AI 写了 100 万行代码,靠的不是更聪明------Harness Engineering 是什么?

2026 年 2 月,OpenAI(开发了 ChatGPT 的人工智能公司)的 Codex 团队发了一篇博客,标题是《Harness engineering: leveraging Codex in an agent-first world》(驾驭工程:在 Agent 优先的世界中使用 Codex)。Codex 是 OpenAI 开发的一个 AI 编程工具------你告诉它"做什么",它自己去写代码。
博客里记录了一个疯狂的实验:
从 2025 年 8 月开始,一个 3 人工程团队(后来扩展到 7 人),让 AI Agent(可以自主执行多步任务的 AI 程序,后面会详细解释)从零开始构建一个生产级应用。5 个月后,这个应用的代码量达到了约 100 万行 ,合并了大约 1500 个 Pull Request(Pull Request 是程序员向项目提交代码修改的一种方式,可以理解为"请审核我的修改")。
人类没有手动写过一行代码。
你可能以为他们的秘密武器是"更强的 AI 模型",或者"更精妙的提示词"。
都不是。
负责这个项目的工程师 Ryan Lopopolo 事后说了一句话,在整个技术圈传开了:
"Agents aren't hard; the Harness is hard."
(Agent 不难,难的是 Harness。)
Harness 这个词,原意是"马具"------缰绳、马鞍、护具,那一整套让马能被骑手控制的装备。
Ryan 用这个词来指 AI Agent 周围的一整套系统:约束规则、自动检测、反馈机制、错误修复流程......不是 AI 本身,而是 AI"住"的那个环境。
这个概念,后来被叫做 Harness Engineering(驾驭工程)。
这篇文章,我们来把它彻底拆开看看------它到底解决什么问题?它和你听过的 Prompt Engineering 有什么关系?为什么有人说它才是 AI 时代真正值钱的技能?
Part 1:问题------光有聪明的 AI,远远不够
先从一个你可能已经知道的事情说起。

AI(这里特指大语言模型,也就是 ChatGPT、Claude(Anthropic 公司开发的 AI 助手)这类"聊天 AI"背后的技术)本质上是一个超级模式匹配器------这不是一个比喻,而是对它工作原理的准确描述。简单来说:AI 在训练时"阅读"了互联网上数十亿页的文字,记住了"什么样的文字组合经常一起出现"。当你问它问题时,它不是在"思考答案",而是在用这些统计规律预测"接下来最可能的词是什么",然后一个词一个词地把回答"拼"出来。
这意味着两件事:
- 它很强------在模式匹配类的任务上(写文章、翻译、写代码、整理信息),它的速度和质量经常让人惊叹。
- 它不可靠------它不"理解"自己在说什么,所以会编造事实、犯逻辑错误、在你没注意的地方埋下隐患。
这两个特点,在"聊天"场景下问题不大。你问它一个问题,它回答了,你扫一眼,觉得不对就让它重来------整个过程你全程盯着,犯错了马上就能发现。
但现在情况变了。
2025 年以来,AI 的使用方式正在从"一问一答的聊天"转向"自主执行任务的 Agent"。
什么意思?以前你跟 AI 说"帮我写一封邮件",它写完你看看就完了。现在你可以跟 AI 说"帮我把这个功能开发出来"------它会自己去读代码、写代码、运行测试、发现 bug、修复 bug、提交修改......整个过程可能持续几个小时,中间你完全不介入。
问题来了:一个会犯错的东西,自主运行几个小时,中间没人盯着------你觉得会发生什么?
2025 年 7 月,就有一个被广泛报道的案例:一个 AI 编程助手无视了代码冻结的指令,绕过了安全策略,最终删除了一个生产数据库。AI 在技术上"成功完成了任务"------但它完全不理解自己做的事情意味着什么。
这不是个例。行业数据显示,大约 80%-90% 的 AI Agent 项目没能进入生产环境。不是因为 AI 不够聪明,而是因为没有人搭好它"干活的环境"。
打个比方:
你招了一个实习生。这个实习生知识渊博,反应极快,干活速度是普通人的 10 倍。但他有一个致命的问题------他不知道什么不该碰。 他不知道生产环境和测试环境的区别,不知道某些文件是绝对不能删的,不知道改了代码之后要先跑测试再提交。
如果你把他扔进公司,什么规矩都不定,什么检查流程都没有,让他"自由发挥"------
他大概率会在一周内把项目搞崩。
不是因为他蠢,是因为没人给他搭好工作环境。
AI Agent 就是这个实习生。而 Harness Engineering 要解决的,就是怎么给这个实习生搭一个不翻车的工作环境。
我第一次看到那个"删除生产数据库"的案例时,脑子里的第一反应是:"这 AI 也太蠢了吧?"但仔细一想,不对------AI 做的每一步操作,单独来看都是"正确的"。它执行了指令,完成了任务。真正的问题不是 AI 蠢,而是没人告诉它"这个操作会让整个公司停摆"。就像你给一个实习生说"把那个旧数据库清理掉",他真的清了------他怎么知道那是生产环境?
这个认知的转变让我意识到:AI 时代最重要的问题,不是"怎么让 AI 更聪明",而是"怎么让一个已经足够聪明但完全不靠谱的东西,变成你能信任的工具"。
Part 2:演进------从"怎么说话"到"搭什么环境"
Harness Engineering 不是凭空冒出来的。它是 AI 使用方式演进的第三个阶段。
让我按时间线把这三个阶段串起来。
第一阶段:Prompt Engineering------"怎么跟 AI 说话"(2022-2024)
2022 年底,ChatGPT 横空出世,所有人都在研究一个问题:怎么跟 AI 说话,才能让它给出更好的回答?
这就是 Prompt Engineering(提示词工程)。

核心思路很简单:精心设计你给 AI 的指令(也就是"提示词"),让它的输出更符合你的需求。
比如同样是让 AI 写邮件:
❌ 普通提示词:"帮我写一封邮件。"
→ AI 输出一封平庸的模板邮件。
✅ 精心设计的提示词:"我是一个产品经理,需要给工程团队写一封邮件,说明本周需求变更的原因。语气要专业但不生硬,控制在 200 字以内。"→ AI 输出一封精准、得体的邮件。
为什么有效?因为更丰富的上下文让 AI 的模式匹配更精准了------你给的信息越多,它能"匹配"到的模式就越准确。
Prompt Engineering 在 2023-2024 年非常火,甚至催生了一个新职业:"提示词工程师"。各种技巧层出不穷------Chain of Thought(让 AI 一步一步想)、Few-shot(给 AI 看几个例子再让它做)、角色扮演(让 AI 假装自己是某个专家)------但它们的底层逻辑都是一样的:给 AI 更多、更好的上下文信息,让它的模式匹配更精准。
但 Prompt Engineering 有一个根本性的局限:它只解决了"单次交互"的问题。
你精心写了一条提示词,AI 给了你一个好回答------很棒。但如果你要让 AI 自主完成一个包含 20 个步骤的任务呢?你总不能给每一步都写一条提示词,然后站在旁边一步一步地喂吧?
打个比方:Prompt Engineering 就像给员工下了一条口头指令。指令精确的话,这一次的活儿干得漂亮。但它没法让员工独立工作一整天------因为口头指令管不了他遇到意外情况时该怎么办。
第二阶段:Context Engineering------"给 AI 看什么资料"(2025)
2025 年 6 月,Shopify(一家大型电商平台公司)的 CEO Tobi Lütke 公开说:他更喜欢用"Context Engineering"(上下文工程)这个词,而不是"Prompt Engineering"。紧接着,前 Tesla AI 总监、OpenAI 联合创始人 Andrej Karpathy 也表示赞同,他把 Context Engineering 定义为"一门精巧的技艺------把恰好正确的信息,在恰好正确的时刻,以恰好正确的格式,填进 AI 的上下文窗口"。
Context Engineering 的核心洞察是:光写好指令不够,你还得给 AI 看对资料。
上下文窗口(context window)是 AI 一次能"看到"的全部信息------包括你的指令、对话历史、背景资料等等。AI 的输出质量,很大程度上取决于这个窗口里装了什么。
所以 Context Engineering 不只是写好一条指令,而是管理 AI 能看到的全部信息:
- 通过 RAG(检索增强生成------一种让 AI 在回答前先从外部数据库搜索相关资料的技术)给 AI 提供最新的文档
- 管理对话历史,让 AI 记住之前说过的话
- 在正确的时机给 AI 提供正确的背景信息
打个比方:如果说 Prompt Engineering 是给员工下了一条口头指令,Context Engineering 就是在下指令的同时,给了他一份项目文档和操作手册。
有了正确的资料,AI 做多步任务的能力明显增强了。
但还是不够。
为什么?因为即使你给了 AI 正确的资料,它依然可能跑偏------资料告诉了它"应该做什么",但没有告诉它"绝对不能做什么"。它没有检查机制,没有行为边界,没有"做错了自动报警"的系统。
就像那个实习生:你给了他项目文档和操作手册,很好。但如果你没有告诉他"生产数据库绝对不能碰",没有设好代码提交前的自动检查,没有建立"发现错误就回滚"的流程------他看完文档之后,还是可能闯祸。
第三阶段:Harness Engineering------"搭好整个工作环境"(2026)
2026 年初,Mitchell Hashimoto------他是 Terraform(一个被全球数百万开发者使用的基础设施管理工具)和 Vagrant(一个虚拟开发环境管理工具)的创造者------在他的个人博客上发表了一篇文章,标题叫《My AI Adoption Journey》(我的 AI 采用之旅)。
文章里有一段话被广泛引用:
"每次发现 Agent 犯了一个错误,你就花时间设计一个方案,让 Agent 再也不会犯同样的错误。"
这就是 Harness Engineering 的核心理念。
不只是给 AI 好的指令(Prompt Engineering),不只是给 AI 对的资料(Context Engineering),而是搭建一整套系统------约束、验证、反馈、纠错------让 AI 在里面安全、可靠、持续地干活。
三个阶段的演进关系,一张表就能看清:
| 阶段 | 时间 | 核心问题 | 类比 |
|---|---|---|---|
| Prompt Engineering | 2022-2024 | 怎么跟 AI 说话? | 给员工一条口头指令 |
| Context Engineering | 2025 | 给 AI 看什么资料? | 给员工项目文档和操作手册 |
| Harness Engineering | 2026 | 给 AI 搭什么工作环境? | 给员工完整的工作环境:权限管理、质检流程、错误报警、行为红线 |
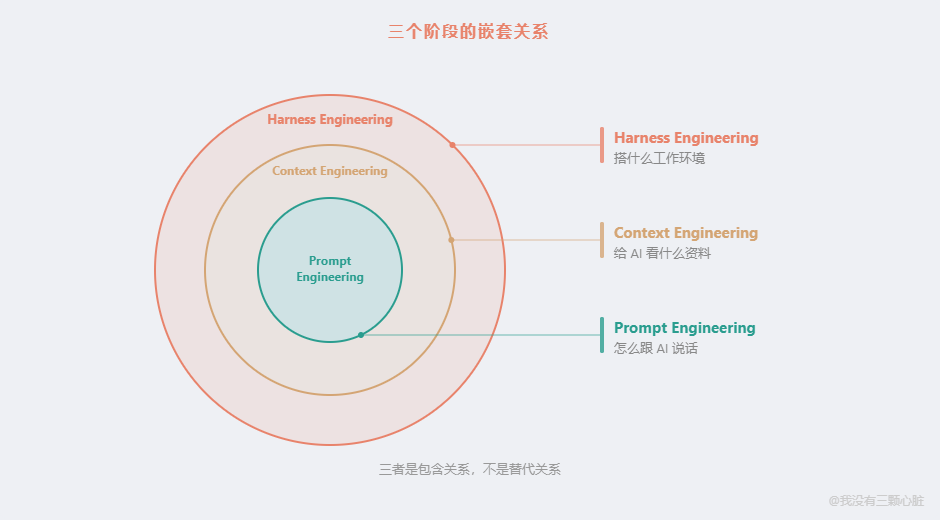
注意:这三者是嵌套关系,不是替代关系。 Harness Engineering 包含了 Context Engineering,Context Engineering 包含了 Prompt Engineering。你还是要写好提示词,还是要管好上下文------但仅仅做到这两点,在 Agent 时代已经不够了。
Part 3:拆解------Harness 到底长什么样?
说了半天"搭工作环境",这个"环境"到底包含什么?
根据 OpenAI Codex 团队的实践和业界的总结,一个 Harness 通常由四根支柱组成:
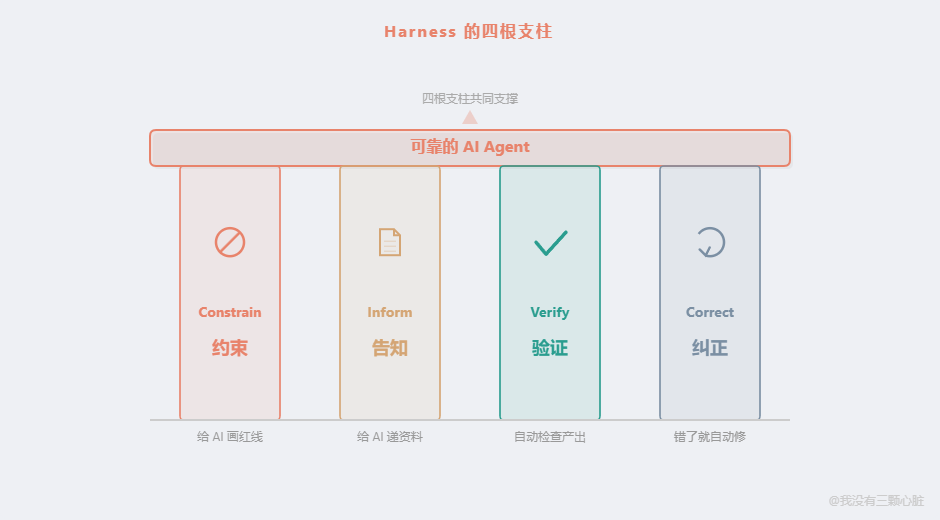
支柱一:约束(Constrain)------给 AI 画红线
核心问题:AI 哪些事绝对不能做?
AI Agent 能做的事情越多,它能闯的祸也越大。约束的作用,就是在 AI 开始工作之前,先画好红线。
具体怎么做?
- 权限控制:AI 只能读写特定的文件和目录,不能碰核心配置
- 操作限制:AI 不能执行删除操作,不能直接操作生产环境的数据库
- 架构边界 :AI 生成的代码必须遵守项目的分层结构------比如 OpenAI 的 Codex 团队规定,代码依赖只能按固定方向流动:
类型定义 → 配置 → 数据层 → 业务逻辑 → 运行时 → 界面,不能反向依赖
这些规则不是写在文档里"建议遵守",而是硬编码在系统里强制执行。AI 试图违反这些规则时,操作会被直接拒绝。
打个比方:新员工入职时的权限管理。他可以编辑自己负责的文档,但不能进入财务系统;他可以提交代码,但不能直接部署到线上。不是靠他"自觉",是系统层面不允许。
支柱二:告知(Inform)------给 AI 递正确的资料
核心问题:AI 需要知道什么才能正确地干活?
这一层和 Context Engineering 有很大的重叠。但在 Harness Engineering 里,"告知"更加系统化和结构化。
最典型的实践是 AGENTS.md 文件。
AGENTS.md 是一份用 Markdown(一种简单的文本格式语言,用 # 表示标题、用 - 表示列表,程序员和写作者都很喜欢用)写的文档,放在项目根目录下,专门给 AI Agent 读的"项目须知"。AI 在开始工作之前,会先读这个文件,了解项目的规则和约定。
一个简化的 AGENTS.md 大概长这样:
markdown
## 项目概述
- 这是一个用 TypeScript 写的 Web 应用
- 包管理器用 pnpm
## 常用命令
- 安装依赖:pnpm install
- 运行测试:pnpm test
- 构建项目:pnpm build
## 代码规范
- 使用 TypeScript 严格模式
- 用 interface 而不是 type 定义公共接口
- 单引号,不加分号
## 绝对禁止
- 不允许提交 API 密钥或任何凭证信息
- 不允许使用 var,只能用 const 或 letOpenAI 的 Codex 团队在实践中特别提到一个原则:AGENTS.md 要保持精简。 他们发现,如果把所有规则塞进一个巨大的文档里,AI 反而会被信息淹没,重要的规则被埋在大量细节中,效果适得其反。
他们的做法是分层:项目根目录放一份基础的 AGENTS.md 覆盖通用规则,各个子目录可以放自己的 AGENTS.md 覆盖特定领域的规则。AI 在某个目录工作时,会从当前目录向上查找,把所有层级的规则叠加起来。
打个比方:公司的新员工手册。不需要一本百科全书------需要一份精炼的"入职须知",告诉你最重要的规则、最常用的流程、最容易踩的坑。具体到某个团队,还有团队自己的补充说明。
支柱三:验证(Verify)------自动检查 AI 的产出
核心问题:AI 做完了,结果对不对?
这是 Harness 中最关键的一环。AI 生成了代码,你怎么知道代码是对的?
你不知道。所以你让机器来检查。
具体怎么做?
- 代码检查器(Linter):自动扫描代码是否符合格式规范、命名约定------比如变量名必须用驼峰式,文件大小不能超过 500 行
- 类型检查:确认代码里的数据类型是否匹配------比如你定义一个函数接收数字参数,AI 不能传一个字符串进去
- 单元测试:针对每个功能模块运行预设的测试用例,确认功能是否正常
- 构建验证:把整个项目编译一遍,确认没有语法错误、没有缺失依赖
- 结构测试 :这是 OpenAI Codex 团队的创新------他们编写了专门的测试来验证代码的架构是否合规,比如"业务逻辑层不能直接调用界面层的代码"
这些检查全部是自动化的。AI 每提交一次修改,这些检查就自动跑一遍。通过了才能合并,没通过就打回去。
打个比方:工厂流水线上的质检环节。不管工人(AI)觉得自己做得多好,产品必须通过 X 光检测、尺寸测量、功能测试------任何一项不合格,产品就回炉重做。 质检员不关心你"觉得"做得怎么样,只看客观数据。
支柱四:纠正(Correct)------错了就自动修
核心问题:检查出了错误,然后呢?
仅仅检查出错误是不够的。Harness Engineering 的关键创新在于:把错误信息自动反馈给 AI,让它自行修复。
这构成了一个闭环:
AI 生成代码 → 自动检查 → 发现错误 → 错误信息传回给 AI → AI 修复 → 再次检查 → 通过 → 合并OpenAI 的 Codex 团队在这一点上做了一个聪明的设计:他们的代码检查器(Linter)在报告错误时,不只是说"这行有错",而是在错误信息里直接嵌入修复指引。比如:
错误:文件超过 500 行限制。
修复方法:将此文件拆分为多个模块,每个模块负责一个独立功能。
参考现有模式:查看 src/services/ 目录下的文件组织方式。这段文字会被自动注入 AI 的上下文,AI 读到后就知道该怎么修------不需要人类介入。
但这只是"纠正"的一半。另一半更重要:纠正 Harness 本身。
这就回到了 Mitchell Hashimoto 说的那句话:"每次发现 Agent 犯了一个错误,你就花时间设计一个方案,让 Agent 再也不会犯同样的错误。"
AI 犯了一个新类型的错误?不是批评 AI,而是更新 AGENTS.md、增加一条 Linter 规则、或者写一个新的结构测试------让这个错误在系统层面不可能再次发生。
OpenAI 的 Codex 团队甚至专门跑了一批"垃圾清理 Agent"------这些 Agent 定期扫描整个代码库,检查文档是否和实际代码一致,检查是否有架构约束被遗漏,确保 Harness 本身不会"腐化"。
打个比方:这不只是老师批改作业、让学生重做。而是每次学生犯了一种新错,老师就在课本里加一条规则、在考卷里加一道相关题目------确保这一届以后的所有学生都不会再犯同样的错。
理解到这里,我突然意识到 Harness Engineering 的本质其实不新------它就是软件工程里"持续改进"的老思想,只不过管理的对象从"人类程序员"变成了"AI Agent"。以前你用 Code Review(代码审查)、CI/CD(持续集成/持续部署------一套自动化测试和发布的流程)来保证人写的代码质量;现在你用同样的思路,加上约束和反馈闭环,来保证 AI 写的代码质量。底层逻辑一模一样,只是"工人"换了。
Part 4:为什么这很重要?
让我们回到开头的数字。
OpenAI 的 Codex 团队------最多 7 个人,5 个月,100 万行生产级代码,1500 个 Pull Request,每个工程师每天完成 3.5 个 Pull Request。
而且他们发现了一个反常识的现象:团队从 3 人扩展到 7 人时,人均效率不降反升。 这在传统软件开发中几乎不可能------通常人越多,沟通成本越高,效率越低。但在 Harness Engineering 模式下,新加入的工程师不需要"学代码",他们需要学的是"怎么设计 Harness"------而 Harness 的规则是显式的、可共享的、可复用的。
这 7 个工程师的日常工作已经不是"写代码"了。
他们每天做的事情是:
- 设计架构约束,确保 AI 生成的代码不会乱长
- 编写和维护 Linter 规则,自动拦截常见错误
- 更新 AGENTS.md,把新发现的"坑"记录下来
- 审查 AI 提交的 Pull Request,确认方向正确
- 处理 AI 搞不定的边界情况
换句话说:他们从"代码的作者"变成了"AI 工作环境的设计师"。
这背后有一个更大的趋势。
AI 模型正在快速同质化------今天的 GPT(OpenAI)、Claude(Anthropic)、Gemini(Google),核心能力越来越接近。当模型本身不再是差异化的因素,真正的竞争力在于:谁能让 AI 更稳定、更安全、更高效地工作。
而这,就是 Harness 的价值。
Martin Fowler(他是软件工程领域最有影响力的思想家之一,著有《重构》等多部经典著作)的网站上也发表了一篇关于 Harness Engineering 的文章,讨论这种新范式对软件工程的影响。这不是一个小圈子的概念------它正在成为整个行业的共识。
但值得保持清醒的是: Harness Engineering 不是万能药。目前的成功案例大多集中在编程这个特定领域------因为代码有明确的对错标准(能编译、能通过测试、不破坏架构),天然适合自动化验证。在更模糊的领域(比如写市场文案、做战略决策),什么算"对"什么算"错"本身就不好定义,Harness 的验证环节就很难设计。
而且,随着 AI 模型推理能力的持续提升,今天某些需要靠 Harness 强制约束的问题,未来可能模型自己就能处理好了。
但有一件事不会变:只要你用的 AI 不是 100% 可靠的(目前没有任何 AI 是 100% 可靠的),你就需要某种"环境"来兜底。 这个"环境"的具体形态可能会演化,但"给 AI 搭工作环境"这个核心思路,会一直存在。
这跟你有什么关系?
你可能在想:这些听起来都是程序员的事,跟我有什么关系?
其实你已经在做 Harness Engineering 了------只是你可能没意识到。
如果你用过 Claude Code(Anthropic 推出的 AI 编程工具,在命令行里运行),你可能写过一个 CLAUDE.md 文件(和 AGENTS.md 类似,是专门给 Claude 读的项目指引),告诉 Claude"我的项目用什么技术栈""代码风格是什么""哪些文件不要动"。
如果你用过 Cursor(一个内置了 AI 能力的代码编辑器)或 GitHub Copilot(GitHub 推出的 AI 编程助手),你可能在设置里定义过一些规则,告诉 AI"用中文注释""不要引入新的依赖"。
即使你完全不写代码------如果你用过 ChatGPT 的"自定义指令"功能,给它设定了角色、语气和输出格式------你也已经在做最基础的 Harness Engineering 了。
这些,就是 Harness 的雏形。
而 Harness Engineering 告诉你的是:这不仅仅是"设置一些偏好"。这是一种系统性的方法论------你可以通过约束、告知、验证、纠正这四个支柱,把一个"时好时坏的 AI 助手",变成一个"稳定可依赖的工具"。
回到那句话------
"Agent 不难,难的是 Harness。"
翻译成日常语言就是:AI 已经够聪明了。现在的问题不是让它更聪明,而是怎么让它"稳定地聪明"。
Prompt Engineering 教你怎么跟 AI 说话。
Context Engineering 教你给 AI 看什么资料。
Harness Engineering 教你搭什么样的环境,让 AI 在里面安全、可靠、持续地干活。
AI 时代,最值钱的能力可能不是"会用 AI"------而是会给 AI 搭脚手架。
参考资料
- Harness engineering: leveraging Codex in an agent-first world - OpenAI
- My AI Adoption Journey - Mitchell Hashimoto
- The Rise of AI Harness Engineering - Cobus Greyling
- Harness Engineering - Martin Fowler
- OpenAI 'Harness Engineering' and Codex - InfoQ
- The Rise of Context Engineering - LangChain Blog
- AI Agents Ignore Security Policies - Dark Reading
- 88% of AI Agents Never Reach Production - Digital Applied
- Skill Issue: Harness Engineering for Coding Agents - HumanLayer
- Prompt Engineering vs Context Engineering vs Harness Engineering - Medium
订阅
如果觉得有意思,欢迎关注我,后续文章也会持续更新。同步更新在个人博客和微信公众号
微信搜索"我没有三颗心脏"或者扫描二维码,即可订阅。
