。施莱歇尔的研究建立在前人与同行的成果之上,他在 1853 年的主要贡献,是对当时该领域的研究现状进行了系统总结。
Sources
参考文献
Campbell, Lyle. 2013. Historical linguistics : An Introduction. Edinburgh: Edinburgh Univ. Press.
坎贝尔,莱尔. 2013. 历史语言学导论. 爱丁堡:爱丁堡大学出版社.
Jones, Sir William. 1824. Discourses delivered before the Asiatic Society: and miscellaneous papers, on the religion, poetry, literature, etc., of the nations of India . Printed for C. S. Arnold.
琼斯,威廉爵士. 1824. 亚洲学会演说集及印度诸民族宗教、诗歌、文学杂论. C. S. 阿诺德出版社.
List, Johann-Mattis, Jananan Sylvestre Pathmanathan, Philippe Lopez & Eric Bapteste. 2016. Unity and disunity in evolutionary sciences: process-based analogies open common research avenues for biology and linguistics. Biology Direct 11(1). 39. doi:10.1186/s13062-016-0145-2
利斯特,约翰-马蒂斯、帕马纳坦,贾纳南·西尔维斯特、洛佩兹,菲利普、巴普泰斯特,埃里克. 2016. 演化科学中的统一与分化:基于过程的类比为生物学与语言学开辟共同研究路径. 生物学导刊, 11(1): 39.
Schleicher, August. 1853. Die ersten Spaltungen des indogermanischen Urvolkes. Allgemeine Zeitung für Wissenschaft und Literatur .
施莱歇尔,奥古斯特. 1853. 印欧原始族群的最初分化. 科学与文学综合报.
Schleicher, August. 1861. Compendium der vergleichenden Grammatik der indogermanischen Sprachen. Band 1 (Kurzer Abriss der indogermanischen Ursprache, des Altindischen, Altiranischen, Altgriechischen, Altitalischen, Altkeltischen, Altslawischen, Litauischen und Altdeutschen.) Weimar: H. Boehlau.
施莱歇尔,奥古斯特. 1861. 印欧语言比较语法纲要. 第一卷(印欧原始语、古印度语、古伊朗语、古希腊语、古意大利语、古凯尔特语、古斯拉夫语、立陶宛语与古德语简述). 魏玛:H. 伯劳出版社.
Trask, Larry. 2015. Trask's Historical Linguistics. Robert McColl Millar(ed.). London, New York: Routledge.
特拉斯克,拉里. 2015. 特拉斯克历史语言学. 米勒,罗伯特·麦科尔 编. 伦敦、纽约:劳特利奇出版社.
OpenEdition schlägt Ihnen vor, diesen Beitrag wie folgt zu zitieren:
Maria Zielenbach (29. August 2023). A very short introduction to the linguistic Tree Model. Bäume, Wellen, Inseln - Trees, Waves and Islands . Abgerufen am 24. März 2026 von https://doi.org/10.58079/pf40
OpenEdition 建议本文引用格式:
玛丽亚·齐伦巴赫(2023 年 8 月 29 日). 语言谱系树模型极简导论. 《树、波与岛》. 2026 年 3 月 24 日 取自 https://doi.org/10.58079/pf40
Trees, Waves and Friends
谱系树、波浪说与语言亲缘关系
Maria Zielenbach
May 2023
In this workshop, we will explore different models of language diversification and the methods they utilize. Models of language diversification try to explain how the many languages on Earth developed (diversified) and how they are related to each other.
本次工作坊将探讨语言分化的不同模型及其所用方法。语言分化模型旨在解释地球上众多语言如何形成(分化),以及语言之间的亲缘关系。
More precisely we will discuss:
具体而言,我们将讨论:
-
The Traditional Tree Model: the genealogical/genetic Trees we all know (and many love)
传统谱系树模型:我们熟知(且许多人推崇)的谱系/亲缘树
-
The Traditional Wave Model: a model intended to be a alternative to the Tree Model but which never really took off (for reasons)
传统波浪模型:本欲作为谱系树模型替代方案、却始终未真正流行的模型(原因见下文)
-
Historical Glottometry: a revised version of the Wave Model
历史语言计量法:波浪模型的改良版本
-
Traditional Lexicostatistics: a quantitative method to infer language Trees which has now mostly been abandoned
传统词汇统计学:用于推演语言谱系树的定量方法,如今已基本被弃用
-
Bayesian Phylogenetics: a new quantitative method to infer language Trees based on Bayesian statistics
贝叶斯系统发生学:基于贝叶斯统计学的新型语言谱系树定量推演方法
The learning goals of the workshop are as follows:
工作坊学习目标如下:
-
acquire a 'passive reading knowledge' of the different models and methods
掌握各类模型与方法的基础认读能力
-
understand that language relatedness and classification is not a theory free issue and that models of language diversification are controversially debated among linguists
理解语言亲缘关系与分类并非无理论预设的问题,语言分化模型在语言学界存在争议
-
understand that not every language tree is based on the same assumptions and method
理解并非所有语言谱系树都基于相同假设与方法
For each model or method we will answer the questions:
针对每个模型或方法,我们将解答以下问题:
-
What does it do and what does it assume?
其功能与预设是什么?
-
How are the findings depicted and how to evaluate them?
研究结果如何呈现、如何评价?
-
What are the pros and cons?
优势与局限是什么?
-
How is the model/method regarded today?
该模型/方法在当下的认可度如何?
There are many more methods and models that could be discussed in this context. We will quickly look at some of them in the last part of the workshop. You will notice that the focus during the discussion of the models and methods lays on the debates around them instead of their individual details. This is done on purpose because I believe it is easier to read up the facts about a model or method. I have also excluded some arguments of the ongoing debate in order to fit the topic into a 1,5h session. One question you may want to ponder for yourself is how each model defines a 'language'.
本主题下尚有更多可讨论的方法与模型,工作坊最后部分将快速概览其中几种。你会发现,模型与方法的讨论重点围绕相关争议展开,而非细节本身。这一安排是刻意为之,因为我认为模型或方法的具体事实更易通过查阅资料掌握。为将主题压缩至 1.5 小时课时,我也删减了部分现有争议中的论点。你不妨自行思考一个问题:每个模型如何定义"语言"。
1 Important terminology
1 重要术语
Before we start, here are some important terms that we will use throughout the workshop.
正式开始前,先介绍工作坊全程会用到的核心术语。
1.1 Cognates
1.1 同源词
Cognates are (lexical and grammatical) morphemes in different languages which derive from the same morpheme in the proto-language. Sometimes you will read that cognates are morphemes that "share form and function". While most cognates do that, detecting similarity is only the first step in finding possible cognates. Many linguists require regular sound correspondences in order to establish legit cognacy. Proposed cognates without establish sound correspondences are suspicious of being mere 'look-alikes'. Cognates are establish through the historical comparative method. (cf Campbell (2013: 110), (Trask 2015: 193))
同源词是不同语言中源自原始语同一语素的(词汇与语法)语素。有时你会看到同源词被定义为"形式与功能一致"的语素。多数同源词确实符合这一特征,但识别相似性只是寻找潜在同源词的第一步。许多语言学家要求规则语音对应 才能确立有效同源关系,无语音对应的拟同源词易被质疑为仅"形似"。同源词通过历史比较法确立。(参见 Campbell 2013: 110;Trask 2015: 193)
1.2 Proto-language
1.2 原始语
The language from which all related languages have developed. In one way or the other, all the models and methods discussed in this workshop assume that languages diversify from one language into several mutually unintelligible languages ('divergence'). The original ancestor language is the Proto-language and the diversified languages are often called daughter languages. If not attested, a Proto-language can be reconstructed through the Historical Comparative Method. (cf Campbell (2013: 107), (Trask 2015: 167))
所有亲缘语言共同源自的语言。本工作坊讨论的所有模型与方法均预设:语言由单一母语分化为多种互不相通的语言(即"分化")。这一原始祖语即原始语 ,分化后的语言常称子语言 。无文献佐证的原始语可通过历史比较法重构。(参见 Campbell 2013: 107;Trask 2015: 167)
1.3 The Historical Comparative Method
1.3 历史比较法
The Historical Comparative Method (HCM) strives to reconstruct the Proto-language from which all related languages are derived through establishing regular correspondences in phonology and morphology between languages. The HCM is closely linked to the Neogrammarians (germ. 'Junggrammatiker') who postulated that sound laws suffer no exceptions (Germ. 'Ausnahmslosigkeit der Lautgesetze'). ¹ (cf Campbell (2013: 107ff), Trask (2015: 191ff))
历史比较法(HCM)通过确立语言间音系与形态的规则对应关系,重构所有亲缘语言的原始语。该方法与新语法学派 紧密相关,学派主张语音规律无例外。¹(参见 Campbell 2013: 107 起;Trask 2015: 191 起)
¹You may wonder why the HCM is not discussed as one of main topics of this workshop. This has the following reasons: Firstly, understanding its basic principles usually is not a problem but going into the details would require a workshop of its own and secondly, information on this method is readily available everywhere.
¹你或许会疑惑,为何历史比较法未作为工作坊核心主题讨论。原因如下:第一,其基本原理不难理解,但深入细节需单独开设工作坊;第二,该方法的相关资料随处可得。
1.4 Shared retentions, shared innovations, horizontal diffusion and parallel evolution
1.4 共同保留特征、共同创新特征、横向扩散与平行演化
Shared retentions, shared innovations, horizontal diffusion and parallel evolution are four explanations for similarities between languages. Shared retentions (symplesiomorphies) are features, lexemes etc. which have been directly inherited from an ancestor language. Shared retentions cannot be used for subgrouping since all languages that developed from one ancestor language are per default supposed to have the same features. If the features, lexemes etc. of an ancestor language are not retained in a daughter language, the new features, lexemes are called shared innovations (synapomorphies). Shared innovations are the main diagnostic for subgrouping. If two or more languages share a feature, lexeme etc. but they are not genetically related, it may have been a borrowing from one language into the other. This is called (horizontal) diffusion. If a shared feature, lexeme etc. cannot be explained as either a shared retention, shared innovation or diffusion, its occurrence may be due to parallel evolution (homoplasies), i.e. the development of the same feature etc. in two unrelated languages by accident. (cf (Jacques & List 2019: 137))
共同保留特征、共同创新特征、横向扩散与平行演化是解释语言相似性的四种路径。共同保留特征 (近祖共性)是直接继承自祖语的特征、词位等,无法用于次分类,因为同一祖语分化的所有语言默认具备相同特征。若子语言未保留祖语特征、词位等,新生特征与词位即为共同创新特征 (近裔共性),是次分类的核心依据。若两种或多种语言共享某特征、词位等却无亲缘关系,可能是语言间的借用,即横向扩散 。若共享特征、词位等无法用上述三种路径解释,则可能源于平行演化(同形现象),即无亲缘关系的语言偶然形成相同特征。(参见 Jacques & List 2019: 137)
2 The Traditional Tree Model
2 传统谱系树模型
The Tree Model (Germ. Stammbaummodell) is the model in historical linguistics. It is usually attributed to German philologist August Schleicher (1821-1868), however, there are language trees that precede Schleicher's (1853) paper (cf. List et al. (2016)).
谱系树模型(德语:Stammbaummodell)是历史语言学的经典模型,通常归为德国语言学家奥古斯特·施莱歇尔(1821--1868)提出,但施莱歇尔 1853 年论文发表前已存在语言谱系树。(参见 List et al. 2016)
"Aus der Art und Weise, wie sämmtliche indogermanische Sprachen unter einander verwandt sind, schloss man nun mit Recht, dass sie aus einer Urspache entsprungen seien, dass eine Nation, das indogermanische Urvolk, sich mit der Zeit in jene acht Völker getheilt habe, von denen jedes in ähnlicher Weise sich später wieder differenziirte, bis endlich die Mannigfaltigkeit unserer Epoche erstand." (Schleicher 1853: 786)
"从所有印欧语言的亲缘关系模式出发,我们有充分理由推断它们源自同一原始语;一个民族,即印欧原始族群,随时间分化为八个部族,每个部族后续以相似方式再度分化,最终形成我们这个时代的语言多样性。"(施莱歇尔 1853: 786)
2.1 What does it do and what does it assume?
2.1 功能与预设
-
The Tree Model assumes that language diversify through abrupt splits from an ancestor language and isolated development of the new varieties.
谱系树模型预设:语言通过祖语突然分裂 与新变体独立演变实现分化。
-
Related languages are sorted into smaller genetic groups ('subgrouping') based on shared innovations established through the Historical Comparative Method. The languages in these subgroups are more closely related.
基于历史比较法确立的共同创新特征,将亲缘语言归入更小的亲缘族群(即"次分类"),同组语言亲缘关系更近。
-
Contact phenomena (e.g. borrowing) are treated as a kind of anomaly since the Tree Model only considers inherited material ('vertical descent').
该模型仅关注垂直传承的继承性成分,将借用等接触现象视为例外。
2.2 How are the findings depicted and how to evaluate them?
2.2 结果呈现与评价
-
Traditional Trees usually proceed from top to bottom or left to right, with the proto-language (German Ursprache) at the top or left side.
传统谱系树通常自上而下或自左向右绘制,原始语(德语:Ursprache)位于顶端或左侧。
-
Every node in the tree represents a split. The language that heads the node is the proto-language from which the languages at the end of each line below the node developed. All languages below a node form a subgroup.
树中每个节点代表一次分裂,节点顶端的语言为原始语,节点下各分支末端语言由其分化而来,同一节点下所有语言构成一个次分类。
-
Authors should tell you which shared innovations their Tree is based on. A subgroup should be based on more than one shared innovation.
研究者应说明谱系树依据的共同创新特征,一个次分类需基于多项共同创新特征。
2.3 What are the pros and cons?
2.3 优势与局限
-
Tree diagrams are easy to read and understand.
谱系树图表直观易懂。
-
Opponents claim that the Tree Model oversimplifies the history of the languages, leaving out contact phenomena and hence half of the story.
批评者认为该模型过度简化语言史,忽略接触现象,缺失关键部分。
-
Opponents say languages do not usually diversify in isolation and that the Tree Model overconventionalizes the rare cases in which this happens as the general model of language diversification: "In a nutshell, cladistic (tree-based) representations are entirely based on the fiction that the main reason why new languages emerge is the abrupt division of a language community into separate social groups. Trees fail to capture the very common situation in which linguistic diversification results from the fragmentation of a language into a network of dialects which remained in contact with an extended period of time" (François 2014: 162)
批评者指出,语言通常并非孤立分化,谱系树模型将罕见的孤立分化特例泛化为普遍模式:"简而言之,支序分类(谱系树)表述完全基于一个虚构前提------新语言诞生的主因是语言社群突然分裂为独立社会群体。语言分化的常见情形是:一种语言裂变为方言网络,且方言间长期保持接触,而谱系树无法刻画这一过程。"(François 2014: 162)
-
The Tree Model relies on bundles of shared innovations for subgrouping. These are often difficult to find for closely related languages that have always been in close contact ('dialect continuum', 'linkage'). Network-like representations have been proposed as an alternative (cf Jacques & List 2019).
该模型依赖成组共同创新特征做次分类,对于长期密切接触的近缘语言(方言连续体、联结型语言),这类特征往往难以找到,因此有学者提出网络状表述作为替代。(参见 Jacques & List 2019)
-
Advocates of the Tree Model usually reply to these issues that the Tree Model is not meant to capture every part of language history ('models are simplifications per definition')
支持者回应:谱系树模型本就无意刻画语言史的全部细节("模型本质即是简化")。
-
Subgroupings are subjective: they are based on the decisions of individuals (Bayesian Phylogenetics is supposed to help out here).
次分类具有主观性,依赖研究者个人判断(贝叶斯系统发生学试图解决这一问题)。
2.4 How is it regarded today?
2.4 当下认可度
-
the Tree Model remains as the standard model of historical linguistics
谱系树模型仍是历史语言学的标准模型。
-
when linguists talk about 'related' they usually mean 'related in the sense of the tree model' and the goal of many historical endeavours is to find the best tree for a language family
语言学家提及"亲缘关系"时,通常指谱系树模型意义上的亲缘关系;诸多历史语言学研究的目标是为语系构建最优谱系树。
2.5 Literature
2.5 参考文献
-
Campbell (2013), chap. 6.4, 7
Trask (2015: 169-172)
-
Carling et al. (2022)
François (2014): critical assessment of the Tree Model (also see the other papers under Historical Glottometry)
3 Traditional Lexicostatistics
3 传统词汇统计学
Traditional Lexicostatistics is an early quantitative approach to genetic classification based on shared lexicon. It was developed in the 1950s by Morris Swadesh (1909-1967) with the aim to introduce a means for dating branching events.
传统词汇统计学是基于共享词汇的早期亲缘分类定量方法,由莫里斯·斯瓦迪士(1909--1967)于 20 世纪 50 年代提出,旨在为语言分化事件提供测年手段。
"The fundamental everyday vocabulary of any language -- as against the specialized or "cultural" vocabulary -- changes at a relatively constant rate. The percentage of retained elements in a suitable test vocabulary therefore indicates the elapsed time." (Swadesh 1952: 452)
"任何语言的基础日常词汇(区别于专业或'文化'词汇)以相对恒定的速率演变,因此合适测试词汇中的保留比例可反映时间跨度。"(斯瓦迪士 1952: 452)
3.1 What does it do and what does it assume?
3.1 功能与预设
-
Lexicostatistics measures relatedness between two languages based on lexical similarity.
词汇统计学基于词汇相似度衡量两种语言的亲缘关系。
-
Standardized word lists ('Swadesh lists') are use which cover is allegedly 'stable' vocabulary which is unlikely to be borrowed ('basic vocabulary').
使用标准化词表("斯瓦迪士词表"),涵盖据称稳定、不易被借用的"基础词汇"。
-
Lexicostatistics assumes that lexical similarity of basic vocabulary is lost at a consonant rate, this is used to date branching events = glottochronology (in analogy to carbon dating, cf Swadesh (1952: 452, 454))
该模型预设:基础词汇的相似度以恒定速率 丧失,据此为分化事件测年,即语言年代学(类比碳十四测年法,参见斯瓦迪士 1952: 452、454)。
3.2 How are the findings depicted and how to evaluate them?
3.2 结果呈现与评价
-
Sometimes the results of a lexicostatistic survey is depicted in a tree, these can be read like traditional trees (but be careful: they are based on a completely different methods).
词汇统计学结果有时以谱系树呈现,阅读方式与传统谱系树一致(但需注意:二者方法完全不同)。
-
Another means of depicting lexicostatistic results are matrices that show the similarity between each compared language.
另一种呈现方式是相似度矩阵,展示各对比语言间的相似程度。
-
Authors should tell you how they chose the languages they compare and how they identified the 'cognates'.
研究者应说明语言选取与"同源词"判定方法。
3.3 What are the pros and cons?
3.3 优势与局限
-
Well, it's easy.
操作简便。
-
Lexicostatistics can give a first impression of how similar languages are.
可快速获得语言相似度的初步判断。
-
There are several problems with using standardized concept word lists: "concept fuzziness" (some concepts are hard to translate, e.g. 'love', 'know' etc.), "synonymous differentiation" (concept is divided among several lexemes in a language, e.g. many languages don't have a word for 'bird (in general)' but only for specific species), "linguistic diversity" ("different translations for the basic concept, due to dialectal or sociolinguistic variation", e.g. watch vs observe vs monitor) (Geisler & List 2010: 3)
-
标准化概念词表存在诸多问题:"概念模糊性"(部分概念难翻译,如"爱""知道")、"同义分化"(一个概念由多个词位表达,如许多语言无泛指"鸟"的词,仅含具体物种名称)、"语言多样性"(基础概念因方言或社会语言变异存在不同译法,如 watch/observe/monitor)。(Geisler & List 2010: 3)
-
'Stability' of vocabulary can vary, every part of the lexicon and grammar can be borrowed.
词汇"稳定性"并非绝对,词汇与语法的所有部分均可被借用。
-
In a perfect world, lexicostatistics would be used for languages whose relatedness has already been establish, based on real cognates. But in the past, linguists have often used superficial lookalikes from superficially similar languages to establish relatedness through lexicostatistics (also cf Geisler & List (2010: 3-4) for more problems with cognacy).
理想情况下,词汇统计学应应用于已确立亲缘关系、基于真实同源词的语言,但过去研究者常以表面相似语言的形似词,通过词汇统计学判定亲缘关系。(同源关系的更多问题参见 Geisler & List 2010: 3--4)
3.4 How is it regarded today?
3.4 当下认可度
-
Glottochronoly was generally rejected: languages don't change at the prescribed constant rates.
语言年代学已被普遍否定:语言演变并非遵循预设恒定速率。
-
Swadesh's lists are now living a second life as elicitation tools in language documentation.
斯瓦迪士词表如今在语言记录中作为语料提取工具重新使用。
-
"The finding of substantial rate variation in languages was so damaging to glottochronology that historical linguistics largely rejected quantitative methods. Today, lexicostatistics and glottochronology are seen as textbook examples of bad linguistic methodology, and we are told that 'linguists do not do dates"' (Greenhill et al. 2021: 227)
"语言演变速率存在显著差异这一发现,对语言年代学造成致命打击,也导致历史语言学基本摒弃定量方法。如今,词汇统计学与语言年代学被视为语言学错误方法论的教科书案例,甚至有观点认为'语言学家不做测年'。"(Greenhill et al. 2021: 227)
3.5 Literature
3.5 参考文献
- Swadesh's original method: Swadesh (1950), Swadesh (1952), Swadesh (1955)
- Greenhill et al. (2021): historical overview from lexicostatistics to Bayesian phylogenetics
- Geisler & List (2010): critical assessment of the method
4 Bayesian Phylogenetics
4 贝叶斯系统发生学
Bayesian Phylogenetics is a new method of doing lexicostatistics which is based on methods from biology and Bayesian statistics. It is claimed to balance out the shortcomings of Traditional Lexicostatistics and Traditional Trees. It is very important to understand that it is not just a 'modern' method to infer a genetic Tree but that it relies on different theoretical and methodological assumptions (cf Carling et al. (2022)).
贝叶斯系统发生学是基于生物学方法与贝叶斯统计学的新型词汇统计方法,宣称可弥补传统词汇统计学与传统谱系树的缺陷。需明确:它并非仅为构建亲缘树的"现代"方法,其理论与方法预设均与传统方法不同。(参见 Carling et al. 2022)
"The approach infers a sample of trees that have a high probability of explaining the patterns in the data under a specified model of character change." (Greenhill et al. 2021: 229)
"该方法在指定特征演变模型下,推演一组高概率解释数据模式的谱系树样本。"(Greenhill et al. 2021: 229)
4.1 What does it do and what does it assume?
4.1 功能与预设
-
Bayesian Phylogenetics can process large data sets (better than humans).
可处理大规模数据集(优于人工)。
-
It can: "evaluate subgrouping hypothesis", "date language divergences", "estimate ancestral states", "infer rates of change in lexical and grammatical traits", "test hypotheses of functional dependencies in linguistic features", "infer geographic homelands and migration routes" (Greenhill et al. 2021: 228-229)
功能包括:"次分类假设检验""语言分化测年""祖语状态估算""词汇与语法特征演变速率推演""语言特征功能依赖假设检验""起源地与迁徙路线推演"。(Greenhill et al. 2021: 228--229)
-
Instead of one tree, a a bunch of trees (forest) is generated. The trees in the forest are rated due to their probability. There are different ways to generate forests.
不生成单棵谱系树,而是生成一组谱系树(树簇),按概率评分,树簇生成方式多样。
-
Like lexicostatistics, Bayesian phylogenetics can be misused, especially when non-specialists take data from random languages without establishing relatedness or cognacy first.
与词汇统计学类似,该方法易被滥用,尤其非专业研究者未先确立亲缘与同源关系就随意取用语言数据时。
-
The data comes in the form of word lists (e.g. Swadesh's 200-meaning list), coded for cognacy beforehand.
数据以词表形式输入(如斯瓦迪士 200 词表),需预先完成同源编码。
-
Bayesian phylogenetics does not directly use sound changes as diagnostics for subgrouping, instead cognates are assumed to entail these innovations.
不直接以语音变化作为次分类依据,而是预设同源词包含创新特征。
-
Splits are dated based on historical information which is then extrapolated to parts of the tree for which no historical records exist, instead of using set rates for all language families ('relaxed clock').
分化测年基于历史信息,外推至无历史记录的谱系树分支,而非对所有语系使用固定速率(即"宽松分子钟")。
4.2 How are the findings depicted and how to evaluate them?
4.2 结果呈现与评价
- Consensus trees show the common denominator of the forest, the little numbers next to the branches show the probability of each subgroup ('clade') aka the percentage of generated trees in the forest that include this subgroup
共有树展示树簇的共性结果,分支旁数字表示各次分类(演化支)的概率,即树簇中包含该次分类的谱系树占比。 - Densitrees show all probably generated trees on top of each other and hence the uncertainties
密度树将所有高概率谱系树叠加呈现,直观展示不确定性。 - Authors should tell you how they chose the languages they compare and how they identified the 'cognates'. There should be an in-depth discussion of the methodology (including the code!).
- 研究者应说明语言选取与同源词判定方法,并深入阐述方法细节(含代码)。
4.3 What are the pros and cons?
4.3 优势与局限
- Well, it's not easy.
操作复杂。 - Opponents say Bayesian Phylogenetics is just fancy lexicostatistics and can't make up for the latter's problems -- advocates usually claim that opponents don't understand the method.
批评者认为该方法只是"包装精致的词汇统计学",无法弥补传统词汇统计学的缺陷;支持者则称批评者未理解方法本质。 - Opponents say that the method invites non-specialist to process huge amounts of data that they understand which leads to wrong findings (which are published in fancy journals anyways) -- advocates usually agree with this point (data must therefore be pre-curated by specialists).
批评者指出,该方法易吸引非专业研究者处理自身无法理解的海量数据,导致错误结论(却仍能发表于高端期刊);支持者通常认同这一观点(因此数据需经专业人员预处理)。 - The word lists in Bayesian phylogentics show the same problems as the word lists used in lexicostatistics (cf above)
所用词表存在与传统词汇统计学词表相同的问题(见上文)。 - Bayesian phylogenetics shares the main assumptions of Traditional Trees: contact phenomena are seen as noise not as an fundamental part of language history. If you have a problem with Traditional Trees you will also have a problem with trees produced by Bayesian Phylogenetics.
与传统谱系树核心预设一致:将语言接触视为噪声,而非语言史的核心部分;若不认同传统谱系树,也会不认同该方法生成的谱系树。 - Advocates claim that matches between result of Bayesian phylogenetics and traditional trees prove that the method works.
支持者称,该方法结果与传统谱系树的一致性证明其有效性。
4.4 How is it regarded today?
4.4 当下认可度
- Bayesian Phylogenetics has gained extreme popularity in the past years.
贝叶斯系统发生学近年极度流行。
4.5 Literature
4.5 参考文献
- Greenhill et al. (2021): comprehensive overview of theory and methodology
- Evans et al. (2021)
https://www.youtube.com/watch?v=KOZDaFM_MnY: lecture about Bayesian Phylogenetics - cf Greenhill et al. (2021) and Simon Greenhill's Website for more publications
5 The Traditional Wave Model
5 传统波浪模型
The Wave Model (German Wellentheorie) was developed as an alternative to the Tree Model. It is usually attributed to Johannes Schmidt (1843-1901, Schmidt (1872)) but was actually proposed a little earlier by Hugo Schuchardt (1842-1927, Schuchardt (1868), cf also Schuchardt (1885)).
波浪模型(德语:Wellentheorie)作为谱系树模型的替代方案提出,通常归为约翰内斯·施密特(1843--1901,施密特 1872),实际由胡戈·舒哈特(1842--1927,舒哈特 1868)更早提出。(另见舒哈特 1885)
"Ich möchte an stelle des baumes das bild der welle setzen, welche sich in concentrischen mit der entfernung vom mittelpunkte immer schwächer werdenden ringen ausbreitet." (Schmidt 1872: 27)
"我愿用波浪图景替代谱系树:波浪以同心圆扩散,距中心越远强度越弱。"(施密特 1872: 27)
5.1 What does it do and what does it assume?
5.1 功能与预设
- The Wave Model assumes that dialect continuums are the most common state of languages (languages are never uniform, huge intra-language variation is the norm), therefore the Wave Model claims to have greater historical accuracy than the Tree Model
波浪模型预设:方言连续体是语言的普遍状态(语言从不统一,内部高度变异是常态),因此宣称历史真实性优于谱系树模型。 - Innovations are assumed to start in one variety and then 'wave' over adjacent varieties which adopt the innovations, likewise innovations within a variety (e.g. sound changes) start in one word and then 'wave' over to other words. Diversification evolves through slow divergence of varieties first into dialects and then into languages.
- 预设创新始于某一变体,再以"波浪"形式扩散至相邻变体并被采纳;变体内部创新(如语音变化)同理,始于单个词汇再扩散至其他词汇。语言分化遵循"变体→方言→语言"的缓慢演变路径。
- "Since later changes may not cover the same area, there may be no sharp boundaries between neighbouring dialects or languages; rather, the greater the distance between them, the fewer linguistic traits dialects or languages may share." (Campbell 2013: 188)
"由于后续变化覆盖范围不同,相邻方言或语言间无清晰边界;距离越远,共享语言特征越少。"(Campbell 2013: 188)
5.2 How are the findings depicted and how to evaluate them?
5.2 结果呈现与评价
- 'Wave diagrams' usually show a number of languages/varieties, displayed according to their geographic location. This depiction was popularized by Bloomfield (1933)³¹⁶.
波浪图通常按地理位置展示多种语言/变体,这一呈现方式由布龙菲尔德(1933)推广。 - Lines are used to show the overlapping shared features, all varieties within a circle share a specific feature.
用线条表示重叠共享特征,圆圈内所有变体共享某一特定特征。 - Authors should demonstrate why they don't assume that a branching event has taken place.
研究者应说明为何不预设发生分支事件。
5.3 What are the pros and cons?
5.3 优势与局限
- The Wave Model targets areas where the Tree Model fails (or has been claimed to fail), i.e. dialects and other closely related varieties.
聚焦谱系树模型失效(或被宣称失效)的场景,即方言及其他近缘变体。 - The Wave Model does not distinguish between variety internal changes and changes that are due to contact (the processes are not distinguished).
不区分变体内部演变 与接触引发的演变(未区分过程)。 - Sound changes are claimed to show exceptions but opponents say that exceptions can only be found because we know the regular sound changes.
宣称语音变化存在例外;批评者则认为,例外的发现恰恰依赖对规则语音变化的认知。 - 'Wave diagrams' may be more faithful to the synchronic distribution of linguistic features but do not have a diachronic depths (they show that features diffused but not when and how), they are also more messy than trees.
波浪图更贴合语言特征的共时分布 ,但缺乏历时深度(仅展示特征扩散,未说明时间与方式),且图表比谱系树更繁杂。
5.4 How is it regarded today?
5.4 当下认可度
- The Wave Model never received the same popularity as the Tree Model in historical linguistics but you may encounter it from time to time
在历史语言学中,波浪模型从未获得谱系树模型的普及度,但仍会被偶尔使用。 - Other linguistic disciplines adopted the Wave Model, or at least Wave Model-like representations, e.g. dialectology and areal linguistics
被方言学、区域语言学等其他语言学分支采用,或至少使用类波浪模型的呈现方式。
5.5 Literature
5.5 参考文献
- Campbell (2013), chap. 7
- Trask (2015: 172-174)
- François (2014): positive assessment of the Wave Model (also see all papers listed under Historical Glottometry)
- Podcast about the criticism against the Neogrammarians
6 Historical Glottometry
6 历史语言计量法
Glottometry was devised by Alexandre François and Siva Kalyan as a modern, Wave Model-based alternative to the Tree Model.
历史语言计量法由亚历山大·弗朗索瓦与西瓦·卡利安提出,是基于波浪模型、替代谱系树模型的现代方案。
"The objective of Historical Glottometry is to identify genealogical subgroups in a language family, and measure their relative strengths so as to assess their historical patterns of distribution across social networks." (François 2014: 173)
"历史语言计量法的目标是识别语系中的谱系次分类,衡量其相对强度,进而评估其在社会网络中的历史分布模式。"(François 2014: 173)
6.1 What does it do and what does it assume?
6.1 功能与预设
- Historical Glottometry adopts the basic assumptions of the Wave Model that innovations 'wave' over varieties and languages develop from dialect continuums. On the other hand, it also assumes that 'related' varieties are derived from the same common ancestor. It therefore mostly deals with 'waves' within related (and mutual intelligible) varieties.
继承波浪模型核心预设:创新以波浪形式扩散、语言由方言连续体演变而来;同时预设"亲缘"变体源自同一祖语,因此主要研究亲缘(且互通)变体内部的波浪扩散。 - The Historical Comparative Method is used to find shared features between languages.
采用历史比较法寻找语言间共享特征。 - Varieties can belong to several diffusion areas (unlike in Trees where every variety or subgroups is headed by one node). "It is often the case ... that an innovation only spreads partway through a population before that population splits. In this situation, an innovation need not be passed on to all of the descendants of the language it occurs in, but only to some of them." (Kalyan & François 2019: 168)
变体可归属多个扩散区域(区别于谱系树中每个变体/次分类仅对应一个节点)。"常见情形是......创新在族群分裂前仅扩散至部分群体,此时创新无需传递给该语言的所有后代,仅部分后代继承即可。"(Kalyan & François 2019: 168) - Historical Glottometry accepts that languages may diversify due to splits, but such cases are regarded as rare and a special case of 'waves'.
承认语言可因分裂分化,但将此类情形视为罕见特例,归为波浪扩散的特殊形式。
6.2 How are the findings depicted and how to evaluate them?
6.2 结果呈现与评价
-
The diagrams are similar to isogloss maps but the thickness and darkness of the lines is used to show degrees of relationship.
图表与同言线地图相似,以线条粗细与深浅表示亲缘程度。
-
The darkness of the lines shows the 'cohesiveness' of a subgroup: "the proportion of supporting evidence with respect to the entire set of relevant evidence" (how many innovations does a subgroup share compared to the total number of scrutinized innovations?)
线条深浅表示次分类的凝聚度:"支撑证据占全部相关证据的比例"(次分类共享创新数占全部检验创新数的比例)。
-
The thickness of the lines shows the 'subgroupiness': "the product of the cohesiveness rate (k) with the number of exclusively shared innovations" (how many innovations does a subgroup share compared to the total number of scrutinized innovations and how many does it share exclusively?)
线条粗细表示次分类的专属度:"凝聚度系数(k)× 专属共享创新数"(次分类共享创新占比与专属共享创新数的乘积)。
-
Authors should explain you how they differentiated between inherited and diffused features.
研究者应说明继承性特征与扩散性特征的区分方法。
6.3 What are the pros and cons?
6.3 优势与局限
Several of the counterarguments discussed here also apply to the Wave Model in general.
本节部分反驳观点同样适用于整体波浪模型。
-
The strongest argument against Historical Glottometry is that it only depicts the synchronic distribution of features and lacks diachronic depths. Advocates claim that diachrony can be read from the isoglosses.
最有力的批评:仅刻画特征共时分布,缺乏历时深度;支持者称可从同言线解读历时信息。
-
Opponents claim that Historical Glottometry does not distinguish between shared innovations and parallel evolution. They also argue that the concept of shared innovations only makes sense within the Tree Model because it does not merely describe a phenomenon (languages share a feature) but also explains it (because they constitute a split event from an ancestor language). Advocates retort that shared innovations can be distinguished from parallel innovations based on their distribution pattern.
批评者认为该方法未区分共同创新与平行演化;且共同创新概念仅在谱系树模型中有意义------它不仅描述"语言共享特征"的现象,更解释"源于祖语分裂"的原因。支持者反驳:可依据分布模式区分共同创新与平行创新。
6.4 How is it regarded today?
6.4 当下认可度
- while they are some studies that have used Glottometry in the past it hasn't really set off
虽有部分研究采用历史语言计量法,但未真正普及。
6.5 Literature
6.5 参考文献
- François (2014): first paper that introduced Glottometry
- Kalyan & François (2018): similar to the previous paper but with a stronger focus on the actual methodology
- Jacques & List (2019): critical reply to Kalyan & François (2018) from a Tree Model perspective
- Kalyan & François (2019): reply to Jacques & List (2019)
- Agee (2018): Glottometric subgrouping for Germanic
6.6 Conclusion
6.6 结论
Some linguists regard the Tree Model and Wave Model not as alternatives but as complementary models that cover different aspects of language history (cf Carling et al. (2022)), others view the shortcomings of one of them as too serious to use both models (cf Jacques & List (2019)).
部分语言学家认为谱系树模型与波浪模型并非对立,而是互补,分别覆盖语言史的不同维度(参见 Carling et al. 2022);另一部分学者则认为其中一种模型缺陷严重,无法二者并用(参见 Jacques & List 2019)。
"The tree model, based on the principle of divergence, classifies according to splits, continually producing new subclades. The wave model illustrates the effects of convergence and advergence over time, i.e., how similarities between geographically adjacent languages may evolve, creating a gradual, dynamic diversity. Both models are equally important in explaining variation and classifying languages, and both models can be used to describe the evolution of languages and dialects, as well as linguistic subdomains, down to the most fine-grained level of individual traits" (Carling et al. (2022))
"谱系树模型基于分化原则,按分裂分类,持续生成新演化支;波浪模型阐释长期聚合与趋同效应,即地理相邻语言的相似性如何演变,形成渐进、动态的多样性。两种模型在解释变异、分类语言方面同等重要,均可用于描述语言、方言及语言子域的演变,直至单个特征的精细层面。"(Carling et al. 2022)
Literature
参考文献
Agee, Joshua. 2018. A Glottometric Subgrouping of the Early Germanic Languages. San Jose, CA, USA: San Jose State University Master of Arts.
艾吉·约书亚. 2018. 早期日耳曼语言的历史语言计量次分类. 美国加利福尼亚州圣何塞:圣何塞州立大学硕士论文.
Bloomfield, Leonard. 1933. Language. London: Allen & Unwin.
布龙菲尔德·伦纳德. 1933. 语言论. 伦敦:艾伦与昂温出版社.
Campbell, Lyle. 2013. Historical linguistics: an introduction. 3. ed. Edinburgh: Edinburgh Univ. Press. 538 pp.
坎贝尔·莱尔. 2013. 历史语言学导论(第 3 版). 爱丁堡:爱丁堡大学出版社. 538 页.
Carling, Gerd, Chundra Cathcart & Erich Round. 2022. Reconstructing the origins of language families and variation. In Nathalie Gontier, Andy Lock & Chris Sinha (eds.), The Oxford Handbook of Human Symbolic Evolution, 1st edn. Oxford University Press.
卡林·格尔德、钱德拉·卡思卡特、埃里希·朗德. 2022. 重构语系起源与变异. 载:纳塔莉·贡捷、安迪·洛克、克里斯·辛哈(编). 牛津人类符号演化手册(第 1 版). 牛津大学出版社.
Evans, Cara L., Simon J. Greenhill, Joseph Watts, Johann-Mattis List, Carlos A. Botero, Russell D. Gray & Kathryn R. Kirby. 2021. The uses and abuses of tree thinking in cultural evolution. Philosophical Transactions of the Royal Society B: Biological Sciences 376(1828).
埃文斯·卡拉·L、格林希尔·西蒙·J、沃茨·约瑟夫、利斯特·约翰-马蒂斯、博特罗·卡洛斯·A、格雷·拉塞尔·D、柯比·凯瑟琳·R. 2021. 文化演化中谱系树思维的运用与滥用. 英国皇家学会哲学汇刊 B:生物科学 376(1828).
François, Alexandre. 2014. Trees, waves and linkages: Models of Language Diversification. In Claire Bowern & Bethany Evans (eds.), The Routledge Handbook of Historical Linguistics (Routledge Handbooks in Linguistics), 161--189. London; New York: Routledge.
弗朗索瓦·亚历山大. 2014. 谱系树、波浪说与联结体:语言分化模型. 载:克莱尔·鲍恩、贝瑟妮·埃文斯(编). 劳特利奇历史语言学手册(劳特利奇语言学手册), 161--189. 伦敦;纽约:劳特利奇出版社.
Geisler, Hans & Johann-Mattis List. 2010. Beautiful Trees on Unstable Ground: Notes on the Data Problem in Lexicostatistics.
盖斯勒·汉斯、利斯特·约翰-马蒂斯. 2010. 根基不稳的精美谱系树:词汇统计学的数据问题札记.
Greenhill, Simon J., Paul Heggarty & Russell D. Gray. 2021. Bayesian Phylolinguistics. In Richard D. Janda, Brian D. Joseph & Barbara S. Vance (eds.), Handbook of historical linguistics (Blackwell Handbooks in Linguistics volume 2), 226--253. Hoboken, NJ, USA: Wiley.
格林希尔·西蒙·J、赫加蒂·保罗、格雷·拉塞尔·D. 2021. 贝叶斯系统语言发生学. 载:理查德·D·詹达、布莱恩·D·约瑟夫、芭芭拉·S·万斯(编). 历史语言学手册(布莱克韦尔语言学手册 第 2 卷), 226--253. 美国新泽西州霍博肯:威利出版社.
Jacques, Guillaume & Johann-Mattis List. 2019. Save the trees: Why we need tree models in linguistic reconstruction (and when we should apply them). Journal of Historical Linguistics 9(1). 128--167.
雅克·纪尧姆、利斯特·约翰-马蒂斯. 2019. 守护谱系树:语言重构为何需要谱系树模型(及适用场景). 历史语言学杂志 9(1). 128--167.
Kalyan, Siva & Alexandre François. 2018. Freeing the Comparative Method from the Tree Model: A Framework for Historical Glottometry. Senri Ethnological Studies 98. 59--89.
卡利安·西瓦、弗朗索瓦·亚历山大. 2018. 让比较法摆脱谱系树模型:历史语言计量法框架. 千里民族学研究 98. 59--89.
Kalyan, Siva & Alexandre François. 2019. When the waves meet the trees: A response to Jacques and List. Journal of Historical Linguistics 9(1). 168--177.
卡利安·西瓦、弗朗索瓦·亚历山大. 2019. 当波浪遇见谱系树:回应雅克与利斯特. 历史语言学杂志 9(1). 168--177.
List, Johann-Mattis, Jananan Sylvestre Pathmanathan, Philippe Lopez & Eric Bapteste. 2016. Unity and disunity in evolutionary sciences: process-based analogies open common research avenues for biology and linguistics. Biology Direct 11(1). 39.
利斯特·约翰-马蒂斯、帕马纳坦·贾纳南·西尔维斯特、洛佩兹·菲利普、巴普泰斯特·埃里克. 2016. 演化科学的统一与分化:基于过程的类比为生物学与语言学开辟共同研究路径. 生物学前沿 11(1). 39.
Schleicher, A. 1853. Die ersten Spaltungen des indogermanischen Urvolkes. Allgemeine Monatsschrift für Wissenschaft und Literatur 3. 786--787.
施莱歇尔·A. 1853. 印欧原始族群的最初分化. 科学与文学综合月刊 3. 786--787.
Schmidt, Johannes. 1872. Die Verwandtschaftsverhältnisse der indogermanischen Sprachen. Weimar: H. Böhlau.
施密特·约翰内斯. 1872. 印欧语言的亲缘关系. 魏玛:H·伯劳出版社.
Schuchardt, Hugo Ernestus Mario. 1868. Der Vokalismus des Vulgärlateins. Leipzig: Teubner.
舒哈特·胡戈·欧内斯图斯·马里奥. 1868. 通俗拉丁语的元音系统. 莱比锡:陶布纳出版社.
Schuchardt, Hugo Ernestus Mario. 1885. Ueber die Lautgesetzte. gegen die Junggrammatiker. Berlin: Robert Oppenheim.
舒哈特·胡戈·欧内斯图斯·马里奥. 1885. 论语音规律------驳新语法学派. 柏林:罗伯特·奥本海姆出版社.
Swadesh, Morris. 1950. Salish Internal Relationships. International Journal of American Linguistics 16(4). 157--167.
斯瓦迪士·莫里斯. 1950. 萨利希语的内部亲缘关系. 美国语言学国际期刊 16(4). 157--167.
Swadesh, Morris. 1952. Lexico-Statistic Dating of Prehistoric Ethnic Contacts: With Special Reference to North American Indians and Eskimos. Proceedings of the American Philosophical Society 96(4). 452--463.
斯瓦迪士·莫里斯. 1952. 史前族群接触的词汇统计测年------以北美印第安人与爱斯基摩人为重点. 美国哲学学会会刊 96(4). 452--463.
Swadesh, Morris. 1955. Towards Greater Accuracy in Lexicostatistic Dating. International Journal of American Linguistics 21(2). 121--137.
斯瓦迪士·莫里斯. 1955. 词汇统计测年的精度提升路径. 美国语言学国际期刊 21(2). 121--137.
Trask, Larry. 2015. Trask's Historical Linguistics. Robert McColl Millar (ed.). 3rd. London; New York: Routledge.
特拉斯克·拉里. 2015. 特拉斯克历史语言学(第 3 版). 罗伯特·麦科尔·米勒(编). 伦敦;纽约:劳特利奇出版社.
- A very short introduction to the linguistic Tree Model -- Bäume, Wellen, Inseln -- Trees, Waves and Islands
https://halmahera.hypotheses.org/391 - Trees, Waves and Friends
https://halmahera.hypotheses.org/files/2023/05/Zielenbach-2023-Trees_Waves_and_Friends_Script.pdf