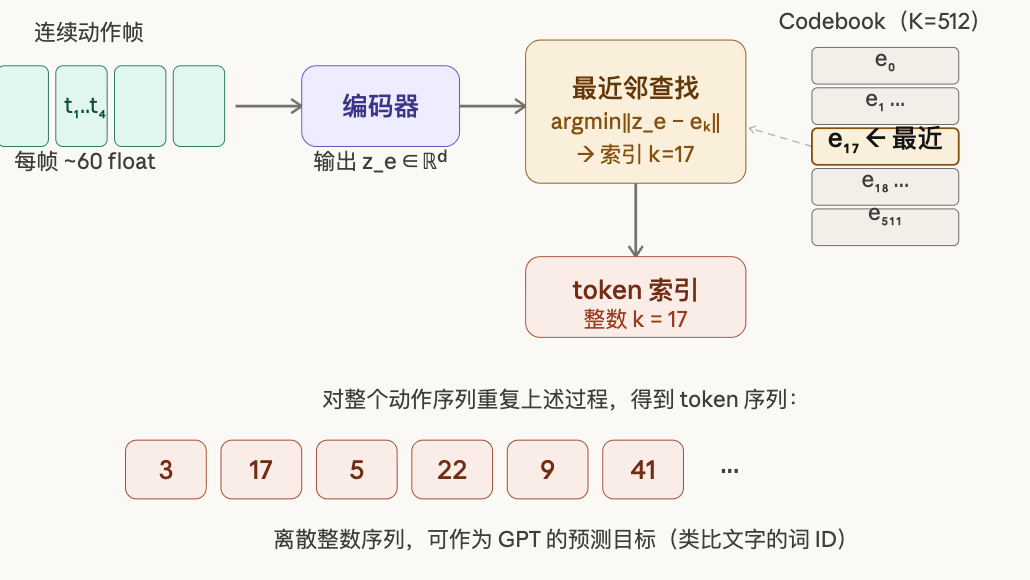
Stage 1:VQVAE 如何把连续动作离散成 token 序列
人体动作天然是连续的------每一帧都是几十个关节的角度值构成的浮点向量。VQVAE 要做的,就是把这种"无限精度的连续信号"压缩成一串"有限词表里的整数索引",就像把音乐压缩成 MP3 编码一样。
Codebook(码本)是关键。 训练前预定义一个大小为K的码本,里面有 K可学习的向量(码字)【只是预定义了码本的大小,这 K个向量的初始值通常是随机初始化,"可学习"发生在 VQVAE 的训练过程中】,例如 K=512。每个码字代表一种"动作基元"------可以理解成动作词汇表里的一个词。
VQVAE 的训练,是一个无监督的重建任务------不需要任何文字标注(文字描述是留给 Stage 2 的 GPT 用的),只需要动作数据本身。输入一段动作序列,压缩成 token,再解码还原,目标是让还原结果尽量接近原始输入。
- 训练前:K个码字随机初始化,值无意义
- 训练中 :每个 batch,编码器把动作压缩成
,查找最近的码字
- 训练后:码本固定不变,每个码字已经收敛成一个有语义的"动作基元"向量
- Stage 2(GPT 训练)时:VQVAE 和码本全部冻结,只是当作一个查表工具使用
具体过程分三步:
-
编码:编码器(通常是 1D 卷积网络)把连续动作序列的每几帧压缩成一个隐向量
编码器的核心操是卷积,但目的不只是"提特征",还要做时间维度上的下采样, 最终输出每个时间步对应的一个连续向量
一段动作序列的形状是 (T,D),T是帧数,D 是每帧的关节维度(比如 263 维)。编码器用几层 1D 卷积沿时间轴滑动,每层可以用 stride=2 把时间长度压缩一半。经过 n层下采样后,T帧变成约
这个压缩比很重要------它决定了 GPT 需要预测多少个 token。如果每 4 帧压成 1 个 token,一段 200 帧的动作就变成 50 个 token,GPT 的序列长度就是 50,降低建模难度。
1D 卷积和普通卷积的区别 在于卷积核只在时间轴上滑动,不在空间上滑动,因为关节维度之间的顺序本身没有局部性(第 3 个关节和第 4 个关节未必相邻相关)。所以核的形状是
-
量化 :把
-
解码:把索引 k对应的码字向量送入解码器,尝试重建原始动作帧。
训练目标是让重建误差尽量小,同时加一个 Commitment Loss 防止编码器输出漂移太远离码字。训练完成后,一段 TT T 帧的动作序列就变成了长度约T/4(下采样倍数取决于架构)的整数序列,例如 [3, 17, 5, 22, 9, ...],这就是 motion token 序列。
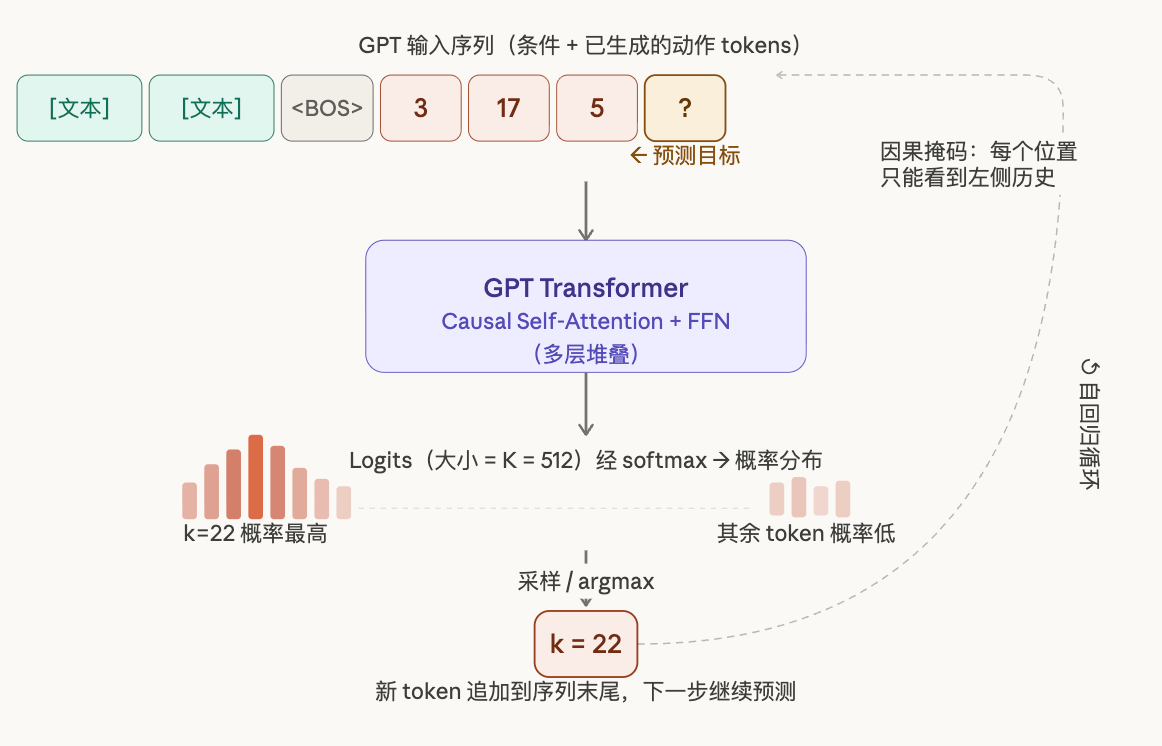
Stage 2:GPT 如何自回归地生成 token 序列
有了 VQVAE 提供的"动作词汇表",GPT 的任务就变成了一个条件语言模型问题:给定文本描述,预测动作 token 序列,就像语言模型根据上文预测下一个词一样。
两个 stage 的数据流是平行的,互不干涉,
动作 token 序列 是 VQVAE 把人体运动压缩后得到的整数序列,比如 [3, 17, 5, 22, ...],描述的是"身体怎么动"。
文本描述 是人写的自然语言句子,比如 "a person walks forward and then turns left",描述的是"这段动作在做什么"。就是 HumanML3D 数据集里配套标注的英文句子。
文本描述是条件输入------先经过 CLIP 或 T5 这样的文本编码器变成 embedding,告诉 GPT"你要生成什么样的动作"。
动作 token 序列是预测目标------GPT 要学会根据文本条件,一步步生成正确的整数序列。
输入拼接。 文本描述先经过 CLIP 或 T5 等文本编码器转换成 embedding,然后和已生成的 token 序列拼接在一起,作为 Transformer 的输入。
token就是 GPT 自己之前已经生成出来的动作 token。
这是自回归生成的核心逻辑------GPT 每次只预测下一个 token,而不是一口气生成整个序列。所以在生成过程中,"已生成的 token 序列"是动态增长的:
- 第 1 步:输入
[文本 embedding, <BOS>]→ 预测出 token3 - 第 2 步:输入
[文本 embedding, <BOS>, 3]→ 预测出 token17 - 第 3 步:输入
[文本 embedding, <BOS>, 3, 17]→ 预测出 token5 - ......以此类推
每一步里"已生成的 token 序列"就是前几步自己预测出来的结果,拼在文本 embedding 后面一起送进 Transformer,让模型既能看到"要生成什么动作"的条件,也能看到"已经生成到哪里了"的上下文。
所以这个序列在推理刚开始时是空的,随着每步预测不断追加,直到生成 <EOS> 结束。训练时加的token是真实的 token 序列------不用自己预测的结果,直接把真实答案喂进去,加速收敛。推理时才用自己预测的 token。 因为推理时根本没有"真实答案"可用
推理阶段自回归生成过程是这样的:
- 时刻 t=0:输入
[文本 token, <BOS>],预测第一个动作 tokenk̂₁; - 时刻 t=1:输入
[文本 token, <BOS>, k̂₁],预测 \hat{k}_2 ; - 依此循环,直到生成
<EOS>结束标记。
每一步 GPT 输出一个大小为 K(码本大小)的 logit 向量,经 softmax 后采样或取 argmax,得到下一个 token 索引。
训练时,用 VQVAE 提取的真实 token 序列作为监督目标,损失函数就是标准的交叉熵。这和语言模型训练几乎完全相同,只是"词汇表"换成了动作码本。
推理时,生成完整的 token 序列后,把每个整数索引送回 VQVAE 的码本查表取出对应向量,再经解码器还原成连续的关节角度序列,就得到最终的动作输出。