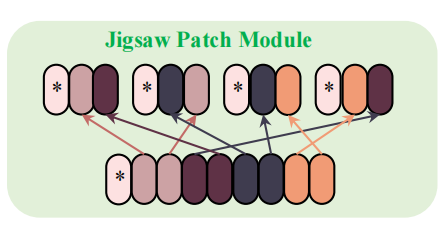
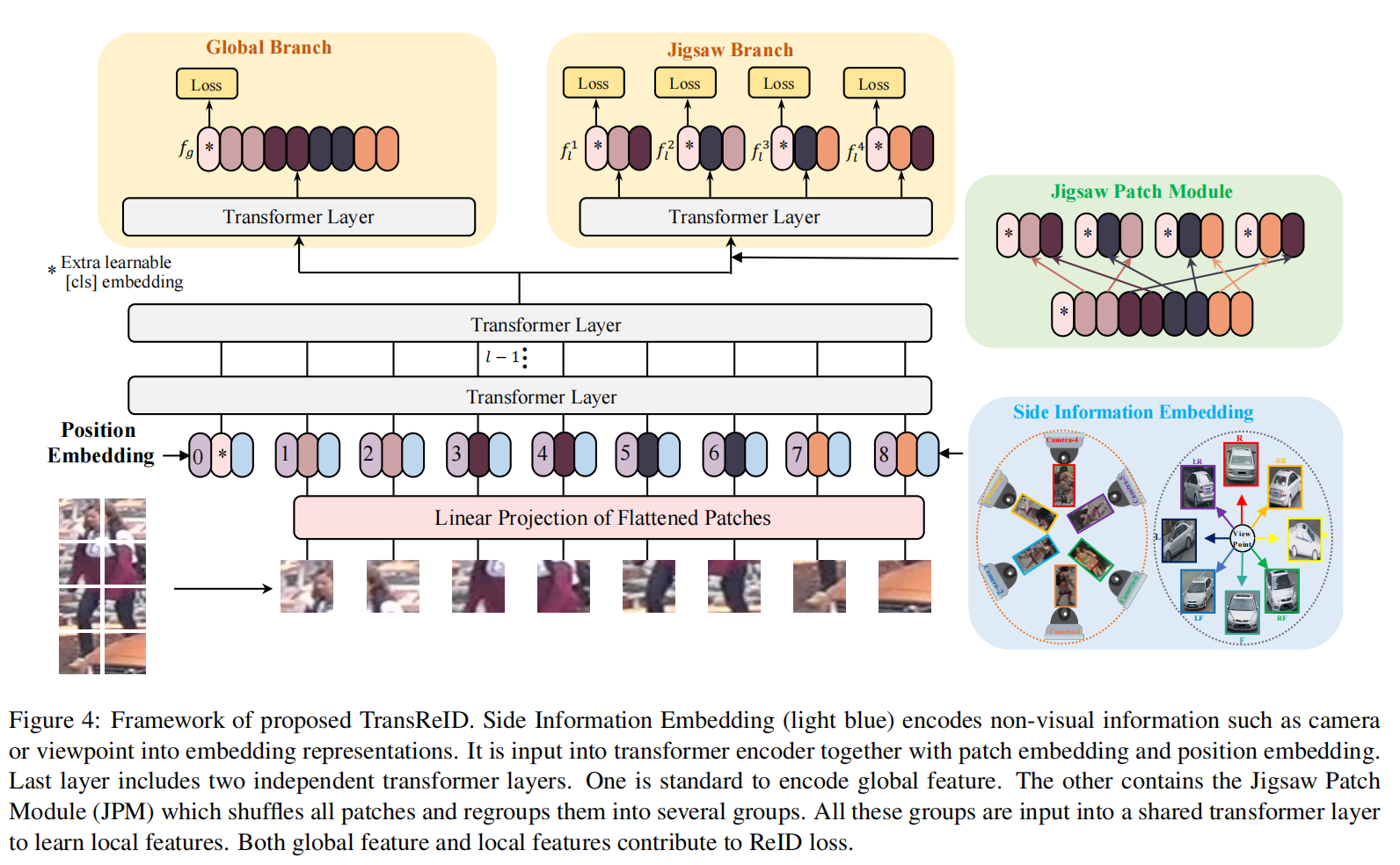
The JPM is employed on the last layer of the model to extract robust features in parallel with the global branch which does not include this special operation. Hence, the network tends to extract perturbation invariant and robust features with global context.
An extra learnable cls embedding token denoted as ( x_{\text{cls}} ) is prepended to the input sequences. The output cls token serves as a global feature representation ( f ). Spatial information is incorporated by adding learnable position embeddings. Then, the input sequences fed into transformer layers can be expressed as:
LID is the cross-entropy loss without label smoothing. For a triplet set {a, p, n} , the triplet loss LT with soft-margin is shown as follows: \mathcal{L}_T = \log \left 1 + \\exp \\left( \\\|f_a - f_p\\\|_2\^2 - \\\|f_a - f_n\\\|_2\^2 \\right) \\right
Pure transformer-based models(e.g. ViT, DeiT) split the images into non-overlapping patches, losing local neighboring structures around the patches. Instead, we use a sliding window to generate patches with overlapping pixels. Denoting the step size as SS , size of the patch as PP (e.g. 16), then the shape of the area where two adjacent patches overlap is (P−S)×P. An input image with a resolution H×W will be split into N patches.
we propose a jigsaw patch module (JPM) to shuffle the patch embeddings and then re-group them into different parts, each of which contains several random patch embeddings of an entire image. In addition, extra perturbation introduced in training also helps improve the robustness of object ReID model. Inspired by ShuffleNet 53, the patch embeddings are shuffled via a shift operation and a patch shuffle operation.
As shown in Figure 4, paralleling with the jigsaw patch, another global branch which is a standard transformer encodes, where fg is served as the global feature of CNN-based methods. Finally, the global feature (f_g) and (k) local features are trained with L_{ID}and L_T. The overall loss is computed as follows:
.
JPM模块就是将上文提到的image patch打乱, ,再分组,使每组特征都有近乎全局的特征。
,故JPM部分的损失函数应该这样写。
Instead of the special and complex designs in CNN-based methods for utilizing these non-visual clues, we propose a unified framework that effectively incorporates non-visual clues through learnable embeddings to alleviate the data bias brought by cameras or viewpoints. Taking cameras for example, the proposed SIE helps address the vast pairwise similarity discrepancy between inter-camera and intra camera matching (see Figure 6). SIE can also be easily extended to include any non-visual clues other than the ones we have demonstrated.
Side Information Embeddings (SIE) 的"自动更新"机制,是通过将其作为可训练参数 融入Transformer的输入端,并利用端到端的反向传播来实现的。整个过程无需人工干预,模型会自行学习如何利用相机ID、视角等非视觉信息来优化最终的特征表达。
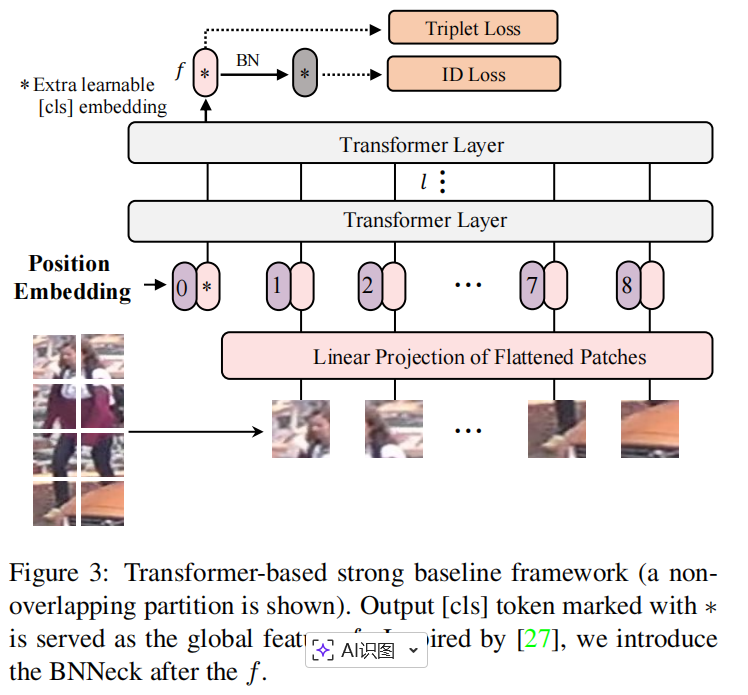
, where fg is served as the global feature of CNN-based methods. Finally, the global feature (f_g) and (k) local features are trained with L_{ID}and L_T. The overall loss is computed as follows: