PP-StructureV3
github地址:https://github.com/PaddlePaddle/PaddleOCR
PP-StructureV3------复杂文档解析器,
能够智能地将复杂的PDF和文档图像转换为Markdown和JSON文件,并保留其原始结构 。在公开基准测试中,其性能优于众多商业解决方案。完美地维护文档布局和层级结构
本文在上一个懒人包的前提下,加了一个PDF转MD的API功能
参考之前的文章PaddleOCR CPU 懒人包 轻松识别中文图片文字
演示用的pdf

使用说明
启动文件新增了一个startGpu.bat,需要cpu启动的选择cpu,需要gpu启动的选择gpu
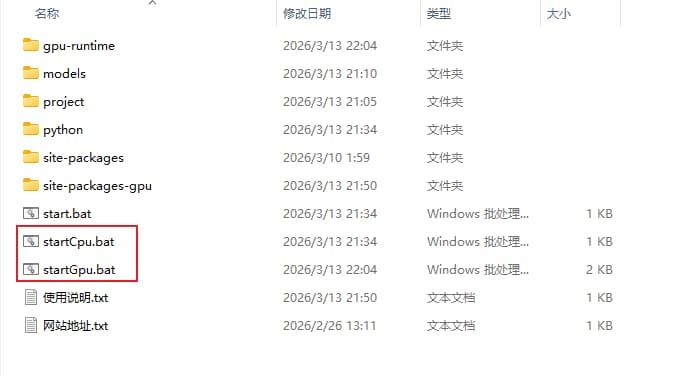
等待终端正常启动
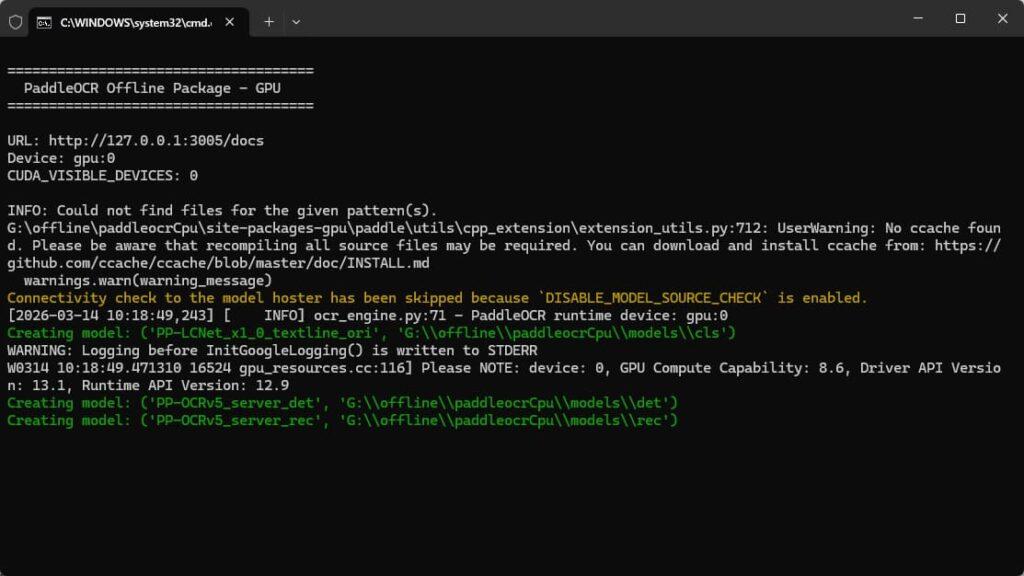
访问localhost:3005/docs
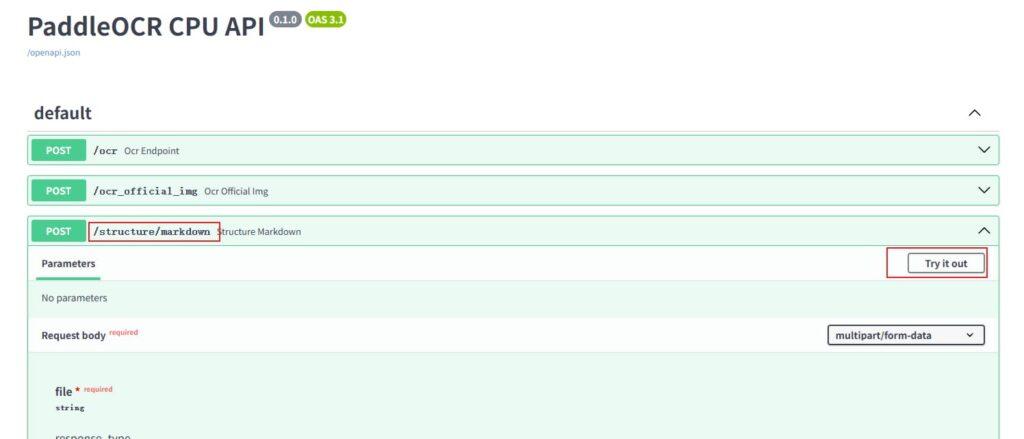
选择markdown接口,点击try it
选择要上传的pdf或者图片,点击Execute执行,就会获取对应的结果
参数可以是file文件,也可以是json,默认是json
Tips
点击此处 网盘下载
选择文件时,会返回文件下载,下载的为zip文件,解压缩会得到对应的md文件和图片文件
如果md内容复杂,有表格,公式等,建议使用专业的md编辑器软件打开,比如开源的marktext
github地址:https://github.com/marktext/marktext
对公式比较友好(使用showdoc之类的简易md,并不能正常显示公式之类的md内容,排版也比较混乱)
pdf转md接口同样也支持图片转md
由于cpu在pdf这个接口上相对比较慢,所以本期懒人包新增了gpu的支持,速度会快上几十倍
由于paperless-ngx内置的ocr只对英文识别效果友好,但是对中文识别不太好,所以打算顺手看看其他开源的ocr,其中paddleocr效果中英文效果不错
另外其他的ocr有空再继续使用对比一下
懒人整合包
注意事项
- 解压缩的软件,整个目录地址最好不好有任何中文,否则可能会出现未知错误,不方便排查和解决
- 如果地址访问不了,先查看控制台是否报错或者是否加载成功,有些项目需要加载久一点,不同电脑配置加载时间也不一样,有错误就查看日志,给ai排查
- 前面2个排除后还是打不开,有网络代理的记得关掉代理
- localhost或者127.0.0.1或者0.0.0.0都可以尝试一下(比如localhost:3005/docs)