集合:一个长度可变的容器
- 单列集合:一次添加一个元素【Collection 接口】
- 双列集合:一次添加两个元素【Map 接口】
Collection 是所有单列集合的父接口,内部的方法,所有单列集合都可以使用
- remove()、contains()底层依赖对象的 equals 方法
1. 方法引用
主要作用是对 Lambda 表达式的进一步简化
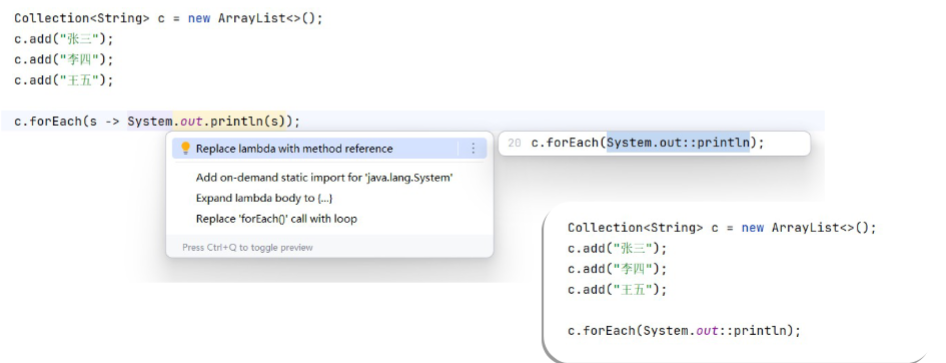
- 方法引用使用一对 ::
- 通过方法的名字来指向一个方法
- 可以使用语言的构造更紧凑简介,减少冗余代码
方法调用:MehodReference.change(s)
方法引用:MehodReference::change
import java.util.ArrayList;
import java.util.function.Consumer;
public class MethodReference {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("Apple");
list.add("Banana");
list.add("Orange");
// 匿名内部类
list.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
MethodReference.change(s);
}
});
}
public static void change(String s) {
System.out.println(s.toUpperCase());
}
}
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("Apple");
list.add("Banana");
list.add("Orange");
// 匿名内部类
list.forEach(MethodReference::change);
}- 可推导可省略原则,省略参数
比如上面代码中,accept 中正好有一个参数
change 方法需要一个 String 参数
那这个就可以推导出,然后省略参数 ::
2. List 接口
包含了 ArrayList 和 LinkedList
存取有序、有索引、可以重复存储
2.1. 遍历方式
1、迭代器 Iterator
2、增强 for
3、foreach 方法【上面三种之前都有】
4、普通 for 循环
import java.util.ArrayList;
import java.util.List;
import java.util.ListIterator;
public class ListDemo1 {
public static void main(String[] args) {
List<Student> list = new ArrayList<>();
list.add(new Student("张三", 20, 90));
list.add(new Student("李四", 21, 92));
list.add(new Student("王五", 20, 88));
// System.out.println(list);
// 普通for循环
for (int i = 0; i < list.size(); i++) {
Student s = list.get(i);
System.out.println(s);
}
// 列表迭代器
ListIterator<Student> listIt = list.listIterator();
System.out.println("列表迭代器正序遍历: ");
while (listIt.hasNext()) {
Student s = listIt.next();
System.out.println(s);
}
System.out.println("列表迭代器倒序遍历: ");
while (listIt.hasPrevious()) {
Student s = listIt.previous();
System.out.println(s);
}
}
}5、列表迭代器 ListIterator
代码在普通 for 循环里面包着,有个注意事项:
- 倒序遍历,必须在正序遍历后面,因为正序遍历,才会将迭代器的指针移到最后,这个时候才可以进行倒序遍历
3. 并发修改异常
ConcurrentModificationException
使用迭代器遍历集合的过程中,调用了集合对象的添加,删除方法,就会出现此异常
因为,调用集合对象自身的 remove 方法的时候,会导致,跳过一些数据,因为源码中设置了一个当前是第几个跟现在的长度的对比,不一样的话
-
迭代过程中做删除:Iterator 自带的 remove 方法使用
-
迭代过程中做添加:使用 ListIterator 自带的 add 方法
import java.util.ArrayList;
import java.util.ConcurrentModificationException;
import java.util.List;public class Demo1 {
public static void main(String[] args) {
Listlist = new ArrayList<>();
list.add("java");
list.add("枸杞子");
list.add("宁夏枸杞");
list.add("北海枸杞");
list.add("甘肃枸杞");for (int i = 0; i < list.size(); i++) { String item = list.get(i); if (item.contains("枸杞")) { list.remove(item); } System.out.println(list); } }}
import java.util.ArrayList;
import java.util.ConcurrentModificationException;
import java.util.List;
import java.util.ListIterator;public class Demo1 {
public static void main(String[] args) {
Listlist = new ArrayList<>();
list.add("java");
list.add("枸杞子");
list.add("宁夏枸杞");
list.add("北海枸杞");
list.add("甘肃枸杞");ListIterator<String> it = list.listIterator(); while (it.hasNext()) { String s = it.next(); if (s.contains("枸杞")) { it.remove(); } System.out.println(list); } }}
4. 数据结构
数据结构是计算机底层存储、组织数据的方式,是指数据相互之间是以什么方式排列在一起的。
通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。
栈:后进先出,先进后出。
队列:先进先出,后进后出。
数组:内存连续区域,查询快,增删慢。
链表:元素是游离的,查询慢,首尾操作极快。
链表
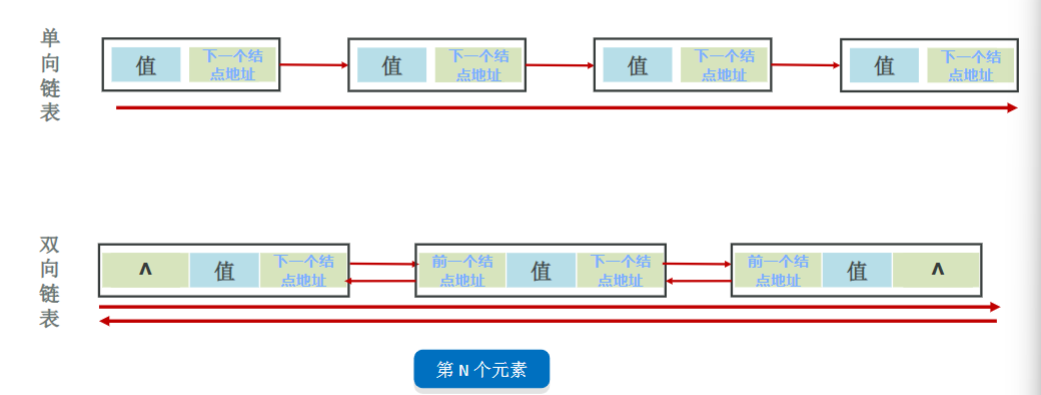
- 链表中的结点是独立的对象,在内存中是不连续的,每个结点包含数据值和下一个结点的地址。
- 链表查询慢,无论查询哪个数据都要从头开始找。
5. ArrayList、LinkedList 类
5.1. ArrayList
ArrayList 底层是基于数组实现的,根据查询元素快,增删相对慢。
ArrayList 长度可变原理:
1、 使用空参构造器创建的集合,在底层创建一个默认长度为0的数组
2、 添加第一个元素时,底层会创建一个新的长度为10的数组
3、 存满时,会扩容1.5倍
5.2. LinkedList
底层是基于双链表实现的,查询元素慢,增删首尾元素是非常快的。
6. 泛型
JDK5 引入的,可以在编译阶段约束操作的数据类型,并进行检查
ArrayList<String> list = new ArrayList<>();
list.add(666); // 报错
list.add("666"); // 正常泛型的好处:统一数据类型,将运行期的错误提升到了编译器
- 泛型中只能编写引用数据类型
学习路径:泛型类------泛型方法------泛型接口------泛型通配符
1、泛型类

2、泛型方法
-
非静态方法:泛型是根据类的泛型去匹配的
-
静态方法:需要声明出自己独立的泛型
// 定义一个带泛型的类
class Box{
private T value;public void setValue(T value) { this.value = value; } // 使用类的泛型T public void printValue(T value) { System.out.println("值: " + value); } // 静态方法必须自己声明泛型 <E> public static <E> void printData(E data) { System.out.println("数据: " + data); }}
public class Demo1 {
public static void main(String[] args) {
Boxbox = new Box<>();
box.printValue("Hello"); // T = StringBox.printData(100); // E = Integer Box.printData("Java"); // E = String }}
3、泛型接口
类实现接口的时候,如果接口带有泛型,有两种操作方式
-
类实现接口的时候,直接确定类型
-
保持接口的泛型,等创建对象的时候再确定【通用】
// 定义一个带泛型的接口
interface Processor{
void process(T data);
}// 在实现接口时,直接指定具体类型(如 String)
class StringProcessor implements Processor{
@Override
public void process(String data) {
System.out.println("处理字符串: " + data);
}
}// 实现类继续保留泛型 T
class GenericProcessorimplements Processor {
@Override
public void process(T data) {
System.out.println("处理数据: " + data);
}
}public class Demo {
public static void main(String[] args) {
StringProcessor sp = new StringProcessor();
sp.process("Hello, World!");GenericProcessor<Integer> gp = new GenericProcessor<>(); gp.process(25); GenericProcessor<String> gp2 = new GenericProcessor<>(); gp2.process("Hello, Java World!"); }}
4、泛型通配符
- ? (任意类型)
- ? extends E (只能接收 E 或者 E 的子类)
- ? super E (只能接收 E 或者 E 的父类)
7. Set 集合
Set 接口:1、存取无序 2、没有索引 3、不可以存储重复的值
遍历方式:三种通用的遍历方式
1、迭代器 Iterator
2、增强 for
3、foreach 方法【上面三种之前都有】
TreeSet 特点:元素排序
HashSet 特点:元素唯一
LinkedHashSet 特点:元素唯一,保证存取顺序
7.1. TreeSet 集合
作用:对集合中的元素进行排序操作(底层是红黑树实现的)
红黑树:就是可以自平衡的二叉树,是一种增删改查数据性能相对都比较好的结构
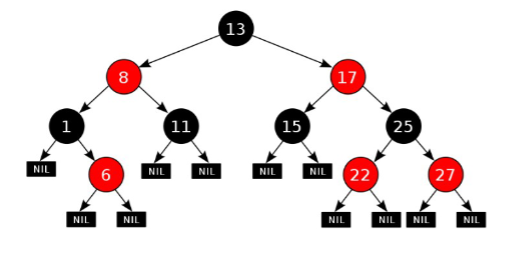
基本特点:
1、任意节点开始,左边的节点都比当前节点小,右边的节点都比当前节点大
2、每一次添加节点,都从根节点开始比大小,小的左边走,大的右边走,一样的不存
排序方式:
1、自然排序
- 类实现 Comparable 接口
- 重写 compareTo 方法,指定比较规则(排序规则)
- 根据方法的返回值,来组织排序规则
-
- 负数:左边走
- 正数:右边走
- 0:不存
补充:字符串的比较
public class StringDemo {
public static void main(String[] args) {
String s1 = "张";
String s2 = "李";
System.out.println(s2.compareTo(s1)); // 2094
}
}
import java.util.TreeSet;
// 自定义类实现 Comparable 接口,并重写 compareTo 方法
class Person implements Comparable<Person> {
String name;
int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// 定义自然排序规则(按年龄升序)
@Override
public int compareTo(Person o) {
return this.age - o.age;
}
@Override
public String toString() {
return name + ":" + age;
}
}
public class TreeSetDemo1 {
public static void main(String[] args) {
TreeSet<Person> set = new TreeSet<>();
set.add(new Person("Alice", 25));
set.add(new Person("Bob", 18));
set.add(new Person("Charlie", 30));
System.out.println(set);
}
}
import java.util.TreeSet;
// 自定义类实现 Comparable 接口,并重写 compareTo 方法
class Person implements Comparable<Person> {
String name;
int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int compareTo(Person o) {
// 倒序
// 需求:根据年龄作为主要排序条件,根据姓名作为次要排序条件,同姓名同年龄,需要保留.
int ageResult = o.age - this.age;
int nameResult = ageResult == 0 ? o.name.compareTo(this.name) : ageResult;
return nameResult == 0 ? 1 : nameResult;
}
@Override
public String toString() {
return name + ":" + age;
}
}
public class TreeSetDemo1 {
public static void main(String[] args) {
TreeSet<Person> set = new TreeSet<>();
set.add(new Person("Alice", 25));
set.add(new Person("Bob", 18));
set.add(new Person("Charlie", 30));
set.add(new Person("Bob", 18));
System.out.println(set);
}
}2、比较器排序
- 在 TreeSet 集合的构造方法中,传入比较器对象 (Comparator接口的实现类对象)
- 重写compare 方法
- 根据方法的返回值组织排序规则
特点:如果同时具备自然排序和比较器排序,优先按照比较器排序的规则进行操作。
import java.util.Comparator;
import java.util.TreeSet;
public class TreeSetDemo2 {
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet<>((o1, o2) -> o2 - o1);
set.add(10);
set.add(5);
set.add(20);
set.add(15);
set.add(30);
System.out.println(set);
TreeSet<String> set2 = new TreeSet<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.length() - o2.length();
}
});
set2.add("hello");
set2.add("world");
set2.add("java");
set2.add("aa");
System.out.println(set2);
}
}7.2. HashSet 集合
- HashSet集合底层采取哈希表存储数据,确保元素的唯一性
HashSet想要保证元素唯一:需要同时重写对象中的 hashCode 方法和 equals 方法
- 哈希表是一种对于增删改查数据性能都较好的结构
当添加对象的时候,会先调用对象的 hashCode 方法计算出一个应该存入的索引位置,查看该位置上是否存在元素
不存在:直接存
存在:调用equals方法比较内容
false:存
true:不存
import java.util.HashSet;
import java.util.Objects;
class Student {
String name;
int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return 1;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
public class HashSetDemo {
public static void main(String[] args) {
HashSet<Student> hs = new HashSet<>();
hs.add(new Student("张三", 23));
hs.add(new Student("李四", 24));
hs.add(new Student("王五", 24));
hs.add(new Student("王五", 24));
System.out.println(hs);
}
}如果 hashCode 方法固定返回相同的值,数据都会挂在一个索引下面,性能会受影响
7.2.1. hashcode 方法介绍
哈希值:就是一个int类型的随机值,Java中每个对象都有一个哈希值。

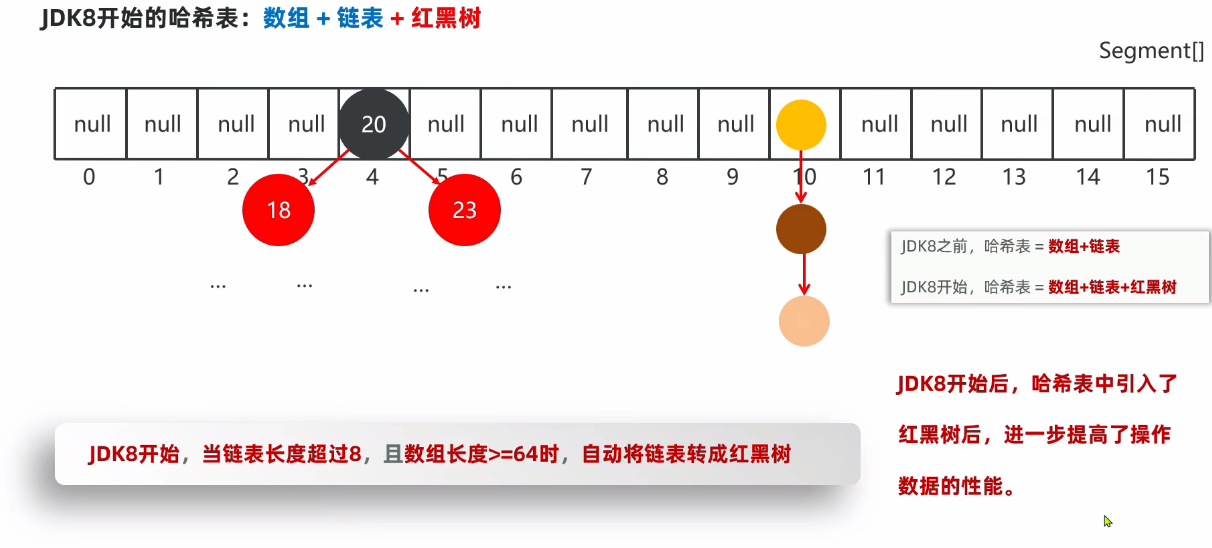
7.2.2. 底层原理
哈希表:
- JDK8版本之前:数组+链表
- JDK8版本之后:数组+链表+红黑树

加载因子:当数组存满到16*0.75=12时,就自动扩容,每次扩容成原先的两倍
7.3. LinkedHashSet
代码跟之前类似。下面是底层原理:
-
依然是基于哈希表(数组、链表、红黑树)实现的。
-
但是,它的每个元素都额外的多了一个双链表的机制记录它前后元素的位置。
import java.util.LinkedHashSet;
class Student {
public String name;
public int age;public Student() { } public Student(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "{name: " + getName() + ", age: " + getAge() + "}"; }}
public class LinkedHashDemo {
public static void main(String[] args) {
LinkedHashSetlhs = new LinkedHashSet<>(); lhs.add(new Student("王五", 25)); lhs.add(new Student("张三", 23)); lhs.add(new Student("李四", 24)); lhs.add(new Student("张三", 23)); for (Student student : lhs) { System.out.println(student); } }}

8. Collections 工具类

import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
public class CollectionsDemo {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 1, 2, 3, 4, 5);
Collections.sort(list, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
System.out.println(list);
// 洗牌
Collections.shuffle(list);
System.out.println(list);
// 求最值,根据自然排序获取的,
// 如果集合中元素没有实现 Comparable 接口,则无法使用此方法
System.out.println(Collections.max(list));
System.out.println(Collections.min(list));
Collections.sort(list);
System.out.println(list);
}
}8.1. 可变参数
可变参数用在形参中可以接收多个数据。【本质是 数组】
可变参数的格式:数据类型...参数名称
好处:传输参数非常灵活,方便,可以不传输参数,可以传输一个或者多个,也可以传输一个数组
public static void getSum(int... nums){xxxx}注意事项:
- 可变参数,在方法中只能有一个
- 如果方法中除了可变参数,还有其它的参数,需要将可变参数放在最后
9. Map 集合
Map 接口: TreeMap、HashMap、LinkedHashMap
- Map集合是一种双列集合,每个元素包含两个数据
- Map集合的每个元素的格式:key=value (键值对元素)
-
- key 不允许重复,value 允许
- key+value 这个整体我们称之为"键值对"或者"键值对对象"在Java中使用Entry 对象表示
需要存储一一对应的数据时,就可以考虑使用Map集合来做
9.1. Map 的常见 API
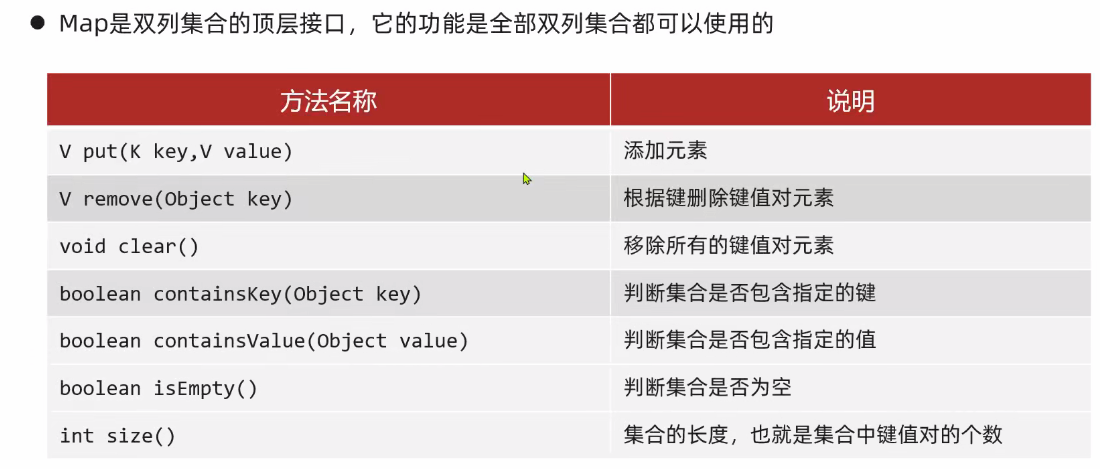
put:如果键已存在,就会使用新值替代旧值;其返回值是被覆盖掉的旧值,没有被覆盖就返回的是 null
remove:返回的是被删掉的值【没啥必要】
import java.util.HashMap;
import java.util.Map;
public class MapDemo1 {
/*
Map集合常用API
---------------------------------------------------------------------------
public V put(K key,V value) 添加元素 (修改: 如果键已经存在了, 就会使用新值, 替换旧值)
- 返回被覆盖掉的旧值.
public V remove(Object key) 根据键删除键值对元素
- 返回被删除的键, 所对应的值
public void clear() 移除所有的键值对元素
public boolean containsKey(Object key) 判断集合是否包含指定的键
public boolean containsValue(Object value) 判断集合是否包含指定的值
public boolean isEmpty() 判断集合是否为空
public int size() 集合的长度,也就是集合中键值对的个数
---------------------------------------------------------------------------
*/
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("张三", "北京");
map.put("李四", "上海");
map.put("王五", "成都");
System.out.println(map);
System.out.println("-------------------------------");
map.remove("李四");
System.out.println(map);
System.out.println("map是否为空: " + map.isEmpty());
System.out.println("map的大小是: " + map.size());
System.out.println("-------------------------------");
System.out.println("map是否包含一个张三的键: " + map.containsKey("张三"));
System.out.println("map是否包含一个上海的值: " + map.containsValue("上海"));
System.out.println("-------------------------------");
map.clear();
System.out.println(map);
}
}9.2. 遍历方式
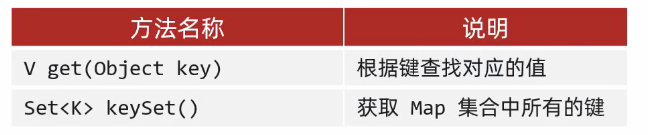
1、通过键找值
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapDemo2 {
/*
* Map集合的第一种遍历方式: 键找值
*
* public V get(Object key) : 根据键查找对应的值
* public Set<K> keySet() : 获取 Map 集合中所有的键
*/
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("张三", "北京");
map.put("李四", "上海");
map.put("王五", "成都");
// 1、获取Map集合中所有的键
Set<String> keySet = map.keySet();
// 2、遍历set集合,获取每一个键
for (String key : keySet) {
// 3、通过map集合的get方法,根据键查找对应的值
String value = map.get(key);
System.out.println(key + "----" + value);
}
}
}2、通过键值对对象获取键和值
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Set;
public class MapDemo3 {
/*
Map集合的第二种遍历方式: 键值对对象, 获取键和值.
public Set<Map.Entry<K,V>> entrySet() : 获取集合中所有的键值对对象
*/
public static void main(String[] args) {
Map<String, String> map = new LinkedHashMap<>();
map.put("张三", "北京");
map.put("李四", "上海");
map.put("王五", "成都");
// System.out.println(map);
// 1、调用entrySet方法,获取所有的键值对对象
Set<Map.Entry<String, String>> entrySet = map.entrySet();
// 2、遍历set集合,获取每一个键值对对象
for (Map.Entry<String, String> entry : entrySet) {
// 3、通过键值对对象,获取键和值
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "-----" + value);
}
}
}3、foreach 方法遍历
import java.util.Map;
import java.util.TreeMap;
import java.util.function.BiConsumer;
public class MapDemo4 {
/*
Map集合的第三种遍历方式: foreach方法
public default void forEach (BiConsumer<? super K,? super V> action)
遍历Map集合, 获取键和值
*/
public static void main(String[] args) {
Map<String, String> map = new TreeMap<>();
map.put("张三", "北京");
map.put("李四", "上海");
map.put("王五", "成都");
// System.out.println(map);
map.forEach(new BiConsumer<String, String>() {
@Override
public void accept(String key, String value) {
System.out.println(key + "---" + value);
}
});
// 对应的lambda表达式
map.forEach((key, value) -> System.out.println(key + "---" + value));
}
}10. Map 集合案例
import java.util.HashMap;
import java.util.Map;
import java.util.function.BiConsumer;
public class MapTest1 {
/*
需求: 字符串 aababcabcdabcde
请统计字符串中每一个字符出现的次数,并按照以下格式输出
输出结果
a(5)b(4)c(3)d(2)e(1)
*/
public static void main(String[] args) {
String s = "aababcabcdabcde";
// 创建Map集合,键的位置存储字符,值得位置存储次数
Map<Character, Integer> map = new HashMap<>();
// 遍历字符串,获取每一个字符
char[] charArray = s.toCharArray();
for (char c : charArray) {
// 判断当前字符在Map集合中是否存在
if (!map.containsKey(c)) {
// 不存在:直接存入,值的位置写1
map.put(c, 1);
} else {
// 存在:取出旧值,+1存回去
map.put(c, map.get(c) + 1);
}
}
// 输出 a(5)b(4)c(3)d(2)e(1)
StringBuilder sb = new StringBuilder();
map.forEach(new BiConsumer<Character, Integer>() {
@Override
public void accept(Character key, Integer value) {
sb.append(key).append("(").append(value).append(")");
}
});
System.out.println(sb);
}
}
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
import java.util.function.BiConsumer;
public class MapTest2 {
/*
定义一个Map集合,键用表示省份名称,值表示市,但是市会有多个。
添加完毕后,遍历结果:
格式如下:
江苏省 = 南京市,扬州市,苏州市,无锡市,常州市
湖北省 = 武汉市,孝感市,十堰市,宜昌市,鄂州市
四川省 = 成都市,绵阳市,自贡市,攀枝花市,泸州市
*/
public static void main(String[] args) {
ArrayList<String> list1 = new ArrayList<>();
Collections.addAll(list1, "南京市", "扬州市", "苏州市", "无锡市", "常州市");
ArrayList<String> list2 = new ArrayList<>();
Collections.addAll(list2, "武汉市", "孝感市", "十堰市", "宜昌市", "鄂州市");
ArrayList<String> list3 = new ArrayList<>();
Collections.addAll(list3, "成都市", "绵阳市", "自贡市", "攀枝花市", "泸州市");
Map<String, ArrayList<String>> map = new HashMap<>();
map.put("江苏省", list1);
map.put("湖北省", list2);
map.put("四川省", list3);
map.forEach(new BiConsumer<String, ArrayList<String>>() {
@Override
public void accept(String key, ArrayList<String> value) {
System.out.print(key + " = ");
for (int i = 0; i < value.size(); i++) {
System.out.print(value.get(i) + ",");
}
System.out.println(value.get(value.size() - 1));
}
});
}
}11. Stream 流介绍
配合 Lambda 表达式,简化集合和数组操作
流思想:
1、将数据到流中(获取流对象)
2、中间方法
3、终结方法
例子:
import java.util.ArrayList;
import java.util.List;
public class StreamDemo {
/*
需求: 按照下面的要求完成集合的创建和遍历
1. 创建一个集合,存储多个字符串元素
2. 把集合中所有以"张"开头的元素存储到一个新的集合
3. 把"张"开头的集合中的长度为3的元素存储到一个新的集合
4. 遍历上一步得到的集合中的元素输出
*/
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("张良");
list.add("王二麻子");
list.add("谢广坤");
list.add("张三丰");
list.add("张翠山");
// 一行做了三段的事情~
list.stream().filter(s -> s.startsWith("张")).filter(s -> s.length() == 3).forEach(System.out::println);
}
private static void method(List<String> list) {
// 2、把集合中所有以 "张" 开头的元素存储到一个新的集合
ArrayList<String> list1 = new ArrayList<>();
for (String s : list) {
if (s.startsWith("张")) {
list1.add(s);
}
}
// 3、把 "张" 开头的集合中的长度为3的元素存储到一个新的集合
ArrayList<String> list2 = new ArrayList<>();
for (String s : list1) {
if (s.length() == 3) {
list2.add(s);
}
}
// 4、遍历上一步得到的集合中的元素输出
list2.forEach(System.out::println);
}
}-
获取 Stream 流对象
import java.util.*;
import java.util.stream.Stream;public class StreamDemo1 {
/*
获取Stream流对象演示
- 将数据放在流水线的传送带上1. 集合获取 Stream 流对象 (使用Collection接口中的默认方法) default Stream<E> stream() * Map集合获取Stream流对象, 需要间接获取 - map.entrySet().stream() 2. 数组获取 Stream 流对象 (使用Arrays数组工具类中的静态方法) static <T> Stream<T> stream (T[] array) 3. 零散的数据获取 Stream 流对象 (使用 Stream 类中的静态方法) static <T> Stream<T> of(T... values) */ public static void main(String[] args) { int[] arr = {11, 22, 33}; String[] names = {"张三", "李四", "王五"}; Arrays.stream(arr).forEach(System.out::println); Arrays.stream(names).forEach(System.out::println); Stream<Integer> s1 = Stream.of(1, 2, 3, 4, 5); Stream<String> s2 = Stream.of("张三", "李二", "陈平安"); } private static void method() { List<String> list = new ArrayList<>(); list.add("张三丰"); list.add("张无忌"); list.add("张翠山"); list.add("王二麻子"); list.add("张良"); list.add("谢广坤"); list.stream().forEach(System.out::println); System.out.println("---------------------------"); Set<String> set = new HashSet<>(); set.add("张三丰"); set.add("张无忌"); set.add("张翠山"); set.add("王二麻子"); set.add("张良"); set.add("谢广坤"); set.stream().forEach(System.out::println); System.out.println("---------------------------"); Map<String, Integer> map = new HashMap<>(); map.put("张三丰", 100); map.put("张无忌", 35); map.put("张翠山", 55); map.put("王二麻子", 22); map.put("张良", 30); map.put("谢广坤", 55); Stream<String> s1 = map.keySet().stream(); s1.forEach(System.out::println); Stream<Integer> s2 = map.values().stream(); s2.forEach(System.out::println); System.out.println("---------------------------"); // 获取map集合,所有键值对的对象 // Set<Map.Entry<String, Integer>> entrySet = map.entrySet(); // Stream<Map.Entry<String, Integer>> s3 = entrySet.stream(); // s3.forEach(System.out::println); map.entrySet().stream().forEach(System.out::println); }}
-
Stream 流中间操作方法
import java.util.ArrayList;
import java.util.stream.Stream;public class StreamDemo2 {
/*
Stream流的中间操作方法
- 操作后返回Stream对象, 可以继续操作Stream<T> filter(Predicate<? super T> predicate) 用于对流中的数据进行过滤 Stream<T> limit(long maxSize) 获取前几个元素 Stream<T> skip(long n) 跳过前几个元素 Stream<T> distinct() 去除流中重复的元素依赖 (hashCode 和 equals方法) static <T> Stream<T> concat(Stream a, Stream b) 合并a和b两个流为一个流 Stream<R> map(Function<? super T,? extends R> mapper) 对流中的每一个元素进行转换 注意事项: 流对象已经被消费过(使用过), 就不允许再次消费了. */ public static void main(String[] args) { Stream<Integer> s1 = Stream.of(1, 2, 3, 4, 5); s1.map(i -> i + "").forEach(System.out::println); // 都变成字符 Stream<Integer> s2 = Stream.of(1, 2, 3, 4, 5); s2.map(j -> j + 10).forEach(System.out::println); } private static void method() { ArrayList<String> list = new ArrayList<>(); list.add("林青霞"); list.add("张曼玉"); list.add("王祖贤"); list.add("柳岩"); list.add("张敏"); list.add("张无忌"); // 需求: 将集合中以 【张】 开头的数据,过滤出来并打印在控制台 list.stream().filter(s -> s.startsWith("张")).forEach(System.out::println); System.out.println("--------------------------"); // 需求1: 取前3个数据在控制台输出 list.stream().limit(3).forEach(System.out::println); System.out.println("--------------------------"); // 需求2: 跳过3个元素, 把剩下的元素在控制台输出 list.stream().skip(3).forEach(System.out::println); System.out.println("--------------------------"); // 需求3: 跳过2个元素, 把剩下的元素中前2个在控制台输出 list.stream().skip(2).limit(2).forEach(System.out::println); System.out.println("--------------------------"); // 需求4: 取前4个数据组成一个流 Stream<String> s1 = list.stream().limit(4); // 需求5: 跳过2个数据组成一个流 Stream<String> s2 = list.stream().skip(2); // 需求6: 合并需求4和需求5得到的流, 并把结果在控制台输出 Stream<String> s3 = Stream.concat(s1, s2); // s3.forEach(System.out::println); // 需求7: 合并需求4和需求5得到的流, 并把结果在控制台输出,要求字符串元素不能重复 System.out.println("--------------------------"); s3.distinct().forEach(System.out::println); }}
Stream 流的注意事项:流对象如果已经被消费过,就不允许再次使用了。
-
Stream 流终结操作方法
import java.util.ArrayList;
import java.util.Collections;
import java.util.stream.Stream;public class StreamDemo3 {
/*
Stream流的终结操作方法
- 流水线中的最后一道工序public void forEach (Consumer action) 对此流的每个元素执行遍历操作 public long count () 返回此流中的元素数 */ public static void main(String[] args) { System.out.println(Stream.of(1, 2, 3, 4, 5).count()); // 细节:流中的操作,不会修改数据源 ArrayList<Integer> list = new ArrayList<>(); Collections.addAll(list, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10); list.stream().filter(s -> s % 2 == 0).forEach(System.out::println); System.out.println(list); }}
-
Stream 收集操作
-
-
把 Stream 流操作后的结果数据转回到集合
-
Stream 流操作,不会修改数据源 【如上面例子】
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;public class StreamDemo4 {
/*
Stream流的收集操作public R collect (Collector c) : 将流中的数据收集到集合 Collectors public static <T> Collector toList() public static <T> Collector toSet() public static Collector toMap(Function keyMapper , Function valueMapper) */ public static void main(String[] args) { ArrayList<Integer> list = new ArrayList<>(); Collections.addAll(list, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 10, 10); List<Integer> result1 = list.stream().filter(s -> s % 2 == 0).collect(Collectors.toList()); System.out.println(result1); Set<Integer> result2 = list.stream().filter(s -> s % 2 == 0).collect(Collectors.toSet()); System.out.println(result2); List<Integer> result3 = list.stream().filter(s -> s % 2 == 0).toList(); System.out.println(result3); }}
-
例子:
import java.util.ArrayList;
import java.util.Map;
import java.util.function.Function;
import java.util.stream.Collectors;
public class StreamDemo5 {
/*
创建一个 ArrayList 集合,并添加以下字符串
"张三,23"
"李四,24"
"王五,25"
将数据收集到 Map 集合中,姓名为键,年龄为值
*/
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("张三, 23");
list.add("李四, 24");
list.add("王五, 25");
Map<String, String> map = list.stream().collect(Collectors.toMap(new Function<String, String>() {
@Override
public String apply(String s) {
return s.split(",")[0];
}
}, new Function<String, String>() {
@Override
public String apply(String s) {
return s.split(",")[1];
}
}));
System.out.println(map);
}
}