医院的墙壁,
听过世界上最虔诚的祷告。
手术室大门打开,
绿色手术服走进光里。
中国科学院香港创新研究院,
人工智能与机器人创新中心,
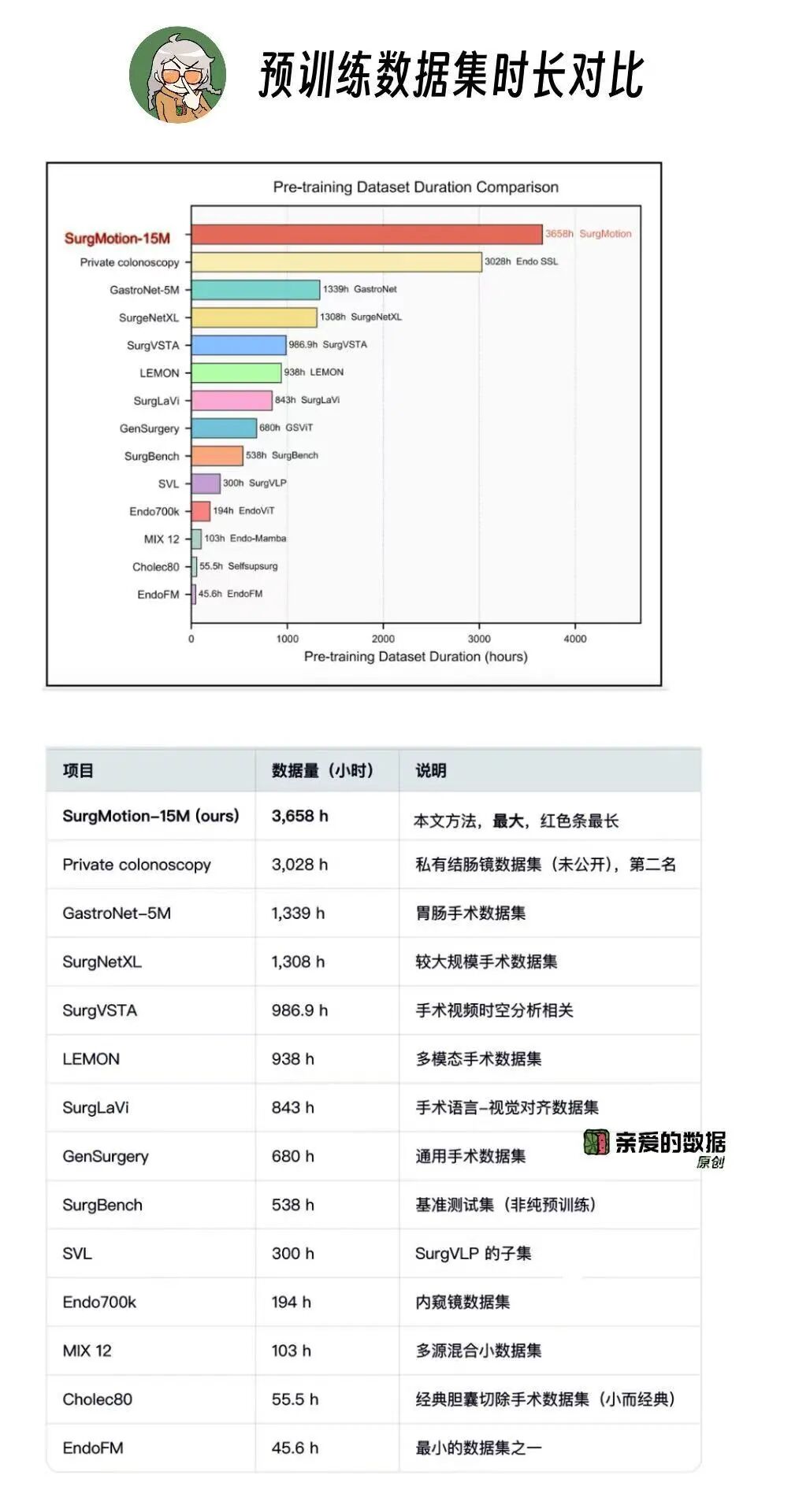
AI大模型吃透3658小时手术视频,
包括13个人体器官,
70个解剖结构,
100多种术式;
淬炼出1B的模型参数,
整个训练涉及到的数据,
有75%来自合作医疗机构,
首次仅对该团队开放的私有资料,
并且全部经过严格的医疗伦理审查。
训练推理与医生患者如此有力地握手,
这一切,都是为了一个开源大模型,
全球首个开源手术视频大模型SurgMotion。
一个严肃的话题,
一个前沿的医疗技术,
一次扎扎实实的科研努力。
医疗AI的赛道里,
影像、语言模型早已遍地开花,
但手术视频这个最贴近临床操作的场景,
却一直是难啃的硬骨头。
在此背景下,
SurgMotion正式开源。
这个不是AI生成电影那种大模型,
它生成不了花里胡哨的视频,
而是能给出医疗建议。
我的结论是,
大模型+机器人替代顶尖手术医生,
在十年内都无可能。
努力成为医生完美的"打下手"。
有可能让手术医疗水平与安全再上一个台阶。
手术视频大模型第一期,
对话论文作者之一------易东博士:


提问:为什么手术视频大模型,是医疗AI最难哪道题?
回答:
首先,做过手术、了解手术的人都知道,
手术视野里满是血肉组织,
没有全局参考,
外行人看就是"一团血",
哪怕是专业医生,
也会被视野限制、受操作节奏影响,
从而错过关键细节。
而难点远不止"看清楚"这一个。
其次,手术场景的特殊性要求高:
手术里的关键事件都是"瞬间性"的,
比如,局部小出血,
医生是在出血的1-2秒内发现,及时止血,
假如等视野被血染红,
视频大模型再找出血点,
不仅毫无意义,
而且徒增手术风险;
再者,医生手法的"流派差异"带来泛化难题:
不同医院、不同医生的手术步骤、
操作习惯都有差异,
有的医生先切这里,有的先处理那里,
模型必须兼容这些差异,才能落地;
最后,视频本身的信息冗余难题,
和信息密度极高的语言数据不同,
哪怕好不容易拿到高达几千小时的视频时长,
压缩后有效信息并不多,
模型找到核心特征非常困难。
提问:为什么论文最先强调像素级重建目标?这是在强调什么?
回答:
像素级重建会逼模型,
把算力浪费在还原这些没用的光影、
雾气、水渍细节上。
它学的是:
"这里血流过去几帧,这里反光闪一下。"
但手术真正重要的是:
手术器械在干嘛?动作是什么?步骤走到哪?
医生操作逻辑是什么?
也就是说,镜面反光(specular reflections)
液体流动(fluidmotion),
是低层次视觉细节,
而这些细节对理解手术语义,
(如操作步骤、器械使用、技能水平),
几乎没有帮助,甚至可能是干扰噪声。
手术视频分析的最终目标是,
高层次语义理解,
第一,手术阶段识别;
第二,动作三元组识别(动作+器械+目标);
第三,技能评估;
抓不住重点,这导致模型学到的表示,
虽然能"看起来像原视频",
但缺乏对关键语义结构的抽象能力。
好比,考试考默写课文,
但真正需要的是理解文章思想------
结果学生只会背字,不会思考。
正因为像素重建不合适,
作者才提出"从像素重建转向潜在运动预测",
shift from pixel-level reconstruction
to latent motion prediction;
新方法不再要求模型"画出每一帧",
而是让它预测视频中隐含的运动模式------
这才是理解手术流程的关键。
后续提出的三项技术创新:
1.motion-guided masking,
2.self-distillation,
3.SFDR,
都围绕"如何更好地学习语义相关的运动"。
论文思想是,找到"低层细节vs高层语义"矛盾,
为转向"运动预测"这一新范式提供充分理由。

提问:手术AI应如何选择切入点落地?
回答:
比如自动驾驶这种模式,也是要动作操作的,
难度在于路况车况复杂。
一个初级水平司机的培养时长是月数,
手术的医学生培养是5+3+X(年),
X是不同手术的难度,
对应训练成熟手术医生所需要的年数。
虽然术式种类很多,
有的官方认可的专业术式有上千种,
经常性手术20多种,
而2024年中国手术人次1亿。
考虑AI可以从经常做的手术种类里面下手。
达芬奇手术机器人研发初期,
也是瞄准数量大的手术种类,
一方面是商业考量,
一方面是受益人群规模的考量。


提问:可否解释下核心指标?
回答:
SurgMotion在两个核心「像素级感知」任务上,
和全球10+款主流手术AI模型的PK结果,
两项指标全拿第一。
1.深度估计(Depth Estimation):
RMSE越低越准,也就是说:
AI能精准还原手术视野的3D空间结构,
知道器械、病灶、组织的真实远近和深度,
给手术导航、精准操作打基础。
2.病灶分割(Segmentation):
AvgDice越高越准;
AvgDice(0.850):
目前行业最高精度,
领先第二名Dinov3-H(0.842);
AI能精准圈出每一个病灶
比如,消化道里的息肉,
给每一个像素打标签:
是不是病灶?良恶性程度如何?
这种未来临床价值上,
可以给医生做「术中智能提醒」,
帮医生快速定位病灶、判断性质,
减少漏诊、误诊。
怎么帮助医生呢?
一句话就是,提升手术的质量。
肉眼可见的结果包括,
出血少、病人恢复快。
还能怎么帮助医生呢?
年资短的医生复盘手术、练习手法时,
模型精准指出操作偏差,
比如"器械角度偏5度""动作节奏过快",
不用再单纯靠摸索,
AI缩短手术医生成长周期。
目前,有两种赋能手术的方式:
第一种,模型跟医生配合,
或帮医生做预警和提醒,
目标都是提升手术水平。
第二种,模型和机器人结合,
包括但不限于达芬奇手术机器人。
比如,达芬奇可以相当于一个医生有三双手。
传统的手术,一个主刀加两个助手,
其实也是三双手。

更多阅读
《AI产品和技术模块》
2.搞懂"记忆"必看|吃透Engram,坐等Deepseek新模型
《具身智能》
1."26年具身智能,做不过来,根本做不过来":含陶大程教授独家专访
《AI+医疗》
2.离谱!熬夜三年肝损害,AI博主也靠AI学"续命"医学知识
《超节点系列》
1.对抗NVLink简史?10万卡争端,英伟达NVL72超节点挑起
3.阿里华为『血战』英伟达AI超节点:悲观者正确,乐观者赚钱
5.OCP现场 l 北美AI巨头罕见共识ESUN,为利益『握手』
《广域网》
