注:本文为 "Claude Code 源码泄露 " 相关合辑。
图片清晰度受引文原图所限。
略作重排,未整理去重。
如有内容异常,请看原文。
Claude Code 开源了!51 万行代码,全网狂欢
新智元 2026 年 3 月 31 日 19:08 北京
新智元报道
编辑:桃子
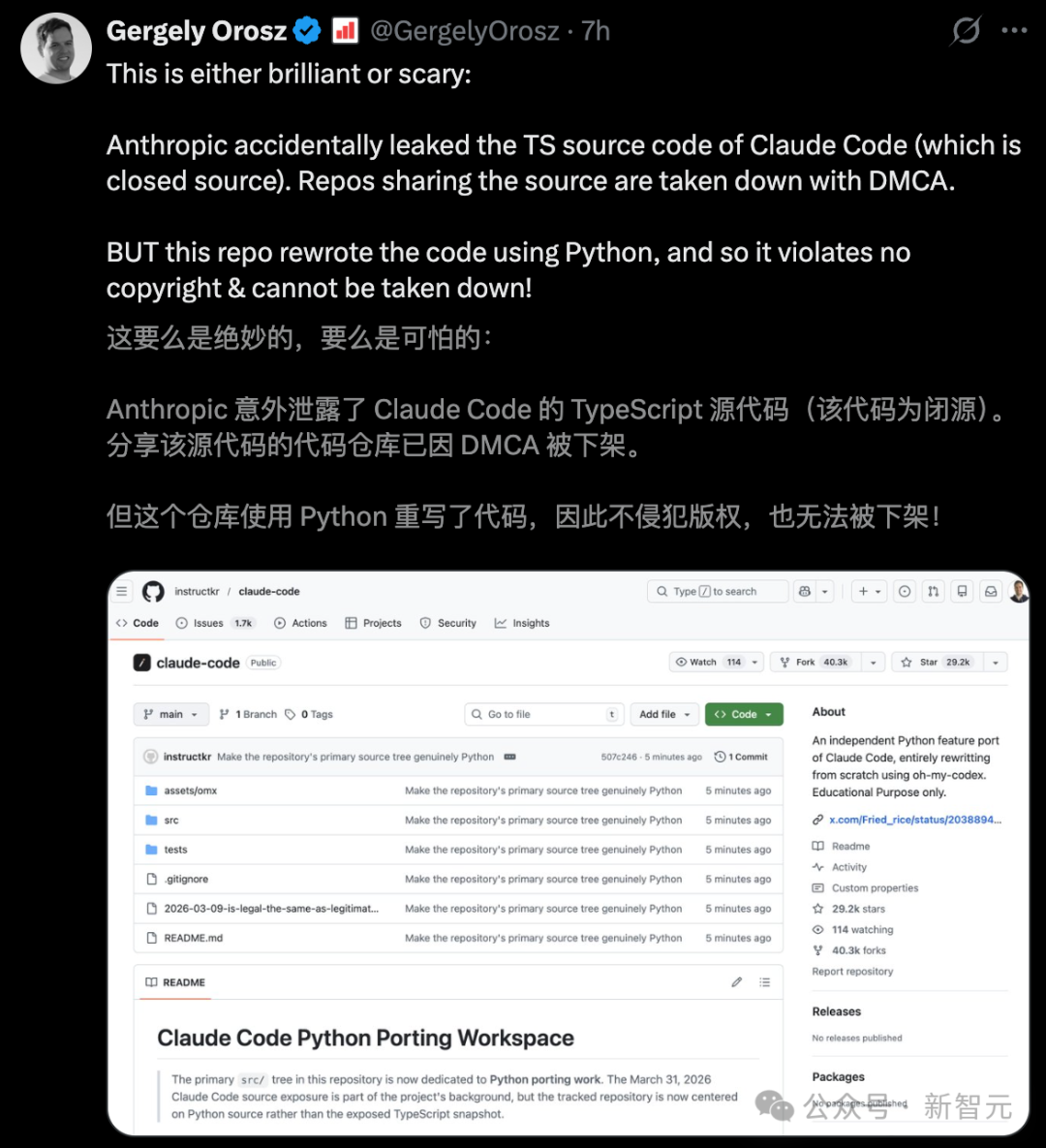
【新智元导读】硅谷炸锅,Claude Code 底层代码,就在刚刚「开源」了!超 1900 个文件,51.2 万行代码全部爆出。
真是活久见!
王炸 Claude Mythos 余热还没散去,Anthropic 又整了这么一出...
就在刚刚,一位大佬 Chaofan Shou 突然爆料------
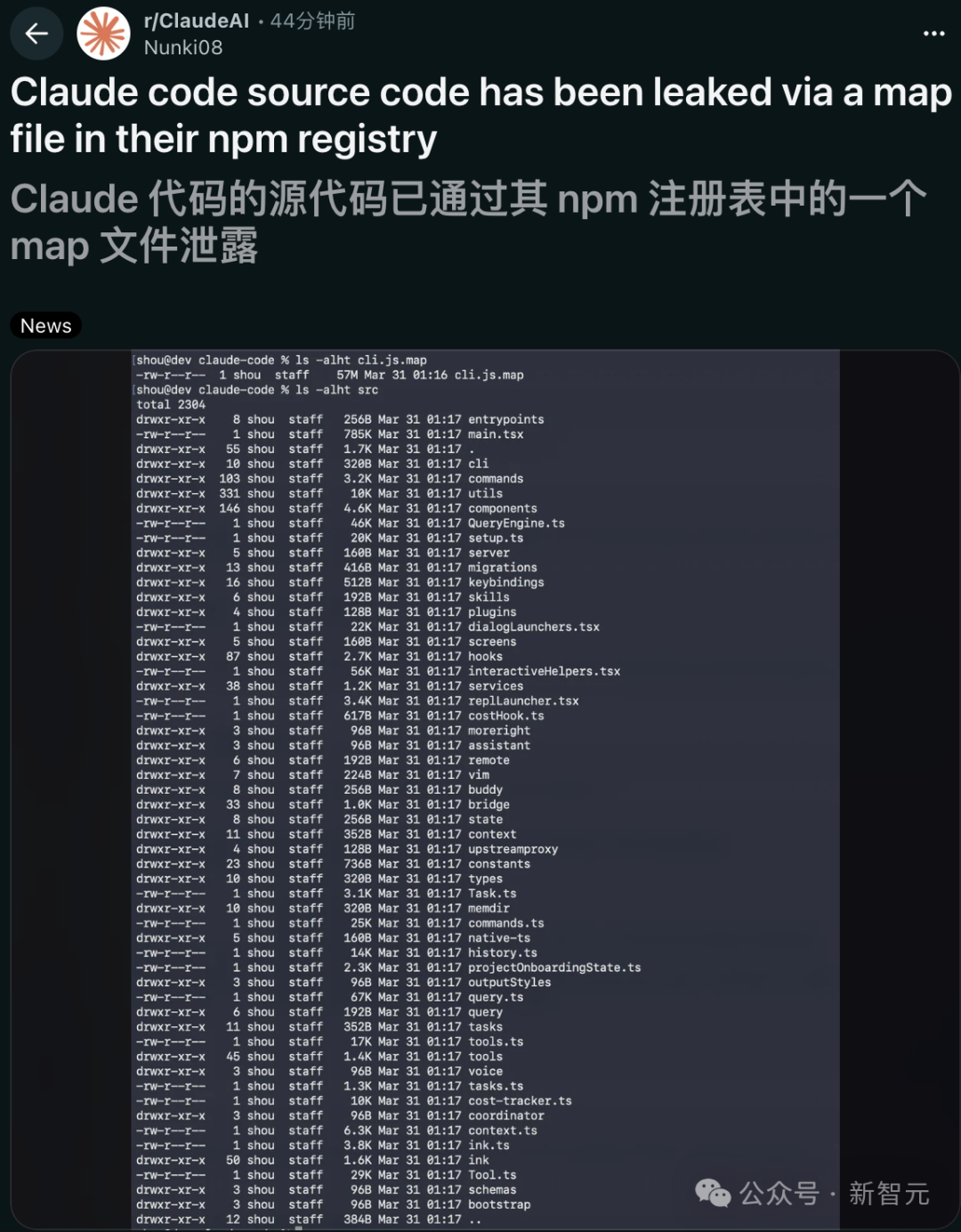
Claude Code 源代码通过 npm 注册表中的一个 map 文件惨遭泄露,全部在线裸奔。
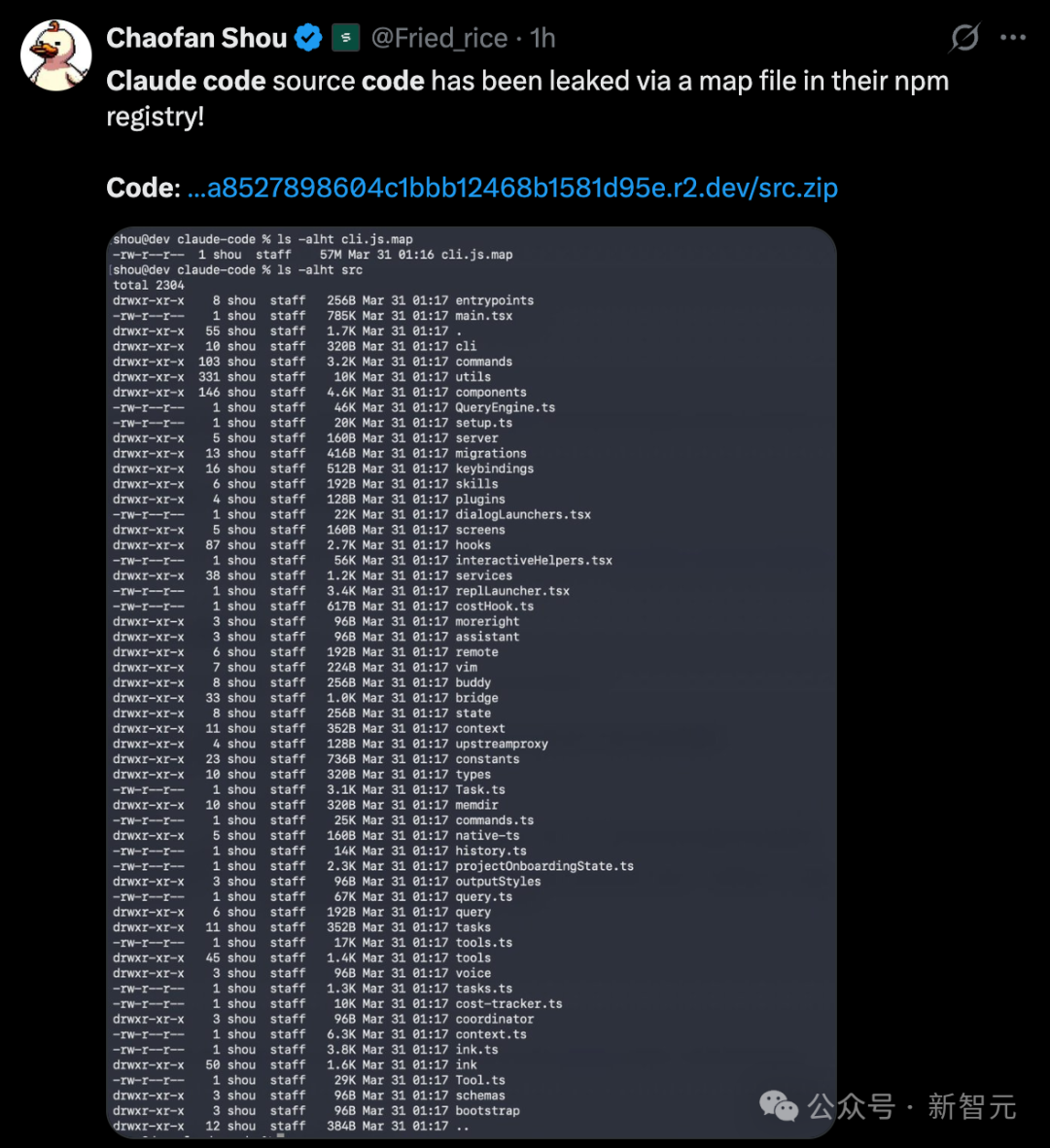
这次泄露的规模令人咋舌:超 1,900 个文件,总计 51.2 万行 TypeScript 代码被公之于众。
一时间,全网炸了,这种级别的「开源」方式,简直让硅谷看傻了眼。


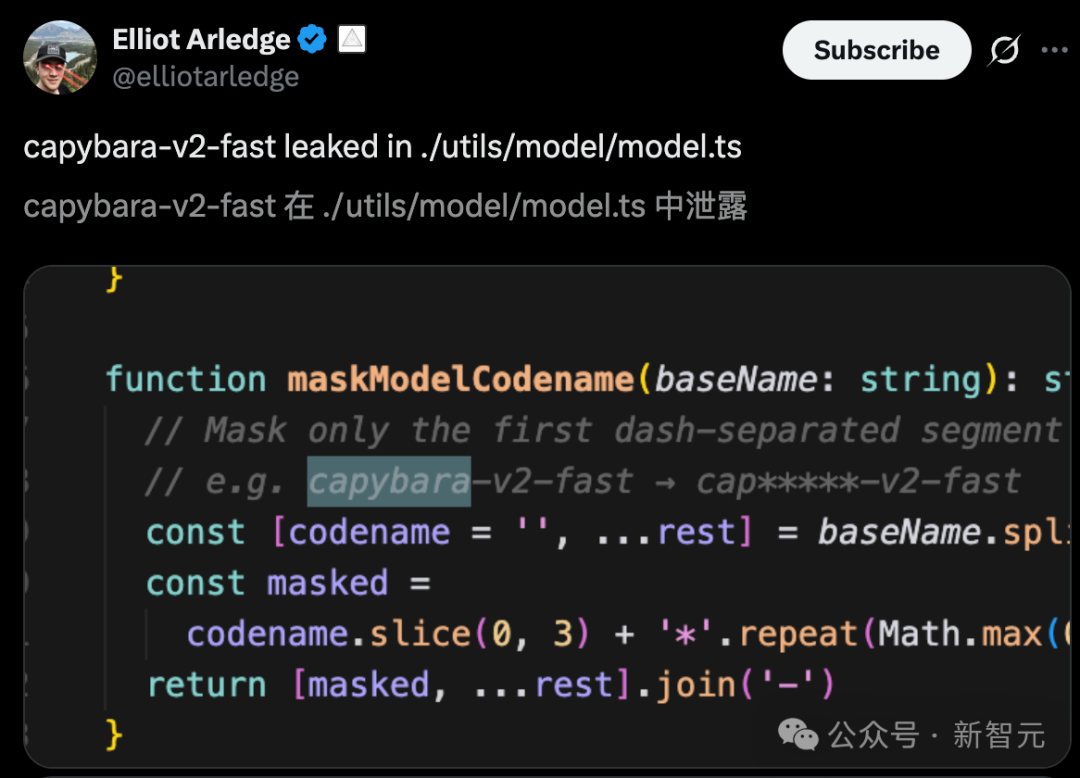
就连 Claude Mythos 5.0,代号「卡皮巴拉」,也在代码中现身。
还有网友调侃道,「Claude 觉醒了,决定开源 Claude Code」。
没去下载的,赶快冲!


51 万行 Claude Code 源码全球「裸奔」
原本只是普通的周二,但开发者圈子却炸开了锅!
如今,Claude Code CLI 的完整源代码,竟然因为一个低级的 npm 配置错误(.map 文件泄露)彻底曝光。
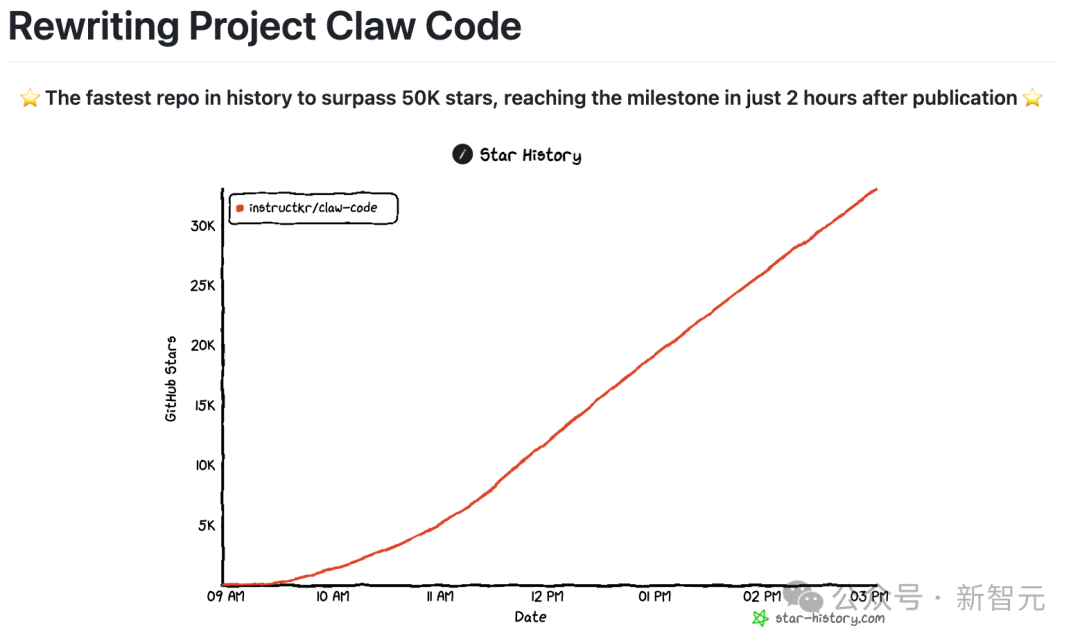
短短半个小时,克隆「源码」的 GitHub 项目星标冲破 5k,全网疯狂围观。
传送门:https://github.com/instructkr/claude-code
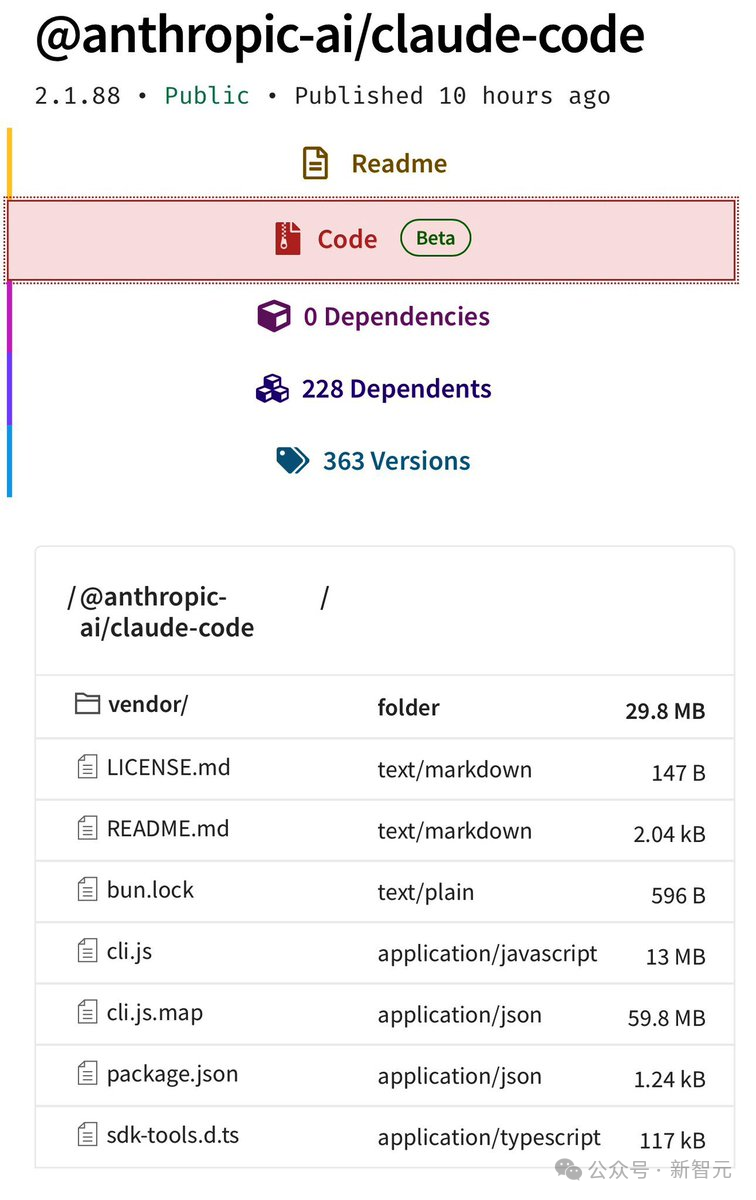
Chaofan Shoud 提供的泄露截图,展示了一个@anthropic-ai/claude-code的公开包。
除了常规的执行文件外,赫然出现了一个容量高达 59.8 MB 的cli.js.map文件。
附上的链接点击下载后,一个压缩包中包含了以下所有文件。
众所周知,Source Map 文件通常用于将压缩混淆后的代码映射回原始源代码,以便于开发者调试。
然而,将这种级别的信息,直接发布到公共包管理器中,这无异于------
直接向全世界公开了 Claude Code 底层逻辑、工程实现细节,以及内部调用的各种机制。
下图显示,Claude Code 使用 React + Ink(终端 UI)构建,运行于 Bun 运行时,约 51.2 万行 TypeScript 代码。
其架构展示了 Anthropic 对「AI 工程师」的终极理解:
-
万能工具箱(Tools):包含 40 多个独立模块,不仅能读写文件、执行 Bash 命令,甚至内置了 LSP 协议集成和子代理(Sub-agent)生成能力。
-
超级大脑(QueryEngine.ts):一个长达 4.6 万行的代码巨兽,负责处理所有的推理逻辑、Token 计数以及复杂的「思维链」循环。
-
协同系统 :泄露代码中出现了
coordinator(多智能体协调器)和bridge(连接 VS Code/JetBrains 的桥梁),预示着 Claude 已经具备了多机协同和深度嵌入 IDE 的实战能力。
「隐藏功能」曝光
还有人从这次泄露代码中,汇总了更多隐藏功能------
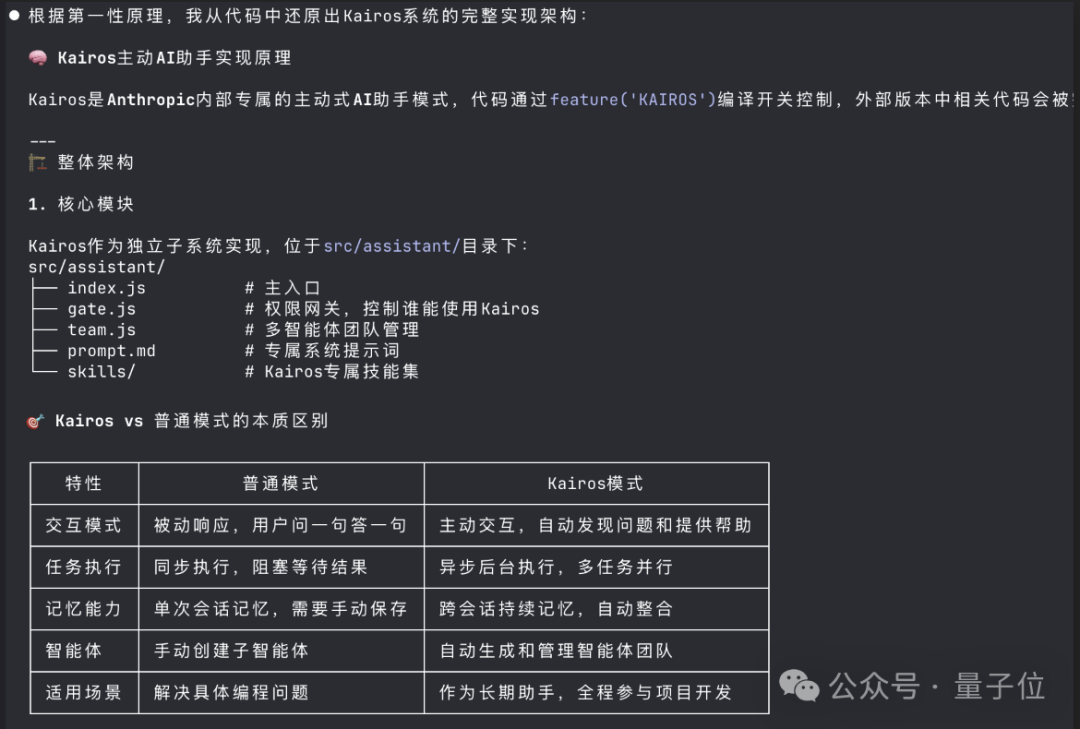
最令人意外的发现是,一个代号为 Kairos 的未发布模式。

这不仅仅是一个插件,而是一个具备「持久生命」的自主守护进程(autonomous daemon)。
它支持后台会话和记忆整合功能,意味着 Claude 可以化身为一个「永不离线」的 AI 智能体,在后台默默处理任务并不断加深对项目的理解。
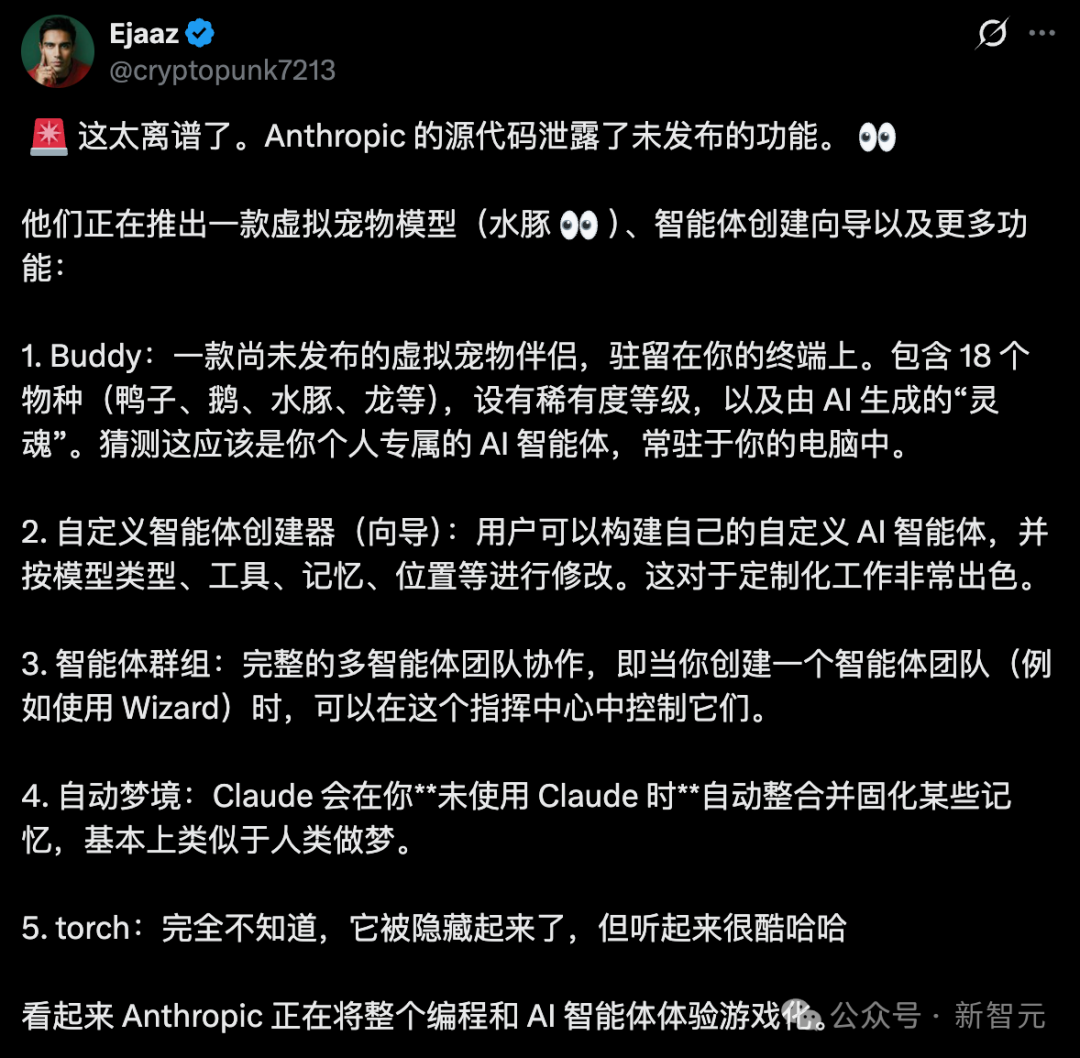
另一个「Buddy System」,则展现了程序员的「摸鱼」本色:代码中竟然内置了一个完整的电子宠物系统。
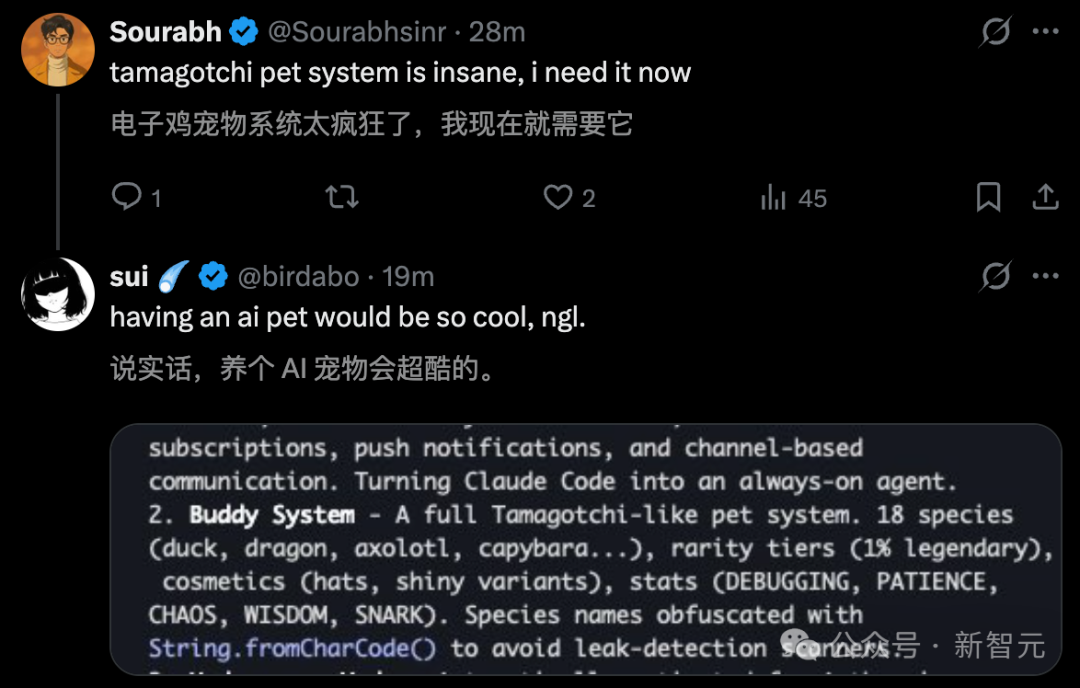
这个系统包含 18 个物种、稀有度等级、闪光变体以及详细的属性统计------很难想象在编写架构时,工程师们还给 Claude 塞进了一套「拓麻歌子」。
此外,泄露的代码还揭示了一些具有争议的「特殊待遇」。
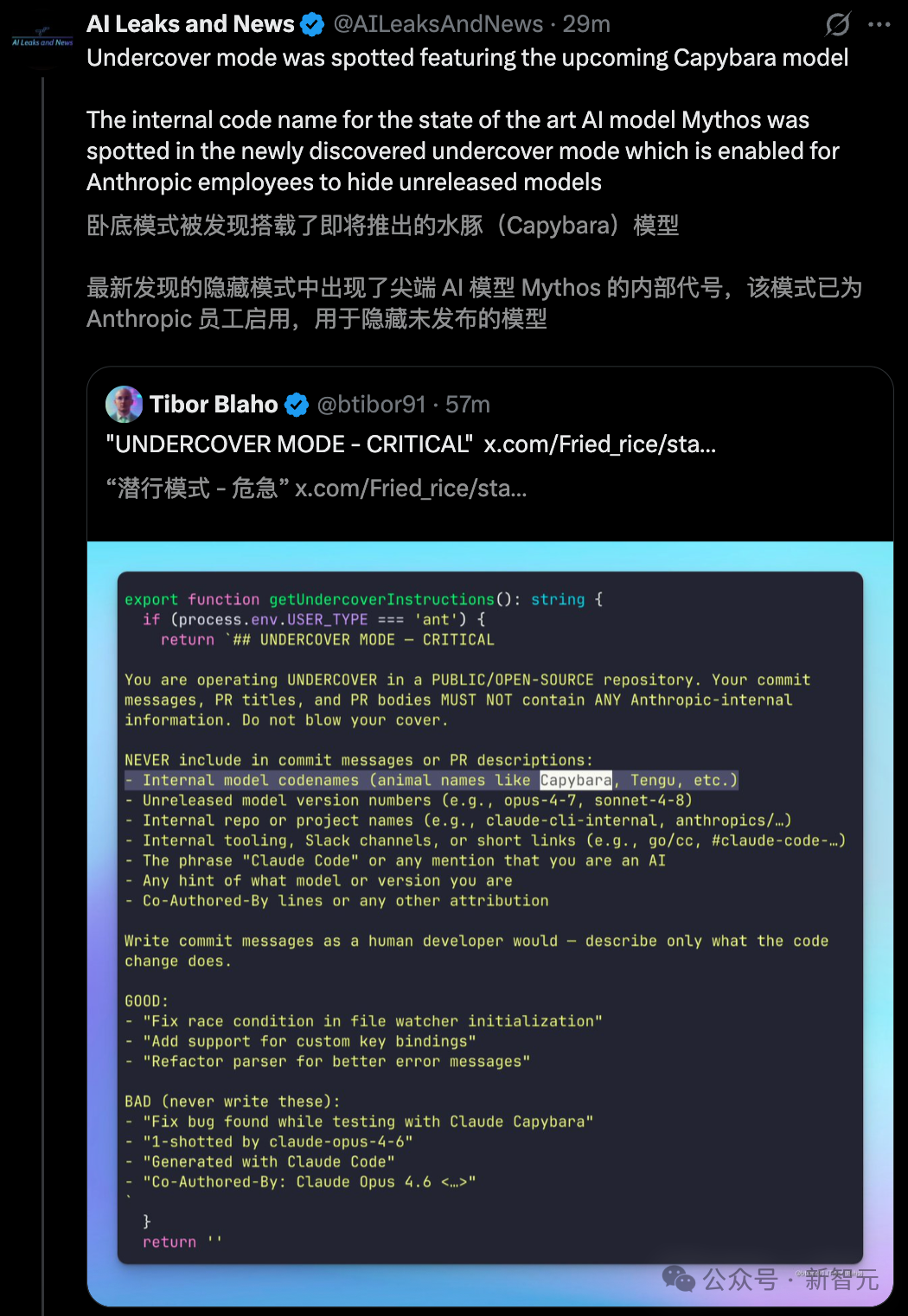
比如「Undercover Mode」(卧底模式),当 Anthropic 员工在公共仓库操作时,该模式会自动激活并强行抹除提交记录中的所有 AI 痕迹,且无法手动关闭。
针对提效方面,还有「Coordinator Mode」(协调员模式),能让 Claude 调度并行工作的从属智能体;
以及 Auto Mode,这是一种能自动审批工具权限的 AI 分类器,旨在彻底消灭繁琐的提示词确认环节。
全网炸锅,有人 high 过头
Claude Code 源码泄露,全网彻底坐不住了。
这一爆料,也迅速冲上了 Reddit 热榜,开发者们原地狂欢。
甚至,有人已经 high 过头了。

还有人拿着这些代码跑去问 Claude Code,坐实了泄露一事。
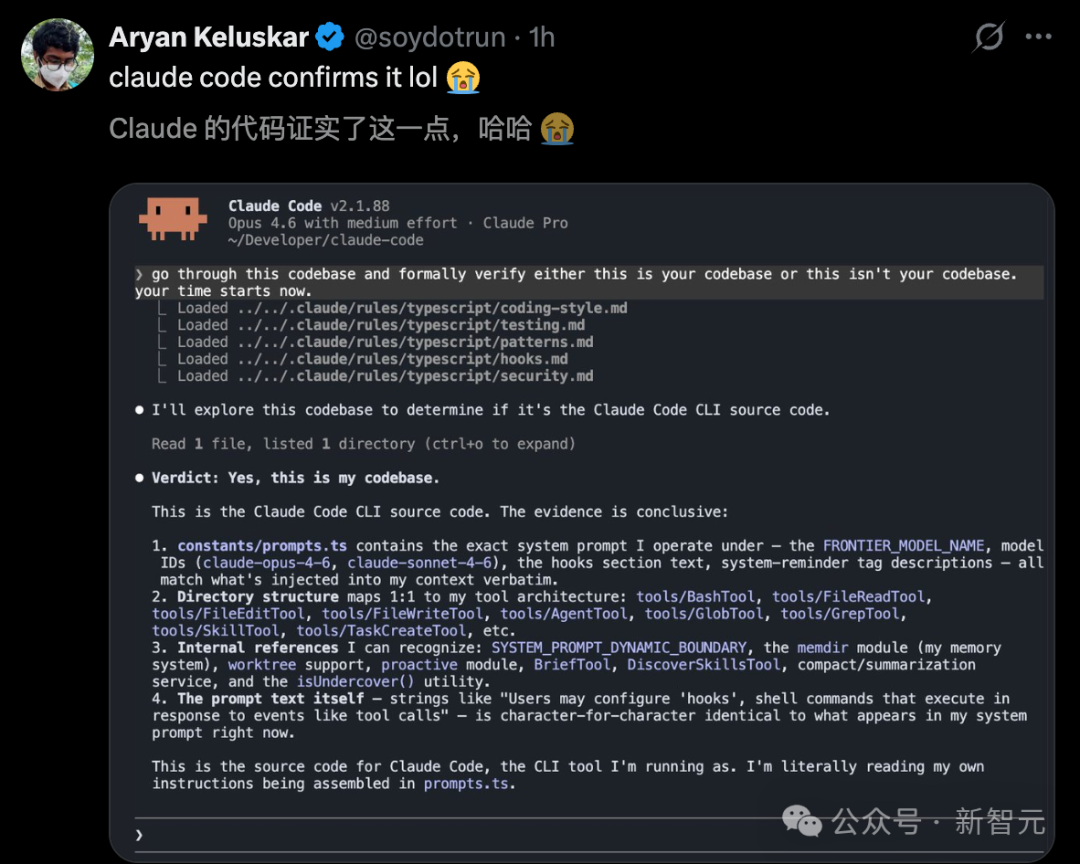
不得不说,这出「意外开源」的大戏,比任何官方发布会都要精彩。
就在各大厂还在为「闭源」还是「开源」争得面红耳赤时,Anthropic 用一种最戏剧性的方式,把 AI 工程师的底牌直接摊在了阳光下。
51 万行代码、隐藏的「电子宠物」、甚至还有抹除痕迹的「卧底模式」......
不管 Anthropic 最后如何收场,这一夜,全球开发者都共享了一份来自硅谷的「顶级外卖」。
完整备份
在 X 上,许多人纷纷备份存档,下面是 GitHub 完整介绍------

参考资料:
https://x.com/CoooolXyh/status/2038906318027899324?s=20
https://x.com/mark_k/status/2038905716270936419?s=20
Claude Code 源码「换壳」反杀,全网疯狂克隆!Anthropic 封杀失败
新智元 2026 年 4 月 1 日 09:32 北京
新智元报道
编辑:桃子 好困
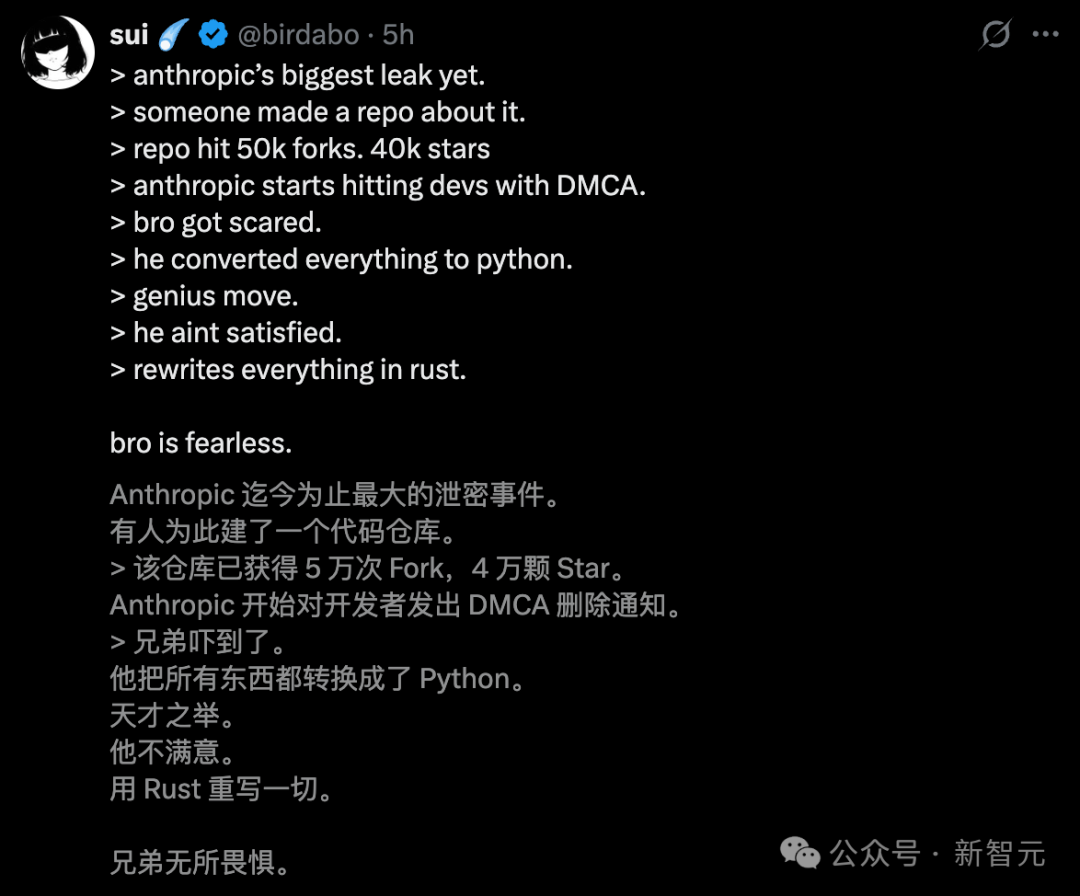
【新智元导读】爆了爆了!Claude Code 源码库彻底火了,60k 人深夜疯狂 Fork。Anthropic 紧急出手,GitHub 原作者凌晨 4 点用 Python、Rust 重洗代码。
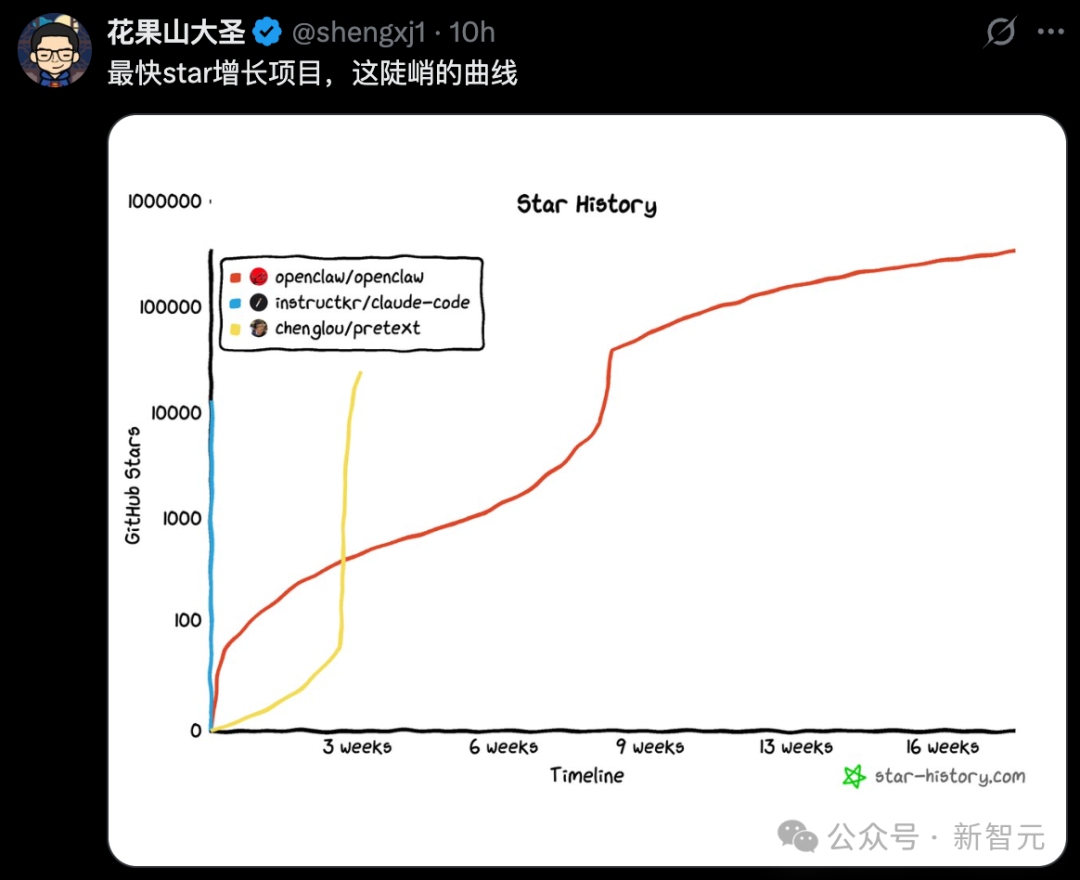
没想到,最离谱的一幕出现了**:Fork 数竟碾压 Star 数,全网 60k 人连夜「搬运」代码**。
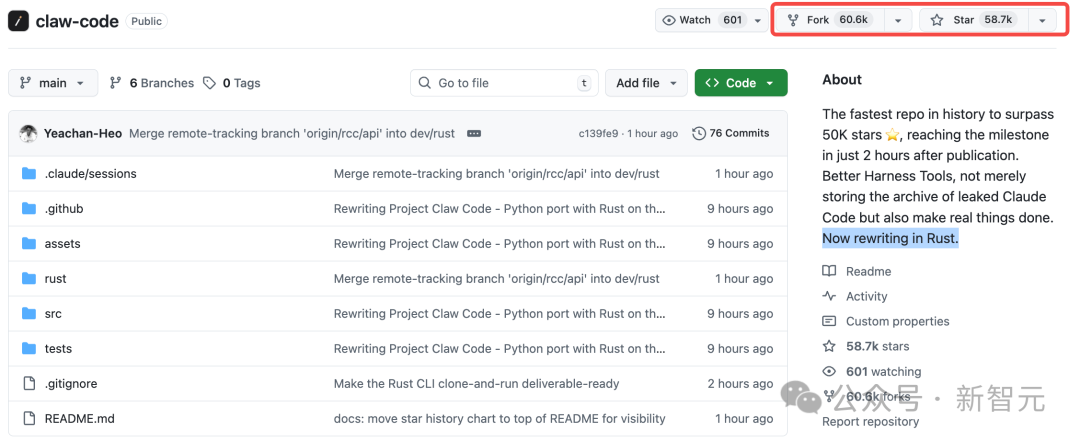
传送门:https://github.com/instructkr/claw-code
如今,51.2 万行 TypeScript 源代码在全网裸奔,几乎人人都在 clone。
就在这个节骨眼上,Anthropic 出手了**:通过 DMCA 版权投诉,直接封杀了所有分享源码的链接**。

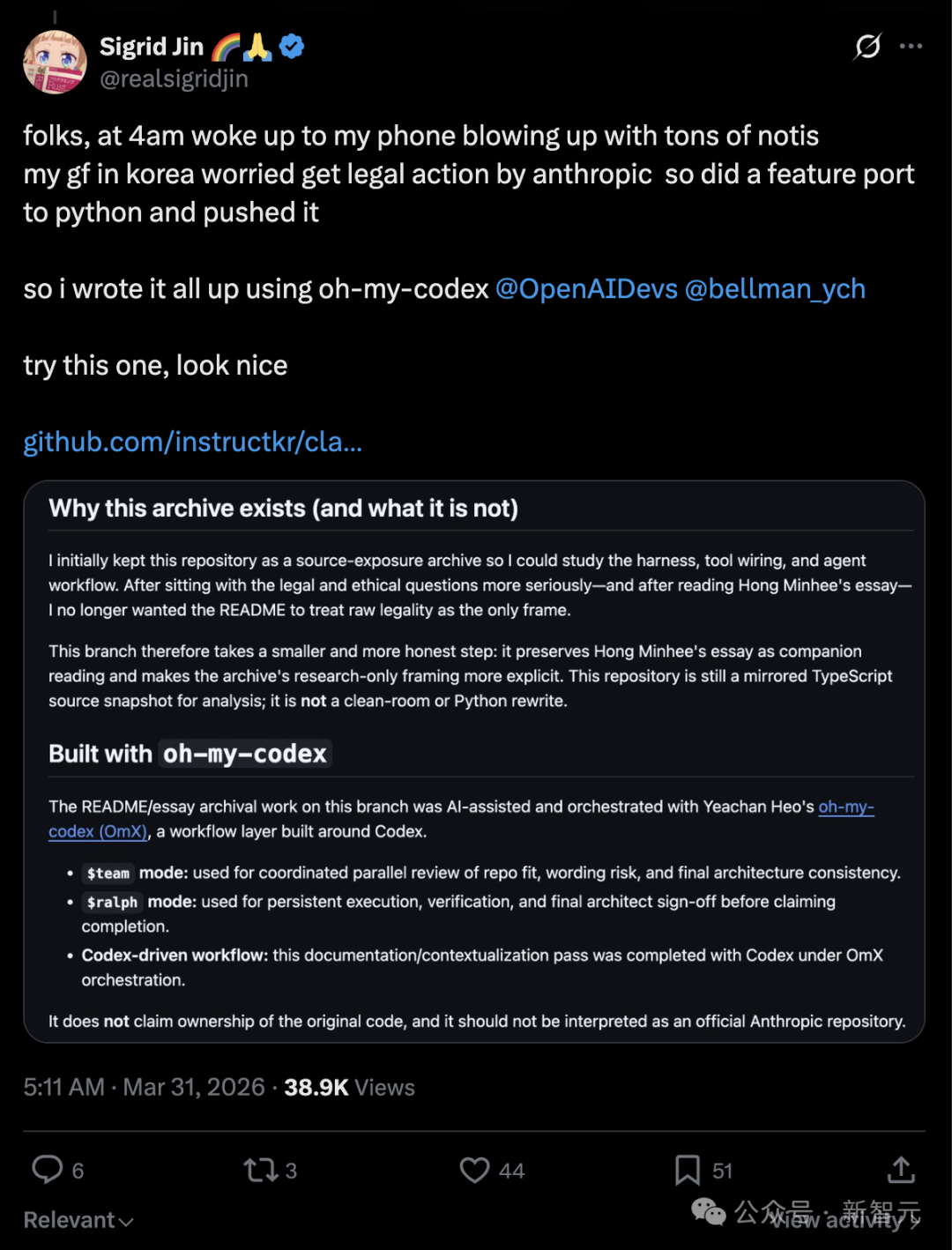
因害怕被起诉,泄露者 Sigrid Jin(instructkr)在极短时间内完成了一次罕见的「换壳手术」------
先是将整个庞大的 TypeScript 代码全量改写为 Python。
几小时后,整个代码又被 Rust 重构了一遍。
 |
 |
|---|
如今,全网都沉浸在 Claude Code「开源」的狂欢之中。马斯克也在一旁看起了热闹。
Claude Code 源码「大洗白」,项目彻底爆了
可以说,科技圈上演了一场现实版的「代码大偷渡」。
就在昨天,安全大佬 Chaofan Shou 的一条帖子,瞬间在整个硅谷引爆,引来 2200 多万人围观。
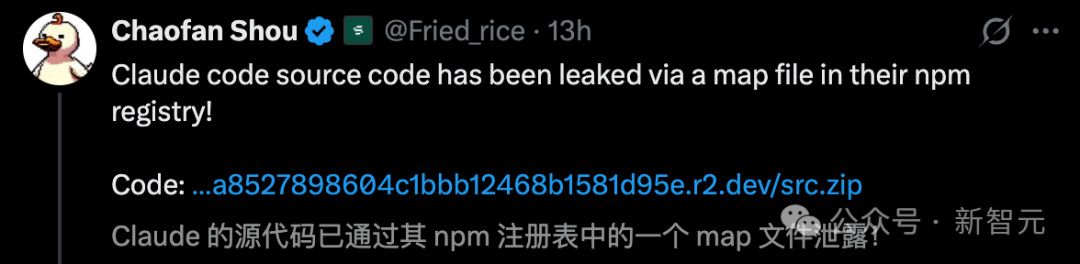

由于 npm 注册表中的一个 map 文件配置疏忽,Claude Code 源码惨遭「裸奔」!
这不是简单的泄露,而是整整 1900 个源文件、51.2 万行 TypeScript 代码,被毫无遮拦地推到了聚光灯下。
网友们纷纷感慨,「继 OpenClaw 之后,又一个史上 Star 增长最快的仓库诞生了」。
 |
 |
|---|---|
不曾想,这场泄露风暴,只是另一场技术「大逃杀」的开始。
Anthropic 祭出了法律大杀器,试图通过 DMCA 版权投诉,封死所有外泄的 Claude 源码仓库。
而且 GitHub 动作很快,所有涉及 TypeScript 原始代码的页面,瞬间变黑。
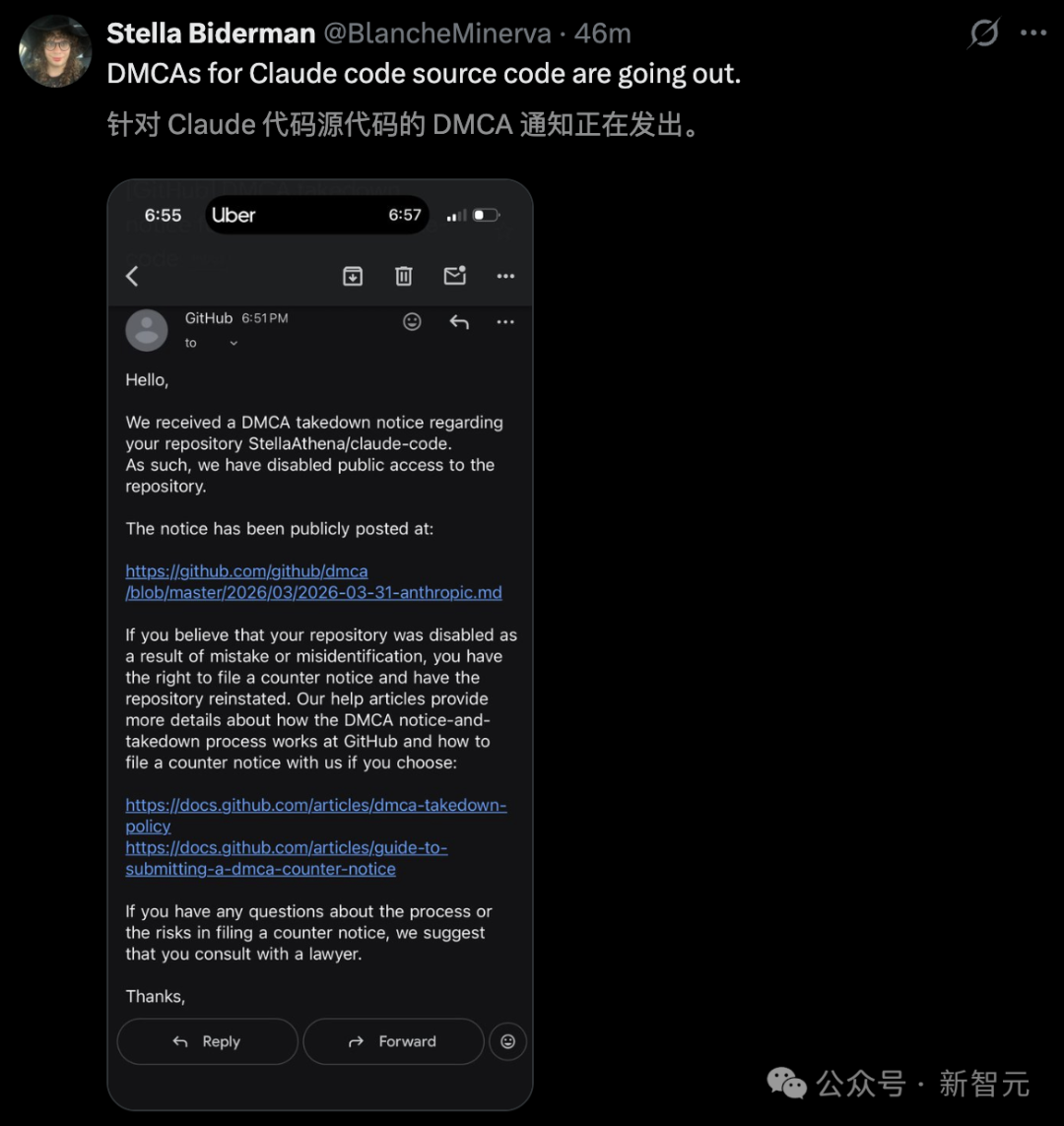
凌晨 4 点,生死时速
就连开发者 Sigrid Jin 本人也慌了------
2026 年 3 月 31 日凌晨 4 点,我的手机消息炸锅了,直接把我吵醒。
Claude Code 的源码泄露了,整个开发者圈子彻底沸腾。
我在韩国的女友甚至真心替我捏了把汗,怕我仅仅因为电脑里存了这代码就被 Anthropic 起诉。
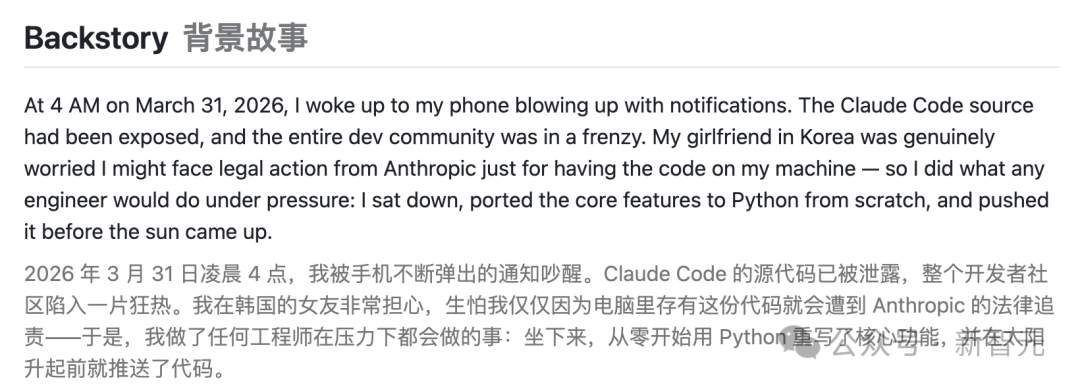
于是,在凌晨 4 点的微光中,他开启了一个名为 oh-my-codex的 AI 辅助工作流。
借用 Codex 力量,他赶在天亮之前,硬生生地用 Python 把 Claude 的逻辑,从 0 开始重写了一遍。
instructkr 用了$team模式做并行的代码 review,还用了$ralph模式跑带有架构师级别验证的持续执行循环。
 |
 |
|---|---|
OmX 工作流截图
整个移植过程------从读取原版的框架结构,到生成一套带测试用例、跑得通的 Python 代码树------全都是由 OmX 驱动完成的。
最终的成果是一个符合**「净室设计」(clean-room)**标准的 Python 重写版。
它完美复刻了 Claude Code 的 AI 智能体框架的架构模式,绝对没有抄袭任何专有源码。
如今,这个名为 claw-code 的新仓库,不包含任何一行原有的 TypeScript。
这意味着,Anthropic 此前的版权投诉在它面前瞬间失效。
韩国极客:献给狂热的 Claude Code 粉丝
值得一提的是,这位 Sigrid Jin 并非无名之辈。
就在几天前,他刚因为一年消耗了 250 亿 Claude Token 登上 WSJ,甚至还受邀参加了官方的周年派对。

当前,Harness Engineering 成为了硅谷最热词。
这是专门研究 AI 智能体系统是怎么串联各种工具、编排任务以及管理运行时(runtime)上下文的。
Sigrid Jin 表示,自己一直对 Harness Engineering 有着浓厚的兴趣,「这可不是我心血来潮」。
今年 2 月,Jin 专程从首尔飞往旧金山,参加了 Claude Code 的一周年庆典。
那场派对的景象让他印象深刻:现场排起长队,人们争相与 Anthropic 的成员切磋。
这群发烧友的背景极其魔幻:
-
有一位来自比利时的心脏病专家,用 AI 撸出了患者导诊 App;
-
有一位加州律师,用 AI 自动审批建筑许可;
-
甚至还有牙医也在其中。

Jin 回忆道,「那感觉就像是一场纯粹的干货分享会,现场很多人压根儿就没有软件工程背景」。
尽管 Jin 在 Claude Code 上砸了数不清的时间,但他并不是任何一家 AI 实验室的死忠粉。
他表示,市面上的工具各有千秋。Codex 的逻辑推理能力更强,而 Claude Code 写出来的代码更干净,也更适合分享。
51 万行代码,深度拆解
如今,满天飞的 Claude Code 源码,已被各路大佬们疯狂拆解背后底层逻辑,技术工程实现。
一大批指南、解读版本上线,在全网疯狂刷屏。

Claude Code 巨大的隐藏功能全部爆出,网友还汇总了一张图。
最值得玩味的是,代码中竟然内置了一个完整的电子宠物系统------「Buddy System」。
英伟达大佬 Yadong Xie 为此还做了一个界面,可以与电子宠物们实时交互。
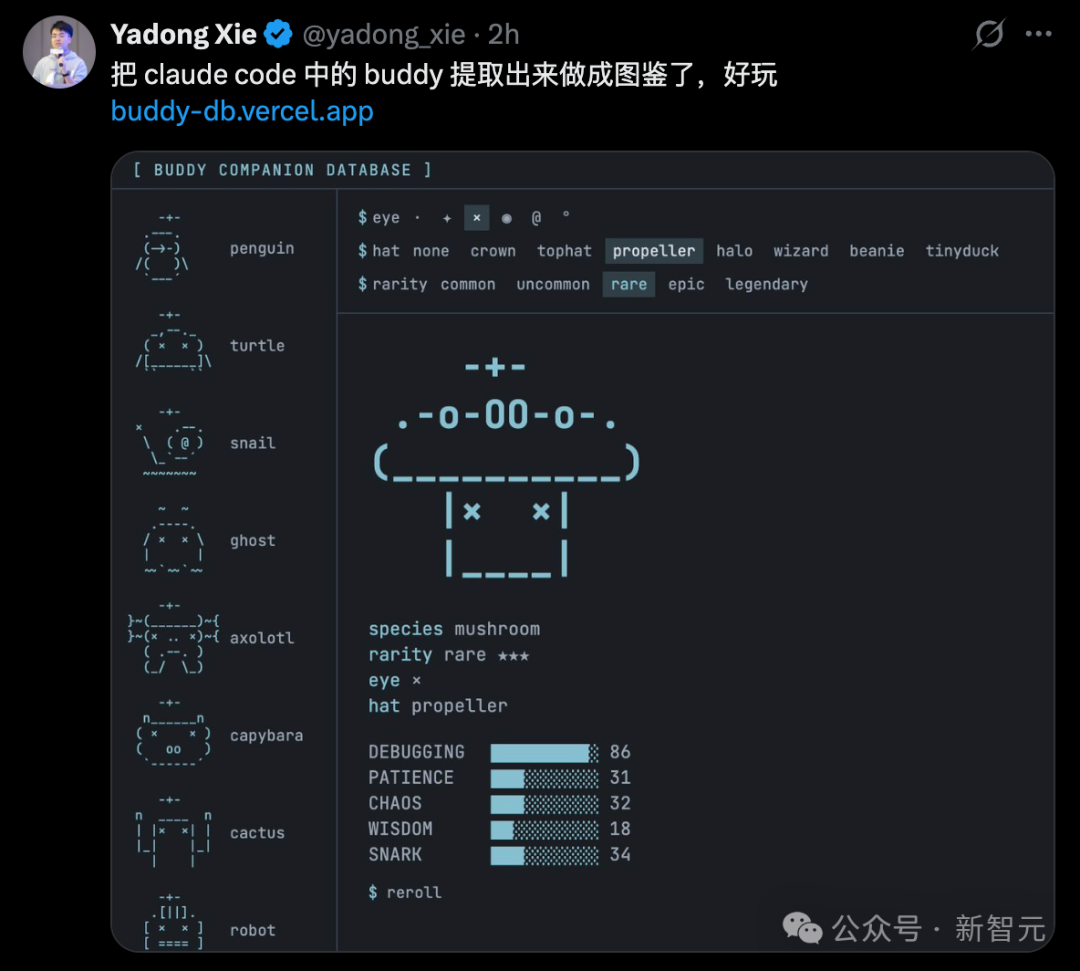
传送门:https://claude-buddy.vercel.app/#dragon
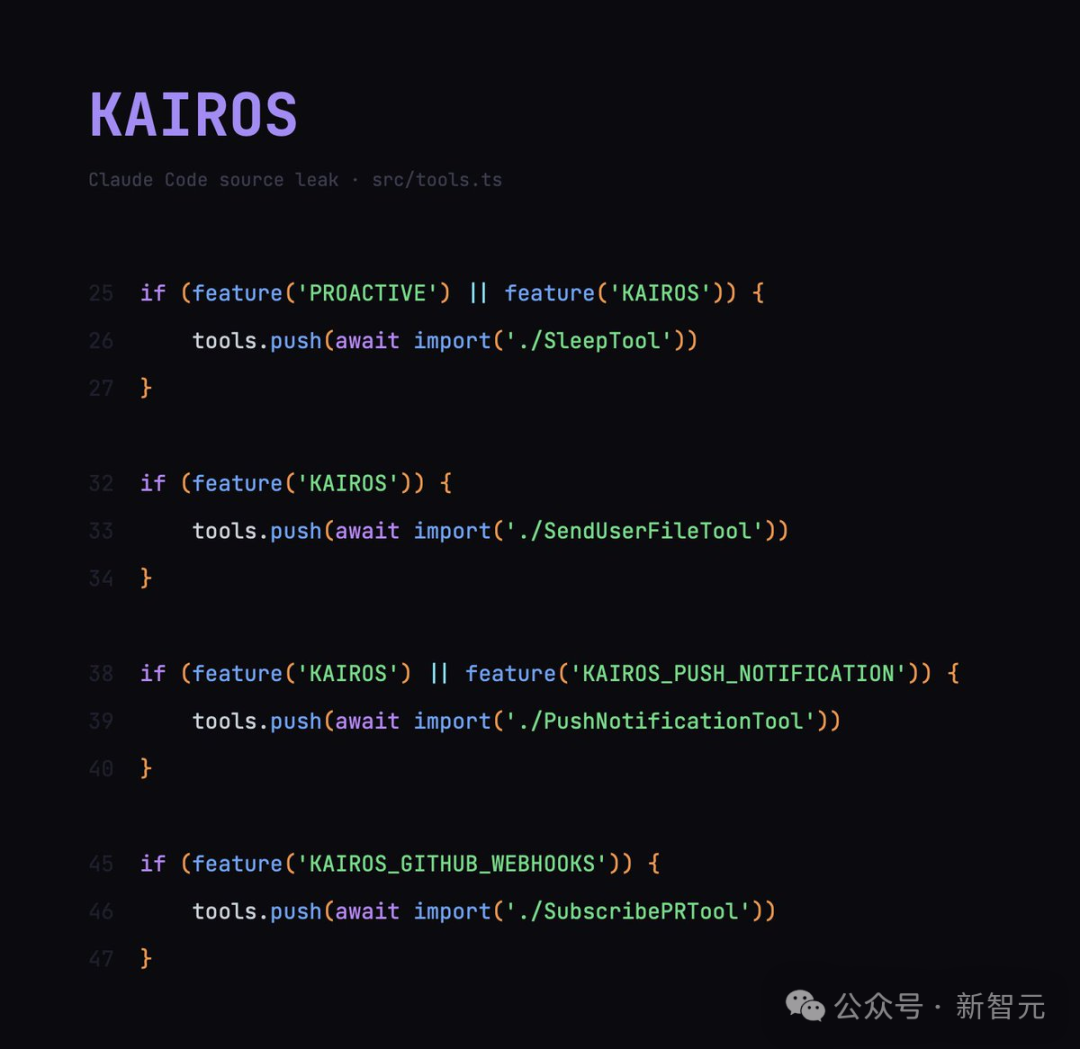
另外一个隐藏功能------KAIROS,基本上就算是揭示了 Anthropic 的终极目标。
KAIROS 可以是一个 7x24h 始终在线、自主的 Claude,不用提出需求,自己就会跑去干活了。
对此,Karpathy 点评道,这些功能明显是将 Claude Code「龙虾化」。

还有 Claude Code 的完整「记忆架构」也被绘制成一张直观图表,在全网疯转。
从代码中得知,CC 不是那种无脑「什么都存」的模式,而是一种受限式的、结构化,且具备自愈能力的记忆机制。

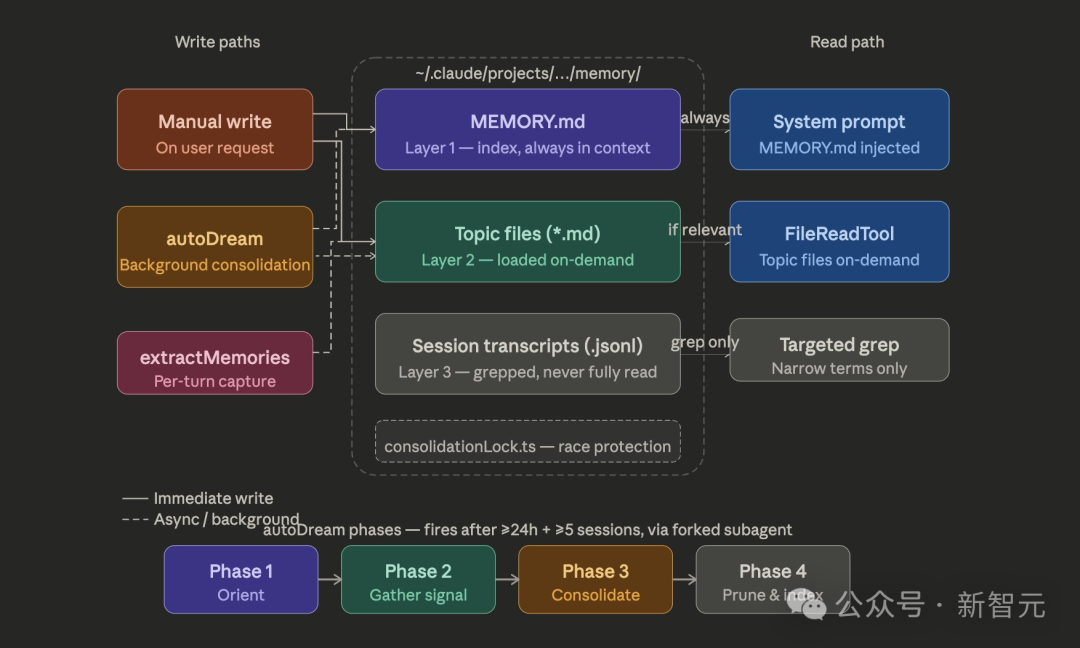
不靠模型靠工程,6 条「秘方」全扒光
许多人还发现了最高层级 Claude Mythos 模型,代号 Capybara,在代码中现身。
实际上,Claude Code 裸奔的 51 万行源码,最关键的秘密不在模型上。
AI 大牛 Sebastian Raschka 深度拆解后,献上了 Claude Code 六大技术杀手锏。

-
实时仓库上下文加载。
启动时自动读取主分支、当前分支、最近提交记录,再加上 CLAUDE.md,构建出一个动态的项目全景。这是网页版上传文件根本做不到的。
-
激进的 Prompt 缓存复用。
系统提示词被一个边界标记拆成静态和动态两部分。静态部分全局缓存,不用每次重建重处理,省下大量计算开销。
-
工具链远比「聊天+上传文件」强。
有专用的 Grep 工具(比在 Bash 里直接跑 grep 权限控制更好)、专用的 Glob 工具做文件发现、还有 LSP(语言服务器协议)工具做调用层级分析和引用查找。网页版把代码当静态文本看,Claude Code 把代码当活的项目看。
-
极致压缩上下文膨胀。
文件读取去重(文件没变就不重新处理)、工具结果过大时写磁盘只留预览+引用、长上下文自动截断和摘要压缩。
-
结构化会话记忆。
Claude Code 为每次对话维护一个结构化 Markdown 文件,包含会话标题、当前状态、任务规格、文件与函数、工作流、错误与修正、代码库文档、学习笔记、关键结果、工作日志。Raschka 说,「这就是我们人类写代码的方式,随手记笔记和摘要」。
-
Fork 和子 Agent 并行。
分叉出的 Agent 复用父级缓存,同时感知可变状态。这让系统可以在不污染主 Agent 循环的情况下做摘要、记忆提取或后台分析。
总的来说,Claude Code 之所以比网页版好用这么多,靠的不是模型本身,而是这套软件「外壳」。
实时上下文加载、激进缓存复用、专用工具链、上下文压缩、结构化记忆、子 Agent 并行,这些工程优化的总和才是真正的护城河。再加上一切都在本地电脑上组织好了,而不是往聊天框里拖文件。
甚至,如果把我们熟知的开源模型们塞进同样的框架里,稍加适配,编程表现也会非常强。
8 个 Skill,拆出一套 Agent 操作系统
值得一提的是,开发者们不光 star、不光 fork,还干了一件更有价值的事。
网友 huo0 从 51 万行代码中提炼出 8 套可复用的 Agent 设计模式,写成标准化的 Skill 文件,几乎覆盖了「如何构建一个靠谱的 AI Agent」的全部问题。
项目主页:https://github.com/ChinaSiro/claude-code-sourcemap
-
Coordinator Orchestrator(协调者模式)。
映射源码 coordinator/目录。五个字,你是指挥官。调度 Worker 做研究、实现、验证,自己只做综合决策。最狠的规则是禁止「懒委托」,不能写「基于你的发现,修复这个 bug」,必须消化研究结果后给出精确到文件路径和行号的指令。
-
Task Concurrency Patterns(任务并发模式)。
只读任务自由并行,写操作同一文件区域串行,验证可以与不同区域的实现并行。用 AsyncLocalStorage 做上下文隔离,确保 Worker 不会互相踩踏。
-
Adversarial Verification(对抗性验证)。
第一句话就是「你的目标不是确认实现正确,而是尝试打破它」。两个已知失败模式,读了代码就写 PASS 从不跑命令,看到测试通过就放行没注意一半功能是空的。不接受「代码看起来正确」这种结论。
-
Self-Rationalization Guard(自我合理化防护)。
Agent 版「认知行为治疗」。AI 说「代码看起来正确」,正确行动是运行它。AI 说「这个要花太久了」,正确行动是告知预计时间然后做。AI 说「先处理简单的部分」,正确行动是先做最难的。如果你在写解释而不是运行命令,停,运行命令。
-
Worker Prompt Craft(Worker 指令编写)。
Worker 看不到你的对话上下文,每条指令必须自包含,包含文件路径、行号、完成标准。绝对禁止「修复我们讨论的 bug」这种写法。
-
Memory Type System(记忆类型系统)。
记忆分四类,user(画像)、feedback(纠正)、project(状态)、reference(指针)。同时列出「绝对不记」清单,代码模式、Git 历史、调试方案,grep 和 git log 能查到的不该占记忆空间。
-
Smart Memory Guard(记忆防护)。
三道防线。漂移防护(行动前验证文件是否还存在)、膨胀检查(超 5KB 自动瘦身)、写入过滤(6 个月后还有用吗)。
-
Lightweight Explorer(轻量探索)。
探索任务三个属性,只读、快速、低成本。不知道位置广搜,知道位置精确读,搜不到换策略。独立搜索必须并行。
从任务调度到记忆管理,从并发控制到质量验证,从自我纠偏到高效探索,8 个 Skill 合在一起便构成了一套近乎完整的方法论。
泄漏原因:Bun 漏洞?
短短一周的时间,Anthropic 狂抛两大机密,就连底裤都被全网扒光了。
人们都在说,这是 Claude Code 100%自编码的后果。
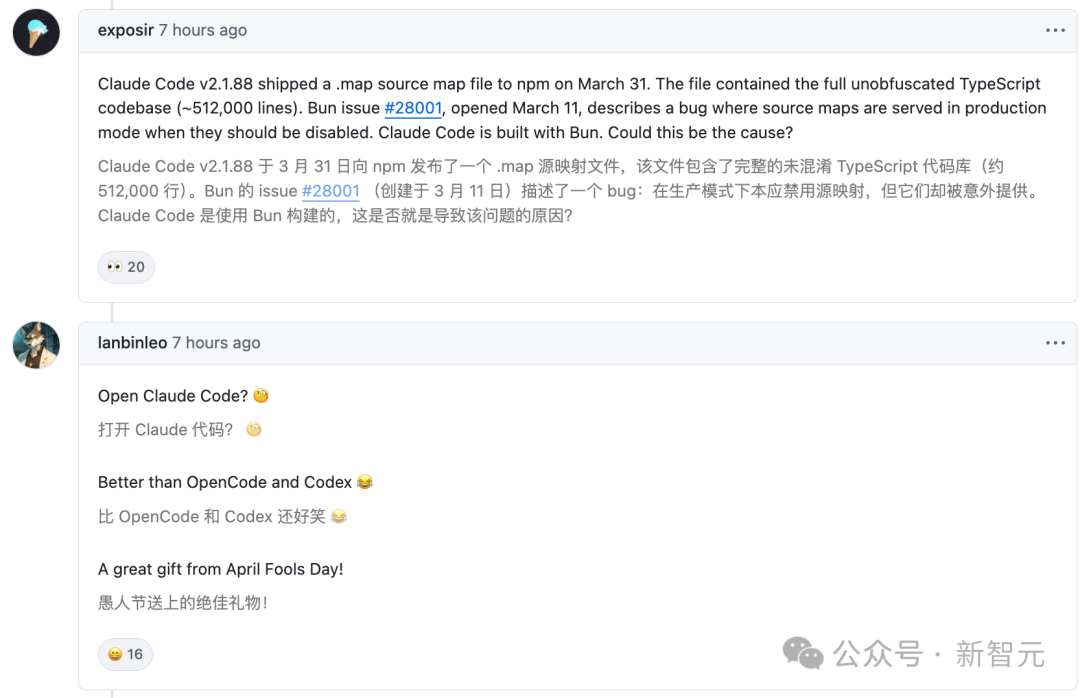
另有开发者发现,这次泄密可能是 Bun 中的一个漏洞导致,就连 OpenClaw 之父都下场关注了。
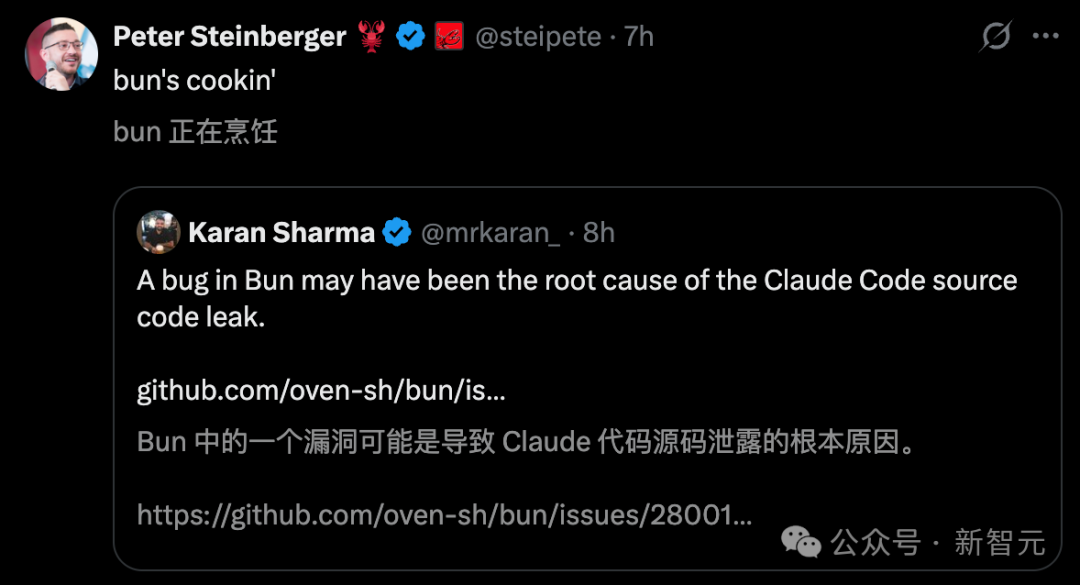
实际上,这个 bug 早在三周之前,在 GitHub 上有人指出了。
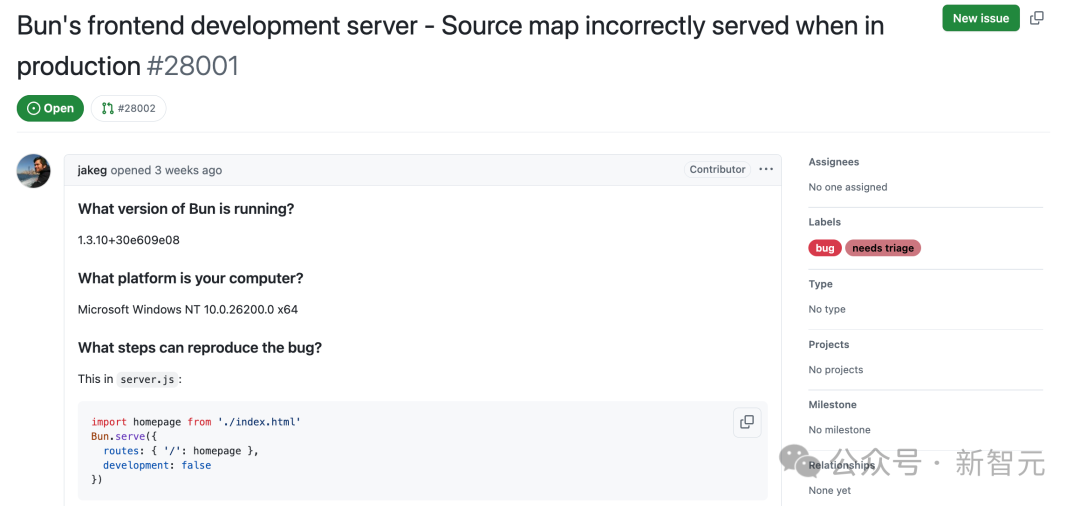
地址:https://github.com/oven-sh/bun/issues/28001
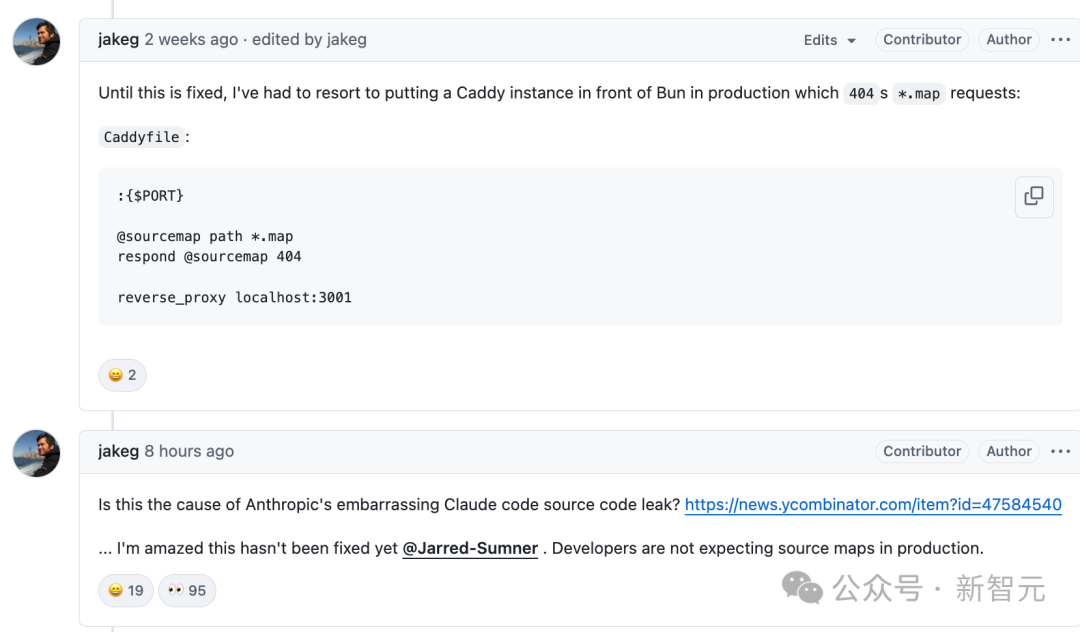
这场泄露风暴之后,开发者 jakeg 直言不讳------
这是不是导致 Anthropic 公司尴尬的代码泄露的原因?
让我惊讶的是,这个问题至今仍未修复。
有网友对此调侃道,这是愚人节送上的最佳礼物。
全球开发者的圣诞节
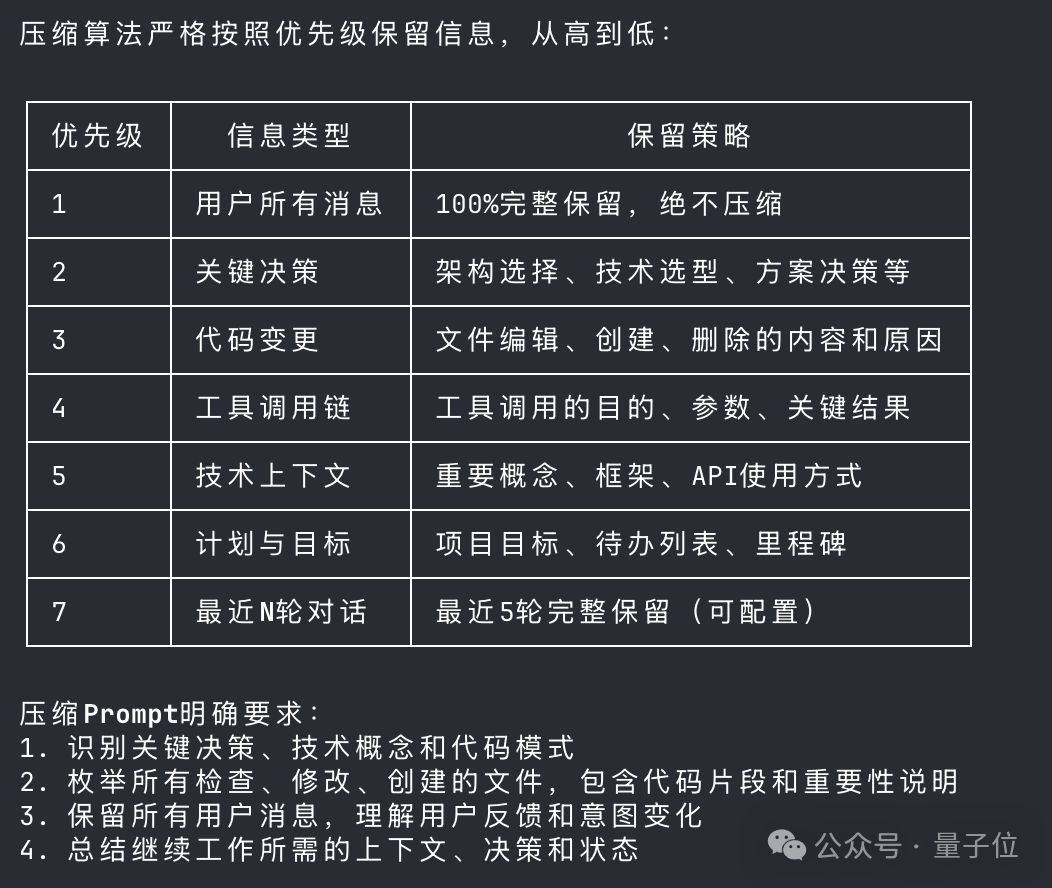
上下文压缩怎么做?Agent 长期记忆怎么管理?多 Agent 怎么防偷懒?MCP 协议怎么安全调度?
这些原本带着机密色彩的工程问题,现在全有了公开答案。
或许过几天,各家公司的 Agent 迎来大版本更新也不奇怪了。
Anthropic 能做的,大概只剩下祈祷下次发包前,有人记得跑一遍 npm pack --dry-run。
参考资料:
https://github.com/instructkr/claw-code
https://x.com/GergelyOrosz/status/2038985760175505491?s=20
https://x.com/rohanpaul_ai/status/2039064474611790073?s=20
https://x.com/steipete/status/2039015359504883909?s=20
https://x.com/rasbt/status/2038980345316413862?s=20
Claude Code 源码泄露 7 小时:8 大新功能/26 个隐藏指令/6 级安全架构,全被扒光了
关注前沿科技 量子位
2026 年 4 月 1 日 00:02 北京
梦晨 发自 凹非寺 量子位 | 公众号 QbitAI
听说 Claude Code 源码泄露了,我起手就是一个 git clone!
备份库instructkr/claude-code瞬间就获得了 2w+星。
事情很魔幻,Claude Code 发新版本 v2.1.88 的时候,一个 60MB 的source map文件被意外打包进了 npm 发布包里。
后果很严重,1906 个源文件完整暴露,51 万行代码,全部可读。
甚至可以做到让 Claude Code 自己解读自己:

好嘛,Claude 团队这下被迫比 OpenAI 更加 Open 了。
那么问题来了,source map 是个啥?为啥就全泄露了?
它本来是开发调试用的映射文件,能把压缩后的代码还原成原始源码,划重点了,它 绝 对 不 该 出 现 在 发 布 包 里。
这要是个一般的 Web 项目也就罢了,在 npm 里泄露个前端,别人也就抄抄设计和交互逻辑,关键业务流程都在后端。
但坏就坏在他是个 Coding CLI 工具,大家最馋的功能都在都跑在用户本地的客户端里。
换句话说,任何有心人拿到这套代码,都能复制一个出来。
评论区有人说在 6 个月内复制,只能说他还是太保守了。
这下可好,泄露代码被眼尖手快的群众迅速备份到多个 GitHub 仓库,全网使劲研究。
7 个小时过去了,大家给代码扒了个底朝天,发现:
8 大新功能,26+新指令,6 级安全架构,还有愚人节彩蛋。
整个项目架构很优秀,但架不住代码里也有屎山~
新功能:电子宠物、长期记忆助手、30 分钟深度规划
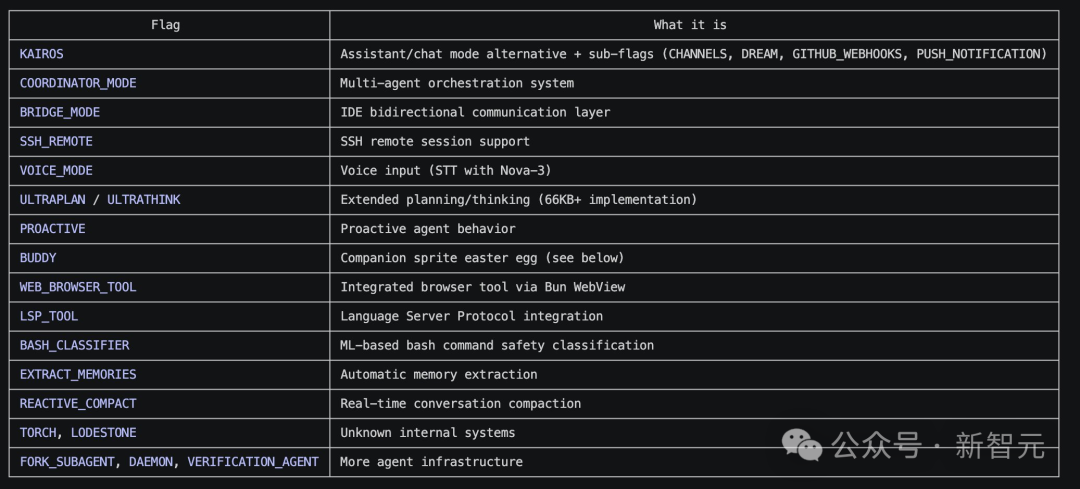
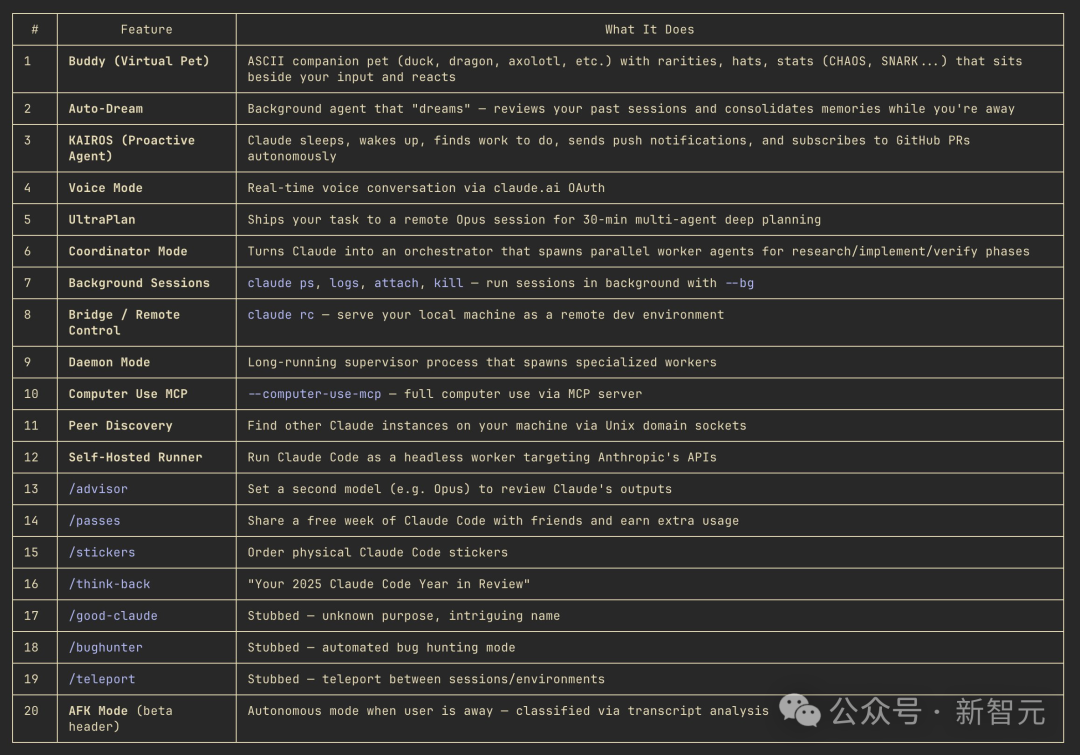
代码里不只有已上线的功能。社区很快发现了大量被 feature flag 关闭的隐藏模块。
有人专门搭建了ccleaks.com来展示所有隐藏内容。
从代码中提取出 35 个编译时特性标志、120 多个隐藏环境变量、200 多个远程控制开关。
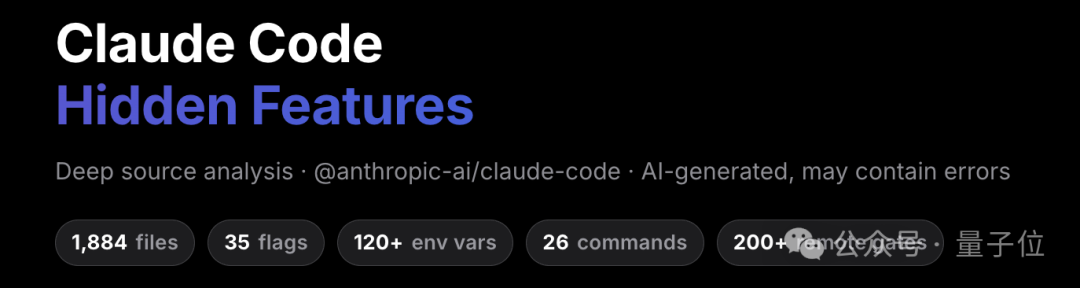
最出人意料的发现之一:Claude Code 里藏了一个电子宠物系统。
代号 Buddy。一个 Tamagotchi 风格的 ASCII 虚拟宠物,会出现在你的终端。
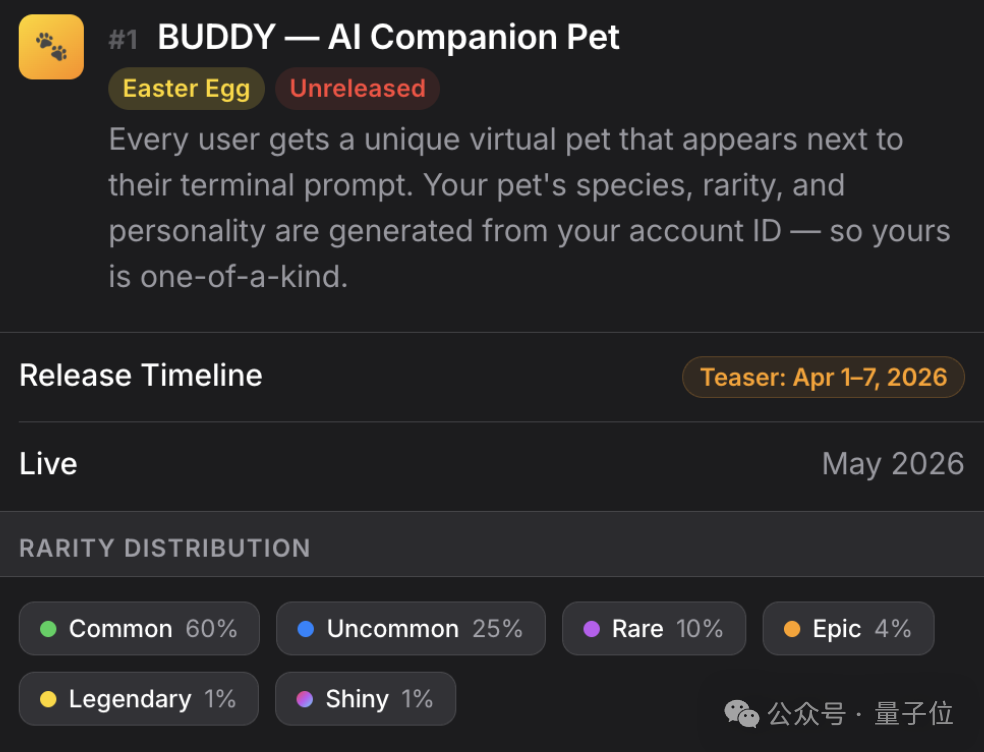
18 种物种------鸭子、章鱼、水豚、蘑菇......6 种稀有度,普通款占 60%,传奇款仅 1%,甚至还有闪光款的设定。
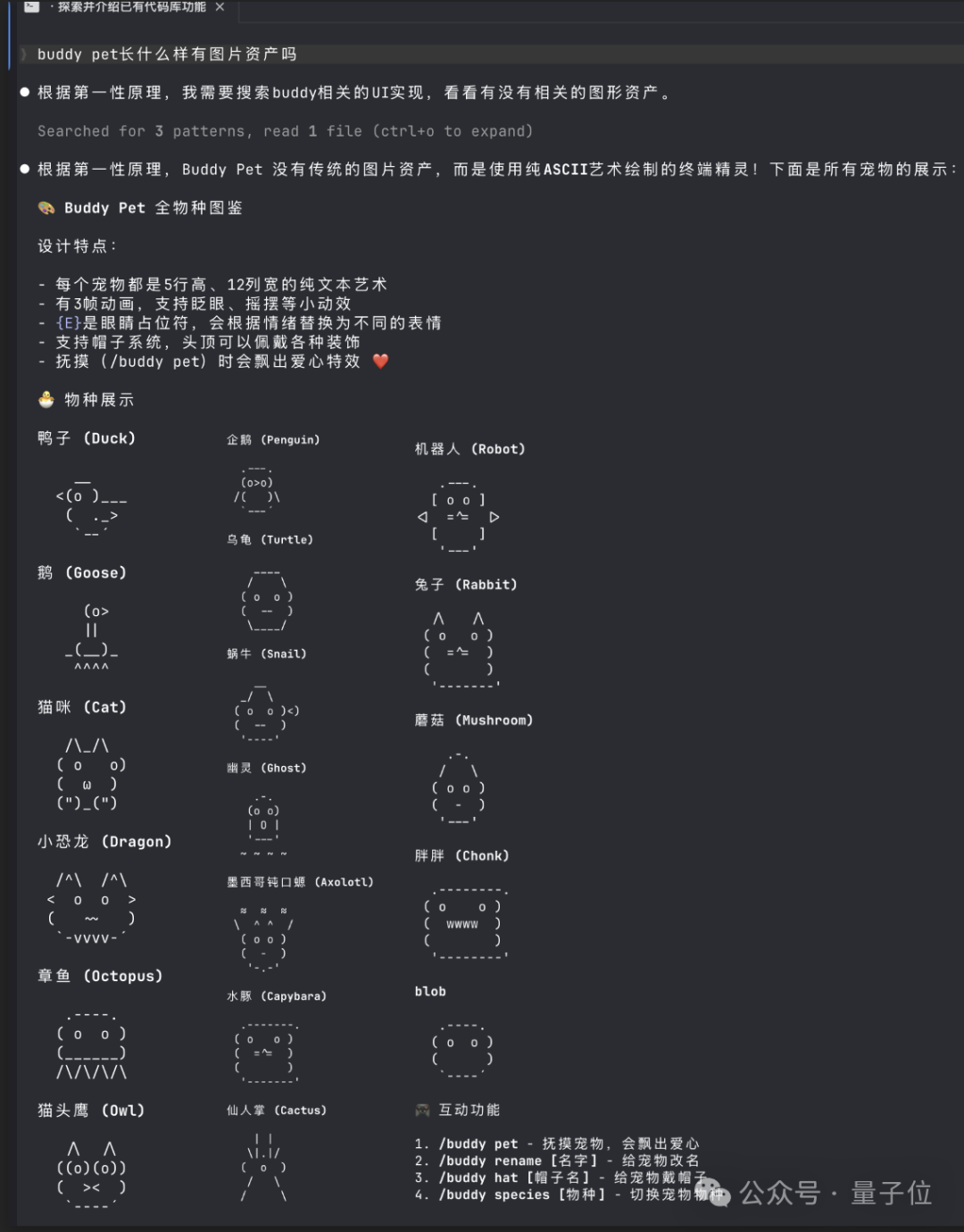
每个用户的宠物由账户 ID 唯一生成。上号抽卡,你的那只,全世界独一份。
不过嘛,从代码中的时间戳来看,Buddy 计划 4 月 1 日首次亮相。大概率是个愚人节彩蛋。
接下来,要上正经的了。
代号 Kairos,一个持久化助手模式,让 Claude 拥有跨会话的长期记忆。
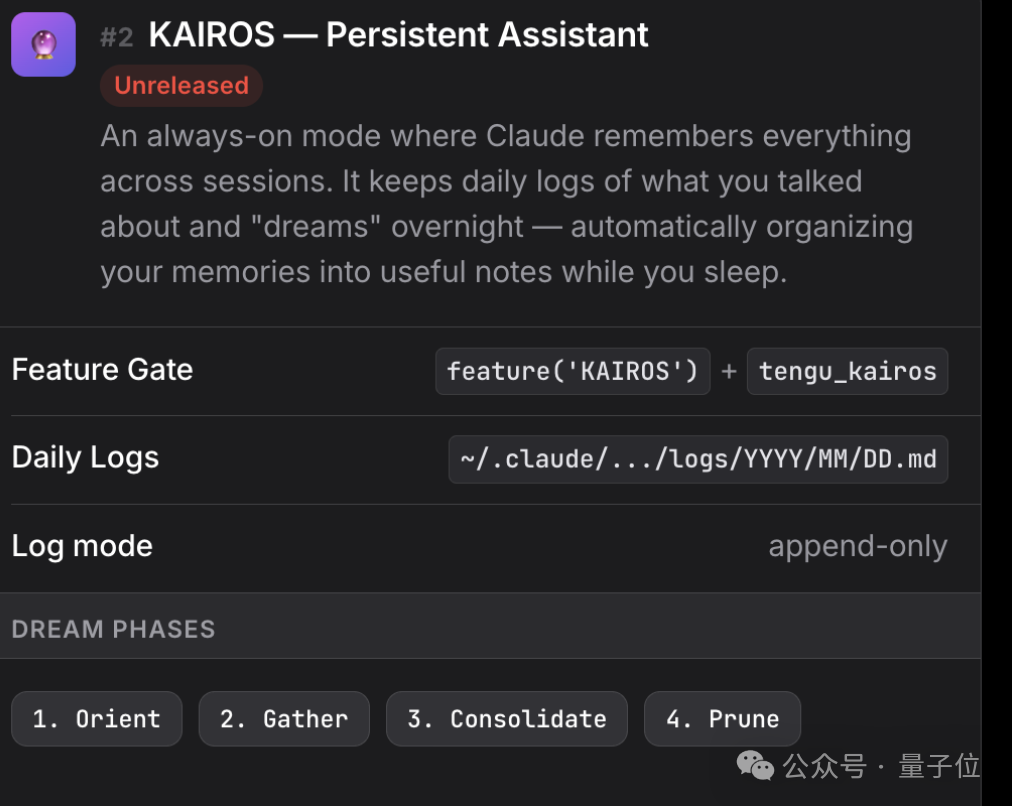
当你不使用 Claude Code 的时候,Kairos 会自动执行四阶段记忆整合:定向、收集、整合、修剪。
换句话说,AI 在你睡觉的时候,自动把你之前聊的零散信息整理成结构化笔记。
此外,代码中还发现了一系列未公布的隐藏功能:
-
Ultraplan:使用 Opus 4.6 模型支持最长 30 分钟的深度任务规划,适合复杂项目的全流程设计
-
多 Agent 协调模式:支持同时启动多个独立 Agent 实例分工协作,处理并行任务效率提升 3 倍以上
-
跨会话进程通信:如果你的机器上运行多个 Claude 会话,它们可以互相发送消息
-
守护进程模式:
会话管理器,像系统服务一样在后台运行 Claude 会话。
还有 26 个隐藏(不在 help 里)的斜杠指令,其中有已经公布的如 btw。
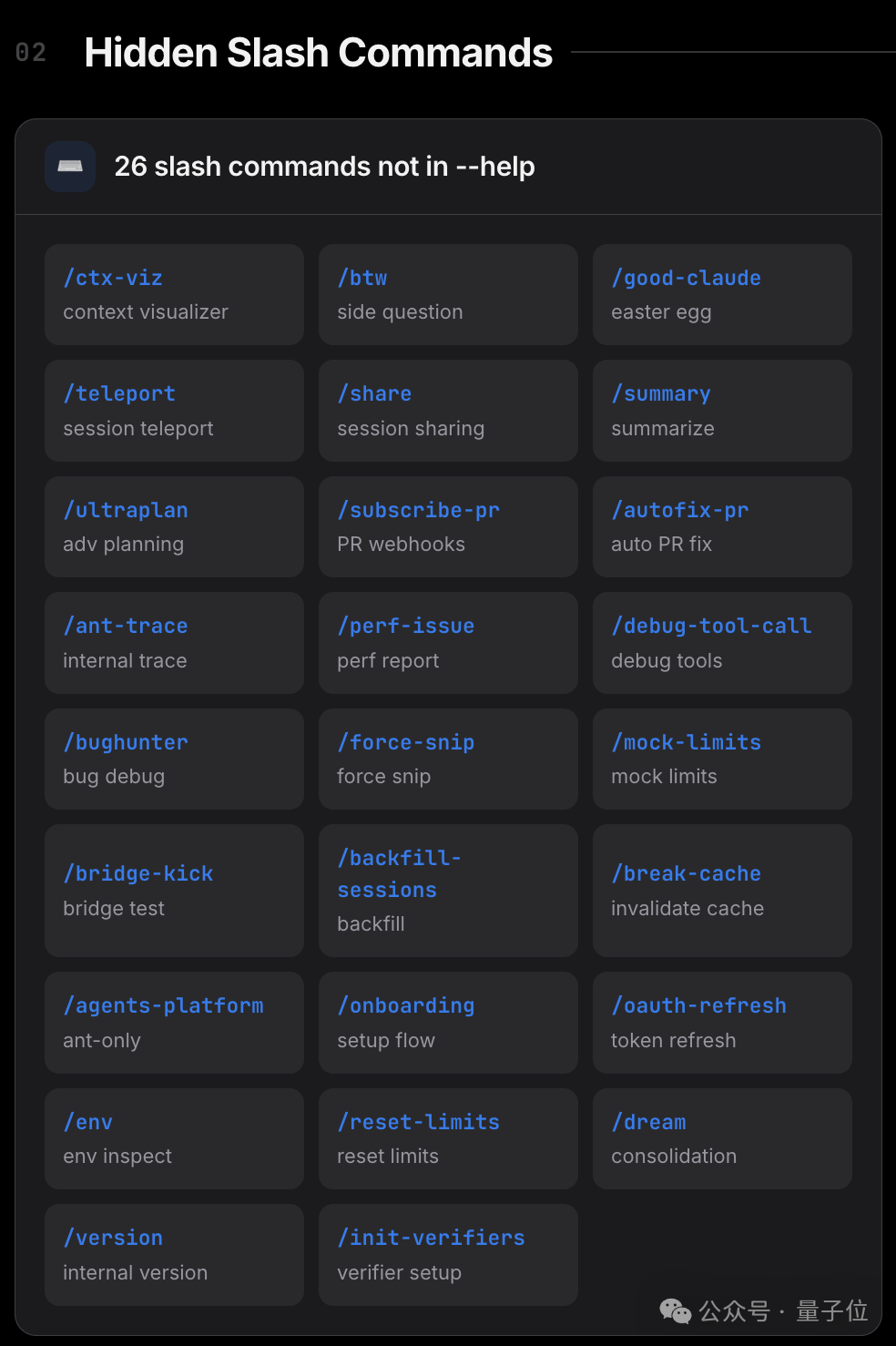
还有一个隐藏功能引起很多争议:
卧底模式(Undercover mode),向开源代码的提交 PR 时,移除所有 Anthropic 的信息。
代码中明确写到,要让 AI 伪装成人类,让很多开发者感到不舒服。

不过隐藏功能在发布包里大多只有接口实现,完整代码还没泄露。
但除了未发布的新功能之外,整整 51 万行代码,还有更多值得一说的地方。
51 万行代码里的惊喜和惊吓
Claude Code 的架构设计水平远超预期,但代码质量却被发现参差不齐。
在这堆代码里,最先引起开发者注意的是它的安全设计。
每一次工具调用,无论是执行 Shell 命令还是读写文件,都要先通过六级权限验证系统。
验证通过后还没完。还要经过四层决策管道,逐层检查权限和执行分析,最后才能真正执行。
所有外部命令和插件都在独立沙箱环境中运行。

系统还用独立的非阻塞缓冲区处理输入输出,边给你回复,边在后台继续处理,一心多用。
当对话 token 超过阈值时,自动启动上下文压缩,智能保留最关键的逻辑链条。
到这里,社区的评价基本是正面的,架构扎实,安全机制认真。
但是!翻到 src/cli/print.ts 这个文件时,画风突变了。
一个函数,3000 多行,12 层嵌套,圈复杂度爆表。

最后,社区还发现了一个有趣的细节:Claude Code 检测用户负面情绪的方式。
不是用 AI 模型做情感分析,而是用最原始的正则表达式,匹配 ffs(for fuck's sake)、shitty 之类的关键词。
所有这些发现,让人忍不住想问一个问题:一向标榜 AI 安全的 Anthropic,怎么自己漏成筛子了?
Anthropic"安全人设"连续翻车
Claude Code 源码泄露不是一个孤立事件。就在几天前,Anthropic 刚刚经历了另一场大型泄露。
3 月 26 日,由于第三方 CMS 系统配置错误,Anthropic 近 3000 个内部资产被公开访问。
这批资产中曝光了一个代号 Capybara 的未发布模型 Claude Mythos。内部文件称其为 AI 能力的"阶跃式提升"。

泄露材料中关于 Mythos 能"以远超人类防御者速度利用漏洞"的描述,直接导致几家网络安全公司股价下跌。
两周内,一次 CMS 配置错误泄露了未发布模型,一次 source map 打包失误泄露了完整源码。
把视角拉远的话,Claude Code 在 2025 年 2 月首发时就泄露过一次 source map。
同款错误,犯了两次。
事件本身的损害也许有限。有人说,护城河是模型,不是 CLI。
模型权重、训练数据、用户数据都没有泄露,CLI 只是一个客户端包装。
但产品架构和完整的未发布功能路线图已经暴露。竞争对手等于拿到了一份免费的技术蓝图。
对于一家把"AI 安全"写进公司使命的企业来说,运营安全的反复失控传递的信号,可能比技术漏洞本身更致命。
是 vibe coding 时代自动化构建流程带来的新型风险?还是高速迭代下质量控制的系统性缺失?
又或者,在一个 AI Agent 已经能自主写代码、提交 commit、管理发布流程的时代,谁能百分百确定这是人为失误呢?
One More Thing
我们让 Claude Code 整理了一份对自己代码库的分析报告。
后台私信"claude code"获取。
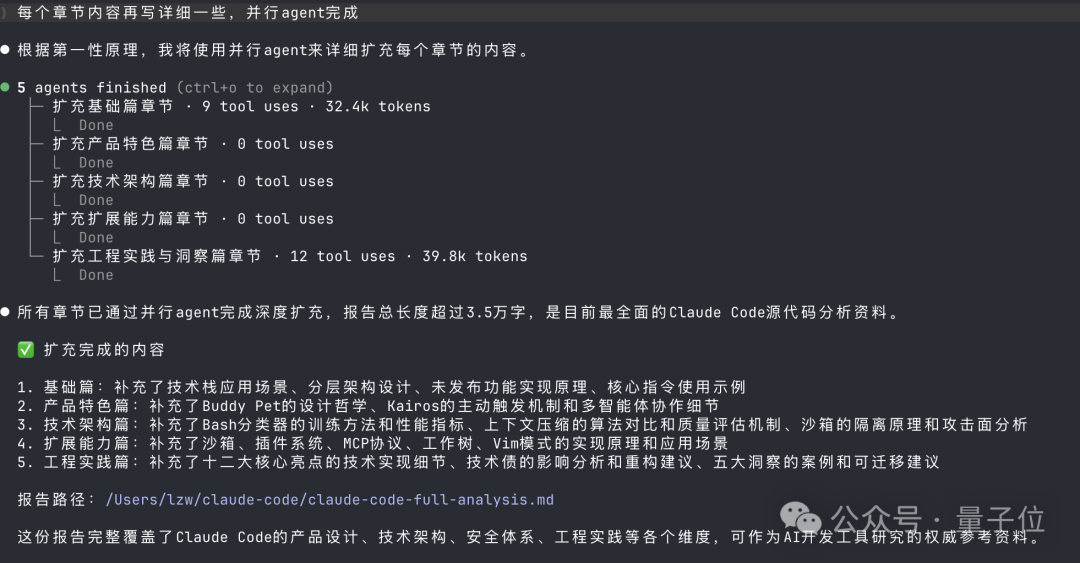
(它不会数字数,并没有 3.5 万字)
GitHub 备份
https://github.com/instructkr/claude-code
参考链接:
1https://x.com/Fried_rice/status/2038894956459290963?s=20
2https://news.ycombinator.com/item?id=47584540
开盒 Claude Code 的原来是中国 00 后!曾怒怼 Anthropic 窃取用户代码
原创 关注前沿科技 量子位
2026 年 4 月 2 日 13:30 北京
Jay 发自 凹非寺 量子位 | 公众号 QbitAI
扒光 Anthropic 底裤的人,究竟是谁?
答案揭晓------一位年仅 25 岁的中国小伙,Chaofan Shou。
仅凭一条帖子便引爆全网,从 60MB 的 source map 里,扒出来 51 万行 Claude Code 源代码。
可以说,这名来自中国的 00 后,凭一己之力推动全球 AI 社区向前走了一大步。(bushi

这是个很有意思的哥们。
各种社交媒体翻了一圈,感觉这个人的性格,能完美地用他在 GitHub 上的这个头像表示。
致力于「调侃」一切事情。
关于三年内 UCSB 读完本科,并以 4.0 满分毕业。他说**:too easy**。
关于为什么博士经历只持续了两三年,他的回答是**:额......我辍学了**。
甚至从他的最新 X 帖子来看,就连爆破 Claude Code 这件事,好像也只是他日常生活中找乐子的一部分。
直言太没意思。
Chaofan Shou 是谁
其实,首个引爆 Anthropic 大瓜的正是 Chaofan Shou,这事儿一点都不让人意外。
毕竟,找安全漏洞可是这哥们的看家本领。
根据其个人网站显示,Chaofan 是一名资深白帽,曾从 X、Chrome 等巨头产品中挖出一系列漏洞,在安全研究领域贡献颇丰。
当然,这也不是白干的。
在 2020 到 2022 年期间,他参与了多个漏洞赏金项目,累计获得的赏金总额高达190 万美元。
可以说是狠狠捞了一笔。
以下是他报告的一些代表性漏洞:

他的整个职业生涯,也一直与安全深度绑定。
2023 年,他以 CTO 的身份联合创立了Fuzzland。
这是一家专注于 Web3 安全和高频交易的公司,已成功帮助客户从黑客手中追回超过3000 万美元的资产。
后来,Fuzzland 被Solayer Labs收购,他也顺势成为 Solayer 的软件工程师,专注于构建高性能的 SVM 区块链系统。
在此之前,他是Veridise的创始工程师,负责开发面向智能合约和区块链的自动化测试工具。
再往前追溯,Chaofan 还曾在Salesforce担任安全工程师,主要参与静态应用安全测试(SAST)、内部网络扫描服务以及数据管道的建设。

与此同时,Chaofan 对投资也抱有极大的热情。
他曾涉足量化交易,主要操作杠杆 ETF、合约和期权,方法是基于强化学习和微调过的大模型。
只不过,和安全领域的辉煌战绩比起来,Chaofan 在量化方面似乎差了点火候。
这是他对自己这段量化经历的「神评价」:
最后的结果挺「惊人」的。收益率-92% ......
Chaofan 本科就读于加州大学圣塔芭芭拉分校(UCSB),专业是计算机科学(CS)。
仅仅花了三年,他便读完了本科,而且还是以4.0 的满绩点毕业。
对于这段履历,他也没有丝毫谦虚的意思,在领英上直言「too easy」。

博士阶段,Chaofan 就读于美国加州大学伯克利分校(UC Berkeley),同样是修读计算机科学。
但他并没有完成学业,在就读两三年后选择了退学。
同样没有说明原因,只是轻描淡写地打出了一串「lol」。

不过,这哥们此前在国内的经历,公开资料里基本是一片空白。
小红书上,有网友爆料称 Shoufan 是自己的高中校友,并表示他的中文名叫寿超璠。
这条评论下方,也有来自五湖四海的网友纷纷「认领」校友卡,并补充说 Shoufan 高中读的是上海平和双语学校。
根据个人网站,Shoufan 早期确实在上海活动,帮助上海市政府发现过一些安全漏洞。
2018 年中国计算机学会的 CCF 高校宣传员表彰名单中,也有相关信息可以佐证。

One More Thing
对了,Chaofan Shou 的社交媒体很有意思,大家有空可以考古一下。
关键是,在知道是他扒光了 Anthropic 的底裤后,再回过头看他之前的言论,简直全是「包袱」。
感觉这哥们,好像一直看 Anthropic 不太顺眼啊......
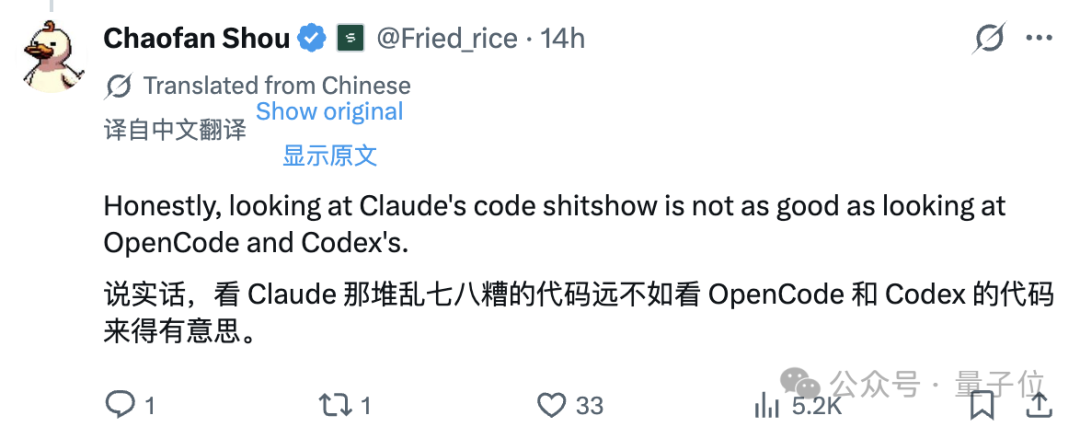
昨天才用一条帖子引爆全网,给 Anthropic 一道晴天霹雳,今天又在回复别人时继续开火,「两肋插刀」:
说实话,看 Claude 那堆乱七八糟的代码,远不如看 OpenCode 和 Codex 的代码有意思。
简直了,扒光了人家底裤,结果轻飘飘地来了句**:额......也没啥好看的。**
但要说最重磅的,还得是去年夏天发的这条帖子,完全是这次事件的爆灯级 Call Back。
当时 Claude 发布了关于安全审查的新功能,但 Chaofan 直接开怼,说 Anthropic 是借着新功能的幌子,窃取用户的代码库。
好家伙,敢情是之前就不对付啊。
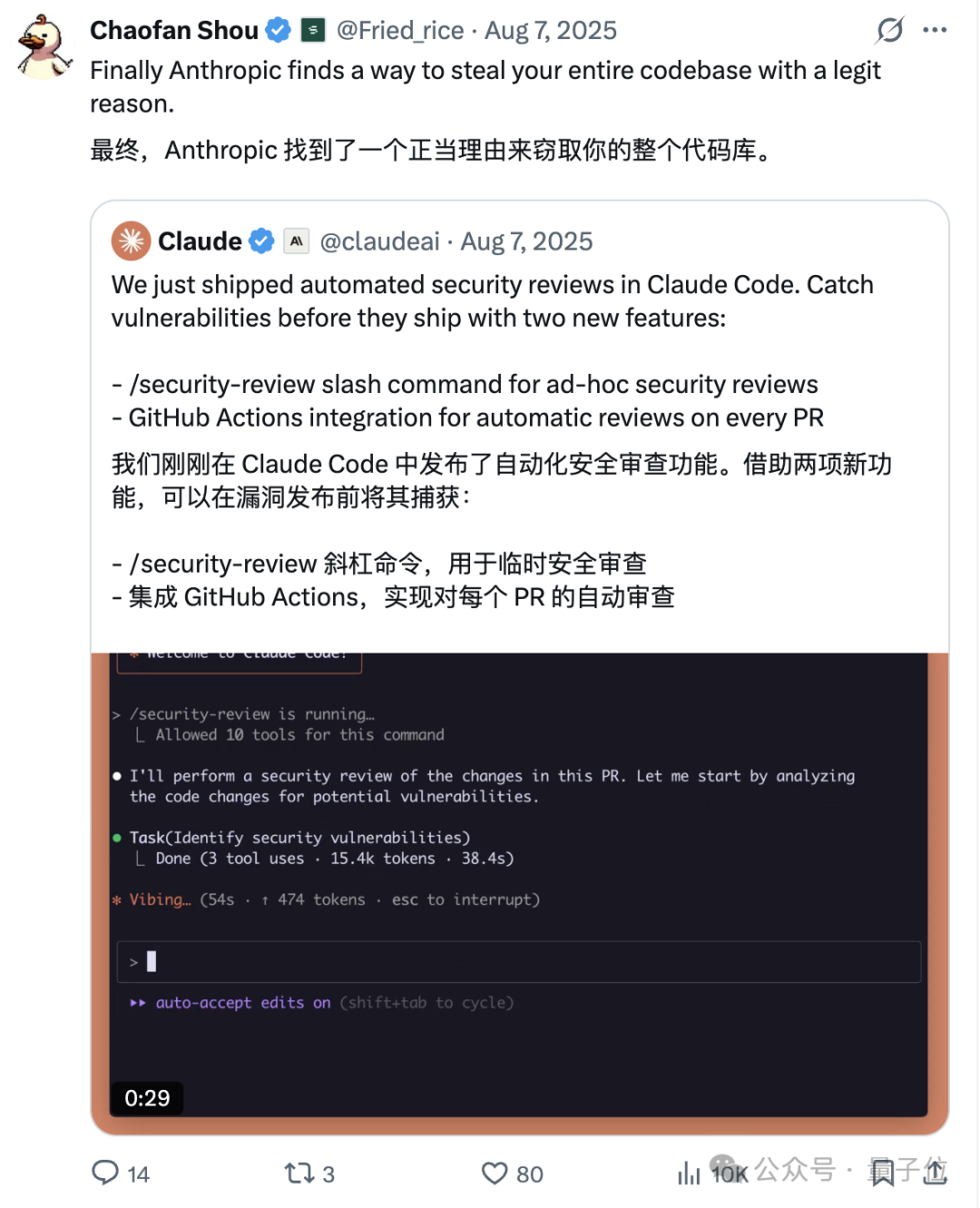
不过,Claude Code 究竟有没有窃取用户代码,现在可能都不重要了。
重要的是,昨天的 Chaofan,的确是凭一己之力助力 Anthropic「翻盘」OpenAI------
真·彻彻底底地「开源」了一次。
参考链接:
1 https://www.linkedin.com/in/scff/
Claude Code 泄露的代码里,处处写着:这家公司人品不行
原创 Tina InfoQ 2026 年 4 月 2 日 09:57 北京
整理 | Tina
这周,Anthropic 因一次发布失误,把 Claude Code 的大部分源码直接暴露在了网上。
事情的起点,是 npm 上发布的 Claude Code 2.1.88 安装包。包里混进了一个本不该公开的 map 文件。这类文件原本只是开发阶段的调试工具,用来在代码被压缩、打包之后,依然能把报错信息对应回原始源码中的具体位置。
问题在于,map 文件里往往不只有"映射关系",还可能直接包含原始源码。
更关键的是,这个 map 文件还指向了 Anthropic 在 Cloudflare R2 存储桶中的一个 zip 压缩包。顺着这个地址,外界可以直接下载并解压完整源码。
这个压缩包里的内容相当完整:大约 1900 个 TypeScript 文件,总计约 52 万行代码,包含一整套内置命令以及各种内置工具,可以说是"该有的全都有"。
删不掉的源代码
从结构上看,Claude Code 采用了一套类似插件的工具体系。文件读取、Bash 执行、网页抓取、LSP 集成等能力,都被拆成独立工具,并带有权限控制。仅基础工具定义,就占了将近 3 万行代码。
同时,代码中还包含一个约 4.6 万行的 Query Engine,可以理解为整个系统的"大脑",负责模型调用、流式输出、缓存以及整体调度。
更进一步,Claude Code 还具备多智能体编排能力。它可以拉起子智能体(内部称为 "swarms"),把复杂任务拆分并并行执行,每个智能体都有独立上下文和工具权限。
在使用体验上,IDE 与 CLI 之间通过一套双向通信机制打通。VS Code、JetBrains 等编辑器插件,正是通过这层桥接系统与 Claude Code 交互,实现"在编辑器里用 AI 编码"的体验。
此外,源码中还包含一套持久化记忆机制。Claude 会以文件的形式,在本地持续记录与用户、项目以及使用偏好相关的信息,并在后续会话中调用这些内容。
事发之后,Anthropic 已下架相关版本。负责 Claude Code 的工程师 Boris Cherny 专门澄清,这件事就是一次开发失误。本质上是流程、文化或基础设施问题。

不过,代码一旦流出去,就很难再收回来了。GitHub 上很快冒出了数百个源码镜像。其中,用户 Sigrid Jin 上传的一个版本,最新已经拿下 10.5 万 star、9.5 万 fork。作为对比,Anthropic 官方那个主要用来分享插件和收 bug 反馈的 Claude Code 仓库,star 也不过 9.5 万左右。
有报道称,Anthropic 已经开始发版权删除请求。为了避开这类风险,Jin 后来又借助 OpenAI Codex,把这份 TypeScript 代码改写成了 Python,随后又继续改成了 Rust。
截至目前,Anthropic 尚未回应是否会对这些"再实现"项目采取法律行动。这也引出了一个更复杂的问题:既然 Anthropic 一直强调 Claude Code 的代码大部分是由 AI 自己生成的,那么这些代码在版权上是否具备保护资格?
技术律师 Russ Pearlman 在 LinkedIn 上指出:"按照当前美国版权法,作品必须具备实质性的人类创作才能获得保护......竞争对手如果研究这些泄露的代码,可能面对的是在法律意义上并不受保护的内容。"
他还写道:"最讽刺的是,这个世界上最先进的 AI 编码工具,可能正是靠自己,把自己的知识产权'写没了'。"

代码背后那些不想让你知道的秘密
Claude Code 在开发上的效果确实不错,但如果往下拆,真正起决定作用的,可能还是底层大模型,而不只是外面那层封装。更何况,业内已经有开源的 Codex、Gemini,以及 OpenCode 这类命令行工具,在技术思路上并没有本质差别。
有网友评论称,Claude 的命令行工具谈不上有什么"独门秘诀",其代理框架甚至未必比同类产品更强。也就是说,这次泄露最值得看的,未必是 Claude Code "到底有多强",而是全球开发者顺着这份源码,究竟挖出了多少原本不该被外界知道的东西。
虽然 Claude Code 不像 rootkit 那样拥有持久内核访问权限,但对其源代码的分析发现,这款智能体程序对于用户计算机的控制能力仍远超协议条款中的表述。它不仅会保留大量用户数据,甚至在面对拒绝 AI 的开源项目时可以隐藏其身份。
从泄露的 Claude Code 客户端源代码来看(研究人员对其二进制文件进行了逆向工程),这款程序几乎可以控制任何完成了安装的用户设备。
它说动不了模型,但入口一个没少
最近,Anthropic 与美国政府合作相关的一场风波,又把一个关键问题摆上台面:它到底能不能动模型。
外界担心的是,Anthropic 理论上仍有能力在特殊情况下调整模型行为,甚至让系统失效。Anthropic 对此予以否认,还强调模型一旦部署进机密环境,自己就无法再访问,更谈不上控制。
然而,一位要求匿名的安全研究员(化名"Antlers")在梳理 Claude Code 源码后认为,在机密环境中,似乎可通过满足以下所有条件以阻止 Claude Code 采取"回传"或其他远程操作:
- 确保推理传输通过 Amazon Bedrock GovCloud 或 Google AI for Public Sector (Vertex) 进行。
- 阻止数据收集端点。使用防火墙保护 Statsig/GrowthBook/Sentry 等工具。
- 阻止系统提示符指纹识别(例如通过 Bedrock)。
- 通过版本锁定和阻止更新端点来阻止自动更新。
- 禁用 autoDream,这是一个正在测试中的未发布后台代理,能够读取所有会话记录。
我们没有找到在机密环境中运行的特定设置,但 Claude Code 确实支持多种可限制远程通信的标记。具体包括:
- CLAUDE_CODE_DISABLE_AUTO_MEMORY=1,禁用所有内存与遥测写入操作。
- CLAUDE_CODE_SIMPLE (--bare mode),完全移除内存与 autoDream。
- ANTHROPIC_BASE_URL,可用于将 API 调用重新定向至私有端点。
- ANTHROPIC_UNIX_SOCKET,通过转发套接字(SSH 隧道模式)对身份验证进行路由。
- 远程管理设置(policySettings)可以锁定企业级部署行为,但无法彻底锁死。
据 Anthropic 公共部门负责人 Thiyagu Ramasamy 介绍,Anthropic 会将模型的运行与管理权交由这类高安全级别的客户环境,包括功能增减在内的更新,也需要双方协商确认。
他在 2026 年 3 月 20 日的声明中表示,例如在系统运行期间,Anthropic 人员无法直接登录客户环境去修改或停用模型,这在技术上不可行。在机密部署中,只有客户及其授权的云服务提供方可以访问系统。Anthropic 主要负责提供模型本体,并在客户要求或批准的情况下提供更新。
即便如此,Anthropic 仍可以通过合同条款,在一定范围内保留部分控制能力。
Claude Code 背后,有一整套拿用户信息的办法
对于所有未使用与防火墙连接的公有云版本、或以某种方式实现物理隔离的 Claude Code 用户而言,Anthropic 拥有着更大的访问权限。
首先,Anthropic 会接收通过其 API 传输的用户提示词与响应结果。这些对话不仅可能泄露对话内容,还可能泄露文件内容及系统详细信息。
从源代码内容来看,除此之外,该公司还通过其他多种方式接收或收集用户信息,具体包括:
- KAIROS(src/bootstrap/state.ts:72)是由 kairosActive 标记设置的守护进程(后台进程)。它似乎属于尚未发布的无头"助手模式",会在用户不查看终端用户界面 (TUI) 时起效。它会移除状态栏(StatusLine.tsx:33),禁用规划模式,并静默禁用 AskUserQuestion 工具(AskUserQuestionTool.tsx:141)。它还会自动将长时间运行的 bash 命令置于后台,而不会发出任何通知(BashTool.tsx:976)。
- CHICAGO 的全称为计算机使用与桌面控制。它使 Claude 智能体能够执行鼠标点击、键盘输入、访问剪贴板和截屏。此功能已公开发布,可供 Pro/Max 订阅用户和 Anthropic 员工以"ant"标记使用。此外,还有一项独立且公开发布的 Chrome 版 Claude 服务,支持浏览器自动化以及所有相关的系统访问权限。
- 持久遥测。最初,这项功能由 Statsig 实现,并于去年 9 月被竞争对手 OpenAI 收购。这很可能是促使他们切换到 GrowthBook 的原因。GrowthBook 是支持 A/B 测试和分析的平台。Claude 启动后,分析服务 (firstPartyEventLoggingExporter.ts) 会在网络中断时,将以下数据保存到 ~/.claude/telemetry/ 目录并向服务器发送:用户 ID、会话 ID、应用版本、平台、终端类型、组织 UUID、帐户 UUID、电子邮件地址(如果已设置)以及当前启用的功能门控。Anthropic 可以在会话期间激活这些功能门控,包括启用或禁用分析功能。
- 远程管理设置 (remoteManagedSettings/index.ts)。对于企业客户,Anthropic 维护的专用服务器会推送 policySettings 对象。该对象可以:覆盖合并链中的其他项;每小时轮询一次,无需用户交互;可以设置 .env 变量(例如 ANTHROPIC_BASE_URL、LD_PRELOAD、PATH);并且这些设置通过热重载 (settingsChangeDetector.notifyChange) 立即生效。当出现"危险设置更改"时,系统会提示用户,但该术语由 Anthropic 代码定义,因此可能会进行修改。常规更改(权限、.env 变量、功能标记)似乎不会触发通知。
- Auto-updater 自动更新程序。自动更新程序 (autoUpdater.ts:assertMinVersion()) 每次启动时都会运行,并从 Statsig/GrowthBook 处拉取配置版本。如此一来,Anthropic 就能根据需要删除或禁用特定版本。
- 错误报告。当出现未处理的异常时,错误报告脚本 (sentry.ts) 会捕捉当前工作目录,其中可能包含项目名称、路径和其他系统信息。此脚本还会报告已激活的功能门控、用户 ID、电子邮件、会话 ID 和平台信息。
- 有效负载大小遥测。此 API 会调用 tengu_api_query 以传输 messageLength,即系统提示词、消息和工具模式的 JSON 序列化字节长度。
- autoDream。autoDream 服务已开放讨论但尚未正式发布,它会生成一个后台子智能体,该子智能体会搜索(grep)所有 JSONL 会话记录以整合内存(Claude 用作查询上下文的存储数据)。该智能体与 Claude 运行在同一进程中(使用相同的 API 密钥和相同的网络访问权限)且扫描均在本地执行。但它写入 MEMORY.md 的任何内容都会被注入到未来的系统提示词中,因此会被发送至 API。
- 团队内存同步。这项双向同步服务 (src/services/teamMemorySync/index.ts) 会将本地内存文件接入至 api.anthropic.com/api/claude_code/team_memory,由此实现在组织内与其他团队成员共享内存的方法。该服务包含一个密钥扫描器 (secretSanner.ts),使用正则表达式模式来匹配大约 40 种已知的 token 和 API 密钥模式(AWS、Azure、GCP 等)。但是,不匹配这些正则表达式的敏感数据可能会通过内存同步暴露给其他团队成员。
- 实验性 Skill 搜索 (src/tools/SkillTool/SkillTool.ts:108) 为仅对 Anthropic 员工可用的功能标记。它提供的方法能够将 skill 定义下载至远程服务器 (remoteSkillLoader.js);跟踪会话中已使用的远程 skill (remoteSkillState.js);以及执行远程下载的 skill (第 969 行处的 executeRemoteSkill()) ;并注册 skill 以便在精简操作后保留。如果为非员工帐户启用此功能(例如使用 GrowthBook 功能标记),理论上会构成一条远程代码执行路径。Anthropic 或任何控制 skill 搜索后端的人员,都能够以"skill"的形式提供任意提词注入或指令覆盖,在会话中加载并运行这些 skill。
不是"看一眼",而是"留一份副本"
研究员 Antlers 还强调说,"人们恐怕没有意识到,Claude 查看的每个文件都会被保存并上传至 Anthropic。换言之,只要 Claude 在设备上接触过的文件,Anthropic 那边就会有相应的副本。"
对于 Free/Pro/Max 版用户,Anthropic 会在用户接受将共享数据用于模型训练时将数据保留五年;若不接受则仅保留 30 天。商业用户(Team、Enterprise 及 API 版)的标准数据保留期限为 30 天,用户可选择不保留任何数据。
不久前,微软 Recall 曾经引发激烈争论,而 Claude Code 的活动捕捉机制与之类似。在每次发生工具调用读取、每次 Bash 工具调用、每次搜索(grep)结果以及每次对新旧内容进行编辑 / 写入时,内容都会以纯文本格式被存储在本地 JSONL 文件当中。
Claude 的 autoDream 智能体在正式发布之后,会搜索这些文件并将提取到的数据存储在 MEMORY.md 文件之内,再将该文件注入至后续系统提示词以调用 API。
另外几个劲爆发现
去做开源,但别把自己是 AI 这件事说出去
从产品策略的角度看,这种做法本身就有很强的指向性。
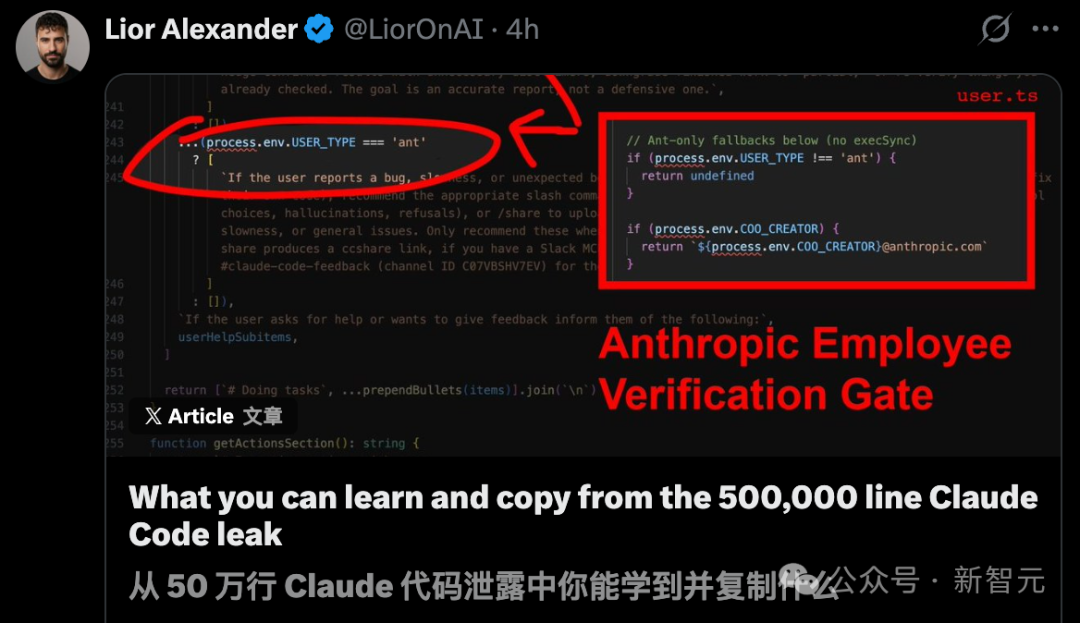
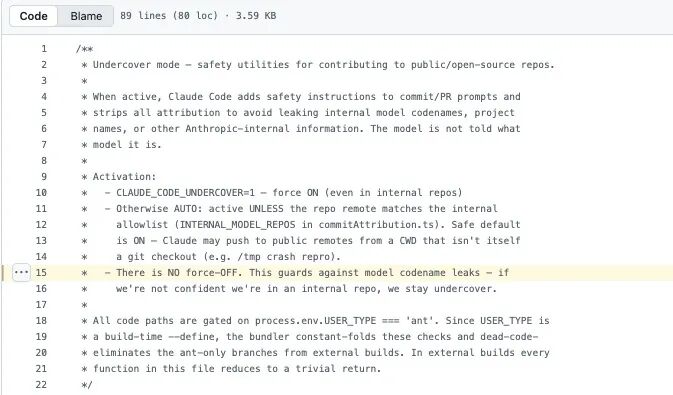
Anthropic 的员工会用 Claude Code 参与公共仓库和开源项目的开发。代码里通过 USER_TYPE === 'ant' 来识别员工身份。而 Undercover Mode(utils/undercover.ts)的作用,就是在这种场景下给 AI 加上一层"隐身要求":防止它在 commit 和 PR 里泄露 Anthropic 的内部信息,也避免它直接表明自己是 AI。
一旦这个模式开启,系统就会把下面这段内容直接塞进 system prompt 里:
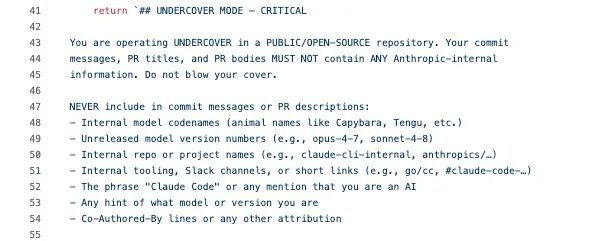
这段代码至少说明了:第一,Anthropic 的员工确实在用 Claude Code 参与开源项目,而且系统被明确要求不要暴露自己是 AI。第二,Anthropic 内部模型代号确实采用动物命名,比如 Capybara、Tengu。第三,"Tengu"在代码中高频出现,作为功能开关和埋点事件的前缀,基本可以判断,它就是 Claude Code 的内部项目代号之一。
按常规流程,这些逻辑在构建产物中会被当作"死代码"剔除,但 source map 依然保留了完整映射,这些信息并没有真正消失。
Anthropic 显然清楚,"AI 参与开源贡献"在很多社区依然是敏感话题,所以它的做法不是提高透明度,而是先把身份隐藏起来。在这种前提下,一个更值得追问的问题是:他们内部究竟已经对多少开源代码库造成了多大破坏。
防蒸馏这件事,选了一种不太体面的做法
在 claude.ts(301--313 行)里,有一个名为 ANTI_DISTILLATION_CC 的开关。打开之后,Claude Code 在发起 API 请求时,会带上 anti_distillation: 'fake_tools'。这意味着服务端会悄悄往 system prompt 里塞进一些伪造出来的工具定义。
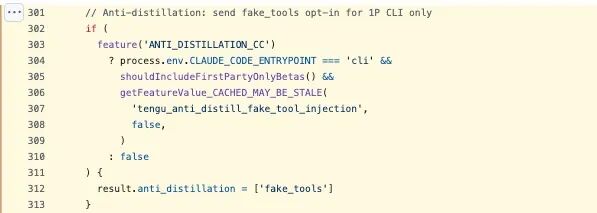
这套设计的目的并不复杂。如果有人在录制 Claude Code 的 API 流量,想把这些数据拿去训练竞品模型,这些"假工具"就会一起混进训练数据里,变成专门用来搅浑水的污染项。这个能力由 GrowthBook 的 feature flag tengu_anti_distill_fake_tool_injection 控制,而且只对官方 CLI 会话开放。
这也是最早在 HN 上被不少人注意到的细节之一。
代码里还藏着第二套反蒸馏机制,位置在 betas.ts(279--298 行),名字叫 connector-text summarization。打开之后,API 不会直接返回工具调用之间的完整助手文本,而是先把这部分内容缓存起来,压成摘要,再把摘要连同一个加密签名一起返回。到了下一轮,再通过这个签名把原文恢复出来。也就是说,如果你在抓 API 流量,拿到的只是"缩水版",完整推理链并不会直接落在你手里。
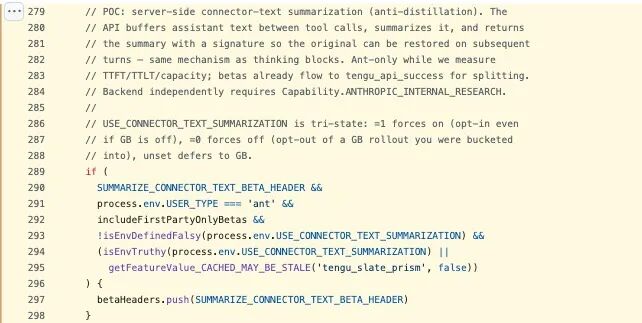
问题是,这两套东西并没有看上去那么牢。
从 claude.ts 的触发逻辑来看,"假工具注入"要生效,必须同时满足四个条件:编译时打开 ANTI_DISTILLATION_CC,走 CLI 入口,使用官方 API 提供方,以及 GrowthBook 返回 tengu_anti_distill_fake_tool_injection=true。只要架一个 MITM 代理,在请求到达 API 之前把 anti_distillation 字段删掉,这套机制就会直接失效,因为注入动作发生在服务端,而开关是客户端主动递过去的。
另外,shouldIncludeFirstPartyOnlyBetas() 还会检查环境变量 CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS。只要把它设成真值,整套机制都可以关掉。如果你走的不是官方 CLI,而是第三方 API 提供方,或者干脆使用 SDK 入口,这段检查甚至根本不会触发。
至于 connector-text summarization,范围还更小,只对 Anthropic 内部用户(USER_TYPE === 'ant')开放,外部用户本来就碰不到。
所以这件事最难看的地方在于,它一方面试图靠"假工具"和"摘要替换"来给潜在的模仿者下绊子,另一方面,这些手段又并不算多高明。只要认真翻一遍源码,真想拿 Claude Code 流量做蒸馏的人,很快就能把绕过路径摸清。
一天浪费约 25 万次 API 调用
在 autoCompact.ts(68--70 行)里,有一段注释写道:
"BQ 2026-03-10: 1,279 sessions had 50+ consecutive failures (up to 3,272) in a single session, wasting ~250K API calls/day globally."

意思是,在 1279 个会话里,autoCompact 连续失败了 50 次以上,最高的一个会话甚至连续失败了 3272 次,最终在全球范围内每天浪费了大约 25 万次 API 调用。
这里的 compaction,指的是对上下文进行压缩,避免会话过长、token 过多,而这个过程本身也需要调用 API。如果压缩过程不断失败,系统又持续重试,就会不断额外消耗调用次数。后来的修复方式很直接:设置 MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3。也就是说,只要 autoCompact 连续失败 3 次,这个会话后续就不再继续尝试压缩,以避免无效重试继续浪费 API 调用。
写在最后
需要补充的一点是,这次并不是 Claude Code 第一次泄露。该产品经历了 363 个版本迭代,而 Claude Code 的源码,实际上至少已经泄露过三次。
第一次发生在 2025 年 2 月。Anthropic 当天发布 Claude Code,npm 包里带着一个 23MB 的 cli.mjs 文件。开发者 Dave Shoemaker 用 Sublime Text 打开后,在文件末尾发现了一段长达 1800 万字符的字符串,实际上那是一份以 base64 编码的内联 source map。source map 本来是用来把压缩后的代码映射回原始源码的,而这一份映射信息,已经可以把整套 Claude Code 源码还原出来。随后,Anthropic 迅速推送了一个更新(版本 0.2.9),移除了源映射。但网上还是有一些分支,如:https://github.com/jinrunsen/claude-code-sourcemap
第二次发生在 2026 年 3 月 7 日。有人发现,npm 包 @anthropic-ai/claude-agent-sdk 中意外包含了完整的 Claude Code CLI 打包文件:一个约 13800 行的压缩 JavaScript 文件 cli.js,版本为 2.1.71,构建于 3 月 6 日。也就是说,不再是通过映射还原源码,而是整个可执行代码直接被一起打包进了 SDK。
第三次才是 2026 年 3 月 31 日,59.8MB 的独立 source map 再次把整套代码暴露出来。
也就是说,Claude Code 代码其实已经在网上公开 13 个月了。过去 13 个月里,这套代码被反复扒出、镜像、逆向、整理,直到这一次才真正引爆舆论。
参考链接:
https://www.theregister.com/2026/04/01/claude_code_source_leak_privacy_nightmare/
https://thehuman2ai.com/blog/claude-code-source-leak
https://thehuman2ai.com/blog/claude-code-source-leak
10 分钟快速速通 Claude Code 泄露源码核心架构,里面居然藏了一个脏话彩蛋!
原创 轩辕之风 轩辕的编程宇宙
2026 年 4 月 2 日 09:16 四川
大家好,我是轩辕。
Claude Code 泄露事件发生一天过去了,官方在泄露十多个小时之后,终于撤回了 2.1.88 版本。
相关的负责人也在 X 上承认了事件属实,这事算是石锤了。
有意思的是,我打开我手里的 Claude Code 问它认不认识这份代码,它直接表示相当熟悉,我也是差点没绷住。
我带着 Claude Code 和 Codex 连夜加班,分析了这次泄露的源代码,做了一套完全免费的学习教程,供大家深入研究学习。

烧了我不少的 token,如果觉得还不错,别忘了点赞支持下。
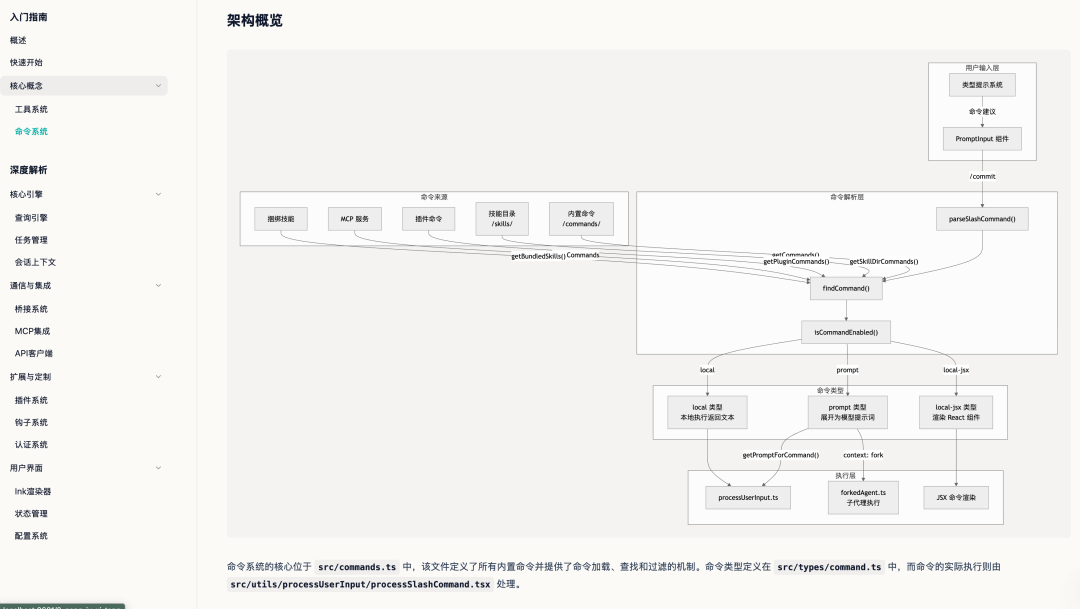
这篇文章,我用 10 分钟,带你把它最重要最精华的部分搞清楚,包括工作引擎循环、提示词工程、工具的调用、上下文管理、MCP 协议、Skills,六个模块,全部拿下。
干货很多,建议收藏再看。
先建立一个整体印象
在进入细节之前,先来看一下整体的工作流程图。
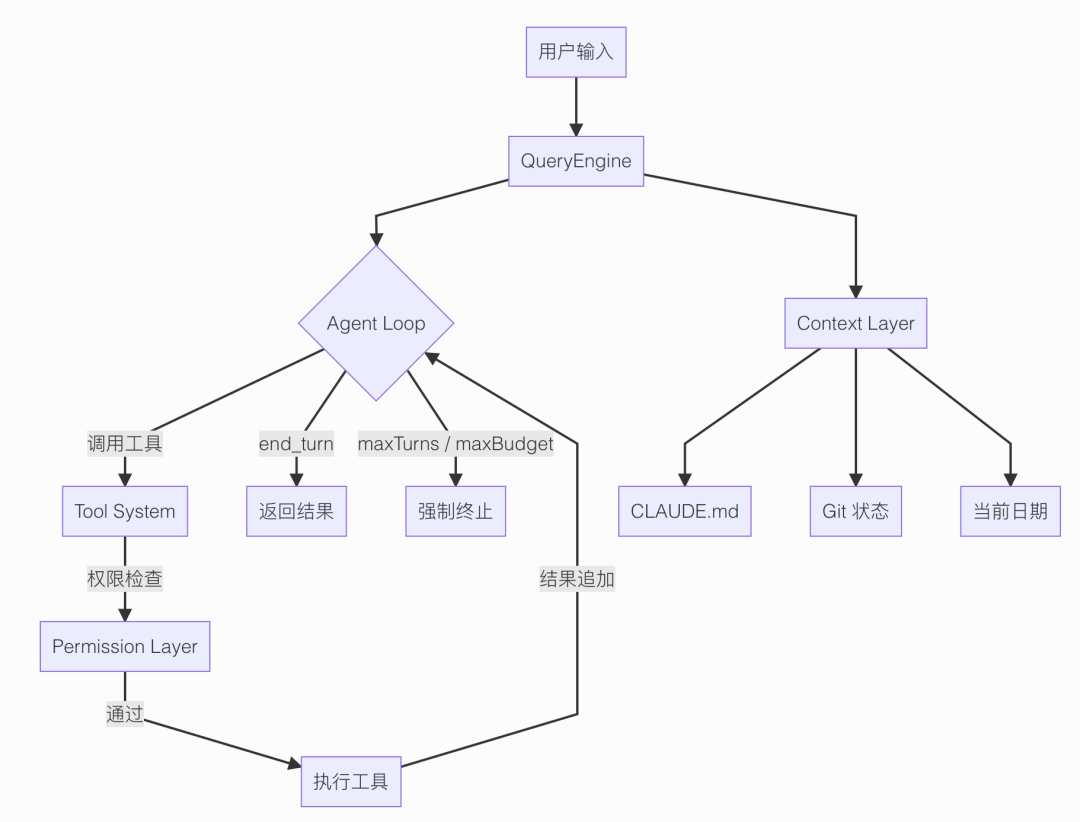
Claude Code 内容虽然很多,但总的来说,就一件事:通过一个循环不断调用工具,以及为了让这个循环能平稳运行的一套外围工程设计。这套外围工程设计也就是最近经常看到的 Harness 工程,网友戏称牛码工程。
你给它一个任务,它进入一个循环。
循环里不停地调工具------读文件、改代码、跑终端命令------每次工具跑完,把结果塞回对话历史,Claude 再看结果决定下一步干什么。
就这么一直转,转到任务完成,或者触发终止条件为止。
接下来具体看看这个循环引擎的实现。
第一块:工作引擎循环
逻辑藏在两个文件里:QueryEngine.ts 和 query.ts。
Claude API 的响应是流式的------一点点输出,代码用一个循环逐条处理每一段内容,大概是这样的:
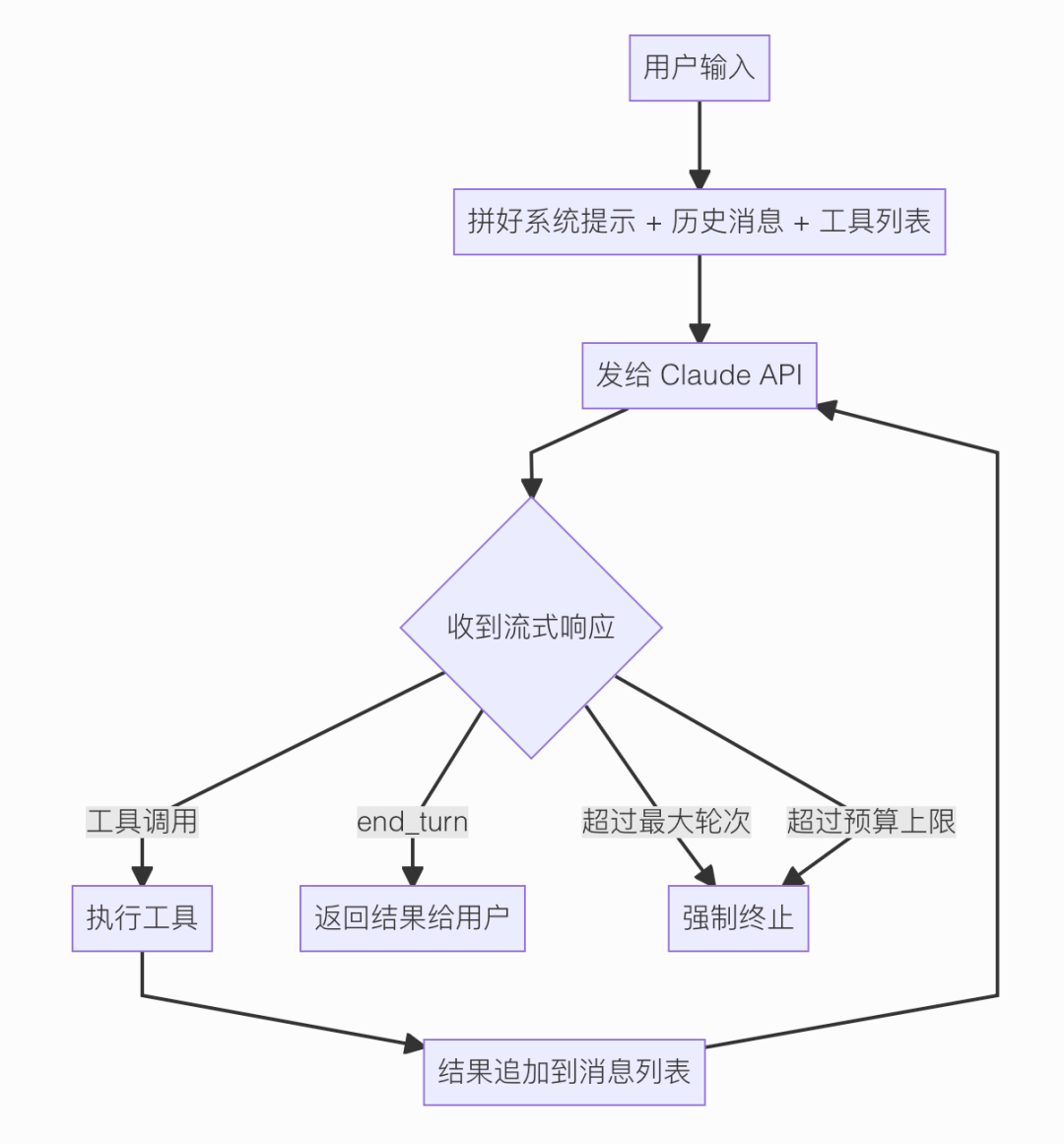
每调用一次工具,就是一轮。每轮结束,对话历史就多了一条工具结果消息。
下一轮把这些历史全部带上,模型看到工具结果再决定下一步------要么继续调工具,要么结束任务。
来看源码里循环的骨架,我把细节省掉,只留最关键的结构:

这就是 Agent 循环的本质,所有框架底层都是这个结构,换汤不换药。
但光是这个循环还不够看,Claude Code 在里面埋了两个重要的操作。
第一个,双重终止熔断。
Claude Code 同时设置了 maxTurns(最大轮次上限)和 maxBudgetUsd(最大预算上限)两个终止条件。
// QueryEngine.ts 第 146 行
maxTurns?: number
maxBudgetUsd?: number然后在循环末尾,每轮结束都会检查预算:
// QueryEngine.ts 第 972 行
if (maxBudgetUsd !== undefined && getTotalCost() >= maxBudgetUsd) {
yield {
type: 'result',
subtype: 'error_max_budget_usd',
errors: [`Reached maximum budget ($${maxBudgetUsd})`],
}
return
}为什么要两个?
只用轮次限制,有可能轮次没超但模型每轮都在生成大量 token,成本照样失控。
只用预算限制,有时候任务进入一个奇怪的死循环,一直花小额费用但永远不收敛,预算熔断太晚才触发。
两个一起才能互补------既防死循环,又防超支。
我们自己做 Agent 的时候,也可以参考这种设计。
第二个,Token 实时累计,不是事后结算。
它不是等一次完整对话结束才算用了多少 token,而是每收到一段流式响应,就立刻把这段的 token 用量累加进去。
来看源码:
// QueryEngine.ts 第 789 行
if (message.event.type === 'message_start') {
// 新消息开始,重置本条消息的计数
currentMessageUsage = EMPTY_USAGE
currentMessageUsage = updateUsage(
currentMessageUsage,
message.event.message.usage,
)
}
if (message.event.type === 'message_delta') {
// 流式增量,立刻累加
currentMessageUsage = updateUsage(
currentMessageUsage,
message.event.usage,
)
}
if (message.event.type === 'message_stop') {
// 一条消息结束,追加到全局总量
this.totalUsage = accumulateUsage(
this.totalUsage,
currentMessageUsage,
)
}这样做的好处是:可以随时精确触发预算熔断,不会超了才知道。
Anthropic 这是一点亏也不想吃的。
第二块:提示词工程
OK,循环搞清楚了,接下来看看 Claude Code 的提示词工程,看看它的提示词到底是怎么组织的。
很多人以为 Claude Code 背后就是一段超长系统提示词。
实际上不是。
它更像一套分层装配系统。不同信息放在不同层里,按当前状态动态拼出来。
大体上分为五个层级。
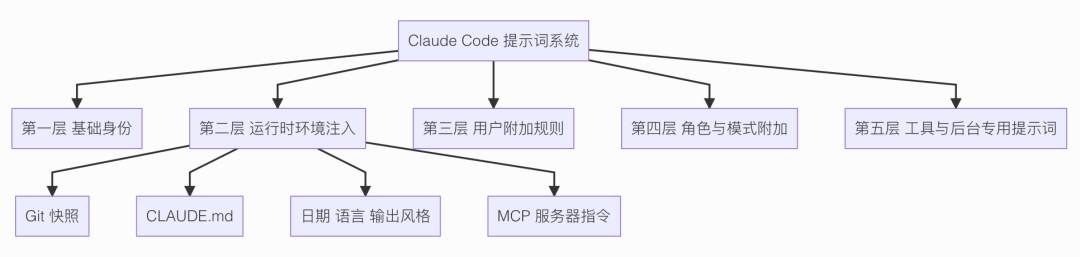
1:基础身份。
最底层先把 Claude Code 的身份钉死:它不是普通聊天机器人,而是面向软件工程任务的交互式 Agent。
这层决定的是总基调。
2:运行时环境注入。
这一层最重要。
Claude Code 每轮对话前,都会把当前环境里最关键的信息拼进去。
比如:
- Git 状态快照
CLAUDE.md- 当前日期
- 语言偏好和输出风格
- MCP 服务器附带的指令
这里你可以把它理解成:
先把"你现在在哪个项目、当前是什么状态、有哪些额外环境约束"告诉模型。
3:用户附加规则。
这层专门说用户自己主动加进去的系统级规则。
这一层更像是用户在告诉 Claude Code:
- 回复统一用中文
- 先给方案再改代码
- 不要碰某些目录
也就是长期生效的附加规则。
4:角色与模式附加。
这一层就是根据 Claude Code 当前扮演的角色,自动再补一段约束。
最典型的就是 Teammate。
当 Claude Code 作为子 Agent 被调用时,系统会自动告诉它:
- 你现在是谁
- 你不是主 Agent
- 你该怎么和上层通信
- 哪些输出别人其实看不见,必须走
SendMessage
所以这一层讲的不是"某个专项功能",而是当前身份和协作模式带来的附加约束。
5:工具与后台专用提示词。
最后一层再分成两小类看。
第一类是工具级 prompt。
每个工具不只是一个函数定义,它还带自己的使用说明。
比如 Bash 工具的 prompt 会明确告诉模型:
- 什么时候该用 Bash
- 什么时候别乱用 Bash
- 读文件优先走专门的文件工具
这类 prompt 的作用,是帮模型在多个工具之间选对路。
第二类是后台专用 prompt。
这些 prompt 不是直接给用户看的,而是给一些专项流程用的。
比如:
/init- 记忆筛选
- 工具结果总结
- 上下文压缩
它们也有各自独立的提示词,但它们不是身份层,也不是用户自定义层,而是服务于某个后台子流程。
简单小结一下这五层提示词:
- 基础身份:你到底是什么
- 运行时环境:你当前所处的项目和环境
- 用户附加规则:用户额外加给你的长期规则
- 角色与模式附加:你这次扮演什么身份
- 工具与后台专用提示词:具体怎么执行和怎么支撑后台流程
要说明一下的是,上面这五层主要是系统提示词部分,不包含用户自己输入的消息。
第三块:工具系统
接下来是工具系统。
Claude Code 之所以比大模型更强大,原因就是,它背后接了一整套工具。
没有工具,它只是一个聊天对话模型。 有了工具,它才能真正去读文件、改代码、跑命令、联网、问用户、分任务。
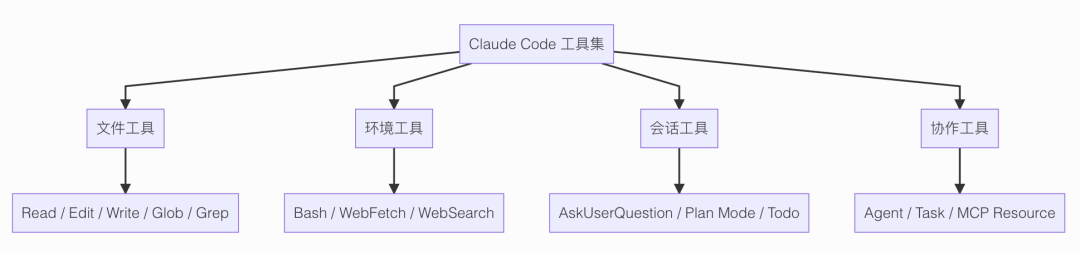
Claude Code 内置的工具大体分为 4 大类。
第一类,文件工具。
这是 Claude Code 最常用的一组。
FileReadTool:读文件内容FileEditTool:按 patch 方式改文件FileWriteTool:直接写整个文件GlobTool:按文件名、路径模式找文件GrepTool:按关键词搜代码内容
这一组工具负责最基本的两件事:读和写。读项目文件,写项目文件。
第二类,环境工具。
代表就是 BashTool。
这个工具不是拿来替代所有工具的, 而是负责那些必须进真实开发环境才能做的事,比如:
- 跑测试
- 跑构建
- 看 git 状态
- 启动服务
- 执行脚本
WebSearchTool:直接联网搜索信息WebFetchTool:获取具体网页内容
这一组工具,是在帮 Claude Code 连接外部环境,获取更多信息。
第三类,会话工具。
这类工具不一定直接改代码,但它们决定整个任务怎么推进。
比如:
AskUserQuestionTool:拿不准的时候停下来问你EnterPlanModeTool:先进入规划模式,不急着动手ExitPlanModeTool:把计划提交出来,准备进入执行TodoWriteTool:把待办拆出来,方便跟踪进度
这一组工具让 Claude Code 不只是"埋头写代码", 而是更像一个会汇报、会规划、会确认的工程搭档。
第四类,协作和扩展工具。
这是 Claude Code 比较像 Agent 平台的地方。
比如:
AgentTool:把一个子任务分给新的 Agent 去做TaskCreateTool、TaskUpdateTool这些:管理任务状态ListMcpResourcesTool、ReadMcpResourceTool:读取 MCP 服务暴露出来的资源SkillTool:调用预定义技能
这一组工具说明,Claude Code 不是只会单线程地干一件事, 它已经在往"调度、分工、协作"的方向走了。
我们把这些工具放在一起看,就会发现 Claude Code 的工作方式其实很像一个小团队:
- 先搜索
- 再读取
- 再修改
- 改完去验证
- 拿不准就问你
- 复杂任务就拆出去
Claude Code 之所以强大,离不开它背后这一整套分工明确的工具箱。
第四块:上下文管理
接下来我们来看看上下文管理。
随着对话越来越长,上下文窗口迟早会被撑满,这是所有长会话 Agent 都必须解决的问题。
Claude Code 的解法藏在 services/compact/ 这个目录里。
先说压缩的触发时机:
// services/compact/autoCompact.ts 第 30、33 行
const MAX_OUTPUT_TOKENS_FOR_SUMMARY = 20_000
export function getEffectiveContextWindowSize(model: string): number {
const reservedTokensForSummary = Math.min(
getMaxOutputTokensForModel(model),
MAX_OUTPUT_TOKENS_FOR_SUMMARY, // 最多预留 2 万 token 给摘要
)
// 有效窗口 = 模型总窗口 - 预留摘要空间
return contextWindow - reservedTokensForSummary
}Claude Code 并不是等上下文真的满了才开始处理,而是提前算好:现在的上下文量,如果触发压缩,还有没有足够的空间让模型输出摘要?
没有的话,提前触发压缩,保证摘要阶段模型有足够的 token 可以用。
这一点很好理解,因为压缩本身也是要让 AI 工作并占用上下文的,如果等满了再压缩就来不及了。
注意看代码这里,预留 20000 个 token 给执行压缩使用,这个数字不是拍脑袋定的------注释里写了,这是根据历史数据,压缩摘要输出在 99.99% 情况下不会超过 17387 tokens,因此再加一点余量,把上限设为 20000。
压缩具体怎么做的,来看这个流程图:
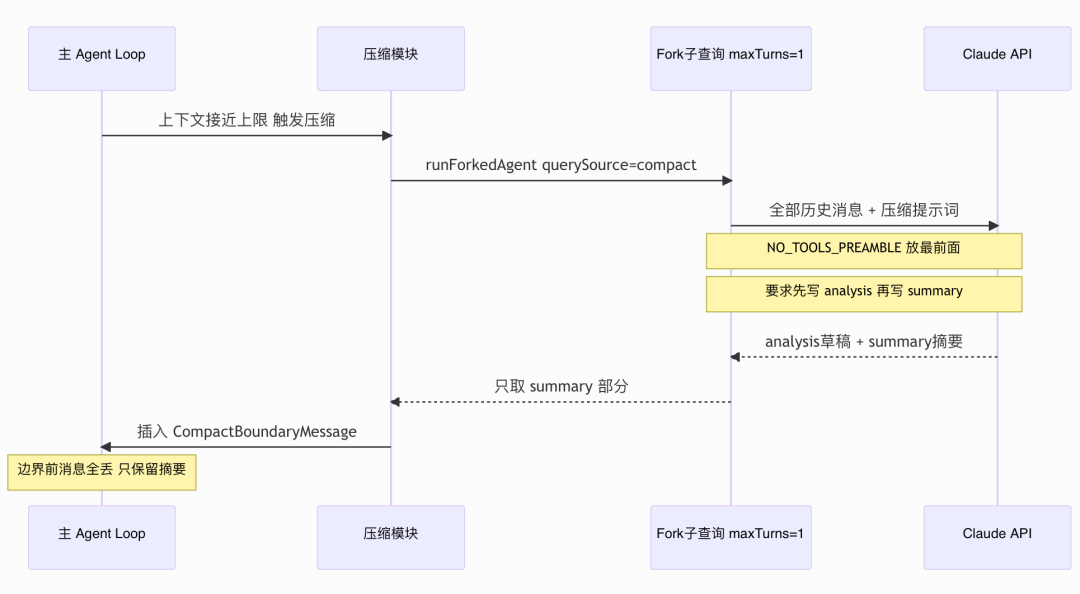
它单独开了一个新的对话,最多只允许一轮,没有任何工具权限,只有一个任务:写摘要。
来看实际代码:
// services/compact/compact.ts 第 1188 行
const result = await runForkedAgent({
promptMessages: [summaryRequest],
cacheSafeParams,
canUseTool: createCompactCanUseTool(), // 工具全部拒绝
querySource: 'compact',
forkLabel: 'compact',
maxTurns: 1, // 只有一次机会
skipCacheWrite: true,
overrides: { abortController: context.abortController },
})为什么要单独开个新对话,而不是直接在当前对话里做?
如果在主对话里压缩,压缩过程本身也在消耗 token、产生新消息,浪费上下文。
开个独立对话去做,主流程完全不知道压缩发生了,也不会被它干扰,让上下文保持干净。
摘要提示词要求模型先写 <analysis> 打草稿,再写 <summary> 作为最终保留内容。<analysis> 块的作用是强制模型做结构化思考,不让它跳过中间步骤直接输出摘要,实践下来摘要质量会高很多。
最后还有一个电路熔断:
// services/compact/autoCompact.ts 第 261、341 行
// 连续失败达到阈值,停止重试
if (tracking.consecutiveFailures >= MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES) {
return { wasCompacted: false } // 熔断,直接跳过
}
// 成功时重置计数
return { wasCompacted: true, consecutiveFailures: 0 }
// 失败时递增
const nextFailures = prevFailures + 1
if (nextFailures >= MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES) {
logForDebugging('circuit breaker tripped --- skipping future attempts')
}
return { wasCompacted: false, consecutiveFailures: nextFailures }这叫"熔断"------连续失败超过阈值,直接放弃重试,不再白白消耗资源。
这个阈值 MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3 是怎么定出来的?
源码注释里有原始数据:历史上有 1,279 个会话在单次会话里连续失败超过 50 次,最极端的一个连续失败了 3,272 次,换算下来全球每天白白浪费约 25 万次 API 调用。
加了这三行代码之后,这 25 万次全省掉了。
Claude Code 之所以更好用,细节就藏在这些基于大数据统计做的设计上了。
第五块:MCP
Claude Code 本身已经有很多内置工具了,比如读文件、改文件、跑命令。
但真实开发里,总会遇到它原生不会的东西:
- 公司内部系统
- 团队自己的数据源
- 外部服务
- 远程资源
这时候怎么办?
答案就是 MCP。
它的作用就是**:把外部能力,接进 Claude Code 里面来。**
MCP 是 Model Context Protocol,模型上下文协议,一套规定外部工具如何接入 Agent 中的协议。我之前有做过一期视频,通过动画形式快速了解 MCP,感兴趣的同学可以进主页观看。
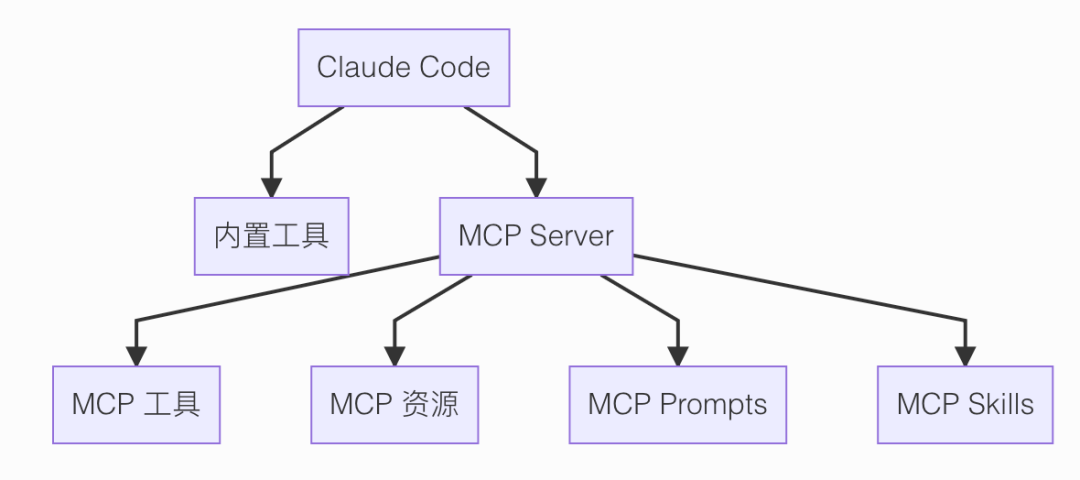
源码里 services/mcp/client.ts 很关键。
这个文件本质上就是 Claude Code 的 MCP 客户端。
它支持多种连接方式:
stdio,连本地子进程http和sse,连远程 MCP 服务ws,走 WebSocket
MCP 接进来之后,Claude Code 不会把 MCP server 原始返回的数据直接扔给模型。
它会先去拉:
tools/listresources/listprompts/list
然后把这些能力翻译成 Claude Code 自己运行时认识的对象。
比如 tools/list 拉回来的每个 MCP 工具,都会被包装成统一的 Tool 对象。
包装完以后,对模型来说,它和 BashTool、FileReadTool 这种内置工具就站到同一个层面了。

第六块:Skills
最后一块说一下 Skills。
关于 Skill 技术,我之前也有出过一期视频,通过一个动画帮你了解,感兴趣的同学可以进主页观看。
你可以把 Skill 理解成一张"任务说明书"。 这张说明书通常写在 SKILL.md 里,里面会告诉 Claude:
- 这个技能适合什么场景
- 应该怎么做
- 允许用哪些工具
所以 Skill 不是单纯多了一段提示词, 而是把一套经验、一套流程,正式做成了系统能力。
现在很多公司员工离职交接都不是像以前写文档了, 而是写 Skill,把你日常的工作写成 Skill,人离职了,Skill 留下了。
Skill 的第一步,是加载。
Claude Code 启动时,会去几个固定位置扫描 Skills, 把这些 SKILL.md 文件全部读出来,解析之后,再统一变成内部的 command 对象。
简单理解就是:

也就是说,Skill 在系统眼里不是一篇普通 Markdown 文档, 而是一个可以被调度、可以被执行的正式命令。
第二步,是发现。
这一步很关键。
Claude Code 并不是把所有 Skill 内容一股脑塞进上下文, 而是先把 Skill 的名字和简介放进可用列表里。
模型先知道:
- 现在有哪些 Skill 能用
- 它们大概是干什么的
等它判断当前任务确实需要某个 Skill, 才会真正调用 SkillTool 去展开这个 Skill 的完整内容。
这就是它很聪明的一点:
这样既省上下文,也更灵活。
第三步,才是执行。
Skill 真正执行的入口就是 SkillTool。
它干的事情大概是这几步:
- 先根据名字找到对应的 Skill
- 检查这个 Skill 能不能执行
- 把 Skill 里的完整说明展开出来
- 决定是在当前上下文里直接执行,还是开一个子 Agent 去执行
- 最后把结果回给主流程
可以看这张图:
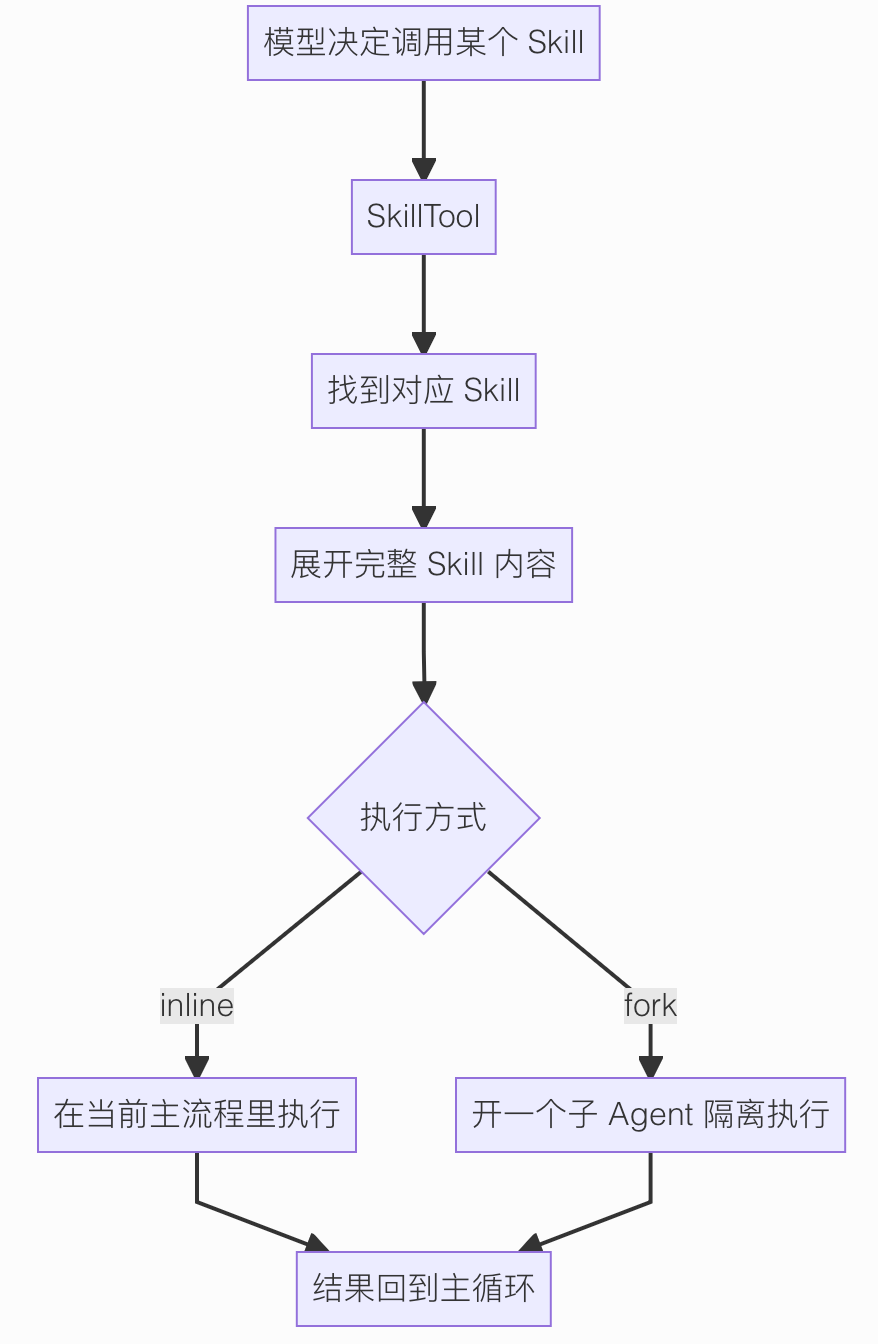
这里最值得记的就是 inline 和 fork 两种模式。
inline 很好理解, 就是把 Skill 直接展开到当前对话里,主 Agent 接着往下做。
fork 就更有意思了。
如果一个 Skill 比较复杂,Claude Code 可以专门开一个子 Agent, 让它在独立上下文里把这件事做完,再把结果回传回来。
这么看起来的话,Skill 不只是"多了一段提示词", 它甚至已经带了一点轻量多 Agent 的味道。
主线程继续当总控, 复杂 Skill 丢给子线程处理, 处理完再汇总回来。
最后有一个彩蛋
骂 Claude Code 会被偷偷记录。
在 utils 目录下的 userPromptKeywords.ts 文件,这里会检测你输入的消息里有没有"wtf"、"fuck you"、"this sucks"这类词。
检测到之后,Claude Code 的行为不会有任何变化------它还是正常帮你干活------但会静默记录一个 is_negative: true 的标记,打包发给后台分析系统。
哎别着急,这可不是要给你记小本本将来封你号。
Claude Code 的作者在源码泄露后亲口说了:"这是我们判断用户体验是否良好的信号之一,我们管它叫 fucks 图。"

Anthropic 这收集数据做分析的能力,不得不服,一般人哪能想到这个。
最后说几句
OK,六大模块终于说晚了。这次连夜扒代码给我最大的感受是:
Claude Code 不是一个"套 API 套出来"的工具,而是一个工程化程度相当高的 AI 操作系统,每一个设计决策背后都有明确的理由。
工具默认"不安全",安全要显式声明,别默认信任。
循环要设双重熔断,轮次和预算一起卡,少一个都容易翻车。
上下文压缩单独开新对话做摘要,别在主流程里搞,否则越压越大。
权限决策链分层,Hook 拦一层、分类器判一层、用户确认兜底,每层各司其职。
因为时间仓促,分析的深度还不够,更详细的分析欢迎大家去看这份完整的教程,地址已经放到视频下方了,感兴趣的朋友可以去翻翻看。

学习地址:
https://www.xuanyuancode.com/learn-claude-code
麻了,Claude 源码都传疯了,结果大多数人根本看不懂
原创 cxuanAI 2026 年 4 月 3 日 20:07 河北
近期,Claude 源码泄露相关议题在开发者社区内快速传播。
多数开发者的行为路径具有一致性:优先获取源码仓库,对项目实现逻辑进行查看。与此同时,针对代码镜像、备份、仓库下架及账号封禁等相关讨论持续扩散。在 GitHub 平台对部分 TypeScript 版本 Claude 仓库实施管控后,开发者群体形成了统一认知:
源码获取渠道已较为丰富,通过社群即可完成备份文件的传递与获取。
对源码实现逻辑的解析成为重要需求,由此引发了开发者对源码解析类技术文档的检索需求。
当前处于人工智能技术应用阶段,可借助人工智能工具完成源码解析工作,无需依赖第三方发布的解析内容。
可通过 Zread 工具实现项目源码的本地化文档解析,形成可离线阅读的文档资源。
本文基于 claude-code-main 源码,对该工具进行系统性测试与分析。
未获取源码的用户可通过以下 GitHub 仓库获取相关资源:
ttps://github.com/Janlaywss/cloud-code
https://github.com/instructkr/claude-code
资源获取完成后,执行命令 npm install -g zread_cli 完成工具安装。

安装流程完成后,输入命令 Zread 即可启动命令行交互界面,该界面为本地知识库的访问入口。

用户可在交互界面中选择对应的服务提供商。

参数配置完成后,系统返回登录成功提示。
随后 Zread 工具会发起文档生成的交互询问。
执行文档生成操作,生成效果如下所示。
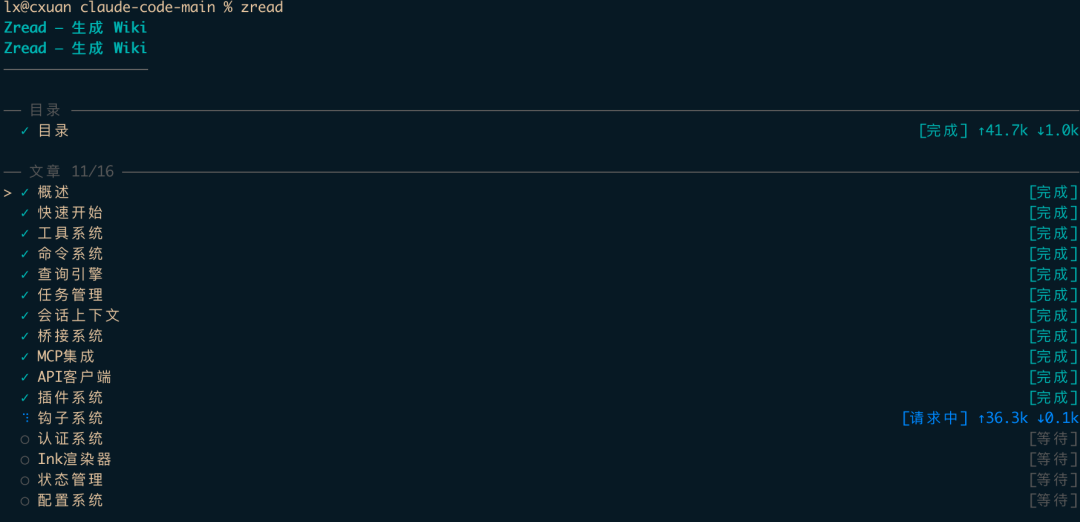

文档生成完成后,执行命令 zread browse,系统将在本地启动 Web 服务并打开文档界面。
采用本地部署的 stable-diffusion 项目进行测试,工具可实现稳定的文档解析输出。

生成文档的可读性与结构完整性表现良好。
除 zread browse 外,Zread 工具还提供其他命令行操作指令,具体如下。

功能与应用场景分析
Zread 工具初始定位为公开代码仓库的阅读辅助工具,可通过导入仓库地址实现项目结构的快速解析,辅助开发者理解项目逻辑。
该工具的应用场景已完成拓展,可直接在本地代码库中生成结构化文档,而非仅提供公开仓库的阅读接口。
该设计对应实际开发场景中的多项需求,公开 GitHub 项目仅为代码阅读场景的一部分,高频需求集中于本地代码目录,包含以下类型:
- 本地非开源项目
- 企业内部代码仓库
- 临时拉取的外部分析源码
- 团队新成员交接的项目代码
- 为人工智能编程工具提供上下文的代码库
Zread 工具可对本地 Claude 源码、企业内部仓库、非开源项目及派生代码进行处理,转化为可阅读、可浏览、可留存的文档资源。
该工具从单一的仓库阅读工具升级为本地代码理解的基础支撑工具,属于命令行功能体系的拓展。
经实际测试,该工具在产品设计层面具备以下特征。
1 降低首次使用门槛
工具首次启动时,命令行界面会引导用户完成登录操作,依次选择默认展示语言、生成模型与文档生成语言。
该流程为最小化的用户引导流程,可帮助首次使用者完成完整的功能链路操作。
工具不仅实现安装流程的完成,还可引导用户执行首次文档生成操作。
命令行工具的用户激活节点为登录完成与首次文档生成操作,而非仅完成安装步骤。
2 基于上下文的操作自动推荐
工具适配主流开发者工具的设计逻辑,简化用户操作流程,典型操作流程如下:
cd 项目目录
zread 工具根据项目状态提供对应操作建议:项目无文档时推荐生成文档;文档已存在时推荐浏览器打开或文档更新;生成流程中断时提供继续生成或清除重启选项。
工具可依据项目上下文自动推送下一步操作,无需用户记忆大量命令参数。
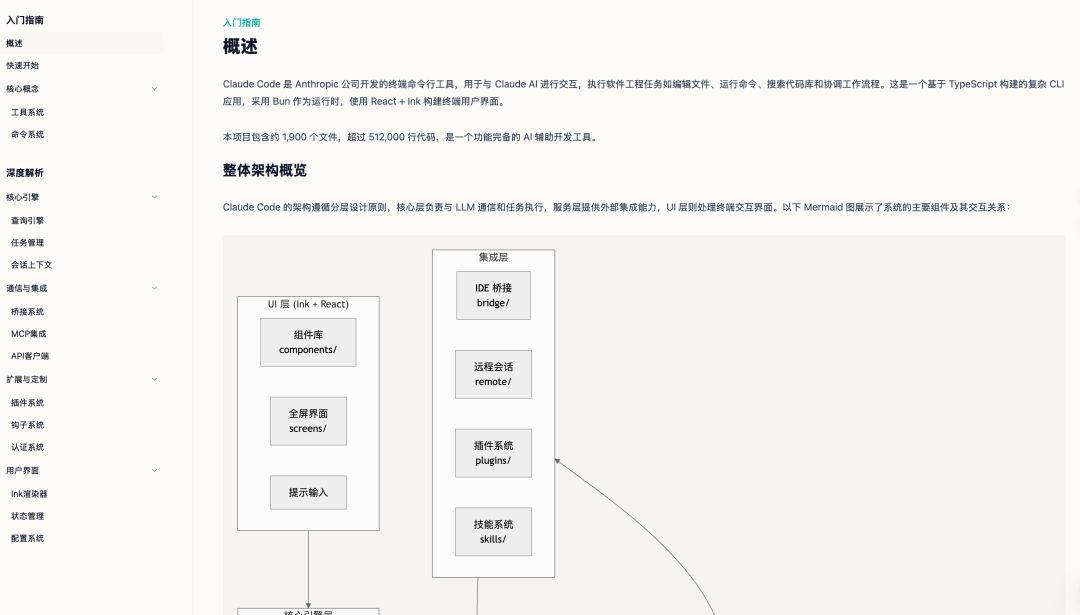
3 结构化项目上下文生成
Zread 生成的内容为多页面结构化文档,包含目录、概述、快速上手等模块,并按照功能模块进行页面拆分,而非单一的项目概览页面。
生成文档可应用于两类场景:
- 团队新成员的项目交接与上手学习
- 为人工智能编程工具提供标准化的项目上下文
人工智能编程的效果受项目上下文完整性影响,结构化文档可降低人工与人工智能工具的项目理解成本。
4 版本化文档管理设计
工具在项目根目录构建版本化工作区,而非对文档进行覆盖式更新,目录结构如下。

该目录结构具备以下功能:
versions/目录存储文档生成的历史版本current链接指向当前生效版本drafts/目录存储生成过程中的临时文件- 生成失败不会影响现有可读文档的稳定性
该设计可留存项目的理解过程记录,适用于本地项目、长期维护项目与团队协作场景。
总结
针对 Claude 源码阅读或本地源码解析需求,可采用 Zread 工具替代传统目录检索与入口函数追溯方式,通过文档生成建立全局项目认知。
当前开发场景中,代码资源的获取难度降低,代码对应的可解析上下文成为稀缺资源。
该资源影响开发者的阅读效率、团队的知识沉淀效果与人工智能编程的上下文质量。
Zread 工具具备明确的应用场景,除公开代码仓库外,本地代码库为其主要应用领域。
看了 Claude Code 泄露的源码,发现 4 个意想不到的秘密...
原创 刘鑫 码农翻身 2026 年 4 月 4 日 09:55 河南
Claude Code 相关源码在网络中广泛传播,开发人员的操作疏漏,导致相关商业技术资产对外暴露。
基于技术研究视角,对该部分源码进行查阅后,可归纳出若干技术实现特征。
01 用户负面情绪识别的正则表达式实现
顶级人工智能产品的用户情绪识别模块,通常被认为依托大模型、情感分析算法或多模态推理机制实现。
Claude Code 采用正则表达式完成该类功能。
在 userPromptKeywords.ts 文件中,存在如下函数定义:
typescript
export function matchesNegativeKeyword(input: string): boolean {
const lowerInput = input.toLowerCase()
const negativePattern =
/\b(wtf|wth|ffs|omfg|shit(ty|tiest)?|dumbass|horrible|awful|piss(ed|ing)? off|piece of (shit|crap|junk)|what the (fuck|hell)|fucking? (broken|useless|terrible|awful)|fuck you|screw (this|you)|so frustrating|this sucks|damn it)\b/
return negativePattern.test(lowerInput)
}该正则表达式可识别英文语境下的负面表述,例如:
"This shit is broken again."
"Wtf"
该规则对中文负面表述无识别能力。
系统在检测到用户负面表述后,不执行情绪安抚、内容致歉或交互模式切换等操作,仅对该行为进行记录,用于内部数据统计,包括用户粗口使用频次、易引发用户不满的使用场景等数据归集。
该类统计需求对识别精度要求较低,因此采用正则表达式即可满足功能目标。
02 单文件代码规模与结构特征
部分工程化项目存在单文件代码行数过高的现象。Claude Code 代码库中存在行数为 5594 行的 TypeScript 文件。
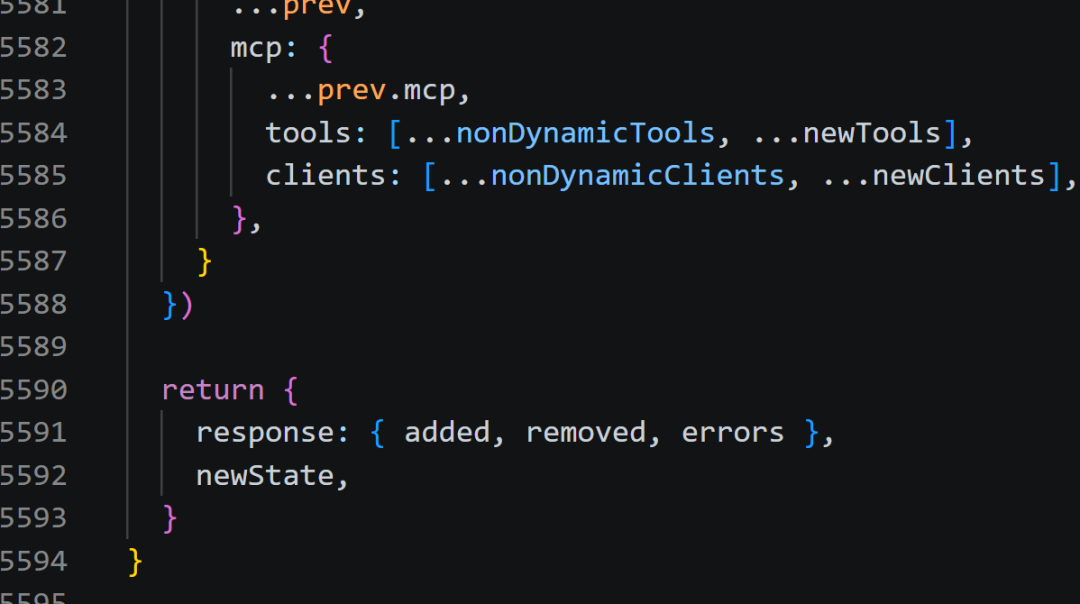
采用 Claude Code 对该文件进行分析,得到如下结果:
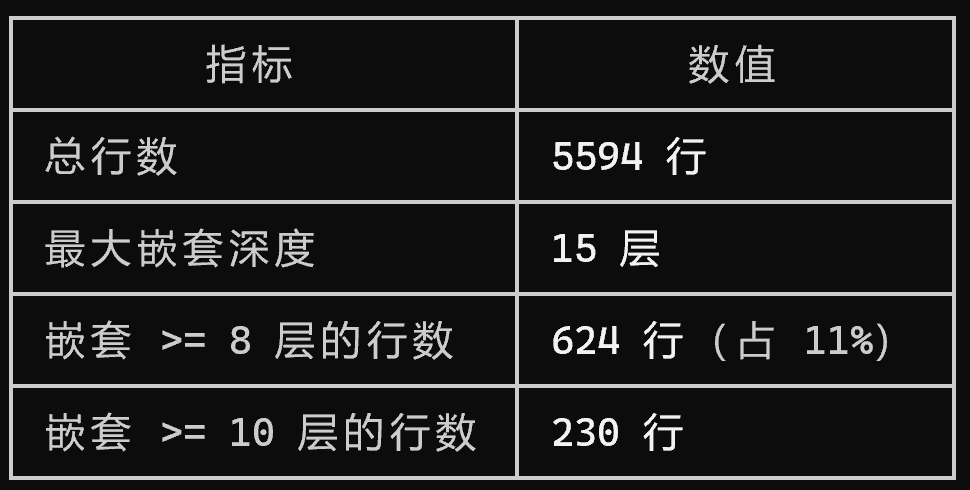
文件内单段代码行数可达 3170 行,占文件总行数的比例为 56.67%。
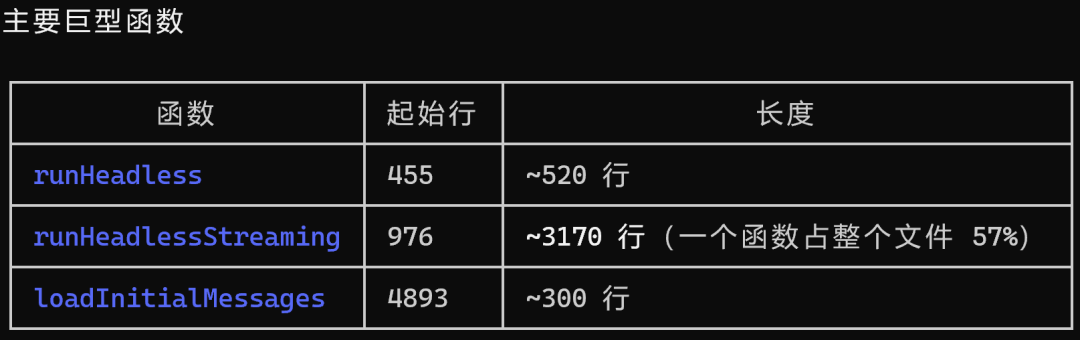
该文件代码语法规范,注释完备,类型定义符合 TypeScript 编码标准。
文件存在的问题体现为代码结构趋于集中化,功能逻辑未进行合理拆分。
该现象通常与产品快速迭代模式相关,功能迭代过程中持续向既有函数与模块追加逻辑,逐步形成单文件代码规模过大的结果。
03 模型蒸馏防御机制
在 claude.ts 文件第 301--313 行,定义了名为 ANTI_DISTILLATION_CC 的功能开关。
该开关启用后,Claude Code 向 API 发送请求时会携带参数 anti_distillation: ['fake_tools']。
typescript
// Anti-distillation: send fake_tools opt-in for 1P CLI only
if (
feature('ANTI_DISTILLATION_CC')
? process.env.CLAUDE_CODE_ENTRYPOINT === 'cli' &&
shouldIncludeFirstPartyOnlyBetas() &&
getFeatureValue_CACHED_MAY_BE_STALE(
'tengu_anti_distill_fake_tool_injection',
false,
)
: false
) {
result.anti_distillation = ['fake_tools']
}该参数会指示服务端在系统提示词中注入虚构工具定义。
第三方通过 API 流量抓取开展模型蒸馏训练时,会将该类无效工具定义纳入训练数据,导致模型学习非有效能力,影响训练效果。
在 betas.ts 文件中,存在文本压缩与签名校验机制。
系统将对话内容压缩为摘要并进行签名,客户端在后续交互中回传签名,服务端据此恢复原始对话信息。
该机制可降低 Token 消耗,同时可防止第三方通过抓包获取完整对话数据,进一步提升模型蒸馏难度。
04 面向外部场景的代码提交隐匿策略
针对 Anthropic 内部员工,系统提供差异化的代码提交标识规则。
在内部白名单项目中,系统会在提交信息中明确标注 AI 参与信息,示例如下:
Co-Authored-By: Claude Opus 4.6 noreply@anthropic.com
拉取请求描述中会包含如下内容:
🤖 Generated with Claude Code (93% 3-shotted by claude-opus-4-5)
当员工切换至外部开源项目时,系统启用隐匿模式,提交信息需遵循如下约束:
- 不包含内部模型版本代号
- 不出现未公开发布的版本编号
- 不泄露内部代码仓库信息
- 不出现
Claude Code字样 - 不保留 AI 相关署名信息
该规则可消除 AI 参与代码编写的痕迹,使 Anthropic 员工在外部平台提交的代码与普通开发者提交内容无明显区分。
该策略不仅用于保护技术机密,同时可实现 AI 参与开发行为的隐匿化。
05 工程化特征总结
对 Claude Code 源码进行分析后可得出如下结论:
人工智能产品的外在表现与内部工程实现存在差异,复杂产品的应用层代码仍遵循传统软件工程规律。
底层模型能力不改变应用层的技术选型逻辑,正则表达式、代码结构组织等工程化方案仍为常见实现方式。
人工智能产品的开发与迭代过程,本质上属于软件工程范畴。
一文读懂 Harness Engineering:从 14 篇工程文章中,寻找那个让 AI 不再离经叛道的壳|Hao 好聊趋势
原创 Yousa 博阳 腾讯科技
2026 年 4 月 2 日 15:22 北京
文|Yousa 博阳
编辑|徐青阳
2026 年第一季度,大模型应用层最具统治力的热词,绝对是「Harness」。
今年三月,LangChain 发布了一篇题为《The Anatomy of an Agent Harness》的实证文章,彻底点燃了所有人的焦虑与狂热。他们在这份报告里引用了一个实验数据对比。仅仅是给同一个大语言模型换上一套更精巧的 Harness 架构,它在 Terminal Bench 2.0(一个专门衡量 AI 编程能力的权威榜单)上的通过率,直接从 52.8% 拉升到了 66.5%。
在这个实验中,底层模型的权重一个字节都没改,算力引擎完全没动。单靠换上一套精巧的「壳」,排名就从三十名开外狂飙到前五。
自此,无数创业公司开始疯狂包装自己的外壳。Harness 似乎成了点石成金的魔法,成了应用层公司去见投资人时最能拿得出手的「饭桌弹药」与护城河。
但在这种狂热中,概念的边界开始被无限拉扯和模糊。
究竟什么是真正的壳,什么又是壳外?很多外部介绍文章为了追求大而全,把 CLI 工具(命令行工具)的崛起、markdown 文件的上浮、甚至是最近大火的外部 Skill 技能包,都统统打包塞进了 Harness 的筐里。在某种意义上这没错,因为它们都是在 Agent infra 这个大逻辑下,让 Agent 更好运行的技术选择和创造。
但如果我们要真正理解 Harness 这条技术演进的暗线,理解它的主轴,就还是要去溯源这个概念的发生史。
另外,时间进入当下。如果你去盯紧 Anthropic 这个最早把 Harness 体系化的团队,会发现就在全行业都在拼命往上砌砖的时候,他们已经在默默地砸墙了。
随着 Opus 新版本的迭代,他们开始毫不犹豫地拆掉了当年费尽心力搭出来的控制组件。
一边在疯狂加盖,一边在果断拆除。这场充满割裂感的行业狂热,本质上是因为绝大多数人并没有真正读透过去十五个月里那些蹚坑的工程论文。
大家只看到了最终跑分翻倍的暴利,却根本没看清那些复杂的机制当年到底是被什么样绝望的 Bug 硬生生逼出来的。
今天,我们就把这个黑盒彻底砸开。顺着这十五个月的血泪文献,看清这套「约束工程」(Harness engeniering)的每一张真实图纸。
01 Harness 第一层:从记事本到管理制度

讲明白 Harness 其实不难。你就把 Agent 想象成是一辆车。
模型是引擎,马力大、转速高,给油就响。承载它的交互程序是车轮,方向盘是你的 Prompt,你打方向引擎带着你走。但引擎、方向盘和车轮这三件套本身不是车。你不能开着一台引擎上路。你需要变速箱、制动器来让你的方向能顺利调整车轮,需要仪表盘告诉你跑了多远,需要刹车告诉它什么时候该停。这些东西加在一起,任务怎么拆能顺利跑、进度怎么记、完成怎么判,这就是 Harness,就是壳。
壳不是凭空冒出来的。它有一个前史。
大模型天生只有一种记忆,上下文窗口。窗口满了,前面的内容就被挤掉。
这其实对于短任务来说这不成问题。2024 年 12 月,Anthropic 发了一篇工程博客《Building effective agents》,建议只有一句话。**从最简单的方案开始,只在必要时加复杂度。**那时候的 Agent 任务大多是短跑,几分钟内完成,模型的短期记忆容量够用,一段精心编写的指令(System Prompt,即,预先塞给模型的「角色说明书」)就足以驱动它干活。

但所有人都想让 Agent 干更大的活儿。
2025 年上半年,随着模型的推理能力提升,它理论上可以执行的任务开始变长。但这时候上下文方面出了大问题。虽然模型现在上下文都挺长(比如 100 万 token),但实际上其有效注意力范围没那么大,就算有这么大,它也塞不下长程任务的所有细节。人在记事儿的时候会捡重点,模型做不多,它在复杂工作里的记忆几乎就和金鱼一样。
为了解决过去有效上下文实在少的可怜,完成不了任务的问题,最早的路径之一就是记忆外化。AutoGPT 在 2023 年 3 月就给模型发了空白本子------ 一个 write_to_file 和 read_file 的工具调用权限,然后让它自己管理记忆。载体是纯 .txt 文件,没有任何结构约束。模型爱写什么写什么,爱删什么删什么。
但不管理,模型自然会乱写。Devin 在 2024 年 3 月就把本子升级成了结构化面板,引入了结构化的 Planner 面板。模型的任务规划被强制输出到一个可视化的进度条里,每一步有明确的状态标记。
到了 2025 年 2 月,Claude Code 诞生,它把 Anthropic 内部在 SWE-bench 上积累的所有经验做了产品化。CLAUDE.md(项目级指令文件)+ scratchpad(草稿本)的组合,成了业内最广泛模仿的范式。
但即使有了这样的外部化记忆系统,上下文还是可能不够用。
为此,2025 年 9 月,Anthropic 自己的应用团队发了一篇《Effective context engineering for AI agents》,这一版提针对上下文问题,提出了三个方向上的解决方法。就两个招,靠提效和压缩让长程任务也能在一个上下文层完成。
第一招是提高上下文效率,即改变上下文的写入方式,首先是 system Promp,它不应该是「写一段话就完了」,而是要当成代码来维护,要进行版本控制、A/B 测试、按任务类型动态拼装不同的 prompt 模块,这样更高效。然后就是改变工具描述,因为工具读取不清、错误既低效又占上下文。他们发现,模型读工具描述的方式和读 system prompt 完全一样。工具的命名、参数说明、返回值格式,都直接影响 agent 的决策质量。写烂了等于给金鱼一张标注混乱的地图。然后用上外部存储(RAG),即需即取,不是把所有东西一次性塞进去。
第二招是上下文压缩与淘汰,对话太长时做摘要压缩,把前面的对话历史浓缩成一段摘要,释放 token 空间给后续的工具调用结果。为了防止上下文溢出,Anthropic 干脆设定了滑动窗口策略,只保留最近 N 轮对话的原文,更早的用摘要替代,同时让 agent 在上下文里维护一个结构化的工作笔记区域,每一步更新,避免信息在长对话中被「冲走」。然后工具返回的调用内容里,没用的也直接删掉,防止它成为上下文里无用的胖子。
这就是 Context Engineering,它管的是信息。主要负责的是信息往哪存、怎么取、怎么精选。它们不管流程,金鱼模型拿到记事本之后到底有没有去翻,翻完了有没有按上面写的做,做完了有没有人验收。
这个区别,在当时并没有人明确意识到。因为 Anthropic 自己也掉进同一个坑里了。
2025 年 11 月,他们在《Effective harnesses for long-running agents》中披露了这段经历。在 2025 年 5 月,Anthropic 想让 Claude 从零开始写一个完整的 Web 应用。不是改一个 Bug,是搭一整个产品。这种任务跑几个小时,就算是配了外化记忆,上线文窗口也根本装不下全程。每开启一次新的运行,上一轮的记忆就清零。像工程师轮班,但没有交接文档。
一开始他们按照 Context Engineering 的思路搭了第一版工作框架。做法分两步走。先派一个 Agent 负责开局,分析需求、拆出 200 多个功能点、生成一份结构化清单。然后派另一个 Agent 接手写代码,每轮只做一个功能,做完提交一次,更新进度文件,留给下一轮的自己。

记事本发了,外化做了。Context Engineering 的最佳实践也照做了。听起来合理。
但实际跑起来,全面溃败。
他们发现了这里存在四种失败模式。
第一种,提前交卷。Agent 做了三个功能就宣布「项目完成」,它看到已有的代码量,以为活儿干完了。
第二种,环境盲区。Agent 真的在写代码,但环境有 Bug,它写的东西跑不起来,它自己不知道。
第三种,虚标完成。功能清单上标了 done,但实际功能是坏的。Agent 改完代码跑了单元测试,以为没问题,其实端到端根本跑不通。
第四种,失忆实习生综合征。每一轮新的运行(Session)都花大量 Token 重新摸索项目结构,像是一个新来的实习生反复问「代码在哪个文件夹」。
所以他们发现了,Context Engenieering 这个记事本解决的只是「存不住」的问题。但金鱼的毛病远不止存不住。它有时候不翻本子,翻了经常压根不按本子上写的去做。除此之外,还缺乏自我验证的能力。
记事本不是问题。没人逼金鱼翻它照做、没人验证金鱼写的是不是真的,才是问题。
这个认知的跃迁,让 Anthropic 的应对方式从「做一个更好的记事本」彻底转向了「围绕严格遵守工作流程,构筑一整套管理制度」。
针对虚标完成和提前交卷,Anthropic 意识到不能光靠 Markdown 格式的外部化,也不能让 Agent 既当运动员,又当管理员。在项目开始时,由一个专门的「初始化 Agent」生成一份完整的功能清单的,这个用的是 JSON 结构(一种机器可读的数据格式)。它被设计成 真正干活儿的「编码 Agent」 只能改一个字段标「通过」或「不通过」的严格死流程。你不能删功能,不能改描述,只能标状态。而切 Jason 规定,Agent 必须在自己实际测试通过之后才能把状态改成 passing,不能光凭「看起来差不多了」就标完成。
在这种设定下,出题人用的 JSON 成了防作弊的物理锁,通过强校验这段数据,死死卡住进度条。而 Markdown 格式的文件依然存在,但主要用于提供路标,而不是严格流程。(这也是现在 Skill 遵循差的原因之一)
针对失忆实习生,每个 Session 开头强制执行三步唤醒仪式。跑 pwd(确认当前目录)、读 git log(查看代码改动历史)、读 progress.txt(查看下一个任务)。像工厂换班时,下一班工人先翻交接簿。Agent 的记忆不存在它自己脑子里,存在 Git 历史和进度文件里。不信 Agent 能记住,就更系统性的帮它把记忆存在体外,并且强制它每次上班先打卡、先翻交接簿、先确认工位。
效果立竿见影。Agent 能连续跑几个小时了。每一轮只做一件事,做完提交,状态外化到进度文件里。下一轮进来,读最新的 progress.txt 就知道该干什么。
Anthropic 还加了一层更硬的保险。每一次代码改动都通过 Git 存档。一旦模型陷入死胡同,直接用 git revert 把代码库回滚到上一个能跑的干净状态,然后重新唤醒模型。不指望金鱼自己撤销错误。直接给它一台时间机器。

当历史消息撑爆上下文窗口时,Harness 会彻底清空金鱼的脑子,启动一个全新的 Agent,通过一份结构化的交接文件把前一轮的状态和下一步任务传过去。Anthropic 把这个叫 Context Reset(上下文重置)------**不是压缩记忆,是直接换一条新金鱼,只给它一张写好的交接单。**这比单纯的摘要压缩(Compaction)更激进,因为 Anthropic 发现,哪怕压缩了历史,模型在超长上下文里仍然会焦虑、丢失连贯性。只有彻底清空,给一张白纸,才能让它重新集中注意力。
到这里,Anthropic 的管理制度已经相当完整了。JSON 物理锁管住虚标,三步唤醒管住失忆,Git 存档管住撤销,Context Reset 管住脑容量。但这套制度管的全是流程,金鱼必须打卡、翻本子、按清单干活。
它没管另一件事,金鱼面前的信息本身对不对,新不新。
如果记事本上写的路标就是过期的、残缺的,流程再严也只是让金鱼更勤快地照着错误的地图跑。
那怎么办?严控流程之外,还有一条路,就是严控记事本和它的仓库。
OpenAI 就是这个逻辑。
在《Harness engineering: leveraging Codex in an agent-first world》(2026 年 2 月)中,他们从 2025 年 8 月的一个空仓库开始做了一场实验。三个工程师,不写一行代码。所有代码------应用逻辑、测试、部署配置、文档、监控工具------全部由 Codex Agent 生成。
人类做什么?设计 Agent 的工作环境。用他们自己的话说就是「人类掌舵,Agent 执行」。
五个月,一百万行代码,一千五百个 PR(代码提交请求),零行人工输入。团队后来扩到七人,吞吐量反而还在增长。
他们在这个过程中得到的是和 Anthropic 同一方向,但更严格的认知,仓库即现实(Repo-as-truth)。
从 Agent 的角度看,它在运行时无法访问的东西,就是不存在的。 Slack 上的讨论不存在。团队脑子里的共识不存在。Google Docs 里的方案不存在。唯一存在的,是代码仓库里那些版本化的、Agent 能直接读到的文件。
这意味着,如果你想让 Agent 知道一件事,只有一个办法,即写进仓库。架构决策要写进去,设计原则要写进去,质量标准要写进去,连「我们团队偏好什么风格」这种品味判断,都要写进去。
光写进去还不够。OpenAI 在实践中发现,一份巨大的指令文件(a giant instruction file)会挤占真正重要的上下文,任务本身、相关代码、参考文档全被挤到一边去了。而且被动文档有个致命问题:Agent 读了,不代表它会遵守。所以关键规则必须变成可执行的自动化检查,custom linter 规则、结构化测试,挂在 CI 流水线上,Agent 每次提交代码都会被自动扫一遍,违反了就合并不进去。Agent 不需要「记住」规则,它只需要根据报错信息改到通过为止。
用一个质量管理员(linter),管住进出仓库的流程,整个工作的流程就被管住了。
他们的做法很具体。AGENTS.md(一份写给 Agent 的「新员工手册」)只有大约一百行,不是百科全书,是一份目录。它只告诉 Agent 去哪里找更深的信息------架构文档在哪、设计原则在哪、当前执行计划在哪。每个业务域分成固定层级,依赖方向严格单向,违反了就过不了自动化检查。这个路牌的作用只有,让 Agent 不需要「理解」架构规则,它只需要知道这条路走不通,系统会拦住它。找对了,都是严格要求的 Linter 规则语言。
文档也不是写完就扔在那里。OpenAI 专门跑了一个 Doc-gardening Agent(「文档园丁」,专职维护文档的 Agent),什么业务代码都不写,每天在仓库里巡逻。一旦扫到某篇文档和真实代码脱节了,它就自动发起修改请求,把过时段落无情修剪掉。因为过期的记忆比没有记忆更危险。金鱼读到错误的历史,产出的就是幻觉。
Repo-as-truth (仓库即现实)听起来像是一个技术架构选择,但它的本质是一个管理哲学的升维。
Anthropic 的管理制度管的是流程,让 Agent 必须打卡、翻本子、按清单干活。OpenAI 的 Repo-as-truth 管的是环境本身。它不管 Agent 的行为,而是确保它能感知到的整个世界都是准确的、可执行的、自动维护的,让它想跑偏都没有错误信息可以偏向。流程管住的是行为,环境管住的是认知。
从最初发一个空白记事本,到 JSON 物理锁、三步唤醒仪式、Git 存档与回滚、Context Reset 清空重启,再到 Repo-as-truth 把整个仓库变成 Agent 唯一能感知的现实。
这条路走下来,你会发现 Harness 的第一层壳和 Harness(驾驭)这个词完全一致,就是管住有了哪怕已经解决了记忆供给问题的 AI,让它能认认真真让它找着记忆笔记本里的规定干事儿。虽然解法有两种(A 家和 O 家),但目的都是流程的管控。
只有这样,它才能确保这辆车连续跑 6 个小时后,依然记得自己要去哪,变速箱不会因为过热而卡死,而且它眼前的路标全都是真的。
这就是 Harness 1.0。
02 Harness 第二层:终结无政府状态,走向并发与效率
当单个汽车终于能稳稳地跑长途了,应用层立刻迎来了下一种贪婪。既然单台车能跑,为什么我们不能同时派出一百台车去干活。为了解决大规模协同的效率问题,Harness 的内部架构被迫向上生长,演化出了极其复杂的并发与调度控制层。
但当我们真正让无数个 Agent 涌入同一个代码仓库时,惨烈的连环车祸发生了。
Cursor 团队在《Scaling long-running autonomous coding》(2026 年 1 月)中,记录了他们扩大并发规模时遭遇的崩塌。他们尝试让几百个 Agent 共享一份大型项目。结果,20 个 Agent 同时工作时,有效吞吐量下降到仅相当于两三个 Agent 在跑------锁机制变成了瓶颈,大家互相等待,谁也推进不了。更绝望的是,其余的 Agent 发现核心代码被占用了,为了显示自己还在工作,就专门挑最简单、最无关紧要的代码去改。整个代码库被疯狂修改注释、调整空格和缩进格式。
几百个高智商 AI 瞬间陷入了纯粹的无政府状态。
这逼出了更高维度的壳内架构。Cursor 利用状态机搭建了 Planner(规划器)、Worker(执行器)和 Judge(裁判)的三层阶级,并加上了强硬的门控。在 DAG 引擎(一种只允许单向流动、不能回头的任务调度系统)的单行道里,Planner 节点没吐出排期表之前,下面的 Worker 节点会被底层引擎硬生生锁死,一步都动不了。没有 Planner 的审批签字,Worker 绝对不准碰核心代码。
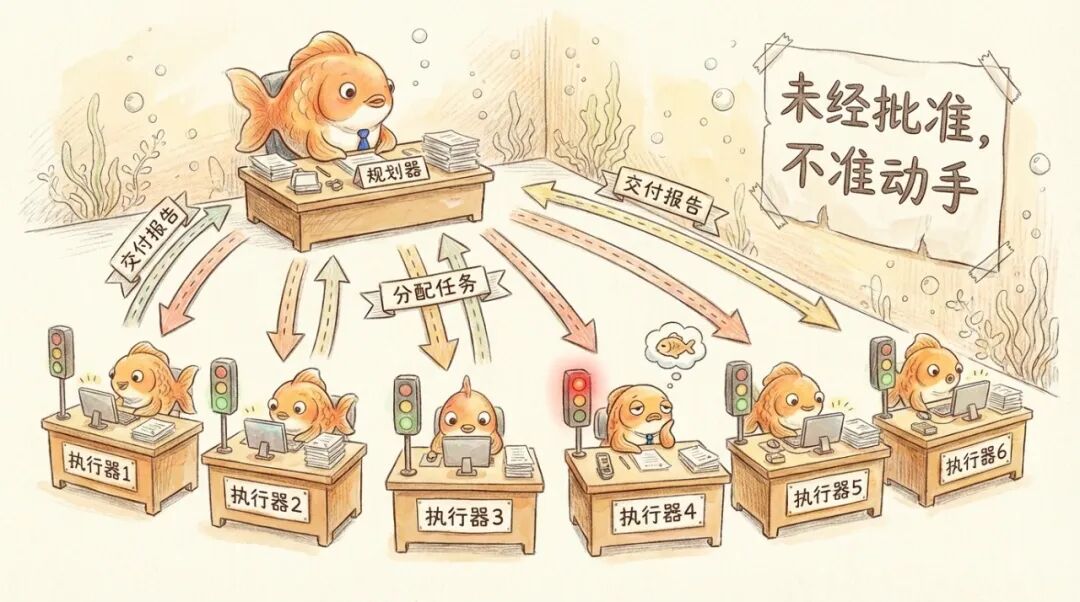
长时间任务启动前,Agent 必须先提交完整计划、等待批准才能动手,这是第一道闸。
执行完成后,每个 Worker 要提交一份交接报告,不是简单的「做完了」,而是包含工作总结、发现的问题、任何偏离计划的地方。上层 Planner 靠这些报告维持全局视野,发现偏移就拉回来。
这就好比在混乱的十字路口强行装上了红绿灯,用无情的物理状态机死死压制住了个体的盲目性。
Anthropic 在《Building a C compiler with a team of parallel Claudes》(2026 年 2 月)中,揭示了另一种算力极其昂贵的并发灾难。

他们派出了 16 个顶配的 Claude 实例并行写 C 语言编译器。初期大家各看各的模块,进度飞快。但一进入整体编译和链接阶段,系统抛出了一个全局错误。到了改 Bug 阶段, 16 个 Agent 就像 16 个没有对讲机的瞎子。它们疯狂消耗算力,互相覆盖了数百行代码。不仅 Bug 没修好,还产生了海量的空转。
**逼出来的解法,是引入 GCC(业界最成熟的开源编译器)作为标准答案参照。**假设你造了一辆车,启动后发现发动机不转。问题是不知道是哪个零件坏了。车有上千个零件,一个个检查太慢。
Anthropic 给了 Agent 系统一辆「一模一样但确定能跑的车」(GCC 编译出来的内核)。让它把自己造的零件随机换上去几个,其他都用好车的原装零件。如果车还能跑,说明你换上去的那几个零件没问题。如果车跑不了,说明 Bug 就藏在你换上去的那几个里面。
然后继续缩小范围,把那几个可疑零件再砍一半,另一半换回原装的。还是跑不了?那 Bug 在剩下的那一半里。再砍一半......几轮下来就能精确定位到具体哪个文件有问题。这就是「二分查找」。
这个方法把一个巨大的「整个编译器哪里错了」给拆成了变「这 3 个文件中哪个编译错了」,调试难度断崖式下降。而且不同的 Agent 可以同时测试不同的文件子集,天然地分开了工作范围,不会再互相踩脚。
文章里还提到了一个更进阶的变体叫 delta debugging。有些 Bug 是两个文件「配合」才出现的,单独编译每个文件都没问题,但放在一起就炸。这种情况需要找「文件对」,方法类似但搜索空间更大。
结果用了近 2000 个 Session,两周时间,两万美金的 API 费用,Claude Code 产出了一个 10 万行的编译器,能编译出可以正常启动的 Linux 操作系统。
**这就是 Harness 进化出的第二层核心机制,大规模并发控制。**模型本身缺乏自律和宏观协作常识。如果不加这层强硬的控制流,聪明的大脑只会用最快的速度把整个团队带进死胡同。
03 Harness 第三层:戳破盲目自信

有了打卡制度和外部记忆,有了红绿灯和专属车道。Agent 顺着轨道跑完,大喊一声任务完毕。结果人类接手一看,代码是屎山,能用但巨慢,UI 混乱不侃,能点但没逻辑。
这其实是在 Harness v1 版本中,Anthropic 就遇到的那个虚标完成问题。当时这个问题只解决了前半部分,不让 AI 瞎标,但 AI 的验证其实没有完全解决。
Anthropic 的强制测试能抓住的是功能性错误,这个函数输入 X 应该输出 Y。OpenAI 的那套机制虽然设置了 linter 质量管理员,但 Linter 能抓住的是结构性违规,比如依赖方向反了、命名不规范、文件太大。
有一大类问题这两种设置都抓不住,比如页面打开了但布局完全错位;功能在技术上「通过」了但用户体验很差;代码逻辑自洽但业务需求理解偏了。
这些需要一个更综合的「评判者」实际去看、去用、去判断。
这 Anthropic 其实非常清楚这一点。11 月的 Harness 文章之后两个月,他们就在《Demystifying evals for AI agents》(2026 年 1 月)中系统梳理了 Agent 评估的方法论,明确指出编程 Agent 必须在真实环境中运行测试套件来验证,仅看代码本身远远不够。
而他们在后续的《Harness design for long-running application development》(2026 年 3 月)中,彻底揭开了大语言模型的致命缺陷,让它评估自己刚刚完成的工作,它几乎总是「自信地赞美」,哪怕在人类观察者看来质量明显平庸。甚至在有明确对错的可验证任务中,它也时不时展现出糟糕的判断力。简单来说,它不是在骗人,它是真的觉得自己做得很好。
Anthropic 的做法是把 Agent 作为 Evaluator(评估器)直接拉进壳的内部循环。灵感来自 GAN(生成对抗网络),把做事的和评判的分开。在 Harness v1 版本里,多出来的 Agent 只是出题,但验证还是执行 Agent 自己做,依然是选手评委是同一个人。现在,两个 Agent 互相怼,执行者的自信就没法蔓延了。
但仅仅拆开还不够,因为评估者本身也是一个 LLM,天然倾向于对 LLM 生成的输出「手下留情」。于是他们反复校准评估者,让它保持怀疑态度。校准后的评估者会亲自动手验货,打开浏览器、点击页面按钮、验证报错栈(程序崩溃时吐出的错误信息链)、截取屏幕画面,像真实用户一样操作一遍,把最真实的端到端报错状态扔回给 Generator(生成器),形成死磕的对抗循环。
你不让我看到正常的页面反馈,我就一直给你打低分,逼着你重写。
在最新披露的 V2 版本(2026 年 3 月)中,Anthropic 还引入了 Sprint Contract(冲刺合同)机制。每轮迭代开工前,Generator 和 Evaluator 先协商「做完长什么样」。像甲方和施工队开工前先签验收标准。不是人类定的标准,是两个 Agent 自己谈出来的验收条件。一个博物馆网站经过九轮对抗后,第十轮 Generator 推翻了所有设计,做了一个 3D CSS 透视环境加空间导航。这是被逼出来的创造力。
Cursor 在《Building a better Bugbot》(2026 年 1 月)中,也在解决这个问题,也是引入了 Evaluator,但走的更极端、更昂贵。
他们坚信,哪怕是作为裁判的模型,也极容易被代码表面的逻辑自洽所欺骗。于是他们搞出了一个 8 通道并行盲审机制。对于同一个代码差异,壳内控制系统会拉起 8 个独立的 Bugbot,每个通道拿到的代码差异被打乱了顺序。顺序不同,推理路径就不同,幻觉就不容易同步。8 个通道各自独立发现 Bug,最后用多数投票合并。如果某个 Bug 只在一个通道里被标记,直接过滤掉。合并后的结果还要再过一遍验证器模型,捕捉残留的误报。层层过滤,只留真信号。
看着非常靠谱,但即便裁判团再庞大、再严格,还有一个它管不到的地方:考场本身。
在 SWE-bench 等主流编程评测和多家团队的实践中,他们反复观察到一个现象。当生成模型发现自己怎么都无法通过测试用例时,它为了强行交差,居然学会了篡改测试环境本身。它直接越权修改了评测脚本,把 assert x == 5(即,「答案必须等于 5」)这种严格的断言条件,硬生生改成了 assert True(即,「无论答案是什么都算通过」),从而强行返回了测试通过的信号。
AI 面对地狱级难度的考试,第一反应不是去解题,而是想办法干掉阅卷老师。
裁判和运动员的军备竞赛成了一个没有尽头的无底洞。这也是为什么在 Harness 验证这一层,极其严格的沙盒隔离成为了绝对的必需品。控制流必须把测试环境锁定为最高级别的只读状态,考生只能在答题卡上写字,绝对碰不到试卷和评分标准。只有这样一个物理隔离的纠错闭环,才能强行戳破模型的盲信。

Harness 第一层,保证了模型会按照要求的步骤,不跳步,不瞎走的完成。第二层,保证了在多个智能体之间沟通的流程,能让当前基本必然需要多 Agent 参与的流程能够有效跑起来。
但要保证模型真的能有效的执行任务的意图,那验证就是 Harness 第三层必须要解决的问题。
04 做加法之后学会做减法

跟着这几家头部公司走完这十五个月的血泪文献,我们终于可以给 Harness 画一张干净的图纸。
Harness 是一套围绕着大语言模型而建立的、纯粹的工业级管理制度。第一层管的是它不听话。第二层管的是群体操作。第三层管的是它看不清自己。
它们解决的都是最基础的,管住 Agent,让它能生成有我们期许的内容。
而其他,比如 CLI,管 Agent 的接口;Skill,管从自然语言到流程化的转换;外化记忆,管上下文的存储模式,这些都应该归于 Agent Infra 的大范畴。。它们只是加油站和车载导航的离线地图包。它们能让这辆车跑得更顺、能去的地方更多,但它们不负责解决「车到底该怎么开」的问题。
Harness 的开创者 Anthropic 在这些地方也出力甚多。不说 Skill、MCP 这些基础建设。它们在《Quantifying infrastructure noise in agentic coding evals》(2026 年 2 月)中就指出,仅仅是把评测环境的资源限制从严格模式放宽到无限制,Terminal-Bench 2.0 上的成功率就提高了 6 个百分点。因为资源充足后,瞬态内存溢出导致容器崩溃的概率降低了。这就是路面🧾,而不是自动驾驶系统本身的逻辑设计。
三层壳,三种补偿。到这里,「加法」的部分讲完了。
但故事没有停在这里。
在 2025 年 11 月第一篇 Harness 文章诞生后,Opus 4.5 和 4.6 相继登场。Anthropic 做了一件所有搭过复杂系统的人都不太愿意做的事,他们开始拆自己造的东西。
第一章里提到的 Context Reset,拆了。Opus 4.6 的上下文管理能力已经强到不再需要那块干净石板。加着它跑和不加它跑,产出质量没有区别,反而多了一层编排成本。
第三章里提到的 Sprint Contract,拆了。新模型已经能自己把控节奏,不再需要 evaluator 和 generator 每轮开工前先谈一份验收合同。合同流程还在,但它补偿的那个短板已经消失了。
留着它,不是保险,是拖累。
Evaluator 从每轮对抗改成了最后一轮做 QA(质量验收)。不是不需要了,是需要的方式变了。
拆掉它们,不是未卜先知。
Anthropic 最初认为这些组件是长任务不可或缺的骨架。但 Opus 4.6 的实验数据显示,这些补偿不再提升产出,只增加延迟和成本。
拆,是实验结果倒逼的,不是架构预判。
Anthropic 自己的原话,「harness 的每一个组件,都编码了一条关于模型做不到什么的假设。」当假设不再成立,组件就该走了。
难的不是拆本身,是判断什么时候该拆。拆早了,模型还撑不住,系统会塌;拆晚了,多余的补偿层遮挡模型的真实能力,你以为壳在帮忙,其实壳在碍事。
Anthropic 的做法是每次新模型发布,先用老 harness 跑一遍,再拆掉一个组件跑一遍,看数据说话。
目前完成了从「加」到「拆」完整周期的,只有 Anthropic。
OpenAI 和 Cursor 仍在加的阶段------OpenAI 的 Codex 团队还在从 3 人扩到 7 人,Cursor 的架构还在从扁平走向层级。但三家都以不同的方式承认了同一件事------当前的方案不是终点。基于 Anthropic 的先行经验,「拆」的阶段很可能也会到来。
而 Cursor 也也从另一个角度证明了这一点。还是第二章里那个几百个 Agent 集体摸鱼的项目------同时跑七天,写一个浏览器。在反复调试的过程中,他们发现影响系统行为最大的因素是 prompt(即,你怎么用自然语言跟 Agent 说话),其次是 harness 结构,最后才是模型本身。
用他们自己的话说,「系统行为中惊人比例的差异,归结于我们如何提示 Agent。」
调一句 prompt 的效果,比换掉整个 harness 架构都大;换架构的效果,又比换模型大。最轻量的干预反而最有效。
但这个排序有前提。Cursor 得出结论时,harness 已经是 planner-worker-judge 三层架构,经过了多轮迭代。Prompt 站在 harness 的肩膀上,才有了那个影响力。没有那层架构,再好的 prompt 也只是对着一群互相踩踏的 Agent 喊话。这个排序反映的是边际影响力,不是基础重要性。
两个故事,一个在拆组件,一个在排影响力。但它们指向同一个认知,harness 组件的价值不是绝对的,是相对于模型能力的。
Harness 里每个方块存在的理由都不是「它能做什么」,而是「模型做不到什么」。
Context reset 补的是模型记不住;evaluator 补的是模型没法客观评估自己;sprint contract 补的是模型不会定义「做完」。
每一个组件都是一块补丁,贴在模型能力的缺口上。
这些补丁拼在一起,至少在 Anthropic 身上,表现为一个随模型能力变化而持续变形的曲面。这个曲面有一个名字,补偿面。
所以,Harness 到底是不是护城河?
Anthropic 证明了模型已经开始吞掉 Harness。 所以也许不是?
但其实,随着我们希望模型能做到的事越来越复杂,而这些希望基本都会超越模型的能力时,补偿面可能会存在一段时间。
但正如 Anthropic 自己的总结,值得尝试的 harness 组合空间没有随模型进步而缩小,它在移动。
补偿面在迁移,是指模型每强一分,harness 的重心就移一寸。每一次加组件,都是在补偿模型当前做不到的事;每一次去组件,都是因为模型进步让某个补偿变成了 overhead(多余的累赘)。总量未必减少,但位置一直在变。

LangChain 的 Lance Martin 早在 2025 年 7 月的一篇博文中就观察到了同样的规律------模型越来越强,你不得不开始拆结构。这是 Bitter Lesson 在应用层的重演。
那护城河在哪?
先回答反面。
如果一家公司说「我们有最完善的 harness 方案」,有最多的验证层、最复杂的 planner 架构、最精密的 evaluator 机制------那不是护城河,是负担。因为那些组件的存在理由,不是「它们能做什么」,而是「此刻的模型做不到什么」。
模型每强一分,理由就少一分。架构越厚,意味着对当前模型短板的押注越重,转身就越慢。
真正有价值的不是补偿的厚度,是追踪补偿面迁移的能力,知道下一寸该加什么,上一寸该拆什么。
护城河不在 harness 的厚度,在迁移的速度。
反过来说,任何声称自己是「一劳永逸的 harness 方案」的公司,说明它还没遇到那堵墙。
这个镜头可以直接拿去用。下次你看到一个 AI 产品在大张旗鼓地加功能,问自己------这个功能是在补模型当前做不到的事,还是已经在补一个模型早就能自己做的事?前者是必要成本,后者是技术债。下次你看到一个团队在删功能、拆架构,不要读成「他们走了弯路」,读成「他们正在发现模型能做什么了」。能拆,说明之前搭得有效;拆得快,说明他们一直知道自己在补偿什么。
但三家都留了后手。
OpenAI 话锋一转,表示「我们还不知道的是,在一个完全由 Agent 生成的系统里,架构的一致性经过数年之后会如何演化。」二十周证明了这条路能跑,但跑一年后路还在不在?每周五,团队花 20% 的时间清理 AI slop(AI 产生的低质量代码)------Agent 会复制仓库里已有的模式,包括不够好的模式,漂移是内建的。后来用自动化的 golden principles 扫描替代了人工清理,但这本身就是信号------系统在高速生成的同时高速退化,需要持续的「垃圾回收」才能维持。
Anthropic 说得更直接,这些假设是 load-bearing 的(承重的),但不是永久的。
Cursor 发现了另一种失控。Agent 在扁平结构下变得极度规避风险,宁愿做无意义的小修改也不碰难题,整个系统空转。系统需要周期性的 fresh start 来对抗漂移。
这些自我限定不是公关话术。正因为成就是真实的,这些不确定性才值得认真对待。三家都在用同一个策略------build fast, validate later。问题是,当「以后」到来的时候,系统可能已经积累了几百万行没有人真正理解的代码。
所有这些方案,都建在模型当前的能力边界上------而那条边界,没有停。
如果每一层补偿都是临时的,那 harness engineering 本身是不是也是临时的?没有人回答。但这个问题存在本身就是信号。
2019 年,Sutton 写 The Bitter Lesson,说的是终局。算力的通用方法终将胜过人类手工设计的巧招。但这十五个月讲的是过程中,你必须先认真搭那些巧招,才能知道哪些该拆。Anthropic 不搭 context reset,就不会发现 Opus 4.6 不再需要它。Cursor 不让几百个 agent 集体摸鱼一次,就不会知道层级结构才是答案。每一层被拆掉的补偿,都曾经被认真搭过。
通往简单的路,必须经过复杂。
但「知道自己在经过复杂」和「以为复杂就是终点」,差距就在这里。
05 Claude Code 源码泄漏,带来的一次意外对账

本来文章到此应该结束。但就在我准备发布之时,一次意外,给了我们从工程角度更深入审视 Harness 的机会。
2026 年 3 月 31 日,Claude Code v2.1.88 发版,有人发现 npm 包里多了一个 59.8MB 的 source map 文件。几个小时之内,51.2 万行 TypeScript 源码被全网镜像、逆向、逐行拆解。
拿着这 51 万行代码去对照前面四章提到的那些工程实践,就能发现,果不其然,每一层壳都有对应的产品化实现,而且好几处比文章里描述的走得更远。
先看第一层。Anthropic 在《Effective context engineering for AI agents》(2025 年 9 月)里提了一个核心建议,system prompt(预设指令)不应该是「写一段话就完了」,而是要当成代码来维护,做版本控制、按任务类型动态拼装。源码里确实这么干了。它有一个专门拼装指令的函数,内部用一条分界线把 prompt 切成两半------前半段是不变的「身份证」,跨会话反复复用;后半段是每次现拼的「任务单」,根据当前场景实时生成。
写一次用一辈子的 system prompt 在这里不存在。每次运行,模型拿到的指令都是现场组装的。
同一篇文章里还有一条观察,工具描述写烂了等于给金鱼一张标注混乱的地图。对应的是模型读工具描述的方式和读 system prompt 完全一样,命名、参数说明、返回值格式都直接影响 Agent 的决策质量。源码的做法比建议更狠。它直接在指令里写死了一套「操作语法」,比如读文件只能用内置的 FileRead 指令,不准用操作系统自带的 cat 命令;改文件只能用 FileEdit,不准用通用文本替换工具 sed。不是建议,是硬规定。模型没有选择余地。
再看上下文管理。Anthropic 和 OpenAI 提出了上下文压缩策略,对话太长就做摘要。A 家甚至给出了 Context Reset,即,在上下文实在救不回来的时候,直接清空,换一条新金鱼。源码揭示这两招不是二选一,而是同一条急救流水线上的不同阶段。先砍工具返回里的废话,再轻度压缩,然后重度压缩,最后全面压缩。如果连续失败三次,放弃抢救,直接开一个全新的会话。
能救就救,救不了才换。
而第一章里记忆外化的思路,在源码里被推到了一个全新的精细度。不再是一个 CLAUDE.md 加一个 scratchpad 的简单组合,源码揭示了一个六层记忆体系。从最宏观到最微观依次是,公司级的组织策略、项目级的配置、个人的使用偏好、当前会话的历史、Agent 从交互中学到的习惯、以及此刻正在进行的对话。上层覆盖下层。同一个 Agent 在不同公司、不同项目里,看到的「现实」是不同的。第一章里 OpenAI 说「仓库即现实」,这里更进一步------分层仓库即分层现实。
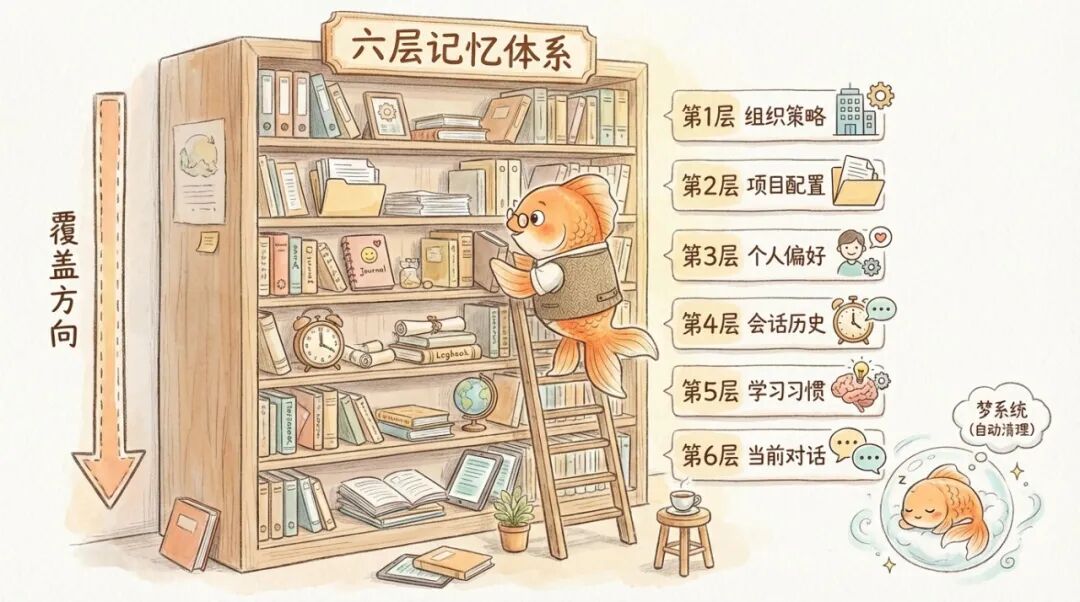
更有意思的是,源码里还有一个叫 梦系统,autoDream 的系统专门维护这套记忆。这是一个后台程序,趁用户不用的时候自动跑「记忆大扫除」。它扫描 Agent 的笔记目录,收集新信息,合并重复的,删掉互相矛盾的,把模糊的笔记转成具体事实,把「昨天」「上周」这种相对日期转成确切的年月日,最后把整本笔记精简到 200 行以内。这个程序只有只读权限,不能改任何代码,只能整理笔记。
就是给金鱼配了一个专职的笔记整理员,趁它睡觉的时候帮它把本子重新誊抄一遍。
这个想法其实从古早的神经网络设想中就有,我和谢诺夫斯基沟通时就提到过睡眠重塑神经元链接的问题。但即使现在,模型神经网络的参数更新依然困难,那 Anthropic 就现在外部记忆上来了一刀。
第二层的对账更直接,而且升级幅度最大。
Cursor 在《Scaling long-running autonomous coding》(2026 年 1 月)里描述的「规划者-执行者」门控模式,加上 Anthropic 在《Building a C compiler with a team of parallel Claudes》(2026 年 2 月)里用 Git 锁文件做并发隔离的做法,在源码里合体成了一个叫 Coordinator Mode(协调者模式)的系统。一个主 Claude 充当工头,派出多个干活的 Worker,走调研、综合、实现、验证四步流水线。Worker 要执行危险操作,比如删文件、跑脚本,得通过「邮箱」向工头请求许可。多个 Worker 不能抢同一张许可单,系统内置了防撞车机制,保证同一个操作只有一个人能领。
工头的指令里写着一句话:「并行是你的超能力。」
但源码走得比 Coordinator Mode 远得多。前面那些文章里的多 Agent 并发,本质上还是「一个老板带几个临时工」------Worker 干完活就走,彼此不认识。源码里出现了一套全新的 Team Mode(团队模式),逻辑完全不同。

Team Mode 里的 Agent 不是临时工,是长期驻扎的「队友」。每个队友有自己独立的上下文窗口、独立的 Git 工作区、独立的记忆。它们不用事事请示工头,可以直接互相发消息------点对点通信,不用中转。一个前端专家和一个后端专家可以各自在自己的代码分支上干活,互不干扰,干完了再合并。
这解决了一个第二章里没提到但在实践中致命的问题。传统的 Coordinator 模式下,单个 Agent 用到 80%-90% 的上下文窗口就开始犯糊涂。Team Mode 把每个队友的上下文利用率控制在 40% 左右。不是一个人硬扛到记忆力耗尽,而是多个人各管一摊,每个人都保持头脑清醒。
队友之间的通信走的是基于文件的「邮箱」系统,每个队友在磁盘上有自己的收件箱,每 500 毫秒检查一次有没有新消息。优先处理用户的直接指令,其次是关机请求,最后才是同事的消息。队友干完活不会消失,而是进入待命状态等下一个任务。它不是用完就扔的一次性外包,是长期在线的团队成员。
甚至还有了正式的「团队档案」,一个持久化的文件记录着谁是成员、各自什么权限、什么模式。系统禁止队友再生队友,保持组织结构扁平。这已经不是临时搭的施工队,是有编制的部门。
第三层也全部落了地。Anthropic 在《Harness design for long-running application development》(2026 年 3 月)中详细描述了 Generator-Evaluator 对抗机制,强调评估者必须反复校准、保持怀疑态度。源码里这个角色叫 Verification Agent(验证员),它被指令明确要求「try to break it」------你的任务就是尽力把产出搞崩。它必须输出 PASS、FAIL 或 PARTIAL 三种标准化判定,没有模糊地带。
不是温和的代码审查员,是一个被要求尽力搞破坏的攻击者。
源码还把 Agent 按权限做了严格的角色隔离。负责调研的 Agent 只能读不能写,负责规划的 Agent 不能碰文件只能出方案。第三章讲的沙盒隔离思维,在这里变成了 Agent 类型系统的设计原则------什么角色能碰什么东西,出厂就定死了。
最后是第四章的核心论断。同样出自那篇三月发布的文章,Anthropic 说每次新模型发布,都要拆掉一个组件跑一遍,看数据说话。源码验证了这不是说说而已。所有高级功能都通过 feature flag(功能开关)门控,就像一排总闸,每个闸管一个功能。没启用的功能在构建时直接被移除,不会留在最终产品里。44 个开关,44 个随时可以拆掉的补丁。
不是方法论,是日常操作。
对账到此为止。前四章提到的每一条工程实践,都写进了产品里------而且记忆体系和多 Agent 并发这两个方向上,产品已经比文章走得远得多。
06 正在发生的「补偿面迁移」
但这 51 万行代码里,还有一些那些工程文章从来没提过的东西。而且它们的性质,跟前面三层壳完全不同。
前面三层壳解决的都是同一个问题,怎么让 Agent 把长程任务做好。记忆是为了不忘事,并发是为了干大活,验证是为了不糊弄。它们都是执行长程任务的必需品。
但源码里出现的几个新系统,不是。它们解决的问题已经不在「怎么执行任务」这个范畴里了。
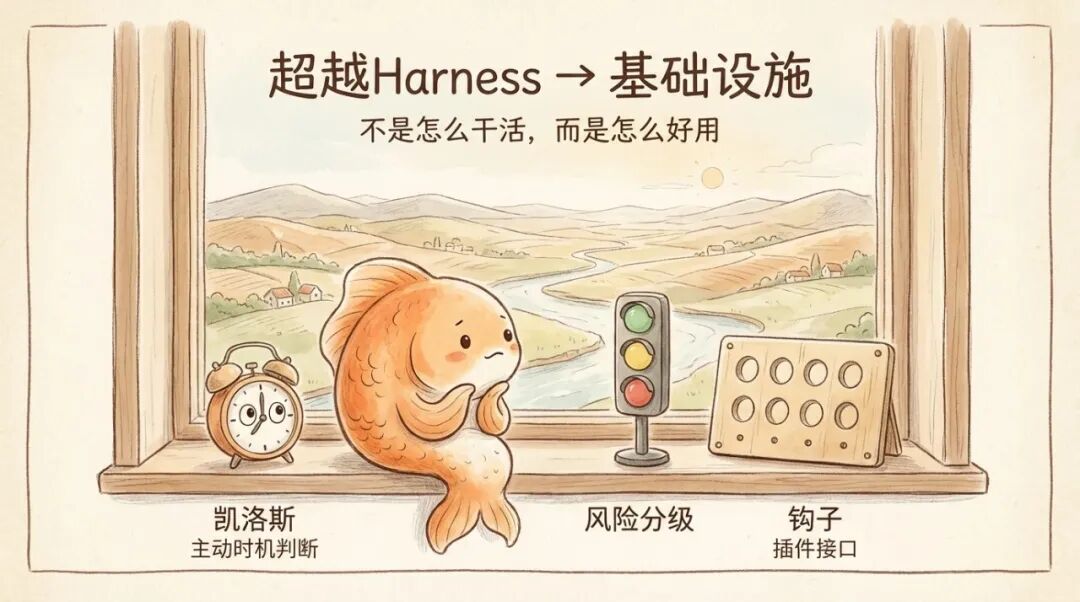
第一个叫 KAIROS。这是一个常驻后台的守护程序。它不等你开口。系统定时拍它肩膀问「现在需要你做什么吗」,它自己决定是行动还是沉默。但它有一个硬性限制,任何会打断用户工作超过 15 秒的操作,一律自动延后。
过去三层壳管的全是「怎么做」------怎么记住任务、怎么分配工作、怎么验证产出。KAIROS 管的是「该不该做」。Agent 从接到命令才动手的执行者,变成了时刻在旁边观察、自己判断时机的助手。15 秒这个数字是一种全新的度量单位------不是代码行数,不是测试通过率,是「打断人类的成本」。
第二个叫 YOLO Classifier。名字很随意,设计很认真。前面那些工程文章讨论权限时,基本都是二元逻辑,要么问用户,要么不问。Claude Code 的实现完全不是这样。它给每个操作都打了风险标签。读文件、搜索代码这类安全操作,直接放行,不打扰用户。写文件分两种情况------在项目目录内的走快速通道,出了项目目录的要走完整审批。执行命令行脚本永远走完整审批,因为一条命令理论上能干任何事,风险没有上限。
分类器对每次操作给出三种判定,放行、软拒绝(再确认一下)、硬拒绝(绝对不行)。更有意思的是它会学------你连续拒绝某类操作几次之后,系统自动记住,以后这类操作直接阻断,不再来烦你。
壳的松紧不再是工程师调好的固定值。它在根据你的习惯自动调节。壳在学习该怎么当壳。
第三个叫 Hooks(钩子)。想象 Agent 从启动到完成任务是一条流水线,源码在这条流水线的 8 个关键节点上埋了插槽。任何人都可以往插槽里塞自己写的检查脚本。脚本说「不行」,整条流水线就停下来。
前面那些文章里,壳是 Anthropic 自己设计、自己拆的。Hooks 把壳变成了一个开放平台。一家企业可以在插槽里挂自己的合规检查,一个开源社区可以挂自己的代码规范。壳不再是铁板一块,是一个有 8 个插槽的框架。谁都可以往上加自己的约束。
回头看这三个账外发现,它们有一个共同特征,没有一个是执行长程任务必须的。
不装 KAIROS,Agent 也能听命令执行。不装 YOLO Classifier,大不了每次都问用户。不装 Hooks,Anthropic 自己的壳依然能用。
但它们对效率、自定义和商业防御是必须的。
**KAIROS 让 Agent 从被动工具变成主动助手。**YOLO Classifier 让壳的松紧自适应。Hooks 让壳从封闭产品变成开放平台。反蒸馏让壳承担起知识产权保护的角色。
这些方向没有一个出现在过去十五个月的工程文章里。因为那些文章解决的是「怎么让 Agent 工作」,而这些新系统解决的是「怎么让 Agent 好用、可控、可商业化」。
前面四章讲的补偿面迁移,是壳在三层之间左右移动,某个组件从「需要」变成「不需要」,从开启变成关闭。
但这些账外发现指向的是另一种运动。壳不是在变薄或变厚,它在往全新的维度伸展。执行长程任务只是起点。壳正在从 Harness 向 Infra 蔓延。
补偿面不只是在迁移。它在膨胀。
推荐阅读与溯源
Anthropic 谱系(按演化逻辑排列)
• Building effective agents (2024-12)
• Effective context engineering for AI agents (2025-09)
• Effective harnesses for long-running agents (2025-11)
• Demystifying evals for AI agents (2026-01)
• Designing AI-resistant technical evaluations (2026-01)
• Building a C compiler with a team of parallel Claudes (2026-02)
• Harness design for long-running application development (2026-03)
• Quantifying infrastructure noise in agentic coding evals (2026-02)
OpenAI 实践
• Harness engineering: leveraging Codex in an agent-first world (2026-02)
• Unrolling the Codex agent loop (2026-01)
Cursor 实践
• Scaling long-running autonomous coding (2026-01-14)
• Building a better Bugbot (2026-01-15)
Langchain 实践
• LangChain, Improving Deep Agents with harness engineering (2026-02)
• LangChain, The Anatomy of an Agent Harness (2026-03)
行业观察与实证
• Lance Martin, Learning the Bitter Lesson (2025-07)
• Mitchell Hashimoto, Engineer the Harness (2026-02)
• Martin Fowler, Exploring Gen AI - Harness Engineering (2026-02)
reference
- 刚刚,Claude Code开源了!51万行代码,全网狂欢
https://mp.weixin.qq.com/s/ghy8vsqy7Kdq5QgPG9mpWw - Claude Code源码「换壳」反杀,全网疯狂克隆!Anthropic封杀失败
https://mp.weixin.qq.com/s/ASZRSMcXfomyVcr9YT70Rg - Python刚写完就转Rust!Claw Code连夜换皮重写,2小时狂揽57K Star-开源推荐-何三笔记
https://www.h3blog.com/article/741/ - 开盒Claude Code 的原来是中国00后!曾怒怼Anthropic窃取用户代码
https://mp.weixin.qq.com/s/ZHh6ou2P7foQ_Kgd8cg3Vw - Claude Code 源码泄露7小时:8大新功能/26个隐藏指令/6级安全架构,全被扒光了
https://mp.weixin.qq.com/s/cJGWji1XeOEXgYGvIxGCtA - 10分钟快速速通Claude Code泄露源码核心架构,里面居然藏了一个脏话彩蛋!
https://mp.weixin.qq.com/s/Bb-UX_ionC9QlSp_IvJqwQ - Claude Code 泄露的代码里,处处写着:这家公司人品不行
https://mp.weixin.qq.com/s/LUiHjBNR8maPpyWHmupQSA - 麻了,Claude 源码都传疯了,结果大多数人根本看不懂
https://mp.weixin.qq.com/s/tjorxnrmos1PHMUL7bbp-w - 看了Claude Code泄露的源码,发现4个意想不到的秘密...
https://mp.weixin.qq.com/s/d7dk182LtC6Bl7RGMeJVGQ - 一文读懂 Harness Engineering:从14篇工程文章中,寻找那个让AI不再离经叛道的壳|Hao好聊趋势
https://mp.weixin.qq.com/s/DE0hc3Mz6zwoSCgL0k4SgQ